Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| J | |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 251 |
| Programming | 102 |
| Language | 97 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Thu, 18 Jun 2026
My 1992 view of the problems of computer programming in 1992
While cleaning out my office today, I found this, which I wrote in 1992:
In the middle 1970's, the IBM corporation did (and perhaps still does) most of their in-house programming in a computer language called FORTRAN. They had a pretty good FORTRAN compiler, called the FORTRAN G compiler. It was fast at translating FORTRAN into machine instructions, and the machine instructions it produced implemented the desired behavior fairly efficiently. Nevertheless, IBM decided to write a new compiler.
This was very daring in the middle 1970's, because compilers were quite complicated programs, and are difficult to write, and it was surprising that IBM was willing to invest the vast resources that a new compiler would require when an adequate compiler was still available. IBM spent millions of dollars and hundreds of programmer-years, and produced the FORTRAN H compiler, which was fast, efficient, and full of nice features. It was an excellent compiler and is still the one that they use.
Here is the first punch line: Compiler programs are no longer difficult to write. The past fifteen years have seen an enormous increase in our understanding of compiler technology and how to write a compiler. Compilers are so easy to write now that third-year undergraduate computer science majors are expected to be able to turn out passable compilers in one semester.
Now a question: Since we're obviously thousands of times better at producing compilers than we were fifteen years ago, so much so that a single undergraduate can write a passable one in four months, why hasn't IBM invested millions of dollars and hundreds of programmer-years to produce a super FORTRAN I compiler that's thousands of times better than the FORTRAN H compiler?
The answer is that compiler program quality is no longer the limiting factor on our ability to write computer programs. The problems that programmers face no longer have to do with how good the compiler is. Instead, they are problems of method and language. We don't really know how to program yet, or how to manage our programs. We don't really know what we want to say or how to say it. We don't have good computer languages for expressing what we want to computer to do. We don't know how to think about programming. In short, the reason IBM doesn't bother with a super FORTRAN I compiler, is that no matter how good it was, it would still be FORTRAN.
Computer programming is still a black art. It's less than fifty years old, and nobody is very good at it yet. We can make better tools than we know how to use.
[Other articles in category /prog] permanent link
Mon, 26 Jan 2026
An anecdote about backward compatibility
A long time ago I worked on a debugger program that our company used to debug software that it sold that ran on IBM System 370. We had IBM 3270 CRT terminals that could display (I think) eight colors (if you count black), but the debugger display was only in black and white. I thought I might be able to make it a little more usable by highlighting important items in color.
I knew that the debugger used a macro called WRTERM to write text to
the terminal, and I thought maybe the description of this macro in the
manual might provide some hint about how to write colored text.
In those days, that office didn't have online manuals, instead we had shelf after shelf of yellow looseleaf binders. Finding the binder you wanted was an adventure. More than once I went to my boss to say I couldn't proceed without the REXX language reference or whatever. Sometimes he would just shrug. Other times he might say something like “Maybe Matthew knows where that is.”
I would go ask Matthew about it. Probably he would just shrug. But if he didn't, he would look at me suspiciously, pull the manual from under a pile of papers on his desk, and wave it at me threateningly. “You're going to bring this back to me, right?”
See, because if Matthew didn't hide it in his desk, he might become the person who couldn't find it when he needed it.
Matthew could have photocopied it and stuck his copy in a new binder, but why do that when burying it on his desk was so much easier?
For years afterward I carried around my own photocopy of the REXX language reference, not because I still needed it, but because it had cost me so much trouble and toil to get it. To this day I remember its horrible IBM name: SC24-5239 Virtual Machine / System Product System Product Interpreter Reference. That's right, "System Product" was in there twice. It was the System Product Interpreter for the System Product, you see.
Anyway, I'm digressing. I did eventually find a copy of the IBM
Assembler Product Macro Reference Document or whatever it was called,
and looked up WRTERM and to my delight it took an optional parameter
named COLOR. Jackpot!
My glee turned to puzzlement. If omitted, the default value for
COLOR was BLACK.
Black? Not white? I read further.
And I learned that the only other permitted value was RED, and only
if your terminal had a “two-color ribbon”.

[Other articles in category /prog] permanent link
Sun, 21 Sep 2025
My new git utility `what-changed-twice` needs a new name
As I have explained in the past, my typical workflow is to go
along commiting stuff that might or might not make sense, then clean it
all up at the end, doing multiple passes with git-add and git-rebase
to get related changes into the same commit, and then to order the
commits in a sensible way. Yesterday I built a new utility that I found
helpful. I couldn't think of a name for it, so I called it
what-changed-twice, which is not great but my I am bad at naming
things and my first attempt was analyze-commits. I welcome
suggestions. In this article I will call it Fred.
What is Fred for? I have a couple of uses for it so far.
Often as I work I'll produce a chain of commits that looks like this:
470947ff minor corrections
d630bf32 continue work on `jq` series
c24b8b24 wip
f4695e97 fix link
a8aa1a5c sp
5f1d7a61 WIP
a337696f Where is the quincunx on the quincunx?
39fe1810 new article: The fivefold symmetry of the quince
0a5a8e2e update broken link
196e7491 sp
bdc781f6 new article: fpuzhpx
40c52f47 merge old and new seasons articles and publish
b59441cd finish updating with Star Wars Droids
537a3545 droids and BJ and the Bear
d142598c Add nicely formatted season tables to this old article
19340470 mention numberphile video
It often happens that I will modify a file on Monday, modify it some more on Tuesday, correct a spelling error on Wednesday. I might have made 7 sets of changes to the main file, of which 4 are related, 2 others are related to each other but not to the other 4, and the last one is unrelated to any of the rest. When a file has changed more than once, I need to see what changed and then group the changes into related sets.
The sp commits are spelling corrections; if the error was made in the
same unmerged topic branch I will want to squash the correction into
the original commit so that the error never appears at all.
Some files changed only once, and I don't need to think about those at this stage. Later I can go back and split up those commits if it seems to make the history clearer.
Fred takes the output of git-log for the commits you are interested
in:
$ git log --stat -20 main...topic | /tmp/what-changed-twice
It finds which files were modified in which commits, and it prints a report about any file that was modified in more than one commit:
calendar/seasons.blog 196 40 d1
math/centrifuge.blog 193 33
misc/straight-men.blog 53 b5 bd
prog/jq-2.blog 33 5f d6
193 1934047
196 196e749
33 33a2304
40 40c52f4
53 537a354
5f 5f1d7a6
b5 b59441c
bd bdc781f
d1 d142598
d6 d630bf3
The report is in two parts. At the top, the path of each file that
changed more than once in the log, and the (highly-abbreviated) commit
IDs of the commits in which it changed. For example,
calendar/seasons.blog changed in commits 196, 40, and d1. The
second part of the report explains that 196 is actually an
abbreviation for commit 196e749.
Now I can look to see what else changed in those three commits:
$ git show --stat 196e749 40c52f4 d142598
then look at the changes to calendar/seasons.blog in those three
commits
$ git show 196e74 40c52f4 d142598 -- calendar/seasons.blog
and then decide if there are any changes I might like to squash together.
Many other files changed on the branch, but I only have to concern myself with four.
There's bonus information too. If a commit is not mentioned in the report, then it only changed files that didn't change in any other commit. That means that in a rebase, I can move that commit literally anywhere else in the sequence without creating a conflict. Only the commits in the report can cause conflicts if they are reordered.
I write most things in Python these days, but this one seemed to cry out for Perl. Here's the code.
Hmm, maybe I'll call it squash-what.
[Other articles in category /prog/git] permanent link
Fri, 29 Nov 2024
A complex bug with a ⸢simple⸣ fix
Last month I did a fairly complex piece of systems programming that worked surprisingly well. But it had one big bug that took me a day to track down.
One reason I find the bug interesting is that it exemplifies the sort of challenges that come up in systems programming. The essence of systems programming is that your program is dealing with the state of a complex world, with many independent agents it can't control, all changing things around. Often one can write a program that puts down a wrench and then picks it up again without looking. In systems programming, the program may have to be prepared for the possibility that someone else has come along and moved the wrench.
The other reason the bug is interesting is that although it was a big bug, fixing it required only a tiny change. I often struggle to communicate to nonprogrammers just how finicky and fussy programming is. Nonprogrammers, even people who have taken a programming class or two, are used to being harassed by crappy UIs (or by the compiler) about missing punctuation marks and trivially malformed inputs, and they think they understand how fussy programming is. But they usually do not. The issue is much deeper, and I think this is a great example that will help communicate the point.
The job of my program, called sync-spam, was to move several weeks of
accumulated email from system S to system T. Each message was
probably spam, but its owner had not confirmed that yet, and the
message was not yet old enough to be thrown away without confirmation.
The probably-spam messages were stored on system S in a directory hierarchy with paths like this:
/spam/2024-10-18/…
where 2024-10-18 was the date the message had been received. Every
message system S had received on October 18 was somewhere under
/spam/2024-10-18.
One directory, the one for the current date, was "active", and new
messages were constantly being written to it by some other programs
not directly related to mine. The directories for the older dates
never changed. Once sync-spam had dealt with the backlog of old messages, it
would continue to run, checking periodically for new messages in the
active directory.
The sync-spam program had a database that recorded, for each message, whether
it had successfully sent that message from S to T, so that it
wouldn't try to send the same message again.
The program worked like this:
- Repeat forever:
- Scan the top-level
spamdirectory for the available dates - For each date D:
- Scan the directory for D and find the messages in it. Add to the database any messages not already recorded there.
- Query the database for the list of messages for date D that have not yet been sent to T
- For each such message:
- Attempt to send the message
- If the attempt was successful, record that in the database
- Wait some appropriate amount of time and continue.
- Scan the top-level
Okay, very good. The program would first attempt to deal with all the
accumulated messages in roughly chronological order, processing the
large backlog. Let's say that on November 1 it got around to scanning
the active 2024-11-01 directory for the first time. There are many
messages, and scanning takes several minutes, so by the time it
finishes scanning, some new messages will be in the active directory that
it hasn't seen. That's okay. The program will attempt to send the
messages that it has seen. The next time it comes around to
2024-11-01 it will re-scan the directory and find the new messages
that have appeared since the last time around.
But scanning a date directory takes several minutes, so we would prefer not to do it if we don't have to. Since only the active directory ever changes, if the program is running on November 1, it can be sure that none of the directories from October will ever change again, so there is no point in its rescanning them. In fact, once we have located the messages in a date directory and recorded them in the database, there is no point in scanning it again unless it is the active directory, the one for today's date.
So sync-spam had an elaboration that made it much more efficient. It was
able to put a mark on a date directory that meant "I have completely
scanned this directory and I know it will not change again". The
algorithm was just as I said above, except with these elaborations.
- Repeat forever:
- Scan the top-level
spamdirectory for the available dates - For each date D:
- If the directory for D is marked as having already been scanned, we already know exactly what messages are in it, since they are already recorded in the database.
- Otherwise:
- Scan the directory for D and find the messages in it. Add to the database any messages not already recorded there.
- If D is not today's date, mark the directory for D as having been scanned completely, because we need not scan it again.
- Query the database for the list of messages for date D that have not yet been sent to T
- For each such message:
- Attempt to send the message
- If the attempt was successful, record that in the database
- Wait some appropriate amount of time and continue.
- Scan the top-level
It's important to not mark the active directory as having been completely scanned, because new messages are continually being deposited into it until the end of the day.
I implemented this, we started it up, and it looked good. For several
days it processed the backlog of unsent messages from
September and October, and it successfully sent most of them. It
eventually caught up to the active directory for the current date, 2024-11-01, scanned
it, and sent most of the messages. Then it went back and started over
again with the earliest date, attempting to send any messages that it
hadn't sent the first time.
But a couple of days later, we noticed that something was wrong.
Directories 2024-11-02 and 2024-11-03 had been created and were
well-stocked with the messages that had been received on those dates. The
program had found the directories for those dates and had marked them as having been
scanned, but there were no messages from those dates in its database.
Now why do you suppose that is?
(Spoilers will follow the horizontal line.)
I investigate this in two ways. First, I made sync-spam's logging more
detailed and looked at the results. While I was waiting for more logs
to accumulate, I built a little tool that would generate a small,
simulated spam directory on my local machine, and then I ran sync-spam
against the simulated messages, to make sure it was doing what I
expected.
In the end, though, neither of these led directly to my solving the problem; I just had a sudden inspiration. This is very unusual for me. Still, I probably wouldn't have had the sudden inspiration if the information from the logging and the debugging hadn't been percolating around my head. Fortune favors the prepared mind.
The problem was this: some other agent was creating the 2024-11-02
directory a bit prematurely, say at 11:55 PM on November 1.
Then sync-spam came along in the last minutes of November 1 and started its
main loop. It scanned the spam directory for available dates, and
found 2024-11-02. It processed the unsent messages from the
directories for earlier dates, then looked at 2024-11-02 for the
first time. And then, at around 11:58, as per above it would:
- Scan the directory for 2024-11-02 and find the messages in it. Add to the database any messages not already recorded there.
There weren't any yet, because it was still 11:58 on November 1.
- If 2024-11-02 is not today's date, mark the directory as having been scanned completely, because we need not scan it again.
Since the 2024-11-02 directory was not the one for today's date —
it was still 11:58 on November 1 — sync-spam recorded that it had
scanned that directory completely and need
not scan it again.
Five minutes later, at 00:03 on November 2, there would be new
messages in the 2024-11-02, which was now the active directory, but
sync-spam wouldn't look for them, because it had already marked 2024-11-02
as having been scanned completely.
This complex problem in this large program was completely fixed by changing:
if ($date ne $self->current_date) {
$self->mark_this_date_fully_scanned($date_dir);
}
to:
if ($date lt $self->current_date) {
$self->mark_this_date_fully_scanned($date_dir);
}
(ne and lt are Perl-speak for "not equal to" and "less than".)
Many organizations have their own version of a certain legend, which tells how a famous person from the past was once called out of retirement to solve a technical problem that nobody else could understand. I first heard the General Electric version of the legend, in which Charles Proteus Steinmetz was called out of retirement to figure out why a large complex of electrical equipment was not working.
In the story, Steinmetz walked around the room, looking briefly at each of the large complicated machines. Then, without a word, he took a piece of chalk from his pocket, marked one of the panels, and departed. When the puzzled engineers removed that panel, they found a failed component, and when that component was replaced, the problem was solved.
Steinmetz's consulting bill for $10,000 arrived the following week. Shocked, the bean-counters replied that $10,000 seemed an exorbitant fee for making a single chalk mark, and, hoping to embarrass him into reducing the fee, asked him to itemize the bill.
Steinmetz returned the itemized bill:
| One chalk mark | $1.00 |
| Knowing where to put it | $9,999.00 |
| TOTAL | $10,000.00 |
This felt like one of those times. Any day when I can feel a connection with Charles Proteus Steinmetz is a good day.
This episode also makes me think of the following variation on an old joke:
A: Ask me what is the most difficult thing about systems programming.
B: Okay, what is the most difficult thing ab—
A: TIMING!
[Other articles in category /prog/bug] permanent link
Sat, 16 Dec 2023
My Git pre-commit hook contained a footgun
The other day I made some changes to a program, but when I ran the tests they failed in a very bizarre way I couldn't understand. After a bit of investigation I still didn't understand. I decided to try to narrow down the scope of possible problems by reverting the code to the unmodified state, then introducing changes from one file at a time.
My plan was: commit all the new work, reset the working directory back to the last good commit, and then start pulling in file changes. So I typed in rapid succession:
git add -u
git commit -m 'broken'
git branch wat
git reset --hard good
So the complete broken code was on the new branch wat.
Then I wanted to pull in the first file from wat. But when I
examined wat there were no changes.
Wat.
I looked all around the history and couldn't find the changes. The
wat branch was there but it was on the current commit, the one with
none of the changes I wanted. I checked in the reflog for the commit
and didn't see it.
Eventually I looked back in my terminal history and discovered the
problem: I had a Git pre-commit hook which git-commit had
attempted to run before it made the new commit. It checks for strings
I don't usually intend to commit, such as XXX and the like.
This time one of the files had something like that. My pre-commit
hook had printed an error message and exited with a failure status, so
git-commit aborted without making the commit. But I had typed the
commands in quick succession without paying attention to what they
were saying, so I went ahead with the git-reset without even seeing
the error message. This wiped out the working tree changes that I had
wanted to preserve.
Fortunately the git-add had gone through, so the modified files were
in the repository anyway, just hard to find. And even more
fortunately, last time this happened to me, I wrote up
instructions about what to do.
This time around recovery was quicker and easier. I knew I only
needed to recover stuff from the last add command, so instead of
analyzing every loose object in the repository, I did
find .git/objects -mmin 10 --type f
to locate loose objects that had been modified in the last ten minutes. There were only half a dozen or so. I was able to recover the lost changes without too much trouble.
Looking back at that previous article, I see that it said:
it only took about twenty minutes… suppose that it had taken much longer, say forty minutes instead of twenty, to rescue the lost blobs from the repository. Would that extra twenty minutes have been time wasted? No! … The rescue might have cost twenty extra minutes, but if so it was paid back with forty minutes of additional Git expertise…
To that I would like to add, the time spent writing up the blog article was also well-spent, because it meant that seven years later I didn't have to figure everything out again, I just followed my own instructions from last time.
But there's a lesson here I'm still trying to figure out. Suppose I want to prevent this sort of error in the future. The obvious answer is “stop splatting stuff onto the terminal without paying attention, jackass”, but that strategy wasn't sufficient this time around and I couldn't think of any way to make it more likely to work next time around.
You have to play the hand you're dealt. If I can't fix myself, maybe I
can fix the software. I would like to make some changes to the
pre-commit hook to make it easier to recover from something like
this.
My first idea was that the hook could unconditionally save the staged changes somewhere before it started, and then once it was sure that it would complete it could throw away the saved changes. For example, it might use the stash for this.
(Although, strangely, git-stash does
not seem to have an easy way to say “stash the current changes, but
without removing them from the working tree”. Maybe git-stash save
followed by git-stash apply would do what I wanted? I have not yet
experimented with it.)
Rather than using the stash, the hook might just commit everything
(with commit -n to prevent infinite loops) and then reset the commit
immediately, before doing whatever it was planning to do. Then if it
was successful, Git would make a second, permanent commit and we could
forget about the one made by the hook. But if something went wrong,
the hook's commit would still be in the reflog. This doubles the
number of commits you make. That doesn't take much time, because Git
commit creation is lightning fast. But it would tend to clutter up
the reflog.
Thinking on it now, I wonder if a better approach isn't to turn the pre-commit hook into a post-commit hook. Instead of a pre-commit hook that does this:
- Check for errors in staged files
- If there are errors:
- Fix the files (if appropriate)
- Print a message
- Fail
- Otherwise:
- Exit successfully
- (
git-commitcontinues and commits the changes)
- If there are errors:
How about a post-commit hook that does this:
- Check for errors in the files that changed in the current head commit
- If there are errors:
- Soft-reset back to the previous commit
- Fix the files (if appropriate)
- Print a message
- Fail
- Otherwise:
- Exit successfully
- If there are errors:
Now suppose I ignore the failure, and throw away the staged changes. It's okay, the changes were still committed and the commit is still in the reflog. This seems clearly better than my earlier ideas.
I'll consider it further and report back if I actually do anything about this.
Larry Wall once said that too many programmers will have a problem, think of a solution, and implement it, but it works better if you can think of several solutions, then implement the one you think is best.
That's a lesson I think I have learned. Thanks, Larry.
Addendum
I see that Eric Raymond's version of the jargon file, last revised December 2003, omits “footgun”. Surely this word is not that new? I want to see if it was used on Usenet prior to that update, but Google Groups search is useless for this question. Does anyone have suggestions for how to proceed?
[Other articles in category /prog/git] permanent link
Sun, 26 Nov 2023
A Qmail example of dealing with unavoidable race conditions
[ I recently posted about a race condition bug reported by Joe Armstrong and said “this sort of thing is now in the water we swim in, but it wasn't yet [in those days of olde].” This is more about that. ]
I learned a lot by reading everything Dan Bernstein wrote about
the design of qmail. A good deal of
it is about dealing with potential issues just like Armstrong's. The
mail server might crash at any moment, perhaps because someone
unplugged the server. In DJB world, it is unacceptable for mail to be
lost, ever, and also for the mail queue structures to be corrupted if
there was a crash. That sounds obvious, right? Apparently it wasn't;
sendmail would do those things.
(I know someone wants to ask what about Postfix? At the time Qmail was released, Postfix was still called ‘VMailer’. The ‘V’ supposedly stood for “Venema” but the joke was that the ‘V’ was actually for “vaporware” because that's what it was.)
A few weeks ago I was explaining one of Qmail's data structures to a junior programmer. Suppose a local user queues an outgoing message that needs to be delivered to 10,000 recipients in different places. Some of the deliveries may succeed immediately. Others will need to be retried, perhaps repeatedly. Eventually (by default, ten days) delivery will time out and a bounce message will be delivered back to the sender, listing the recipients who did not receive the delivery. How does Qmail keep track of this information?
2023 junior programmer wanted to store a JSON structure or something. That is not what Qmail does. If the server crashes halfway through writing a JSON file, it will be corrupt and unreadable. JSON data can be written to a temporary file and the original can be replaced atomically, but suppose you succeed in delivering the message to 9,999 of the 10,000 recipients and the system crashes before you can atomically update the file? Now the deliveries will be re-attempted for those 9,999 recipients and they will get duplicate copies.
Here's what Qmail does instead. The file in the queue directory is in the following format:
Trecip1@host1■Trecip2@host2■…Trecip10000@host10000■
where ■ represents a zero byte. To 2023 eyes this is strange and uncouth, but to a 20th-century system programmer, it is comfortingly simple.
When Qmail wants to attempt a delivery to recip1346@host1346 it has
located that address in the file and seen that it has a T (“to-do”)
on the front. If it had been a D (“done”) Qmail would know that
delivery to that address had
already succeeded, and it would not attempt it again.
If delivery does succeed, Qmail updates the T to a D:
if (write(fd,"D",1) != 1) { close(fd); break; }
/* further errors -> double delivery without us knowing about it, oh well */
close(fd);
return;
The update of a single byte will be done all at once or not at all. Even writing two bytes is riskier: if the two bytes span a disk block boundary, the power might fail after only one of the modified blocks has been written out. With a single byte nothing like that can happen. Absent a catastrophic hardware failure, the data structure on the disk cannot become corrupted.
Mail can never be lost. The only thing that can go wrong here is if the local system crashes in between the successful delivery and the updating of the byte; in this case the delivery will be attempted again, to that one user.
Addenda
I think the data structure could even be updated concurrently by more than one process, although I don't think Qmail actually does this. Can you run multiple instances of
qmail-sendthat share a queue directory? (Even if you could, I can't think of any reason it would be a good idea.)I had thought the update was performed by
qmail-remote, but it appears to be done byqmail-send, probably for security partitioning reasons.qmail-localruns as a variable local user, so it mustn't have permission to modify the queue file, or local users would be able to steal email.qmail-remotedoesn't have this issue, but it would be foolish to implement the same functionality in two places without a really good reason.
[Other articles in category /prog] permanent link
Sat, 25 Nov 2023
Puzzling historical artifact in “Programming Erlang”?

Lately I've been reading Joe Armstrong's book Programming Erlang, and today I was brought up short by this passage from page 208:
Why Spawning and Linking Must Be an Atomic Operation
Once upon a time Erlang had two primitives,
spawnandlink, andspawn_link(Mod, Func, Args)was defined like this:spawn_link(Mod, Func, Args) -> Pid = spawn(Mod, Func, Args), link(Pid), Pid.Then an obscure bug occurred. …
Can you guess the obscure bug? I don't think I'm unusually skilled at concurrent systems programming, and I'm certainly no Joe Armstrong, but I thought the problem was glaringly obvious:
The spawned process died before the link statement was called, so the process died but no error signal was generated.
I scratched my head over this for quite some time. Not over the technical part, but about how famous expert Joe Amstrong could have missed this.
Eventually I decided that it was just that this sort of thing is now in the water we swim in, but it wasn't yet in the primeval times Armstrong was writing about. Sometimes problems are ⸢obvious⸣ because it's thirty years later and everyone has thirty years of experience dealing with those problems.
Another example
I was reminded of a somewhat similar example. Before the WWW came, a sysadmin's view of network server processes was very different than it is now. We thought of them primarily as attack surfaces, and ran as few as possible, as little as possible, and tried hard to prevent anyone from talking to them.
Partly this was because encrypted, authenticated communications
protocols were still an open research area. We now have ssh and
https layers to build on, but in those days we built on sand.
Another reason is that networking itself was pretty new, and we didn't
yet have a body of good technique for designing network services and
protocols, or for partitioning trust.
We didn't know how to write
good servers, and the ones that had been written were bad, often very
bad. Even thirty years ago, sendmail was notorious and had been a
vector for mass security failures, and even something as
innocuous-seeming as finger had turned out to have major issues.
When the Web came along, every sysadmin was thrust into a terrifying new world in which users clamored to write network services that could be talked to at all times by random Internet people all over the world. It was quite a change.
[ I wrote more about system race conditions, but decided to postpone it to Monday. Check back then. ]
[Other articles in category /prog] permanent link
Mon, 23 Oct 2023Katara is taking a Data Structures course this year. The most recent assignment gave her a lot of trouble, partly because it was silly and made no sense, but also because she does not yet know an effective process for writing programs, and the course does not attempt to teach her. On the day the last assignment was due I helped her fix the remaining bugs and get it submitted. This is the memo I wrote to her to memorialize the important process issues that I thought of while we were working on it.
You lost a lot of time and energy dealing with issues like: Using
vim; copying files back and forth with scp; losing the network connection; the college shared machine is slow and yucky.It's important to remove as much friction as possible from your basic process. Otherwise it's like trying to cook with dull knives and rusty pots, except worse because it interrupts your train of thought. You can't do good work with bad tools.
When you start the next project, start it in VScode in the beginning. And maybe set aside an hour or two before you start in earnest, just to go through the VSCode tutorial and familiarize yourself with its basic features, without trying to do that at the same time you are actually thinking about your homework. This will pay off quickly.
It's tempting to cut corners when writing code. For example:
It's tempting to use the first variable or function name you think of instead of taking a moment to think of a suggestive one. You had three classes in your project, all with very similar names. You might imagine that this doesn't matter, you can remember which is which. But remembering imposes a tiny cost every time you do it. These tiny costs seem insignificant. But they compound.
It's tempting to use a short, abbreviated variable or method name instead of a longer more recognizable one because it's quicker to type. Any piece of code is read more often than it is written, so that is optimizing in the wrong place. You need to optimize for quick and easy reading, at the cost of slower and more careful writing, not the other way around.
It's tempting to write a long complicated expression instead of two or three shorter ones where the intermediate results are stored in variables. But then every time you look at the long expression you have to pause for a moment to remember what is going on.
It's tempting to repeat the same code over and over instead of taking the time to hide it behind an interface. For example your project was full of
array[d-1900]all over. This minus-1900 thing should have been hidden inside one of the classes (I forget which). Any code outside that had to communicate with this class should have done so with full year numbers like 1926. That way, when you're not in that one class, you can ignore and forget about the issue entirely. Similarly, if code outside a class is doing the same thing in more than once place, it often means that the class needs another method that does that one thing. You add that method, and then the code outside can just call the method when it needs to do the thing. You advance the program by extending the number of operations it can perform without your thinking of them.If something is messy, it is tempting to imagine that it doesn't matter. It does matter. Those costs are small but compound. Invest in cleaning it up messy code, because if you don't the code will get worse and worse until the mess is a serious impediment. This is like what happens when you are cooking if you don't clean up as you go. At first it's only a tiny hindrance, but if you don't do it constantly you find yourself working in a mess, making mistakes, and losing and breaking things.
Debugging is methodical. Always have clear in your mind what question you are trying to answer, and what your plan is for investigating that question. The process looks like this:
I don't like that it is printing out 0 instead of 1. Why is it doing that? Is the printing wrong, or is the printing correct but the data is wrong?
I should go into the function that does the printing, and print out the data in the simplest way possible, to see if it is correct. (If it's already printing out the data in the simplest way possible, the problem must be in the data.)
(Supposing that the it's the data that is bad) Where did the bad data come from? If it came from some other function, what function was it? Did that function make up the wrong data from scratch, or did it get it from somewhere else?
If the function got the data from somewhere else, did it pass it along unchanged or did it modify the data? If it modified the data, was the data correct when the function got it, or was it already wrong?
The goal here is to point the Finger of Blame: What part of the code is really responsible for the problem? First you accuse the code that actually prints the wrong result. Then that code says “Nuh uh, it was like that when I got it, go blame that other guy that gave it to me.” Eventually you find the smoking gun.
Novice programmers often imagine that they can figure out what is wrong from looking at the final output and intuiting the solution Sherlock Holmes style. This is mistaken. Nobody can do this. Debugging is an engineering discipline: You come up with a hypothesis, then test the hypothesis. Then you do it again.
Ask Dad for assistance when appropriate. I promise not to do anything that would violate the honor code.
Something we discussed that I forgot to include in the memo that we discussed is: After you fix something significant, or add significant new functionality, make a checkpoint copy of the entire source code. This can be as simple as simply copying it all into separate folder. That way, when you are fixing the next thing, if you mess up and break everything, it's easy to get back to a known-good state. The computer is really clumsy to use for many tasks, but it's just great at keeping track of information, so exploit that when you can.
I think CS curricula should have a class that focuses specifically on these issues, on the matter of how do you actually write software?
But they never do.
[Other articles in category /prog] permanent link
Wed, 13 Sep 2023
Horizontal and vertical complexity
Note: The jumping-off place for this article is a conference talk which I did not attend. You should understand this article as rambling musings on related topics, not as a description of the talk or a response to it or a criticism of it or as a rebuttal of its ideas.
A co-worker came back from PyCon reporting on a talk called “Wrapping up the Cruft - Making Wrappers to Hide Complexity”. He said:
The talk was focussed on hiding complexity for educational purposes. … The speaker works for an educational organisation … and provided an example of some code for blinking lights on a single board machine. It was 100 lines long, you had to know about a bunch of complexity that required you to have some understanding of the hardware, then an example where it was the initialisation was wrapped up in an import and for the kids it was as simple as selecting a colour and which led to light up. And how much more readable the code was as a result.
The better we can hide how the sausage is made the more approachable and easier it is for those who build on it to be productive. I think it's good to be reminded of this lesson.
I was on fully board with this until the last bit, which gave me an uneasy feeling. Wrapping up code this way reduces horizontal complexity in that it makes the top level program shorter and quicker. But it increases vertical complexity because there are now more layers of function calling, more layers of interface to understand, and more hidden magic behavior. When something breaks, your worries aren't limited to understanding what is wrong with your code. You also have to wonder about what the library call is doing. Is the library correct? Are you calling it correctly? The difficulty of localizing the bug is larger, and when there is a problem it may be in some module that you can't see, and that you may not know exists.
Good interfaces successfuly hide most of this complexity, but even in the best instances the complexity has only been hidden, and it is all still there in the program. An uncharitable description would be that the complexity has been swept under the carpet. And this is the best case! Bad interfaces don't even succeed in hiding the complexity, which keeps leaking upward, like a spreading stain on that carpet, one that warns of something awful underneath.
Advice about how to write programs bangs the same drum over and over and over:
- Reduce complexity
- Do the simplest thing that could possibly work
- You ain't gonna need it
- Explicit is better than implicit
But here we have someone suggesting the opposite. We should be extremely wary.
There is always a tradeoff. Leaky abstractions can increase the vertical complexity by more than they decrease the horizontal complexity. Better-designed abstractions can achieve real wins.
It’s a hard, hard problem. That’s why they pay us the big bucks.
Ratchet effects
This is a passing thought that I didn't consider carefully enough to work into the main article.
A couple of years ago I wrote an article called Creeping featurism and the ratchet effect about how adding features to software, or adding more explanations to the manual, is subject to a “ratcheting force”. The benefit of the change is localized and easy to imagine:
You can imagine a confused person in your head, someone who happens to be confused in exactly the right way, and who is miraculously helped out by the presence of the right two sentences in the exact right place.
But the cost of the change is that the manual is now a tiny bit larger. It doesn't affect any specific person. But it imposes a tiny tax on everyone who uses the manual.
Similarly adding a feature to software has an obvious benefit, so there's pressure to add more features, and the costs are hidden, so there's less pressure in the opposite direction.
And similarly, adding code and interfaces and libraries to software has an obvious benefit: look how much smaller the top-level code has become! But the cost, that the software is 0.0002% more complex, is harder to see. And that cost increases imperceptibly, but compounds exponentially. So you keep moving in the same direction, constantly improving the software architecture, until one day you wake up and realize that it is unmaintainable. You are baffled. What could have gone wrong?
Kent Beck says, “design isn't free”.
Anecdote
The original article is in the context of a class for beginners where the kids just want to make the LEDs light up. If I understand the example correctly, in this context I would probably have made the same choice for the same reason.
But I kept thinking of an example where I made the opposite choice. I
taught an introduction to programming in C class about thirty years
ago. The previous curriculum had considered pointers an advanced topic
and tried to defer them to the middle of the semester. But the author
of the curriculum had had a big problem: you need pointers to deal with
scanf. What to do?
The solution chosen by the previous curriculum was to supply the students with a library of canned input functions like
int get_int(void); /* Read an integer from standard input */
These used scanf under the hood. (Under the carpet, one might say.)
But all the code with pointers was hidden.
I felt this was a bad move. Even had the library been a perfect abstraction (it wasn't) and completely bug-free (it wasn't) it would still have had a giant flaw: Every minute of time the students spent learning to use this library was a minute wasted on something that would never be of use and that had no intrinsic value. Every minute of time spent on this library was time that could have been spent learning to use pointers! People programming in C will inevitably have to understand pointers, and will never have to understand this library.
My co-worker from the first part of this article wrote:
The better we can hide how the sausage is made the more approachable and easier it is for those who build on it to be productive.
In some educational contexts, I think this is a good idea. But not if you are trying to teach people sausage-making!
[Other articles in category /prog] permanent link
Mon, 27 Feb 2023
I wish people would stop insisting that Git branches are nothing but refs
I periodically write about Git, and sometimes I say something like:
Branches are named sequences of commits
and then a bunch of people show up and say “this is wrong, a branch is nothing but a ref”. This is true, but only in a very limited and unhelpful way. My description is a more useful approximation to the truth.
Git users think about branches and talk about branches. The Git documentation talks about branches and many of the commands mention branches. Pay attention to what experienced users say about branches while using Git, and it will be clear that they do not think of branches simply as just refs. In that sense, branches do exist: they are part of our mental model of how the repository works.
Are you a Git user who wants to argue about this? First ask yourself what we mean when we say “is your topic branch up to date?” “be sure to fetch the dev branch” “what branch did I do that work on?” “is that commit on the main branch or the dev branch?” “Has that work landed on the main branch?” “The history splits in two here, and the left branch is Alice's work but the right branch is Bob's”. None of these can be understood if you think that a branch is nothing but a ref. All of these examples show that when even the most sophisticated Git users talk about branches, they don't simply mean refs; they mean sequences of commits.
Here's an example from the official Git documentation, one of many: “If the upstream branch already contains a change you have made…”. There's no way to understand this if you insist that “branch” here means a ref or a single commit. The current Git documentation contains the word “branch” over 1400 times. Insisting that “a branch is nothing but a ref” is doing people disservice, because they are going to have to unlearn that in order to understand the documentation.
Some unusually dogmatic people might still argue that a branch is nothing but a ref. “All those people who say those things are wrong,” they might say, “even the Git documentation is wrong,” ignoring the fact that they also say those things. No, sorry, that is not the way language works. If someone claims that a true shoe is is really a Javanese dish of fried rice and fish cake, and that anyone who talks about putting shoes on their feet is confused or misguided, well, that person is just being silly.
The reason people say this, the disconnection is that the Git
software doesn't have any formal representation of branches.
Conceptually, the branch is there; the git commands just don't
understand it. This is the most important mismatch between the
conceptual model and what the Git software actually does.
Usually when a software model doesn't quite match its domain, we recognize that it's the software that is deficient. We say “the software doesn't represent that concept well” or “the way the software deals with that is kind of a hack”. We have a special technical term for it: it's a “leaky abstraction”. A “leaky abstraction” is when you ought to be able to ignore the underlying implementation, but the implementation doesn't reflect the model well enough, so you have to think about it more than you would like to.
When there's a leaky abstraction we don't normally try to pretend that the software's deficient model is actually correct, and that everyone in the world is confused. So why not just admit what's going on here? We all think about branches and talk about branches, but Git has a leaky abstraction for branches and doesn't handle branches very well. That's all, nothing unusual. Sometimes software isn't perfect.
When the Git software needs to deal with branches, it has to finesse
the issue somehow. For some commands, hardly any finesse is required.
When you do git log dev to get the history of the dev branch, Git
starts at the commit named dev and then works its way back, parent
by parent, to all the ancestor commits. For history logs, that's
exactly what you want! But Git never has to think of the branch as a
single entity; it just thinks of one commit at a time.
When you do git-merge, you might think you're merging two branches,
but again Git can finesse the issue. Git has to look at a little bit
of history to figure out a merge base, but after that it's not merging
two branches at all, it's merging two sets of changes.
In other cases Git uses a ref to indicate the end point of the branch (called the ‘tip’), and sorta infers the start point from context. For example, when you push a branch, you give the software a ref to indicate the end point of the branch, and it infers the start point: the first commit that the remote doesn't have already. When you rebase a branch, you give the software a ref to indicate the end point of the branch, and the software infers the start point, which is the merge-base of the start point and the upstream commit you're rebasing onto. Sometimes this inference goes awry and the software tries to rebase way more than you thought it would: Git's idea of the branch you're rebasing isn't what you expected. That doesn't mean it's right and you're wrong; it's just a miscommunication.
And sometimes the mismatch isn't well-disguised. If I'm looking at
some commit that was on a branch that was merged to master long ago,
what branch was that exactly? There's no way to know, if the ref was
deleted. (You can leave a note in the commit message, but that is not
conceptually different from leaving a post-it on your monitor.) The
best I can do is to start at the current master, work my way back in
history until I find the merge point, then study the other commits
that are on the same topic branch to try to figure out what was going
on. What if I merged some topic branch into master last week, other
work landed after that, and now I want to un-merge the topic? Sorry,
Git doesn't do that. And why not? Because the software doesn't
always understand branches in the way we might like. Not because the
question doesn't make sense, just because the software doesn't always
do what we want.
So yeah, the the software isn't as good as we might like. What software is? But to pretend that the software is right, and that all the defects are actually benefits is a little crazy. It's true that Git implements branches as refs, plus also a nebulous implicit part that varies from command to command. But that's an unfortunate implementation detail, not something we should be committed to.
[ Addendum 20230228: Several people have reminded me that the suggestions of the next-to-last paragraph are possible in some other VCSes, such as Mercurial. I meant to mention this, but forgot. Thanks for the reminder. ]
[Other articles in category /prog/git] permanent link
Sun, 04 Dec 2022
Software horror show: SAP Concur
This complaint is a little stale, but maybe it will still be interesting. A while back I was traveling to California on business several times a year, and the company I worked for required that I use SAP Concur expense management software to submit receipts for reimbursement.
At one time I would have had many, many complaints about Concur. But today I will make only one. Here I am trying to explain to the Concur phone app where my expense occurred, maybe it was a cab ride from the airport or something.
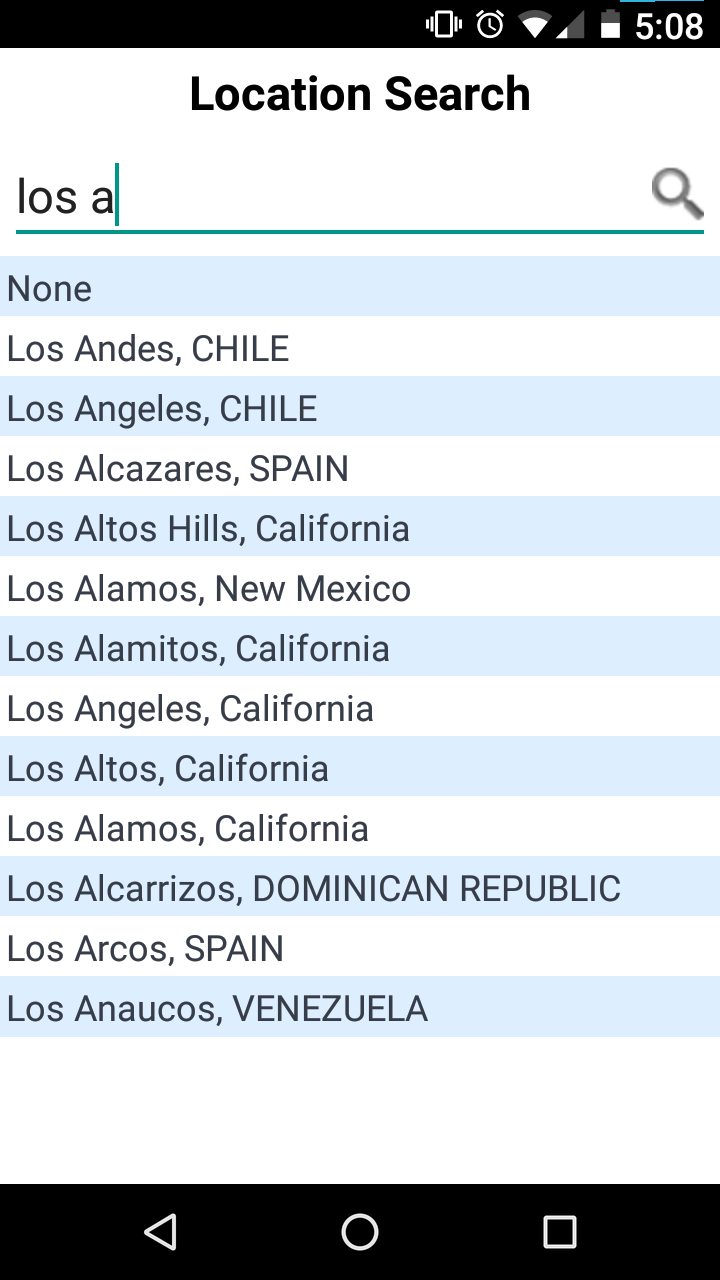
I had to interact with this control every time there was another expense to report, so this is part of the app's core functionality.
There are a lot of good choices about how to order this list. The best ones require some work. The app might use the phone's location feature to figure out where it is and make an educated guess about how to order the place names. (“I'm in California, so I'll put those first.”) It could keep a count of how often this user has chosen each location before, and put most commonly chosen ones first. It could store a list of the locations the user has selected before and put the previously-selected ones before the ones that had never been selected. It could have asked, when the expense report was first created, if there was an associated location, say “California”, and then used that to put California places first, then United States places, then the rest. It could have a hardwired list of the importance of each place (or some proxy for that, like population) and put the most important places at the top.
The actual authors of SAP Concur's phone app did none of these things. I understand. Budgets are small, deadlines are tight, product managers can be pigheaded. Sometimes the programmer doesn't have the resources to do the best solution.
But this list isn't even alphabetized.
There are two places named Los Alamos; they are not adjacent. There are two places in Spain; they are also not adjacent. This is inexcusable. There is no resource constraint that is so stringent that it would prevent the programmers from replacing
displaySelectionList(matches)
with
displaySelectionList(matches.sorted())
They just didn't.
And then whoever reviewed the code, if there was a code review, didn't
say “hey, why didn't you use displaySortedSelectionList here?”
And then the product manager didn't point at the screen and say “wouldn't it be better to alphabetize these?”
And the UX person, if there was one, didn't raise any red flag, or if they did nothing was done.
I don't know what Concur's software development and release process is like, but somehow it had a complete top-to-bottom failure of quality control and let this shit out the door.
I would love to know how this happened. I said a while back:
Assume that bad technical decisions are made rationally, for reasons that are not apparent.
I think this might be a useful counterexample. And if it isn't, if the individual decision-makers all made choices that were locally rational, it might be an instructive example on how an organization can be so dysfunctional and so filled with perverse incentives that it produces a stack of separately rational decisions that somehow add up to a failure to alphabetize a pick list.
Addendum : A possible explanation
Dennis Felsing, a former employee of SAP working on their HANA database, has suggested how this might have come about. Suppose that the app originally used a database that produced the results already sorted, so that no sorting in the client was necessary, or at least any omitted sorting wouldn't have been noticed. Then later, the backend database was changed or upgraded to one that didn't have the autosorting feature. (This might have happened when Concur was acquired by SAP, if SAP insisted on converting the app to use HANA instead of whatever it had been using.)
This change could have broken many similar picklists in the same way. Perhaps there was large and complex project to replace the database backend, and the unsorted picklist were discovered relatively late and were among the less severe problems that had to be overcome. I said “there is no resource constraint that is so stringent that it would prevent the programmers from (sorting the list)”. But if fifty picklists broke all at the same time for the same reason? And you weren't sure where they all were in the code? At the tail end of a large, difficult project? It might have made good sense to put off the minor problems like unsorted picklists for a future development cycle. This seems quite plausible, and if it's true, then this is not a counterexample of “bad technical decisions are made rationally for reasons that are not apparent”. (I should add, though, that the sorting issue was not fixed in the next few years.)
In the earlier article I said “until I got the correct explanation, the only explanation I could think of was unlimited incompetence.” That happened this time also! I could not imagine a plausible explanation, but M. Felsing provided one that was so plausible I could imagine making the decision the same way myself. I wish I were better at thinking of this kind of explanation.
[Other articles in category /prog] permanent link
Fri, 04 Nov 2022
A map of Haskell's numeric types
I keep getting lost in the maze of Haskell's numeric types. Here's the map I drew to help myself out. (I think there might have been something like this in the original Haskell 1998 report.)

Ovals are typeclasses. Rectangles are types. Black mostly-straight arrows show instance relationships. Most of the defined functions have straightforward types like !!\alpha\to\alpha!! or !!\alpha\to\alpha\to\alpha!! or !!\alpha\to\alpha\to\text{Bool}!!. The few exceptions are shown by wiggly colored arrows.
Basic plan
After I had meditated for a while on this picture I began to understand the underlying organization. All numbers support !!=!! and !!\neq!!. And there are three important properties numbers might additionally have:
Ord: ordered; supports !!\lt\leqslant\geqslant\gt!! etc.Fractional: supports divisionEnum: supports ‘pred’ and ‘succ’
Integral types are both Ord and Enum, but they are not
Fractional because integers aren't closed under division.
Floating-point and rational types are Ord and Fractional but not
Enum because there's no notion of the ‘next’ or ‘previous’ rational
number.
Complex numbers are numbers but not Ord because they don't admit a
total ordering. That's why Num plus Ord is called Real: it's
‘real’ as constrasted with ‘complex’.
More stuff
That's the basic scheme. There are some less-important elaborations:
Real plus Fractional is called RealFrac.
Fractional numbers can be represented as exact rationals or as
floating point. In the latter case they are instances of
Floating. The Floating types are required to support a large
family of functions like !!\log, \sin,!! and π.
You can construct a Ratio a type for any a; that's a fraction
whose numerators and denominators are values of type a. If you do this, the
Ratio a that you get is a Fractional, even if a wasn't one. In particular,
Ratio Integer is called Rational and is (of course) Fractional.
Shuff that don't work so good
Complex Int and Complex Rational look like they should exist, but
they don't really. Complex a is only an instance of Num when a
is floating-point. This means you can't even do 3 :: Complex
Int — there's no definition of fromInteger.
You can construct values of type Complex Int, but you can't do
anything with them, not even addition and subtraction. I think the
root of the problem is that Num requires an abs
function, and for complex numbers you need the sqrt function to be
able to compute abs.
Complex Int could in principle support most of the functions
required by Integral (such as div and mod) but Haskell
forecloses this too because its definition of Integral requires
Real as a prerequisite.
You are only allowed to construct Ratio a if a is integral.
Mathematically this is a bit odd. There is a generic construction,
called the field of quotients, which takes
a ring and turns it into a field, essentially by considering all the
formal fractions !!\frac ab!! (where !!b\ne 0!!), and with !!\frac ab!!
considered equivalent to !!\frac{a'}{b'}!! exactly when !!ab' = a'b!!.
If you do this with the integers, you get the rational numbers; if you
do it with a ring of polynomials, you get a field of rational functions, and
so on. If you do it to a ring that's already a field, it still
works, and the field you get is trivially isomorphic to the original
one. But Haskell doesn't allow it.
I had another couple of pages written about yet more ways in which the numeric class hierarchy is a mess (the draft title of this article was "Haskell's numbers are a hot mess") but I'm going to cut the scroll here and leave the hot mess for another time.
[ Addendum: Updated SVG and PNG to version 1.1. ]
[Other articles in category /prog/haskell] permanent link
Sun, 23 Oct 2022
This search algorithm is usually called "group testing"
Yesterday I described an algorithm that locates the ‘bad’ items among a set of items, and asked:
does this technique have a name? If I wanted to tell someone to use it, what would I say?
The answer is: this is group testing, or, more exactly, the “binary splitting” version of adaptive group testing, in which we are allowed to adjust the testing strategy as we go along. There is also non-adaptive group testing in which we come up with a plan ahead of time for which tests we will perform.
I felt kinda dumb when this was pointed out, because:
- A typical application (and indeed the historically first application) is for disease testing
- My previous job was working for a company doing high-throughput disease testing
- I found out about the job when one of the senior engineers there happened to overhear me musing about group testing
- Not only did I not remember any of this when I wrote the blog post, I even forgot about the disease testing application while I was writing the post!
Oh well. Thanks to everyone who wrote in to help me! Let's see, that's Drew Samnick, Shreevatsa R., Matt Post, Matt Heilige, Eric Harley, Renan Gross, and David Eppstein. (Apologies if I left out your name, it was entirely unintentional.)
I also asked:
Is the history of this algorithm lost in time, or do we know who first invented it, or at least wrote it down?
Wikipedia is quite confident about this:
The concept of group testing was first introduced by Robert Dorfman in 1943 in a short report published in the Notes section of Annals of Mathematical Statistics. Dorfman's report – as with all the early work on group testing – focused on the probabilistic problem, and aimed to use the novel idea of group testing to reduce the expected number of tests needed to weed out all syphilitic men in a given pool of soldiers.
Eric Harley said:
[It] doesn't date back as far as you might think, which then makes me wonder about the history of those coin weighing puzzles.
Yeah, now I wonder too. Surely there must be some coin-weighing puzzles in Sam Loyd or H.E. Dudeney that predate Dorfman?
Dorfman's original algorithm is not the one I described. He divides the items into fixed-size groups of n each, and if a group of n contains a bad item, he tests the n items individually. My proposal was to always split the group in half. Dorfman's two-pass approach is much more practical than mine for disease testing, where the test material is a body fluid sample that may involve a blood draw or sticking a swab in someone's nose, where the amount of material may be limited, and where each test offers a chance to contaminate the sample.
Wikipedia has an article about a more sophisticated of the binary-splitting algorithm I described. The theory is really interesting, and there are many ingenious methods.
Thanks to everyone who wrote in. Also to everyone who did not. You're all winners.
[ Addendum 20221108: January First-of-May has brought to my attention section 5c of David Singmaster's Sources in Recreational Mathematics, which has notes on the known history of coin-weighing puzzles. To my surprise, there is nothing there from Dudeney or Loyd; the earliest references are from the American Mathematical Monthly in 1945. I am sure that many people would be interested in further news about this. ]
[Other articles in category /prog] permanent link
Fri, 21 Oct 2022
More notes on deriving Applicative from Monad
A year or two ago I wrote about what you do if you already have a Monad and you need to define an Applicative instance for it. This comes up in converting old code that predates the incorporation of Applicative into the language: it has these monad instance declarations, and newer compilers will refuse to compile them because you are no longer allowed to define a Monad instance for something that is not an Applicative. I complained that the compiler should be able to infer this automatically, but it does not.
My current job involves Haskell programming and I ran into this issue again in August, because I understood monads but at that point I was still shaky about applicatives. This is a rough edit of the notes I made at the time about how to define the Applicative instance if you already understand the Monad instance.
pure is easy: it is identical to return.
Now suppose we
have >>=: how can we get <*>? As I eventually figured out last
time this came up, there is a simple solution:
fc <*> vc = do
f <- fc
v <- vc
return $ f v
or equivalently:
fc <*> vc = fc >>= \f -> vc >>= \v -> return $ f v
And in fact there is at least one other way to define it is just as good:
fc <*> vc = do
v <- vc
f <- fc
return $ f v
(Control.Applicative.Backwards
provides a Backwards constructor that reverses the order of the
effects in <*>.)
I had run into this previously
and written a blog post about it.
At that time I had wanted the second <*>, not the first.
The issue came up again in August because, as an exercise, I was trying to
implement the StateT state transformer monad constructor from scratch. (I found
this very educational. I had written State before, but StateT was
an order of magnitude harder.)
I had written this weird piece of code:
instance Applicative f => Applicative (StateT s f) where
pure a = StateT $ \s -> pure (s, a)
stf <*> stv = StateT $
\s -> let apf = run stf s
apv = run stv s
in liftA2 comb apf apv where
comb = \(s1, f) (s2, v) -> (s1, f v) -- s1? s2?
It may not be obvious why this is weird. Normally the definition of
<*> would look something like this:
stf <*> stv = StateT $
\s0 -> let (s1, f) = run stf s0
let (s2, v) = run stv s1
in (s2, f v)
This runs stf on the initial state, yielding f and a new state
s1, then runs stv on the new state, yielding v and a final state
s2. The end result is f v and the final state s2.
Or one could just as well run the two state-changing computations in the opposite order:
stf <*> stv = StateT $
\s0 -> let (s1, v) = run stv s0
let (s2, f) = run stf s1
in (s2, f v)
which lets stv mutate the state first and gives stf the result
from that.
I had been unsure of whether I wanted to run stf or stv first. I
was familiar with monads, in which the question does not come up. In
v >>= f you must run v first because you will pass its value
to the function f. In an Applicative there is no such dependency, so I
wasn't sure what I neeeded to do. I tried to avoid the question by
running the two computations ⸢simultaneously⸣ on the initial state
s0:
stf <*> stv = StateT $
\s0 -> let (sf, f) = run stf s0
let (sv, v) = run stv s0
in (sf, f v)
Trying to sneak around the problem, I was caught immediately, like a
small child hoping to exit a room unseen but only getting to the
doorway. I could run the computations ⸢simultaneously⸣ but on the
very next line I still had to say what the final state was in the end:
the one resulting from computation stf or the one resulting from
computation stv. And whichever I chose, I would be discarding the
effect of the other computation.
My co-worker Brandon Chinn
opined that this must
violate one of the
applicative functor laws.
I wasn't sure, but he was correct.
This implementation of <*> violates the applicative ”interchange”
law that requires:
f <*> pure x == pure ($ x) <*> f
Suppose f updates the state from !!s_0!! to !!s_f!!. pure x and
pure ($ x), being pure, leave it unchanged.
My proposed implementation of <*> above runs the two
computations and then updates the state to whatever was the result of
the left-hand operand, sf discarding any updates performed by the right-hand
one. In the case of f <*> pure x the update from f is accepted
and the final state is !!s_f!!.
But in the case of pure ($ x) <*> f the left-hand operand doesn't do
an update, and the update from f is discarded, so the final state is
!!s_0!!, not !!s_f!!. The interchange law is violated by this implementation.
(Of course we can't rescue this by yielding (sv, f v) in place of
(sf, f v); the problem is the same. The final state is now the
state resulting from the right-hand operand alone, !!s_0!! on the
left side of the law and !!s_f!! on the right-hand side.)
Stack Overflow discussion
I worked for a while to compose a question about this for Stack Overflow, but it has been discussed there at length, so I didn't need to post anything:
<**>is a variant of<*>with the arguments reversed. What does "reversed" mean?- How arbitrary is the "ap" implementation for monads?
- To what extent are Applicative/Monad instances uniquely determined?
That first thread contains this enlightening comment:
Functors are generalized loops
[ f x | x <- xs];Applicatives are generalized nested loops
[ (x,y) | x <- xs, y <- ys];Monads are generalized dynamically created nested loops
[ (x,y) | x <- xs, y <- k x].
That middle dictum provides another way to understand why my idea of running the effects ⸢simultaneously⸣ was doomed: one of the loops has to be innermost.
The second thread above (“How arbitrary is the ap implementation for
monads?”) is close to what I was aiming for in my question, and
includes a wonderful answer by Conor McBride (one of the inventors of
Applicative). Among other things, McBride points out that there are at least
four reasonable Applicative instances consistent with the monad
definition for nonempty lists.
(There is a hint in his answer here.)
Another answer there sketches a proof that if the applicative
”interchange” law holds for some applicative functor f, it holds for
the corresponding functor which is the same except that its <*>
sequences effects in the reverse order.
[Other articles in category /prog/haskell] permanent link
Wed, 19 Oct 2022
What's this search algorithm usually called?
Consider this problem:
Input: A set !!S!! of items, of which an unknown subset, !!S_{\text{bad}}!!, are ‘bad’, and a function, !!\mathcal B!!, which takes a subset !!S'!! of the items and returns true if !!S'!! contains at least one bad item:
$$ \mathcal B(S') = \begin{cases} \mathbf{false}, & \text{if $S'\cap S_{\text{bad}} = \emptyset$} \\ \mathbf{true}, & \text{otherwise} \\ \end{cases} $$
Output: The set !!S_{\text{bad}}!! of all the bad items.
Think of a boxful of electronic components, some of which are defective. You can test any subset of components simultaneously, and if the test succeeds you know that each of those components is good. But if the test fails all you know is that at least one of the components was bad, not how many or which ones.
The obvious method is simply to test the components one at a time:
$$ S_{\text{bad}} = \{ x\in S \mid \mathcal B(\{x\}) \} $$
This requires exactly !!|S|!! calls to !!\mathcal B!!.
But if we expect there to be relatively few bad items, we may be able to do better:
- Call !!\mathcal B(S)!!. That is, test all the components at once. If none is bad, we are done.
- Otherwise, partition !!S!! into (roughly-equal) halves !!S_1!! and !!S_2!!, and recurse.
In the worst case this takes (nearly) twice as many calls as just calling !!\mathcal B!! on the singletons. But if !!k!! items are bad it requires only !!O(k\log |S|)!! calls to !!\mathcal B!!, a big win if !!k!! is small compared with !!|S|!!.
My question is: does this technique have a name? If I wanted to tell someone to use it, what would I say?
It's tempting to say "binary search" but it's not very much like binary search. Binary search finds a target value in a sorted array. If !!S!! were an array sorted by badness we could use something like binary search to locate the first bad item, which would solve this problem. But !!S!! is not a sorted array, and we are not really looking for a target value.
Is the history of this algorithm lost in time, or do we know who first invented it, or at least wrote it down? I think it sometimes pops up in connection with coin-weighing puzzles.
[ Addendum 20221023: this is the pure binary-splitting variation of adaptive group testing. I wrote a followup. ]
[Other articles in category /prog] permanent link
Tue, 18 Oct 2022In Perl I would often write a generic tree search function:
# Perl
sub search {
my ($is_good, $children_of, $root) = @_;
my @queue = ($root);
return sub {
while (1) {
return unless @queue;
my $node = shift @queue;
push @queue, $children_of->($node);
return $node if $is_good->($node);
}
}
}
For example, see Higher-Order Perl, section 5.3.
To use this, we provide two callback functions. $is_good checks
whether the current item has the properties we were searching for.
$children_of takes an item and returns its children in the tree.
The search function returns an iterator object, which, each time it is
called, returns a single item satisfying the $is_good predicate, or
undef if none remains. For example, this searches the space of all
strings over abc for palindromic strings:
# Perl
my $it = search(sub { $_[0] eq reverse $_[0] },
sub { return map "$_[0]$_" => ("a", "b", "c") },
"");
while (my $pal = $it->()) {
print $pal, "\n";
}
Many variations of this are possible. For example, replacing push
with unshift changes the search from breadth-first to depth-first.
Higher-Order Perl shows how to modify it to do heuristically-guided search.
I wanted to do this in Haskell, and my first try didn’t work at all:
-- Haskell
search1 :: (n -> Bool) -> (n -> [n]) -> n -> [n]
search1 isGood childrenOf root =
s [root]
where
s nodes = do
n <- nodes
filter isGood (s $ childrenOf n)
There are two problems with this. First, the filter is in the wrong
place. It says that the search should proceed downward only from the
good nodes, and stop when it reaches a not-good node.
To see what's wrong with this, consider a search for palindromes. Th
string ab isn't a palindrome, so the search would be cut off
at ab, and never proceed downward to find aba or abccbccba.
It should be up to childrenOf to decide how to
continue the search. If the search should be pruned at a particular
node, childrenOf should return an empty list of children. The
$isGood callback has no role here.
But the larger problem is that in most cases this function will compute
forever without producing any output at all, because the call to s
recurses before it returns even one list element.
Here’s the palindrome example in Haskell:
palindromes = search isPalindrome extend ""
where
isPalindrome s = (s == reverse s)
extend s = map (s ++) ["a", "b", "c"]
This yields a big fat !!\huge \bot!!: it does nothing, until memory is exhausted, and then it crashes.
My next attempt looked something like this:
search2 :: (n -> Bool) -> (n -> [n]) -> n -> [n]
search2 isGood childrenOf root = filter isGood $ s [root]
where
s nodes = do
n <- nodes
n : (s $ childrenOf n)
The filter has moved outward, into a single final pass over the
generated tree. And s now returns a list that at least has the node
n on the front, before it recurses. If one doesn’t look at the nodes
after n, the program doesn’t make the recursive call.
The palindromes program still isn’t right though. take 20
palindromes produces:
["","a","aa","aaa","aaaa","aaaaa","aaaaaa","aaaaaaa","aaaaaaaa",
"aaaaaaaaa", "aaaaaaaaaa","aaaaaaaaaaa","aaaaaaaaaaaa",
"aaaaaaaaaaaaa","aaaaaaaaaaaaaa", "aaaaaaaaaaaaaaa",
"aaaaaaaaaaaaaaaa","aaaaaaaaaaaaaaaaa", "aaaaaaaaaaaaaaaaaa",
"aaaaaaaaaaaaaaaaaaa"]
It’s doing a depth-first search, charging down the leftmost branch to
infinity. That’s because the list returned from s (a:b:rest) starts
with a, then has the descendants of a, before continuing with b
and b's descendants. So we get all the palindromes beginning with
“a” before any of the ones beginning with "b", and similarly all
the ones beginning with "aa" before any of the ones beginning with
"ab", and so on.
I needed to convert the search to breadth-first, which is memory-expensive but at least visits all the nodes, even when the tree is infinite:
search3 :: (n -> Bool) -> (n -> [n]) -> n -> [n]
search3 isGood childrenOf root = filter isGood $ s [root]
where
s nodes = nodes ++ (s $ concat (map childrenOf nodes))
This worked. I got a little lucky here, in that I had already had the
idea to make s :: [n] -> [n] rather than the more obvious s :: n ->
[n]. I had done that because I wanted to do the n <- nodes thing,
which is no longer present in this version. But it’s just what we need, because we
want s to return a list that has all the nodes at the current
level (nodes) before it recurses to compute the nodes farther down.
Now take 20 palindromes produces the answer I wanted:
["","a","b","c","aa","bb","cc","aaa","aba","aca","bab","bbb","bcb",
"cac", "cbc","ccc","aaaa","abba","acca","baab"]
While I was writing this version I vaguely wondered if there was something that combines concat and map, but I didn’t follow up on it until just now. It turns out there is and it’s called concatMap. 😛
search3' :: (n -> Bool) -> (n -> [n]) -> n -> [n]
search3' isGood childrenOf root = filter isGood $ s [root]
where
s nodes = nodes ++ (s $ concatMap childrenOf nodes)
So this worked, and I was going to move on. But then a brainwave hit me: Haskell is a lazy language. I don’t have to generate and filter the tree at the same time. I can generate the entire (infinite) tree and filter it later:
-- breadth-first tree search
bfsTree :: (n -> [n]) -> [n] -> [n]
bfsTree childrenOf nodes =
nodes ++ bfsTree childrenOf (concatMap childrenOf nodes)
search4 isGood childrenOf root =
filter isGood $ bfsTree childrenOf [root]
This is much better because it breaks the generation and filtering into independent components, and also makes clear that searching is nothing more than filtering the list of nodes. The interesting part of this program is the breadth-first tree traversal, and the tree traversal part now has only two arguments instead of three; the filter operation afterwards is trivial. Tree search in Haskell is mostly tree, and hardly any search!
With this refactoring we might well decide to get rid of search entirely:
palindromes4 = filter isPalindrome allStrings
where
isPalindrome s = (s == reverse s)
allStrings = bfsTree (\s -> map (s ++) ["a", "b", "c"]) [""]
And then I remembered something I hadn’t thought about in a long, long time:
[Lazy evaluation] makes it practical to modularize a program as a generator that constructs a large number of possible answers, and a selector that chooses the appropriate one.
That's exactly what I was doing and what I should have been doing all along. And it ends:
Lazy evaluation is perhaps the most powerful tool for modularization … the most powerful glue functional programmers possess.
(”Why Functional Programming Matters”, John Hughes, 1990.)
I felt a little bit silly, because I wrote a book about lazy functional programming and yet somehow, it’s not the glue I reach for first when I need glue.
[ Addendum 20221023: somewhere along the way I dropped the idea of
using the list monad for the list construction, instead using explicit
map and concat. But it could be put back. For example:
s nodes = (nodes ++) . s $ do
n <- nodes
childrenOf n
I don't think this is an improvement on just using concatMap. ]
[Other articles in category /prog/haskell] permanent link
Wed, 06 Jul 2022
Things I wish everyone knew about Git (Part II)
This is a writeup of a talk I gave in December for my previous employer. It's long so I'm publishing it in several parts:
- Part I:
- Part II (you are here):
- More coming later:
- Branches are fictitious
- Committing partial changes
- Push and fetch; tracking branches
- Aliases and custom commands
The most important material is in Part I.
It is really hard to lose stuff
A Git repository is an append-only filesystem. You can add snapshots
of files and directories, but you can't modify or delete anything.
Git commands sometimes purport to modify data. For
example git commit --amend suggests that it amends a commit.
It doesn't. There is no such thing as amending a commit; commits are
immutable.
Rather, it writes a completely new commit, and then kinda turns its back on the old one. But the old commit is still in there, pristine, forever.
In a Git repository you can lose things, in the sense of forgetting
where they are. But they can almost always be found again, one way or
another, and when you find them they will be exactly the same as they
were before. If you git commit --amend and change your mind later,
it's not hard to get the old ⸢unamended⸣ commit back if you want it
for some reason.
If you have the SHA for a file, it will always be the exact same version of the file with the exact same contents.
If you have the SHA for a directory (a “tree” in Git jargon) it will always contain the exact same versions of the exact same files with the exact same names.
If you have the SHA for a commit, it will always contain the exact same metainformation (description, when made, by whom, etc.) and the exact same snapshot of the entire file tree.
Objects can have other names and descriptions that come and go, but the SHA is forever.
(There's a small qualification to this: if the SHA is the only way to refer to a certain object, if it has no other names, and if you haven't used it for a few months, Git might discard it from the repository entirely.)
But what if you do lose something?
There are many good answers to this question but I think the one to
know first is git-reflog, because it covers the great majority of
cases.
The git-reflog command means:
“List the SHAs of commits I have visited recently”
When I run git reflog the top of the output says what commits I
had checked out at recently, with the top line being the commit I have checked
out right now:
523e9fa1 HEAD@{0}: checkout: moving from dev to pasha
5c31648d HEAD@{1}: pull: Fast-forward
07053923 HEAD@{2}: checkout: moving from pr2323 to dev
...
The last thing I did was check out the branch named pasha; its tip
commit is at 523e9f1a.
Before
that, I did git pull and Git updated my local dev branch from the
remote one, updating it to 5c31648d.
Before that, I had switched to dev from a different branch,
pr2323. At that time, before the pull, dev referred to commit
07053923.
Farther down in the output are some commits I visited last August:
...
58ec94f6 HEAD@{928}: pull --rebase origin dev: checkout 58ec94f6d6cb375e09e29a7a6f904e3b3c552772
e0cfbaee HEAD@{929}: commit: WIP: model classes for condensedPlate and condensedRNAPlate
f8d17671 HEAD@{930}: commit: Unskip tests that depend on standard seed data
31137c90 HEAD@{931}: commit (amend): migrate pedigree tests into test/pedigree
a4a2431a HEAD@{932}: commit: migrate pedigree tests into test/pedigree
1fe585cb HEAD@{933}: checkout: moving from LAB-808-dao-transaction-test-mode to LAB-815-pedigree-extensions
...

Suppose I'm caught in some horrible Git nightmare. Maybe I deleted the entire test suite or accidentally put my Small Wonder fanfic into a commit message or overwrote the report templates with 150 gigabytes of goat porn. I can go back to how things were before. I look in the reflog for the SHA of the commit just before I made my big blunder, and then:
git reset --hard 881f53fa
Phew, it was just a bad dream.
(Of course, if my colleagues actually saw the goat porn, it can't fix that.)
I would like to nominate Wile E. Coyote to be the mascot of Git. Because Wile E. is always getting himself into situations like this one:

But then, in the next scene, he is magically unharmed. That's Git.
Finding old stuff with git-reflog
git reflogby itself lists the places thatHEADhas beengit reflog some-branchlists the places thatsome-branchhas been- That
HEAD@{1}thing in thereflogoutput is another way to name that commit if you don't want to use the SHA. - You can abbreviate it to just
@{1}. The following locutions can be used with any git command that wants you to identify a commit:
@{17}(HEADas it was 17 actions ago)@{18:43}(HEADas it was at 18:43 today)@{yesterday}(HEADas it was 24 hours ago)dev@{'3 days ago'}(devas it was 3 days ago)some-branch@{'Aug 22'}(some-branchas it was last August 22)
(Use with
git-checkout,git-reset,git-show,git-diff, etc.)Also useful:
git show dev@{'Aug 22'}:path/to/some/file.txt“Print out that file, as it was on
dev, asdevwas on August 22”
It's all still in there.
What if you can't find it?
Don't panic! Someone with more experience can probably find it for you. If you have a local Git expert, ask them for help.
And if they are busy and can't help you immediately, the thing you're looking for won't disappear while you wait for them. The repository is append-only. Every version of everything is saved. If they could have found it today, they will still be able to find it tomorrow.
(Git will eventually throw away lost and unused snapshots, but typically not anything you have used in the last 90 days.)
What if you regret something you did?
Don't panic! It can probably put it back the way it was.
Git leaves a trail
When you make a commit, Git prints something like this:
your-topic-branch 4e86fa23 Rework foozle subsystem
If you need to find that commit again, the SHA 4e86fa23 is in your
terminal scrollback.
When you fetch a remote branch, Git prints:
6e8fab43..bea7535b dev -> origin/dev
What commit was origin/dev before the fetch? At 6e8fab43.
What commit is it now? bea7535b.
What if you want to look at how it was before? No problem, 6e8fab43
is still there. It's not called origin/dev any more, but the SHA is
forever. You can still check it out and look at it:
git checkout -b how-it-was-before 6e8fab43
What if you want to compare how it was with how it is now?
git log 6e8fab43..bea7535b
git show 6e8fab43..bea7535b
git diff 6e8fab43..bea7535b
Git tries to leave a trail of breadcrumbs in your terminal. It's constantly printing out SHAs that you might want again.
A few things can be lost forever!
After all that talk about how Git will not lose things, I should point
out the exceptions. The big exception is that if you have created
files or made changes in the working tree, Git is unaware of them
until you have added them with git-add. Until then, those changes
are in the working tree but not in the repository, and if you discard
them Git cannot help you get them back.
Good advice is Commit early and often. If you don't commit, at
least add changes with git-add. Files added but not committed are
saved in the repository,
although they can be hard to find
because they haven't been packaged into a commit with a single SHA id.
Some people automate this: they have a process that runs every few minutes and commits the current working tree to a special branch that they look at only in case of disaster.
The dangerous commands are
git-resetandgit-checkout
which modify the working tree, and so might wipe out changes that aren't in the repository. Git will try to warn you before doing something destructive to your working tree changes.
git-rev-parse
We saw a little while ago that Git's language for talking about commits and files is quite sophisticated:
my-topic-branch@{'Aug 22'}:path/to/some/file.txt
Where is this language documented? Maybe not where you would expect: it's in the
manual for git-rev-parse.
The git rev-parse command is less well-known than it should be. It takes a
description of some object and turns it into a SHA.
Why is that useful? Maybe not, but
The
git-rev-parseman page explains the syntax of the descriptions Git understands.
A good habit is to skim over the manual every few months. You'll pick up something new and useful every time.
My favorite is that if you use the syntax :/foozle you get the most
recent commit on the current branch whose message mentions
foozle. For example:
git show :/foozle
or
git log :/introduce..:/remove
Coming next week (probably), a few miscellaneous matters about using Git more effectively.
[Other articles in category /prog/git] permanent link
Wed, 29 Jun 2022
Things I wish everyone knew about Git (Part I)
This is a writeup of a talk I gave in December for my previous employer. It's long so I'm publishing it in several parts:
- Part I (you are here):
- Part II: (coming later)
- More coming later still:
- Branches are fictitious
- Committing partial changes
- Push and fetch; tracking branches
- Aliases and custom commands
How to approach Git; general strategy
Git has an elegant and powerful underlying model based on a few simple concepts:
- Commits are immutable snapshots of the repository
- Branches are named sequences of commits
- Every object has a unique ID, derived from its content
Built atop this elegant system is a flaming trash pile.

The command set wasn't always well thought out, and then over the years it grew by accretion, with new stuff piled on top of old stuff that couldn't be changed because Backward Compatibility. The commands are non-orthogonal and when two commands perform the same task they often have inconsistent options or are described with different terminology. Even when the individual commands don't conflict with one another, they are often badly-designed and confusing. The documentation is often very poorly written.
What this means
With a lot of software, you can opt to use it at a surface level without understanding it at a deeper level:
“I don't need to
know how it works.
I just want to know which commands to run.”
This is often an effective strategy, but
with Git, this does not work.
You can't “just know which commands to run” because the commands do not make sense!
To work effectively with Git, you must have a model of what the repository is like, so that you can formulate questions like “is the repo on this state or that state?” and “the repo is in this state, how do I get it into that state?”. At that point you look around for a command that answers your question, and there are probably several ways to do what you want.
But if you try to understand the commands without the model, you will suffer, because the commands do not make sense.
Just a few examples:
git-resetdoes up to three different things, depending on flagsgit-checkoutis worseThe opposite of
git-pushis notgit-pull, it'sgit-fetchetc.
If you try to understand the commands without a clear idea of the model, you'll be perpetually confused about what is happening and why, and you won't know what questions to ask to find out what is going on.
READ THIS
When I first used Git it drove me almost to tears of rage and frustration. But I did get it under control. I don't love Git, but I use it every day, by choice, and I use it effectively.
The magic key that rescued me was
John Wiegley's
Git From the
Bottom Up
Git From the Bottom Up explains the model. I read it. After that I wept no more. I understood what was going on. I knew how to try things out and how to interpret what I saw. Even when I got a surprise, I had a model to fit it into.
That's the best advice I have. Read Wiegley's explanation. Set aside time to go over it carefully and try out his examples. It fixed me.
If I were going to tell every programmer just one thing about Git, that would be it.
The rest of this series is all downhill from here.
But if I were going to tell everyone just one more thing, it would be:
It is very hard to
permanently lose work.
If something seems to have gone wrong, don't panic.
Remain calm and ask an expert.
Many more details about that are in the followup article.
[Other articles in category /prog/git] permanent link
Tue, 26 Apr 2022[ I hope this article won't be too controversial. My sense is that SML is moribund at this point and serious ML projects that still exist are carried on in OCaml. But I do observe that there was a new SML/NJ version released only six months ago, so perhaps I am mistaken. ]
It was apparent that SML had some major problems. When I encountered Haskell around 1998 it seemed that Haskell at least had a story for how these problems might be fixed.
A reader wrote to ask:
I was curious what the major problems you saw with SML were.
I actually have notes about this that I made while I was writing the first article, and was luckily able to restrain myself from writing up at the time, because it would have been a huge digression. But I think the criticism is technically interesting and may provide some interesting historical context about what things looked like in 1995.
I had three main items in mind. Every language has problems, but these three seemed to me be the deep ones where a drastically different direction was needed.
Notation for types and expressions in this article will be a mishmash of SML, Haskell, and pseudocode. I can only hope that the examples will all be simple enough that the meaning is clear.
Mutation
Reference type soundness
It seems easy to write down the rules for type inference in the presence of references. This turns out not to be the case.
The naïve idea was: for each type α there is a corresponding
type ref α, the type of memory cells containing a value of type
α. You can create a cell with an initialized value by using the
ref function: If v has type α, then ref v has type ref α
and its value is a cell that has been initialized to contain the value
v. (SML actually calls the type α ref, but the meaning is the same.)
The reverse of this is the operator ! which takes a reference of
type ref α and returns the referenced value of type α.
And finally,
if m is a reference, then you can overwrite the value stored in its
its memory cell by saying with m := v. For example:
m = ref 4 -- m is a cell containing 4
m := 1 + !m -- overwrite contents with 1+4
print (2 * !m) -- prints 10
The type rules seem very straightforward:
ref :: α → ref α
(!) :: ref α → α
(:=) :: ref α × α → unit
(Translated into Haskellese, that last one would look more like (ref α, α) → ()
or perhaps ref α → α → () because Haskell loves currying.)
This all seems clear, but it is not sound. The prototypical example is:
m = ref (fn x ⇒ x)
Here m is a reference to the identity function. The identity
function has type α → α, so variable m has type ref(α → α).
m := not
Now we assign the Boolean negation operator to m. not has type
bool → bool, so the types can be unified: m has type ref(α →
α). The type elaborator sees := here and says okay, the first
argument has type
ref(α → α), the second has type bool → bool, I can unify that, I
get α = bool, everything is fine.
Then we do
print ((!m) 23)
and again the type checker is happy. It says:
mhas typeref(α → α)!mhas typeα → α23has typeint
and that unifies, with α = int, so the result will have type
int. Then the runtime blithely invokes the boolean not
function on the argument 23. OOOOOPS.
SML's reference type variables
A little before the time I got into SML, this problem had been discovered and a patch
put in place to prevent it. Basically, some type variables were
ordinary variables, other types (distinguished by having names that began
with an underscore) were special “reference type variables”. The ref
function didn't have type α → ref α, it had type _α → ref _α.
The type elaboration algorithm was stricter when specializing
reference types than when specializing ordinary types. It was
complicated, clearly a hack, and I no longer remember the details.
At the time I got out of SML, this hack been replaced with a more complicated hack, in which the variables still had annotations to say how they related to references, but instead of a flag the annotation was now a number. I never understood it. For details, see this section of the SML '97 documentation, which begins “The interaction between polymorphism and side-effects has always been a troublesome problem for ML.”
After this article was published, Akiva Leffert reminded me that SML later settled on a third fix to this problem, the “value restriction”, which you can read about in the document linked previously. (I thought I remembered there being three different systems, but then decided that I was being silly, and I must have been remembering wrong. I wasn't.)
Haskell's primary solution to this is to burn it all to the ground. Mutation doesn't cause any type problems because there isn't any.
If you want something like ref which will break purity, you
encapsulate it inside the State monad or something like it, or else
you throw up your hands and do it in the IO monad, depending on what
you're trying to accomplish.
Scala has a very different solution to this problem, called covariant and contravariant traits.
Impure features more generally
More generally I found it hard to program in SML because I didn't understand the evaluation model. Consider a very simple example:
map print [1..1000]
Does it print the values in forward or reverse order? One could implement it either way. Or perhaps it prints them in random order, or concurrently. Issues of normal-order versus applicative-order evaluation become important. SML has exceptions, and I often found myself surprised by the timing of exceptions. It has mutation, and I often found that mutations didn't occur in the order I expected.
Haskell's solution to this again is monads. In general it promises
nothing at all about execution order, and if you want to force
something to happen in a particular sequence, you use the monadic bind
operator >>=. Peyton-Jones’ paper
“Tackling the Awkward Squad”
discusses the monadic approach to impure features.
Combining computations that require different effects (say, state
and IO and exceptions) is very badly handled by Haskell. The
standard answer is to use a stacked monadic type like IO ExceptionT a
(State b) with monad transformers. This requires explicit liftings
of computations into the appropriate monad. It's confusing and
nonorthogonal. Monad composition is non-commutative so that IO
(Error a) is subtly different from Error (IO a), and you may find
you have the one when you need the other, and you need to rewrite a
large chunks of your program when you realize that you stacked your
monads in the wrong order.
My favorite solution to this so far is algebraic effect systems. Pretnar's 2015 paper “An Introduction to Algebraic Effects and Handlers” is excellent. I see that Alexis King is working on an algebraic effect system for Haskell but I haven't tried it and don't know how well it works.
Overloading and ad-hoc polymorphism
Arithmetic types
Every language has to solve the problem of 3 + 0.5. The left
argument is an integer, the right argument is something else, let's
call it a float. This issue is baked into the hardware, which has two
representations for numbers and two sets of machine instructions for
adding them.
Dynamically-typed languages have an easy answer: at run time, discover that the left argument is an integer, convert it to a float, add the numbers as floats, and yield a float result. Languages such as C do something similar but at compile time.
Hindley-Milner type languages like ML have a deeper problem: What is the type of the addition function? Tough question.
I understand that OCaml punts on this. There are two addition
functions with different names. One, +, has type int × int → int. The other,
+., has type float × float → float. The expression 3 + 0.5 is
ill-typed because its right-hand argument is not an integer. You
should have written something like int_to_float 3 +. 0.5.
SML didn't do things this way. It was a little less inconvenient and a
little less conceptually simple. The + function claimed to
have type α × α → α, but this was actually a lie. At compile
time it would be resolved to either int × int → int
or to float × float → float. The problem expression above was still
illegal. You needed to write int_to_float 3 + 0.5, but at least
there was only one symbol for addition and you were still writing +
with no adornments. The explicit
calls to int_to_float and similar conversions still cluttered up the
code, sometimes severely
The overloading of + was a special case in the compiler.
Nothing like it was available to the programmer. If you wanted to
create your own numeric type, say a complex number, you could not overload
+ to operate on it. You would have to use |+| or some other
identifier. And you couldn't define anything like this:
def dot_product (a, b) (c, d) = a*c + b*d -- won't work
because SML wouldn't know which multiplication and addition to use;
you'd have to put in an explicit type annotation and have two versions
of dot_product:
def dot_product_int (a : int, b) (c, d) = a*c + b*d
def dot_product_float (a : float, b) (c, d) = a*c + b*d
Notice that the right-hand sides are identical. That's how you can tell that the language is doing something stupid.
That only gets you so far. If you might want to compute the dot product of an int vector and a float vector, you would need four functions:
def dot_product_ii (a : int, b) (c, d) = a*c + b*d
def dot_product_ff (a : float, b) (c, d) = a*c + b*d
def dot_product_if (a, b) (c, d) = (int_to_float a) * c + (int_to_float b)*d
def dot_product_fi (a, b) (c, d) = a * (int_to_float c) + b * (int_to_float d)
Oh, you wanted your vectors to maybe have components of different types? I guess you need to manually define 16 functions then…
Equality types
A similar problem comes up in connection with equality. You can write
3 = 4 and 3.0 = 4.0 but not 3 = 4.0; you need to say int_to_float 3
= 4.0. At least the type of = is clearer here; it really is
α × α → bool because you can compare not only numbers but also
strings, booleans, lists, and so forth. Anything, really, as
indicated by the free variable α.
Ha ha, I lied, you can't actually compare functions. (If you could, you could
solve the halting problem.) So the α in the type of = is not
completely free; it mustn't be replaced by a function type. (It is also
questionable whether it should work for real numbers, and I think SML
changed its mind about this at one point.)
Here, OCaml's +. trick was unworkable. You cannot have a different
identifier for equality comparisons at every different type. SML's
solution was a further epicycle on the type system. Some type
variables were designated “equality type variables”. The type of =
was not
α × α → bool
but
''α × ''α → bool
where ''α means that the α can be instantiated only for an
“equality type” that admits equality comparisons. Integers were an
equality type, but functions (and, in some versions, reals) were not.
Again, this
mechanism was not available to the programmer. If your type was a
structure, it would be an equality type if and only if all its members
were equality types. Otherwise you would have to write your own
synthetic equality function and name it === or something. If !!t!!
is an equality type, then so too is “list of !!t!!”, but this sort of
inheritance, beautifully handled in general by Haskell's type subclass
feature, was available in SML only as a couple of hardwired special cases.
Type classes
Haskell dealt with all these issues reasonably well with type classes,
proposed in Wadler and Blott's 1988 paper
“How to make ad-hoc polymorphism less ad hoc”.
In Haskell, the addition function now has type Num a ⇒ a → a → a
and the equality function has type Eq a ⇒ a → a → Bool. Anyone can
define their own instance of Num and define an addition function for
it. You need an explicit conversion if you want to add it to an
integer:
some_int + myNumericValue -- No
toMyNumericType some_int + myNumericValue -- Yes
but at least it can be done. And you can define a type class and overload toMyNumericType so that
one identifier serves for every type you can convert to your type. Also, a
special hack takes care of lexical constants with no explicit conversion:
23 + myNumericValue -- Yes
-- (actually uses overloaded fromInteger 23 instead)
As far as I know Haskell still doesn't have a complete solution to the
problem of how to make numeric types interoperate smoothly. Maybe
nobody does. Most dynamic languages with ad-hoc polymorphism will
treat a + b differently from b + a, and can give you spooky action
at a distance problems. If type B isn't overloaded, b + a will
invoke the overloaded addition for type A, but then if someone defines
an overloaded addition operator for B, in a different module, the
meaning of every b + a in the program changes completely because it
now calls the overloaded addition for B instead of the one for A.
In Structure and Interpretation of Computer Programs, Abelson and Sussman describe an arithmetic system in which the arithmetic types form an explicit lattice. Every type comes with a “promotion” function to promote it to a type higher up in the lattice. When values of different types are added, each value is promoted, perhaps repeatedly, until the two values are the same type, which is the lattice join of the two original types. I've never used anything like this and don't know how well it works in practice, but it seems like a plausible approach, one which works the way we usually think about numbers, and understands that it can add a float to a Gaussian integer by construing both of them as complex numbers.
[ Addendum 20220430: Phil Eaton informs me that my sense of SML's moribundity is exaggerated: “Standard ML variations are in fact quite alive and the number of variations is growing at the moment”, they said, and provided a link to their summary of the state of Standard ML in 2020, which ends with a recommendation of SML's “small but definitely, surprisingly, not dead community.” Thanks, M. Eaton! ]
[ Addendum 20221108: On the other hand, the Haskell Weekly News annual survey this year includes a question that asks “Which programming languages other than Haskell are you fluent in?” and the offered choices include C#, Ocaml, Scala, and even Perl, but not SML. ]
[Other articles in category /prog/haskell] permanent link
Mon, 01 Nov 2021!!\def\zpr#1#2{\langle{#1},{#2}\rangle}\def\zkp#1#2{\{\{{#1}\}, \{{#1},{#2}\}\}}!!In Friday's article about the cartesian product I needed to show what the Kuratowski ordered-pair construction looks like when you nest the pairs. I originally wrote out the TeX for these by hand, but later decided I ought to use TeX macros to generate the formulas. First I did
\def\pr#1#2{\langle{#1},{#2}\rangle}
so that \pr ab would turn into !!\zpr ab!! and \pr a{\pr bc} would
turn into !!\zpr a{\zpr bc}!!.
Then I defined a macro for Kuratowski pairs. The Kuratowski pair for !!\zpr ab!! is the set !!\zkp ab!!, which is kind of a mess:
\def\kp#1#2{\{\{{#1}\}, \{{#1},{#2}\}\}}
Then the nested Kuratowski pairs turn into:
$$\begin{array}{cc} \verb+\kp a{\kp bc}+ & \zkp a{\zkp bc} \\ \verb+\kp{\kp ab}c+ & \zkp{\zkp ab}c \\ \end{array} $$
When I got this far I realized that my hand-expansion of
\kp{\kp ab}c had actually been wrong! I had originally written: $$
\{\{\{a\}, \{a, b\}\}, \{\{\{a\}, \{a, b\}\}, c\}\}.\qquad\color{\maroon}{Wrong!}$$
(There's a pair of braces missing around the first of the two !!\zkp ab!!.)
I used to give classes on programming style and technique, and one of the maxims I taught was “let the computer do the work”: use the computer to automate repetitive or error-prone tasks.
I was going to say I wish I'd taken my own advice here but hey — I did take my own advice, and it worked!
[Other articles in category /prog] permanent link
Sun, 07 Mar 2021(Summary: Henry Baker's web site has disappeared after 30 years. I kept an archive.)
Henry G. Baker is a computer programmer and computer scientist, one of the founders of the Symbolics company that made Lisp Machines.
I discovered Baker's writing probably in the early 1990s and immediately put him on my “read everything this person writes” list. I found everything he wrote clear and well-reasoned. I always learned something from reading it. He wrote on many topics, and when he wrote about a topic I hadn't been interested in, I became interested in it because he made it interesting.
Sometimes I thought Baker was mistaken about something. But usually it was I who was mistaken.
Baker had a web site with an archive of his articles and papers. It disappeared last year sometime. But I have a copy that I made around 1998, Just In Case.
Baker's web site is a good example of mid-1990s web design. Here's his “Gratuitous Waste of Bandwidth” page. It features a link to a 320×240 pixel color photo of Baker, and an inlined monochrome GIF version of it.

| 
|
Browsers at the time could inline GIF files but not JPEGs, and it would have been rude to inline a color JPEG because that would have forced the user to wait while the browser downloaded the entire 39kb color image. It was a rather different time.
Some of my favorite articles of his were:
CONS Should not CONS its Arguments, or, a Lazy Alloc is a Smart Alloc
(The Internet Archive also has a more recent copy of the site.)
Addendum 20220108
I just rediscovered this note I wrote in 2006 but never published:
The bozo bit isn't really a bit; it works in the other direction too. Some people are so consistently thoughtful and insightful that I go looking for stuff they have said, and pay extra-close attention to it, particularly if I disagree with it, because that indicates a greater-than-average chance that I am mistaken about something.
Henry Baker is one of these people. I try to read everything Henry Baker writes, extra carefully, because in the past I've determined that he seems to be correct about almost everything. If M. Baker says something I think is probably wrong, that's a good sign that I should reconsider, because there's a decent chance that I'm the one that's wrong.
[Other articles in category /prog] permanent link
Sat, 06 Feb 2021Git comes with
a very complicated shell function,, called
__git_ps1,
for interpolating Git information into your shell prompt. A typical
use would be:
PS1='>>> $(__git_ps1) :) '
PS1 is the variable that contains the shell's main prompt. Before
printing the prompt, the shell does variable and command interpolation
on this string. This means that if PS1 contains something like $(command
args...), the shell replaces that string with the output from running
command args…. Here, it runs __git_ps1 and inserts the output into the
prompt. In the simplest case, __git_ps1 emits the name of the
currently-checked-out branch, so that the shell will actually print
this prompt:
>>> the-branch :)
But __git_ps1 has many other features besides. If you are in the middle
of a rebase or cherry-pick operation, it will emit something
like
the-branch|REBASE-i 1/5
or
the-branch|CHERRY-PICKING
instead. If HEAD is detached, it can still display the head
location in several formats. There are options to have the emitted string
indicate when the working tree is dirty and other things. My own
PS1 looks like this:
PS1='[$(_path) $(__git_ps1 "(%s)" )]> '
The _path command is something I
wrote to emit the path of the current working directory, abbreviated
in a contextually dependent way. It makes my prompt look like this:
[lib/app (the-branch)]>
Here lib/app is the path relative to the root of the repository.
The %s thing is an additional formatting instruction to __git_ps1.
After it computes the description string, __git_ps1 inserts it into
"(%s)" in place of the %s, and emits the result of that
replacement. If you don't give __git_ps1 an argument, it uses "(%s) "
as a default, which has an extra space compared with what I have.
Lately I have been experimenting with appending .mjd.yyyymmdd to my
public branch names, to help me remember to delete my old dead
branches from the shared repository. This makes the branch names
annoyingly long:
gh1067-sort-dates-chronologically.mjd.20210103
gh1067-sort-dates-no-test.mjd.20210112
gh1088-cache-analysis-list.mjd.20210105
and these annoyingly long names appear in the output of __git_ps1 that is
inserted into my shell prompts.
One way to deal with this is to have the local branch names be
abbreviated and configure their upstream names to the long versions.
And that does work: I now have a little program called new-branch
that creates a new branch with the local short name, pushes it to the
long remote name, and sets the upstream. But I also wanted a generic
mechanism for abbreviating or transforming the branch name in the
prompt.
The supplied __git_ps1 function didn't seem to have an option
for that, or a callback for modifying the branch name before inserting
it into the prompt. I could have copied the function, modified the
parts I wanted, and used the modified version in place of the supplied
version, but it is 243 lines long, so I preferred not to do that.
But __git_ps1 does have one hook. Under the right circumstances,
it will attempt to colorize the prompt by inserting terminal
escape codes. To do this it invokes __git_ps_colorize_gitstring to
insert the escape codes into the various prompt components before it
assembles them. I can work with that!
The goal is now:
- Figure out how to tell
__git_ps1to call__git_ps_colorize_gitstring - Figure out how
__git_ps1and__git_ps_colorize_gitstringcommunicate prompt components - Write my own
__git_ps_colorize_gitstringto do something else
How to tell __git_ps1 to call __git_ps_colorize_gitstring
You have to do two things to get __git_ps1 to call the hook:
Set
GIT_PS1_SHOWCOLORHINTSto some nonempty string. I set it totrue, which is a little deceptive, becausefalsewould have worked as well.Invoke
__git_ps1with two or more arguments.
Unfortunately, invoking the __git_ps1 with two or more arguments changes
its behavior in another way. It still computes a string, but it no
longer prints the string. Instead, it computes the string and
assigns it to PS1. This means that
PS1="$(__git_ps arg arg….)"
won't work properly: the next time the shell wants to prompt, it will
evaluate PS1, which will call __git_ps arg arg…, which will set
PS1 to some string like (the-branch). Then the next time the
shell wants to print the prompt, it will evaluate PS1, which will be
just some dead string like (the-branch), with nothing in it to call
__git_ps1 again.
So we need to use a different shell feature. Instead of setting PS1
directly, we set PROMPT_COMMAND. This command is run before the
prompt is printed. Although this doesn't have anything to do directly
with the prompt, the command can change the prompt. If we set
PROMPT_COMMAND to invoke __git_ps1, and if __git_ps1 modifies PS1, the
prompt will change.
Formerly I had had this:
PS1='[$(_path) $(__git_ps1 "(%s)")]> '
but instead I needed to use:
GIT_PS1_SHOWCOLORHINTS=true
PROMPT_COMMAND='__git_ps1 "[$(_path) " " ] "' "(%s)"
Here __git_ps1 is getting three arguments:
"[$(_path) "" ] ""(%s)"
__git_ps1 computes its description of the Git state and inserts it into
the third argument in place of the %s. Then it takes the result of
this replacement, appends the first argument on the front and the
second on the back, and sets the prompt to the result. The shell will
still invoke _path in the course of evaluating the first string,
before passing it to __git_ps1 as an argument. Whew.
How __git_ps1 communicates prompt components to __git_ps_colorize_gitstring
The end result of all this rigamarole is that __git_ps1 is now being
called before every prompt, as before, but now it will also invoke
__git_ps_colorize_gitstring along the way. What does that actually get us?
The internals of __git_ps_colorize_gitstring aren't documented because I don't think this
is a planned use case, and __git_ps_colorize_gitstring isn't an advertised part of the
interface. __git_ps1 does something to construct the prompt, possibly
colorizing it in the process, but how it does the colorizing is
forbidden knowledge. From looking at the code I can see that the
colorizing is done by __git_ps_colorize_gitstring, and I needed to know what was going in
inside.
The (current) interface is that __git_ps1 puts the various components of
the prompts into a family of single-letter variables, which __git_ps_colorize_gitstring
modifies. Here's what these variables do, as best as I have been able
to ascertain:
bcontains a description of the current HEAD, either the current branch name or some other description
cindicates if you are in a bare repository
iindicates if changes have been recorded to the index
pcontains information about whether the current head is behind or ahead of its upstream branch
rdescribes the rebase / merge / cherry-pick state
sindicates if there is something in the stash
uindicates whether there are untracked files
windicates whether the working tree is dirty
zis the separator between the branch name and the other indicators
Oddly, the one thing I wanted to change is the only one that __git_ps_colorize_gitstring
doesn't modify: the b variable that contains the name or
description of the current branch. Fortunately, it does exist and
there's nothing stopping me from writing a replacement __git_ps_colorize_gitstring that
does modify it.
Write a replacement for __git_ps_colorize_gitstring to do something else
So in the end all I needed was:
GIT_PS1_SHOWCOLORHINTS=true
PROMPT_COMMAND='__git_ps1 "[$(_path) " " ] "' "(%s)"
__git_ps1_colorize_gitstring () {
b=${b%%.[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]}
b=${b%%.mjd}
}
The ${b%%PAT} thing produces the value of the variable b, except
that if the value ends with something matching the pattern PAT, that
part is removed. So the first assignment trims a trailing
.20210206 from the branch name, if there is one, and the second
trims off a trailing .mjd. If I wanted to trim off the leading gh
also I could use b=${b##gh}.
There's probably some way to use this in addition to the standard
__git_ps_colorize_gitstring, rather than in place of it. But I don't know how.
In conclusion
This was way harder to figure out than it should have been.
[Other articles in category /prog] permanent link
Sun, 31 Jan 2021
Early warning signs of shitty software
Here's a screenshot of menu on the documentation page of a package I'm using. You can see right away that the software is going to be crappy:
Major warning sign: The items are not in alphabetical order. (They are in numeric order, but the numbers are not displayed.)
- Was alphabetization too hard for these people?
Or did they simply not think for one second about who would want to use this menu and how?
If you are looking up a particular function to find out what it does, you have to do linear search on the list to find the one you want.
Yes, you could do full-text search on the whole page, but then what is the menu for?
Minor warning sign: But at least they included an API function to
generate the frequently-used HTTP 418 I'm a teapot status.
<sarcasm>Clearly a lot of thought here about what really matters.</sarcasm>
[Other articles in category /prog] permanent link
Wed, 23 Sep 2020
The mystery of the malformed command-line flags
Today a user came to tell me that their command
greenlight submit branch-name --require-review-by skordokott
failed, saying:
**
** unexpected extra argument 'branch-name' to 'submit' command
**
This is surprising. The command looks correct. The branch name is
required. The --require-review-by option can be supplied any
number of times (including none) and each must have a value provided.
Here it is given once and the provided value appears to be
skordocott.
The greenlight command is a crappy shell script that pre-validates
the arguments before sending them over the network to the real server.
I guessed that the crappy shell script parser wanted the branch name
last, even though the server itself would have been happy to take the
arguments in either order. I suggested that the user try:
greenlight submit --require-review-by skordokott branch-name
But it still didn't work:
**
** unexpected extra argument '--require-review-by' to 'submit' command
**
I dug in to the script and discovered the problem, which was not actually a programming error. The crappy shell script was behaving correctly!
I had written up release notes for the --require-review-by feature.
The user had clipboard-copied the option string out of
the release notes and pasted it into the shell. So why didn't it work?
In an earlier draft of the release notes, when they were displayed as an HTML page, there would be bad line breaks:
blah blah blah be sure to use the
-
-require-review-byoption…
or:
blah blah blah the new
--
require-review-byfeature is…
No problem, I can fix it! I just changed the pair of hyphens (- U+002D)
at the beginning of --require-review-by to Unicode nonbreaking
hyphens (‑ U+2011). Bad line breaks begone!
But then this hapless user clipboard-copied the option string out of
the release notes, including its U+2011 characters. The parser in the
script was (correctly) looking for U+002D characters, and didn't
recognize --require-review-by as an option flag.
One lesson learned: people will copy-paste stuff out of documentation, and I should be prepared for that.
There are several places to address this. I made the error message more transparent; formerly it would complain only about the first argument, which was confusing because it was the one argument that wasn't superfluous. Now it will say something like
**
** extra branch name '--require-review-by' in 'submit' command
**
**
** extra branch name 'skordokott' in 'submit' command
**
which is more descriptive of what it actually doesn't like.
I could change the nonbreaking hyphens in the release notes back to regular hyphens and just accept the bad line breaks. But I don't want to. Typography is important.
One idea I'm toying with is to have the shell script silently replace all nonbreaking hyphens with regular ones before any further processing. It's a hack, but it seems like it might be a harmless one.
So many weird things can go wrong. This computer stuff is really complicated. I don't know how anyone get anything done.
[ Addendum: A reader suggests that I could have fixed the line breaks with CSS. But the release notes were being presented as a Slack “Post”, which is essentially a WYSIWYG editor for creating shared documents. It presents the document in a canned HTML style, and as far as I know there's no way to change the CSS it uses. Similarly, there's no way to insert raw HTML elements, so no way to change the style per-element. ]
[Other articles in category /prog/bug] permanent link
Sun, 31 May 2020
Reordering git commits (not patches) with interactive rebase
This is the third article in a series. ([1] [2]) You may want to reread the earlier ones, which were in 2015. I'll try to summarize.
The original issue considered the implementation of some program feature X. In commit A, the feature had not yet been implemented. In the next commit C it had been implemented, and was enabled. Then there was a third commit, B, that left feature X implemented but disabled it:
no X X on X off
A ------ C ------ B
but what I wanted was to have the commits in this order:
no X X off X on
A ------ B ------ C
so that when X first appeared in the history, it was disabled, and then a following commit enabled it.
The first article in the series began:
I know, you want to say “Why didn't you just use
git-rebase?” Becausegit-rebasewouldn't work here, that's why.
Using interactive rebase here “to reorder B and C” will not work
because git-rebase reorders patches, not commits. It will attempt
to apply the B→C diff as a patch to A, and will fail, because
the patch is attempting to disable a feature that isn't implemented in
commit A.
My original articles described a way around this, using the plumbing
command git-commit-tree to construct the desired commits with the
desired parents. I also proposed that one could write a
git-reorder-commits command to automate the process, but my proposal
gave it a clumsy and bizarre argument convention.
Recently, Curtis Dunham wrote to me with a much better idea that uses the
interactive rebase UI to accomplish the same thing much more cleanly.
If we had B checked out and we tried git rebase -i A, we would get a
little menu like this:
pick ccccccc implement feature X
pick bbbbbbb disable feature X
As I said before, just switching the order of these two pick
commands doesn't work, because the bbbbbbb diff can't be applied on
the base commit A.
M. Dunham's suggestion is to use git-rebase -i as usual, but instead
of simply reversing the order of the two pick commands, which
doesn't work, also change them to exec git snap:
exec git snap bbbbbbb disable feature X
exec git snap ccccccc implement feature X
But what's git snap? Whereas pick means
run
git showto construct a patch from the next commit,
then apply that patch to the current tree
git snap means:
get the complete tree from the next commit,
and commit it unchanged
That is, “take a snapshot of that commit”.
It's simple to implement:
# read the tree from the some commit and store it in the index
git read-tree $SHA^{tree}
# then commit the index, re-using the old commit message
git commit -C $SHA
There needs to be a bit of cleanup to get the working tree back into
sync with the new index.
M. Dunham's actual implementation
does this with git-reset (which I'm not sure is quite sufficient),
and has some argument checking, but that's the main idea.
I hadn't know about the exec command in a git-rebase script, but
it seems like it could do all sorts of useful things. The
git-rebase man page suggests
inserting exec make at points in your script, to check that your
reordering hasn't broken the build along the way.
Thank you again, M. Dunham!
[Other articles in category /prog] permanent link
Tue, 24 Mar 2020
git log --author=... confused me
Today I was looking for recent commits by co worker Fred Flooney,
address fflooney@example.com, so I did
git log --author=ffloo
but nothing came up. I couldn't remember if --author would do a
substring search, so I tried
git log --author=fflooney
git log --author=fflooney@example.com
and still nothing came up. “Okay,” I said, “probably I have Fred's address wrong.” Then I did
git log --format=%ae | grep ffloo
The --format=%ae means to just print out commit author email
addresses, instead of the usual information. This command did
produce many commits with the author address
fflooney@example.com.
I changed this to
git log --format='%H %ae' | grep ffloo
which also prints out the full hash of the matching commits. The first one was 542ab72c92c2692d223bfca4470cf2c0f2339441.
Then I had a perplexity. When I did
git log -1 --format='%H %ae' 542ab72c92c2692d223bfca4470cf2c0f2339441
it told me the author email address was
fflooney@example.com. But when I did
git show 542ab72c92c2692d223bfca4470cf2c0f2339441
the address displayed was fredf@example.com.
The answer is, the repository might have a file in its root named
.mailmap that says “If you see this name and address, pretend you
saw this other name and address instead.” Some of the commits really
had been created with the address I was looking for, fflooney. But
the .mailmap said that the canonical version of that address was
fredf@. Nearly all Git operations use the canonical address. The
git-log --author option searches the canonical address, and
git-show and git-log, by default, display the canonical address.
But my --format=%ae overrides the default behavior; %ae explicitly
requests the actual address. To display the canonical address, I
should have used --format=%aE instead.
Also, I learned that --author= does not only a substring search but
a regex search. I asked it for --author=d* and was puzzled when
it produced commits written by people with no d. This is a beginner
mistake: d* matches zero or more instances of d, and every name
contains zero or more instances of d. (I had thought that the *
would be like a shell glob.)
Also, I learned that --author=d+ matches only authors that contain
the literal characters d+. If you want the + to mean “one or
more” you need --author=d\+.
Thanks to Cees Hek, Gerald Burns, and Val Kalesnik for helping me get to the bottom of this.
The .mailmap thing is documented in
git-check-mailmap.
[ Addendum: I could also have used git-log --no-use-mailmap ...,
had I known about this beforehand. ]
[Other articles in category /prog] permanent link
Mon, 11 Nov 2019All programming languages are equally crappy, but some are more equally crappy than others.
[Other articles in category /prog] permanent link
Tue, 01 Oct 2019
How do I keep type constructors from overrunning my Haskell program?
Here's a little function I wrote over the weekend as part of a suite for investigating Yahtzee:
type DiceChoice = [ Bool ]
type DiceVals = [ Integer ]
type DiceState = (DiceVals, Integer)
allRolls :: DiceChoice -> DiceState -> [ DiceState ]
allRolls [] ([], n) = [ ([], n-1) ]
allRolls [] _ = undefined
allRolls (chosen:choices) (v:vs, n) =
allRolls choices (vs,n-1) >>=
\(roll,_) -> [ (d:roll, n-1) | d <- rollList ]
where rollList = if chosen then [v] else [ 1..6 ]
I don't claim this code is any good; I was just hacking around exploring the problem space. But it does do what I wanted.
The allRolls function takes a current game state, something like
( [ 6, 4, 4, 3, 1 ], 2 )
which means that we have two rolls remaining in the round, and the most recent roll of the five dice showed 6, 4, 4, 3, and 1, respectively. It also takes a choice of which dice to keep: The list
[ False, True, True, False, False ]
means to keep the 4's and reroll the 6, the 3, and the 1.
The allRolls function then produces a list of the possible resulting
dice states, in this case 216 items:
[ ( [ 1, 4, 4, 1, 1 ], 1 ) ,
( [ 1, 4, 4, 1, 2 ], 1 ) ,
( [ 1, 4, 4, 1, 3 ], 1 ) ,
…
( [ 6, 4, 4, 6, 6 ], 1 ) ]
This function was not hard to write and it did work adequately.
But I wasn't satisfied. What if I have some unrelated integer list
and I pass it to a function that is expecting a DiceVals, or vice
versa? Haskell type checking is supposed to prevent this from
happening, and by using type aliases I am forgoing this advantage.
No problem, I can easily make DiceVals and the others into datatypes:
data DiceChoice = DiceChoice [ Bool ]
data DiceVals = DiceVals [ Integer ]
data DiceState = DiceState (DiceVals, Integer)
The declared type of allRolls is the same:
allRolls :: DiceChoice -> DiceState -> [ DiceState ]
But now I need to rewrite allRolls, and a straightforward
translation is unreadable:
allRolls (DiceChoice []) (DiceState (DiceVals [], n)) = [ DiceState(DiceVals [], n-1) ]
allRolls (DiceChoice []) _ = undefined
allRolls (DiceChoice (chosen:choices)) (DiceState (DiceVals (v:vs), n)) =
allRolls (DiceChoice choices) (DiceState (DiceVals vs,n-1)) >>=
\(DiceState(DiceVals roll, _)) -> [ DiceState (DiceVals (d:roll), n-1) | d <- rollList ]
where rollList = if chosen then [v] else [ 1..6 ]
This still compiles and it still produces the results I want. And it
has the type checking I want. I can no longer pass a raw integer
list, or any other isomorphic type, to allRolls. But it's
unmaintainable.
I could rename allRolls to something similar, say allRolls__, and
then have allRolls itself be just a type-checking front end to
allRolls__, say like this:
allRolls :: DiceChoice -> DiceState -> [ DiceState ]
allRolls (DiceChoice dc) (DiceState ((DiceVals dv), n)) =
allRolls__ dc dv n
allRolls__ [] [] n = [ DiceState (DiceVals [], n-1) ]
allRolls__ [] _ _ = undefined
allRolls__ (chosen:choices) (v:vs) n =
allRolls__ choices vs n >>=
\(DiceState(DiceVals roll,_)) -> [ DiceState (DiceVals (d:roll), n-1) | d <- rollList ]
where rollList = if chosen then [v] else [ 1..6 ]
And I can do something similar on the output side also:
allRolls :: DiceChoice -> DiceState -> [ DiceState ]
allRolls (DiceChoice dc) (DiceState ((DiceVals dv), n)) =
map wrap $ allRolls__ dc dv n
where wrap (dv, n) = DiceState (DiceVals dv, n)
allRolls__ [] [] n = [ ([], n-1) ]
allRolls__ [] _ _ = undefined
allRolls__ (chosen:choices) (v:vs) n =
allRolls__ choices vs n >>=
\(roll,_) -> [ (d:roll, n-1) | d <- rollList ]
where rollList = if chosen then [v] else [ 1..6 ]
This is not unreasonably longer or more cluttered than the original
code. It does forgo type checking inside of allRolls__,
unfortunately. (Suppose that the choices and vs arguments had the
same type, and imagine that in the recursive call I put them in the
wrong order.)
Is this considered The Thing To Do? And if so, where could I have learned this, so that I wouldn't have had to invent it? (Or, if not, where could I have learned whatever is The Thing To Do?)
I find most Haskell instruction on the Internet to be either too elementary
pet the nice monad, don't be scared, just approach it very slowly and it won't bite
or too advanced
here we've enabled the
{-# SemispatulatedTypes #-}pragma so we can introduce an overloaded contravariant quasimorphism in the slice category
with very little practical advice about how to write, you know, an actual program. Where can I find some?
[Other articles in category /prog/haskell] permanent link
Wed, 28 Aug 2019It has sometimes happened that I couldn't get my git add -p to work. I would carefully
edit a chunk, and then Git would say
Your edited hunk does not apply. Edit again (saying "no" discards!) [y/n]? e
or sometimes also
error: patch fragment without header at line 33: @@ -26,21 +29,20 @@ class Parser():
so I'd do it over, and it still wouldn't work.
Today I learned that at least some of those are because Emacs's
diff-mode has some bug. It's getting the @@ lines wrong. When I
switched to text-mode and composed the @@ line myself, the patch
applied.
[Other articles in category /prog] permanent link
Sat, 03 Aug 2019
Git wishlist: aggregate changes across non-contiguous commits
(This is actually an essay on the difference between science and engineering.)
My co-worker Lemuel recently asked if there was a way to see all the
changes to master from the last week that pertained to a certain
ticket. The relevant commit messages all contained the ticket ID, so
he knew which commits he wanted; that part is clear. Suppose Lemuel
wanted to see the changes introduced in commits C, E, and H, but not
those from A, B, D, F, or G.

The closest he could come was git show H E C, which wasn't quite what
he wanted. It describes the complete history of the changes, but what
he wanted is more analogous to a diff. For comparison, imagine a
world in which
git diff A H didn't exist, and you were told to use git show A B C
D E F G H instead. See the problem? What Lemuel wants is more like
diff than like show.
Lemuel's imaginary command would solve another common request: How can
I see all the changes that I have landed on master in a certain
time interval? Or similarly: how can I add up the git diff --stat
line counts for all my commits in a certain interval?
He said:
It just kinda boggles my mind you can't just get a collective diff on command for a given set of commits
I remember that when I was first learning Git, I often felt boggled in this way. Why can't it just…? And there are several sorts of answers, of which one or more might apply in a particular situation:
- It surely could, but nobody has done it yet
- It perhaps could, but nobody is quite sure how
- It maybe could, but what you want is not as clear as you think
- It can't, because that is impossible
- I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question
Often, engineers will go straight to #5, when actually the answer is in a higher tier. Or they go to #4 without asking if maybe, once the desiderata are clarified a bit, it will move from “impossible” to merely “difficult”. These are bad habits.
I replied to Lemuel's (implicit) question here and tried to make it a mixture of 2 and 3, perhaps with a bit of 4:
Each commit is a snapshot of the state of the repo at a particular instant. A diff shows you the difference between two snapshots. When you do git show commit you're looking at the differences between the snapshot at that commit and at its parent.
Now suppose you have commit A with parent B, and commit C with parent D. I come to you and say I want to see the differences in both A and C at that same time. What would you have it do?

If A and B are on a separate branch and are completely unrelated to C
and D, it is hard to see what to do here. But it's not impossible.
Our hypothetical command could produce the same output as git show A
C. Or it could print an error message Can't display changes from
unrelated commits A, C and die without any more output. Either of
those might be acceptable.
And if A, B, C, D are all related and on the same branch, say with D , then C, then B, then A, the situation is simpler and perhaps we can do better.

If so, very good, because this is probably the most common case by far. Note that Lemuel's request is of this type.
I continued:
Suppose, for example,that C changes some setting from 0 to 1, then B changes it again to be 2, then A changes it a third time, to say 3. What should the diff show?
This is a serious question, not a refutation. Lemuel could quite
reasonably reply by saying that it should show 0 changing to 3, the
intermediate changes being less important. (“If you wanted to see
those, you should have used git show A C.”)
It may be that that wouldn't work well in practice, that you'd find there were common situations where it really didn't tell you what you wanted to know. But that's something we'd have to learn by trying it out.
I was trying really hard to get away from “what you want is stupid” and toward “there are good reasons why this doesn't exist, but perhaps they are surmountable”:
(I'm not trying to start an argument, just to reduce your bogglement by explaining why this may be less well-specified and more complex than you realize.)
I hoped that Lemuel would take up my invitation to continue the discussion and I tried to enocurage him:
I've wanted this too, and I think something like it could work, especially if all the commits are part of the same branch. … Similarly people often want a way to see all the changes made only by a certain person. Your idea would answer that use case also.
Let's consider another example. Suppose some file contains functions X, Y, Z in that order. Commit A removes Y entirely. Commit B adds a new function, YY, between X and Z. Commit C modifies YY to produce YY'. Lemuel asks for the changes introduced by A and C; he is not interested in B. What should happen?
If Y and YY are completely unrelated, and YY just happens to be at the same place in the file, I think we definitely want to show Y being removed by A, and then that C has made a change to an unrelated function. We certainly don't want to show all of YY beind added. But if YY is considered to be a replacement for Y, I'm not as sure. Maybe we can show the same thing? Or maybe we want to pretend that A replaced Y with YY? That seems dicier now than when I first thought about it, so perhaps it's not as big a problem as I thought.
Or maybe it's enough to do the following:
Take all the chunks produced by the diffs in the output of
git show .... In fact we can do better: if A, B, and C are a contiguous sequence, with A the parent of B and B the parent of C, then don't use the chunks fromgit show A B C; usegit diff A C.Sort the chunks by filename.
Merge the chunks that are making changes to the same file:
If two chunks don't overlap at all, there's no issue, just keep them as separate chunks.
If two chunks overlap and don't conflict, merge them into a single chunk
If they overlap and do conflict, just keep them separate but retain the date and commit ID information. (“This change, then this other change.”)
Then output all the chunks in some reasonable order: grouped by file, and if there were unmergeable chunks for the same file, in chronological order.
This is certainly doable.
If there were no conflicts, it would certainly be better than git
show ... would have been. Is it enough better to offset whatever
weirdness might be introduced by the overlap handling? (We're
grouping chunks by filename. What if files are renamed?) We don't
know, and it does not even have an objective answer. We would have to
try it, and then the result might be that some people like it and use
it and other people hate it and refuse to use it. If so, that is a win!
[Other articles in category /prog] permanent link
Sun, 07 Jul 2019[ I wrote this in 2007 and forgot to publish it. Or maybe I was planning to finish it first. But if so I have no idea what I was originally planning to say, so here we are. ]
In computer programs, it's quite common to need a numerical value for π. Often you see something like:
#define PI 3.141592654
This has the drawback of not representing π as exactly as possible. But to do that in C probably requires putting in 16 digits after the decimal point, and most people don't have so much memorized. And anyway, you don't really know at compile time what the floating-point precision will be; some platforms support quad-width floats. So you can do better, maybe, by using the math library to calculate π. And people do:
static double pi = 4*atan2(1,1);
The atan2(y, x) function produces the (almost-)unique value θ from the range !![-\pi, \pi]!! such that a ray from the origin, passing through point (x, y), makes angle θ with the x-axis.
Note that the arguments have y first and x second.
For example, atan2(17, 0) returns !!\frac\pi
2!!, because a line at angle !!\frac\pi 2!! passes through the point
(0, 17). Similarly, atan2(-17, 0) returns -!!\frac\pi 2!!.
You can use atan2 to calculate π, by using
!!4·{\operatorname{atan}}2(1,1)!!, as I mentioned above. Many people
do; Google searching finds hundreds of examples. The manual for the
standard Perl module constant.pm mentions this example.
But this is a bit strange. Why is this so well-known? Why calculate 4*atan2(1,1) when $$\pi = {\operatorname{atan}}2(0,-1)$$ produces the same result and is simpler?
(Obligatory IEEE 754 complaining: atan2 should return an always-unique value from
!!(-\pi, \pi]!!, but I have to say “almost-unique” because as usual IEEE
754 fucks everything up, this time with its stupid distinction between
0 and -0.)
[ Addendum: Leah Neukirchen suggests that the atan2(1,1) is a
translation from earlier systems that provide a single-argument atan
function but no atan2. In those systems, there is no
workable analogue of atan2(0, -1) because the transformation
!!{\operatorname{atan}}2(y, x)\Rightarrow
{\operatorname{atan}}\left(\frac yx\right)!! gives !!{\operatorname{atan}}(0)!!, which doesn't work for this
application as it yields !!0!! instead of the desired !!\pi!!. And
similarly in languages with atan but not atan2 there is no analogue of !!\pi =
2·{\operatorname{atan}}2(1, 0)!!. So the simplest thing you can do is pi = 4 * atan(1),
and after the transformation above one gets !!\pi = 4·{\operatorname{atan}}2(1,1)!!. ]
[Other articles in category /prog] permanent link
Mon, 17 Jun 2019
Don't let the man page write checks that the programmer can't cash
My big work project is called “Greenlight”. It's a Git branch merging
service. After you've pushed a remote branch, say mjd.fix-bugs, you
use a very thin client program to ask the Greenlight server to land your
branch on master and publish it for you:
greenlight submit mjd.fix-bugs
Greenlight analyzes the branch to see if it touches any sensitive code
that requires signoffs. If so it contacts the correct people on
Slack, and asks them to review it. Once they have approved it,
Greenlight rebases the branch onto the current master and pushes the
result back to master. If the push fails, it retries silently.
Throughout, it communicates via Slack what is going on.
 A user, Locksher, complained last week that it didn't do what he had
expected. He had a Git
A user, Locksher, complained last week that it didn't do what he had
expected. He had a Git pre-push hook he had written. Whenever he
ran git push, his pre-push hook would look to see if he was pushing
to master. If so, it would look at the messages of the commits he
was trying to push. If any of them contained WIP or !fixup or !squash,
it would abort the push.
With Greenlight, this check wasn't done, because Locksher never pushed
to master himself. Instead he pushed to some topic branch, and then
asked Greenlight to publish it to master, which it did, including
his WIP commits. Oops!
Locksher asked if it was possible to have Greenlight “respect local
hooks”. Once I understood what he wanted, my first suggestion was
that he wrap the greenlight client in a shell script that did the
check he wanted. My second suggestion, less work for him but also
less immediate, was that the Greenlight client could look in
.git/hooks for a greenlight-pre-submit hook, and run that before
communicating with the server, aborting the request if the hook
failed. I think this would adequately solve the problem, especially
if the calling convention for the new hook was identical to that of
pre-push. Then you would just:
ln -s pre-push .git/hooks/greenlight-pre-submit
and get exactly the desired behavior. I said that if Locksher wanted to implement this, I would include it in the standard client, or alternatively I would open a ticket to implement it myself, eventually.
Locksher suggested instead that the greenlight client configuration
should support this:
[git]
respect-git-hooks = true
I didn't have time then to answer in detail, so I just said:
I consider that very unlikely.
Here's what I said to him once I did have time to answer in detail:
There are currently 23 documented Git hooks, and it's not immediately clear what it would mean to “respect” many of them. I'd have to go over the man page and decide, for each one, what the behavior should be, then possibly implement it, and then document it. Just to pick one example, should Greenlight “respect” your
prepare-commit-messagehook? If so, how?Even for the hooks where the correct behavior seemed clear to me, it might seem clearly something else to someone else. So the feature is severely under-specified and seems likely to cause confusion. I foresee a future of inquiries like “I set
respect-git-hooksbut Greenlight didn't run mypre-auto-gchook.”It is an open-ended promise. The way the option is phrased, it guarantees to “respect” every hook. So it commits me to keep track of what new hooks are introduced in every future version of Git, and to decide what to do about each of them.
Since
greenlightruns on your local machine, the local version of Git may vary. What if the behavior of Git'spre-cake-slicinghook changes between Git 1.24 and Git 1.26? Now Greenlight will have to implement two behaviors, and look at your local Git version to decide what to do.Oh, and 5, it is a YAGNI.
In contrast, the functionality provided by
greenlight-pre-submitis something someone has actually asked for. It is small, sharply bounded in scope and its definition is completely under my control.
 I will elaborate a little on the main items 1–2, that different
people might have different ideas about what it means to “respect” a
local hook. Consider Locksher's specific request, for
I will elaborate a little on the main items 1–2, that different
people might have different ideas about what it means to “respect” a
local hook. Consider Locksher's specific request, for greenlight to
“respect” his pre-push hook. Another user, say Zubi, could object,
quite reasonably, that greenlight submit is not the same as git
push, and that the correct way for it to “respect” her pre-push
hook is to ignore it. “I want my pre-push hook run when I push a
branch,” she might say, “not when I do greenlight submit.” Who
could argue with that? (Other than Locksher, of course.)
So then I would have to add an escape hatch for Zubi, so that everyone who didn't want Locksher's feature would have to affirmatively opt out of it.
Nah.
[Other articles in category /prog] permanent link
Tue, 21 May 2019Say $dt is a Perl DateTime
object.
You are allowed to say
$dt->add( days => 2 )
$dt->subtract( days => 2 )
Today Jeff Boes pointed out that I had written a program that used
$dt->add({ days => 2 })
which as far as I can tell is not documented to work. But it did work. (I wrote it in 2016 and would surely have noticed by now if it hadn't.) Jeff told me he noticed when he copied my code and got a warning. When I tried it, no warning.
It turns out that
$dt->add({ days => 2 })
$dt->subtract({ days => 2 })
both work, except that:
The
subtractcall produces a warning (adddoesn't! and Jeff had changed myaddtosubtract)If you included an
end_of_month => $modeparameter in the arguments tosubtract, it would get lost.
Also, the working-ness of what I wrote is a lucky fluke. It is
undocumented (I think) and works only because of a quirk of the
implementation. ->add passes its arguments to
DateTime::Duration->new, which passes them to
Params::Validate::validate. The latter is documented to accept
either form. But its use by DateTime::Duration is an undocumented
implementation detail.
->subtract works the same way, except that it does a little bit of
preprocessing on the arguments before calling
DateTime::Duration->new. That's where the warning comes from, and
why end_of_month won't work with the hashref form.
(All this is as of version 1.27. The current version is 1.51. Matthew Horsfall points out that 1.51 does not raise a warning, because of a different change to the same interface.)
This computer stuff is amazingly complicated. I don't know how anyone gets anything done.
[Other articles in category /prog/bug] permanent link
Tue, 04 Dec 2018
I figured out that context manager bug!
A couple of days ago I described a strange bug in my “Greenlight” project that was causing Git to fail unpredictably, saying:
fatal: this operation must be run in a work tree
The problem seemed to go away when I changed
with env_var("GIT_DIR", self.repo_dir):
with env_var("GIT_WORK_TREE", self.work_dir):
result = subprocess.run(command, ...)
to
with env_var("GIT_DIR", self.repo_dir, "GIT_WORK_TREE", self.work_dir):
result = subprocess.run(command, ...)
but I didn't understand why. I said:
This was so unexpected that I wondered if the real problem was nondeterministic and if some of the debugging messages had somehow perturbed it. But I removed everything but the context manager change and ran another test, which succeeded. By then I was five and half hours into the debugging and I didn't have any energy left to actually understand what the problem had been. I still don't know.
The problem re-manifested again today, and this time I was able to track it down and fix it. The context manager code I mentioned above was not the issue.
That subprocess.run call is made inside a git_util object which,
as you can see in the tiny excerpt above, has a self.work_dir
attribute that tells it where to find the working tree. Just before
running a Git command, the git_util object installs self.work_dir
into the environment to tell Git where the working tree is.
The git_util object is originally manufactured by Greenlight itself,
which sets the work_dir attribute to a path that contains the
current process ID number. Just before the process exits, Greenlight
destroys the working tree. This way, concurrent processes never try
to use the same working tree, which would be a mess.
When Greenlight needs to operate on the repository, it uses its
git_util object directly. It also creates a submission object to
represent the submitted branch, and it installs the git_util object
into the submission object, so that the submission object can also
operate on the repository. For example, the submission object may ask
its git_util object if it needs to be rebased onto some other
branch, and if so to please do it. So:
- Greenlight has a
submission. submission.gitis thegit_utilobject that deals with Git.submission.git.work_diris the path to the per-process temporary working tree.
Greenlight's main purpose is to track these submission objects, and it has a database of them. To save time when writing the initial implementation, instead of using a real database, I had Greenlight use Python's “pickle” feature to pickle the list of submissions.
Someone would submit a branch, and Greenlight would pickle the
submission. The submission contained its git_util object, and that
got pickled along with the rest. Then Greenlight would exit and, just
before doing so, it would destroy its temporary working tree.
Then later, when someone else wanted to approve the submission for
publication, Greenlight would set up a different working tree with its
new process ID, and unpickle the submission. But the submission's
git.work_dir had been pickled with the old path, which no longer
existed.
The context manager was working just fine. It was setting
GIT_WORK_TREE to the work_dir value in the git_util object. But
the object was obsolete and its work_dir value pointed to a
directory that had been destroyed!
Adding to the confusion:
Greenlight's own
git_utilobject was always fresh and had the right path in it, so Git commands run directly by Greenlight all worked properly.Any new
submissionobjects created by Greenlight would have the right path, so Git commands run by fresh submissions also worked properly.Greenlight doesn't always destroy the working tree when it exits. If it exits abnormally, it leaves the working tree intact, for a later autopsy. And the unpickled submission would work perfectly if the working tree still existed, and it would be impossible to reproduce the problem!
Toward the end of the previous article, I said:
I suspect I'm being sabotaged somewhere by Python's weird implicit ideas of scope and variable duration, but I don't know. Yet.
For the record, then: The issue was indeed one of variable duration. But Python's weird implicit ideas were, in this instance, completely blameless. Instead the issue was caused by a software component even more complex and more poorly understood: “Dominus”.
This computer stuff is amazingly complicated. I don't know how anyone gets anything done.
[Other articles in category /prog/bug] permanent link
Sun, 02 Dec 2018
Another day, another bug. No, four bugs.
I'm working on a large and wonderful project called “Greenlight”. It's a Git branch merging service that implements the following workflow:
- Submitter submits a branch to Greenlight (
greenlight submit my-topic-branch) - Greenlight analyzes the branch to decide if it changes anything that requires review and signoff
- If so, it contacts the authorized reviewers, who then inform
Greenlight that they approve the changes (
greenlight approve 03a46dc1) - Greenlight merges the branch to
masterand publishes the result to the central repository
Of course, there are many details elided here.
Multiple instances of Greenlight share a local repository, but to avoid
confusion each has its own working tree. In Git you can configure
these by setting GIT_DIR and GIT_WORK_TREE environment variables,
respectively. When Greenlight needs to run a Git command, it does so
like this:
with env_var("GIT_DIR", self.repo_dir):
with env_var("GIT_WORK_TREE", self.work_dir):
result = subprocess.run(command, ...)
The env_var here is a Python context manager that saves the old
environment, sets the new environment variable, and then when the body
of the block is complete, it restores the environment to the way it
was. This worked in testing every time.
But the first time a beta tester ran the approve command, Greenlight
threw a fatal exception. It was trying to run git checkout --quiet
--detach, and this was failing, with Git saying
fatal: this operation must be run in a work tree
Where was the GIT_WORK_TREE setting going? I still don't know. But
in the course of trying to track the problem down, I changed the code
above to:
with env_var("GIT_DIR", self.repo_dir, "GIT_WORK_TREE", self.work_dir):
result = subprocess.run(command, ...)
and the problem, whatever it was, no longer manifested.
But this revealed a second bug: Greenlight no longer failed in the
approval phase. It went ahead and merged the branch, and then tried
to publish the merge with git push origin .... But the push was
rejected.
This is because the origin repository had an update hook that ran
on every push, which performed the same review analysis that Greenlight
was performing; one of Greenlight's main purposes is to be a
replacement for this hook. To avoid tying up the main repository for
too long, this hook had a two-minute timeout, after which it would die
and reject the push. This had only happened very rarely in the past,
usually when someone was inadvertently trying to push a malformed
branch. For example, they might have rebased all of master onto
their topic branch. In this case, however, the branch really was
legitimately enormous; it contained over 2900 commits.
“Oh, right,” I said. “I forgot to add the exception to the hook that tells it that it can immediately approve anything pushed by Greenlight.” The hook can assume that if the push comes from Greenlight, it has already been checked and authorized.
Pushes are happening via SSH, and Greenlight has its own SSH identity,
which is passed to the hook itself in the GL_USERNAME variable.
Modifying the hook was easy: I just added:
if environ["GL_USERNAME"] == 'greenlight':
exit(0)
This didn't work. My first idea was that Greenlight's public SSH key
had not been installed in the authorized_keys file in the right
place. When I grepped for greenlight in the authorized_keys file,
there were no matches. The key was actually there, but in Gitlab the
authorized_keys file doesn't have actual usernames in it. It has
internal userids, which are then mapped to GL_USERNAME variables by
some other entity. So I chased that wild goose for a while.
Eventually I determined that the key was in the right place, but
that the name of the Greenlight identity on the receiving side was not
greenlight but bot-greenlight, which I had forgotten.
So I changed the exception to say:
if environ["GL_USERNAME"] == 'bot-greenlight':
exit(0)
and it still didn't work. I eventually discovered that when
Greenlight did the push, the GL_USERNAME was actually set to mjd.
“Oh, right,” I said. “I forgot to have Greenlight use its own
SSH credentials in the ssh connection.”
The way you do this is to write a little wrapper program that obtains
the correct credentials and runs ssh, and then you set GIT_SSH to
point to the wrapper. It looks like this:
#!/usr/bin/env bash
export -n SSH_CLIENT SSH_TTY SSH_AUTH_SOCK SSH_CONNECTION
exec /usr/bin/ssh -i $HOME/.ssh/identity "$@"
But wait, why hadn't I noticed this before? Because, apparently,
every single person who had alpha-tested Greenlight had had their own
credentials stored in ssh-agent, and every single one had had
agent-forwarding enabled, so that when Greenlight tried to use ssh
to connect to the Git repository, SSH duly forwarded their credentials
along and the pushes succeeded. Amazing.
With these changes, the publication went through. I committed the changes to the SSH credential stuff, and some other unrelated changes, and I looked at what was left to see what had actually fixed the original bug. Every change but one was to add diagnostic messages and logging. The fix for the original bug had been to replace the nested context managers with a single context manager. This was so unexpected that I wondered if the real problem was nondeterministic and if some of the debugging messages had somehow perturbed it. But I removed everything but the context manager change and ran another test, which succeeded. By then I was five and half hours into the debugging and I didn't have any energy left to actually understand what the problem had been. I still don't know.
If you'd like to play along at home, the context manager looks like this, and did not change during the debugging process:
from contextlib import contextmanager
@contextmanager
def env_var(*args):
# Save old values of environment variables in `old`
# A saved value of `None` means that the variable was not there before
old = {}
for i in range(len(args)//2):
(key, value) = (args[2*i : 2*i+2])
old[key] = None
if key in os.environ:
old[key] = os.environ[str(key)]
if value is None: os.environ.pop(str(key), "dummy")
else:
os.environ[str(key)] = str(value)
yield
# Undo changes from versions saved in `old`
for (key, value) in old.items():
if value is None: os.environ.pop(str(key), "dummy")
else: os.environ[str(key)] = value
I suspect I'm being sabotaged somewhere by Python's weird implicit ideas of scope and variable duration, but I don't know. Yet.
This computer stuff is amazingly complicated. I don't know how anyone gets anything done.
[ Addendum 20181204: I figured it out. ]
[Other articles in category /prog/bug] permanent link
Fri, 09 Nov 2018
Why I never finish my Haskell programs (part 3 of ∞)
I'm doing more work on matrix functions. A matrix represents a
relation, and I am representing a matrix as a [[Integer]]. Then
matrix addition is simply liftA2 (liftA2 (+)). Except no, that's
not right, and this is not a complaint, it's certainly my mistake.
The overloading for liftA2 for lists does not do what I want, which
is to apply the operation to each pair of correponding elements. I want
liftA2 (+) [1,2,3] [10,20,30] to be [11,22,33] but it is not.
Instead liftA2 lifts an operation to apply to each possible pair of
elements, producing [11,21,31,12,22,32,13,23,33].
And the twice-lifted version is
similarly not what I want:
$$ \require{enclose} \begin{pmatrix}1&2\\3&4\end{pmatrix}\enclose{circle}{\oplus} \begin{pmatrix}10&20\\30&40\end{pmatrix}= \begin{pmatrix} 11 & 21 & 12 & 22 \\ 31 & 41 & 32 & 42 \\ 13 & 23 & 14 & 24 \\ 33 & 43 & 34 & 44 \end{pmatrix} $$
No problem, this is what ZipList is for. ZipLists are just regular
lists that have a label on them that advises liftA2 to lift an
operation to the element-by-element version I want instead of the
each-one-by-every-other-one version that is the default. For instance
liftA2 (+) (ZipList [1,2,3]) (ZipList [10,20,30])
gives ZipList [11,22,33], as desired. The getZipList function
turns a ZipList back into a regular list.
But my matrices are nested lists, so I need to apply the ZipList
marker twice, once to the outer list, and once to each of the inner
lists, because I want the element-by-element behavior at both
levels. That's easy enough:
matrix :: [[a]] -> ZipList (ZipList a)
matrix m = ZipList (fmap ZipList m)
(The fmap here is actually being specialized to map, but that's
okay.)
Now
(liftA2 . liftA2) (+) (matrix [[1,2],[3,4]]) (matrix [[10,20],[30, 40]])
does indeed produce the result I want, except that the type markers are still in there: instead of
[[11,22],[33,44]]
I get
ZipList [ ZipList [11, 22], ZipList [33, 44] ]
No problem, I'll just use getZipList to turn them back again:
unmatrix :: ZipList (ZipList a) -> [[a]]
unmatrix m = getZipList (fmap getZipList m)
And now matrix addition is finished:
matrixplus :: [[a]] -> [[a]] -> [[a]]
matrixplus m n = unmatrix $ (liftA2 . liftA2) (+) (matrix m) (matrix n)
This works perfectly.
But the matrix and unmatrix pair bugs me a little. This business
of changing labels at both levels has happened twice already and
I am likely to need it again. So I will turn the two functions
into a single higher-order function by abstracting over ZipList.
This turns this
matrix m = ZipList (fmap ZipList m)
into this:
twice zl m = zl (fmap zl m)
with the idea that I will now have matrix = twice ZipList and
unmatrix = twice getZipList.
The first sign that something is going wrong is that twice does not
have the type I wanted. It is:
twice :: Functor f => (f a -> a) -> f (f a) -> a
where I was hoping for something more like this:
twice :: (Functor f, Functor g) => (f a -> g a) -> f (f a) -> g (g a)
which is not reasonable to expect: how can Haskell be expected to
figure out I wanted two diferent functors in there when there is only one
fmap? And indeed twice does not work; my desired matrix = twice
ZipList does not even type-check:
<interactive>:19:7: error:
• Occurs check: cannot construct the infinite type: a ~ ZipList a
Expected type: [ZipList a] -> ZipList a
Actual type: [a] -> ZipList a
• In the first argument of ‘twice’, namely ‘ZipList’
In the expression: twice ZipList
In an equation for ‘matrix’: matrix = twice ZipList
• Relevant bindings include
matrix :: [[ZipList a]] -> ZipList a (bound at <interactive>:20:5)
Telling GHC explicitly what type I want for twice doesn't work
either, so I decide it's time to go to lunch. I take paper with me,
and while I am eating my roast pork hoagie with sharp provolone and
spinach (a popular local delicacy) I work out the results of the type
unification algorithm on paper for both cases to see what goes wrong.
I get the same answers that Haskell got, but I can't see where the difference was coming from.
So now, instead of defining matrix operations, I am looking into the
type unification algorithm and trying to figure out why twice
doesn't work.
And that is yet another reason why I never finish my Haskell programs. (“What do you mean, λ-abstraction didn't work?”)
[Other articles in category /prog/haskell] permanent link
Thu, 08 Nov 2018
Haskell type checker complaint 184 of 698
I want to build an adjacency matrix for the vertices of a cube; this
is a matrix that has m[a][b] = 1 exactly when vertices a and b
share an edge. We can enumerate the vertices arbitrarily but a
convenient way to do it is to assign them the numbers 0 through 7 and
then say that vertices !!a!! and !!b!! are adjacent if, regarded as
binary numerals, they differ in exactly one bit, so:
import Data.Bits
a `adj` b = if (elem (xor a b) [1, 2, 4]) then 1 else 0
This compiles and GHC infers the type
adj :: (Bits a, Num a, Num t) => a -> a -> t
Fine.

Now I want to build the adjacency matrix, which is completely straightforward:
cube = [ [a `adj` b | b <- [0 .. 7] ] | a <- [0 .. 7] ] where
a `adj` b = if (elem (xor a b) [1, 2, 4]) then 1 else 0
Ha ha, no it isn't; in Haskell nothing is straightforward. This
produces 106 lines of type whining, followed by a failed compilation.
Apparently this is because because 0 and 7 are overloaded, and
could mean some weird values in some freakish instance of Num, and
then 0 .. 7 might generate an infinite list of 1-graded torsion
rings or something.
To fix this I have to say explicitly what I mean by 0. “Oh, yeah,
by the way, that there zero is intended to denote the integer zero,
and not the 1-graded torsion ring with no elements.”
cube = [ [a `adj` b | b <- [0 :: Integer .. 7] ] | a <- [0 .. 7] ] where
a `adj` b = if (elem (xor a b) [1, 2, 4]) then 1 else 0
Here's another way I could accomplish this:
zero_i_really_mean_it = 0 :: Integer
cube = [ [a `adj` b | b <- [zero_i_really_mean_it .. 7] ] | a <- [0 .. 7] ] where
a `adj` b = if (elem (xor a b) [1, 2, 4]) then 1 else 0
Or how about this?
cube = [ [a `adj` b | b <- numbers_dammit [0 .. 7] ] | a <- [0 .. 7] ] where
p `adj` q = if (elem (xor p q) [1, 2, 4]) then 1 else 0
numbers_dammit = id :: [Integer] -> [Integer]
I think there must be something really wrong with the language design here. I don't know exactly what it is, but I think someone must have made the wrong tradeoff at some point.
[Other articles in category /prog/haskell] permanent link
Fri, 02 Nov 2018
Another trivial utility: git-q
One of my favorite programs is a super simple Git utility called
git-vee
that I just love, and I use fifty times a day. It displays a very
simple graph that shows where two branches diverged. For example, my
push of master was refused because it was not a
fast-forward. So I
used git-vee to investigate, and saw:
* a41d493 (HEAD -> master) new article: Migraine
* 2825a71 message headers are now beyond parody
| * fa2ae34 (origin/master) message headers are now beyond parody
|/
o 142c68a a bit more information
The current head (master) and its upstream (origin/master) are
displayed by default. Here the nearest common ancestor is 142c68a,
and I can see the two commits after that on master that are
different from the commit on origin/master. The command is called
git-vee because the graph is (usually) V-shaped, and I want to find
out where the point of the V is and what is on its two arms.
From this V, it appears that what happened was: I pushed fa2ae34,
then amended it to produce 2825a71, but I have not yet force-pushed
the amendment. Okay! I should simply do the force-push now…
Except wait, what if that's not what happened? What if what
happened was, 2825a71 was the original commit, and I pushed it, then
fetched it on a different machine, amended it to produce fa2ae34,
and force-pushed that? If so, then force-pushing 2825a71 now would
overwrite the amendments. How can I tell what I should do?
Formerly I would have used diff and studied the differences, but now
I have an easier way to find the answer. I run:
git q HEAD^ origin/master
and it produces the dates on which each commit was created:
2825a71 Fri Nov 2 02:30:06 2018 +0000
fa2ae34 Fri Nov 2 02:25:29 2018 +0000
Aha, it was as I originally thought: 2825a71 is five minutes newer.
The force-push is the right thing to do this time.
Although the commit date is the default output, the git-q
command can
produce any of the information known to git-log, using the usual
escape sequences.
For example, git q %s ... produces subject lines:
% git q %s HEAD origin/master 142c68a
a41d493 new article: Migraine
fa2ae34 message headers are now beyond parody
142c68a a bit more information
and git q '%an <%ae>' tells you who made the commits:
a41d493 Mark Jason Dominus (陶敏修) <mjd@plover.com>
fa2ae34 Mark Jason Dominus (陶敏修) <mjd@plover.com>
142c68a Mark Jason Dominus (陶敏修) <mjd@plover.com>
The program is in my personal git-util repository but it's totally simple and should be easy to customize the way you want:
#!/usr/bin/python3
from sys import argv, stderr
import subprocess
if len(argv) < 3: usage()
if argv[1].startswith('%'):
item = argv[1]
ids = argv[2:]
else:
item='%cd'
ids = argv[1:]
for id in ids:
subprocess.run([ "git", "--no-pager",
"log", "-1", "--format=%h " + item, id])
[Other articles in category /prog] permanent link
Mon, 29 Oct 2018Warning: Long and possibly dull.
I spent a big chunk of today fixing a bug that should have been easy but that just went deeper and deeper. If you look over in the left sidebar there you'll se a sub-menu titled “subtopics” with a per-category count of the number of articles in each section of this blog. (Unless you're using a small display, where the whole sidebar is suppressed.) That menu was at least a year out of date. I wanted to fix it.
The blog software I use is the wonderfully terrible
Blosxom. It has a plugin system,
and the topic menu was generated by a plugin that I wrote some time
ago. When the topic plugin starts up it opens two Berkeley
DB files. Each is a simple
key-value mapping. One maps topic names to article counts. The other
is just a set of article IDs for the articles that have already been
counted. These key-value mappings are exposed in Perl as hash
variables.
When I regenerate the static site, the topic plugin has a
subroutine, story, that is called for each article in each generated
page. The business end of the subroutine looks something like this:
sub story {
# ... acquire arguments ..
if ( $Seen{ $article_id } ) {
return;
} else {
$topic_count{ $article_topic }++;
$Seen{ $article_id } = 1;
}
}
The reason the menu wasn't being updated is that at some point in the
past, I changed the way story plugins were called. Out of the box,
Blosxom passes story a list of five arguments, like this:
my ($pkg, $path, $filename, $story_ref, $title_ref) = @_;
Over the years I had extended this to eight or nine, and I felt it was getting unwieldy, so at some point I changed it to pass a hash, like this:
my %args = (
category => $path, # directory of this story
filename => $fn, # filename of story, without suffix
...
)
$entries = $plugin->story(\%args);
When I made this conversion, I had to convert all the plugins. I
missed converting topic. So instead of getting the eight or nine
arguments it expected, it got two: the plugin itself, and the hash.
Then it used the hash as the key into the databases, which by now
were full of thousands of entries for things like HASH(0x436c1d)
because that is what Perl silently and uselessly does if you try to
use a hash as if it were a string.
Anyway, this was easily fixed, or should have been easily fixed. All I needed to do was convert the plugin to use the new calling convention. Ha!
One thing all my plugins do when they start up is write a diagnostic log, something like this:
sub start {
open F, ">", "/tmp/topic.$>";
print F "Writing to $blosxom::plugin_state_dir/topics\n";
}
Then whenever the plugin has something to announce it just does
print F. For example, when the plugin increments the count for a
topic, it inserts a message like this:
print F "'$article_id' is item $topic_count{$article_topic} in topic $article_topic.\n";
If the article has already been seen, it remains silent.
Later I can look in /tmp/topic.119 or whatever to see what it said.
When I'm debugging a plugin, I can open an Emacs buffer on this file
and put it in auto-revert mode so that Emacs always displays the
current contents of the file.
Blosxom has an option to generate pages on demand for a web browser,
and I use this for testing. https://blog.plover.com/PATH is the
static version of the article, served from a pre-generated static
file. But https://blog.plover.com/test/PATH calls Blosxom as a CGI
script to generate the article on the fly and send it to the browser.
So I visited https://blog.plover.com/test/2018/, which should
generate a page with all the articles from 2018, to see what the
plugin put in the file. I should have seen it inserting a lot of
HASH(0x436c1d) garbage:
'lang/etym/Arabic-2' is article 1 in topic HASH(0x22c501b)
'addenda/200801' is article 1 in topic HASH(0x5300aa2)
'games/poker-24' is article 1 in topic HASH(0x4634a79)
'brain/pills' is article 1 in topic HASH(0x1a9f6ab)
'lang/long-s' is article 1 in topic HASH(0x29489be)
'google-roundup/200602' is article 1 in topic HASH(0x360e6f5)
'prog/van-der-waerden-1' is article 1 in topic HASH(0x3f2a6dd)
'math/math-se-gods' is article 1 in topic HASH(0x412b105)
'math/pow-sqrt-2' is article 1 in topic HASH(0x23ebfe4)
'aliens/dd/p22' is article 1 in topic HASH(0x878748)
I didn't see this. I saw the startup message and nothing else. I did
a bunch of very typical debugging, such as having the plugin print a
message every time story was called:
sub story {
print F "Calling 'story' (@_)\n";
...
}
Nothing. But I knew that story was being called. Was I maybe
editing the wrong file on disk? No, because I could introduce a
syntax error and the browser would happily report the resulting 500
Server Error. Fortunately, somewhere along the way I changed
open F, ">", "/tmp/topic.$>";
to
open F, ">>", "/tmp/topic.$>";
and discovered that each time I loaded the page, the plugin was run
exactly twice. When I had had >, the second run would immediately
overwrite the diagnostics from the first run.
But why was the plugin being run twice? This took quite a while to track down. At first I suspected that Blosxom was doing it, either on purpose or by accident. My instance of Blosxom is a hideous Frankenstein monster that has been cut up and reassembled and hacked and patched dozens of times since 2006 and it is full of unpleasant surprises. But the problem turned out to be quite different. Looking at the Apache server logs I saw that the browser was actually making two requests, not one:
100.14.199.174 - mjd [28/Oct/2018:18:00:49 +0000] "GET /test/2018/ HTTP/1.1" 200 213417 "-" ...
100.14.199.174 - mjd [28/Oct/2018:18:00:57 +0000] "GET /test/2018/BLOGIMGREF/horseshoe-curve-small.mp4 HTTP/1.1" 200 623 ...
Since the second request was for a nonexistent article, the story
callback wasn't invoked in the second run. So I would see the startup
message, but I didn't see any messages from the story callback.
They had been there in the first run for the first request, but that
output was immediately overwritten on the second request.
BLOGIMGREF is a tag that I include in image URLs, that expands to
whatever is the appropriate URL for the images for the particular
article it's in. This expansion is done by a different plugin, called
path2, and apparently in this case it wasn't being expanded. The
place it was being used was easy enough to find; it looked like this:
<video width="480" height="270" controls>
<source src="BLOGIMGREF/horseshoe-curve-small.mp4" type="video/mp4">
</video>
So I dug down into the path2 plugin to find out why BLOGIMGREF
wasn't being replaced by the correct URL prefix, which should have
been in a different domain entirely.
This took a very long time to track down, and I think it was totally
not my fault. When I first wrote path2 I just had it do a straight
text substitution. But at some point I had improved this to use a real
HTML parser, supplied by the Perl HTML::TreeBuilder module. This
would parse the article body and return a tree of HTML::Element
objects, which the plugin would then filter, looking for img and a
elements. The plugin would look for the magic tags and replace them
with the right URLs.
This magic tag was not in an img or an a element, so the plugin
wasn't finding it. I needed to tell the plugin to look in source
elements also. Easy fix! Except it didn't work.
Then began a tedious ten-year odyssey through the HTML::TreeBuilder
and HTML::Element modules to find out why it hadn't worked. It took
a long time because I'm good at debugging. When you lose your wallet,
you look in the most likely places first, and I know from many years
of experience what the most likely places are — usually in my
misunderstanding of the calling convention of some library I didn't
write, or my misunderstanding of what it was supposed to do; sometimes
in my own code. The downside of this is that when the wallet is in
an unlikely place it takes a really long time to find it.
The end result this time was that it wasn't in any of the usual
places. It was 100% not my fault: HTML::TreeBuilder has a bug in
its parser. For
some reason it completely ignores source elements:
perl -MHTML::TreeBuilder -e '$z = q{<source src="/media/horseshoe-curve-small.mp4" type="video/mp4"/>}; HTML::TreeBuilder->new->parse($z)->eof->elementify()->dump(\*STDERR)'
The output is:
<html> @0 (IMPLICIT)
<head> @0.0 (IMPLICIT)
<body> @0.1 (IMPLICIT)
No trace of the source element. I reported the bug, commented out
the source element in the article, and moved on. (The article was
unpublished, in part because I could never get the video to play
properly in the browser. I had been tearing my hair about over it,
but now I knew why! The BLOGIMGREF in the URL was not being
replaced! Because of a bug in the HTML parser!)
With that fixed I went back to finish the work on the topic plugin.
Now that the diagnostics were no longer being overwritten by the bogus
request for /test/2018/BLOGIMGREF/horseshoe-curve-small.mp4, I
expected to see the HASH(0x436c1d) garbage. I did, and I fixed
that. Then I expected the 'article' is article 17 in topic prog
lines to go away. They were only printed for new articles that hadn't
been seen before, and by this time every article should have been in
the %Seen database.
But no, every article on the page, every article from 2018, was being processed every time I rebuilt the page. And the topic counts were going up, up, up.
This also took a long time to track down, because again the cause was so unlikely. I must have been desperate because I finally found it by doing something like this:
if ( $Seen{ $article_id } ) {
return;
} else {
$topic_count{ $article_topic }++;
$Seen{ $article_id } = 1;
die "WTF!!" unless $Seen{ $article_id };
}
Yep, it died. Either Berkeley DB, or Perl's BerkeleyDB module, was
just flat-out not working. Both of them are ancient, and this kind of
shocking bug should have been shaken out 20 years go. WTF, indeed,
I fixed this by discarding the entire database and rebuilding it. I
needed to clean out the HASH(0x436c1d) crap anyway.
I am sick of DB files. I am never using them again. I have been bitten too many times. From now on I am doing the smart thing, by which I mean the dumb thing, the worse-is-better thing: I will read a plain text file into memory, modify it, and write out the modified version whem I am done. It will be simple to debug the code and simple to modify the database.
Well, that sucked. Usually this sort of thing is all my fault, but this time I was only maybe 10% responsible.
At least it's working again.
[ Addendum: I learned that discarding the source element is a
⸢feature⸣ of HTML::Parser. It has a list of valid HTML4 tags and by
default it ignores any element that isn't one. The maintainer won't
change the default to HTML5 because that might break backward
compatibility for people who are depending on this behavior. ]
[Other articles in category /prog/bug] permanent link
Sun, 28 Oct 2018
More about auto-generated switch-cases
Yesterday I described what I thought was a cool hack I had seen in
rsync, to try several
possible methods and then remember which one worked so as to skip the
others on future attempts. This was abetted by a different hack, for
automatically generating the case labels for the switch, which I
thought was less cool.
Simon Tatham wrote to me with a technique for compile-time generation
of case labels that I liked better. Recall that the context is:
int set_the_mtime(...) {
static int switch_step = 0;
switch (switch_step) {
#ifdef METHOD_1_MIGHT_WORK
case ???:
if (method_1_works(...))
break;
switch_step++;
/* FALLTHROUGH */
#endif
#ifdef METHOD_2_MIGHT_WORK
case ???:
if (method_2_works(...))
break;
switch_step++;
/* FALLTHROUGH */
#endif
... etc. ...
}
return 1;
}
M. Tatham suggested this:
#define NEXT_CASE switch_step = __LINE__; case __LINE__
You use it like this:
int set_the_mtime(...) {
static int switch_step = 0;
switch (switch_step) {
default:
#ifdef METHOD_1_MIGHT_WORK
NEXT_CASE:
if (method_1_works(...))
break;
/* FALLTHROUGH */
#endif
#ifdef METHOD_2_MIGHT_WORK
NEXT_CASE:
if (method_2_works(...))
break;
/* FALLTHROUGH */
#endif
... etc. ...
}
return 1;
}
The case labels are no longer consecutive, but that doesn't matter;
all that is needed is for them to be distinct. Nobody is ever going
to see them except the compiler. M. Tatham called this
“the case __LINE__ trick”, which suggested to me that it was
generally known. But it was new to me.
One possible drawback of this method is that if the file contains more
than 255 lines, the case labels will not fit in a single byte. The
ultimate effect of this depends on how the compiler handles switch.
It might be compiled into a jump table with !!2^{16}!! entries, which
would only be a problem if you had to run your program in 1986. Or it
might be compiled to an if-else tree, or something else we don't want.
Still, it seems like a reasonable bet.
You could use case 0: at the beginning instead of default:, but
that's not as much fun. M. Tatham observes that it's one of very few
situations in which it makes sense not to put default: last. He
says this is the only other one he knows:
switch (month) {
case SEPTEMBER:
case APRIL:
case JUNE:
case NOVEMBER:
days = 30;
break;
default:
days = 31;
break;
case FEBRUARY:
days = 28;
if (leap_year)
days = 29;
break;
}
Addendum 20181029: Several people have asked for an explanation of why
the default is in the middle of the last switch. It follows the
pattern of a very well-known mnemonic
poem that goes
Thirty days has September,
April, June and November.
All the rest have thirty-one
Except February, it's a different one:
It has 28 days clear,
and 29 each leap year.
Wikipedia says:
[The poem has] been called “one of the most popular and oft-repeated verses in the English language” and “probably the only sixteenth-century poem most ordinary citizens know by heart”.
[Other articles in category /prog] permanent link
Sat, 27 Oct 2018
A fun optimization trick from rsync
I was looking at the rsync source code today and I saw a neat trick
I'd never seen before. It wants to try to set the mtime on a file,
and there are several methods that might work, but it doesn't know
which. So it tries them in sequence, and then it remembers which one
worked and uses that method on subsequent calls:
int set_the_mtime(...) {
static int switch_step = 0;
switch (switch_step) {
case 0:
if (method_0_works(...))
break;
switch_step++;
/* FALLTHROUGH */
case 1:
if (method_1_works(...))
break;
switch_step++;
/* FALLTHROUGH */
case 2:
...
case 17:
if (method_17_works(...))
break;
return -1; /* ultimate failure */
}
return 0; /* success */
}
The key item here is the static switch_step variable. The first
time the function is called, its value is 0 and the switch starts at
case 0. If methods 0 through 7 all fail and method 8 succeeds,
switch_step will have been set to 8, and on subsequent calls to the
function the switch will jump immediately to case 8.
The actual code is a little more sophisticated than this. The list of
cases is built depending on the setting of several compile-time config
flags, so that the code that is compiled only includes the methods
that are actually callable. Calling one of the methods can produce
three distinguishable results: success, real failure (because of
permission problems or some such), or a sort of fake failure
(ENOSYS) that only means that the underlying syscall is
unimplemented. This third type of result is the one where it makes
sense to try another method. So the cases actually look like this:
case 7:
if (method_7_works(...))
break;
if (errno != ENOSYS)
return -1; /* real failure */
switch_step++;
/* FALLTHROUGH */
On top of this there's another trick: since the various cases are
conditionally compiled depending on the config flags, we don't know
ahead of time which ones will be included. So the case labels
themselves are generated at compile time this way:
#include "case_N.h"
if (method_7_works(...))
break;
...
#include "case_N.h"
if (method_8_works(...))
break;
...
The first time we #include "case_N.h", it turns into case 0:; the
second time, it turns into case 1:, and so on:
#if !defined CASE_N_STATE_0
#define CASE_N_STATE_0
case 0:
#elif !defined CASE_N_STATE_1
#define CASE_N_STATE_1
case 1:
...
#else
#error Need to add more case statements!
#endif
Unfortunately you can only use this trick one switch per file.
Although I suppose if you really wanted to reuse it you could make a
reset_case_N.h file which would contain
#undef CASE_N_STATE_0
#undef CASE_N_STATE_1
...
[ Addendum 20181028: Simon Tatham brought up a technique for
generating the case labels that we agree is
better than what rsync did. ]
[Other articles in category /prog] permanent link
Fri, 26 Oct 2018
A snide addendum about implicit typeclass instances
In an earlier article I demanded:
Maybe someone can explain to me why this is a useful behavior, and then explain why it is so useful that it should happen automatically …
“This” being that instead of raising a type error, Haskell quietly accepts this nonsense:
fmap ("super"++) (++"weasel")
but it clutches its pearls and faints in horror when confronted with this expression:
fmap ("super"++) "weasel"
Nobody did explain this.
But I imagined
someone earnestly explaining: “Okay, but in the first case, the
(++"weasel") is interpreted as a value in the environment functor,
so fmap is resolved to its the environment instance, which is (.).
That doesn't happen in the second example.”
Yeah, yeah, I know that. Hey, you know what else is a functor? The
identity functor. If fmap can be quietly demoted to its (->) e
instance, why can't it also be quietly demoted to its Id instance,
which is ($), so that fmap ("super"++) "weasel" can quietly
produce "superweasel"?
I understand this is a terrible idea. To be clear, what I want is for it to collapse on the divan for both expressions. Pearl-clutching is Haskell's finest feature and greatest strength, and it should do it whenever possible.
[Other articles in category /prog/haskell] permanent link
Tue, 23 Oct 2018
Getting Applicatives from Monads and “>>=” from “join”
I complained recently about GHC not being able to infer an
Applicative instance from a type that already has a Monad
instance, and there is a related complaint that the Monad instance
must define >>=. In some type classes, you get a choice about
what to define, and then the rest of the functions are built from the
ones you provided. To take a particular simple example, with Eq
you have the choice of defining == or /=, and if you omit one
Haskell will construct the other for you. It could do this with >>=
and join, but it doesn't, for technical reasons I don't
understand
[1]
[2]
[3].
But both of these problems can be worked around. If I have a Monad instance, it seems to work just fine if I say:
instance Applicative Tree where
pure = return
fs <*> xs = do
f <- fs
x <- xs
return (f x)
Where this code is completely canned, the same for every Monad.
And if I know join but not >>=, it seems to work just fine if I say:
instance Monad Tree where
return = ...
x >>= f = join (fmap f x) where
join tt = ...
I suppose these might faul foul of whatever problem is being described in the documents I linked above. But I'll either find out, or I won't, and either way is a good outcome.
[ Addendum: Vaibhav Sagar points out that my definition of <*> above
is identical to that of Control.Monad.ap, so that instead of
defining <*> from scratch, I could have imported ap and then
written <*> = ap. ]
[ Addendum 20221021: There are actually two definitions of <*> that will work. [1] [2] ]
[Other articles in category /prog/haskell] permanent link
Mon, 22 Oct 2018While I was writing up last week's long article about Traversable, I wrote this stuff about Applicative also. It's part of the story but I wasn't sure how to work it into the other narrative, so I took it out and left a remark that “maybe I'll publish a writeup of that later”. This is a disorganized collection of loosely-related paragraphs on that topic.
It concerns my attempts to create various class instance definitions for the following type:
data Tree a = Con a | Add (Tree a) (Tree a)
deriving (Eq, Show)
which notionally represents a type of very simple expression tree over values of type a.
I need some function for making Trees that isn't too
simple or too complicated, and I went with:
h n | n < 2 = Con n
h n = if even n then Add (h (n `div` 2)) (h (n `div` 2))
else Add (Con 1) (h (n - 1))
which builds trees like these:
2 = 1 + 1
3 = 1 + (1 + 1)
4 = (1 + 1) + (1 + 1)
5 = 1 + ((1 + 1) + (1 + 1))
6 = (1 + (1 + 1)) + (1 + (1 + 1))
7 = 1 + (1 + (1 + 1)) + (1 + (1 + 1))
8 = ((1 + 1) + (1 + 1)) + ((1 + 1) + (1 + 1))
Now I wanted to traverse h [1,2,3] but I couldn't do that because I
didn't have an Applicative instance for Tree. I had been putting off
dealing with this, but since Traversable doesn't really make sense without
Applicative I thought the day of reckoning would come. Here it was. Now is
when I learn how to fix all my broken monads.
To define an Applicative instance for Tree I needed to define pure, which
is obvious (it's just Con) and <*> which would apply a tree of
functions to a tree of inputs to get a tree of results. What the hell
does that mean?
Well, I can kinda make sense of it. If I apply one function to a
tree of inputs, that's straightforward, it's just fmap, and I get a
tree of results. Suppose I have a tree of functions, and I replace
the function at each leaf with the tree of its function's results.
Then I have a tree of trees. But a tree that has trees at its leaves
is just a tree. So I could write some tree-flattening function that
builds the tree of trees, then flattens out the type. In fact this is just
join that I already know from Monad world.
The corresponding operation for lists takes a list of lists
and flattens them into a single list.) Flattening a tree is quite easy to do:
join (Con ta) = ta
join (Add ttx tty) = Add (join ttx) (join tty)
and since this is enough to define a Monad instance for Tree I
suppose it is enough to get an Applicative instance also, since every Monad
is an Applicative. Haskell makes this a pain. It should be able to infer
the Applicative from this, and I wasn't clever enough to do it myself. And
there ought to be some formulaic way to get <*> from >>= and
join and fmap, the way you can get join from >>=:
join = (>>= id)
but I couldn't find out what it was. This gets back to my original
complaint: Haskell now wants every Monad instance to be an instance
of Applicative, but if I give it the fmap and the join and the return
it ought to be able to figure out the Applicative instance itself instead of
refusing to compile my program. Okay, fine, whatever. Haskell's
gonna Hask.
(I later realized that building <*> when you have a Monad instance
is easy once you know the recipe; it's just:
fs <*> xs = do
f <- fs
x <- xs
return (f x)
So again, why can't GHC infer <*> from my Monad instance, maybe
with a nonfatal warning?
Warning: No Applicative instance provided for Tree; deriving one from Monad
This is not a rhetorical question.)
(Side note: it seems like there ought to be a nice short abbreviation
of the (<*>) function above, the way one can write join = (>>=
id). I sought one but did not find any. One can eliminate the do
notation to obtain the expression:
fs <*> xs = fs >>= \f -> xs >>= \x -> return (f x)
but that is not any help unless we can simplify the expression with
the usual tricks, such as combinatory logic and η-conversion. I was
not able to do this, and the automatic pointfree
converter produced
(. ((. (return .)) . (>>=))) . (>>=) ARGH MY EYES.)
Anyway I did eventually figure out my <*> function for trees by
breaking the left side into cases. When the tree of functions is Con
f it's a single function and we can just use fmap to map it over
the input tree:
(Con f) <*> tv = fmap f tv
And when it's bigger than that we can break it up recursively:
(Add lt rt) <*> tv = Add (lt <*> tv) (rt <*> tv)
Once this is written it seemed a little embarrassing that it took me so long to figure out what it meant but this kind of thing always seems easier from the far side of the fence. It's hard to understand until you understand it.
Actually that wasn't quite the <*> I wanted. Say we have a tree of
functions and a tree of arguments.

Add (Con (* 10))
(Con (* 100))
Add (Add (Con 3) (Con 4)) (Con 5)I can map the whole tree of functions over each single leaf on the right, like this:
Add (Add (Add (Con 30) (Con 300))
(Add (Con 40) (Con 400)))
(Add (Con 50) (Con 500))
or I can map each function over the whole tree on the right, like this:
Add
(Add (Add (Con 30) (Con 40)) (Con 50))
(Add (Add (Con 300) (Con 400)) (Con 500))The code I showed earlier does the second of those. You can see it from
the fmap f tv expression, which takes a single function and maps it over a whole
tree of values. I had actually wanted the other one, but there isn't
anything quite like fmap for that. I was busy trying to
understand Applicative and I was afraid if I got distracted trying to invent
a reverse fmap I might lose the thread. This happens to me a lot
with Haskell. I did eventually go back and figure it out. The
reverse fmap is
pamf fs v = fmap ($ v) fs -- good
or
pamf = flip (fmap . flip id) -- yuck
Now there's a simple answer to this which occurs to me now that I
didn't think of before, but I'm going to proceed with how I planned to
do it before, with pamf. The <*> that I didn't want looked like this:
(Con f) <*> tv = fmap f tv
(Add lt rt) <*> tv = Add (lt <*> tv) (rt <*> tv)
I need to do the main recursion on the values argument instead of on the functions argument:
tf <*> (Con v) = pamf tf v
where pamf fs v = fmap ($ v) fs
tf <*> (Add lv rv) = Add (tf <*> lv) (tf <*> rv)
(This is an interesting example: usually the base case is trivial and the recursive clause is harder to write, but this time it's the base case that's not perfectly straightforward.)
Anyway, this worked, but there was an easier solution at hand. The difference between the first version and the second is exactly the same as the difference between
fs <*> xs = do
f <- fs
x <- xs
return (f x)
and
fs <*> xs = do
x <- xs
f <- fs
return (f x)
Digging deeper into why this worked this way was interesting, but it's bed time, so I'm going to cut the scroll here.
[ Addendum 20221021: More about the two versions of <*> and a third version that doesn't work. ]
[Other articles in category /prog/haskell] permanent link
Sat, 20 Oct 2018
I struggle to understand Traversable
Haskell evolved a lot since the last time I seriously wrote any
Haskell code, so much so that all my old programs broke. My Monad
instances don't compile any more because I'm no longer allowed to
have a monad which isn't also an instance of Applicative. Last time I used
Haskell, Applicative wasn't even a thing. I had read the McBride and
Paterson paper that introduced applicative functors, but that was
years ago, and I didn't remember any of the details. (In fact, while
writing this article, I realized that the paper I read was a preprint,
and I probably read it before it was published, in 2008.) So to
resuscitate my old code I had to implement a bunch of <*> functions
and since I didn't really understand what it was supposed to be doing
I couldn't do that. It was a very annoying experience.
Anyway I got that more or less under control (maybe I'll publish a
writeup of that later) and moved on to Traversable which, I hadn't realized
before, was also introduced in that same paper. (In the
prepublication version, Traversable had been given the unmemorable name
IFunctor.) I had casually looked into this several times in the
last few years but I never found anything enlightening. A Traversable is a
functor (which must also implement Foldable, but let's pass over that
for now, no pun intended) that implements a traverse method with the
following signature:
traverse :: Applicative f => (a -> f b) -> t a -> f (t b)
The traversable functor itself here is t. The f thing is an
appurtenance. Often one looks at the type of some function and says “Oh, that's what
that does”, but I did not get any understanding from this signature.
The first thing to try here is to make it less abstract. I was thinking about Traversable this time because I thought I might want it for a certain type of tree structure I was working with. So I defined an even simpler tree structure:
data Tree a = Con a | Add (Tree a) (Tree a)
deriving (Eq, Show)
Defining a bunch of other cases wouldn't add anything to my understanding, and it would make it take longer to try stuff, so I really want to use the simplest possible example here. And this is it: one base case, one recursive case.
Then I tried to make this type it into a Traversable instance. First we need it to be a Functor, which is totally straightforward:
instance Functor Tree where
fmap f (Con a) = Con (f a)
fmap f (Add x y) = Add (fmap f x) (fmap f y)
Then we need it to be a Foldable, which means it needs to provide a
version of foldr. The old-fashioned foldr was
foldr :: (a -> b -> b) -> b -> [a] -> b
but these days the list functor in the third place has been generalized:
foldr :: Foldable f => (a -> b -> b) -> b -> f a -> b
The idea is that foldr fn collapses a list of as into a single b
value by feeding in the as one at a time. Each time, foldr takes
the previous b and the current a and constructs a new b. The
second argument is the initial value of b.
Another way to think about it is that every list has the form
e1 : e2 : .... : []
and foldr fn b applied to this list replaces the (:) calls with fn
and the trailing [] with b, giving me
e1 `f` e2 `f` .... `f` b
The canonical examples for lists are:
sum = foldr (+) 0
(add up the elements, starting with zero) and
length = foldr (\_ -> (+ 1)) 0
(ignore the elements, adding 1 to the total each time, starting with
zero). Also foldr (:) [] is the identity function for lists because
it replaces the (:) calls with (:) and the trailing [] with [].
Anyway for Tree it looks like this:
instance Foldable Tree where
foldr f b (Con a) = f a b
foldr f b (Add x y) = (foldr f) (foldr f b x) y
The Con clause says to take the constant value and combine it with
the default total. The Add clause says to first fold up the
left-side subtree x to a single value, then use that as the initial
value for folding up the right-side subtree y, so everything gets
all folded up together. (We could of course do the right subtree
before the left; the results would be different but just as good.)
I didn't write this off the top of my head, I got it by following the types, like this:
In the first clause
foldr f b (Con a) = ???we have a function
fthat wants anavalue and abvalue, and we have both anaand ab, so put the tabs in the slots.In the second clause
foldr f b (Add x y) = ???fneeds anavalue and none is available, so we can't usefby itself. We can only use it recursively viafoldr. So forgetf, we will only be dealing only withfoldr f, which has typeb -> Tree a -> b. We need to apply this to abvalue and the only one we have isb, and then we need to apply that to one of the subtrees, sayx, and thus we have synthesized thefoldr f b xsubexpression. Then pretty much the same process gets us the rest of it: we need aband the only one we have now isfoldr f b x, and then we need another tree and the only one we haven't used isy.
It turns out it is easier and more straightforward to write foldMap
instead, but I didn't know that at the time. I won't go into it
further because I have already digressed enough. The preliminaries
are done, we can finally get on to the thing I wanted, the Traversable:
instance Traversable Tree where
traverse = ....
and here I was stumped. What is this supposed to actually do?
For our Tree functor it has this signature:
traverse :: Applicative f => (a -> f b) -> Tree a -> f (Tree b)
Okay, a function a -> f b I understand, it turns each tree leaf
value into a list or something, so at each point of the tree it gets
out a list of bs, and it potentially has one of those for each item
in the input tree. But how the hell do I turn a tree of lists into
a single list of Tree b? (The answer is that the secret sauce is
in the Applicative, but I didn't understand that yet.)
I scratched my head and read a bunch of different explanations and none of them helped. All the descriptions I found were in either prose or mathematics and I still couldn't figure out what it was for. Finally I just wrote a bunch of examples and at last the light came on. I'm going to show you the examples and maybe the light will come on for you too.
We need two Traversable functors to use as examples. We don't have a Traversable
implementation for Tree yet so we can't use that. When I think of
functors, the first two I always think of are List and Maybe, so
we'll use those.
> traverse (\n -> [1..n]) Nothing
[Nothing]
> traverse (\n -> [1..n]) (Just 3)
[Just 1,Just 2,Just 3]
Okay, I think I could have guessed that just from the types. And
going the other way is not very interesting because the output, being
a Maybe, does not have that much information in it.
> let f x = if even x then Just (x `div` 2) else Nothing
If the !!x!! is even then the result is just half of !!x!!, and otherwise the division by 2 “fails” and the result is nothing. Now:
> traverse f [ 1, 2, 3, 4 ]
Nothing
> traverse f [ 10, 4, 18 ]
Just [5,2,9]
It took me a few examples to figure out what was going on here: When
all the list elements are even, the result is Just a list of half of
each. But if any of the elements is odd, that spoils the whole result
and we get Nothing. (traverse f [] is Just [] as one would
expect.)
That pretty much exhausts what can be done with lists and maybes. Now
I have two choices about where to go next: I could try making both
functors List, or I could use a different functor entirely. (Making
both Maybe seemed like a nonstarter.) Using List twice seemed
confusing, and when I tried it I could kinda see what it was doing but
I didn't understand why. So I took a third choice: I worked up a Traversable
instance for Tree just by following the types even though I didn't
understand what it ought to be doing. I thought I'd at least see if I
could get the easy clause:
traverse :: Applicative f => (a -> f b) -> Tree a -> f (Tree b)
instance Traversable Tree where
traverse fn (Con a) = ...
In the ... I have fn :: a -> f b and I have at hand a single a. I need to
construct a Tree b. The only way to get a b is to apply fn to
it, but this gets me an f b and I need f (Tree b). How do I get the
Tree in there? Well, that's what Con is for, getting Tree in
there, it turns a t into Tree t. But how do I do that inside of
f? I tinkered around a little bit and eventually found
traverse fn (Con a) = Con <$> (fn a)
which not only type checks but looks like it could even be correct.
So now I have a motto for what <$> is about: if I have some
function, but I want to use it inside of some applicative functor
f, I can apply it with <$> instead of with $.
Which, now that I have said it myself, I realize it is exactly what
everyone else was trying to tell me all along: normal function
application takes an a -> b and applies to to an a giving a b.
Applicative application takes an f (a -> b) and applies it to an f a
giving an f b. That's what applicative functors are all about,
doing stuff inside of f.
Okay, I can listen all day to an explanation of what an electric drill does, but until I hold it in my hand and drill some holes I don't really understand.
Encouraged, I tried the hard clause:
traverse fn (Add x y) = ...
and this time I had a roadmap to follow:
traverse fn (Add x y) = Add <$> ...
The Con clause had fn a at that point to produce an f b but that won't
work here because we don't have an a, we have a whole Tree a, and we
don't need an f b, we need an f (Tree b). Oh, no problem,
traverse fn supposedly turns a Tree a into an f (Tree b), which
is just what we want.
And it makes sense to have a recursive call to traverse because this is the
recursive part of the recursive data structure:
traverse fn (Add x y) = Add <$> (traverse fn x) ...
Clearly traverse fn y is going to have to get in there somehow, and
since the pattern for all the applicative functor stuff is
f <$> ... <*> ... <*> ...
let's try that:
traverse fn (Add x y) = Add <$> (traverse fn x) <*> (traverse fn y)
This looks plausible. It compiles, so it must be doing something.
Partial victory! But what is it doing? We can run it and see, which
was the whole point of an exercise: work up a Traversable instance for Tree
so that I can figure out what Traversable is about.
Here are some example trees:
t1 = Con 3 -- 3
t2 = Add (Con 3) (Con 4) -- 3 + 4
t3 = Add (Add (Con 3) (Con 4)) (Con 2) -- (3 + 4) + 2
(I also tried Add (Con 3) (Add (Con 4) (Con 2)) but it did not
contribute any new insights so I will leave it out of this article.)
First we'll try Maybe. We still have that f function from before:
f x = if even x then Just (x `div` 2) else Nothing
but traverse f t1, traverse f t2, and traverse f t3 only produce
Nothing, presumably because of the odd numbers in the trees. One
odd number spoils the whole thing, just like in a list.
So try:
traverse f (Add (Add (Con 10) (Con 4)) (Con 18))
which yields:
Just (Add (Add (Con 5) (Con 2)) (Con 9))
It keeps the existing structure, and applies f at each value
point, just like fmap, except that if f ever returns Nothing
the whole computation is spoiled and we get Nothing. This is
just like what traverse f was doing on lists.
But where does that spoilage behavior come from exactly? It comes
from the overloaded behavior of <*> in the Applicative instance of Maybe:
(Just f) <*> (Just x) = Just (f x)
Nothing <*> _ = Nothing
_ <*> Nothing = Nothing
Once we get a Nothing in there at any point, the Nothing takes
over and we can't get rid of it again.
I think that's one way to think of traverse: it transforms each
value in some container, just like fmap, except that where fmap
makes all its transformations independently, and reassembles the exact
same structure, with traverse the reassembly is done with the
special Applicative semantics. For Maybe that means “oh, and if at any
point you get Nothing, just give up”.
Now let's try the next-simplest Applicative, which is List. Say,
g n = [ 1 .. n ]
Now traverse g (Con 3) is [Con 1,Con 2,Con 3] which is not exactly
a surprise but traverse g (Add (Con 3) (Con 4)) is something that
required thinking about:
[Add (Con 1) (Con 1),
Add (Con 1) (Con 2),
Add (Con 1) (Con 3),
Add (Con 1) (Con 4),
Add (Con 2) (Con 1),
Add (Con 2) (Con 2),
Add (Con 2) (Con 3),
Add (Con 2) (Con 4),
Add (Con 3) (Con 1),
Add (Con 3) (Con 2),
Add (Con 3) (Con 3),
Add (Con 3) (Con 4)]
This is where the light finally went on for me. Instead of thinking
of lists as lists, I should be thinking of them as choices. A list
like [ "soup", "salad" ] means that I can choose soup or salad, but
not both. A function g :: a -> [b] says, in restaurant a, what
bs are on the menu.
The g function says what is on the menu at each node. If a node has
the number 4, I am allowed to choose any of [1,2,3,4], but if it has
the number 3 then the choice 4 is off the menu and I can choose only
from [1,2,3].
Traversing g over a Tree means, at each leaf, I am handed a menu,
and I make a choice for what goes at that leaf. Then the result of
traverse g is a complete menu of all the possible complete trees I
could construct.
Now I finally understand how the t and the f switch places in
traverse :: Applicative f => (a -> f b) -> t a -> f (t b)
I asked “how the hell do I turn a tree of lists into a single list
of Tree b”? And that's the answer: each list is a local menu of
dishes available at one leaf, and the result list is the global menu
of the complete dinners available over the entire tree.
Okay! And indeed traverse g (Add (Add (Con 3) (Con 4)) (Con 2)) has
24 items, starting
Add (Add (Con 1) (Con 1)) (Con 1)
Add (Add (Con 1) (Con 1)) (Con 2)
Add (Add (Con 1) (Con 2)) (Con 1)
...
and ending
Add (Add (Con 3) (Con 4)) (Con 1)
Add (Add (Con 3) (Con 4)) (Con 2)
That was traversing a list function over a Tree. What if I go the
other way? I would need an Applicative instance for Tree and I didn't
really understand Applicative yet so that wasn't going to happen for a
while. I know I can't really understand Traversable without understanding
Applicative first but I wanted to postpone the day of reckoning as long as
possible.
What other functors do I know? One easy one is the functor that takes
type a and turns it into type (String, a). Haskell even has a
built-in Applicative instance for this, so I tried it:
> traverse (\x -> ("foo", x)) [1..3]
("foofoofoo",[1,2,3])
> traverse (\x -> ("foo", x*x)) [1,5,2,3]
("foofoofoofoo",[1,25,4,9])
Huh, I don't know what I was expecting but I think that wouldn't have
been it. But I figured out what was going on: the built-in Applicative
instance for the a -> (String, a) functor just concatenates the
strings. In general it is defined on a -> (m, b) whenever m is a
monoid, and it does fmap on the right component and uses monoid
concatenation on the left component. So I can use integers instead of
strings, and it will add the integers instead of concatenating the
strings. Except no, it won't, because there are several ways to make
integers into a monoid, but each type can only have one kind of
Monoid operations, and if one was wired in it might not be the one I
want. So instead they define a bunch of types that are all integers
in obvious disguises, just labels stuck on them that say “I am not an
integer, I am a duck”; “I am not an integer, I am a potato”. Then
they define different overloadings for “ducks” and “potatoes”. Then
if I want the integers to get added up I can put duck labels on my
integers and if I want them to be multiplied I can stick potato labels
on instead. It looks like this:
import Data.Monoid
h n = (Sum 1, n*10)
Sum is the duck label. When it needs to combine two
ducks, it will add the integers:
> traverse h [5,29,83]
(Sum {getSum = 3},[50,290,830])
But if we wanted it to multiply instead we could use the potato label,
which is called Data.Monoid.Product:
> traverse (\n -> (Data.Monoid.Product 7, 10*n)) [5,29,83]
(Product {getProduct = 343}, [50,290,830])
There are three leaves, so we multiply three sevens and get 343.
Or we could do the same sort of thing on a Tree:
> traverse (\n -> (Data.Monoid.Product n, 10*n)) (Add (Con 2) (Add (Con 3) (Con 4)))
(Product {getProduct = 24}, Add (Con 20) (Add (Con 30) (Con 40)))
Here instead of multiplying together a bunch of sevens we multiply together the leaf values themselves.
The McBride and Paterson paper spends a couple of pages talking about
traversals over monoids, and when I saw the example above it started
to make more sense to me. And their ZipList example became clearer
too. Remember when we had a function that gave us a menu at every
leaf of a tree, and traverse-ing that function over a tree gave us a
menu of possible trees?
> traverse (\n -> [1,n,n*n]) (Add (Con 2) (Con 3))
[Add (Con 1) (Con 1),
Add (Con 1) (Con 3),
Add (Con 1) (Con 9),
Add (Con 2) (Con 1),
Add (Con 2) (Con 3),
Add (Con 2) (Con 9),
Add (Con 4) (Con 1),
Add (Con 4) (Con 3),
Add (Con 4) (Con 9)]
There's another useful way to traverse a list function. Instead of taking each choice at each leaf we make a single choice ahead of time about whether we'll take the first, second, or third menu item, and then we take that item every time:
> traverse (\n -> Control.Applicative.ZipList [1,n,n*n]) (Add (Con 2) (Con 3))
ZipList {getZipList = [Add (Con 1) (Con 1),
Add (Con 2) (Con 3),
Add (Con 4) (Con 9)]}
There's a built-in instance for Either a b also. It's a lot like
Maybe. Right is like Just and Left is like Nothing. If all
the sub-results are Right y then it rebuilds the structure with all
the ys and gives back Right (structure). But if any of the
sub-results is Left x then the computation is spoiled and it gives
back the first Left x. For example:
> traverse (\x -> if even x then Left (x `div` 2) else Right (x * 10)) [3,17,23,9]
Right [30,170,230,90]
> traverse (\x -> if even x then Left (x `div` 2) else Right (x * 10)) [3,17,22,9]
Left 11
Okay, I think I got it.
Now I just have to drill some more holes.
[Other articles in category /prog/haskell] permanent link
Mon, 15 Oct 2018
'The' reader monad does not exist
Reading over my recent article complaining about the environment functor I realized there's yet another terminology problem that makes the discussion unnecessarily confusing. “The” environment functor isn't unique. There is a family of environment functors, one for each possible environment type e. If g is the environment functor at type e, a value of type g t is a function e → t. But e could be anything and if g and h are environment functors at two different types e and e’ they are of course different functors.
This is even obvious from the definition:
data Environ e t = Env (e -> t)
instance Functor (Environ e) where
fmap f (Env x) = Env $ \e -> f (x e)
The functor isn't Environ, it's Environ e, and the functor
instance declaration, as it says on line 2. (It seems to me that the
notation is missing a universal quantifier somewhere, but I'm not
going to open that issue.)
We should speak of Environ e as an environment functor, not
the environment functor. So for example instead of:
When operating in the environment functor,
fmaphas the type(a -> b) -> g a -> g b
I should have said:
When operating in an environment functor,
fmaphas the type(a -> b) -> g a -> g b
And instead of:
A function
p -> qis aqparcel in the environment functor
I should have said:
A function
p -> qis aqparcel in an environment functor
or
A function
p -> qis aqparcel in the environment functor atp
although I'm not sure I like the way the prepositions are proliferating there.
The same issue affects ⸢the⸣ reader monad, ⸢the⸣ state monad, and many others.
I'm beginning to find remarkable how much basic terminology Haskell is missing or gets wrong. Mathematicians have a very keen appreciation of the importance of specific and precise terminology, and you'd think this would have filtered into the Haskell world. People are forever complaining that Haskell uses unfamiliar terms like “functor”, and the community's response is (properly, I think) that these terms are pre-existing and there is no point to inventing a new term that will be just as unfamiliar, or, worse, lure people into thinking that the know what it means when they don't. You don't want to call a functor a “container”, says the argument, because many functors (environment functors for example) are nothing at all like containers. I think this is wise.
But having planted their flag on that hill, the Haskell folks don't
then use their own terminology correctly. I complained years
ago that the term
“monad” was used interchangeably for four subtly different concepts,
and here we actually have a fifth. I pointed out that in the case of
Environment e t, common usage refers to both Environment e and
Environment e t as monads, and only the first is correct. But when
people say “the environment monad” they mean that Environment itself
is a monad, which it is not.
[Other articles in category /prog/haskell] permanent link
Thu, 11 Oct 2018Is there any good terminology for a value of type
f awhenfis an arbitrary functor? I will try calling anf tvalue a “tparcel” and see how that works.
The more I think about “parcel” the happier I am with it. It strongly
suggests container types, of course, so that a t parcel might be a
boxful of ts. But it also hints at some other possible situations:
- You might open the parcel and find it empty. (
Maybe t) - You might open the parcel and find, instead of the
tyou expected, a surprising prank snake. (Either ErrorMessage t) - You might open the parcel and find that your
thas been shipped with assembly required. (env -> t) - The parcel might explode when you open it. (
IO t) - And, of course, a burrito is a sort of parcel of meat and beans.
I coined “parcel” thinking that one would want different terminology
for values of type f t depending on whether f was a functor
(“parcel”) or also a monad (“mote”). Of course every mote is a
parcel, but not always vice versa. Now I'm not sure that both terms
are needed. Non-monadic functors are unusual, and non-applicative
functors rare, so perhaps one term will do for all three.
[Other articles in category /prog/haskell] permanent link
I hate the environment functor
Here we have the well-known fmap function:
fmap :: Functor f => (a -> b) -> f a -> f b
It takes a single function and a (collection of input values / decorated input value / something something input value) and produces a (collection of output values / decorated output value / something something output value).
Yow, that's not going to work. Is there any good terminology for a
value of type f a when f is an arbitrary functor? A while back I
discussed a similar
problem and suggested
the term “mote” for a value in a monadic type. I will try calling an
f t value a “t parcel and see how that works. So
[t], Maybe t, and IO t are all examples of t parcels, in
various functors.
Starting over then. Here we have the well-known fmap function:
fmap :: Functor f => (a -> b) -> f a -> f b
It takes a single function, and an a parcel, and produces a b
parcel, by applying the function independently to the a values in
the parcel.
Here is a sort of reversed version of fmap that I call pamf:
pamf :: Functor f => f (a -> b) -> a -> f b
It takes a parcel of functions, and a single input and produces a
parcel of outputs, by applying each function in the parcel
independently to the single a value. It can be defined in terms of
fmap:
pamf fs a = fmap ($ a) fs
So far so good. Now I ask you to predict the type of
pamf fmap
Certainly it should start out with
pamf fmap :: (Functor f, Functor g) => ...
because the pamf and the fmap might be operating in two different
functors, right? Indeed, if I compose the functions the other way
around, fmap pamf, the type does begin this way; it is:
(Functor f, Functor g) => f (g (a -> b)) -> f (a -> g b)
The f here is the functor in which fmap operates, and the g is
the functor in which pamf is operating. In general fmap takes an
arbitrary function
a -> b
and lifts it to a new function that operates in the f functor:
f a -> f b
Here it has taken pamf, which is a function
g (a -> b) -> (a -> g b)
and lifted it to a new function that operates in the f functor:
f (g (a -> b)) -> f (a -> g b)
This is complicated but straightforward. Okay, that was fmap pamf.
What about pamf fmap though? The computed type is
pamf fmap :: Functor f => f a -> (a -> b) -> f b
and when I saw this I said “What. Where did g go? What happened to
g?”
Then I paused and for a while and said “… I bet it's that goddamn environment thing again.” Yep, that's what it was. It's the environment functor, always turning up where I don't want it and least expect it, like that one guy we all went to college with. The environment functor, by the way, is yet another one of those things that Haskell ought to have a standard name for, but doesn't. The phrase “the reader monad” is fairly common, but here I only want the functor part of the monad. And people variously say “reader monad”, “environment monad”, and “evaluation monad” to mean the same thing. In this article, it will be the environment functor.
Here's what happened. Here are fmap and pamf again:
fmap :: Functor f => (p -> q) -> f p -> f q
pamf :: Functor g => g (a -> b) -> a -> g b
The first argument to pamf should be a parcel in the g functor.
But fmap is not a parcel, so pamf fmap will be a type error,
right? Wrong! If you are committed enough, there is a way to
construe any function as a parcel. A function p -> q is a q
parcel in the environment functor. Say that g denotes an
environment functor. In this functor, a parcel of type g t is a
function which consults an “environment” of type e and yields a
result of type t. That is, $$g\ t \equiv e \to t.$$
When operating in the environment functor, fmap has the type (a ->
b) -> g a -> g b, which is shorthand for (a -> b) -> (e -> a) -> (e
-> b). This instance of fmap is defined this way:
fmap f x = \e -> f (x e)
or shorter and more mysteriously
fmap = (.)
which follows by η-reduction, something Haskell enthusiasts never seem to get enough of.
In fmap f x, the x isn't the actual value to give to f; instead
it's a parcel, as it always is with fmap. In the context of the
environment functor, x is a function that consults the environment
e and returns an a. The result of fmap f x is a new parcel: it
uses x to consult the supplied environment for a value of type a,
which it then feeds to f to get the required value of type b.
In the application pamf fmap, the left side pamf wants fmap to
be a parcel. But it's not a parcel, it's a function. So, type error,
right? No! Any function is a parcel if you want it to be, it's a
parcel in the environment functor! And fmap is a function:
fmap :: Functor f => (p -> q) -> f p -> f q
so it can be understood as a parcel in the environment functor, where
the environment e has type p -> q. Then pamf is operating in
this environment functor, so $$g\ t = (p \to q) \to t.$$ A g t parcel
is a function that consults an “environment” of type p -> q and
somehow produces a t value. (Haskell folks, who are obsessed with
currying all the things, will write this as the
nearly unreadable g = ((->) (p -> q)).)
We wanted pamf to have this type:
pamf :: Functor g => g (a -> b) -> a -> g b
and since Haskell has decided that g must be the environment functor
with !!g\ x \equiv (p \to q) \to x!!,
this is an abbreviation for:
pamf :: ((p -> q) -> (a -> b)) -> a -> ((p -> q) -> b)
To apply this to fmap, we have to unify the type of pamf's
argument, which is (p -> q) -> (a -> b), and the type of fmap,
which is (p -> q) -> (f p -> f q). Then !!a\equiv f\ p!! and !!b
\equiv f\ q!!, so the result of pamf fmap is
pamf fmap :: Functor f => f p -> ((p -> q) -> f q)
Where did g go? It was specialized to mean the environment functor
((->) (p -> q)), so it's gone.
The funny thing about the type of pamf fmap is that it is exactly
the type of flip fmap, which is fmap with the order of its two
arguments reversed:
(flip fmap) x f ≡ fmap f x
and indeed, by some theorem or other, because the types are identical,
the functions themselves must be identical also! (There are some side
conditions, all of which hold here.) The two functions pamf fmap and
flip fmap are identical. Analogous to the way fmap, restricted
to the environment functor, is identical to (.), pamf, when
similarly restricted, is exactly
flip. You can even see this from its type:
pamf :: ((p -> q) -> (a -> b)) -> a -> ((p -> q) -> b)
Or, cleaning up some superfluous parentheses and inserting some new ones:
pamf :: ((p -> q) -> a -> b) -> (a -> (p -> q) -> b)
And putting !!c = p\to q!!:
pamf :: (c -> a -> b) -> (a -> c -> b)
flip :: ( the same )
Honestly, I would have preferred a type error: “Hey, dummy, fmap has
the wrong type to be an argument to pamf, which wants a functorial
value.” Instead I got “Okay, if you want functions to be a kind of
functor I can do that, also wouldn't it be simpler if the universe was
two-dimensional and there were only three kinds of quarks? Here you
go, no need to thank me!” Maybe someone can explain to me why this is
a useful behavior, and then explain why it is so useful that it should
happen automatically and implicitly instead of being triggered
by some lexical marker like:
newtype Environment e a = Environment (e -> a)
instance Functor (Environment e) where
fmap f (Environment x) = Environment $ \e -> f (x e)
I mean, seriously, suppose you wrote a + b where b was
accidentally a function instead of a number. What if when you did
that, instead of a type error, Haskell would silently shift into some
restricted domain in which it could implicitly interpret b as a
number in some weird way and give you something totally bizarre?
Isn't the whole point of Haskell supposed to be that it doesn't
implicitly convert things that way?
[ Addendum 20181111: Apparently, everyone else hates it too. ]
[Other articles in category /prog/haskell] permanent link
Mon, 08 Oct 2018
Notes on using git-replace to get rid of giant objects
A couple of years ago someone accidentally committed a 350 megabyte
file to our Git repository. Now it's baked in. I wanted to get rid
of it. I thought that I might be able to work out a partial but
lightweight solution using git-replace.
Summary: It didn't work.
Details
In 2016 a programmer commited a 350 megabyte file to my employer's repo, then in the following commit they removed it again. Of course it's still in there, because someone might check out the one commit where it existed. Everyone who clones the repo gets a copy of the big file. Every copy of the repo takes up an extra 350 megabytes on disk.
The usual way to fix this is onerous:
Use
git-filter-branchto rebuild all the repository history after the bad commit.Update all the existing refs to point to the analogous rebuilt objects.
Get everyone in the company to update all the refs in their local copies of the repo.
I thought I'd tinker around with git-replace to see if there was
some way around this, maybe something that someone could do locally on
their own repo without requiring everyone else to go along with it.
The git-replace command annotates the Git repository to say that
whenever object A is wanted, object B should be used instead. Say
that the 350 MB file has an ID of
ffff9999ffff9999ffff9999ffff9999ffff9999. I can create a small file
that says
This is a replacement object. It replaces a very large file
that was committed by mistake. To see the commit as it really
was, use
git --no-replace-objects show 183a5c7e90b2d4f6183a5c7e90b2d4f6183a5c7e
git --no-replace-objects checkout 183a5c7e90b2d4f6183a5c7e90b2d4f6183a5c7e
or similarly. To see the file itself, use
git --no-replace-objects show ffff9999ffff9999ffff9999ffff9999ffff9999
I can turn this small file into an object with git-add; say the new
small object has ID 1111333311113333111133331111333311113333. I
then run:
git replace ffff9999ffff9999ffff9999ffff9999ffff9999 1111333311113333111133331111333311113333
This creates
.git/refs/replace/ffff9999ffff9999ffff9999ffff9999ffff9999, which
contains the text 1111333311113333111133331111333311113333.
thenceforward, any Git command that tries to access the original
object ffff9999 will silently behave as if it were 11113333
instead. For example, git show 183a5c7e will show the diff between
that commit and the previous, as if the user had committed my small
file back in 2016 instead of their large one. And checking out that
commit will check out the small file instead of the large one.
So far this doesn't help much. The checkout is smaller, but nobody was likely to have that commit checked out anyway. The large file is still in the repository, and clones and transfers still clone and transfer it.
The first thing I tried was a wan hope: will git gc discard the
replaced object? No, of course not. The ref in refs/replace/
counts as a reference to it, and it will never be garbage-collected.
If it had been, you would no longer be able to examine it with the
--no-replace-objects commands. So much for following the rules!
Now comes the hacking part: I am going to destroy the actual object. Say for example, what if:
cp /dev/null .git/objects/ff/ff9999ffff9999ffff9999ffff9999ffff9999
Now the repository is smaller! And maybe Git won't notice, as long as
I do not use --no-replace-objects?
Indeed, much normal Git usage doesn't notice. For example, I can make
new commits with no trouble, and of course any other operation that
doesn't go back as far as 2016 doesn't notice the change. And
git-log works just fine even past the bad commit; it only looks at
the replacement object and never notices that the bad object is
missing.
But some things become wonky. You get an error message when you clone
the repo because an object is missing. The replacement refs are local
to the repo, and don't get cloned, so clone doesn't know to use the
replacement object anyway. In the clone, you can use git replace -f
.... to reinstate the replacement, and then all is well unless
something tries to look at the missing object. So maybe a user could
apply this hack on their own local copy if they are willing to
tolerate a little wonkiness…?
No. Unfortunately, there is a show-stopper: git-gc no longer
works in either the parent repo or in the clone:
fatal: unable to read ffff9999ffff9999ffff9999ffff9999ffff9999
error: failed to run repack
and it doesn't create the pack files. It dies, and leaves behind a
.git/objects/pack/tmp_pack_XxXxXx that has to be cleaned up by hand.
I think I've reached the end of this road. Oh well, it was worth a look.
[ Addendum 20181009: A lot of people have unfortunately missed the point of this article, and have suggested that I use BFG or reposurgeon. I have a small problem and a large problem. The small problem is how to remove some files from the repository. This is straightforward, and the tools mentioned will help with it. But because of the way Git works, the result is effectively a new repository. The tools will not help with the much larger problem I would have then: How to get 350 developers to migrate to the new repository at the same time. The approach I investigated in this article was an attempt to work around this second, much larger problem. ]
[Other articles in category /prog] permanent link
Wed, 12 Sep 2018
Perils of hacking on mature software
Yesterday I wrote up an interesting bug in git-log --follow's
handling of empty files. Afterward
I thought I'd see if I could fix it.
People complain that the trouble of working on mature software like Git is to understand the way the code is structured, its conventions, the accumulated layers of cruft, and where everything is. I think this is a relatively minor difficulty. The hard part is no so much doing what you want, as knowing what you want to do.
My original idea for the fix was this: I can give git log a new
option, say --follow-size-threshhold=n. This would disable all
copy and rename detection for any files of size less than n bytes.
If not specified or configured, n would default to 1, so that the
default behavior would disable copy and rename detection of empty
files but not of anything else. I was concerned that an integer
option was unnecessarily delicate. It might have been sufficient to
have a boolean --follow-empty-files flag. But either way the
programming would be almost the same and it would be easy to simplify
the option later if the Git maintainers wanted it that way
I excavated the code and found where the change needed to go. It's
not actually in git-log itself. Git has an internal system for
diffing pairs of files, and git-log --follow uses this to decide
when two blobs are similar enough for it to switch from following one
to the other. So the flag actually needed to be added to git-diff,
where I called it --rename-size-threshhold. Then git-log would
set that option internally before using the Git diff system to detect
renames.
But then I ran into a roadblock. Diff already has an undocumented
flag called --rename-empty that tells it to report on renames of
empty files in certain contexts — not the context I was interested in
unfortunately. The flag is set by default, but it is cleared internally
when git-merge is resolving conflicts. The issue it addresses is
this: Suppose the merge base has some empty file X. Somewhere along
the line X has been removed. In one branch, an unrelated empty file
Y has been created, and in the other branch a different unrelated
empty file Z has been created. When merging these two branches, Git
will detect a merge conflict: was file X moved to location Y or to
location Z? This ⸢conflict⸣ is almost certainly spurious, and is is
very unlikely that the user will thank us for demanding that they
resolve it manually. So git-merge sets --no-rename-empty
internally and Git resolves the ⸢conflict⸣ automatically.
(See this commit for further details.)
The roadblock is: how does --rename-empty fit together with my
proposed --rename-size-threshhold flag? Should they be the same
thing? Or should they be separate options? There appear to be at
least three subsystems in Git that try to decide if two similar or
identical files (which might have different names, or the same name in
different directories) are “the same file” for various purposes. Do
we want to control the behavior of these subsystems separately or in
unison?
If they should be controlled in unison, should
--rename-size-threshhold be demoted to a boolean, or should
--rename-empty be promoted to an integer? And if they should be the
same, what are the implications for backward compatibility? Should
the existing --rename-empty be documented?
If we add new options, how do they interact with the existing and
already non-orthogonal flags that do something like this? They
include at least the following options of git-diff, git-log, and
git-show:
--follow
--find-renames=n
--find-copies
--find-copies-harder
-l
Only git-log has --follow and my new feature was conceived as a
modification of it, which is why I named it
--follow-size-threshhold. But git-log wouldn't be implementing
this itself, except to pass the flag into the diff system. Calling it
--follow-size-threshhold in git-diff didn't make sense because
git-diff doesn't have a --follow option. It needs a different
name. But if I do that, then we have git-diff and git-log options
with different names that nevertheless do exactly the same thing.
Confusing!
Now suppose you would like to configure a default for this option in
your .gitconfig. Does it make sense to have both
diff.renameSizeThreshhold and log.followSizeThreshhold options?
Not really. It would never be useful to set one but not the other.
So eliminate log.followSizeThreshhold. But now someone like me who
wants to change the behavior of git-log --follow will not know to
look in the right place for the option they need.
The thing to do at this point is to come up with some
reasonable-seeming proposal and send it to Jeff King, who created the
undocumented --rename-empty feature, and who is also a good person
to work with. But coming up with a good solution entirely on my own
is unlikely.
Doing any particular thing would not be too hard. The hard part is deciding what particular thing to do.
[Other articles in category /prog] permanent link
Mon, 10 Sep 2018
Why hooks and forks in the J language?
I don't know why [Ken] Iverson thought the hook was the thing to embed in the [J] language.
And I think I now recall that the name of the language itself, J, is intended to showcase the hook, so he must have thought it was pretty wonderful.
A helpful Hacker News
comment pointed me to
the explanation. Here Iverson explains why the “hook”
feature: it is actually the
S combinator in disguise. Recall that
$${\bf S} x y z = x z (y z).$$ This is exactly what J's hook computes
when you write (x y) z. For instance, if I understand correctly, in
J (+ !) means the one-place operation that takes an argument !!z!!
to !!z + z! !!.
As McBride and Paterson point
out, S
is also the same as the <*> operator in the Reader instance of
Applicative.
Since in J the only possible inputs to a hook are functions, it is
operating in the Reader idiom and in that context its hook is doing
the same thing as Haskell's <*>. Similarly, J's “fork” feature can
be understood as essentially the same as the Reader insance of
Haskell's liftA2.
[Other articles in category /prog] permanent link
git log --follow enthusiastically tracks empty files
This bug I just found in git log --follow is impressively massive.
Until I worked out what was going on I was really perplexed, and even
considered that my repository might have become corrupted.
I knew I'd written a draft of a blog article about the Watchmen movie, and I went to find out how long it had been sitting around:
% git log -- movie/Watchmen.blog
commit 934961428feff98fa3cb085e04a0d594b083f597
Author: Mark Dominus <mjd@plover.com>
Date: Fri Feb 3 16:32:25 2012 -0500
link to Mad Watchmen parody
also recategorize under movie instead of under book
The log stopped there, and the commit message says clearly that the
article was moved from elsewhere, so I used git-log --follow --stat
to find out how old it really was. The result was spectacularly
weird. It began in the right place:
commit 934961428feff98fa3cb085e04a0d594b083f597
Author: Mark Dominus <mjd@plover.com>
Date: Fri Feb 3 16:32:25 2012 -0500
link to Mad Watchmen parody
also recategorize under movie instead of under book
{book => movie}/Watchmen.blog | 8 +++++++-
1 file changed, 7 insertions(+), 1 deletion(-)
Okay, it was moved, with slight modifications, from book to movie,
as the message says.
commit 5bf6e946f66e290fc6abf044aa26b9f7cfaaedc4
Author: Mark Jason Dominus (陶敏修) <mjd@plover.com>
Date: Tue Jan 17 20:36:27 2012 -0500
finally started article about Watchment movie
book/Watchmen.blog | 40 ++++++++++++++++++++++++++++++++++++++++
1 file changed, 40 insertions(+)
Okay, the previous month I added some text to it.
Then I skipped to the bottom to see when it first appeared, and the bottom was completely weird, mentioning a series of completely unrelated articles:
commit e6779efdc9510374510705b4beb0b4c4b5853a93
Author: mjd <mjd>
Date: Thu May 4 15:21:57 2006 +0000
First chunk of linear regression article
prog/maxims/paste-code.notyet => math/linear-regression.notyet | 0
1 file changed, 0 insertions(+), 0 deletions(-)
commit 9d9038a3358a82616a159493c6bdc91dd03d03f4
Author: mjd <mjd>
Date: Tue May 2 14:16:24 2006 +0000
maxims directory reorganization
tech/mercury.notyet => prog/maxims/paste-code.notyet | 0
1 file changed, 0 insertions(+), 0 deletions(-)
commit 1273c618ed6efa4df75ce97255204251678d04d3
Author: mjd <mjd>
Date: Tue Apr 4 15:32:00 2006 +0000
Thingy about propagation delay and mercury delay lines
tech/mercury.notyet | 0
1 file changed, 0 insertions(+), 0 deletions(-)
(The complete output is available for your perusal.)
The log is showing unrelated files being moved to totally unrelated
places. And also, the log messages do not seem to match up. “First
chunk of linear regression article” should be on some commit that adds
text to math/linear-regression.notyet or
math/linear-regression.blog. But according to the output above,
that file is still empty after that commit. Maybe I added the text in
a later commit? “Maxims directory reorganization” suggests that I
reorganized the contents of prog/maxims, but the stat says
otherwise.
My first thought was: when I imported my blog from CVS to Git, many years ago, I made a series of mistakes, and mismatched the log messages to the commits, or worse, and I might have to do it over again. Despair!
But no, it turns out that git-log is just intensely confused.
Let's look at one of the puzzling commits. Here it is as reported by
git log --follow --stat:
commit 9d9038a3358a82616a159493c6bdc91dd03d03f4
Author: mjd <mjd>
Date: Tue May 2 14:16:24 2006 +0000
maxims directory reorganization
tech/mercury.notyet => prog/maxims/paste-code.notyet | 0
1 file changed, 0 insertions(+), 0 deletions(-)
But if I do git show --stat 9d9038a3, I get a very different
picture, one that makes sense:
% git show --stat 9d9038a3
commit 9d9038a3358a82616a159493c6bdc91dd03d03f4
Author: mjd <mjd>
Date: Tue May 2 14:16:24 2006 +0000
maxims directory reorganization
prog/maxims.notyet | 226 -------------------------------------------
prog/maxims/maxims.notyet | 95 ++++++++++++++++++
prog/maxims/paste-code.blog | 134 +++++++++++++++++++++++++
prog/maxims/paste-code.notyet | 0
4 files changed, 229 insertions(+), 226 deletions(-)
This is easy to understand. The commit message was correct: the
maxims are being reorganized. But git-log --stat, in conjunction
with --follow, has produced a stat that has only a tenuous
connection with reality.
I believe what happened here is this: In 2012 I “finally started article”. But I didn't create the file at that time. Rather, I had created the file in 2009 with the intention of putting something into it later:
% git show --stat 5c8c5e66
commit 5c8c5e66bcd1b5485576348cb5bbca20c37bd330
Author: mjd <mjd>
Date: Tue Jun 23 18:42:31 2009 +0000
empty file
book/Watchmen.blog | 0
book/Watchmen.notyet | 0
2 files changed, 0 insertions(+), 0 deletions(-)
This commit does appear in the git-log --follow output, but it
looks like this:
commit 5c8c5e66bcd1b5485576348cb5bbca20c37bd330
Author: mjd <mjd>
Date: Tue Jun 23 18:42:31 2009 +0000
empty file
wikipedia/mega.notyet => book/Watchmen.blog | 0
1 file changed, 0 insertions(+), 0 deletions(-)
It appears that Git, having detected that book/Watchmen.blog was
moved to movie/Watchmen.blog in Febraury 2012, is now following
book/Watchmen.blog backward in time. It sees that in January 2012
the file was modified, and was formerly empty, and after that it sees
that in June 2009 the empty file was created. At that time there was
another empty file, wikipedia/mega.notyet. And git-log decides that the
empty file book/Watchmen.blog was copied from the other empty
file.
At this point it has gone completely off the rails, because it is now
following the unrelated empty file wikipedia/mega.notyet. It then
makes more mistakes of the same type. At one point there was an empty
wikipedia/mega.blog file, but commit ff0d744d5 added some text to it
and also created an empty wikipedia/mega.notyet alongside it. The
git-log --follow command has interpreted this as the empty
wikipedia/mega.blog being moved to wikipedia/mega.notyet and a
new wikipedia/mega.blog being created alongside it. It is now following
wikipedia/mega.blog.
Commit ff398402 created the empty file wikipedia/mega.blog fresh,
but git-log --follow interprets the commit as copying
wikipedia/mega.blog from the already-existing empty file
tech/mercury.notyet. Commit 1273c618 created tech/mercury.notyet,
and after that the trail comes to an end, because that was shortly
after I started keeping my blog in revision control; there were no
empty files before that. I suppose that attempting to follow the
history of any file that started out empty is going to lead to the
same place, tech/mercury.notyet.
On a different machine with a different copy of the repository, the
git-log --follow on this file threads its way through ten
irrelvant files before winding up at tech/mercury.notyet.
There is a --find-renames=... flag to tell Git how conservative to
be when guessing that a file might have been renamed and modified at
the same time. The default is 50%. But even turning it up to 100%
doesn't help with this problem, because in this case the false
positives are files that are actually identical.
As far as I can tell there is no option to set an absolute threshhold
on when two files are considered the same by --follow. Perhaps it
would be enough to tell Git that it should simply not try to follow
files whose size is less than !!n!! bytes, for some small !!n!!, perhaps
even !!n=1!!.
The part I don't fully understand is how git-log --follow is
generating its stat outputs. Certainly it's not doing it in the
same way that git show is. Instead it is trying to do something
clever, to highlight the copies and renames it thinks it has found,
and in this case it goes badly wrong.
The problem appears in Git 1.7.11, 2.7.4, and 2.13.0.
[ Addendum 20180912: A followup about my work on a fix for this. ]
[Other articles in category /prog] permanent link
Sun, 09 Sep 2018I very recently suggested a mathematical operation that does this:
$$\begin{align} \left((\sqrt\bullet) \cdot x + \left(\frac1\bullet\right) \cdot 1 \right) ⊛ (9x+4) & = \sqrt9 x^2 + \sqrt4 x + \frac19 x + \frac14 \\ & = 3x^2 + \frac{19}{9} x + \frac 14 \end{align}$$
Here the left-hand argument is like a polynomial, except that the coefficients are functions. The right-hand argument is an ordinary polynomial.
It occurs to me that the APL progamming lanaguage (invented around 1966) actually has something almost like this, in its generalized matrix product.
In APL, if ? and ! are any binary operators, you can write ?.!
to combine them into a matrix operator. Like ordinary matrix
multiplication, the new operator combines an !!m×n!! and an !!n×r!! matrix
into an !!m×r!! matrix. Ordinary matrix multiplication is defined like
this:
$$c_{ij} = a_{i1} \cdot b_{1j} +
a_{i2} \cdot b_{2j} + \ldots +
a_{in} \cdot b_{nj} $$
The APL ?.! operator replaces the addition with ? and the
multiplication with !, so that +.× is exactly the standard matrix
multiplication. Several other combined operations of this type are,
if not common, at least idiomatic. For example, I have seen, and
perhaps used, ∨.∧, +.∧, and ⌈.⌊. (⌈ and ⌊ are APL's
two-argument minimum and maximum operators.)
With this feature, the ⊛ operator I proposed above would be something
like +.∘, where ∘ means function composition. To make it work you
need to interpret the coefficients of an ordinary polynomial as
constant functions, but that is not much of a stretch. APL doesn't
actually have a function composition operator.
APL does have a ∘ symbol, but it doesn't mean function composition,
and also the !.? notation is special cased, in typically APL style,
so that ∘.? does something sort of related but rather different.
Observe also that if !!a!! and !!b!! are !!1×n!! and !!n×1!! matrices,
respectively, then !!a +.× b!! ought to be dot product of !!a!! and !!b!!:
it is a !!1×1!! matrix whose sole entry is:
$$c_{11} = a_{11} \cdot b_{11} +
a_{12} \cdot b_{21} + \ldots +
a_{1n} \cdot b_{n1} $$
and similarly if !!a!! is !!n×1!! and !!b!! is !!1×m!! then !!a +.× b!! is the
outer product, the !!n×m!! matrix whose !!c_{ij} = a_i × b_j!!. But I
think APL doesn't distinguish between a !!1×n!! matrix and a vector,
though, and always considers them to be vectors, so that in such cases
!!a +.× b!! always gets you the dot product, if !!a!! and !!b!! are the same
length, and an error otherwise. If you want the outer product of two
vectors you use a ∘.× b instead. a ∘.+ b would be the outer
product matrix with !!c_{ij} = a_i + b_j!!. APL is really strange.
I applied for an APL job once; I went to a job fair (late 1980s maybe?) and some Delaware bank was looking for APL programmers to help maintain their legacy APL software. I was quite excited at the idea of programming APL professionally, but I had no professional APL experience so they passed me over. I think they made a mistake, because there are not that many people with professional APL experience anyway, and how many twenty-year-olds are there who know APL and come knocking on your door looking for a job? But whatever, it's probably better that I didn't take that route.
The +.× thing exemplifies my biggest complaint about APL semantics:
it was groping toward the idea of functional programming without quite
getting there, never quite general enough. You could use !/, where
! was any built-in binary operator, and this was quite like a fold.
But you couldn't fold a user-defined function of two arguments! And
you couldn't write a higher-order fold function either.
I was pleased to find out that Iverson had designed a successor language, J, and then quickly disappointed when I saw how little it added. For example, it has an implicit “hook” construction, which is a special case in the language for handling one special case of function composition. In Haskell it would be:
hook f g x = x `f` (g x)
but in J the hook itself is implicit. If you would rather use (g x) `f` x
instead, you are out of luck because that is not built-in. I don't
know why Iverson thought the hook was the thing to embed in the
language. (J also has an implicit “fork” which is fork f g h x =
(f x) `g` (h x).)
[ Addendum 20180910: The explanation. ]
Meanwhile the awful APL notation has gotten much more awful in J, and
you get little in return. You even lose all the fun of the little
squiggles. Haskell is a much better J than J ever was. Haskell's
notation can be pretty awful too ((.) . (.)?), but at least you are
are getting your money's worth.
I thought I'd see about implementing APL's !.? thing in Haskell to
see what it would look like. I decided to do it by implementing a
regular matrix product and then generalizing. Let's do the simplest
thing that could possibly work and represent a matrix as a list of
rows, each of which is a list of entries.
For a regular matrix product, !!C = AB!! means that !!c_{ij}!! is the dot product of the !!i!!th row of !!A!! and the !!j!!th column of !!B!!, so I implemented a dot product function:
dot_product :: Num b => [b] -> [b] -> b
dot_product a b = foldr (+) 0 $ zipWith (*) a b
OK, that was straightforward.
The rows of !!A!! are right there, but we also need the columns from !!B!!, so here's a function to get those:
transpose ([]:_) = []
transpose x = (map head x) : transpose (map tail x)
Also straightforward.
After that I toiled for a very long time over the matrix product itself. My first idea was to turn !!A!! into a list of functions, each of which would dot-product one of the rows of !!A!! by a given vector. Then I would map each of these functions over the columns of !!B!!.
Turning !!A!! into a list of functions was easy:
map dot_product a :: [ [x] -> x ]
and getting the columns of !!B!! I had already done:
transpose b :: [[x]]
and now I just need to apply each row of functions in the first part to each column in the second part and collect the results:
??? (map dot_product a) (transpose b)
I don't know why this turned out to be so damn hard. This is the sort of thing that ought to be really, really easy in Haskell. But I had many difficulties.
First I wasted a bunch of time trying to get <*> to work, because it
does do something like that.
But the thing
I wanted has signature
??? :: [a -> b] -> [a] -> [[b]]
whereas <*> flattens the result:
<*> :: [a -> b] -> [a] -> [b]
and I needed to keep that extra structure. I tried all sorts of
tinkering with <*> and <$> but never found what I wanted.
Another part of the problem was I didn't know any primitive for “map a list of functions over a single argument”. Although it's not hard to write, I had some trouble thinking about it after I wrote it:
pamf fs b = fmap ($ b) fs
Then the “map each function over each list of arguments” is map . pamf, so I got
(map . pamf) (map dot_product a) (transpose b)
and this almost works, except it produces the columns of the results
instead of the rows. There is an easy fix and a better fix. The easy
fix is to just transpose the final result. I never did find the
better fix. I thought I'd be able to replace map . pamf with pamf
. map but the latter doesn't even type check.
Anyway this did work:
matrix_product a b =
transpose $ (map . pamf) (map dot_product a) (transpose b)
but that transpose on the front kept bothering me and I couldn't
leave it alone.
So then I went down a rabbit hole and wrote nine more versions of
???:
fs `op` as = do
f <- fs
return $ fmap f as
fs `op2` as = fs >>= (\f -> return $ fmap f as)
fs `op3` as = fs >>= (return . flip fmap as )
fs `op4` as = fmap ( flip fmap as ) fs
op5 as = fmap ( flip fmap as )
op6 :: [a -> b] -> [a] -> [[b]]
op6 = flip $ fmap . (flip fmap)
fs `op7` as = map (\f -> [ f a | a <- as ]) fs
fs `op8` as = map (\f -> (map f as)) fs
fs `op9` as = map (flip map as) fs
I finally settled on op6, except it takes the arguments in the
“wrong” order, with the list of functions second and their arguments
first. But I used it anyway:
matrix_product a b = (map . flip map) (transpose b) (map dot_product a)
The result was okay, but it took me so long to get there.
Now I have matrix_product and I can generalize it to uses two
arbitrary operations instead of addition and multiplication. And
hey, I don't have to touch matrix_product! I only need to change
dot_product because that's where the arithmetic is. Instead of
dot_product a b = foldr (+) 0 $ zipWith (*) a b
just use:
inner_product u v = foldr add 0 $ zipWith mul u v
Except uh oh, that 0 is wrong. It might not be the identity for
whatever weird operation add is; it might be min and then we need
the 0 to be minus infinity.
I tinkered a bit with requiring a Monoid instance for the matrix
entries, which seemed interesting at least, but to do that I would
need to switch monoids in the middle of the computation and I didn't
want to think about how to do that. So instead I wrote a version of
foldr that doesn't need an identity element:
foldr' f (a:as) = foldr f a as
This fails on empty lists, which is just fine, since I wasn't planning on multiplying any empty matrices.
Then I have the final answer:
general_matrix_product add mul a b =
(map . flip map) (transpose b) (map inner_product a) where
inner_product u v = foldr' add $ zipWith mul u v
It's nice and short, but on the other hand it has that mysterious map
. flip map in there. If I hadn't written that myself I would see it
and ask what on earth it was doing. In fact I did write it myself
and I although I do know what it is doing I don't really understand
why.
As for the shortness, let's see what it looks like in a more conventional language:
def transpose(m):
return list(zip(*m))
Wow, that was amazingly easy.
def matrix_product(a, b):
def dot_product(u, v):
total = 0
for pair in zip(u, v):
total += pair[0] * pair[1]
return total
bT = transpose(b)
c = []
for i in range(len(a)):
c.append([])
for j in range(len(bT)):
c[-1].append(None)
c[i][j] = dot_product(a[i], bT[j])
return c
Okay, that was kind of a mess. The dot_product should be shorter
because Python has a nice built-in sum function but how do I build
the list of products I want to sum? It doesn't have map because it
doesn't have lambdas. I know, I know, someone is going to insist that
Python has lambdas. It does, sort of, but they suck.
I think the standard Python answer to this is that you don't need
map because you're supposed to use list comprehension instead:
def dot_product(u, v):
return sum([ x*y for (x, y) in zip(u, v) ])
I don't know how I feel about that argument in general but in this case the result was lovely. I have no complaints.
While I was writing the Python program I got a weird bug that turned
out to be related to mutability: I had initialized c with
c = [[None] * len(bT)] * len(a)
But this makes the rows of c the same mutable object, and then
installing values in each row overwrites the entries we stored in the
previous rows. So definitely score one point for Haskell there.
A lot of the mess in the code is because Python is so obstinate about extending lists when you need them extended, you have to say pretty please every time. Maybe I can get rid of that by using more list comprehensions?
def matrix_product2(a, b):
def dot_product(u, v):
return sum([ x*y for (x, y) in zip(u, v) ])
return [ [ dot_product(u, v) for v in transpose(b) ] for u in a ]
Python's list comprehensions usually make me long for Haskell's, which are so much nicer, but this time they were fine. Python totally wins here. No wait, that's not fair: maybe I should have been using list comprehensions in Haskell also?
matrix_product = [ [ dot_product row col | col <- transpose b ] | row <- a ]
Yeah, okay. All that map . flip map stuff was for the birds. Guido
thinks that map is a bad idea, and I thought he was being silly, but
maybe he has a point. If I did want the ??? thing that applies a
list of functions to a list of arguments, the list comprehension
solves that too:
[ f x | f <- fs, x <- xs ]
Well, lesson learned.
I really wish I could write Haskell faster. In the mid-1990s I wrote thousands of lines of SML code and despite (or perhaps because of) SML's limitations I was usually able to get my programs to do what I wanted. But when I try to write programs in Haskell it takes me a really long time to get anywhere.
Apropos of nothing, today is the 77th birthday of Dennis M. Ritchie.
[ Addendum: It took me until now to realize that, after all that, the operation I wanted for polynomials is not matrix multiplication. Not at all! It is actually a convolution:
$$ c_k = \sum_{i+j=k} a_ib_j $$
or, for my weird functional version, replace the multiplication !!a_ib_j!! with function composition !!a_i ∘ b_j!!. I may implement this later, for practice. And it's also tempting to try to do it in APL, even though that would most likely be a terrible waste of time… ]
[ Addendum 20180909: Vaibhav Sagar points out that my foldr' is the
standard Prelude function
foldr1.
But as I said in the previous
article, one of the
problems I have is that faced with a need for something like foldr1,
instead of taking one minute to write it, I will waste fifteen minutes
looking for it in Hoogle. This time I opted to not do that. In
hindsight it was a mistake, perhaps, but I don't regret the choice.
It is not easy to predict what is worth looking for. To see the
downside risk, consider pamf. A Hoogle search for
pamf
produces nothing like what I want, and, indeed, it doesn't seem to
exist. ]
[Other articles in category /prog] permanent link
Sat, 08 Sep 2018
Why I never finish my Haskell programs (part 2 of ∞)
Here's something else that often goes wrong when I am writing a Haskell program. It's related to the problem in the previous article but not the same.
Let's say I'm building a module for managing polynomials. Say
Polynomial a is the type of (univariate) polynomials over some
number-like set of coefficients a.
Now clearly this is going to be a functor, so I define the Functor instance, which is totally straightforward:
instance Functor Polynomial where
fmap f (Poly a) = Poly $ map f a
Then I ask myself if it is also going to be an Applicative.
Certainly the pure function makes sense; it just lifts a number to
be a constant polynomial:
pure a = Poly [a]
But what about <*>? This would have the
type:
(Polynomial (a -> b)) -> Polynomial a -> Polynomial b
The first argument there is a polynomial whose coefficients are functions. This is not something we normally deal with. That ought to be the end of the matter.
But instead I pursue it just a little farther. Suppose we did have such an object. What would it mean to apply a functional polynomial and an ordinary polynomial? Do we apply the functions on the left to the coefficients on the right and then collect like terms? Say for example
$$\begin{align} \left((\sqrt\bullet) \cdot x + \left(\frac1\bullet\right) \cdot 1 \right) ⊛ (9x+4) & = \sqrt9 x^2 + \sqrt4 x + \frac19 x + \frac14 \\ & = 3x^2 + \frac{19}{9} x + \frac 14 \end{align}$$
Well, this is kinda interesting. And it would mean that the pure
definition wouldn't be what I said; instead it would lift a number to
a constant function:
pure a = Poly [λ_ -> a]
Then the ⊛ can be understood to be just like polynomial
multiplication, except that coefficients are combined with function
composition instead of with multiplication. The operation is
associative, as one would hope and expect, and even though the ⊛
operation is not commutative, it has a two-sided identity element,
which is Poly [id]. Then I start to wonder if it's useful for anything, and
how ⊛ interacts with ordinary multiplication, and so forth.
This is different from the failure mode of the previous article because in that example I was going down a Haskell rabbit hole of more and more unnecessary programming. This time the programming is all trivial. Instead, I've discovered a new kind of mathematical operation and I abandon the programming entirely and go off chasing a mathematical wild goose.
[ Addendum 20181109: Another one of these. ]
[Other articles in category /prog/haskell] permanent link
Mon, 03 Sep 2018
Why I never finish my Haskell programs (part 1 of ∞)
Whenever I try to program in Haskell, the same thing always goes wrong. Here is an example.
I am writing a module to operate on polynomials. The polynomial !!x^3 - 3x + 1!! is represented as
Poly [1, -3, 0, 1]
[ Addendum 20180904: This is not an error. The !!x^3!! term is last, not first. Much easier that way. Fun fact: two separate people on Reddit both commented that I was a dummy for not doing it the easy way, which is the way I did do it. Fuckin' Reddit, man. ]
I want to add two polynomials. To do this I just add the corresponding coefficients, so it's just
(Poly a) + (Poly b) = Poly $ zipWith (+) a b
Except no, that's wrong, because it stops too soon. When the lists
are different lengths, zipWith discards the extra, so for example it
says that !!(x^2 + x + 1) + (2x + 2) = 3x + 3!!, because it has
discarded the extra !!x^2!! term. But I want it to keep the extra, as
if the short list was extended with enough zeroes. This would be a
correct implementation:
(Poly a) + (Poly b) = Poly $ addup a b where
addup [] b = b
addup a [] = a
addup (a:as) (b:bs) = (a+b):(addup as bs)
and I can write this off the top of my head.
But do I? No, this is where things go off the rails. “I ought to be
able to generalize this,” I say. “I can define a function like
zipWith that is defined over any Monoid, it will combine the
elements pairwise with mplus, and when one of the lists
runs out, it will pretend that that one has some memptys stuck on the
end.” Here I am thinking of something like ffff :: Monoid a => [a] ->
[a] -> [a], and then the (+) above would just be
(Poly a) + (Poly b) = Poly (ffff a b)
as long as there is a suitable Monoid instance for the as and bs.
I could write ffff in two minutes, but instead I spend fifteen
minutes looking around in Hoogle to see if there is already an ffff,
and I find mzip, and waste time being confused by mzip, until I
notice that I was only confused because mzip is for Monad, not
for Monoid, and is not what I wanted at all.
So do I write ffff and get on with my life? No, I'm still not done.
It gets worse. “I ought to be able to generalize this,” I say. “It
makes sense not just for lists, but for any Traversable… Hmm, or
does it?” Then I start thinking about trees and how it should decide
when to recurse and when to give up and use mempty, and then I start
thinking about the Maybe version of it.
Then I open a new file and start writing
mzip :: (Traversable f, Monoid a) => f a -> f a -> f a
mzip as bs = …
And I go father and farther down the rabbit hole and I never come back
to what I was actually working on. Maybe the next step in this
descent into madness is that I start thinking about how to perform
unification of arbitrary algebraic data structures, I abandon mzip
and open a new file for defining class Unifiable…
Actually when I try to program in Haskell there a lot of things that go wrong and this is only one of them, but it seems like this one might be more amenable to a quick fix than some of the other things.
[ Addendum 20180904: A lobste.rs
user
points out that I don't need Monoid, but only Semigroup, since
I don't need mempty. True that! I didn't know there was a
Semigroup class. ]
[ Addendum 20181109: More articles in this series: [2] [3] ]
[Other articles in category /prog/haskell] permanent link
Wed, 08 Aug 2018In my original article, I said:
I was fairly confident I had seen something like this somewhere before, and that it was not original to me.
Jeremy Yallop brought up an example that I had definitely seen before.
In 2008 Conor McBride and Ross Paterson wrote an influential paper, “Idioms: applicative programming with effects” that introduced the idea of an applicative functor, a sort of intermediate point between functors and monads. It has since made its way into standard Haskell and was deemed sufficiently important to be worth breaking backward compatibility.
McBride and Paterson used several notations for operations in an
applicative functor. Their primary notation was !!\iota!! for what is
now known as pure and !!\circledast!! for what has since come to be written
as <*>. But the construction
$$\iota f \circledast is_1 \circledast \ldots \circledast is_n$$
came up so often they wanted a less cluttered notation for it:
We therefore find it convenient, at least within this paper, to write this form using a special notation
$$ [\![ f is_1 \ldots is_n ]\!] $$
The brackets indicate a shift into an idiom where a pure function is applied to a sequence of computations. Our intention is to provide a sufficient indication that effects are present without compromising the readability of the code.
On page 5, they suggested an exercise:
… show how to replace !![\![!! and !!]\!]!! by identifiers
iIandIiwhose computational behaviour delivers the above expansion.
They give a hint, intended to lead the reader to the solution, which
involves a function named iI that does some legerdemain on the front
end and then a singleton type data Ii = Ii that terminates the legerdemain on
the back end. The upshot is that one can write
iI f x y Ii
and have it mean
(pure f) <*> x <*> y
The haskell wiki has details, written by Don Stewart when the McBride-Paterson paper was still in preprint. The wiki goes somewhat further, also defining
data J = J
so that
iI f x y J z Ii
now does a join on the result of f x y before applying the result
to z.
I have certainly read this paper more than once, and I was groping for this example while I was writing the original article, but I couldn't quite put my finger on it. Thank you, M. Yallop!
[ By the way, I am a little bit disappointed that the haskell wiki is not called “Hicki”. ]
[Other articles in category /prog/haskell] permanent link
In the previous article I described a rather odd abuse of the Haskell type system to use a singleton type as a sort of pseudo-keyword, and asked if anyone had seen this done elsewhere.
Joachim Breitner reported having seen this before. Most recently in
LiquidHaskell, which defines a QED singleton
type:
data QED = QED
infixl 2 ***
(***) :: a -> QED -> Proof
_ *** _ = ()
so that they can end every proof with *** QED:
singletonP x
= reverse [x]
==. reverse [] ++ [x]
==. [] ++ [x]
==. [x]
*** QED
This example is from Vazou et al., Functional Pearl: Theorem Proving
for All, p. 3. The authors
explain: “The QED argument serves a purely aesthetic purpose,
allowing us to conclude proofs with *** QED.”.
Or see the examples from the bottom of the LH splash
page, proving the
associative law for ++.
I looked in the rest of the LiquidHaskell distribution but did not find any other uses of the singleton-type trick. I would still be interested to see more examples.
[ Addendum: Another example. ]
[Other articles in category /prog/haskell] permanent link
Is this weird Haskell technique something I made up?
A friend asked me the other day about techniques in Haskell to pretend
to make up keywords. For example, suppose we want something like a
(monadic) while loop, say like this:
while cond act =
cond >>= \b -> if b then act >> while cond act
else return ()
This uses a condition cond (which might be stateful or
exception-throwing or whatever, but which must yield a boolean value)
and an action act (likewise, but its value is ignored) and it
repeates the action over and over until the condition is false.
Now suppose for whatever reason we don't like writing it as while
condition action and we want instead to write while condition do
action or something of that sort. (This is a maximally simple
example, but the point should be clear even though it is silly.) My
first suggestion was somewhat gross:
while c _ a = ...
Now we can write
while condition "do" action
and the "do" will be ignored. Unfortunately we can also write
while condition "wombat" action and you know how programmers are
when you give them enough rope.
But then I had a surprising idea. We can define it this way:
data Do = Do
while c Do a = ...
Now we write
while condition
Do action
and if we omit or misspell the Do we get a compile-time type error
that is not even too obscure.
For a less trivial (but perhaps sillier) example, consider:
data Exception a = OK a | Exception String
instance Monad Exception where ...
data Catch = Catch
data OnSuccess = OnSuccess
data AndThen = AndThen
try computation Catch handler OnSuccess success AndThen continuation =
case computation of OK a -> success >> (OK a) >>= continuation
Exception e -> (handler e) >>= continuation
The idea here is that we want to try a computation, and do one thing
if it succeeds and another if it throws an exception. The point is
not the usefulness of this particular and somewhat contrived exception
handling construct, it's the syntactic sugar of the Catch,
OnSuccess, and AndThen:
try (evaluate some_expression)
Catch (\error -> case error of "Divison by zero" -> ...
... )
OnSuccess ...
AndThen ...
I was fairly confident I had seen something like this somewhere before, and that it was not original to me. But I've asked several Haskell experts and nobody has said it was familar. I thought perhaps I had seen it somewhere in Brent Yorgey's code, but he vehemently denied it.
So my question is, did I make up this technique of using a one-element type as a pretend keyword?
[ Addendum: At least one example of this trick appears in LiquidHaskell. I would be interested to hear about other places it has been used. ]
[ Addendum: Jeremy Yallop points out that a similar trick was hinted at in McBride and Paterson “Idioms: applicative programming with effects” (2008), with which I am familiar, although their trick is both more useful and more complex. So this might have been what I was thinking of. ]
[Other articles in category /prog/haskell] permanent link
Wed, 11 Jul 2018Here is another bit of Perl code:
sub function {
my ($self, $cookie) = @_;
$cookie = ref $cookie && $cookie->can('value') ? $cookie->value : $cookie;
...
}
The idea here is that we are expecting $cookie to be either a
string, passed directly, or some sort of cookie object with a value
method that will produce the desired string.
The ref … && … condition
distinguishes the two situations.
A relatively minor problem is that if someone passes an object with no
value method, $cookie will be set to that object instead of to a
string, with mysterious results later on.
But the real problem here is that the function's interface is not simple enough. The function needs the string. It should insist on being passed the string. If the caller has the string, it can pass the string. If the caller has a cookie object, it should extract the string and pass the string. If the caller has some other object that contains the string, it should extract the string and pass the string. It is not the job of this function to know how to extract cookie strings from every possible kind of object.
I have seen code in which this obsequiousness has escalated to
absurdity. I recently saw a function whose job was to send an email.
It needs an EmailClass object, which encapsulates the message
template and some of the headers. Here is how it obtains that object:
12 my $stash = $args{stash} || {};
…
16 my $emailclass_obj = delete $args{emailclass_obj}; # isn't being passed here
17 my $emailclass = $args{emailclass_name} || $args{emailclass} || $stash->{emailclass} || '';
18 $emailclass = $emailclass->emailclass_name if $emailclass && ref($emailclass);
…
60 $emailclass_obj //= $args{schema}->resultset('EmailClass')->find_by_name($emailclass);
Here the function needs an EmailClass object. The caller can pass
one in $args{emailclass_obj}. But maybe the caller doesn't have
one, and only knows the name of the emailclass it wants to use. Very
well, we will allow it to pass the string and look it up later.
But that string could be passed in any of $args{emailclass_name}, or
$args{emailclass}, or $args{stash}{emailclass} at the caller's
whim and we have to rummage around hoping to find it.
Oh, and by the way, that string might not be a string! It might be the actual object, so there are actually seven possibilities:
$args{emailclass}
$args{emailclass_obj}
$args{emailclass_name}
$args{stash}{emailclass}
$args{emailclass}->emailclass_name
$args{emailclass_name}->emailclass_name
$args{stash}{emailclass}->emailclass_name
Notice that if $args{emailclass_name} is actually an emailclass
object, the name will be extracted from that object on line 18, and
then, 42 lines later, the name may be used to perform a database
lookup to recover the original object again.
We hope by the end of this rigamarole that $emailclass_obj will
contain an EmailClass object, and $emailclass will contain its
name. But can you find any combinations of arguments where this turns
out not to be true? (There are several.) Does the existing code
exercise any of these cases? (I don't know. This function is called
in 133 places.)
All this because this function was not prepared to insist firmly that its arguments be passed in a simple and unambiguous format, say like this:
my $emailclass = $args->{emailclass}
|| $self->look_up_emailclass($args->{emailclass_name})
|| croak "one of emailclass or emailclass_name is required";
I am not certain why programmers think it is a good idea to have functions communicate their arguments by way of a round of Charades. But here's my current theory: some programmers think it is discreditable for their function to throw an exception. “It doesn't have to die there,” they say to themselves. “It would be more convenient for the caller if we just accepted either form and did what they meant.” This is a good way to think about user interfaces! But a function's calling convention is not a user interface. If a function is called with the wrong arguments, the best thing it can do is to drop dead immediately, pausing only long enough to gasp out a message explaining what is wrong, and incriminating its caller. Humans are deserving of mercy; calling functions are not.
Allowing an argument to be passed in seven different ways may be
convenient for the programmer writing the call, who can save a few
seconds looking up the correct spelling of emailclass_name, but
debugging what happens when elaborate and inconsistent arguments are
misinterpreted will eat up the gains many times over. Code is
written once, and read many times, so we should be willing to spend
more time writing it if it will save trouble reading it again later.
Novice programmers may ask “But what if this is business-critical code? A failure here could be catastrophic!”
Perhaps a failure here could be catastrophic. But if it is a catastrophe to throw an exception, when we know the caller is so confused that it is failing to pass the required arguments, then how much more catastrophic to pretend nothing is wrong and to continue onward when we are surely ignorant of the caller's intentions? And that catastrophe may not be detected until long afterward, or at all.
There is such a thing as being too accommodating.
[Other articles in category /prog/perl] permanent link
Fri, 06 Jul 2018[ This article has undergone major revisions since it was first published yesterday. ]
Here is a line of Perl code:
if ($self->fidget && blessed $self->fidget eq 'Widget::Fidget') {
This looks to see if $self has anything in its fidget slot, and if
so it checks to see if the value there is an instance of the class
Widget::Fidget. If both are true, it runs the following block.
That blessed check is bad practice for several reasons.
It duplicates the declaration of the
fidgetmember data:has fidget => ( is => 'rw', isa => 'Widget::Fidget', init_arg => undef, );So the
fidgetslot can't contain anything other than aWidget::Fidget, because the OOP system is already enforcing that. That means that theblessed…eqtest is not doing anything — unless someone comes along later and changes the declared type, in which case the test will then be checking the wrong condition.Actually, that has already happened! The declaration, as written, allows
fidgetto be an instance not just ofWidget::Fidgetbut of any class derived from it. But theblessed…eqcheck prevents this. This reneges on a major promise of OOP, that if a class doesn't have the behavior you need, you can subclass it and modify or extend it, and then use objects from the subclass instead. But if you try that here, theblessed…eqcheck will foil you.So this is a prime example of “… in which case the test will be checking the wrong condition” above. The test does not match the declaration, so it is checking the wrong condition. The
blessed…eqcheck breaks the ability of the class to work with derived classes ofWidget::Fidget.Similarly, the check prevents someone from changing the declared type to something more permissive, such as
“either
Widget::FidgetorGidget::Fidget”or
“any object that supports
wiggleandwagglemethods”or
“any object that adheres to the specification of
Widget::Interface”and then inserting a different object that supports the same interface. But the whole point of object-oriented programming is that as long as an object conforms to the required interface, you shouldn't care about its internal implementation.
In particular, the check above prevents someone from creating a mock
Widget::Fidgetobject and injecting it for testing purposes.We have traded away many of the modularity and interoperability guarantees that OOP was trying to preserve for us. What did we get in return? What are the purported advantages of the
blessed…eqcheck? I suppose it is intended to detect an anomalous situation in which some completely wrong object is somehow stored into theself.fidgetmember. The member declaration will prevent this (that is what it is for), but let's imagine that it has happened anyway. This could be a very serious problem. What will happen next?With the check in place, the bug will go unnoticed because the function will simply continue as if it had no fidget. This could cause a much more subtle failure much farther down the road. Someone trying to debug this will be mystified: At best “it's behaving as though it had no fidget, but I know that one was set earlier”, and at worst “why is there two years of inconsistent data in the database?” This could take a very long time to track down. Even worse, it might never be noticed, and the method might quietly do the wrong thing every time it was used.
Without the extra check, the situation is much better: the function will throw an exception as soon as it tries to call a fidget method on the non-fidget object. The exception will point a big fat finger right at the problem: “hey, on line 2389 you tried to call the
rotatemethod on aSkunk::Stinkyobject, but that class has no such method`. Someone trying to debug this will immediately ask the right question: “Who put a skunk in there instead of a widget?”
It's easy to get this right. Instead of
if ($self->fidget && blessed $self->fidget eq 'Widget::Fidget') {
one can simply use:
if ($self->fidget) {
Moral of the story: programmers write too much code.
I am reminded of something chess master Aron Nimzovitch once said, maybe in Chess Praxis, that amateur chess players are always trying to be Doing Something.
[Other articles in category /prog/perl] permanent link
Wed, 04 Jul 2018
Jackson and Gregg on optimization
Today Brendan Gregg's blog has an article Evaluating the Evaluation: Benchmarking Checklist that begins:
A co-worker introduced me to Craig Hanson and Pat Crain's performance mantras, which neatly summarize much of what we do in performance analysis and tuning. They are:
Performance mantras
- Don't do it
- Do it, but don't do it again
- Do it less
- Do it later
- Do it when they're not looking
- Do it concurrently
- Do it cheaper
I found this striking because I took it to be an obvious reference Michael A. Jackson's advice in his brilliant 1975 book Principles of Program Design. Jackson said:
We follow two rules in the matter of optimization:
Rule 1: Don't do it.
Rule 2 (for experts only). Don't do it yet.
The intent of the two passages is completely different. Hanson and Crain are offering advice about what to optimize. “Don't do it” means that to make a program run faster, eliminate some of the things it does. “Do it, but don't do it again” means that to make a program run faster, have it avoid repeating work it has already done, say by caching results. And so on.
Jackson's advice is of a very different nature. It is only indirectly about improving the program's behavior. Instead it is addressing the programmer's behavior: stop trying to optimize all the damn time! It is not about what to optimize but whether, and Jackson says that to a first approximation, the answer is no.
Here are Jackson's rules with more complete context. The quotation is from the preface (page vii) and is discussing the style of the examples in his book:
Above all, optimization is avoided. We follow two rules in the matter of optimization:
Rule 1. Don't do it.
Rule 2 (for experts only). Don't do it yet — that is, not until you have a perfectly clear and unoptimized solution.Most programmers do too much optimization, and virtually all do it too early. This book tries to act as an antidote. Of course, there are systems which must be highly optimized if they are to be economically useful, and Chapter 12 discusses some relevant techniques. But two points should always be remembered: first, optimization makes a system less reliable and harder to maintain, and therefore more expensive to build and operate; second, because optimization obscures structure it is difficult to improve the efficiency of a system which is already partly optimized.
Here's some code I dealt with this month:
my $emailclass = $args->{emailclass};
if (!$emailclass && $args->{emailclass_name} ) {
# do some caching so if we're called on the same object over and over we don't have to do another find.
my $last_emailclass = $self->{__LAST_EMAILCLASS__};
if ( $last_emailclass && $last_emailclass->{name} eq $args->{emailclass_name} ) {
$emailclass = $last_emailclass->{emailclass};
} else {
$emailclass = $self->schema->resultset('EmailClass')
->find_by_name($args->{emailclass_name});
$self->{__LAST_EMAILCLASS__} = {
name => $args->{emailclass_name},
emailclass => $emailclass,
};
}
}
Holy cow, this is wrong in so many ways. 8 lines of this mess, for
what? To cache a single database lookup (the ->find_by_name call),
in a single object, if it happens to be looking for the same name as
last time. If caching was actually wanted, it should have been
addressed in the ->find_by_name call, which could do the caching
more generally, and which has some hope of knowing something about
when the cache entries should be expired. Even stipulating that
caching was wanted and for some reason should have been put here, why
such an elaborate mechanism, all to cache just the last lookup? It
could have been:
$emailclass = $self->emailclass_for_name($args->{emailclass_name});
...
sub emailclass_for_name {
my ($self, $name) = @_;
$self->{emailclass}{$name} //=
$self->schema->resultset('EmailClass')->find_by_name($name);
return $self->{emailclass}{$name};
}
I was able to do a bit better than this, and replaced the code with:
$emailclass = $self->schema->resultset('EmailClass')
->find_by_name($args->{emailclass_name});
My first thought was that the original caching code had been written by a very inexperienced programmer, someone who with more maturity might learn to do their job with less wasted effort. I was wrong; it had been written by a senior developer, someone who with more maturity might learn to do their job with less wasted effort.
The tragedy did not end there. Two years after the original code was written a more junior programmer duplicated the same unnecessary code elsewhere in the same module, saying:
I figured they must have had a reason to do it that way…
Thus is the iniquity of the fathers visited on the children.
In a nearby piece of code, an object A, on the first call to a certain method, constructed object B and cached it:
B->new(
base_path => ...
schema => $self->schema,
retry => ...,
);
Then on subsequent calls, it reused B from the cache.
But the cache was shared among many instances of A, not all of which
had the same ->schema member. So some of those instances of A
would ask B a question and get the answer from the wrong database.
A co-worker spent hours and hours in the middle of the night last
month tracking this down. Again, the cache was not only broken but
completely unnecesary. What was being saved? A single object
construction, probably a few hundred bytes and a few hundred
microseconds at most. And again, the code was perpetrated by a senior
developer who should have known better. My co-worker replaced 13
lines of broken code with four that worked.
Brendan Gregg is unusually clever, and an exceptional case. Most programmers are not Brendan Gregg, and should take Jackson's advice and stop trying to be so clever all the time.
[Other articles in category /prog] permanent link
Tue, 13 Feb 2018(If you already know about reservoir sampling, just skip to the good part.)
The basic reservoir sampling algorithm asks us to select a random item from a list, easy peasy, except:
- Each item must be selected with equal probability
- We don't know ahead of time how big the list is
- We may only make one pass over the list
- We may use only constant memory
Maybe the items are being read from a pipe or some other lazy data structure. There might be zillions of them, so we can't simply load them into an array. Obviously something like this doesn't work:
# Python
from random import random
selected = inputs.next()
for item in inputs:
if random() < 0.5:
selected = item
because it doesn't select the items with equal probability. Far from it! The last item is selected as often as all the preceding items put together.
The requirements may seem at first impossible to satisfy, but it can be done and it's not even difficult:
from random import random
n = 0
selected = None
for item in inputs:
n += 1
if random() < 1/n:
selected = item
The inputs here is some sort of generator that presents the list of
items, one at a time. After the loop completes, the selected item is
in selected. A proof that this selects each item equiprobably is
left as an easy exercise, or see this math StackExchange
post. A variation
for selecting !!k!! items instead of only one is quite easy.
The good part
Last week I thought of a different simple variation. Suppose each item !!s_i!! is presented along with an arbitrary non-negative weight !!w_i!!, measuring the relative likelihood of its being selected for the output. For example, an item with weight 6 should be selected twice as often as an item with weight 3, and three times as often as an item with weight 2.
The total weight is !!W = \sum w_i!! and at the end, whenever that is, we want to have selected each item !!s_i!! with probability !!\frac{w_i}{W}!!:
total_weight = 0
selected = None
for item, weight in inputs:
if weight == 0: continue
total += weight
if random() < weight/total:
selected = item
The correctness proof is almost the same. Clearly this reduces to the standard algorithm when all the weights are equal.
This isn't a major change, but it seems useful and I hadn't seen it before.
[Other articles in category /prog] permanent link
Thu, 30 Nov 2017Another public service announcement about Git.
There are a number of commands everyone learns when they first start out using Git. And there are some that almost nobody learns right away, but that should be the first thing you learn once you get comfortable using Git day to day.
One of these has the uninteresting-sounding name git-rev-parse. Git
has a bewildering variety of notations for referring to commits and
other objects. If you type something like origin/master~3, which
commit is that? git-rev-parse is your window into Git's
understanding of names:
% git rev-parse origin/master~3
37f2bc78b3041541bb4021d2326c5fe35cbb5fbb
A pretty frequent question is: How do I find out the commit ID of the current HEAD? And the answer is:
% git rev-parse HEAD
2536fdd82332846953128e6e785fbe7f717e117a
or if you want it abbreviated:
% git rev-parse --short HEAD
2536fdd
But more important than the command itself is the manual for the command. Whether you expect to use this command, you should read its manual. Because every command uses Git's bewildering variety of notations, and that manual is where the notations are completely documented.
When you use a ref name like master, Git finds it in
.git/refs/heads/master, but when you use origin/master, Git finds
it in .git/refs/remotes/origin/master, and when you use HEAD Git
finds it in .git/HEAD. Why the difference? The git-rev-parse
manual explains what Git is doing here.
Did you know that if you have an annoying long branch name like
origin/martin/f42876-change-tracking you can create a short alias
for it by sticking
ref: origin/martin/f42876-change-tracking
into .git/CT, and from then on you can do git log CT or git
rebase --onto CT or whatever?
Did you know that you can write topic@{yesterday} to mean “whatever
commit topic was pointing to yesterday”?
Did you know that you can write ':/penguin system' to refer to the most
recent commit whose commit message mentions the penguin system, and
that 'HEAD:/penguin system' means the most recent such commit on the
HEAD branch?
Did you know that there's a powerful sublanguage for ranges that you can
give to git-log to specify all sorts of useful things about which
commits you want to look at?
Once I got comfortable with Git I got in the habit of rereading the
git-rev-parse manual every few months, because each time I would
notice some new useful tool.
Check it out. It's an important next step.
[ Previous PSAs:
- Two things (beginners ought to know) about Git
- Git remote branches and Git's missing terminology
- Git's rejected push error
]
[Other articles in category /prog] permanent link
Thu, 16 Nov 2017[ Warning: This article is meandering and does not end anywhere in particular ]
My recent article about system software errors kinda blew up the Reddit / Hacker News space, and even got listed on Voat, which I understand is the Group W Bench where they send you if you aren't moral enough to be in Reddit. Many people on these fora were eager to tell war stories of times that they had found errors in the compiler or other infrastructural software.
This morning I remembered another example that had happened to me. In the middle 1990s, I was just testing some network program on one of the Sun Solaris machines that belonged to the Computational Linguistics program, when the entire machine locked up. I had to go into the machine room and power-cycle it to get it to come back up.
I returned to my desk to pick up where I had left off, and the machine locked up, again just as I ran my program. I rebooted the machine again, and putting two and two together I tried the next run on a different, less heavily-used machine, maybe my desk workstation or something.
The problem turned out to be a bug in that version of Solaris: if you bound a network socket to some address, and then tried to connect it to the same address, everything got stuck. I wrote a five-line demonstration program and we reported the bug to Sun. I don't know if it was fixed.
My boss had an odd immediate response to this, something along the lines that connecting a socket to itself is not a sanctioned use case, so the failure is excusable. Channeling Richard Stallman, I argued that no user-space system call should ever be able to crash the system, no matter what stupid thing it does. He at once agreed.
I felt I was on safe ground, because I had in mind the GNU GCC bug reporting instructions of the time, which contained the following unequivocal statement:
If the compiler gets a fatal signal, for any input whatever, that is a compiler bug. Reliable compilers never crash.
I love this paragraph. So clear, so pithy! And the second sentence! It could have been left off, but it is there to articulate the writer's moral stance. It is a rock-firm committment in a wavering and uncertain world.
Stallman was a major influence on my writing for a long time. I first encountered his work in 1985, when I was browsing in a bookstore and happened to pick up a copy of Dr. Dobb's Journal. That issue contained the very first publication of the GNU Manifesto. I had never heard of Unix before, but I was bowled over by Stallman's vision, and I read the whole thing then and there, standing up.

(It hit the same spot in my heart as Albert Szent-Györgyi's The Crazy Ape, which made a similarly big impression on me at about the same time. I think programmers don't take moral concerns seriously enough, and this is one reason why so many of them find Stallman annoying. But this is what I think makes Stallman so important. Perhaps Dan Bernstein is a similar case.)
I have very vague memories of perhaps finding a bug in gcc, which is
perhaps why I was familiar with that particular section of the gcc
documentation. But more likely I just read it because I read
a lot of stuff. Also Stallman was probably on my “read everything he
writes” list.
Why was I trying to connect a socket to itself, anyway? Oh, it was a bug. I meant to connect it somewhere else and used the wrong variable or something. If the operating system crashes when you try, that is a bug. Reliable operating systems never crash.
[ Final note: I looked for my five-line program that connected a
socket to itself, but I could not find it. But I found something
better instead: an email I sent in April 1993 reporting a program that
caused g++ version 2.3.3 to crash with an internal compiler error.
And yes, my report does quote the same passage I quoted above. ]
[Other articles in category /prog] permanent link
Sun, 12 Nov 2017
No, it is not a compiler error. It is never a compiler error.
When I used to hang out in the comp.lang.c Usenet group, back when
there was a comp.lang.c Usenet group, people would show up fairly
often with some program they had written that didn't work, and ask if
their compiler had a bug. The compiler did not have a bug. The
compiler never had a bug. The bug was always in the programmer's code
and usually in their understanding of the language.
When I worked at the University of Pennsylvania, a grad student posted to one of the internal bulletin boards looking for help with a program that didn't work. Another graduate student, a super-annoying know-it-all, said confidently that it was certainly a compiler bug. It was not a compiler bug. It was caused by a misunderstanding of the way arguments to unprototyped functions were automatically promoted.
This is actually a subtle point, obscure and easily misunderstood.
Most examples I have seen of people blaming the compiler are much
sillier. I used to be on the mailing list for discussing the
development of Perl 5, and people would show up from time to time to
ask if Perl's if statement was broken. This is a little
mind-boggling, that someone could think this. Perl was first released
in 1987. (How time flies!) The if statement is not exactly an
obscure or little-used feature. If there had been a bug in if it
would have been discovered and fixed by 1988. Again, the bug was
always in the programmer's code and usually in their understanding of
the language.
Here's something I wrote in October 2000,
which I think makes the case very clearly, this time concerning a
claimed bug in the stat() function, another feature that first
appeared in Perl 1.000:
On the one hand, there's a chance that the compiler has a broken
statand is subtracting 6 or something. Maybe that sounds likely to you but it sounds really weird to me. I cannot imagine how such a thing could possibly occur. Why 6? It all seems very unlikely.Well, in the absence of an alternative hypothesis, we have to take what we can get. But in this case, there is an alternative hypothesis! The alternative hypothesis is that [this person's] program has a bug.
Now, which seems more likely to you?
- Weird, inexplicable compiler bug that nobody has ever seen before
or
- Programmer fucked up
Hmmm. Let me think.
I'll take Door #2, Monty.
Presumably I had to learn this myself at some point. A programmer can waste a lot of time looking for the bug in the compiler instead of looking for the bug in their program. I have a file of (obnoxious) Good Advice for Programmers that I wrote about twenty years ago, and one of these items is:
Looking for a compiler bug is the strategy of LAST resort. LAST resort.
Anyway, I will get to the point. As I mentioned a few months ago, I built a simple phone app that Toph and I can use to find solutions to “twenty-four puzzles”. In these puzzles, you are given four single-digit numbers and you have to combine them arithmetically to total 24. Pennsylvania license plates have four digits, so as we drive around we play the game with the license plate numbers we see. Sometimes we can't solve a puzzle, and then we wonder: is it because there is no solution, or because we just couldn't find one? Then we ask the phone app.
The other day we saw the puzzle «5 4 5 1», which is very easy, but I asked the phone app, to find out if there were any other solutions that we missed. And it announced “No solutions.” Which is wrong. So my program had a bug, as my programs often do.
The app has a pre-populated dictionary containing all possible
solutions to all the puzzles that have solutions, which I generated
ahead of time and embedded into the app. My first guess was that bug
had been in the process that generated this dictionary, and that it
had somehow missed the solutions of «5 4 5 1». These would be indexed
under the key 1455, which is the same puzzle, because each list of
solutions is associated with the four input numbers in ascending
order. Happily I still had the original file containing the
dictionary data, but when I looked in it under 1455 I saw exactly
the two solutions that I expected to see.
So then I looked into the app itself to see where the bug was. Code Studio's underlying language is Javascript, and Code Studio has a nice debugger. I ran the app under the debugger, and stopped in the relevant code, which was:
var x = [getNumber("a"), getNumber("b"), getNumber("c"), getNumber("d")].sort().join("");
This constructs a hash key (x) that is used to index into the canned
dictionary of solutions. The getNumber() calls were retrieving the
four numbers from the app's menus, and I verified that the four
numbers were «5 4 5 1» as they ought to be. But what I saw next
astounded me: x was not being set to 1455 as it should have been.
It was set to 4155, which was not in the dictionary. And it was set
to 4155 because
the built-in sort() function
was sorting the numbers
into
the
wrong
order.

For a while I could not believe my eyes. But after another fifteen or thirty minutes of tinkering, I sent off a bug report… no, I did not. I still didn't believe it. I asked the front-end programmers at my company what my mistake had been. Nobody had any suggestions.
Then I sent off a bug report that began:
I think that Array.prototype.sort() returned a wrongly-sorted result when passed a list of four numbers. This seems impossible, but …
I was about 70% expecting to get a reply back explaining what I had
misunderstood about the behavior of Javascript's sort().
But to my astonishment, the reply came back only an hour later:
Wow! You're absolutely right. We'll investigate this right away.
In case you're curious, the bug was as follows: The sort() function
was using a bubble sort. (This is of course a bad choice, and I think
the maintainers plan to replace it.) The bubble sort makes several
passes through the input, swapping items that are out of order. It
keeps a count of the number of swaps in each pass, and if the number
of swaps is zero, the array is already ordered and the sort can stop
early and skip the remaining passes. The test for this was:
if (changes <= 1) break;
but it should have been:
if (changes == 0) break;
Ouch.
The Code Studio folks handled this very creditably, and did indeed fix it the same day. (The support system ticket is available for your perusal, as is the Github pull request with the fix, in case you are interested.)
I still can't quite believe it. I feel as though I have accidentally spotted the Loch Ness Monster, or Bigfoot, or something like that, a strange and legendary monster that until now I thought most likely didn't exist.
A bug in the sort() function. O day and night, but this is wondrous
strange!
[ Addendum 20171113: Thanks to Reddit user spotter for pointing me to a related 2008 blog post of Jeff Atwood's, “The First Rule of Programming: It's Always Your Fault”. ]
[ Addendum 20171113: Yes, yes, I know sort() is in the library, not in the compiler. I am using “compiler error” as a synecdoche
for “system software error”. ]
[ Addendum 20171116: I remembered examples of two other fundamental system software errors I have discovered, including one honest-to-goodness compiler bug. ]
[ Addendum 20200929: Russell O'Connor on a horrifying GCC bug ]
[Other articles in category /prog] permanent link
Mon, 19 Jun 2017On Saturday I posted an article explaining how remote branches and remote-tracking branches work in Git. That article is a prerequisite for this one. But here's the quick summary:
When dealing with a branch (say, master) copied from a remote repository (say, origin), there are three branches one must consider:
The copy of master in the local repository The copy of master in the remote repository The local branch origin/master that records the last known position of the remote branch
Branch 3 is known as a “remote-tracking branch”. This is because it tracks the remote branch, not because it is itself a remote branch. Actually it is a local copy of the remote branch. From now on I will just call it a “tracking branch”.The git-fetch command (green) copies branch (2) to (3).
The git-push command (red) copies branch (1) to (2), and incidentally updates (3) to match the new (2).
The diagram at right summarizes this.
We will consider the following typical workflow:
- Fetch the remote
masterbranch and check it out. - Do some work and commit it on the local
master. - Push the new work back to the remote.
But step 3 fails, saying something like:
! [rejected] master -> master (fetch first)
error: failed to push some refs to '../remote/'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
In older versions of Git the hint was a little shorter:
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Merge the remote changes (e.g. 'git pull')
hint: before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Everyone at some point gets one of these messages, and in my experience it is one of the most confusing and distressing things for beginners. It cannot be avoided, worked around, or postponed; it must be understood and dealt with.
Not everyone gets a clear explanation. (Reading it over, the actual message seems reasonably clear, but I know many people find it long and frighting and ignore it. It is tough in cases like this to decide how to trade off making the message shorter (and perhaps thereby harder to understand) or longer (and frightening people away). There may be no good solution. But here we are, and I am going to try to explain it myself, with pictures.)
In a large project, the remote branch is always moving, as other
people add to it, and they do this without your knowing about it.
Immediately after you do the fetch in step 1 above, the
tracking branch origin/master reflects the state of the
remote branch. Ten seconds later, it may not; someone else may have
come along and put some more commits on the remote branch in the
interval. This is a fundamental reality that new Git users must
internalize.
Typical workflow
We were trying to do this:
- Fetch the remote
masterbranch and check it out. - Do some work and commit it on the local
master. - Push the new work back to the remote.
and the failure occurred in step 3. Let's look at what each of these operations actually does.
1. Fetch the remote master branch and check it out.

git checkout master
The black circles at the top represent some commits that we want to
fetch from the remote repository. The fetch copies them to the local
repository, and the tracking branch origin/master points to
the local copy. Then we check out master and the local branch
master also points to the local copy.
Branch names like master or origin/master are called “refs”. At
this moment all three refs refer to the same commit (although there are
separate copies in the two repositories) and the three branches have
identical contents.
2. Do some work and commit it on the local master.

git add …
git commit …
…
The blue dots on the local master branch are your new commits. This
happens entirely inside your local repository and doesn't involve the
remote one at all.
But unbeknownst to you, something else is happening where you can't see it. Your collaborators or co-workers are doing their own work in their own repositories, and some of them have published this work to the remote repository. These commits are represented by the red dots in the remote repository. They are there, but you don't know it yet because you haven't looked at the remote repository since they appeared.
3. Push the new work back to the remote.

Here we are trying to push our local master, which means that we are
asking the remote repo to overwrite its master with our local
one. If the remote repo agreed to this, the red commits would be lost
(possibly forever!) and would be completely replaced by the blue
commits. The error message that is the subject of this article is Git
quite properly refusing to fulfill your request:
! [rejected] master -> master (fetch first)
error: failed to push some refs to '../remote/'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Let's read through that slowly:
Updates were rejected because the remote contains work that you do not have locally.
This refers specifically to the red commits.
This is usually caused by another repository pushing to the same ref.
In this case, the other repository is your co-worker's repo, not shown
in the diagram. They pushed to the same ref (master) before you did.
You may want to first integrate the remote changes (e.g., 'git pull ...') before pushing again.
This is a little vague. There are many ways one could conceivably “integrate the remote changes” and not all of them will solve the problem.
One alternative (which does not integrate the changes) is to use
git push -f. The -f is for “force”, and instructs the remote
repository that you really do want to discard the red commits in favor
of the blue ones. Depending on who owns it and how it is configured,
the remote repository may agree to this and discard the red commits,
or it may refuse. (And if it does agree, the coworker whose commits
you just destroyed may try to feed you poisoned lemonade, so
use -f with caution.)
See the 'Note about fast-forwards' in 'git push --help' for details.
To “fast-forward” the remote ref means that your local branch is a direct forward extension of the remote branch, containing everything that the remote branch does, in exactly the same order. If this is the case, overwriting the remote branch with the local branch is perfectly safe. Nothing will be lost or changed, because the local branch contains everything the remote branch already had. The only change will be the addition of new commits at the end.
There are several ways to construct such a local branch, and choosing between them depends on many factors including personal preference, your familiarity with the Git tool set, and the repository owner's policies. Discussing all of this is outside the scope of the article, so I'll just use one as an example: We are going to rebase the blue commits onto the red ones.
4. Refresh the tracking branch.

The first thing to do is to copy the red commits into the local repo;
we haven't even seen them yet. We do that as before, with
git-fetch. This updates the
tracking branch with a copy of the remote branch
just as it did in step 1.
If instead of git fetch origin master we did git pull --rebase
origin master, Git would do exactly the same fetch, and then
automatically do a rebase as described in the next section. If we did
git pull origin master without --rebase, it would do exactly the
same fetch, and then instead of a rebase it would do a merge, which I
am not planning to describe. The point to remember is that git pull
is just a convenient way to combine the commands of this section and
the next one, nothing more.
5. Rewrite the local changes.

Now is the moment when we “integrate the remote changes” with our own
changes. One way to do this is git rebase origin/master. This tells
Git to try to construct new commits that are just like the blue ones,
but instead of starting from the last black commit, they will start from the
last red one. (For more details about how this works,
see my talk slides about it.)
There are many alternatives here to rebase, some quite elaborate,
but that is a subject for another article, or several other articles.
If none of the files modified in the blue commits have also been modified in any of the red commits, there is no issue and everything proceeds automatically. And if some of the same files are modified, but only in non-overlapping portions, Git can automatically combine them. But if some of the files are modified in incompatible ways, the rebase process will stop in the middle and ask how to proceed, which is another subject for another article. This article will suppose that the rebase completed automatically. In this case the blue commits have been “rebased onto” the red commits, as in the diagram at right.
The diagram is a bit misleading here: it looks as though those black
and red commits appear in two places in the local repository, once on
the local master branch and once on the tracking branch. They don't.
The two branches share those commits, which are stored only once.
Notice that the command is git rebase origin/master. This is
different in form from git fetch origin master or git push origin
master. Why a slash instead of a space? Because with git-fetch or
git-push, we tell it the name of the remote repo, origin, and the
name of the remote branch we want to fetch or push, master. But
git-rebase operates locally and has no use for the name of a remote
repo. Instead, we give it the name of the branch onto which we want to
rebase the new commits. In this case, the target branch is the
tracking branch origin/master.
6. Try the push again.

We try the exact same git push origin master that failed in step 3,
and this time it succeeds, because this time the operation is a
“fast-forward”. Before, our blue commits would have replaced the red
commits. But our rewritten local branch does not have that problem: it
includes the red commits in exactly the same places as they are
already on the remote branch. When the remote repository replaces its
master with the one we are pushing, it loses nothing, because the
red commits are identical. All it needs to do is to add the
blue commits onto the end and then move its master ref forward to
point to the last blue commit instead of to the last red commit. This
is a “fast-forward”.
At this point, the push is successful, and the git-push command also
updates the tracking branch to reflect that the remote branch
has moved forward. I did not show this in the illustration.
But wait, what if someone else had added yet more commits to the
remote master while we were executing steps 4 and 5? Wouldn't our
new push attempt fail just like the first one did? Yes, absolutely!
We would have to repeat steps 4 and 5 and try a third time. It is
possible, in principle, to be completely prevented from pushing
commits to a remote repo because it is always changing so quickly that
you never get caught up on its current state. Repeated push failures
of this type are sign that the project is large enough that
repository's owner needs to set up a more structured code release
mechanism than “everyone lands stuff on master whenever they feel
like it”.
An earlier draft of this article ended at this point with “That is all I have to say about this.” Ha!
Unavoidable problems
Everyone suffers through this issue at some point or another. It is tempting to wonder if Git couldn't somehow make it easier for people to deal with. I think the answer is no. Git has multiple, distributed repositories. To abandon that feature would be to go back to the dark ages of galley slaves, smallpox, and SVN. But if you have multiple distributed anythings, you must face the issue of how to synchronize them. This is intrinsic to distributed systems: two components receive different updates at the same time, and how do you reconcile them?
For reasons I have discussed before, it does not appear possible to automate the reconciliation in every case in a source code control system, because sometimes the reconciliation may require going over to a co-worker's desk and arguing for two hours, then calling in three managers and the CTO and making a strategic decision which then has to be approved by a representative of the legal department. The VCS is not going to do this for you.
I'm going to digress a bit and then come back to the main point.
Twenty-five years ago I taught an introductory programming class in C.
The previous curriculum had tried hard to defer pointers to the middle
of the semester, as K&R does (chapter 7, I think). I decided this was
a mistake. Pointers are everywhere in C and without them you can't
call scanf or pass an array to a function (or access the command-line
arguments or operate on strings or use most of the standard library
or return anything that isn't a
number…). Looking back a few years later I wrote:
Pointers are an essential part of [C's] solution to the data hiding problem, which is an essential issue. Therefore, they cannot be avoided, and in fact should be addressed as soon as possible. … They presented themselves in the earliest parts of the material not out of perversity, but because they were central to the topic.
I developed a new curriculum that began treating pointers early on, as early as possible, and which then came back to them repeatedly, each time elaborating on the idea. This was a big success. I am certain that it is the right way to do it.
(And I've been intending since 2006 to write an article about K&R's crappy discussion of pointers and how its deficiencies and omissions have been replicated down the years by generation after generation of C programmers.)
I think there's an important pedagogical principle here. A good teacher makes the subject as simple as possible, but no simpler. Many difficult issues, perhaps most, can be ignored, postponed, hidden, prevaricated, fudged, glossed over, or even solved. But some must be met head-on and dealt with, and for these I think the sooner they are met and dealt with, the better.
Push conflicts in Git, like pointers in C, are not minor or peripheral; they are an intrinsic and central issue. Almost everyone is going to run into push conflicts, not eventually, but right away. They are going to be completely stuck until they have dealt with it, so they had better be prepared to deal with it right away.
If I were to write a book about Git, this discussion would be in chapter 2. Dealing with merge conflicts would be in chapter 3. All the other stuff could wait.
That is all I have to say about this. Thank you for your kind attention, and thanks to Sumana Harihareswara and AJ Jordan for inspiration.
[Other articles in category /prog] permanent link
Sat, 17 Jun 2017
Git remote branches and Git's missing terminology

Beginning and even intermediate Git users have several common problem areas, and one of these is the relationship between remote and local branches. I think the basic confusion is that it seems like there ought to be two things, the remote branch and the local one, and you copy back and forth between them. But there are not two but three, and the Git documentation does not clearly point this out or adopt clear terminology to distinguish between the three.
Let's suppose we have a remote repository, which could be called
anything, but is typically named origin. And we have a local
repository which has no name; it's just the local repo.
And let's suppose we're working on a branch named master, as one
often does.
There are not two but three branches of interest, and they might all be pointing to different commits:
The branch named
masterin the local repo. This is where we do our work and make our commits. This is the local branch. It is at the lower left in the diagram.The branch named
masterin the remote repo. This is the remote branch, at the top of the diagram. We cannot normally see this at all because it is (typically) on another computer and (typically) requires a network operation to interact with it. So instead, we mainly deal with…The branch named
origin/masterin the local repo. This is the tracking branch, at the lower right in the diagram.We never modify the tracking branch ourselves. It is automatically maintained for us by Git. Whenever Git communicates with the remote repo and learns something about the disposition of the remote
masterbranch, it updates the local branchorigin/masterto reflect what it has learned.
I think this triangle diagram is the first thing one ought to see when
starting to deal with remote repositories and with git-fetch and
git-push.
The Git documentation often calls the tracking branch the “remote-tracking branch”. It is important to understand that the remote-tracking branch is a local branch in the local repository. It is called the “remote-tracking” branch because it tracks the state of the remote branch, not because it is itself remote. From now on I will just call it the “tracking branch”.
Now let's consider a typical workflow:
We use
git fetch origin master. This copies the remote branchmasterfrom the remote repo to the tracking branchorigin/masterin the local repo. This is the green arrow in the diagram.If other people have added commits to the remote
masterbranch since our last fetch, now is when we find out what they are. We can compare the local branchmasterwith the tracking branchorigin/masterto see what is new. We might usegit log origin/masterto see the new commits, orgit diff origin/masterto compare the new versions of the files with the ones we had before. These commands do not look at the remote branch! They look at the copy of the remote branch that Git retrieved for us. If a long time elapses between the fetch and the compare, the actual remote branch might be in a completely different place than when we fetched at it.(Maybe you use
pullinstead offetch. Butpullis exactly likefetchexcept that it doesmergeorrebaseafter the fetch completes. So the process is the same; it merely combines this step and the next step into one command. )We decide how to combine our local master with
origin/master. We might usegit merge origin/masterto merge the two branches, or we might usegit rebase origin/masterto copy our new local commits onto the commits we just fetched. Or we could usegit reset --hard origin/masterto throw away our local commits (if any) and just take the ones on the tracking branch. There are a lot of things that could happen here, but the blue arrow in the diagram shows the general idea: we see new stuff inorigin/masterand update the localmasterto include that new stuff in some way.After doing some more work on the local
master, we want to publish the new work. We usegit push origin master. This is the red arrow in the diagram. It copies the localmasterto the remotemaster, updating the remotemasterin the process. If it is successful, it also updates the tracking branchorigin/masterto reflect the new position of the remotemaster.
In the last step, why is there no slash in git push origin master?
Because origin/master is the name of the tracking branch, and
the tracking branch is not involved. The push command gets
two arguments: the name of the remote (origin) and the branch to
push (master) and then it copies the local branch to the remote one
of the same name.
Deleting a branch
How do we delete branches? For the local branch, it's easy: git
branch -d master does it instantly.
For the tracking branch, we include the -r flag: git branch
-d -r origin/master. This deletes the tracking branch, and
has no effect whatever on the remote repo. This is a very unusual
thing to do.
To delete the remote branch, we have to use git-push because that
is the only way to affect the remote repo. We use git push origin
:master. As is usual with a push, if this is successful Git also
deletes the tracking branch origin/master.
This section has glossed over an important point: git branch -d
master does not delete the master branch, It only deletes the
ref, which is the name for the branch. The branch itself remains.
If there are other refs that refer to it, it will remain as long as
they do. If there are no other refs that point to it, it will be
deleted in due course, but not immediately. Until the branch is
actually deleted, its contents can be recovered.
Hackery
Another way to delete a local ref (whether tracking or not) is just to
go into the repository and remove it. The repository is usually in a
subdirectory .git of your working tree, and if you cd .git/refs
you can see where Git records the branch names and what they refer to.
The master branch is nothing more nor less than a file heads/master
in this directory, and its contents are the commit ID of the commit to
which it refers. If you edit this commit ID, you have pointed the
ref at a different commit. If you remove the file, the ref is
gone. It is that simple.
Tracking branches are similar. The origin/master ref is
in .git/refs/remotes/origin/master.
The remote master branch, of course, is not in your repository at
all; it's in the remote repository.
Poking around in Git's repository is fun and rewarding. (If it
worries you, make another clone of the repo, poke around in the clone,
and throw it away when you are finished poking.) Tinkering with the
refs is a good place to start Git repo hacking: create a couple of
branches, move them around, examine them, delete them again, all
without using git-branch. Git won't know the difference. Bonus fun
activity: HEAD is defined by the file .git/HEAD. When you make a
new commit, HEAD moves forward. How does that
work?
There is a
gitrepository-layout manual
that says what else you can find in the repository.
Failed pushes
We're now in a good position to understand one of the most common problems that Git beginners face: they have committed some work, and they want to push it to the remote repository, but Git says
! [rejected] master -> master (fetch first)
error: failed to push some refs to 'remote'
something something fast-forward, whatever that is
My article explaining this will appear here on Monday. (No, I really mean it.)
Terminology problems
I think one of the reasons this part of Git is so poorly understood is
that there's a lack of good terminology in this area. There needs to
be a way to say "the local branch named master” and “the branch
named master in the remote named origin” without writing a five-
or nine-word phrase every time. The name origin/master looks like
it might be the second of these, but it isn't. The documentation uses
the descriptive but somewhat confusing term “remote-tracking branch”
to refer to it. I think abbreviating this to “tracking branch” would
tend to clear things up more than otherwise.
I haven't though of a good solution to the rest of it yet. It's
tempting to suggest that we should abbreviate “the branch named
master in the remote named origin” to something like
“origin:master” but I think that would be a disaster. It would be
too easy to confuse with origin/master and also with the use of the
colon in the refspec arguments to git-push. Maybe something like
origin -> master that can't possibly be mistaken for part of a shell
command and that looks different enough from origin/master to make
clear that it's related but not the same thing.
Git piles yet another confusion on this:
$ git checkout master
Branch master set up to track remote branch master from origin.
This sounds like it has something to with the remote-tracking branch,
but it does not! It means that the local branch master has been
associated with the remote origin so that fetches and pushes that
pertain to it will default to using that remote.
I will think this over and try to come up with something that sucks a little less. Suggestions are welcome.
[Other articles in category /prog] permanent link
Thu, 16 Feb 2017
Automatically checking for syntax errors with Git's pre-commit hook
Previous related article
Earlier related article
Over the past couple of days I've written about how I committed a syntax error on a cron script, and a co-worker had to fix it on Saturday morning. I observed that I should have remembered to check the script for syntax errors before committing it, and several people wrote to point out to me that this is the sort of thing one should automate.
(By the way, please don't try to contact me on Twitter. It won't work. I have been on Twitter Vacation for months and have no current plans to return.)
Git has a “pre-commit hook” feature, which means that you can set up a program that will be run every time you attempt a commit, and which can abort the commit if it doesn't like what it sees. This is the natural place to put an automatic syntax check. Some people suggested that it should be part of the CI system, or even the deployment system, but I don't control those, and anyway it is much better to catch this sort of thing as early as possible. I decided to try to implement a pre-commit hook to check syntax.
Unlike some of the git hooks, the pre-commit hook is very simple to use. It gets run when you try to make a commit, and the commit is aborted if the hook exits with a nonzero status.
I made one mistake right off the bat: I wrote the hook in Bourne shell, even though I swore years ago to stop writing shell scripts. Everything that I want to write in shell should be written in Perl instead or in some equivalently good language like Python. But the sample pre-commit hook was written in shell and when I saw it I went into automatic shell scripting mode and now I have yet another shell script that will have to be replaced with Perl when it gets bigger. I wish I would stop doing this.
Here is the hook, which, I should say up front, I have not yet tried in day-to-day use. The complete and current version is on github.
#!/bin/bash
function typeof () {
filename=$1
case $filename in
*.pl | *.pm) echo perl; exit ;;
esac
line1=$(head -1 $1)
case $line1 in '#!'*perl )
echo perl; exit ;;
esac
}
Some of the sample programs people showed me decided which files
needed to be checked based only on the filename. This is not good
enough. My most important Perl programs have filenames with no
extension. This typeof function decides which set of checks to
apply to each file, and the minimal demonstration version here can do
that based on filename or by looking for the #!...perl line in the
first line of the file contents. I expect that this function will
expand to include other file types; for example
*.py ) echo python; exit ;;
is an obvious next step.
if [ ! -z $COMMIT_OK ]; then
exit 0;
fi
This block is an escape hatch. One day I will want to bypass the hook
and make a commit without performing the checks, and then I can
COMMIT_OK=1 git commit …. There is actually a --no-verify flag to
git-commit that will skip the hook entirely, but I am unlikely to
remember it.

(I am also unlikely to remember COMMIT_OK=1. But I know from
experience that I will guess that I might have put an escape hatch
into the hook. I will also guess that there might be a flag to
git-commit that does what I want, but that will seem less likely to
be true, so I will look in the hook program first. This will be a
good move because my hook is much shorter than the git-commit man
page. So I will want the escape hatch, I will look for it in the best place,
and I will find it. That is worth two lines of code. Sometimes I feel
like the guy in Memento. I have not yet resorted to tattooing
COMMIT_OK=1 on my chest.)
exec 1>&2
This redirects the standard output of all subsequent commands to go to
standard error instead. It makes it more convenient to issue error
messages with echo and such like. All the output this hook produces
is diagnostic, so it is appropriate for it to go to standard error.
allOK=true
badFiles=
for file in $(git diff --cached --name-only | sort) ; do
allOK is true if every file so far has passed its checks.
badFiles is a list of files that failed their checks. the
git diff --cached --name-only function interrogates the Git index
for a list of the files that have been staged for commit.
type=$(typeof "$file")
This invokes the typeof function from above to decide the type of
the current file.
BAD=false
When a check discovers that the current file is bad, it will signal
this by setting BAD to true.
echo
echo "## Checking file $file (type $type)"
case $type in
perl )
perl -cw $file || BAD=true
[ -x $file ] || { echo "File is not executable"; BAD=true; }
;;
* )
echo "Unknown file type: $file; no checks"
;;
esac
This is the actual checking. To check Python files, we would add a
python) … ;; block here. The * ) case is a catchall. The perl
checks run perl -cw, which does syntax checking without executing
the program. It then checks to make sure the file is executable, which
I am sure is a mistake, because these checks are run for .pm files,
which are not normally supposed to be executable. But I wanted to
test it with more than one kind of check.
if $BAD; then
allOK=false;
badFiles="$badFiles;$file"
fi
done
If the current file was bad, the allOK flag is set false, and the
commit will be aborted. The current filename is appended to badFiles
for a later report. Bash has array variables but I don't remember how
they work and the manual made it sound gross. Already I regret not
writing this in a real language.
After the modified files have been checked, the hook exits successfully if they were all okay, and prints a summary if not:
if $allOK; then
exit 0;
else
echo ''
echo '## Aborting commit. Failed checks:'
for file in $(echo $badFiles | tr ';' ' '); do
echo " $file"
done
exit 1;
fi
This hook might be useful, but I don't know yet; as I said, I haven't
really tried it. But I can see ahead of time that it has a couple of
drawbacks. Of course it needs to be built out with more checks. A
minor bug is that I'd like to apply that is-executable check to Perl
files that do not end in .pm, but that will be an easy fix.
But it does have one serious problem I don't know how to fix yet. The hook checks the versions of the files that are in the working tree, but not the versions that are actually staged for the commit!
The most obvious problem this might cause is that I might try to commit some files, and then the hook properly fails because the files are broken. Then I fix the files, but forget to add the fixes to the index. But because the hook is looking at the fixed versions in the working tree, the checks pass, and the broken files are committed!
A similar sort of problem, but going the other way, is that I might
make several changes to some file, use git add -p to add the part I
am ready to commit, but then the commit hook fails, even though the
commit would be correct, because the incomplete changes are still in
the working tree.
I did a little tinkering with git stash save -k to try to stash the
unstaged changes before running the checks, something like this:
git stash save -k "pre-commit stash" || exit 2
trap "git stash pop" EXIT
but I wasn't able to get anything to work reliably. Stashing a modified index has never worked properly for me, perhaps because there is something I don't understand. Maybe I will get it to work in the future. Or maybe I will try a different method; I can think of several offhand:
The hook could copy each file to a temporary file and then run the check on the temporary file. But then the diagnostics emitted by the checks would contain the wrong filenames.
It could move each file out of the way, check out the currently-staged version of the file, check that, and then restore the working tree version. (It can skip this process for files where the staged and working versions are identical.) This is not too complicated, but if it messes up it could catastrophically destroy the unstaged changes in the working tree.
Check out the entire repository and modified index into a fresh working tree and check that, then discard the temporary working tree. This is probably too expensive.
This one is kind of weird. It could temporarily commit the current index (using
--no-verify), stash the working tree changes, and check the files. When the checks are finished, it would unstash the working tree changes, usegit-reset --softto undo the temporary commit, and proceed with the real commit if appropriate.Come to think of it, this last one suggests a much better version of the same thing: instead of a pre-commit hook, use a post-commit hook. The post-commit hook will stash any leftover working tree changes, check the committed versions of the files, unstash the changes, and, if the checks failed, undo the commit with
git-reset --soft.
Right now the last one looks much the best but perhaps there's something straightforward that I didn't think of yet.
[ Thanks to Adam Sjøgren, Jeffrey McClelland, and Jack Vickeridge for discussing this with me. Jeffrey McClelland also suggested that syntax checks could be profitably incorporated as a post-receive hook, which is run on the remote side when new commits are pushed to a remote. I said above that running the checks in the CI process seems too late, but the post-receive hook is earlier and might be just the thing. ]
[ Addendum: Daniel Holz wrote to tell me that the Yelp pre-commit frameworkhandles the worrisome case of unstaged working tree changes. The strategy is different from the ones I suggested above. If I'm reading this correctly, it records the unstaged changes in a patch file, which it sticks somewhere, and then checks out the index. If all the checks succeed, it completes the commit and then tries to apply the patch to restore the working tree changes. The checks in Yelp's framework might modify the staged files, and if they do, the patch might not apply; in this case it rolls back the whole commit. Thank you M. Holtz! ]
[Other articles in category /prog] permanent link
Tue, 14 Feb 2017
More thoughts on a line of code with three errors
Yesterday I wrote, in great irritation, about a line of code I had written that contained three errors.
I said:
What can I learn from this? Most obviously, that I should have tested my code before I checked it in.
Afterward, I felt that this was inane, and that the matter required a little more reflection. We do not test every single line of every program we write; in most applications that would be prohibitively expensive, and in this case it would have been excessive.
The change I was making was in the format of the diagnostic that the program emitted as it finished to report how long it had taken to run. This is not an essential feature. If the program does its job properly, it is of no real concern if it incorrectly reports how long it took to run. Two of my errors were in the construction of the message. The third, however, was a syntax error that prevented the program from running at all.
Having reflected on it a little more, I have decided that I am only really upset about the last one, which necessitated an emergency Saturday-morning repair by a co-worker. It was quite acceptable not to notice ahead of time that the report would be wrong, to notice it the following day, and to fix it then. I would have said “oops” and quietly corrected the code without feeling like an ass.
The third problem, however, was serious. And I could have prevented it with a truly minimal amount of effort, just by running:
perl -cw the-script
This would have diagnosed the syntax error, and avoided the main problem at hardly any cost. I think I usually remember to do something like this. Had I done it this time, the modified script would have gone into production, would have run correctly, and then I could have fixed the broken timing calculation on Monday.
In the previous article I showed the test program that I wrote to test the time calculation after the program produced the wrong output. I think it was reasonable to postpone writing this until after program ran and produced the wrong output. (The program's behavior in all other respects was correct and unmodified; it was only its report about its running time that was incorrect.) To have written the test ahead of time might be an excess of caution.
There has to be a tradeoff between cautious preparation and risk. Here I put everything on the side of risk, even though a tiny amount of caution would have eliminated most of the risk. In my haste, I made a bad trade.
[ Addendum 20170216: I am looking into automating the perl -cw check. ]
[Other articles in category /prog] permanent link
Mon, 12 Dec 2016
Another Git catastrophe cleaned up
My co-worker X had been collaborating with a front-end designer on a very large change, consisting of about 406 commits in total. The sum of the changes was to add 18 new files of code to implement the back end of the new system, and also to implement the front end, a multitude of additions to both new and already-existing files. Some of the 406 commits modified just the 18 back-end files, some modified just the front-end files, and many modified both.
X decided to merge and deploy just the back-end changes, and then, once that was done and appeared successful, to merge the remaining front-end changes.
His path to merging the back-end changes was unorthodox: he checked
out the current master, and then, knowing that the back-end changes
were isolated in 18 entirely new files, did
git checkout topic-branch -- new-file-1 new-file-2 … new-file-18
He then added the 18 files to the repo, committed them, and published
the resulting commit on master. In due course this was deployed to
production without incident.
The next day he wanted to go ahead and merge the front-end changes,
but he found himself in “a bit of a pickle”. The merge didn't go
forward cleanly, perhaps because of other changes that had been made
to master in the meantime. And trying to rebase the branch onto the
new master was a complete failure. Many of those 406 commits included
various edits to the 18 back-end files that no longer made sense now
that the finished versions of those files were in the master branch
he was trying to rebase onto.
So the problem is: how to land the rest of the changes in those 406 commits, preferably without losing the commit history and messages.
The easiest strategy in a case like this is usually to back in time:
If the problem was caused by the unorthodox checkout-add-commit, then
reset master to the point before that happened and try doing it a
different way. That strategy wasn't available because X had already
published the master with his back-end files, and a hundred other
programmers had copies of them.
The way I eventually proceeded was to rebase the 406-commit work
branch onto the current master, but to tell Git meantime that
conflicts in the 18 back-end files should be ignored, because the
version of those files on the master branch was already perfect.
Merge drivers
There's no direct way to tell Git to ignore merge conflicts in exactly
18 files, but there is a hack you can use to get the same effect.
The repo can contain a .gitattributes file that lets you specify
certain per-file options. For example, you can use .gitattributes
to say that the files in a certain directory are text, that when they
are checked out the line terminators should be converted to whatever
the local machine's line terminator convention is, and they should be
converted back to NLs when changes are committed.
Some of the per-file attributes control how merge conflicts are resolved. We were already using this feature for a certain frequently-edited file that was a list of processes to be performed in a certain order:
do A
then do B
Often different people would simultaneously add different lines to the end of this file:
# Person X's change:
do A
then do B
then do X
# Person Y's change:
do A
then do B
then do Y
X would land their version on master and later there would be a
conflict when Y tried to land their own version:
do A
then do B
<<<<<<<<
then do X
--------
then do Y
>>>>>>>>
Git was confused: did you want new line X or new line Y at the end of the file, or both, and if both then in what order? But the answer was always the same: we wanted both, X and then Y, in that order:
do A
then do B
then do X
then do Y
With the merge attribute set to union for this file, Git
automatically chooses the correct resolution.
So, returning to our pickle, I wanted to set the merge attribute for
the 18 back-end files to tell Git to always choose the version already
in master, and always ignore the changes from the branch I was
merging.
There is not exactly a way to do this, but the mechanism that is provided is extremely general, and it is not hard to get it to do what we want in this case.
The merge attribute in .gitattributes specifies the name of a
“driver” that resolves merge conflicts. The driver can be one of a
few built-in drivers, such as the union driver I just described, or
it can be the name of a user-supplied driver, configured in
.gitconfig. The first step is to use .gitattributes to tell Git
to use our private, special-purpose driver for the 18 back-end files:
new-file-1 merge=ours
new-file-2 merge=ours
…
new-file-18 merge=ours
(The name ours here is completely arbitrary. I chose it because its
function was analogous to the -s ours and -X ours options of
git-merge.)
Then we add a section to .gitconfig to say what the
ours driver should do:
[merge "ours"]
name = always prefer our version to the one being merged
driver = true
The name is just a human-readable description and is ignored by Git.
The important part is the deceptively simple-appearing driver = true
line. The driver is actually a command that is run when there is
a merge conflict. The command is run with the names of three files
containing different versions of the target file: the main file
being merged into, and temporary files containing the version with the
conflicting changes and the common ancestor of the first two files. It is
the job of the driver command to examine the three files, figure out how to
resolve the conflict, and modify the main file appropriately.
In this case merging the two or three versions of the file is very
simple. The main version is the one on the master branch, already
perfect. The proposed changes are superfluous, and we want to ignore
them. To modify the main file appropriately, our merge driver command
needs to do exactly nothing. Unix helpfully provides a command that
does exactly nothing, called true, so that's what we tell Git to use
to resolve merge conflicts.
With this configured, and the changes to .gitattributes checked in,
I was able to rebase the 406-commit topic branch onto the current
master. There were some minor issues to work around, so it was not
quite routine, but the problem was basically solved and it wasn't a
giant pain.
I didn't actually use git-rebase
I should confess that I didn't actually use git-rebase at this
point; I did it semi-manually, by generating a list of commit IDs and
then running a loop that cherry-picked them one at a time:
tac /tmp/commit-ids |
while read commit; do
git cherry-pick $commit || break
done
I don't remember why I thought this would be a better idea than just
using git-rebase, which is basically the same thing. (Superstitious anxiety,
perhaps.) But I think the process and the result were pretty much the
same. The main drawback of my approach is that if one of the
cherry-picks fails, and the loop exits prematurely, you have to
hand-edit the commit-ids file before you restart the loop, to remove the commits that were
successfully picked.
Also, it didn't work on the first try
My first try at the rebase didn't quite work. The merge driver was
working fine, but some commits that it wanted to merge modified only
the 18 back-end files and nothing else. Then there were merge
conflicts, which the merge driver said to ignore, so that the net
effect of the merged commit was to do nothing. But git-rebase
considers that an error, says something like
The previous cherry-pick is now empty, possibly due to conflict resolution.
If you wish to commit it anyway, use:
git commit --allow-empty
and stops and waits for manual confirmation. Since 140 of the 406 commits modified only the 18 perfect files I was going to have to intervene manually 140 times.
I wanted an option that told git-cherry-pick that empty commits were
okay and just to ignore them entirely, but that option isn't in
there. There is something almost as good though; you can supply
--keep-redundant-commits and instead of failing it will go ahead and create commits
that make no changes. So I ended up with a branch with 406 commits of
which 140 were empty. Then a second git-rebase eliminated them,
because the default behavior of git-rebase is to discard empty
commits. I would have needed that final rebase anyway, because I had
to throw away the extra commit I added at the beginning to check in
the changes to the .gitattributes file.
A few conflicts remained
There were three or four remaining conflicts during the giant rebase, all resulting from the following situation: Some of the back-end files were created under different names, edited, and later moved into their final positions. The commits that renamed them had unresolvable conflicts: the commit said to rename A to B, but to Git's surprise B already existed with different contents. Git quite properly refused to resolve these itself. I handled each of these cases manually by deleting A.
I made this up as I went along
I don't want anyone to think that I already had all this stuff up my sleeve, so I should probably mention that there was quite a bit of this I didn't know beforehand. The merge driver stuff was all new to me, and I had to work around the empty-commit issue on the fly.
Also, I didn't find a working solution on the first try; this was my second idea. My notes say that I thought my first idea would probably work but that it would have required more effort than what I described above, so I put it aside planning to take it up again if the merge driver approach didn't work. I forget what the first idea was, unfortunately.
Named commits
This is a minor, peripheral technique which I think is important for everyone to know, because it pays off far out of proportion to how easy it is to learn.
There were several commits of interest that I referred to repeatedly while investigating and fixing the pickle. In particular:
- The last commit on the topic branch
- The first commit on the topic branch that wasn't on
master - The commit on
masterfrom which the topic branch diverged
Instead of trying to remember the commit IDs for these I just gave
them mnemonic names with git-branch: last, first, and base,
respectively. That enabled commands like git log base..last … which
would otherwise have been troublesome to construct. Civilization
advances by extending the number of important operations which we can
perform without thinking of them. When you're thinking "okay, now I
need to rebase this branch" you don't want to derail the train of
thought to remember where the bottom of the branch is every time.
Being able to refer to it as first is a big help.
Other approaches
After it was all over I tried to answer the question “What should X
have done in the first place to avoid the pickle?” But I couldn't
think of anything, so I asked Rik Signes. Rik immediately said that
X should have used git-filter-branch to separate the 406 commits
into two branches, branch A with just the changes to the 18 back-end
files and branch B with just the changes to the other files. (The
two branches together would have had more than 406 commits, since a
commit that changed both back-end and front-end files would be
represented in both branches.) Then he would have had no trouble
landing branch A on master and, after it was deployed, landing
branch B.
At that point I realized that git-filter-branch also provided a less
peculiar way out of the pickle once we were in: Instead of using my
merge driver approach, I could have filtered the original topic branch
to produce just branch B, which would have rebased onto master
just fine.
I was aware that git-filter-branch was not part of my personal
toolkit, but I was unaware of the extent of my unawareness. I would
have hoped that even if I hadn't known exactly how to use it, I would
at least have been able to think of using it. I plan to
set aside an hour or two soon to do nothing but mess around with
git-filter-branch so that next time something like this happens I
can at least consider using it.
It occurred to me while I was writing this that it would probably have
worked to make one commit on master to remove the back-end files
again, and then rebase the entire topic branch onto that commit. But
I didn't think of it at the time. And it's not as good as what I did
do, which left the history as clean as was possible at that point.
I think I've written before that this profusion of solutions is the sign of a well-designed system. The tools and concepts are powerful, and can be combined in many ways to solve many problems that the designers didn't foresee.
[Other articles in category /prog] permanent link
Thu, 21 Jul 2016
A hack for getting the email address Git will use for a commit
Today I invented a pretty good hack.
Suppose I have branch topic checked out. It often happens that I want to
git push origin topic:mjd/topic
which pushes the topic branch to the origin repository, but on
origin it is named mjd/topic instead of topic. This is a good
practice when many people share the same repository. I wanted to write
a program that would do this automatically.
So the question arose, how should the program figure out the mjd
part? Almost any answer would be good here: use some selection of
environment variables, the current username, a hard-wired default, and
the local part of Git's user.email configuration setting, in some
order. Getting user.email is easy (git config get user.email) but
it might not be set and then you get nothing. If you make a commit
but have no user.email, Git doesn't mind. It invents an address
somehow. I decided that I would like my program to to do exactly what
Git does when it makes a commit.
But what does Git use for the committer's email address if there is
no user.email set? This turns out to be complicated. It consults
several environment variables in some order, as I suggested before.
(It is documented in
git-commit-tree if you
are interested.) I did not want to duplicate Git's complicated
procedure, because it might change, and because duplicating code is a
sin. But there seemed to be no way to get Git to disgorge this value,
short of actually making a commit and examining it.
So I wrote this command, which makes a commit and examines it:
git log -1 --format=%ce $(git-commit-tree HEAD^{tree} < /dev/null)
This is extremely weird, but aside from that it seems to have no concrete drawbacks. It is pure hack, but it is a hack that works flawlessly.
What is going on here? First, the $(…) part:
git-commit-tree HEAD^{tree} < /dev/null
The git-commit-tree command is what git-commit uses to actually
create a commit. It takes a tree object, reads a commit message from
standard input, writes a new commit object, and prints its SHA1 hash
on standard output. Unlike git-commit, it doesn't modify the index
(git-commit would use git-write-tree to turn the index into a tree
object) and it doesn't change any of the refs (git-commit would
update the HEAD ref to point to the new commit.) It just creates
the commit.
Here we could use any tree, but the tree of the HEAD commit is
convenient, and HEAD^{tree} is its name. We supply an empty commit
message from /dev/null.
Then the outer command runs:
git log -1 --format=%ce $(…)
The $(…) part is replaced by the SHA1 hash of the commit we just
created with git-commit-tree. The -1 flag to git-log gets the
log information for just this one commit, and the --format=%ce tells
git-log to print out just the committer's email address, whatever it
is.
This is fast—nearly instantaneous—and cheap. It doesn't change the state of the repository, except to write a new object, which typically takes up 125 bytes. The new commit object is not attached to any refs and so will be garbage collected in due course. You can do it in the middle of a rebase. You can do it in the middle of a merge. You can do it with a dirty index or a dirty working tree. It always works.
(Well, not quite. It will fail if run in an empty repository, because
there is no HEAD^{tree} yet. Probably there are some other
similarly obscure failure modes.)
I called the shortcut git-push program
git-pusho
but I dropped the email-address-finder into
git-get,
which is my storehouse of weird “How do I find out X” tricks.
I wish my best work of the day had been a little bit more significant, but I'll take what I can get.
[ Addendum: Twitter user @shachaf has reminded me that the right way to do this is
git var GIT_COMMITTER_IDENT
which prints out something like
Mark Jason Dominus (陶敏修) <mjd@plover.com> 1469102546 -0400
which you can then parse. @shachaf also points out that a Stack Overflow discussion of this very question contains a comment suggesting the same weird hack! ]
[Other articles in category /prog] permanent link
Thu, 14 Jul 2016
Surprising reasons to use a syntax-coloring editor
[ Danielle Sucher reminded me of this article I wrote in 1998, before I had a blog, and I thought I'd repatriate it here. It should be interesting as a historical artifact, if nothing else. Thanks Danielle! ]
I avoided syntax coloring for years, because it seemed like a pretty stupid idea, and when I tried it, I didn't see any benefit. But recently I gave it another try, with Ilya Zakharevich's `cperl-mode' for Emacs. I discovered that I liked it a lot, but for surprising reasons that I wasn't expecting.
I'm not trying to start an argument about whether syntax coloring is good or bad. I've heard those arguments already and they bore me to death. Also, I agree with most of the arguments about why syntax coloring is a bad idea. So I'm not trying to argue one way or the other; I'm just relating my experiences with syntax coloring. I used to be someone who didn't like it, but I changed my mind.
When people argue about whether syntax coloring is a good idea or not, they tend to pull out the same old arguments and dust them off. The reasons I found for using syntax coloring were new to me; I'd never seen anyone mention them before. So I thought maybe I'd post them here.
Syntax coloring is when the editor understands something about the
syntax of your program and displays different language constructs in
different fonts. For example, cperl-mode displays strings in
reddish brown, comments in a sort of brick color, declared variables
(in my) in gold, builtin function names (defined) in green,
subroutine names in blue, labels in teal, and keywords (like my and
foreach) in purple.
The first thing that I noticed about this was that it was easier to recognize what part of my program I was looking at, because each screenful of the program had its own color signature. I found that I was having an easier time remembering where I was or finding that parts I was looking for when I scrolled around in the file. I wasn't doing this consciously; I couldn't describe the color scheme any particular part of the program was, but having red, gold, and purple blotches all over made it easier to tell parts of the program apart.
The other surprise I got was that I was having more fun programming. I felt better about my programs, and at the end of the day, I felt better about the work I had done, just because I'd spent the day looking at a scoop of rainbow sherbet instead of black and white. It was just more cheerful to work with varicolored text than monochrome text. The reason I had never noticed this before was that the other coloring editors I used had ugly, drab color schemes. Ilya's scheme won here by using many different hues.
I haven't found many of the other benefits that people say they get from syntax coloring. For example, I can tell at a glance whether or not I failed to close a string properly—unless the editor has screwed up the syntax coloring, which it does often enough to ruin the benefit for me. And the coloring also slows down the editor. But the two benefits I've described more than outweigh the drawbacks for me. Syntax coloring isn't a huge win, but it's definitely a win.
If there's a lesson to learn from this, I guess it's that it can be valuable to revisit tools that you rejected, to see if you've changed your mind. Nothing anyone said about it was persuasive to me, but when I tried it I found that there were reasons to do it that nobody had mentioned. Of course, these reasons might not be compelling for anyone else.
Addenda 2016
Looking back on this from a distance of 18 years, I am struck by the following thoughts:
Syntax highlighting used to make the editor really slow. You had to make a real commitment to using it or not. I had forgotten about that. Another victory for Moore’s law!
Programmers used to argue about it. Apparently programmers will argue about anything, no matter how ridiculous. Well okay, this is not a new observation. Anyway, this argument is now finished. Whether people use it or not, they no longer find the need to argue about it. This is a nice example that sometimes these ridiculous arguments eventually go away.
I don't remember why I said that syntax highlighting “seemed like a pretty stupid idea”, but I suspect that I was thinking that the wrong things get highlighted. Highlighters usually highlight the language keywords, because they're easy to recognize. But this is like highlighting all the generic filler words in a natural language text. The words you want to see are exactly the opposite of what is typically highlighted.
Syntax highlighters should be highlighting the semantic content like expression boundaries, implied parentheses, boolean subexpressions, interpolated variables and other non-apparent semantic features. I think there is probably a lot of interesting work to be done here. Often you hear programmers say things like “Oh, I didn't see the that the trailing comma was actually a period.” That, in my opinion, is the kind of thing the syntax highlighter should call out. How often have you heard someone say “Oh, I didn't see that
whilethere”?I have been misspelling “arguments” as “argmuents” for at least 18 years.
[Other articles in category /prog] permanent link
Fri, 15 Apr 2016
How to recover lost files added to Git but not committed
If you lose something [in Git], don't panic. There's a good chance that you can find someone who will be able to hunt it down again.
I was not expecting to have a demonstration ready so soon. But today
I finished working on a project, I had all the files staged in the
index but not committed, and for some reason I no longer remember I
chose that moment to do git reset --hard, which throws away the
working tree and the staged files. I may have thought I had
committed the changes. I hadn't.
If the files had only been in the working tree, there would have been nothing to do but to start over. Git does not track the working tree. But I had added the files to the index. When a file is added to the Git index, Git stores it in the repository. Later on, when the index is committed, Git creates a commit that refers to the files already stored. If you know how to look, you can find the stored files even before they are part of a commit.
(If they are part of a commit, the problem is much easier.
Typically the answer is simply “use git-reflog to find the commit
again and check it out”. The git-reflog command is probably the
first thing anyone should learn on the path from being a Git beginner
to becoming an intermediate Git user.)
Each file added to the Git index is stored as a “blob object”. Git
stores objects in two ways. When it's fetching a lot of objects from
a remote repository, it gets a big zip file with an attached table of
contents; this is called a pack. Getting objects from a pack can be
a pain. Fortunately, not all objects are in packs. When when you just
use git-add to add a file to the index, git makes a single object,
called a “loose” object. The loose object is basically the file
contents, gzipped, with a header attached. At some point Git will
decide there are too many loose objects and assemble them into a pack.
To make a loose object from a file, the contents of the file are checksummed, and the checksum is used as the name of the object file in the repository and as an identifier for the object, exactly the same as the way git uses the checksum of a commit as the commit's identifier. If the checksum is 0123456789abcdef0123456789abcdef01234567, the object is stored in
.git/objects/01/23456789abcdef0123456789abcdef01234567
The pack files are elsewhere, in .git/objects/pack.
So the first thing I did was to get a list of the loose objects in the repository:
cd .git/objects
find ?? -type f | perl -lpe 's#/##' > /tmp/OBJ
This produces a list of the object IDs of all the loose objects in the repository:
00f1b6cc1dfc1c8872b6d7cd999820d1e922df4a
0093a412d3fe23dd9acb9320156f20195040a063
01f3a6946197d93f8edba2c49d1bb6fc291797b0
…
ffd505d2da2e4aac813122d8e469312fd03a3669
fff732422ed8d82ceff4f406cdc2b12b09d81c2e
There were 500 loose objects in my repository. The goal was to find the eight I wanted.
There are several kinds of objects in a Git repository. In addition
to blobs, which represent file contents, there are commit objects,
which represent commits, and tree objects, which represent
directories. These are usually constructed at the time the commit is
done. Since my files hadn't been committed, I knew I wasn't
interested in these types of objects. The command git cat-file -t
will tell you what type an object is. I made a file that related each
object to its type:
for i in $(cat /tmp/OBJ); do
echo -n "$i ";
git type $i;
done > /tmp/OBJTYPE
The git type command is just an alias for git cat-file -t. (Funny
thing about that: I created that alias years ago when I first started
using Git, thinking it would be useful, but I never used it, and just
last week I was wondering why I still bothered to have it around.) The
OBJTYPE file output by this loop looks like this:
00f1b6cc1dfc1c8872b6d7cd999820d1e922df4a blob
0093a412d3fe23dd9acb9320156f20195040a063 tree
01f3a6946197d93f8edba2c49d1bb6fc291797b0 commit
…
fed6767ff7fa921601299d9a28545aa69364f87b tree
ffd505d2da2e4aac813122d8e469312fd03a3669 tree
fff732422ed8d82ceff4f406cdc2b12b09d81c2e blob
Then I just grepped out the blob objects:
grep blob /tmp/OBJTYPE | f 1 > /tmp/OBJBLOB
The f 1 command throws away the types and
keeps the object IDs. At this point I had filtered the original 500
objects down to just 108 blobs.
Now it was time to grep through the blobs to find the ones I was
looking for. Fortunately, I knew that each of my lost files would
contain the string org-service-currency, which was my name for the
project I was working on. I couldn't grep the object files directly,
because they're gzipped, but the command git cat-file disgorges
the contents of an object:
for i in $(cat /tmp/OBJBLOB ) ; do
git cat-file blob $i |
grep -q org-service-curr
&& echo $i;
done > /tmp/MATCHES
The git cat-file blob $i produces the contents of the blob whose ID
is in $i. The grep searches the contents for the magic string.
Normally grep would print the matching lines, but this behavior is
disabled by the -q flag—the q is for “quiet”—and tells grep
instead that it is being used only as part of a test: it yields true
if it finds the magic string, and false if not. The && is the test;
it runs echo $i to print out the object ID $i only if the grep
yields true because its input contained the magic string.
So this loop fills the file MATCHES with the list of IDs of the
blobs that contain the magic string. This worked, and I found that
there were only 18 matching blobs, so I wrote a very similar loop to
extract their contents from the repository and save them in a
directory:
for i in $(cat /tmp/OBJBLOB ) ; do
git cat-file blob $i |
grep -q org-service-curr
&& git cat-file blob $i > /tmp/rescue/$i;
done
Instead of printing out the matching blob ID number, this loop passes
it to git cat-file again to extract the contents into a file in
/tmp/rescue.
The rest was simple. I made 8 subdirectories under /tmp/rescue
representing the 8 different files I was expecting to find. I
eyeballed each of the 18 blobs, decided what each one was, and sorted
them into the 8 subdirectories. Some of the subdirectories had only 1
blob, some had up to 5. I looked at the blobs in each subdirectory to
decide in each case which one I wanted to keep, using diff when it
wasn't obvious what the differences were between two versions of the
same file. When I found one I liked, I copied it back to its correct
place in the working tree.
Finally, I went back to the working tree and added and committed the rescued files.
It seemed longer, but it only took about twenty minutes. To recreate the eight files from scratch might have taken about the same amount of time, or maybe longer (although it never takes as long as I think it will), and would have been tedious.
But let's suppose that it had taken much longer, say forty minutes instead of twenty, to rescue the lost blobs from the repository. Would that extra twenty minutes have been time wasted? No! The twenty minutes spent to recreate the files from scratch is a dead loss. But the forty minutes to rescue the blobs is time spent learning something that might be useful in the future. The Git rescue might have cost twenty extra minutes, but if so it was paid back with forty minutes of additional Git expertise, and time spent to gain expertise is well spent! Spending time to gain expertise is how you become an expert!
Git is a core tool, something I use every day. For a long time I have been prepared for the day when I would try to rescue someone's lost blobs, but until now I had never done it. Now, if that day comes, I will be able to say “Oh, it's no problem, I have done this before!”
So if you lose something in Git, don't panic. There's a good chance that you can find someone who will be able to hunt it down again.
[Other articles in category /prog] permanent link
Fri, 08 Apr 2016I'm becoming one of the people at my company that people come to when they want help with git, so I've been thinking a lot about what to tell people about it. It's always tempting to dive into the technical details, but I think the first and most important things to explain about it are:
Git has a very simple and powerful underlying model. Atop this model is piled an immense trashheap of confusing, overlapping, inconsistent commands. If you try to just learn what commands to run in what order, your life will be miserable, because none of the commands make sense. Learning the underlying model has a much better payoff because it is much easier to understand what is really going on underneath than to try to infer it, Sherlock-Holmes style, from the top.
One of Git's principal design criteria is that it should be very difficult to lose work. Everything is kept, even if it can sometimes be hard to find. If you lose something, don't panic. There's a good chance that you can find someone who will be able to hunt it down again. And if you make a mistake, it is almost always possible to put things back exactly the way they were, and you can find someone who can show you how to do it.
One exception is changes that haven't been committed. These are not yet under Git's control, so it can't help you with them. Commit early and often.
[ Addendum 20160415: I wrote a detailed account of a time I recovered lost files. ]
[ Addendum 20160505: I don't know why I didn't mention it before, but if you want to learn Git's underlying model, you should read Git from the Bottom Up (which is what worked for me) or Git from the Inside Out which is better illustrated. ]
[Other articles in category /prog] permanent link
Wed, 12 Aug 2015
Another solution to Tuesday's git problem
On Tuesday I discussed an interesting solution to the problem of turning this:
no X X on
A --------------- C
into this:
no X X off X on
A ------ B ------ C
Dave Du Cros has suggested an alternative solution: Make the changes required to turn off feature X, and commit them as B, as in my solution:
no X X on X off
A ------ C ------ B
Then use git-revert to revert the changes, making a new C commit in
the right place:
no X X on X off X on
A ------ C ------ B ------ C'
C' and C have identical trees.
Then use git-rebase to squash together C and B:
no X X off X on
A --------------- B ------ C'
This has the benefit of not requiring anything strange. I think my solution is more general, but it's also weird, and it's not clear that the increased generality is useful.
However, what if there were a git-reorder-commits command? Then my
solution would seem much less weird. It would look like this: create
B, as before, and do:
git reorder-commits 0 1
This last command would mean that the previous two commits, normally
HEAD~1 and HEAD~0, should switch places. This might be a useful
standard tool. Or similarly to turn
B -- 3 -- 2 -- 1 -- 0
into
B -- 2 -- 0 -- 3 -- 1
one would use
git reorder-commits 2 0 3 1
I think git-reorder-commits would be easy to implement, as a loop
atop git-commit-tree, as in the previous article.
[ Addendum 20200531: Curtis Dunham suggested a much better interface to this functionality
than my git-reorder-commits proposal. ]
[Other articles in category /prog] permanent link
Tue, 11 Aug 2015
Reordering git commits with git-commit-tree
I know, you want to say “Why didn't you just use git-rebase?”
Because git-rebase wouldn't work here, that's why. Let me back up.
Say I have commit A, in which feature X does not exist yet. Then in commit C, I implement feature X.
But I realize what I really wanted was to have A, then B, in which feature X was implemented but disabled, and then C in which feature X was enabled. The C I want is just like the C that I have, but I don't have the intervening B.
I have:
no X X on
A --------------- C
I want:
no X X off X on
A ------ B ------ C
One way to do this is to use git-rebase in edit mode to split C into
B and C. To do this I would pause while rebasing C, edit C to disable
feature X, commit the result, which is B, then undo the previous edits
to re-enable X, and continue the rebase, creating C. That's two sets
of edits. I could backup the files before the first edit and then
copy them back for the second edit, but that's the SVN way, so I'm not
going to do that.
Now someone wants me to use git-rebase to “reorder the commits”.
Their idea is: I have C. Edit C to disable feature X and commit the
result as B':
no X X on X off
A ------ C ------ B'
Now use interactive git-rebase to reorder B and C. But this will
not work. git-rebase will construct a patch for turning C into B'
and will try to apply it to A. This will fail completely, because a
patch for turning C into B' is a patch for turning off feature X once
it is implemented. Feature X is not in A and you can't turn something
off that isn't there. So the rebase will fail to apply the
patch.
What I did instead was rather bizarre, using a plumbing command, but worked well. I wrote the code to disable X, and committed it as B, obtaining this:
no X X on X off
A ------ C ------ B
Now B and C have the files I want in them, but their parents are wrong. That is, the history is in the wrong order, but if the parent of C was B and the parent of B was A, eveything would be perfect.
But we can't just change the parents; we have to create a new commit, say B', which has the same files as B but whose parent is A instead of C, and we have to create a new commit C' which has the same files as C but whose parent is B' instead of A.
This is what git-commit-tree does. You give it a tree object
containing the files you want, a list of parents, and a commit
message, and it creates the commit you asked for and prints its SHA1.
When we use git-commit, it first turns the index into a tree, with
git-write-tree, then creates the commit, with git-commit-tree, and
then moves the current head ref up to the new commit. Here we will
use git-commit-tree directly.
So I did:
% git checkout -b XX A
Switched to a new branch 'XX'
% git commit-tree -p HEAD B^{tree}
10ddf433039fd3cbc5bec0c64970a45add15482e
% git reset --hard 10ddf433039fd3cbc5bec0c64970a45add15482e
% git commit-tree -p HEAD C^{tree}
ce46beb90d4aa4e2c9fe0e2e3d22eea256edceac
% git reset --hard ce46beb90d4aa4e2c9fe0e2e3d22eea256edceac
The first git-commit-tree
% git commit-tree -p HEAD B^{tree}
says to make a commit whose tree is the same as B's, and whose parent
is the current HEAD, which is A. (B^{tree} is a special notation
that means to get the tree from commit B.) Git pauses here to read the
commit message from standard input (not shown), and prints the SHA of
the new commit on the terminal. I then use git-reset to move the
current head ref, XX, up to the new commit. Normally git-commit
would do this for us, but we're not using git-commit today.
Then I do the same thing with C:
% git commit-tree -p HEAD C^{tree}
makes a new commit whose tree is the same as C's, and whose parent is
the current head, which looks just like B. Again it reads a commit
message from standard input, and prints the SHA of the new commit on
the terminal, and again I use git-reset to move XX up to the new
commit.
Now I have what I want and I only had to edit the files once. To
complete the task I just reset the head of my working branch to
wherever XX is now, discarding the old A-C-B branch in favor of the
new A-B-C branch. If there's an easier way to do this, I don't know
it.
It seems to me that there have been a number of times in the past
when I wanted to do something like reordering commits, and
git-rebase did not do what I wanted because it reorders patches
and not commits. I should keep my eyes open, and see if this comes up
again, and if it is worth automating.
[ Thanks to Jeremy Leader for suggesting I write this up and to Jeremy Leader and Rik Signes for advance editing. ]
[ Addendum 20150813: a followup article ]
[ Addendum 20200531: a better way to accomplish the same thing ]
[Other articles in category /prog] permanent link
Tue, 04 Aug 2015
The list monad in Perl and Python
A few months ago I wrote an article about using Haskell's list monad to do exhaustive search, with the running example of solving this cryptarithm puzzle:
S E N D
+ M O R E
-----------
M O N E Y
(This means that we want to map the letters S, E, N, D, M,
O, R, Y to distinct digits 0 through 9 to produce a five-digit
and two four-digit numerals which, when added in the indicated way,
produce the indicated sum.)
At the end, I said:
It would be an interesting and pleasant exercise to try to implement the same underlying machinery in another language. I tried this in Perl once, and I found that although it worked perfectly well, between the lack of the do-notation's syntactic sugar and Perl's clumsy notation for lambda functions (
sub { my ($s) = @_; … }instead of\s -> …)the result was completely unreadable and therefore unusable. However, I suspect it would be even worse in Python because of semantic limitations of that language. I would be interested to hear about this if anyone tries it.
I was specifically worried about Python's peculiar local variable binding. But I did receive the following quite clear solution from Peter De Wachter, who has kindly allowed me to reprint it:
digits = set(range(10))
def to_number(*digits):
n = 0
for d in digits:
n = n * 10 + d
return n
def let(x, f):
return f(x)
def unit(x):
return [x]
def bind(xs, f):
ys = []
for x in xs:
ys += f(x)
return ys
def guard(b, f):
return f() if b else []
after which the complete solution looks like:
def solutions():
return bind(digits - {0}, lambda s:
bind(digits - {s}, lambda e:
bind(digits - {s,e}, lambda n:
bind(digits - {s,e,n}, lambda d:
let(to_number(s,e,n,d), lambda send:
bind(digits - {0,s,e,n,d}, lambda m:
bind(digits - {s,e,n,d,m}, lambda o:
bind(digits - {s,e,n,d,m,o}, lambda r:
let(to_number(m,o,r,e), lambda more:
bind(digits - {s,e,n,d,m,o,r}, lambda y:
let(to_number(m,o,n,e,y), lambda money:
guard(send + more == money, lambda:
unit((send, more, money))))))))))))))
print(solutions())
I think this shows that my fears were unfounded. This code produces the correct answer in about 1.8 seconds on my laptop.
Thus inspired, I tried doing it again in Perl, and it was not as bad as I remembered:
sub bd { my ($ls, $f) = @_;
[ map @{$f->($_)}, @$ls ] # Yow
}
sub guard { $_[0] ? [undef] : [] }
I opted to omit unit/return since an idiomatic solution doesn't
really need it. We can't name the bind function bind because that
is reserved for a built-in function; I named it bd instead. We
could use Perl's operator overloading to represent binding with the
>> operator, but that would require turning all the lists into
objects, and it didn't seem worth doing.
We don't need to_number, because Perl does it implicitly, but we do
need a set subtraction function, because Perl has no built-in set
operators:
sub remove {
my ($b, $a) = @_;
my %h = map { $_ => 1 } @$a;
delete $h{$_} for @$b;
return [ keys %h ];
}
After which the solution, although cluttered by Perl's verbose notation for lambda functions, is not too bad:
my $digits = [0..9];
my $solutions =
bd remove([0], $digits) => sub { my ($s) = @_;
bd remove([$s], $digits) => sub { my ($e) = @_;
bd remove([$s,$e], $digits) => sub { my ($n) = @_;
bd remove([$s,$e,$n], $digits) => sub { my ($d) = @_;
my $send = "$s$e$n$d";
bd remove([0,$s,$e,$n,$d], $digits) => sub { my ($m) = @_;
bd remove([$s,$e,$n,$d,$m], $digits) => sub { my ($o) = @_;
bd remove([$s,$e,$n,$d,$m,$o], $digits) => sub { my ($r) = @_;
my $more = "$m$o$r$e";
bd remove([$s,$e,$n,$d,$m,$o,$r], $digits) => sub { my ($y) = @_;
my $money = "$m$o$n$e$y";
bd guard($send + $more == $money) => sub { [[$send, $more, $money]] }}}}}}}}};
for my $s (@$solutions) {
print "@$s\n";
}
This runs in about 5.5 seconds on my laptop. I guess, but am not sure,
that remove is mainly at fault for this poor performance.
An earlier version of this article claimed, incorrectly, that the Python version had lazy semantics. It does not; it is strict.
[ Addendum: Aaron Crane has done some benchmarking of the Perl
version. A better implementation of remove (using an array instead
of a hash) does speed up the calculation somewhat, but contrary to my
guess, the largest part of the run time is bd itself, apparently
becuse Perl function calls are relatively slow.
HN user masklinn tried a translation of the Python code into a
version that returns a lazy
iterator; I gather the
changes were minor. ]
Addendum 20241010
There is a discussion on StackOverflow about doing this in Elixr.
[Other articles in category /prog] permanent link
Wed, 13 May 2015
Want to work with me on one of these projects?
I did a residency at the Recurse Center last month. I made a profile page on their web site, which asked me to list some projects I was interested in working on while there. Nobody took me up on any of the projects, but I'm still interested. So if you think any of these projects sounds interesting, drop me a note and maybe we can get something together.
They are listed roughly in order of their nearness to completion, with the most developed ideas first and the vaporware at the bottom. I am generally language-agnostic, except I refuse to work in C++.
Or if you don't want to work with me, feel free to swipe any of these ideas yourself. Share and enjoy.
Linogram
Linogram is a constraint-based diagram-drawing language that I think
will be better than prior languages (like pic, Metapost, or, god
forbid, raw postscript or SVG) and very different from WYSIWYG drawing
programs like Inkscape or Omnigraffle. I described it in detail in
chapter 9 of Higher-Order
Perl
and it's missing only one or two important features that I can't quite
figure out how to do. It also needs an SVG output module, which I
think should be pretty simple.
Most of the code for this already exists, in Perl.
I have discussed Linogram previously in this blog.
Orthogonal polygons
Each angle of an orthogonal polygon is either 90° or 270°. All 4-sided orthogonal polygons are rectangles. All 6-sided orthogonal polygons are similar-looking letter Ls. There are essentially only four different kinds of 8-sided orthogonal polygons. There are 8 kinds of 10-sided orthogonal polygons:
There are 29 kinds of 12-sided orthogonal polygons. I want to efficiently count the number of orthogonal polygons with N sides, and have the computer draw exemplars of each type.
I have a nice method for systematically generating descriptions of all simple orthogonal polygons, and although it doesn't scale to polygons with many sides I think I have an idea to fix that, making use of group-theoretic (mathematical) techniques. (These would not be hard for anyone to learn quickly; my ten-year-old daughter picked them right up. Teaching the computer would be somewhat trickier.) For making the pictures, I only have half the ideas I need, and I haven't done the programming yet.
The little code I have is written in Perl, but it would be no trouble to switch to a different language.
[ Addendum 20150607: the orthogonal polygon sequence is now in OEIS! ]
Simple Android app
I want to learn to build Android apps for my Android phone. I think a
good first project would be a utility where you put in a sequence of
letters, say FBS, and it displays all the words that contain those
letters in order. (For FBS the list contains "afterburners",
"chlorofluorocarbons", "fables", "fabricates", …, "surfboards".) I
play this game often with my kid (the letters are supplied by license
plates we pass) and we want a way to cheat when we are stumped.
My biggest problem with Android development in the past has been getting the immense Android SDK set up.
The project would need to be done in Java, because that is what Android uses.
gi
Git is great, but its user interface is awful. The command set is obscure and non-orthogonal. Error messages are confusing. gi is a thinnish layer that tries to present a more intuitive and uniform command set, with better error messages and clearer advice, without removing any of git's power.
There's no code written yet, and we could do it in any language. Perl or Python would be good choices. The programming is probably easy; the hard part of this project is (a) design and (b) user testing.
I have a bunch of design notes written up about this already.
Twingler
Twingler takes an example of an input data structure and and output data structure, and writes code in your favorite language for transforming the input into the output. Or maybe it takes some sort of simplified description of what is wanted and writes the code from that. The description would be declarative, not procedural. I'm really not at all sure what it should do or how it should work, but I have a lot of notes, and if we could make it happen a lot of people would love it.
No code is written; we could do this in your favorite language. Haskell maybe?
Bonus: Whatever your favorite language is, I bet it needs something like this.
Crapspad
I want a simple library that can render simple pixel graphics and detect and respond to mouse events. I want people to be able to learn to use it in ten minutes. It should be as easy as programming graphics on an Apple II and easier than a Commodore 64. It should not be a gigantic object-oriented windowing system with widgets and all that stuff. It should be possible to whip up a simple doodling program in Crapspad in 15 minutes.
I hope to get Perl bindings for this, because I want to use it from Perl programs, but we could design it to have a language-independent interface without too much trouble.
Git GUI
There are about 17 GUIs for Git and they all suck in exactly the same way: they essentially provide a menu for running all the same Git commands that you would run at the command line, obscuring what is going on without actually making Git any easier to use. Let's fix this.
For example, why can't you click on a branch and drag it elsewhere to rebase it, or shift-drag it to create a new branch and rebase that? Why can't you drag diff hunks from one commit to another?
I'm not saying this stuff would be easy, but it should be possible. Although I'm not convinced I really want to put ion the amount of effort that would be required. Maybe we could just submit new features to someone else's already-written Git GUI? Or if they don't like our features, fork their project?
I have no code yet, and I don't even know what would be good to use.
[Other articles in category /prog] permanent link
Fri, 24 Apr 2015
Easy exhaustive search with the list monad
(Haskell people may want to skip this article about Haskell, because the technique is well-known in the Haskell community.)
Suppose you would like to perform an exhaustive search. Let's say for concreteness that we would like to solve this cryptarithm puzzle:
S E N D
+ M O R E
-----------
M O N E Y
This means that we want to map the letters S, E, N, D, M,
O, R, Y to distinct digits 0 through 9 to produce a five-digit
and two four-digit numerals which, when added in the indicated way,
produce the indicated sum.
(This is not an especially difficult example; my 10-year-old daughter Katara was able to solve it, with some assistance, in about 30 minutes.)
If I were doing this in Perl, I would write up either a recursive descent search or a solution based on a stack or queue of partial solutions which the program would progressively try to expand to a full solution, as per the techniques of chapter 5 of Higher-Order Perl. In Haskell, we can use the list monad to hide all the searching machinery under the surface. First a few utility functions:
import Control.Monad (guard)
digits = [0..9]
to_number = foldl (\a -> \b -> a*10 + b) 0
remove rs ls = foldl remove' ls rs
where remove' ls x = filter (/= x) ls
to_number takes a list of digits like [1,4,3] and produces the
number they represent, 143. remove takes two lists and returns all
the things in the second list that are not in the first list. There
is probably a standard library function for this but I don't remember
what it is. This version is !!O(n^2)!!, but who cares.
Now the solution to the problem is:
-- S E N D
-- + M O R E
-- ---------
-- M O N E Y
solutions = do
s <- remove [0] digits
e <- remove [s] digits
n <- remove [s,e] digits
d <- remove [s,e,n] digits
let send = to_number [s,e,n,d]
m <- remove [0,s,e,n,d] digits
o <- remove [s,e,n,d,m] digits
r <- remove [s,e,n,d,m,o] digits
let more = to_number [m,o,r,e]
y <- remove [s,e,n,d,m,o,r] digits
let money = to_number [m,o,n,e,y]
guard $ send + more == money
return (send, more, money)
Let's look at just the first line of this:
solutions = do
s <- remove [0] digits
…
The do notation is syntactic sugar for
(remove [0] digits) >>= \s -> …
where “…” is the rest of the block. To expand this further, we need
to look at the overloading for >>= which is implemented differently
for every type. The mote on the left of >>= is a list value, and
the definition of >>= for lists is:
concat $ map (\s -> …) (remove [0] digits)
where “…” is the rest of the block.
So the variable s is bound to each of 1,2,3,4,5,6,7,8,9 in turn, the
rest of the block is evaluated for each of these nine possible
bindings of s, and the nine returned lists of solutions are combined
(by concat) into a single list.
The next line is the same:
e <- remove [s] digits
for each of the nine possible values for s, we loop over nine value
for e (this time including 0 but not including whatever we chose for
s) and evaluate the rest of the block. The nine resulting lists of
solutions are concatenated into a single list and returned to the
previous map call.
n <- remove [s,e] digits
d <- remove [s,e,n] digits
This is two more nested loops.
let send = to_number [s,e,n,d]
At this point the value of send is determined, so we compute and
save it so that we don't have to repeatedly compute it each time
through the following 300 loop executions.
m <- remove [0,s,e,n,d] digits
o <- remove [s,e,n,d,m] digits
r <- remove [s,e,n,d,m,o] digits
let more = to_number [m,o,r,e]
Three more nested loops and another computation.
y <- remove [s,e,n,d,m,o,r] digits
let money = to_number [m,o,n,e,y]
Yet another nested loop and a final computation.
guard $ send + more == money
return (send, more, money)
This is the business end. I find guard a little tricky so let's
look at it slowly. There is no binding (<-) in the first line, so
these two lines are composed with >> instead of >>=:
(guard $ send + more == money) >> (return (send, more, money))
which is equivalent to:
(guard $ send + more == money) >>= (\_ -> return (send, more, money))
which means that the values in the list returned by guard will be
discarded before the return is evaluated.
If send + more == money is true, the guard expression yields
[()], a list of one useless item, and then the following >>= loops
over this one useless item, discards it, and returns yields a list
containing the tuple (send, more, money) instead.
But if send + more == money is false, the guard expression yields
[], a list of zero useless items, and then the following >>= loops
over these zero useless items, never runs return at all, and yields
an empty list.
The result is that if we have found a solution at this point, a list
containing it is returned, to be concatenated into the list of all
solutions that is being constructed by the nested concats. But if
the sum adds up wrong, an empty list is returned and concated
instead.
After a few seconds, Haskell generates and tests 1.36 million choices for the eight bindings, and produces the unique solution:
[(9567,1085,10652)]
That is:
S E N D 9 5 6 7
+ M O R E + 1 0 8 5
----------- -----------
M O N E Y 1 0 6 5 2
It would be an interesting and pleasant exercise to try to implement
the same underlying machinery in another language. I tried this in
Perl once, and I found that although it worked perfectly well, between
the lack of the do-notation's syntactic sugar and Perl's clumsy
notation for lambda functions (sub { my ($s) = @_; … } instead of
\s -> …) the result was completely unreadable and therefore
unusable. However, I suspect it would be even worse in Python
because of semantic limitations of that language. I would be
interested to hear about this if anyone tries it.
[ Addendum: Thanks to Tony Finch for pointing out the η-reduction I missed while writing this at 3 AM. ]
[ Addendum: Several people so far have misunderstood the question
about Python in the last paragraph. The question was not to implement
an exhaustive search in Python; I had no doubt that it could be done
in a simple and clean way, as it can in Perl. The question was to
implement the same underlying machinery, including the list monad
and its bind operator, and to find the solution using the list
monad.
[ Peter De Wachter has written in with a Python solution that clearly demonstrates that the problems I was worried about will not arise, at least for this task. I hope to post his solution in the next few days. ]
[ Addendum 20150803: De Wachter's solution and one in Perl ]
[Other articles in category /prog/haskell] permanent link
Wed, 16 Jul 2014
Guess what this does (solution)
A few weeks ago I asked people to predict, without trying it first, what this would print:
perl -le 'print(two + two == five ? "true" : "false")'
(If you haven't seen this yet, I recommend that you guess, and then test your guess, before reading the rest of this article.)
People familiar with Perl guess that it will print true; that is
what I guessed. The reasoning is as follows: Perl is willing to treat
the unquoted strings two and five as strings, as if they had been
quoted, and is also happy to use the + and == operators on them,
converting the strings to numbers in its usual way. If the strings
had looked like "2" and "5" Perl would have treated them as 2 and
5, but as they don't look like decimal numerals, Perl interprets them
as zeroes. (Perl wants to issue a warning about this, but the warning is not enabled by default.
Since the two and five are treated as
zeroes, the result of the == comparison are true, and the string
"true" should be selected and printed.
So far this is a little bit odd, but not excessively odd; it's the
sort of thing you expect from programming languages, all of which more
or less suck. For example, Python's behavior, although different, is
about equally peculiar. Although Python does require that the strings
two and five be quoted, it is happy to do its own peculiar thing
with "two" + "two" == "five", which happens to be false: in Python
the + operator is overloaded and has completely different behaviors
on strings and numbers, so that while in Perl "2" + "2" is the
number 4, in Python is it is the string 22, and "two" + "two"
yields the string "twotwo". Had the program above actually printed
true, as I expected it would, or even false, I would not have
found it remarkable.
However, this is not what the program does do. The explanation of two paragraphs earlier is totally wrong. Instead, the program prints nothing, and the reason is incredibly convoluted and bizarre.
First, you must know that print has an optional first argument. (I
have plans for an article about how optional first arguments are almost
always a bad move, but contrary to my usual practice I will not insert
it here.) In Perl, the print function can be invoked in two ways:
print HANDLE $a, $b, $c, …;
print $a, $b, $c, …;
The former prints out the list $a, $b, $c, … to the filehandle
HANDLE; the latter uses the default handle, which typically points
at the terminal. How does Perl decide which of these forms is being
used? Specifically, in the second form, how does it know that $a is
one of the items to be printed, rather than a variable containing the filehandle
to print to?
The answer to this question is further complicated by the fact that
the HANDLE in the first form could be either an unquoted string,
which is the name of the handle to print to, or it could be a variable
containing a filehandle value. Both of these prints should do the
same thing:
my $handle = \*STDERR;
print STDERR $a, $b, $c;
print $handle $a, $b, $c;
Perl's method to decide whether a particular print uses an explicit
or the default handle is a somewhat complicated heuristic. The basic
rule is that the filehandle, if present, can be distinguished because
its trailing comma is omitted. But if the filehandle were allowed to
be the result of an arbitrary expression, it might be difficult for
the parser to decide where there was a a comma; consider the
hypothetical expression:
print $a += EXPRESSION, $b $c, $d, $e;
Here the intention is that the $a += EXPRESSION, $b expression
calculates the filehandle value (which is actually retrieved from $b, the
$a += … part being executed only for its side effect) and the
remaining $c, $d, $e are the values to be printed. To allow this
sort of thing would be way too confusing to both Perl and to the
programmer. So there is the further rule that the filehandle
expression, if present, must be short, either a simple scalar
variable such as $fh, or a bare unquoted string that is in the right
format for a filehandle name, such as HANDLE. Then the parser need
only peek ahead a token or two to see if there is an upcoming comma.
So for example, in
print STDERR $a, $b, $c;
the print is immediately followed by STDERR, which could be a
filehandle name, and STDERR is not followed by a comma, so STDERR
is taken to be the name of the output handle. And in
print $x, $a, $b, $c;
the print is immediately followed by the simple scalar value $x,
but this $x is followed by a comma, so is considered one of the
things to be printed, and the target of the print is the default
output handle.
In
print STDERR, $a, $b, $c;
Perl has a puzzle: STDERR looks like a filehandle, but it is
followed by a comma. This is a compile-time error; Perl complains “No
comma allowed after filehandle” and aborts. If you want to print the
literal string STDERR, you must quote it, and if you want to print A, B,
and C to the standard error handle, you must omit the first comma.
Now we return to the original example.
perl -le 'print(two + two == five ? "true" : "false")'
Here Perl sees the unquoted string two which could be a filehandle
name, and which is not followed by a comma. So it takes the first
two to be the output handle name. Then it evaluates the expression
+ two == five ? "true" : "false"
and obtains the value true. (The leading + is a unary plus
operator, which is a no-op. The bare two and five are taken to be
string constants, which, compared with the numeric == operator, are
considered to be numerically zero, eliciting the same warning that I
mentioned earlier that I had not enabled. Thus the comparison Perl
actually does is is 0 == 0, which is true, and the resulting string is
true.)
This value, the string true, is then printed to the filehandle named
two. Had we previously opened such a filehandle, say with
open two, ">", "output-file";
then the output would have been sent to the filehandle as usual.
Printing to a non-open filehandle elicits an optional warning from
Perl, but as I mentioned, I have not enabled warnings, so the print
silently fails, yielding a false value.
Had I enabled those optional warnings, we would have seen a plethora of them:
Unquoted string "two" may clash with future reserved word at -e line 1.
Unquoted string "two" may clash with future reserved word at -e line 1.
Unquoted string "five" may clash with future reserved word at -e line 1.
Name "main::two" used only once: possible typo at -e line 1.
Argument "five" isn't numeric in numeric eq (==) at -e line 1.
Argument "two" isn't numeric in numeric eq (==) at -e line 1.
print() on unopened filehandle two at -e line 1.
(The first four are compile-time warnings; the last three are issued
at execution time.) The crucial warning is the one at the end,
advising us that the output of print was directed to the filehandle
two which was never opened for output.
[ Addendum 20140718: I keep thinking of the following remark of Edsger W. Dijkstra:
[This phenomenon] takes one of two different forms: one programmer places a one-line program on the desk of another and … says, "Guess what it does!" From this observation we must conclude that this language as a tool is an open invitation for clever tricks; and while exactly this may be the explanation for some of its appeal, viz., to those who like to show how clever they are, I am sorry, but I must regard this as one of the most damning things that can be said about a programming language.
But my intent is different than what Dijkstra describes. His programmer is proud, but I am disgusted. Incidentally, I believe that Dijkstra was discussing APL here. ]
[ Addendum 20150508: I never have much sympathy for the school of thought that says that you should always always enable warnings in every Perl program; I think Perl produces too many spurious warnings for that. But I also think this example is part of a cogent argument in the other direction. ]
[Other articles in category /prog/perl] permanent link
Here's a Perl quiz that I confidently predict nobody will get right. Without trying it first, what does the following program print?
perl -le 'print(two + two == five ? "true" : "false")'
(I will discuss the surprising answer tomorrow.)
[Other articles in category /prog/perl] permanent link
Sat, 01 Feb 2014My current employer uses an online quiz to pre-screen applicants for open positions. The first question on the quiz is a triviality, just to let the candidate get familiar with the submission and testing system. The question is to write a program that copies standard input to standard output. Candidates are allowed to answer the questions using whatever language they prefer.
Sometimes we get candidates who get a zero score on the test. When I see the report that they failed to answer even the trivial question, my first thought is that this should not reflect badly on the candidate. Clearly, the testing system itself is so hard to use that the candidate was unable to submit even a trivial program, and this is a failure of the testing system and not the candidate.
But it has happened more than once that when I look at the candidate's incomplete submissions I see that the problem, at least this time, is not necessarily in the testing system. There is another possible problem that had not even occurred to me. The candidate failed the trivial question because they tried to write the answer in Java.
I am reminded of Dijkstra's remark that the teaching of BASIC should be rated as a criminal offense. Seeing the hapless candidate get bowled over by a question that should be a mere formality makes me wonder if the same might be said of Java.
I'm not sure. It's possible that this is still a failure of the quiz. It's possible that the Java programmers have valuable skills that we could use, despite their inability to produce even a trivial working program in a short amount of time. I could be persuaded, but right now I have a doubtful feeling.
When you learn Perl, Python, Ruby, or Javascript, one of the things you learn is a body of technique for solving problems using hashes, which are an integral part of the language. When you learn Haskell, you similarly learn a body of technique for solving problems with lazy lists and monads. These kinds of powerful general-purpose tools are at the forefront of the language.
But when you learn Java, there aren't any powerful language features
you can use to solve many problems. Instead, you spend your time
learning a body of technique for solving problems in the language.
Java has hashes, but if you are aware of them at all, they are just
another piece of the immense Collections library, lost among the
many other sorts of collections, and you have no particular reason to
know about them or think about them. A good course of Java instruction
might emphasize the more useful parts of the Collections, but since
they're just another part of the library it may not be obvious that
hashes are any more or less useful than, say, AbstractAction or
zipOutputStream.
I was a professional Java programmer for three years (in a different organization), and I have meant for some time to write up my thoughts about it. I am often very bitter and sarcastic, and I willingly admit that I am relentlessly negative and disagreeable, so it can be hard to tell when I am in earnest about liking something. I once tried to write a complimentary article about Blosxom, which has generated my blog since 2006, and I completely failed; people thought I was being critical, and I had to write a followup article to clarify, and people still thought I was dissing Blosxom. Because this article about Java might be confused with sarcastic criticism, I must state clearly that everything in this article about Java is in earnest, and should be taken at face value. Including:
I really like Java
I am glad to have had the experience of programming in Java. I liked
programming in Java mainly because I found it very relaxing. With a
bad language, like say Fortran or csh, you struggle to do anything
at all, and the language fights with you every step of the way
forward. With a good language there is a different kind of struggle,
to take advantage of the language's strengths, to get the maximum
amount of functionality, and to achieve the clearest possible
expression.
Java is neither a good nor a bad language. It is a mediocre language, and there is no struggle. In Haskell or even in Perl you are always worrying about whether you are doing something in the cleanest and the best way. In Java, you can forget about doing it in the cleanest or the best way, because that is impossible. Whatever you do, however hard you try, the code will come out mediocre, verbose, redundant, and bloated, and the only thing you can do is relax and keep turning the crank until the necessary amount of code has come out of the spout. If it takes ten times as much code as it would to program in Haskell, that is all right, because the IDE will generate half of it for you, and you are still being paid to write the other half.
So you turn the crank, draw your paycheck, and you don't have to worry about the fact that it takes at least twice as long and the design is awful. You can't solve any really hard design problems, but there is a book you can use to solve some of the medium-hard ones, and solving those involves cranking out a lot more Java code, for which you will also be paid. You are a coder, your job is to write code, and you write a lot of code, so you are doing your job and everyone is happy.
You will not produce anything really brilliant, but you will probably not produce anything too terrible either. The project might fail, but if it does you can probably put the blame somewhere else. After all, you produced 576 classes that contain 10,000 lines of Java code, all of it seemingly essential, so you were doing your job. And nobody can glare at you and demand to know why you used 576 classes when you should have used 50, because in Java doing it with only 50 classes is probably impossible.
(Different languages have different failure modes. With Perl, the project might fail because you designed and implemented a pile of shit, but there is a clever workaround for any problem, so you might be able to keep it going long enough to hand it off to someone else, and then when it fails it will be their fault, not yours. With Haskell someone probably should have been fired in the first month for choosing to do it in Haskell.)
So yes, I enjoyed programming in Java, and being relieved of the responsibility for producing a quality product. It was pleasant to not have to worry about whether I was doing a good job, or whether I might be writing something hard to understand or to maintain. The code was ridiculously verbose, of course, but that was not my fault. It was all out of my hands.
So I like Java. But it is not a language I would choose for answering test questions, unless maybe the grade was proportional to the number of lines of code written. On the test, you need to finish quickly, so you need to optimize for brevity and expressiveness. Java is many things, but it is neither brief nor expressive.
When I see that some hapless job candidate struggled for 15 minutes and 14 seconds to write a Java program for copying standard input to standard output, and finally gave up, without even getting to the real questions, it makes me sad that their education, which was probably expensive, has not equipped them with with better tools or to do something other than grind out Java code.
[Other articles in category /prog] permanent link
Fri, 10 Jan 2014
DateTime::Moonpig, a saner interface to DateTime
(This article was previously published at the Perl Advent Calendar on 2013-12-23.)
The DateTime suite is an impressive tour de force, but I hate its interface. The methods it provides are usually not the ones you want, and the things it makes easy are often things that are not useful.
Mutators
The most obvious example is that it has too many mutators. I believe
that date-time values are a kind of number, and should be treated like
numbers. In particular they should be immutable. Rik Signes has
a hair-raising story
about an accidental mutation that caused a hard to diagnose bug,
because the add_duration method modifies the object on which it is
called, instead of returning a new object.
DateTime::Duration
But the most severe example, the one that drives me into a rage, is
that the subtract_datetime method returns a DateTime::Duration object,
and this object is never what you want, because it is impossible to
use it usefully.
For example, suppose you would like to know how much time elapses between 1969-04-02 02:38:17 EST and 2013-12-25 21:00:00 EST. You can set up the two DateTime objects for the time, and subtract them using the overloaded minus operator:
#!perl
my ($a) = DateTime->new( year => 1969, month => 04, day => 02,
hour => 2, minute => 38, second => 17,
time_zone => "America/New_York" ) ;
my ($b) = DateTime->new( year => 2013, month => 12, day => 25,
hour => 21, minute => 0, second => 0,
time_zone => "America/New_York" ) ;
my $diff = $b - $a;
Internally this invokes subtract_datetime to yield a
DateTime::Duration object for the difference. The
DateTime::Duration object $diff will contain the information
that this is a difference of 536 months, 23 days, 1101 minutes, and 43
seconds, a fact which seems to me to be of very limited usefulness.
You might want to know how long this interval is, so you can compare
it to similar intervals. So you might want to know how many seconds
this is. It happens that the two times are exactly 1,411,669,328
seconds apart, but there's no way to get the $diff object to
tell you this.
It seems like there are methods that will get you the actual
elapsed time in seconds, but none of them will do it. For example,
$diff->in_units('seconds') looks promising, but will
return 43, which is the 43 seconds left over after you've thrown away
the 536 months, 23 days, and 1101 minutes. I don't know what the use
case for this is supposed to be.
And indeed, no method can tell you how long the duration really is, because the subtraction has thrown away all the information about how long the days and months and years were—days, months and years vary in length—so it simply doesn't know how much time this object actually represents.
Similarly if you want to know how many days there are between the two dates, the DateTime::Duration object won't tell you because it can't tell you. If you had the elapsed seconds difference, you could convert it to the correct number of days simply by dividing by 86400 and rounding off. This works because, even though days vary in length, they don't vary by much, and the variations cancel out over the course of a year. If you do this you find that the elapsed number of days is approximately 16338.7653, which rounds off to 16338 or 16339 depending on how you want to treat the 18-hour time-of-day difference. This result is not quite exact, but the error is on the order of 0.000002%. So the elapsed seconds are useful, and you can compute other useful values with them, and get useful answers. In contrast, DateTime::Duration's answer of "536 months and 23 days" is completely useless because months vary in length by nearly 10% and DateTime has thrown away the information about how long the months were. The best you can do to guess the number of days from this is to multiply the 536 months by 30.4375, which is the average number of days in a month, and add 23. This is clumsy, and gets you 16337.5 days—which is close, but wrong.
To get what I consider a useful answer out of the DateTime objects you must not use the overloaded subtraction operator; instead you must do this:
#!perl
$b->subtract_datetime_absolute($a)->in_units('seconds')
What's DateTime::Moonpig for?
DateTime::Moonpig
attempts to get rid of the part of DateTime I don't like and keep the
part I do like, by changing the interface and leaving the internals
alone. I developed it for the Moonpig billing system that Rik
Signes and I did; hence the
name.
DateTime::Moonpig introduces five main changes to the interface of DateTime:
Most of the mutators are gone. They throw fatal exceptions if you try to call them.
The overridden addition and subtraction operators have been changed to eliminate DateTime::Duration entirely. Subtracting two DateTime::Moonpig objects yields the difference in seconds, as an ordinary Perl number. This means that instead of
#!perl $x = $b->subtract_datetime_absolute($a)->in_units('seconds')one can write
#!perl $x = $b - $aFrom here it's easy to get the approximate number of days difference: just divide by 86400. Similarly, dividing this by 3600 gets the number of hours difference.
An integer number of seconds can be added to or subtracted from a DateTime::Moonpig object; this yields a new object representing a time that is that many seconds later or earlier. Writing
$date + 2is much more convenient than writing$date->clone->add( seconds => 2 ).If you are not concerned with perfect exactness, you can write
#!perl sub days { $_[0] * 86400 } my $tomorrow = $now + days(1);This might be off by an hour if there is an intervening DST change, or by a second if there is an intervening leap second, but in many cases one simply doesn't care.
There is nothing wrong with the way DateTime overloads
<and>, so DateTime::Moonpig leaves those alone.The constructor is extended to accept an epoch time such as is returned by Perl's built-in
time()orstat()functions. This means that one can abbreviate this:#!perl DateTime->from_epoch( epoch => $epoch )to this:
#!perl DateTime::Moonpig->new( $epoch )The default time zone has been changed from DateTime's "floating" time zone to UTC. I think the "floating" time zone is a mistake, and best avoided. It has bad interactions with
set_time_zone, whichDateTime::Moonpigdoes not disable, because it is not actually a mutator—unless you use the "floating" time zone. An earlier blog article discusses this.I added a few additional methods I found convenient. For example there is a
$date->stthat returns the date and time in the formatYYYY-MM-DD HH:MM::SS, which is sometimes handy for quick debugging. (Thestis for "string".)
Under the covers, it is all just DateTime objects, which seem to do
what one needs. Other than the mutators, all the many DateTime
methods work just the same; you are even free to use
->subtract_datetime to obtain a DateTime::Duration object if you
enjoy being trapped in an absurdist theatre production.
When I first started this module, I thought it was likely to be a failed experiment. I expected that the Moonpig::DateTime objects would break once in a while, or that some operation on them would return a DateTime instead of a Moonpig::DateTime, which would cause some later method call to fail. But to my surprise, it worked well. It has been in regular use in Moonpig for several years.
I recently split it out of Moonpig, and released it to CPAN. I will be interested to find out if it works well in other contexts. I am worried that disabling the mutators has left a gap in functionality that needs to be filled by something else. I will be interested to hear reports from people who try.
[Other articles in category /prog/perl] permanent link
Mon, 23 Dec 2013
Two reasons I don't like DateTime's "floating" time zone
(This is a companion piece to my article about
DateTime::Moonpig
on the Perl Advent Calendar today. One
of the ways DateTime::Moonpig differs from DateTime is by
defaulting to UTC time instead of to DateTime's "floating" time
zone. This article explains some of the reasons why.)
Perl's DateTime module lets you create time values in a so-called
"floating" time zone. What this means really isn't clear. It would
be coherent for it to mean a time with an unknown or unspecified time
zone, but it isn't treated that way. If it were, you wouldn't be
allowed to compare "floating" times with regular times, or convert
"floating" times to epoch times. If "floating" meant "unspecified
time zone", the computer would have to honestly say that it didn't
know what to do in such cases. But it doesn't.
Unfortunately, this confused notion is the default.
Here are two demonstrations of why I don't like "floating" time zones.
1.
The behavior of the set_time_zone method may not be what you were
expecting, but it makes sense and it is useful:
my $a = DateTime->new( second => 0,
minute => 0,
hour => 5,
day => 23,
month => 12,
year => 2013,
time_zone => "America/New_York",
);
printf "The time in New York is %s.\n", $a->hms;
$a->set_time_zone("Asia/Seoul");
printf "The time in Seoul is %s.\n", $a->hms;
Here we have a time value and we change its time zone from New York to Seoul. There are at least two reasonable ways to behave here. This could simply change the time zone, leaving everything else the same, so that the time changes from 05:00 New York time to 05:00 Seoul time. Or changing the time zone could make other changes to the object so that it represents the same absolute time as it did before: If I pick up the phone at 05:00 in New York and call my mother-in-law in Seoul, she answers the call at 19:00 in Seoul, so if I change the object's time zone from New York to Seoul, it should change from 05:00 to 19:00.
DateTime chooses the second of these: setting the time zone retains
the absolute time stored by the object, so this program prints:
The time in New York is 05:00:00. The time in Seoul is 19:00:00.
Very good. And we can get to Seoul by any route we want:
$a->set_time_zone("Europe/Berlin");
$a->set_time_zone("Chile/EasterIsland");
$a->set_time_zone("Asia/Seoul");
printf "The time in Seoul is still %s.\n", $a->hms;
This prints:
The time in Seoul is still 19:00:00.
We can hop all around the globe, but the object always represents 19:00 in Seoul, and when we get back to Seoul it's still 19:00.
But now let's do the same thing with floating time zones:
my $b = DateTime->new( second => 0,
minute => 0,
hour => 5,
day => 23,
month => 12,
year => 2013,
time_zone => "America/New_York",
);
printf "The time in New York is %s.\n", $b->hms;
$b->set_time_zone("floating");
$b->set_time_zone("Asia/Seoul");
printf "The time in Seoul is %s.\n", $b->hms;
Here we take a hop through the imaginary "floating" time zone. The output is now:
The time in New York is 05:00:00.
The time in Seoul is 05:00:00.
The time has changed! I said there were at least two reasonable ways
to behave, and that set_time_zone behaves in the second reasonable
way. Which it does, except that conversions to the "floating" time
zone behave the first reasonable way. Put together, however, they are
unreasonable.
2.
use DateTime;
sub dec23 {
my ($hour, $zone) = @_;
return DateTime->new( second => 0,
minute => 0,
hour => $hour,
day => 23,
month => 12,
year => 2013,
time_zone => $zone,
);
}
my $a = dec23( 8, "Asia/Seoul" );
my $b = dec23( 6, "America/New_York" );
my $c = dec23( 7, "floating" );
printf "A is %s B\n", $a < $b ? "less than" : "not less than";
printf "B is %s C\n", $b < $c ? "less than" : "not less than";
printf "C is %s A\n", $c < $a ? "less than" : "not less than";
With DateTime 1.04, this prints:
A is less than B
B is less than C
C is less than A
There are non-transitive relations in the world, but comparison of
times is not among them. And if your relation is not transitive, you
have no business binding it to the < operator.
However...
Rik Signes points out that the manual says:
If you are planning to use any objects with a real time zone, it is strongly recommended that you do not mix these with floating datetimes.
However, while a disclaimer in the manual can document incorrect
behavior, it does not annul it. A bug doesn't stop being a bug just
because you document it in the manual. I think it would have been
possible to implement floating times sanely, but DateTime didn't do
that.
[ Addendum: Rik has now brought to my attention that while the primary
->new constructor defaults to the "floating" time zone, the ->now
method always returns the current time in the UTC zone, which seems to
me to be a mockery of the advice not to mix the two. ]
[Other articles in category /prog/perl] permanent link
Mon, 16 Dec 2013
Moonpig: a billing system that doesn't suck
I'm in Amsterdam now, because Booking.com brought me out to tell them
about Moonpig, the billing and accounting system that Rik Signes and I
wrote. The talk was mostly a rehash of one I gave a Pittsburgh Perl
Workshop a couple of months ago, but I think it's of general interest.
The assumption behind the talk is that nobody wants to hear about how the billing system actually works, because most people either have their own billing system already or else don't need one at all. I think I could do a good three-hour talk about the internals of Moonpig, and it would be very interesting to the right group of people, but it would be a small group. So instead I have this talk, which lasts less than an hour. The takeaway from this talk is a list of several basic design decisions that Rik and I made while building Moonpig which weren't obviously good ideas at the time, but which turned out well in hindsight. That part I think everyone can learn from. You may not ever need to write a billing system, but chances are at some point you'll consider using an ORM, and it might be useful to have a voice in your head that says “Dominus says it might be better to do something completely different instead. I wonder if this is one of those times?”
So because I think the talk was pretty good, and it's fresh in my mind right now, I'm going to try to write it down. The talk slides are here if you want to see them. The talk is mostly structured around a long list of things that suck, and how we tried to design Moonpig to eliminate, avoid, or at least mitigate these things.
- Times and time zones suck
- Floating-point arithmetic sucks
- It sucks to fix your mangled data after an automated process fails
- Testing a yearlong sequence of events sucks
- It sucks to have your automated test accidentally send a bunch of bogus invoices to the customers
- Rounding errors suck
- Relational databases usually suck
- Modeling objects in the RDB really really sucks
- Perl's garbage collection sucks
- OO inheritance sucks
Sometimes I see other people fuck up a project over and over, and I say “I could do that better”, and then I get a chance to try, and I discover it was a lot harder than I thought, I realize that those people who tried before are not as stupid as as I believed.
That did not happen this time. Moonpig is a really good billing system. It is not that hard to get right. Those other guys really were as stupid as I thought they were.
Brief explanation of IC Group
When I tell people I was working for IC Group, they frown; they haven't heard of it. But quite often when I say that IC Group runs pobox.com, those same people smile and say “Oh, pobox!”.ICG is a first wave dot-com. In the late nineties, people would often have email through their employer or their school, and then they would switch jobs or graduate and their email address would go away. The basic idea of pobox was that for a small fee, something like $15 per year, you could get a pobox.com address that would forward all your mail to your real email address. Then when you changed jobs or schools you could just tell pobox to change the forwarding record, and your friends would continue to send email to the same pobox.com address as before. Later, ICG offered mail storage, web mail, and, through listbox.com, mailing list management and bulk email delivery.
Moonpig was named years and years before the project to write it was started. ICG had a billing and accounting system already, a terrible one. ICG employees would sometimes talk about the hypothetical future accounting system that would solve all the problems of the current one. This accounting system was called Moonpig because it seemed clear that it would never actually be written, until pigs could fly.
And in fact Moonpig wouldn't have been written, except that the existing system severely constrained the sort of pricing structures and deals that could actually be executed, and so had to go. Even then the first choice was to outsource the billing and accounting functions to some company that specialized in such things. The Moonpig project was only started as a last resort after ICG's president had tried for 18 months to find someone to take over the billing and collecting. She was unsuccessful. A billing provider would seem perfect and then turn out to have some bizarre shortcoming that rendered it unsuitable for ICG's needs. The one I remember was the one that did everything we wanted, except it would not handle checks. “Don't worry,” they said. “It's 2010. Nobody pays by check any more.”
Well, as it happened, many of our customers, including some of the largest institutional ones, had not gotten this memo, and did in fact pay by check.
So with some reluctance, she gave up and asked Rik and me to write a replacement billing and accounting system.
As I mentioned, I had always wanted to do this. I had very clear ideas, dating back many years, about mistakes I would not make, were I ever called upon to write a billing system.
For example, I have many times received a threatening notice of this sort:
Your account is currently past due! Pay the outstanding balance of $ 0 . 00 or we will be forced to refer your account for collection.What I believe happened here is: some idiot programmer knows that money amounts are formatted with decimal points, so decides to denominate the money with floats. The amount I paid rounds off a little differently than the amount I actually owed, and the result after subtraction is all roundoff error, and leaves me with a nominal debt on the order of !!2^{-64}!! dollars.
So I have said to myself many times “If I'm ever asked to write a billing system, it's not going to use any fucking floats.” And at the meeting at which the CEO told me and Rik that we would write it, those were nearly the first words out of my mouth: No fucking floats.
Moonpig conceptual architecture
I will try to keep this as short as possible, including only as much as is absolutely required to understand the more interesting and generally applicable material later.
Pobox and Listbox accounts
ICG has two basic use cases. One is Pobox addresses and mailboxes, where the customer pays us a certain amount of money to forward (or store) their mail for a certain amount of time, typically a year. The other is Listbox mailing lists, where the customer pays us a certain amount to attempt a certain number of bulk email deliveries on their behalf.
The basic model is simple…
The life cycle for a typical service looks like this: The customer pays us some money: a flat fee for a Pobox account, or a larger or smaller pile for Listbox bulk mailing services, depending on how much mail they need us to send. We deliver service for a while. At some point the funds in the customer's account start to run low. That's when we send them an invoice for an extension of the service. If they pay, we go back and continue to provide service and the process repeats; if not, we stop providing the service.
…just like all basic models
But on top of this basic model there are about 10,019 special cases:
Customers might cancel their service early.
Pobox has a long-standing deal where you get a sixth year free if you pay for five years of service up front.
Sometimes a customer with only email forwarding ($20 per year) wants to upgrade their account to one that does storage and provides webmail access ($50 per year), or vice-versa, in the middle of a year. What to do in this case? Business rules dictate that they can apply their current balance to the new service, and it should be properly pro-rated. So if I have 64 days of $50-per-year service remaining, and I downgrade to the $20-per-year service, I now have 160 days of service left.
Well, that wasn't too bad, except that we should let the customer know the new expiration date. And also, if their service will now expire sooner than it would have, we should give them a chance to pay to extend the service back to the old date, and deal properly with their payment or nonpayment.
Also something has to be done about any 6th free year that I might have had. We don't want someone to sign up for 5 years of $50-per-year service, get the sixth year free, then downgrade their account and either get a full free year of $50-per-year service or get a full free year of $20-per-year service after only !!\frac{20}{50}!! of five full years.
Sometimes customers do get refunds.
Sometimes we screw up and give people a credit for free service, as an apology. Unlike regular credits, these are not refundable!
Some customers get gratis accounts. The other cofounder of ICG used to hand these out at parties.
There are a number of cases for coupons and discounts. For example, if you refer a friend who signs up, you get some sort of credit. Non-profit institutions get some sort of discount off the regular rates. Customers who pay for many accounts get some sort of bulk discount. I forget the details.
Most customers get their service cut off if they don't pay. Certain large and longstanding customers should not be treated so peremptorily, and are allowed to run a deficit.
And so to infinity and beyond.
Ledgers and Consumers
The Moonpig data store is mostly organized as a huge pile of ledgers. Each represents a single customer or account. It contains some contact information, a record of all the transactions associated with that customer, a history of all the invoices ever sent to that customer, and so forth.A ledger also contains some consumer objects. Each consumer represents some service that we have promised to perform in exchange for money. The consumer has methods in it that you can call to say “I just performed a certain amount of service; please charge accordingly”. It has methods for calculating how much money has been allotted to it, how much it has left, how fast it is consuming its funds, how long it expects to last, and when it expects to run out of money. And it has methods for constructing its own replacement and for handing over control to that replacement when necessary.
Heartbeats
Every day, a cron job sends a heartbeat event to each ledger. The ledger doesn't do anything with the heartbeat itself; its job is to propagate the event to all of its sub-components. Most of those, in turn, ignore the heartbeat event entirely.But consumers do handle heartbeats. The consumer will wake up and calculate how much longer it expects to live. (For Pobox consumers, this is simple arithmetic; for mailing-list consumers, it guesses based on how much mail has been sent recently.) If it notices that it is going to run out of money soon, it creates a successor that can take over when it is gone. The successor immediately sends the customer an invoice: “Hey, your service is running out, do you want to renew?”
Eventually the consumer does run out of money. At that time it hands over responsibility to its replacement. If it has no replacement, it will expire, and the last thing it does before it expires is terminate the service.
Things that suck: manual repairs
Somewhere is a machine that runs a daily cron job to heartbeat each ledger. What if one day, that machine is down, as they sometimes are, and the cron job never runs?Or what if the machine crashes while the cron job is running, and the cron job only has time to heartbeat 3,672 of the 10,981 ledgers in the system?
In a perfect world, every component would be able to depend on exactly one heartbeat arriving every day. We don't live in that world. So it was an ironclad rule in Moonpig development that anything that handles heartbeat events must be prepared to deal with missing heartbeats, duplicate heartbeats, or anything else that could screw up.
When a consumer gets a heartbeat, it must not cheerfully say "Oh, it's the dawn of a new day! I'll charge for a day's worth of service!". It must look at the current date and at its own charge record and decide on that basis whether it's time to charge for a day's worth of service.
Now the answers to those questions of a few paragraphs earlier are quite simple. What if the machine is down and the cron job never runs? What to do?
A perfectly acceptable response here is: Do nothing. The job will run the next day, and at that time everything will be up to date. Some customers whose service should have been terminated today will have it terminated tomorrow instead; they will have received a free day of service. This is an acceptable loss. Some customers who should have received invoices today will receive them tomorrow. The invoices, although generated and sent a day late, will nevertheless show the right dates and amounts. This is also an acceptable outcome.
What if the cron job crashes after heartbeating 3,672 of 10,981 ledgers? Again, an acceptable response is to do nothing. The next day's heartbeat will bring the remaining 7,309 ledgers up to date, after which everything will be as it should. And an even better response is available: simply rerun the job. 3,672 of the ledgers will receive the same event twice, and will ignore it the second time.
Contrast this with the world in which heartbeats were (mistakenly) assumed to be reliable. In this world, the programming staff must determine precisely which ledgers received the event before the crash, either by trawling through the log files or by grovelling over the ledger data. Then someone has to hack up a program to send the heartbeats to just the 7,309 ledgers that still need it. And there is a stiff deadline: they have to get it done before tomorrow's heartbeat issues!
Making everything robust in the face of heartbeat failure is a little more work up front, but that cost is recouped the first time something goes wrong with the heartbeat process, when instead of panicking you smile and open another beer. Let N be the number of failures and manual repairs that are required before someone has had enough and makes the heartbeat handling code robust. I hypothesize that you can tell a lot about an organization from the value of N.
Here's an example of the sort of code that is required. The non-robust version of the code would look something like this:
sub charge {
my ($self, $event) = @_;
$self->charge_one_day();
}
The code, implemented by a role called
Moonpig::Role::Consumer::ChargesPeriodically, actually looks
something like this:
has last_charge_date => ( … );
sub charge {
my ($self, $event) = @_;
my $now = Moonpig->env->now;
CHARGE: until ($self->next_charge_date->follows($now)) {
my $next = $self->next_charge_date;
$self->charge_one_day();
$self->last_charge_date($next);
if ($self->is_expired) {
$self->replacement->handle_event($event) if $self->replacement;
last CHARGE;
}
}
}
The last_charge_date member records the last time the
consumer actually issued a charge. The next_charge_date
method consults this value and returns the next day on which the
consumer should issue a charge—not necessarily the following
day, since the consumer might issue weekly or monthly charges. The
consumer will issue charge after charge until the
next_charge_date is the future, when it will stop. It runs
the until loop, using charge_one_day to issue
another charge each time through, and updating
last_charge_date each time, until the
next_charge_date is in the future. The one tricky part here the if block. This is because the consumer might run out of money before the loop completes. In that case it passes the heartbeat event on to its successor (replacement) and quits the loop. The replacement will run its own loop for the remaining period.
Things that suck: real-time testing
A customer pays us $20. This will cover their service for 365 days. The business rules say that they should receive their first invoice 30 days before the current service expires; that is, after 335 days. How are we going to test that the invoice is in fact sent precisely 335 days later?Well, put like that, the answer is obvious: Your testing system must somehow mock the time. But obvious as this is, I have seen many many tests that made some method call and then did sleep 60, waiting and hoping that the event they were looking for would have occurred by then, reporting a false positive if the system was slow, and making everyone that much less likely to actually run the tests.
I've also seen a lot of tests that crossed their fingers and hoped that a certain block of code would execute between two ticks of the clock, and that failed nondeterministically when that didn't happen.
So another ironclad law of Moonpig design was that no object is ever allowed to call the time() function to find out what time it actually is. Instead, to get the current time, the object must call Moonpig->env->now.
The tests run in a test environment. In the test environment, Moonpig->env returns a Moonpig::Env::Test object, which contains a fake clock. It has a stop_clock method that stops the clock, and an elapse_time method that forces the clock forward a certain amount. If you need to check that something happens after 40 days, you can call Moonpig->env->elapse_time(86_400 * 40), or, more likely:
for (1..40) {
Moonpig->env->elapse_time(86_400);
$test_ledger->heartbeat;
}
In the production environment, the environment object still has a
now method, but one that returns the true current time from
the system clock. Trying to stop the clock in the production
environment is a fatal error.Similarly, no Moonpig object ever interacts directly with the database; instead it must always go through the mediator returned by Moonpig->env->storage. In tests, this can be a fake storage object or whatever is needed. It's shocking how many tests I've seen that begin by allocating a new MySQL instance and executing a huge pile of DDL. Folks, this is not how you write a test.
Again, no Moonpig object ever posts email. It asks Moonpig->env->email_sender to post the email on its behalf. In tests, this uses the CPAN Email::Sender::Transport suite, and the test code can interrogate the email_sender to see exactly what emails would have been sent.
We never did anything that required filesystem access, but if we had, there would have been a Moonpig->env->fs for opening and writing files.
The Moonpig->env object makes this easy to get right, and hard to screw up. Any code that acts on the outside world becomes a red flag: Why isn't this going through the environment object? How are we going to test it?
Things that suck: floating-point numbers
I've already complained about how I loathe floating-point numbers. I just want to add that although there are probably use cases for floating-point arithmetic, I don't actually know what they are. I've had a pretty long and varied programming career so far, and legitimate uses for floating point numbers seem very few. They are really complicated, and fraught with traps; I say this as a mathematical expert with a much stronger mathematical background than most programmers.The law we adopted for Moonpig was that all money amounts are integers. Each money amount is an integral number of “millicents”, abbreviated “m¢”, worth !!\frac1{1000}!! of a cent, which in turn is !!\frac1{100}!! of a U.S. dollar. Fractional millicents are not allowed. Division must be rounded to the appropriate number of millicents, usually in the customer's favor, although in practice it doesn't matter much, because the amounts are so small.
For example, a $20-per-year Pobox account actually bills $$\$\left\lfloor\frac{20,00,000}{365}\right\rfloor = 5479$$ m¢ each day. (5464 in leap years.)
Since you don't want to clutter up the test code with a bunch of numbers like 1000000 ($10), there are two utterly trivial utility subroutines:
sub cents { $_[0] * 1000 }
sub dollars { $_[0] * 1000 * 100 }
Now $10 can be written dollars(10).Had we dealt with floating-point numbers, it would have been tempting to write test code that looked like this:
cmp_ok(abs($actual_amount - $expected_amount), "<", $EPSILON, …);
That's because with floats, it's so hard to be sure that you won't end
up with a leftover !!2^{-64}!! or something, so you
write all the tests to ignore small discrepancies. This can lead to
overlooking certain real errors that happen to result in small
discrepancies. With integer amounts, these discrepancies have nowhere
to hide. It sometimes happened that we would write some test and the
money amount at the end would be wrong by 2m¢. Had we been using
floats, we might have shrugged and attributed this to incomprehensible
roundoff error.
But with integers, that is a difference of 2, and you cannot shrug it
off. There is no incomprehensible roundoff error.
All the calculations are exact, and if some integer is off by 2
it is for a reason. These tiny discrepancies usually pointed to
serious design or implementation errors. (In contrast, when a test
would show a gigantic discrepancy of a million or more m¢, the bug was
always quite easy to find and fix.)There are still roundoff errors; they are unavoidable. For example, a consumer for a $20-per-year Pobox account bills only 365·5479m¢ = 1999835m¢ per year, an error in the customer's favor of 165m¢ per account; after 12,121 years the customer will have accumulated enough error to pay for an extra year of service. For a business of ICG's size, this loss was deemed acceptable. For a larger business, it could be significant. (Imagine 6,000,000 customers times 165m¢ each; that's $9,900.) In such a case I would keep the same approach but denominate everything in micro-cents instead.
Happily, Moonpig did not have to deal with multiple currencies. That would have added tremendous complexity to the financial calculations, and I am not confident that Rik and I could have gotten it right in the time available.
Things that suck: dates and times
Dates and times are terribly complicated, partly because the astronomical motions they model are complicated, and mostly because the world's bureaucrats keep putting their fingers in. It's been suggested recently that you can identify whether someone is a programmer by asking if they have an opinion on time zones. A programmer will get very red in the face and pound their fist on the table.After I wrote that sentence, I then wrote 1,056 words about the right way to think about date and time calculations, which I'll spare you, for now. I'm going to try to keep this from turning into an article about all the ways people screw up date and time calculations, by skipping the arguments and just stating the main points:
- Date-time values are a kind of number, and should be
considered as such. In particular:
- Date-time values inside a program should be immutable
- There should be a single canonical representation of date-time values in the program, and it should be chosen for ease of calculation.
- If the program does have to deal with date-time values in some other representation, it should convert them to the canonical representation as soon as possible, or from the canonical representation as late as possible, and in any event should avoid letting non-canonical values percolate around the program.
We held our noses when we chose to use DateTime. It has my grudging approval, with a large side helping of qualifications. The internal parts of it are okay, but the methods it provides are almost never what you actually want to use. For example, it provides a set of mutators. But, as per item 1 above, date-time values are numbers and ought to be immutable. Rik has a good story about a horrible bug that was caused when he accidentally called the ->subtract method on some widely-shared DateTime value and so mutated it, causing an unexpected change in the behavior of widely-separated parts of the program that consulted it afterward.
So instead of using raw DateTime, we wrapped it in a derived class called Moonpig::DateTime. This removed the mutators and also made a couple of other convenient changes that I will shortly describe.
Things that really really suck: DateTime::Duration
If you have a pair of DateTime objects and you want to know how much time separates the two instants that they represent, you have several choices, most of which will return a DateTime::Duration object. All those choices are wrong, because DateTime::Duration objects are useless. They are a kind of Roach Motel for date and time information: Data checks into them, but doesn't check out. I am not going to discuss that here, because if I did it would take over the article, but I will show the simple example I showed in the talk:
my $then = DateTime->new( month => 4, day => 2, year => 1969,
hour => 0, minute => 0, second => 0);
my $now = DateTime->now();
my $elapsed = $now - $then;
print $elapsed->in_units('seconds'), "\n";
You might think, from looking at this code, that it might print the
number of seconds that elapsed between 1969-04-02 00:00:00 (in some
unspecified time zone!) and the current moment. You would be
mistaken; you have failed to reckon with the $elapsed object, which is a
DateTime::Duration. Computing this object seems reasonable, but as far as I know once you
have it there is nothing to do but throw it away and
start over, because there is no way to extract from it the elapsed amount of time, or indeed
anything else of value.
In any event, the print here does not print the
correct number of seconds. Instead it prints ME CAGO
EN LA LECHE, which I have discovered is Spanish for “I shit in
the milk”.So much for DateTime::Duration. When a and b are Moonpig::DateTime objects, a-b returns the number of seconds that have elapsed between the two times; it is that simple. You can divide it by 86,400 to get the number of days.
Other arithmetic is similarly overloaded: If i is a number, then a+i and a-i are the times obtained by adding or subtracting i seconds to a, respectively.
(C programmers should note the analogy with pointer arithmetic; C's pointers, and date-time values—also temperatures—are examples of a mathematical structure called an affine space, and study of the theory of affine spaces tells you just what rules these objects should obey. I hope to discuss this at length another time.)
Going along with this arithmetic are a family of trivial convenience functions, such as:
sub hours { $_[0] * 3600 }
sub days { $_[0] * 86400 }
so that you can use $a + days(7) to find the time 7 days
after $a. Programmers at the Amsterdam talk were worried about this:
what about leap seconds? And they are correct: the name days
is not quite honest, because it promises, but does not deliver, exactly
7 days. It can't, because the definition of the day varies widely from
place to place and time to time, and not only can't you know how long
7 days unless you know where it is, but it doesn't even make
sense to ask. That is all right. You just have to be aware, when
you add days(7), the resulting time might not be the same
time of day 7 days later. (Indeed, if the local date and time laws
are sufficiently bizarre, it could in principle be completely wrong. But
since Moonpig::DateTime objects are always reckoned in UTC, it is never more than
one second wrong.)Anyway, I was afraid that Moonpig::DateTime would turn out to be a leaky abstraction, producing pleasantly easy and correct results thirty times out of thirty-one, and annoyingly wrong or bizarre results the other time. But I was surprised: it never caused a problem, or at least none has come to light. I am working on releasing this module to CPAN, under the name DateTime::Moonpig. [ Addendum: DateTime::Moonpig is now available on CPAN. ]
Things that suck: mutable data
I left this out of the talk, by mistake, but this is a good place to mention it: mutable data is often a bad idea. In the billing system we wanted to avoid it for accountability reasons: We never wanted the customer service agent to be in the position of being unable to explain to the customer why we thought they owed us $28.39 instead of the $28.37 they claimed they owed; we never wanted ourselves to be in the position of trying to track down a billing system bug only to find that the trail had been erased.One of the maxims Rik and I repeated freqently was that the moving finger writes, and, having writ, moves on. Moonpig is full of methods with names like is_expired, is_superseded, is_canceled, is_closed, is_obsolete, is_abandoned and so forth, representing entities that have been replaced by other entities but which are retained as part of the historical record.
For example, a consumer has a successor, to which it will hand off responsibility when its own funds are exhausted; if the customer changes their mind about their future service, this successor might be replaced with a different one, or replaced with none. This doesn't delete or destroy the old successor. Instead it marks the old successor as "superseded", simultaneously recording the supersession time, and pushes the new successor (or undef, if none) onto the end of the target consumer's replacement_history array. When you ask for the current successor, you are getting the final element of this array. This pattern appeared in several places. In a particularly simple example, a ledger was required to contain a Contact object with contact information for the customer to which it pertained. But the Contact wasn't simply this:
has contact => (
is => 'rw',
isa => role_type( 'Moonpig::Role::Contact' ),
required => 1,
);
Instead, it was an array; "replacing" the contact actually pushed the
new contact onto the end of the array, from which the contact
accessor returned the final element:
has contact_history => (
is => 'ro',
isa => ArrayRef[ role_type( 'Moonpig::Role::Contact' ) ],
required => 1,
traits => [ 'Array' ],
handles => {
contact => [ get => -1 ],
replace_contact => 'push',
},
);
Similarly, what happens if we send the customer an invoice for three services, and they inform customer service that they want to continue two of the services but cancel the third? We need to throw away the old invoice, which will never be paid, and issue a new one. The old invoice remains in the system, marked "abandoned", with a pointer to the new invoice.
Things that suck: relational databases
Why do we use relational databases, anyway? Is it because they cleanly and clearly model the data we want to store? No, it's because they are lightning fast.When your data truly is relational, a nice flat rectangle of records, each with all the same fields, RDBs are terrific. But Moonpig doesn't have much relational data. It basic datum is the Ledger, which has a bunch of disparate subcomponents, principally a heterogeneous collection of Consumer objects. And I would guess that most programs don't deal in relational data; Like Moonpig, they deal in some sort of object network.
Nevertheless we try to represent this data relationally, because we have a relational database, and when you have a hammer, you go around hammering everything with it, whether or not that thing needs hammering.
When the object model is mature and locked down, modeling the objects relationally can be made to work. But when the object model is evolving, it is a disaster. Your relational database schema changes every time the object model changes, and then you have to find some way to migrate the existing data forward from the old schema. Or worse, and more likely, you become reluctant to let the object model evolve, because reflecting that evolution in the RDB is so painful. The RDB becomes a ball and chain locked to your program's ankle, preventing it from going where it needs to go. Every change is difficult and painful, so you avoid change. This is the opposite of the way to design a good program. A program should be light and airy, its object model like a string of pearls.
In theory the mapping between the RDB and the objects is transparent, and is taken care of seamlessly by an ORM layer. That would be an awesome world to live in, but we don't live in it and we may never.
Things that really really suck: ORM software
Right now the principal value of ORM software seems to be if your program is too fast and you need it to be slower; the ORM is really good at that. Since speed was the only benefit the RDB was providing in the first place, you have just attached two large, complex, inflexible systems to your program and gotten nothing in return.Watching the ORM try to model the objects is somewhere between hilariously pathetic and crushingly miserable. Perl's DBIx::Class, to the extent it succeeds, succeeds because it doesn't even try to model the objects in the database. Instead it presents you with objects that represent database rows. This isn't because a row needs to be modeled as an object—database rows have no interesting behavior to speak of—but because the object is an access point for methods that generate SQL. DBIx::Class is not for modeling objects, but for generating SQL. I only realized this recently, and angrily shouted it at the DBIx::Class experts, expecting my denunciation to be met with rage and denial. But they just smiled with amusement. “Yes,” said the DBIx::Class experts on more than one occasion, “that is exactly correct.” Well then.
So Rik and I believe that for most (or maybe all) projects, trying to store the objects in an RDB, with an ORM layer mediating between the program and the RDB, is a bad, bad move. We determined to do something else. We eventually brewed our own object store, and this is the part of the project of which I'm least proud, not because the object store itself was a bad idea, but because I believe we probably made every possible mistake that could be made, even the ones that everyone writing an object store should already know not to make.
For example, the object store has a method, retrieve_ledger, which takes a ledger's ID number, reads the saved ledger data from the disk, and returns a live Ledger object. But it must make sure that every such call returns not just a Ledger object with the right data, but the same object. Otherwise two parts of the program will have different objects to represent the same data, one part will modify its object, and the other part, looking at a different object, will not see the change it should see. It took us a while to figure out problems like this; we really did not know what we were doing.
What we should have done, instead of building our own object store, was use someone else's object store. KiokuDB is frequently mentioned in this context. After I first gave this talk people asked “But why didn't you use KiokuDB?” or, on hearing what we did do, said “That sounds a lot like KiokuDB”. I had to get Rik to remind me why we didn't use KiokuDB. We had considered it, and decided to do our own not for technical but for political reasons. The CEO, having made the unpleasant decision to have me and Rik write a new billing system, wanted to see some progress. If she had asked us after the first week what we had accomplished, and we had said “Well, we spent a week figuring out KiokuDB,” her head might have exploded. Instead, we were able to say “We got the object store about three-quarters finished”. In the long run it was probably more expensive to do it ourselves, and the result was certainly not as good. But in the short run it kept the customer happy, and that is the most important thing; I say this entirely in earnest, without either sarcasm or bitterness.
(On the other hand, when I ran this article by Rik, he pointed out that KiokuDB had later become essentially unmaintained, and that had we used it he would have had to become the principal maintainer of a large, complex system which which he did not help design or implement. The Moonpig object store may be technically inferior, but Rik was with it from the beginning and understands it thoroughly.)
Our object store
All that said, here is how our object store worked. The bottom layer was an ordinary relational database with a single table. During the test phase this database was SQLite, and in production it was IC Group's pre-existing MySQL instance. The table had two fields: a GUID (globally-unique identifier) on one side, and on the other side a copy of the corresponding Ledger object, serialized with Perl's Storable module. To retrieve a ledger, you look it up in the table by GUID. To retrieve a list of all the ledgers, you just query the GUID field. That covers the two main use-cases, which are customer service looking up a customer's account history, and running the daily heartbeat job. A subsidiary table mapped IC Group's customer account numbers to ledger GUIDs, so that the storage engine could look up a particular customer's ledger starting from their account number. (Account numbers are actually associated with Consumers. Once you have the right ledger a simple method call to the ledger will retrieve the consumer object, but finding the right ledger requires a table.) There were a couple of other tables of that sort, but overall it was a small thing.There are some fine points to consider. For example, you can choose whether to store just the object data, or the code as well. The choice is clear: you must store only the data, not the code. Otherwise, you would have to update all the stored objects every time you made a code change such as a bug fix. It should be clear that this would have discouraged bug fixes, and that had we gone this way the project would have ended as a pile of smoking rubble. Since the code is not stored in the database, the object store must be responsible, whenever it loads an object, for making sure that the correct class for that object actually exists. The solution for this was that along with every object is stored a list of all the roles that it must perform. At object load time, if the object's class doesn't exist yet, the object store retrieves this list of roles (stored in a third column, parallel to the object data) and uses the MooseX::ClassCompositor module to create a new class that does those roles. MooseX::ClassCompositor was something Rik wrote for the purpose, but it seems generally useful for such applications.
Every once in a while you may make an upward-incompatible change to the object format. Renaming an object field is such a change, since the field must be renamed in all existing objects, but adding a new field isn't, unless the field is mandatory. When this happened—much less often than you might expect—we wrote a little job to update all the stored objects. This occurred only seven times over the life of the project; the update programs are all very short.
We did also make some changes to the way the objects themselves were stored: Booking.Com's Sereal module was released while the project was going on, and we switched to use it in place of Storable. Also one customer's Ledger object grew too big to store in the database field, which could have been a serious problem, but we were able to defer dealing with the problem by using gzip to compress the serialized data before storing it.
The relational database provides transactions
The use of the RDB engine for the underlying storage got us MySQL's implementation of transactions and atomicity guarantees, which we trusted. This gave us a firm foundation on which to build the higher functions; without those guarantees you have nothing, and it is impossible to build a reliable system. But since they are there, we could build a higher-level transactional system on top of them.For example, we used an opportunistic locking scheme to prevent race conditions while updating a single ledger. For performance reasons you typically don't want to force all updates to be done through a single process (although it can be made to work; see Rochkind's Advanced Unix Programming). In an optimistic locking scheme, you store a version number with each record. Suppose you are the low-level storage manager and you get a request to update a ledger with a certain ID. Instead of doing this:
update ledger set serialized_data = …
where ledger_id = 789
You do this:
update ledger set serialized_data = …
, version = 4
where ledger_id = 789 and version = 3
and you check the return value from the SQL to see how many records
were actually updated. The answer must be 0 or 1. If it is 1, all is
well and you report the successful update back to your caller. But if
it is 0, that means that some other process got there first and
updated the same ledger, changing its version number from the 3 you
were expecting to something bigger. Your changes are now in limbo;
they were applied to a version of the object that is no longer current, so
you throw an exception. But is the exception safe? What if the caller had previously made changes to the database that should have been rolled back when the ledger failed to save? No problem! We had exposed the RDB transactions to the caller, so when the caller requested that a transaction be begun, we propagated that request into the RDB layer. When the exception aborted the caller's transaction, all the previous work we had done on its behalf was aborted back to the start of the RDB transaction, just as one wanted. The caller even had the option to catch the exception without allowing it to abort the RDB transaction, and to retry the failed operation.
Drawbacks of the object store
The major drawback of the object store was that it was very difficult to aggregate data across ledgers: to do it you have to thaw each ledger, one at a time, and traverse its object structure looking for the data you want to aggregate. We planned that when this became important, we could have a method on the Ledger or its sub-objects which, when called, would store relevant numeric data into the right place in a conventional RDB table, where it would then be available for the usual SELECT and GROUP BY operations. The storage engine would call this whenever it wrote a modified Ledger back to the object store. The RDB tables would then be a read-only view of the parts of the data that were needed for building reports.A related problem is some kinds of data really are relational and to store them in object form is extremely inefficient. The RDB has a terrible impedance mismatch for most kinds of object-oriented programming, but not for all kinds. The main example that comes to mind is that every ledger contains a transaction log of every transaction it has ever performed: when a consumer deducts its 5479 m¢, that's a transaction, and every day each consumer adds one to the ledger. The transaction log for a large ledger with many consumers can grow rapidly.
We planned from the first that this transaction data would someday move out of the ledger entirely into a single table in the RDB, access to which would be mediated by a separate object, called an Accountant. At present, the Accountant is there, but it stores the transaction data inside itself instead of in an external table.
The design of the object store was greatly simplified by the fact that all the data was divided into disjoint ledgers, and that only ledgers could be stored or retrieved. A minor limitation of this design was that there was no way for an object to contain a pointer to a Ledger object, either its own or some other one. Such a pointer would have spoiled Perl's lousy garbage collection, so we weren't going to do it anyway. In practice, the few places in the code that needed to refer to another ledger just store the ledger's GUID instead and looked it up when it was needed. In fact every significant object was given its own GUID, which was then used as needed. This was Rik's strategy, and it was a good one. I was surprised to find how often it was useful to have a simple, reliable identifier for every object, and how much time I had formerly spent on programming problems that would have been trivially solved if objects had had GUIDs.
The object store was a success
In all, I think the object store technique worked well and was a smart choice that went strongly against prevailing practice. I would recommend the technique for similar projects, except for the part where we wrote the object store ourselves instead of using one that had been written already. Had we tried to use an ORM backed by a relational database, I think the project would have taken at least a third longer; had we tried to use an RDB without any ORM, I think we would not have finished at all.
Things that suck: multiple inheritance
After I had been using Moose for a couple of years, including the Moonpig project, Rik asked me what I thought of it. I was lukewarm. It introduces a lot of convenience for common operations, but also hides a lot of complexity under the hood, and the complexity does not always stay well-hidden. It is very big and very slow to start up. On the whole, I said, I could take it or leave it.“Oh,” I added. “Except for Roles. Roles are awesome.” I had a long section in the talk about what is good about Roles, but I moved it out to a separate talk, so I am going to take that as a hint about what I should do here. As with my theory of dates and times, I will present only the thesis, and save the arguments for another post:
- Object-oriented programming is centered around objects, which are encapsulated groups of related data, and around methods, which are opaque functions for operating on particular kinds of objects.
- OOP does not mandate any particular theory of inheritance, either single or multiple, class-based or prototype based, etc., and indeed, while all OOP systems have objects and methods that are pretty much the same, each has an inheritance system all its own.
- Over the past 30 years of OOP, many theories of inheritance have been tried, and all of them have had serious problems.
- If there were no alternative to inheritance, we would have to
struggle on with inheritance. However, Roles are a good alternative to inheritance:
- Every problem solved by inheritance is solved at least as well by Roles.
- Many problems not solved at all by inheritance are solved by Roles.
- Many problems introduced by inheritance do not arise when using Roles.
- Roles introduce some of their own problems, but none of them are as bad as the problems introduced by inheritance.
- It's time to give up on inheritance. It was worth a try; we tried it as hard as we could for thirty years or more. It didn't work.
- I'm going to repeat that: Inheritance doesn't work. It's time to give up on it.
I plan to write more extensively on this later on.
This section is the end of the things I want to excoriate. Note the transition from multiple inheritance, which was a tremendous waste of everyone's time, to Roles, which in my opinion are a tremendous success, the Right Thing, and gosh if only Smalltalk-80 had gotten this right in the first place look how much trouble we all would have saved.
Things that are GOOD: web RPC APIs
Moonpig has a web API. Moonpig applications, such as the customer service dashboard, or the heartbeat job, invoke Moonpig functions through the API. The API is built using a system, developed in parallel with Moonpig, called Stick. (It was so-called because IC Group had tried before to develop a simple web API system, but none had been good enough to stick. This one, we hoped, would stick.)The basic principle of Stick is distributed routing, which allows an object to have a URI, and to delegate control of the URIs underneath it to other objects.
To participate in the web API, an object must compose the Stick::Role::Routable role, which requires that it provide a _subroute method. The method is called with an array containing the path components of a URI. The _subroute method examines the array, or at least the first few elements, and decides whether it will handle the route. To refuse, it can throw an exception, or just return an undefined value, which will turn into a 404 error in the web protocol. If it does handle the path, it removes the part it handled from the array, and returns another object that will handle the rest, or, if there is nothing left, a public resource of some sort. In the former case the routing process continues, with the remaining route components passed to the _subroute method of the next object.
If the route is used up, the last object in the chain is checked to make sure it composes the Stick::Role::PublicResource role. This is to prevent accidentally exposing an object in the web API when it should be private. Stick then invokes one final method on the public resource, either resource_get, resource_post, or similar. Stick collects the return value from this method, serializes it and sends it over the network as the response.
So for example, suppose a ledger wants to provide access to its consumers. It might implement _subroute like this:
sub _subroute {
my ($self, $route) = @_;
if ($route->[0] eq "consumer") {
shift @$route;
my $consumer_id = shift @$route;
return $self->find_consumer( id => $consumer_id );
} else {
return; # 404
}
}
Then if /path/to/ledger is any URI that leads to a certain
ledger, /path/to/ledger/consumer/12435 will be a valid URI
for the specified ledger's consumer with ID 12345. A request to
/path/to/ledger/FOOP/de/DOOP will yield a 404 error, as will
a request to /path/to/ledger/consumer/98765 whenever
find_consumer(id => 98765) returns undefined.A common pattern is to have a path that invokes a method on the target object. For example, suppose the ledger objects are already addressable at certain URIs, and one would like to expose in the API the ability to tell a ledger to handle a heartbeat event. In Stick, this is incredibly easy to implement:
publish heartbeat => { -http_method => 'post' } => sub {
my ($self) = @_;
$self->handle_event( event('heartbeat') );
};
This creates an ordinary method, called heartbeat, which can
be called in the usual way, but which is also invoked whenever an HTTP
POST request arrives at the appropriate URI, the appropriate URI being
anything of the form /path/to/ledger/heartbeat.The default case for publish is that the method is expected to be GET; in this case one can omit mentioning it:
publish amount_due => sub {
my ($self) = @_;
…
return abs($due - $avail);
};
More complicated published methods may receive arguments; Stick takes care of
deserializing them, and checking that their types are correct, before
invoking the published method. This is the ledger's method for updating its
contact information:
publish _replace_contact => {
-path => 'contact',
-http_method => 'put',
attributes => HashRef,
} => sub {
my ($self, $arg) = @_;
my $contact = class('Contact')->new($arg->{attributes});
$self->replace_contact($contact);
return $contact;
};
Although the method is named _replace_contact, is is
available in the web API via a PUT request to /path/to/ledger/contact,
rather than one to /path/to/ledger/_replace_contact.
If the contact information supplied in the HTTP request data is accepted by class('Contact')->new, the
ledger's contact is updated. (class('Contact') is a
utility method that returns the name of the class that represents
a contact. This is probably just the string Moonpig::Class::Contact.)In some cases the ledger has an entire family of sub-objects. For example, a ledger may have many consumers. In this case it's also equipped with a "collection" object that manages the consumers. The ledger can use the collection object as a convenient way to look up its consumers when it needs them, but the collection object also provides routing: If the ledger gets a request for a route that begins /consumers, it strips off /consumers and returns its consumer collection object, which handles further paths such as /guid/XXXX and /xid/1234 by locating and returning the appropriate consumer.
The collection object is a repository for all sorts of convenient behavior. For example, if one composes the Stick::Role::Collection::Mutable role onto it, it gains support for POST requests to …/consumers/add, handled appropriately.
Adding a new API method to any object is trivial, just a matter of adding a new published method. Unpublished methods are not accessible through the web API.
After I wrote this talk I wished I had written a talk about Stick instead. I'm still hoping to write one and present it at YAPC in Orlando this summer.
Things that are GOOD: Object-oriented testing
Unit tests often have a lot of repeated code, to set up test instances or run the same set of checks under several different conditions. Rik's Test::Routine makes a test program into a class. The class is instantiated, and the tests are methods that are run on the test object instance. Test methods can invoke one another. The test object's attributes are available to the test methods, so they're a good place to put test data. The object's initializer can set up the required test data. Tests can easily load and run other tests, all in the usual ways. If you like OO-style programming, you'll like all the same things about building tests with Test::Routine.
Things that are GOOD: Free software
All this stuff is available for free under open licenses:(This has been a really long article. Thanks for sticking with me. Headers in the article all have named anchors, in case you want to refer someone to a particular section.)
(I suppose there is a fair chance that this will wind up on Hacker News, and I know how much the kids at Hacker News love to dress up and play CEO and Scary Corporate Lawyer, and will enjoy posting dire tut-tuttings about whether my disclosure of ICG's secrets is actionable, and how reluctant they would be to hire anyone who tells such stories about his previous employers. So I may as well spoil their fun by mentioning that I received the approval of ICG's CEO before I posted this.)
[ Addendum: A detailed description of DateTime::Moonpig is now available. ]
[ Addendum 20140208: Jesper Andersen has written an account of a surprisingly similar system that he wrote in Erlang. ]
[ Addendum 20200319: In connection with “DBIx::Class is not for modeling objects, but for generating SQL”, see The Troublesome Active Record Pattern, which comes to similar conclusions as me, but more intelligently reasoned and with more technical detail. Paterson says “The only workable alternative is to make queries first class objects”. This is what DBIx::Class does. ]
[Other articles in category /prog] permanent link
Tue, 17 Sep 2013
Overlapping intervals
Our database stores, among other things, "budgets", which have a
lifetime with a start and end time. A business rule is that no two
budgets may be in force at the same time. I wanted to build a method
which, given a proposed start and end time for a new budget, decided
whether there was already a budget in force during any part of the
proposed period.
The method signature is:
sub find_overlapping_budgets {
my ($self, $start, $end) = @_;
...
}
and I want to search the contents of $self->budgets for any
budgets that overlap the time interval from $start to
$end. Budgets have a start_date and an
end_date property.My first thought was that for each existing budget, it's enough to check to see if its start_date or its end_date lies in the interval of interest, so I wrote it like this:
sub find_overlapping_budgets {
my ($self, $start, $end) = @_;
return $self->budgets->search({
[ { start_date => { ">=" , $start },
start_date => { "<=" , $end },
},
{ end_date => { ">=" , $start },
end_date => { "<=" , $end },
},
]
});
}
People ridicule Lisp for having too many parentheses, and code like
this, a two-line function which ends with },},]});}, should
demonstrate that that is nothing but xenophobia.
I'm not gonna explain the ridiculous proliferation of braces and
brackets here, except to say that this is expressing the following
condition:
$$ \begin{array}{} ( start_A \le & start_B & & \wedge & \\ & start_B & \le end_A & & ) \vee \\ ( start_A \le & end_B & & \wedge & \\ & end_B & \le end_A & & ) \\ \end{array} $$
which we can abbreviate as:$$ start_A \le start_B \le end_A \vee \\ start_A \le end_B \le end_A \\ $$
And if this condition holds, then the intervals overlap. Anyway, this seemed reasonable at the time, but is totally wrong, and happily, the automated tests I wrote for the method caught the error. Say that we ask whether we can create a budget that runs from June 1 to June 10. Say there is a budget that already exists, running from June 6 to June 7. Then the query asks :$$ \text{June 5} \le \text{June 1} \le \text{June 6} \vee \\ \text{June 5} \le \text{June 10} \le \text{June 6} \\ $$
Both of the disjuncts are false, so the method reports that there is no overlap. My implementation was just completely wrong. it's not enough to check to see if either endpoint of the proposed interval lies within an existing interval; you also have to check to see if any of the endpoints of the existing intervals lie within the proposed interval. (Alert readers will have noticed that although the condition "Intervals A and B overlap" is symmetric in A and B, the condition as I wrote it is not symmetric, and this should raise your suspicions.)This was yet another time when I felt slightly foolish as I wrote the automated tests, assuming that the time and effort I spent on testing this trivial function would would be time and effort thrown away on nothing—and then they detected a real fault. Someday perhaps I'll stop feeling foolish writing tests for functions like this one; until then, many cases just like this one will help me remember that I must write the tests even though I feel foolish doing it.
Okay, how to get this right? I tried a bunch of things, mostly involving writing out a conjunction of every required condition and then using boolean algebra to simplify the resulting expression:
$$ start_A \le start_B \le end_A \vee \\ start_A \le end_B \le end_A \vee \\ start_B \le start_A \le end_B \vee \\ start_B \le end_A \le end_B \\ $$
This didn't work well, partly because I was doing it at two in the morning, partly because there are many conditions, all very similar, and I kept getting them mixed up, and partly because, for implementation reasons, the final expression must be a query on interval A, even though it is most naturally expressed symmetrically between the two intervals.But then I had a happy idea: For some reason it seemed much simpler to express the opposite condition, that the two intervals do not conflict. If they don't conflict, then interval A must be entirely to the left of interval B, so that $$end_A \lt start_B,$$ or vice-versa, so that $$end_B\lt start_A.$$ Then the intervals do not overlap if either of these is true:
$$ end_A \lt start_B \vee end_B \lt start_A $$
and the condition that we want, that the two intervals do overlap, is simply its negation:$$ end_A \ge start_B \wedge end_B \ge start_A $$
This is correct, or at least all the tests now pass, and it is even simpler than the incorrect condition I wrote in the first place. The code looks like this:
sub find_overlapping_budgets {
my ($self, $start, $end) = @_;
return $self->budgets->search({
end_date => { '>=', $start },
start_date => { '<=', $end },
});
}
Usually I like to draw some larger lesson from this sort of
thing. What comes to mind now (other than “Just write the
tests, fool!”) is this: The end result is quite
clever. Often I see the final version of the code and say "Oh, I
wonder why I didn't see that right off?" Not this time. I want to say
I couldn't have found it by myself, except that I did find it
by myself, not by just pulling it magically out of my head, but by
applying technique.Instead of "not by magically pulling it out of my head" I was about to write "not by just thinking", but that is not quite right. I did solve it by "just thinking", but it was a different sort of thinking. Sometimes I consider a problem, and a solution leaps to mind, as it did in this case, except that it was wrong. That is what I call "just thinking". But applying carefully-learned and practiced technique is also thinking.
The techniques I applied in this problem included: noticing and analyzing symmetries of the original problem, and application of laws of boolean algebra, both in the unsuccessful and the successful attempt. Higher-level strategies included trying more than one approach, and working backwards. Learning and correctly applying technique made me effectively a better thinker, not just in general, but in this particular case.
[ Addendum 20130917: Dfan Schmidt remarks: "I'm astonished you didn't know the interval-overlap trick already." I was a little surprised, also, when I tried to pull the answer out of my head and didn't find one there already, either from having read it somewhere before, or from having solved the problem before. ]
[Other articles in category /prog] permanent link
Sat, 15 Dec 2012
How I got four errors into a one-line program
At my current job, each task is assigned a ticket number of the form
e12345. The git history is extremely convoluted, and it's
been observed that it's easier to find things if you include the
ticket number at the front of the commit message. I got tired of
inserting it manually, and thought I would write a prepare-commit-message hook to insert
it automatically.
A prepare-commit-message hook is a program that you stick in the file .git/hooks/prepare-commit-hook. When you run git-commit, git first writes the commit message to a file, then invokes the prepare-commit-message program on file; the program can modify the contents of the message, or abort the commit if it wants to. Then git runs the editor on the message, if it was going to do that, and creates the commit with the edited message.
The hook I wrote was basically a one-liner, and the reason I am posting this note is because I found three significant programming errors in it in the first day of use.
Here's the first cut:
case $2 in
message)
perl -i -lpe "s/^(e\d+:\s+)?/$(cs -): /" $1
;;
esac
This is a shell script, but the main purpose is to run the perl
one-liner. The shell script gets two arguments: $1 is the
path to the file that contains the proposed commit message.
The $2 argument is a tag which describes the commit's
context; it's merge if the commit is a merge commit, for
example; it's template if the commit message is supplied from
a template via -t on the command line or the
commit.template configuration option. The default is the
empty string, and message, which I have here, means that the
message was supplied with the -m command-line option.The Perl script edits the commit message file, named in $1, in-place, looking for something like e12345: at the beginning of a line, and replacing it with the output of the cs - command, which is a little program I wrote to print the current ticket number.
(cs is run by the shell, and its output is inserted into the Perl script before perl is run, so that the program that Perl sees is something like s/^(e\d+:\s+)?/e12345: /.) Simple enough.
There is already an error here, although it's a design error, not an implementation error: the Perl one-liner is only invoked when $2 is message. For some reason I decided that I would want it only when I supplied git-commit with the -m message option. This belief lasted exactly until the first time I ran git-commit in default mode it popped up the editor to edit the commit message, and I had to insert the ticket number manually.
So the first change was to let the hook run in the default case as well as the message case:
case $2 in
""|message)
perl -i -lpe "s/^(e\d+:\s+)?/$(cs -): /" $1
;;
esac
This was wrong because it inserts the ticket number at the start of
each line; I wanted it only at the start of the first line. So that
was programming error number 1:
case $2 in
""|message)
perl -i -lpe "$. == 1 && s/^(e\d+:\s+)?/$(cs -): /" $1
;;
esac
So far, so good.Bug #2 appeared the first time I tried a rebase. The cs command infers the ticket number from the name of the current branch. If it fails, it issues a warning and emits the string eXXXXX instead. During a rebase, the head is detached and there is no current branch. So the four commits I rebased all had their formerly-correct ticket numbers replaced with the string eXXXXX.
There are several ways to fix this. The best way would be to make sure that the current ticket number was stashed somewhere that cs could always get it. Instead, I changed the Perl script to recognize when the commit message already began with a ticket number, and to leave it alone if so:
case $2 in
""|message)
perl -i -lpe "\$. == 1 && !/^e\d+:\s+/ && s/^/$(cs -): /" $1
;;
esac
It probably would have been a good idea to leave an escape hatch, and
have cs emit the value of $ENV{TICKET_NUMBER} if
that is set, to allow invocations like TICKET_NUMBER=e71828 git
commit -m …, but I didn't do it, yet.The third bug appeared when I did git commit --fixup for the first time. With --fixup you tell it which commit you are trying to fix up, and it writes the commit message in a special form that tells a subsequent git-rebase --interactive that this new commit should be handled specially. (It should be applied immediately after that other one, and should be marked as a "fixup", which means that it is squashed into the other one and that its log message is discarded in favor of the other one.) If you are fixing up a commit whose message was Frobulate the veeblefetzers, the fixup commit's message is automatically generated as fixup! Frobulate the veeblefetzers. Or it would have been, if you were not using my prepare-commit-message hook, which would rewrite it to e12345: fixup! Frobulate the veeblefetzers. This is not in the right form, so it's not recognized by git-rebase --interactive for special handling.
So the hook became:
case $2 in
""|message)
perl -i -lpe "\$. == 1 && !/^(squash|fixup)! / && !/^e\d+:\s+/ && s/^/$(cs -): /" $1
;;
esac
(The exception for squash is similar to the one for
fixup. I never use squash, but it seemed foolish not
to put it in while I was thinking of it.)This is starting to look a little gross, but in a program this small I can tolerate a little grossness.
I thought it was remarkable that such a small program broke in so many different ways. Much of that is because it must interact with git, which is very large and complicated, and partly it is that it must interact with git, which is in many places not very well designed. The first bug, where the ticket number was appended to each line instead of just the first, is not git's fault. It was fallout from my initial bad design decision to apply the script only to messages supplied with -m, which are typically one-liners, so that's what I was thinking of when I wrote the Perl script.
But the other two errors would have been avoided had the interface to the hook been more uniform. There seems to be no reason that rebasing (or cherry-picking) and git-commit --fixup contexts couldn't have been communicated to the hook via the same $2 argument that communicates other contexts. Had this been done in a more uniform way, my program would have worked more correctly. But it wasn't done, and it's probably too late to change it now, since such a change risks breaking many existing prepare-commit-message hooks. (“The enemy of software is software.”) A well-written hook will of course have a catchall:
case $2 in
""|message)
perl -i -lpe "\$. == 1 && !/^(squash|fixup)! / && !/^e\d+:\s+/ && s/^/$(cs -): /" $1
;;
merge|template|squash|commit)
# do nothing
;;
*) # wat
echo "prepare-message-hook: unknown context '$2'" 1>&2
exit 1;
;;
esac
But mine doesn't and I bet a lot of others don't either.
[Other articles in category /prog] permanent link
Sun, 26 Aug 2012
Rewriting published history in Git
My earlier article about my
habits using Git attracted some comment, most of which was
favorable. But one recurring comment was puzzlement about my seeming
willingness to rewrite published history. In practice, this was not
at all a problem, I think for three reasons:
- Rewriting published history is not nearly as confusing as people seem to think it will be.
- I worked in a very small shop with very talented developers, so the necessary communication was easy.
- Our repository setup and workflow were very well-designed and unusually effective, and made a lot of things easier, including this one.
If there are N developers, there are N+1 repositories.
There is a master repository to which only a few very responsible persons can push. It is understood that history in this repository should almost never be rewritten, only in the most exceptional circumstances. We usually call this master repository gitbox. It has only a couple of branches, typically master and deployed. You had better not push incomplete work to master, because if you do someone is likely to deploy it. When you deploy a new version from master, you advance deployed up to master to match.
In addition, each developer has their own semi-public repository, named after them, which everyone can read, but which nobody but them can write. Mine is mjd, and that's what we call it when discussing it, but my personal git configuration calls it origin. When I git push origin master I am pushing to this semi-public repo.
It is understood that this semi-public repository is my sandbox and I am free to rewrite whatever history I want in it. People building atop my branches in this repo, therefore, know that they should be prepared for me to rewrite the history they see there, or to contact me if they want me to desist for some reason.
When I get the changes in my own semi-public repository the way I want them, then I push the changes up to gitbox. Nothing is considered truly "published" until it is on the master repo.
When a junior programmer is ready to deploy to the master repository, they can't do it themselves, because they only have read access on the master. Instead, they publish to their own semi-private repository, and then notify a senior programmer to review the changes. The senior programmer will then push those changes to the master repository and deploy them.
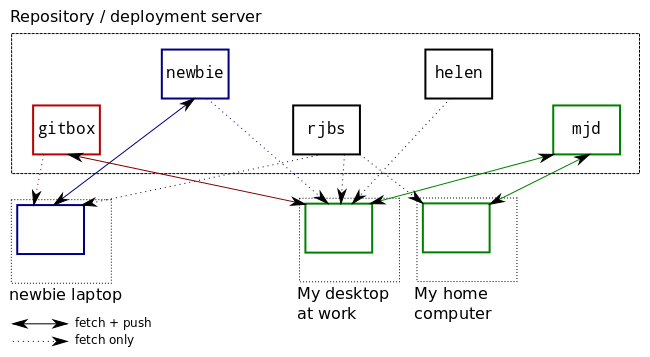
If I do work from three or four different machines, I can use the mjd repo to exchange commits between them. At the end of the day I will push my work-in-progress up to the mjd repo, and then if I want to look at it later that evening, I can fetch the work-in-progress to my laptop or another home computer.
I can create and abandon many topic branches without cluttering up the master repository's history. If I want to send a change or a new test file to a co-worker, I can push it to mjd and then point them at the branch there.
A related note: There is a lot of FUD around the rewriting of published history. For example, the "gitinfo" robot on the #git IRC channel has a canned message:
Rewriting public history is a very bad idea. Anyone else who may have pulled the old history will have to git pull --rebase and even worse things if they have tagged or branched, so you must publish your humiliation so they know what to do. You will need to git push -f to force the push. The server may not allow this. See receive.denyNonFastForwards (git-config)I think this grossly exaggerates the problems. Very bad! Humiliation! The server may deny you! But dealing with a rebased upstream branch is not very hard. It is at worst annoying: you have to rebase your subsequent work onto the rewritten branch and move any refs that pointed to that branch. If you don't have any subsequent work, you might still have to move refs, if you have any that point to it, but you might not have any.
[ Thanks to Rik Signes for helping me put this together. ]
[Other articles in category /prog] permanent link
Thu, 15 Mar 2012
My Git Habits
Miles Gould asked his Twitter followers whether they used git-add
-p or git-commit -a and how often. My reply was too
long for Twitter, so here it is.
First the short version: I use git-add -p frequently, and git-commit -a almost never. The exception is when I'm working on the repo that holds my blog, where I rarely commit changes to more than one or two files at a time. Then I'll usually just git-commit -a -m ....
But I use git-add -p all the time. Typically what will happen is that I will be developing some fairly complicated feature. It will necessitate a bunch of changes and reshuffling elsewhere in the system. I'll make commits on the topic branch as I go along without worrying too much about whether the commits are neatly packaged.
Often I'll be in the middle of something, with a dirty work tree, when it's time to leave for the day. Then I'll just commit everything with the subject WIP ("work-in-progress"). First thing the next morning I'll git-reset HEAD^ and continue where I left off.
So the model is that the current head is usually a terrible mess, accumulating changes as it moves forward in time. When I'm done, I will merge the topic into master and run the tests.
If they pass, I am not finished. The merge I just created is only a draft merge. The topic branch is often full of all sorts of garbage, commits where I tried one approach, found it didn't work later on, and then tried a different approach, places where I committed debugging code, and so on. So it is now time to clean up the topic branch. Only the cleaned-up topic branch gets published.
Cleaning up messy topic branches
The core of the cleanup procedure is to reset the head back to the last place that look good, possibly all the way back to the merge-base if that is not too long ago. This brings all the topic changes into the working directory. Then:
- Compose the commits: Repeat until the working tree is clean:
- Eyeball the output of git-diff
- Think of an idea for an intelligible commit
- Use git-add -p to stage the planned commit
- Use git diff --cached to make sure it makes sense
- Commit it
- Order the commits: Use git-rebase --interactive
By separating these tasks, I can proceed something like this: I eyeball the diff, and the first thing I see is something about the penguin feature. I can immediately say "Great, I'll make up a commit of all the stuff related to the penguin feature", and proceed to the git-add -p step without worrying that there might be other stuff that should precede the penguin feature in the commit sequence. I can focus on just getting the penguin commit right without needing to think about any of the other changes.
When the time comes to put the commits in order, I can do it well because by then I have abstracted away all the details, and reduced each group of changes to a single atomic unit with a one-line description.
For the most complicated cases, I will print out the diffs, read them over, and mark them up in six colors of highlighter: code to throw away gets marked in orange; code that I suspect is erroneous is pink. I make many notes in pen to remind me how I want to divide up the changes into commits. When a commit occurs to me I'll jot a numbered commit message, and then mark all the related parts of the diff with that number. Once I have the commits planned, I'll reset the topic ref and then run through the procedure above, using git-add -p repeatedly to construct the commits I planned on paper. Since I know ahead of time what they are I might do them in the right order, but more likely I'll just do them in the order I thought of them and then reorder them at the end, as usual.
For simple cases I'll just do a series of git-rebase --interactive passes, pausing at any leftover WIP commits to run the loop above, reordering the commits to squash related commits together, and so on.
The very simplest cases of all require no cleanup, of course.
For example, here's my current topic branch, called c-domain, with the oldest commits at the top:
055a2f7 correction to bulk consumer template
d9630bd DomainActivator half of Pobox Domain consumer
ebebb4a Add HasDomain role to provide ->domain reader for domain consumers
ade6ac6 stubbed domain test
e170e77 start templates for Pobox domain consumers
067ca81 stubbed Domain::ThumbTwiddler
685a3ee cost calculations for DomainActivator
ec8b1cc test fixes; trivial domain test passes now
845b1f2 rename InvoiceCharge::CreateDomain to ..::RegisterDomain
(e) 6083a97 add durations to Domain consumers and charges
c64fda0 tests for Domain::Activator consumer
41e4292 repeat activator tests for 1-year and 3-year durations
7d68065 tests for activator's replacement
(d) 87f3b09 move days_in_year to Moonpig::Util
3cd9f3b WIP
e5063d4 add test for sent invoice in domain.t
c8dbf41 WIP
9e6ffa4 add missing MakesReplacement stuff
fc13059 bring in Net::OpenSRS module
(c) 52c18fb OpenSRS interface
893f16f notes about why domain queries might fail
(b) f64361f rename "croak" method to "fail" to avoid conflicts
4e500ec Domain::Activator initial_invoice_charge_pairs
(a) 3c5cdd4 WIP
3c5cdd4 (a) was the end-of-day state for yesterday; I made it and
pushed it just before I dashed out the door to go home. Such commits
rarely survive beyond the following morning, but if I didn't make them,
I wouldn't be able to continue work from home if the mood took me to
do that.f64361f (b) is a prime candidate for later squashing. 5c218fb (c) introduced a module with a "croak" method. This turned out to be a stupid idea, because this conflicted with the croak function from Perl's Carp module, which we use everywhere. I needed to rename it. By then, the intervening commit already existed. I probably should have squashed these right away, but I didn't think of it at the time. No problem! Git means never having to say "If only I'd realized sooner."
Similarly, 6083a97 (e) added a days_in_year function that I later decided at 87f3b09 (d) should be in a utility module in a different repository. 87f3b09 will eventually be squashed into 6083a97 so that days_in_year never appears in this code at all.
I don't know what is in the WIP commits c8dbf41 or 3cd9f3b, for which I didn't invent commit messages. I don't know why those are left in the tree, but I can figure it out later.
An example cleanup
Now I'm going to clean up this branch. First I git-checkout -b cleanup c-domain so that if something goes awry I can start over completely fresh by doing git-reset --hard c-domain. That's probably superfluous in this case because origin/c-domain is also pointing to the same place, and origin is my private repo, but hey, branches are cheap.The first order of business is to get rid of those WIP commits. I'll git-reset HEAD^ to bring 3c5cdd4 into the working directory, then use git-status to see how many changes there are:
M lib/Pobox/Moonpig/Consumer/Domain/Activator.pm
M lib/Pobox/Moonpig/Role/HasDomain.pm
M lib/Pobox/Moonpig/TemplateSet.pm
?? bin/register_domains
M t/consumer/domain.t
?? t/lib/MockOpenSRS.pm
(This is the output from git-status --short, for which I have
an alias, git s. I use this probably 99 times as often as
plain git-status.)Not too bad, probably no need for a printout. The new bin/register-domains program can go in right away by itself:
% git add bin
% git commit -m 'new register_domains utility program'
Next I'll deal with that new mock object class in
t/lib/MockOpenSRS.pm. I'll add that, then use git-add
-p to add the related changes from the other files:
% git add t/lib
% git add -p
...
% git s
MM lib/Pobox/Moonpig/Consumer/Domain/Activator.pm
M lib/Pobox/Moonpig/Role/HasDomain.pm
M lib/Pobox/Moonpig/TemplateSet.pm
A t/lib/MockOpenSRS.pm
MM t/consumer/domain.t
% git ix
...
The git ix command at the end there is an alias for git diff
--cached: it displays what's staged in the index. The output
looks good, so I'll commit it:
% git commit -m 'mock OpenSRS object; add tests'
Now I want to see if those tests actually pass. Maybe I forgot
something!
% git stash
% make test
...
OK
% git stash pop
The git-stash command hides the unrelated changes from the
test suite so that I can see if the tests I just put into
t/consumer/domain.t work properly. They do, so I bring back
the stashed changes and continue. If they didn't, I'd probably amend
the last commit with git commit --amend and try again.Continuing:
% git diff
...
% git add -p lib/Pobox/Moonpig/Role/HasDomain.pm
...
% git commit -m 'Domains do not have explicit start dates'
% git diff
...
% git add -p
...
% git commit --fixup :/mock
That last bit should have been part of the "mock OpenSRS object"
commit, but I forgot it. So I make a fixup commit, which I'll merge
into the main commit later on. A fixup commit is one whose subject
begins with fixup!. Did you know that you can name a commit
by writing :/text, and it names the most recent commit
whose message contains that text?It goes on like that for a while:
% git diff
...
% git add -p ...
...
% git commit -m 'Activator consumer can generate special charges'
% git diff
...
% git checkout lib/Pobox/Moonpig/Role/HasDomain.pm
The only uncommitted change left in HasDomain.pm was a
superfluous line, so I just threw it away.
% git diff
...
% git add -u
% git commit -m 'separate templates for domain-registering and domain-renewing consumers'
By this time all the remaining changes belong in the same commit, so I
use git-add -u to add them all at once. The working tree is
now clean. The history is as I showed above, except that in place of
the final WIP commit, I have:
a3c0b92 new register_domains utility program
53d704d mock OpenSRS object; add tests
a24acd8 Domains do not have explicit start dates
17a915d fixup! mock OpenSRS object; add tests
86e472b Activator consumer can generate special charges
5b2ad2b separate templates for domain-registering and domain-renewing consumers
(Again the oldest commit is first.) Now I'll get rid of that
fixup!:
% git rebase -i --autosquash HEAD~6
Because of --autosquash, the git-rebase menu is
reordered so that the fixup commit is put just after
the commit it fixes up, and its default action is 'fixup' instead of
'pick'. So I don't need to edit the rebase instructions at all. But
I might as well take the opportunity to put the commits in the right
order. The result is:
a3c0b92 new register_domains utility program
ea8dacd Domains do not have explicit start dates
297366a separate templates for domain-registering and domain-renewing consumers
4ef0e28 mock OpenSRS object; add tests
c3ab1eb Activator consumer can generate special charges
I have two tools for dealing with cleaned-up
branches like this one. One is git-vee, which compares two branches. It's
just a wrapper around the command git log --decorate --cherry-mark
--oneline --graph --boundary A"..."B. Here's a comparison the original c-domain branch and my new cleanup version:
% git vee c-domain
* c3ab1eb (HEAD, cleanup) Activator consumer can generate special charges
* 4ef0e28 mock OpenSRS object; add tests
* 297366a separate templates for domain-registering and domain-renewing consumer
* ea8dacd Domains do not have explicit start dates
* a3c0b92 new register_domains utility program
| * 3c5cdd4 (origin/c-domain, c-domain) WIP
|/
o 4e500ec Domain::Activator initial_invoice_charge_pairs
This clearly shows where the original and cleaned up branches diverge,
and what the differences are. I also use git-vee to compare
pre- and post-rebase versions of branches (with git-vee
ORIG_HEAD) and local branches with their remote tracking branches
after fetching (with git-vee remote or just plain
git-vee).A cleaned-up branch should usually have the same final tree as the tree at the end of the original branch. I have another tool, git-treehash, which compares trees. By default it compares HEAD with ORIG_HEAD, so after I use git-rebase to squash or to split commits, I sometimes run "git treehash" to make sure that the tree hasn't changed. In this example, I do:
% git treehash c-domain HEAD
d360408d1afa90e0176aaa73bf8d3cae641a0850 HEAD
f0fd6ea0de7dbe60520e2a69fbec210260370d78 c-domain
which tells me that they are not the same. Most often this
happens because I threw away all the debugging code that I put in
earlier, but this time it was because of that line of superfluous code
I eliminated from HasDomain.pm. When the treehashes differ, I'll use
git-diff to make sure that the difference is innocuous:
% git diff c-domain
diff --git a/lib/Pobox/Moonpig/Role/HasDomain.pm b/lib/Pobox/Moonpig/Role/HasDomain.pm
index 3d8bb8c..21cb752 100644
--- a/lib/Pobox/Moonpig/Role/HasDomain.pm
+++ b/lib/Pobox/Moonpig/Role/HasDomain.pm
@@ -5,7 +5,6 @@ use Carp qw(croak confess);
use ICG::Handy qw(is_domain);
use Moonpig::Types qw(Factory Time);
use Moose::Util::TypeConstraints qw(duck_type enum subtype);
-use MooseX::SetOnce;
with (
'Moonpig::Role::StubBuild',
Okay then.The next task is probably to deal with the older WIP commits. This time I'll omit all the details. But the enclosing procedure looks like this:
% git checkout -b wip-cleanup c8dbf41
% git reset HEAD^
% ... (a lot of git-add -p as above) ...
...
% git vee c8dbf41
* 4c6ff45 (wip-cleanup) get rid of unused twiddler test
* b328de5 test full payment cycle
* 201a4f2 abstract out pay_invoice operation
* 55ae45e add upper limit (default 30d) to wait_until utility
| * c8dbf41 WIP
|/
o e5063d4 add test for sent invoice in domain.t
% git treehash c8dbf41 HEAD
7f52ba68923e2ede8fda407ffa9c06c5c48338ae
% git checkout cleanup
% git rebase wip-cleanup
The output of git-treehash says that the tree at the end of
the wip-cleanup branch is identical to the one in the WIP
commit it is supposed to replace, so it's perfectly safe to rebase the
rest of the cleanup branch onto it, replacing the one WIP
commit with the four new commits in wip-cleanup. Now the
cleaned up branch looks like this:
% git vee c-domain
* a425aa1 (HEAD, cleanup) Activator consumer can generate special charges
* 2bb0932 mock OpenSRS object; add tests
* a77bfcb separate templates for domain-registering and domain-renewing consumer
* 4c44db2 Domains do not have explicit start dates
* fab500f new register_domains utility program
= 38018b6 Domain::Activator initial_invoice_charge_pairs
= aebbae6 rename "croak" method to "fail" to avoid conflicts
= 45a224d notes about why domain queries might fail
= 80e4a90 OpenSRS interface
= 27f4562 bring in Net::OpenSRS module
= f5cb624 add missing MakesReplacement stuff
* 4c6ff45 (wip-cleanup) get rid of unused twiddler test
* b328de5 test full payment cycle
* 201a4f2 abstract out pay_invoice operation
* 55ae45e add upper limit (default 30d) to wait_until utility
| * 3c5cdd4 (origin/c-domain, c-domain) WIP
| = 4e500ec Domain::Activator initial_invoice_charge_pairs
| = f64361f rename "croak" method to "fail" to avoid conflicts
| = 893f16f notes about why domain queries might fail
| = 52c18fb OpenSRS interface
| = fc13059 bring in Net::OpenSRS module
| = 9e6ffa4 add missing MakesReplacement stuff
| * c8dbf41 WIP
|/
o e5063d4 add test for sent invoice in domain.t
git-vee marks a commit with an equal sign instead of a star
if it's equivalent to a commit in the other branch. The commits in
the middle marked with equals signs are the ones that weren't changed.
The upper WIP was replaced with five commits, and the lower one with
four.I've been planning for a long time to write a tool to help me with breaking up WIP commits like this, and with branch cleanup in general: It will write each changed hunk into a file, and then let me separate the hunk files into several subdirectories, each of which represents one commit, and then it will create the commits automatically from the directory contents. This is still only partly finished, but I think when it's done it will eliminate the six-color diff printouts.
[ Addendum 20120404: Further observation has revealed that I almost never use git-commit -a, even when it would be quicker to do so. Instead, I almost always use git-add -u and then git-commit the resulting index. This is just an observation, and not a claim that my practice is either better or worse than using git-commit -a. ]
[ Addendum 20120825: There is now a followup article about how to manage rewriting of published history. ]
[Other articles in category /prog] permanent link
Sun, 04 Mar 2012
Why can't Git resolve all conflicted merges?
I like to be prepared ahead of time for questions, and one such
question is why Git can't resolve all merge conflicts automatically.
People do show up on IRC asking this from time to time. If you're a
sophisticated user the answer is obvious, but I've made a pretty good
living teaching classes to people who don't find such things
obvious.
What we need is a nice example. In the past my example was sort of silly. You have a file that contains the instruction:
Pay potato tax every April 15
One branch adds an exception:
Pay potato tax every April 15
(Except in years of potato blight.)
While another branch broadens the original instruction:
Pay all tax due every April 15
What's the correct resolution here? It's easy to understand that
mashing together the two changes is a recipe for potential
catastrophe:
Pay all tax due every April 15
(Except in years of potato blight.)
You get fined for tax evasion after the next potato blight. And it's
similarly easy to construct scenarios in which the correct resolution
is to leave the whole thing in place including the modifier, change
the thing to something else completely, delete the whole thing, or to
refer the matter to Legal and shut down the whole system until you
hear back. Clearly it's outside Git's scope to recognize when to call
in the lawyers, much less to predict what their answer will be. But a few months ago I ran into a somewhat less silly example. At work we had two seprate projects, "Moonpig" and "Stick", each in its own repository. Moonpig contained a subsystem, "Collections", which we decided would make more sense as part of Stick. I did this work, removing the Collections code from the Moonpig project and integrating it into the Stick project. From the point of view of the Moonpig repository, the Collections system was deleted entirely.
Meanwhile, on a parallel branch of Moonpig, R.J.B. Signes made some changes that included bug fixes to the Collections. After I removed the collections, he tried to merge his changes into the master branch, and got a merge conflict, because some of the files to which he was making bug fixes were no longer there.
The correct resolution was to perform the rest of the merge without the bug fixes, which Git could conceivably have done. But then the unapplied bug fixes needed to be applied to the Collections module that was now in the completely separate Stick project, and there is no way Git could have done this, or even to have known it should be done. Human intervention was the only answer.
[Other articles in category /prog] permanent link
Wed, 15 Feb 2012
Insane calculations in bash
A few weeks ago I wrote an
article about various methods of arithmetic calculation in shell
scripts and in bash in particular, but it was all leading
up to today's article, which I think is more interesting
technically.
A while back, Zach Holman (who I hadn't heard of before, but who is apparently a bigwig at GitHub) implemented a kind of cute little hack, called "spark". It's a little shell utility, spark, which gets a list of numbers as its input and uses Unicode block characters to print a little bar graph of the numbers on the output. For example, the invocation:
spark 2,4,6,8will print out something like:
▃▄▆▇To do this in one of the 'P' languages (Perl, Python, PHP, Puby, or maybe Pickle) takes something like four lines of code. But M. Holman decided to implement it in bash for maximum portability, so it took 72 lines, not counting comments, whitespace, etc.
Let's begin by discussing the (very simple) mathematics that underlies drawing bar graphs. Suppose you want to generate a set of bars for the numbers $1, $9, $20. And suppose you can actually generate bars of integer heights only, say integers from 0–7:
0 1 ▁ 2 ▂ 3 ▃ 4 ▄ 5 ▅ 6 ▆ 7 ▇(M. Holman 's original program did this, even though a height-8 bar █ is available. But the mathematics is the same either way.)
Absolute scaling
The first step is to scale the input numbers onto the range of the bars. To do this, we find a scale factor f that maps dollars onto bar heights, say that f bar units = $1.A reasonable thing to try is to say that since your largest number is $20, we will set 7 bar units = $20. Then 0.35 bar units = $1, and 3.45 bar units = $9. We'll call these the "natural heights" for the bars.
Unfortunately we can't render the bars at their natural heights; we can only render them at integer heights, so we have to round off. 0.35 bar units rounds off to 0, so we will represent $1 as no bar at all. 3.45 bar units rounds off, badly, to 3, but that's the way it goes; if you try to squeeze the numbers from 1 to 20 into the range 0 to 7, something has to give. Anyway, this gives
(1,9,20) → ( ▃▇)
The formula is: Let max be the largest input number (here,
20) and let n be the size of the largest possible bar (here, 7).
Then an input number x becomes a bar of size
n·x / max:
$$x\rightarrow {n\cdot x \over max } $$
Note that this maps max itself to n, and 0 to 0.I'll call this method "absolute scaling", because big numbers turn into big bars. (It fails for negative numbers, but we'll assume that the numbers are non-negative.)
(0…20) → ( ▁▁▁▂▂▂▃▃▄▄▄▅▅▅▆▆▆▇▇)There are a couple of variations we might want to apply. First, maybe we don't like that $1 mapped to no bar at all; it's too hard to see, depending on the context. Perhaps we would like to guarantee that only 0 maps to 0. One way to ensure that is to round everything up, instead of rounding to the nearest integer:
(0…20) → ( ▁▁▂▂▂▃▃▃▄▄▄▅▅▅▆▆▆▇▇▇)
(1,9,20) → (▁▄▇)
Another benefit of always rounding up is that it uses the bars
equally. Suppose we're mapping numbers in the range 1–100 to bars of
heights 1–7. If we round off to the nearest integer, each bar
represents 14 or 15 different numbers, except that the tallest bar
only represents the 8 numbers 93–100. This is a typical situation.
If we always round up, each bar corresponds to a nearly equal range of
numbers. (Another way to adjust this is to replace n with
n+½ in the formula.)
Relative scaling
Now consider the numbers $18, $19, $20. Under the absolute scaling method, we get:
(18,19,20) → (▆▇▇)or, if you're rounding up,
(18,19,20) → (▇▇▇)which obscures the difference between the numbers. There's only an 11% difference between the tallest and shortest bar, and that doesn't show up at this resolution. Depending on your application, this might be what you want, but we might also want to avail ourselves of the old trick of adjusting the baseline. Instead of the bottom of the bar being 0, we can say it represents 17. This effectively reduces every bar by 17 before scaling it, so that the number x is now represented by a bar with natural height n·(x−17) / (max−17). Then we get these bars:
(18,19,20) → (▃▅▇)Whether this "relative scaling" is a better representation than ▇▇▇ depends on the application. It emphasizes different properties of the data.
In general, if we put the baseline at b, the natural height for a bar representing number x is:
$$x\rightarrow {n\cdot (x-b) \over (max-b) } $$
That is the same formula as before, except that everything has been shifted down by b.A reasonable choice of b would be the minimum input value, or perhaps a bit less than the minimum input value.
The shell sucks
But anyway, what I really wanted to talk about was how to fix this program, because I think my solution was fun and interesting. There is a tricky problem, which is that you need to calculate values like (n-b)/(x-b), which so you might like to do some division, but as I wrote earlier, bash has no facilities for doing fractional arithmetic. The original program used $((…)) everywhere, which throws away fractions. You can work around that, because you don't actually the fractional part of (n-b)/(x-b); you only need the greatest integer part. But the inputs to the program might themselves be fractional numbers, like say 3.5, and $((…)) barfs if you try to operate on such a number:
$ x=3.5; echo $((x + 1)) bash: 3.5: syntax error: invalid arithmetic operator (error token is ".5")and you seemingly cannot work around that.
My first response to this was to replace all the uses of $((…)) with bc, which, as I explained in the previous article, does not share this problem. M. Holman rejected this, saying that calling out to bc all the time made the program too slow. And there is something to be said for this. M. Holman also said that bc is non-portable, which I find astounding, since it has been in Unix since 1974, but sadly plausible.
So supposing that you take this complaint seriously, what can you do? Are you just doomed? No, I found a solution to the problem that solves all the problems. It is portable, efficient, and correct. It is also slightly insane.
Portable fractions in bash
We cannot use decimal numbers:
$ x=3.5; echo $((x + 1)) bash: 3.5: syntax error: invalid arithmetic operator (error token is ".5")But we can use fractions:
$ x_n=7; x_d=2; echo $((x_n + x_d))/$((x_d))
9/2
And we can convert decimal inputs to fractions without arithmetic:
# given an input number which might be a decimal, convert it to
# a rational number; set n and d to its numerator and
# denominator. For example, 3.3 becomes n=33 and d=10;
# 17 becomes n=17 and d=1.
to_rational() {
# Crapulent bash can't handle decimal numbers, so we will convert
# the input number to a rational
if [[ $1 =~ (.*)\.(.*) ]] ; then
i_part=${BASH_REMATCH[1]}
f_part=${BASH_REMATCH[2]}
n="$i_part$f_part";
d=$(( 10 ** ${#f_part} ))
else
n=$1
d=1
fi
}
This processes a number like 35.17 in a purely lexical way, extracting
the 35 and the 17, and turning them into the numerator 3517 and the
denominator 100. If the input number contains no decimal point, our
task is trivial: 23 has a numerator of 23 and a denominator of 1.Now we can rewrite all the shell arithmetic in terms of rational numbers. If a_n and a_d are the numerator and denominator of a, and b_n and b_d are the numerator and denominator of b, then addition, subtraction, multiplication, and even division of a and b are fast, easy, and even portable:
# a + b
sum_n = $((a_n * b_d + a_d * b_n))
sum_d = $((a_d * b_d))
# a - b
diff_n = $((a_n * b_d - a_d * b_n))
diff_d = $((a_d * b_d))
# a * b
prod_n = $((a_n * b_n))
prod_d = $((a_d * b_d))
# a / b
quot_n = $((a_n * b_d))
quot_d = $((a_d * b_n))
We can easily truncate a number to produce an integer, because the
built-in division does this for us:
greatest_int = $((a_n / a_d))
And we can round to the nearest integer by adding 1/2 before
truncating:
nearest_int = $(( (a_n * 2 + a_d) / (a_d * 2) ))
(Since n/d + 1/2 = (2n+d)/2d.)For complicated calculations, you can work the thing out as several steps, or you can solve it on paper and then just embed a big rational expression. For example, suppose you want to calculate ((x-min)·number_of_tiers)/range, where number_of_tiers is known to be an integer. You could do each operation in a separate step, or you could use instead:
tick_index_n=$(( ( x_n * min_d - min_n * x_d ) * number_of_tiers * range_d )) tick_index_d=$(( range_n * x_d * min_d ))Should you need to convert to decimals for output, the following is a proof-of-concept converter:
function to_dec {
n=$1
d=$2
maxit=$(( 1 + ${3:-10} ))
while [ $n != 0 -a $maxit -gt -1 ]; do
next=$((n/d))
if [ "$r" = "" ]; then r="$next."; else r="$r$next"; fi
n=$(( (n - d * next) * 10 ))
maxit=$(( maxit - 1 ))
done
r=${r:-'0.'}
}
For example, to_dec 13 8 sets r to
1.625, and to_dec 13 7 sets r to
1.857142857. The optional third argument controls the
maximum number of digits after the decimal point, and defaults to
10. The principal defect is that it doesn't properly round off;
frac2dec 19 10 0 yields 1. instead of 2.,
but this could be fixed without much trouble. Extending it to
convert to arbitrary base output is quite easy as well.Coming next month, libraries in bash for computing with continued fractions using Gosper's algorithms. Ha ha, just kidding. The obvious next step is to implement base-10 floating-point numbers in bash like this:
prod_mantissa=$((a_mantissa * b_mantissa)) prod_exponent=$((a_exponent + b_exponent))[ Addendum 20120306: David Jones corrects a number of portability problems in my implementation. ]
[ Addendum 20180101: Shane Hansen did something similar to calculate Euler's number (2.71818…) in Bash a while back. It might be fun to compare our implementations. ]
[Other articles in category /prog] permanent link
Thu, 09 Feb 2012
Testing for exceptions
The Test::Fatal
module makes it very easy to test code that is supposed to throw
an exception. It provides an exception function that takes a
code block. If the code completes normally, exception {
code } returns undefined; if the code throws an exception,
exception { code } returns the exception value that
was thrown. So for example, if you want to make sure that some
erroneous call is detected and throws an exception, you can use
this:
isnt( exception { do_something( how_many_times => "W" ) },
undef,
"how_many_times argument requires a number" );
which will succeed if do_something(…) throws an exception,
and fail if it does not. You can also write a stricter test, to look
for the particular exception you expect:
like( exception { do_something( how_many_times => "W" ) },
qr/how_many_times is not numeric/,
"how_many_times argument requires a number" );
which will succeed if do_something(…) throws an exception
that contains how_many_times is not numeric, and fail
otherwise.Today I almost made the terrible mistake of using the first form instead of the second. The manual suggests that you use the first form, but it's a bad suggestion. The problem is that if you completely screw up the test and write a broken code block that dies, the first test will cheerfully succeed anyway. For example, suppose you make a typo in the test code:
isnt( exception { do_something( how_many_tims => "W" ) },
undef,
"how_many_times argument requires a number" );
Here the do_something(…) call throws some totally different
exception that we are not interested in, something like unknown
argument 'how_many_tims' or mandatory 'how_many_times'
argument missing, but the exception is swallowed and the test
reports success, even though we know nothing at all about the feature
we were trying to test. But the test looks like it passed.In my example today, the code looked like this:
isnt( exception {
my $invoice = gen_invoice();
$invoice->abandon;
}, undef,
"Can't abandon invoice with no abandoned charges");
});
The abandon call was supposed to fail, for reasons you don't
care about. But in fact, the execution never got that far, because
there was a totally dumb bug in gen_invoice() (a missing
required constructor argument) that caused it to die with a completely
different exception.I would never have noticed this error if I hadn't spontaneously decided to make the test stricter:
like( exception {
my $invoice = gen_invoice();
$invoice->abandon;
}, qr/Can't.*with no abandoned charges/,
"Can't abandon invoice with no abandoned charges");
});
This test failed, and the failure made clear that
gen_invoice(), a piece of otherwise unimportant test
apparatus, was completely broken, and that several other tests I had
written in the same style appeared to be passing but weren't actually
running the code I thought they were.So the rule of thumb is: even though the Test::Fatal manual suggests that you use isnt( exception { … }, undef, …), do not.
I mentioned this to Ricardo Signes, the author of the module, and he released a new version with revised documentation before I managed to get this blog post published.
[Other articles in category /prog/perl] permanent link
Wed, 16 Nov 2011
Arithmetic expressions in shell scripts
This spring will be the 25th anniversary of my involvement with Unix,
and I have spent way too much of that time writing shell scripts.
Back before we had Perl and the other 'P' languages (Python, PHP,
Puby, and Pickle) you programmed in C or you programmed in shell.
Bourne shell, to be specific. (It was named for its author, Steven
Bourne. There was a time before there was a Bourne shell, when there
was only "the shell", written by Ken Thompson, but that predates even
my experience.) People did sometimes try to program the C shell,
but only the very foolish tried it more than once. (Tom Christiansen
once wrote a very
detailed article explaining why, if you are interested.)
C is still used, but it is still C, and, as they say, C is a language that combines the power of raw assembly with the expressiveness of raw assembly. If you wanted to do systems programming, you wrote in C, because that was what there was, but if you wanted to do almost anything else, you wrote in Bourne shell, because otherwise you spent a lot of time counting bytes and groveling over core dumps. If you knew what you were doing, you wrote as much as possible in Bourne shell, and for the parts where your shell script needed to do something interesting, you had it invoke some small utility program that you or someone else had written in C.
"Interesting" in this case had an extremely low threshhold. You called out to a C utility to sort data. You called out to a C utility to remove or rename a file. You called out to a C utility to test for the existence of a file. You called out to a C utility to compare two strings. In early versions of the shell, you called out to a C utility to perform file globbing—that is, to expand something like dir?/*.c to a list of files—although this function had been absorbed into the shell itself by 1979, several years before I arrived. You called out to a C utility to print a string to the terminal. And you called out to a C utility if you wanted to do arithmetic.
Even including languages that nobody is expected to actually use, Bourne shell is probably the only programming language I have ever used that does not have any built-in operators for performing arithmetic. Instead, there is a C utility program called expr which interprets its command-line arguments as an arithmetic expression, evaluates the expression, and prints the result on the standard output. So for example, if your script has variables x and y and you want to add these and store the result into z, you write:
z=`expr $x + $y`
This will fork a subprocess, which will execute the command expr
3 + 4 (or whatever). The command will emit the string
7 into a pipe, and the shell will read the string out of the
pipe and store it into z. Astounding!The expr program is a real piece of crap. The following reasonable-seeming invocations of expr all fail:
z=`expr $x + 1.5`
z=`expr $x+$y`
z=`expr $x * $y`
The first fails because the craptastic yacc parser in expr has a value stack
that is integer-only, so the program was not written to handle
fractional values, and will instantly abort with the message
non-numeric argument upon encountering the string 1.5 in
the input. The second fails because the craptastrophic lexer (a whole 12
lines of C code) assumes that
each command argument will be a single token, and makes no effort to
actually do any, you know, lexing. The third fails because
expr is a command run in a subshell, and since the * character is special
in the shell it expands to a list of the files in the current
directory, so although you thought you were going to run expr 3 * 4
you actually ran expr 3 hostid sys3 sys3.tar.gz v5root
v5root.tar.gz v6doc v6doc.tar.gz v6root v6root.tar.gz v6src
v6src.tar.gz v7 v7.tar.gz 4. The whole thing is a craptaclysm of craptitude.A better way to do arithmetic in a shell script was to invoke a different utility program, bc, the "basic calculator". You sent your arithmetic expression to bc on the standard input (which avoided the craptysmal shell expansion of *) and got the answer on the standard output, typically something like this:
z=`echo "$x + $y" | bc -l`
You needed the -l flag to enable floating-point calculations;
it also enabled certain higher functions such as square roots and
trigonometry. [ Addendum 20200108: The effect of -l is rather more complicated than I said; bc actually does base-10 floating-point arithmetic by default. ]
I had assumed that bc was a later development than expr, but it appeared in Unix version 6, while expr did not appear until version 7. So then I thought perhaps expr had been thrown in as a demonstration of yacc, but no, yacc was already present in version 5, and anyway, bc was written with yacc. So I no longer have any workable theory about who perpetrated expr, or why. (I have emailed Brian Kernighan to ask, and if he says anything interesting I will post an addendum.)
Anyway, about ten years after all this, the GNU project was in full swing and was reimplementing all the standard Unix tools, including the shell. Since they wanted their implementations to displace the standard implementations, they added all sorts of bells and whistles to them. So their shell, bash, contained all sorts of stuff. Among other things, it had built-in arithmetic. In bash, if you want to add x and y and put the result into z you can write:
z=$(( x + y ))
or even:
z=$((x+y))
The nifty $(( punctuation was necessary because the syntax had
to be backward compatible with the Bourne shell, and every clean
syntax was already used for something else. The $((…)) feature was a great
improvement over expr, and in some ways, it was even an
improvement over bc. It is much faster, for one thing. And
since it does not invoke a subshell, you don't have to worry about
* doing something weird.But in other ways it was a step backwards. It does not have any of bc's higher mathematical functions. It doesn't do radix conversion. And it does all its calculation in machine integers, so not only does it fall short of bc's arbitrary-precision arithmetic, it can't even handle fractions:
x=3; y=4.5 echo $((x+y)) bash: 4.5: syntax error: invalid arithmetic operator (error token is ".5")Why? Why why why??? Who ordered that? I mean, I hate floating-point arithmetic as much as the next guy—probably more—but even I recognize that people need to do it sometimes.
Well, here we are, eleven hundred words into this article and I have still not come to the point. That is typical for me, but I think that contrary to my usual practice, I will cut the scroll here and get to the real point in a day or two.
[ Addendum 20120215: At last, I got to the real point. ]
[Other articles in category /prog] permanent link
Wed, 24 Nov 2010
git-reset
The Git subcommand git-reset is very frequently used, and is one of very few
commonly-used Git commands that can permanently destroy real work.
Once work is in the repository, it is almost completely safe from any
catastrophe. But git-reset also affects the working tree, and it is quite
possible to utterly destroy a day's work by doing git-reset --hard at the wrong
time. Unfortunately, the manual is unusually bad, with a huge pile of
this stuff:
working index HEAD target working index HEAD
----------------------------------------------------
A B C D --soft A B D
--mixed A D D
--hard D D D
--merge (disallowed)
working index HEAD target working index HEAD
----------------------------------------------------
A B C C --soft A B C
--mixed A C C
--hard C C C
--merge (disallowed)
Six more of these tables follow, giving the impression that git-reset is quite complicated. Sure, I'm gonna memorize 256 table entries. Or look up the results on the table before every git-reset. Not.
The thing to notice about the two tables I quoted above is that they are redundant, because the second one is simply a special case of the first, with D replaced by C. So if you were really in love with the tables, you might abbreviate the 64 table entries to 28:
working index target working index HEAD
----------------------------------------------------
A B C --soft A B C
--mixed A C C
--hard C C C
--merge (disallowed)
But even this is much more complicated than it should be. git-reset does up
to three things:
- It points the HEAD ref at a new 'target' commit, if you specified one.
- Then it copies the tree of the HEAD commit to the index, unless you said --soft.
- Finally, it copies the contents of the index to the working tree, if you said --hard.
Tables are good for computers to understand, because they have a uniform format and computers are unfazed by giant masses of redundant data. The computer will not understand the data regardless of how well-structured they are, so there is no reason to adopt a representation that showcases the structure.
For humans, however, tables are most useful when there is no deeper understanding of the structure to be had, because the structure tends to get lost in the profusion of data, as it did here.
[ Thanks to Aristotle Pagaltzis for pointing out that git checkout can also destroy the working tree, and for other corrections. ]
[Other articles in category /prog] permanent link
Wed, 10 Nov 2010
Revert-all-buffers
This is another article about a trivial tool that is worth more to me
than it cost to make. It's my new revert-all-buffers
function for Emacs.
Here's the use case: I'm editing 17 files, and I've saved a bunch of changes to them. Then I commit the changes with git, and then I change the working copy of the files out from under Emacs by doing some other git operation—I merge in another branch, or do a rebase, or something like that.
Now when I go back to edit the files, the Emacs buffers are out of date. Emacs notices that, and for each file, it will at some point ask me "Contents of ... have changed on disk; do you really want to edit the buffer?", interrupting my train of thought. I can answer the question by typing r, which will refresh the buffer from the disk version, but having to do that for every buffer is a pain, because I know all those files have changed, and I don't want to be asked each time.
Here's the solution:
(defun revert-all-buffers ()
"Refreshes all open buffers from their respective files"
(interactive)
(let* ((list (buffer-list))
(buffer (car list)))
(while buffer
(when (and (buffer-file-name buffer)
(not (buffer-modified-p buffer)))
(set-buffer buffer)
(revert-buffer t t t))
(setq list (cdr list))
(setq buffer (car list))))
(message "Refreshed open files"))
I have this function bound to some otherwise useless key: it runs
through all the buffers, and for each one that has an associated file,
and has no unsaved changes, it reverts the contents from the
version on the disk.This occasionally fails, most often because I have removed or renamed a file from the disk that I still have open in Emacs. Usually the response is to close the buffer, or reopen it from the new name. I could probably handle that properly in 99% of cases just by having Emacs close the buffer, but the other cases could be catastrophic, so I'm leaving it the way it is for a while.
I swiped the code, with small changes, from EmacsWiki.
[Other articles in category /prog] permanent link
Fri, 27 Aug 2010
A dummy generator for mock objects
I am not sure how useful this actually is, but I after having used it
once it was not yet obvious that it was a bad idea, so I am writing it
up here.
Suppose you are debugging some method, say someMethod, which accepts as one of its arguments complicated, annoying objects $annoying that you either can't or don't want to instantiate. This might be because $annoying is very complicated, with many sub-objects to set up, or perhaps you simply don't know how to build $annoying and don't care to find out.
That is okay, because you can get someMethod to run without the full behavior of $annoying. Say for example someMethod calls $annoying->foo_manager->get_foo(...)->get_user_id. You don't understand or care about the details because for debugging someMethod it is enough to suppose that the end result is the user ID 3. You could supply a mock object, or several, that implement the various methods, but that requires some work up front.
Instead, use this canned Dummy class. Instead of instantiating a real $annoying (which is difficult) or using a bespoke mock object, use Dummy->new("annoying"):
package Dummy;
use Data::Dumper;
$Data::Dumper::Terse = 1;
our $METHOD;
my @names = qw(bottle corncob euphonium octopus potato slide);
my $NAME = "aaa";
sub new {
my ($class, $name) = @_;
$name ||= $METHOD || shift(@names) || $NAME++;
bless { N => $name } => $class;
}
The call Dummy->new("annoying") will generate an ad-hoc mock
object; whenever any method is called on this dummy object, the call
will be caught by an AUTOLOAD that will prompt you for the
return value you want it to produce:
sub AUTOLOAD {
my ($self, @args) = @_;
my ($p, $m) = $AUTOLOAD =~ /(.*)::(.*)/;
local $METHOD = $m;
print STDERR "<< $_[0]{N}\->$m >>\n";
print STDERR "Arguments: " . Dumper(\@args) . "\n";
my $v;
do {
print STDERR "Value? ";
chomp($v = <STDIN>);
} until eval "$v; 1";
return(eval $v);
}
sub DESTROY { }
1;
The prompt looks like this:
<< annoying->foo_manager >> Arguments: [] Value?If the returned value should be a sub-object, no problem: just put in new Dummy and it will make a new Dummy object named foo_manager, and the next prompt will be:
<< foo_manager->get_foo >> Arguments: ... ... Value?Now you can put in new Dummy "(Fred's foo)" or whatever. Eventually it will ask you for a value for (Fred's foo)->id and you can have it return 4.
It's tempting to add caching, so that it won't ask you twice for the results of the same method call. But that would foreclose the option to have the call return different results twice. Better, I think, is for the user to cache the results themselves if they plan to use them again; there is nothing stopping the user from entering a value expression like $::val = ....
This may turn out to be one of those things that is mildly useful, but not useful enough to actually use; we'll see.
[Other articles in category /prog/perl] permanent link
Thu, 26 Aug 2010
Monad terminology problem
I think one problem (of many) that beginners might have with Haskell
monads is the confusing terminology. The word "monad" can refer to
four related but different things:
- The Monad typeclass itself.
- When a type constructor T of kind ∗ → ∗ is an
instance of Monad we say that T "is a monad".
For example, "Tree is a monad"; "((→) a) is
a monad". This is the only usage that is strictly corrrect.
- Types resulting from the application of monadic type constructors
(#2) are sometimes referred to as monads. For example, "[Integer]
is a monad".
- Individual values of monadic types (#3) are often referred to as
monads. For example, the "All
About Monads" tutorial says "A
list is also a monad".
The most serious problem here is #4, that people refer to individual values of monadic types as "monads". Even when they don't do this, they are hampered by the lack of a good term for it. As I know no good alternative has been proposed. People often say "monadic value" (I think), which is accurate, but something of a mouthful.
One thing I have discovered in my writing life is that the clarity of a confusing document can sometimes be improved merely by replacing a polysyllabic noun phrase with a monosyllable. For example, chapter 3 of Higher-Order Perl discussed the technique of memoizing a function by generating an anonymous replacement for it that maintains a cache and calls the real function on a cache miss. Early drafts were hard to understand, and improved greatly when I replaced the phrase "anonymous replacement function" with "stub". The Perl documentation was significantly improved merely by replacing "associative array" everywhere with "hash" and "funny punctuation character" with "sigil".
I think a monosyllabic replacement for "monadic value" would be a similar boon to discussion of monads, not just for beginners but for everyone else too. The drawback, of introducing yet another jargon term, would in this case be outweighed by the benefits. Jargon can obscure, but sometimes it can clarify.
The replacement word should be euphonious, clear but not overly specific, and not easily confused with similar jargon words. It would probably be good for it to begin with the letter "m". I suggest:
So return takes a value and returns a mote. The >>= function similarly lifts a function on pure values to a function on motes; when the mote is a container one may think of >>= as applying the function to the values in the container. [] is a monad, so lists are motes. The expression on the right-hand side of a var ← expr in a do-block must have mote type; it binds the mote on the right to the name on the left, using the >>= operator.
I have been using this term privately for several months, and it has been a small but noticeable success. Writing and debugging monadic programs is easier because I have a simple name for the motes that the program manipulates, which I can use when I mumble to myself: "What is the type error here? Oh, commit should be returning a mote." And then I insert return in the right place.
I'm don't want to oversell the importance of this invention. But there is clearly a gap in the current terminology, and I think it is well-filled by "mote".
(While this article was in progress I discovered that What a Monad is not uses the nonceword "mobit". I still prefer "mote".)
[Other articles in category /prog/haskell] permanent link
Sun, 03 Jan 2010
A short bibliography of probability monads
Several people helpfully wrote to me to provide references to earlier
work on probability
distribution monads. Here is a summary:
- Material related to Martin Erwig and Steve Kollmansberger's
probability library:
- Probabilistic Functional Programming in Haskell, their 2006 paper
- the package, described in the paper, and specifically its probability distribution monad
- Some
commentary on this library, by someone who doesn't put their name
on their blog.
- Some stuff from Dan Piponi's blog:
- Eric Kidd's blog: "What would a programming language look like if Bayes’ rule were as simple as an if statement?"
I did not imagine that my idea was a new one. I arrived at it by thinking about List as a representation of non-deterministic computation. But if you think of it that way, the natural interpretation is that every list element represents an equally likely outcome, and so annotating the list elements with probabilities is the obvious next step. So the existence of the Erwig library was not a big surprise.
A little more surprising though, were the references in the Erwig paper. Specifically, the idea dates back to at least 1981; Erwig cites a paper that describes the probability monad in a pure-mathematics context.
Nobody responded to my taunting complaint about Haskell's failure to provide support a good monad of sets. It may be that this is because they all agree with me. (For example, the documentation of the Erwig package says "Unfortunately we cannot use a more efficient data structure because the key type must be of class Ord, but the Monad class does not allow constraints for result types.") But a number of years ago I said that the C++ macro processor blows goat dick. I would not have put it so strongly had I not naïvely believed that this was a universally-held opinion. But no, plenty of hapless C++ programmers wrote me indignant messages defending their macro system. So my being right is no guarantee that language partisans will not dispute with me, and the Haskell community's failure to do so in this case reflects well on them, I think.
[Other articles in category /prog/haskell] permanent link
Thu, 31 Dec 2009
A monad for probability and provenance
I don't quite remember how I arrived at this, but it occurred to me
last week that probability distributions form a monad. This is the
first time I've invented a new monad that I hadn't seen before; then I
implemented it and it behaved pretty much the way I thought it would.
So I feel like I've finally arrived, monadwise.
Suppose a monad value represents all the possible outcomes of an event, each with a probability of occurrence. For concreteness, let's suppose all our probability distributions are discrete. Then we might have:
data ProbDist p a = ProbDist [(a,p)] deriving (Eq, Show) unpd (ProbDist ps) = psEach a is an outcome, and each p is the probability of that outcome occurring. For example, biased and unbiased coins:
unbiasedCoin = ProbDist [ ("heads", 0.5),
("tails", 0.5) ];
biasedCoin = ProbDist [ ("heads", 0.6),
("tails", 0.4) ];
Or a couple of simple functions for making dice:
import Data.Ratio
d sides = ProbDist [(i, 1 % sides) | i <- [1 .. sides]]
die = d 6
d n is an n-sided die.
The Functor instance is straightforward:
instance Functor (ProbDist p) where
fmap f (ProbDist pas) = ProbDist $ map (\(a,p) -> (f a, p)) pas
The Monad instance requires return and
>>=. The return function merely takes an event and
turns it into a distribution where that event occurs with probability
1. I find join easier to think about than >>=.
The join function takes a nested distribution, where each
outcome of the outer distribution specifies an inner distribution for
the actual events, and collapses it into a regular, overall
distribution. For example, suppose you put a biased coin and an
unbiased coin in a bag, then pull one out and flip it:
bag :: ProbDist Double (ProbDist Double String)
bag = ProbDist [ (biasedCoin, 0.5),
(unbiasedCoin, 0.5) ]
The join operator collapses this into a single ProbDist
Double String:
ProbDist [("heads",0.3),
("tails",0.2),
("heads",0.25),
("tails",0.25)]
It would be nice if join could combine the duplicate
heads into a single ("heads", 0.55) entry. But that
would force an Eq a constraint on the event type, which isn't
allowed, because (>>=) must work for all data types, not
just for instances of Eq. This is a problem with Haskell,
not with the monad itself. It's the same problem that prevents one
from making a good set monad in Haskell, even though categorially sets
are a perfectly good monad. (The return function constructs
singletons, and the join function is simply set union.)
Maybe in the next language.Perhaps someone else will find the >>= operator easier to understand than join? I don't know. Anyway, it's simple enough to derive once you understand join; here's the code:
instance (Num p) => Monad (ProbDist p) where return a = ProbDist [(a, 1)] (ProbDist pas) >>= f = ProbDist $ do (a, p) <- pas let (ProbDist pbs) = f a (b, q) <- pbs return (b, p*q)So now we can do some straightforward experiments:
liftM2 (+) (d 6) (d 6) ProbDist [(2,1 % 36),(3,1 % 36),(4,1 % 36),(5,1 % 36),(6,1 % 36),(7,1 % 36),(3,1 % 36),(4,1 % 36),(5,1 % 36),(6,1 % 36),(7,1 % 36),(8,1 % 36),(4,1 % 36),(5,1 % 36),(6,1 % 36),(7,1 % 36),(8,1 % 36),(9,1 % 36),(5,1 % 36),(6,1 % 36),(7,1 % 36),(8,1 % 36),(9,1 % 36),(10,1 % 36),(6,1 % 36),(7,1 % 36),(8,1 % 36),(9,1 % 36),(10,1 % 36),(11,1 % 36),(7,1 % 36),(8,1 % 36),(9,1 % 36),(10,1 % 36),(11,1 % 36),(12,1 % 36)]This is nasty-looking; we really need to merge the multiple listings of the same event. Here is a function to do that:
agglomerate :: (Num p, Eq b) => (a -> b) -> ProbDist p a -> ProbDist p b
agglomerate f pd = ProbDist $ foldr insert [] (unpd (fmap f pd)) where
insert (k, p) [] = [(k, p)]
insert (k, p) ((k', p'):kps) | k == k' = (k, p+p'):kps
| otherwise = (k', p'):(insert (k,p) kps)
agg :: (Num p, Eq a) => ProbDist p a -> ProbDist p a
agg = agglomerate id
Then agg $ liftM2 (+) (d 6) (d 6) produces:
ProbDist [(12,1 % 36),(11,1 % 18),(10,1 % 12),(9,1 % 9),
(8,5 % 36),(7,1 % 6),(6,5 % 36),(5,1 % 9),
(4,1 % 12),(3,1 % 18),(2,1 % 36)]
Hey, that's correct.There must be a shorter way to write insert. It really bothers me, because it looks look it should be possible to do it as a fold. But I couldn't make it look any better.
You are not limited to calculating probabilities. The monad actually will count things. For example, let us throw three dice and count how many ways there are to throw various numbers of sixes:
eq6 n = if n == 6 then 1 else 0
agg $ liftM3 (\a b c -> eq6 a + eq6 b + eq6 c) die die die
ProbDist [(3,1),(2,15),(1,75),(0,125)]
There is one way to throw three sixes, 15 ways to throw two sixes, 75
ways to throw one six, and 125 ways to throw no sixes. So
ProbDist is a misnomer. It's easy to convert counts to probabilities:
probMap :: (p -> q) -> ProbDist p a -> ProbDist q a probMap f (ProbDist pds) = ProbDist $ (map (\(a,p) -> (a, f p))) pds normalize :: (Fractional p) => ProbDist p a -> ProbDist p a normalize pd@(ProbDist pas) = probMap (/ total) pd where total = sum . (map snd) $ pas normalize $ agg $ probMap toRational $ liftM3 (\a b c -> eq6 a + eq6 b + eq6 c) die die die ProbDist [(3,1 % 216),(2,5 % 72),(1,25 % 72),(0,125 % 216)]I think this is the first time I've gotten to write die die die in a computer program.
The do notation is very nice. Here we calculate the distribution where we roll four dice and discard the smallest:
stat = do
a <- d 6
b <- d 6
c <- d 6
d <- d 6
return (a+b+c+d - minimum [a,b,c,d])
probMap fromRational $ agg stat
ProbDist [(18,1.6203703703703703e-2),
(17,4.1666666666666664e-2), (16,7.253086419753087e-2),
(15,0.10108024691358025), (14,0.12345679012345678),
(13,0.13271604938271606), (12,0.12885802469135801),
(11,0.11419753086419752), (10,9.41358024691358e-2),
(9,7.021604938271606e-2), (8,4.7839506172839504e-2),
(7,2.9320987654320986e-2), (6,1.6203703703703703e-2),
(5,7.716049382716049e-3), (4,3.0864197530864196e-3),
(3,7.716049382716049e-4)]
One thing I was hoping to get didn't work out. I had this idea that
I'd be able to calculate the outcome of a game of craps like this:
dice = liftM2 (+) (d 6) (d 6) point n = do roll <- dice case roll of 7 -> return "lose" _ | roll == n = "win" _ | otherwise = point n craps = do roll <- dice case roll of 2 -> return "lose" 3 -> return "lose" 4 -> point 4 5 -> point 5 6 -> point 6 7 -> return "win" 8 -> point 8 9 -> point 9 10 -> point 10 11 -> return "win" 12 -> return "lose"This doesn't work at all; point is an infinite loop because the first value of dice, namely 2, causes a recursive call. I might be able to do something about this, but I'll have to think about it more.
It also occurred to me that the use of * in the definition of >>= / join could be generalized. A couple of years back I mentioned a paper of Green, Karvounarakis, and Tannen that discusses "provenance semirings". The idea is that each item in a database is annotated with some "provenance" information about why it is there, and you want to calculate the provenance for items in tables that are computed from table joins. My earlier explanation is here.
One special case of provenance information is that the provenances are probabilities that the database information is correct, and then the probabilities are calculated correctly for the joins, by multiplication and addition of probabilities. But in the general case the provenances are opaque symbols, and the multiplication and addition construct regular expressions over these symbols. One could generalize ProbDist similarly, and the ProbDist monad (even more of a misnomer this time) would calculate the provenance automatically. It occurs to me now that there's probably a natural way to view a database table join as a sort of Kleisli composition, but this article has gone on too long already.
Happy new year, everyone.
[ Addendum 20100103: unsurprisingly, this is not a new idea. Several readers wrote in with references to previous discussion of this monad, and related monads. It turns out that the idea goes back at least to 1981. ]
[ Addendum 20220522: The article begins “I don't quite remember how I arrived at this”, but I just remembered how I arrived at it! I was thinking about how List can be interpreted as the monad that captures the idea of nondeterministic computation. A function that yields a list [a, b, c] represents a nondeterministic computation that might yield any of a, b, or c. (This idea goes back at least as far as Moggi's 1989 monads paper.) I was thinking about an extension to this idea: what if the outcomes were annotated with probabilities to indicate how often each was the result. ]
My thanks to Graham Hunter for his donation.
[Other articles in category /prog/haskell] permanent link
Tue, 15 Dec 2009
Monads are like burritos
A few months ago Brent
Yorgey complained about a certain class of tutorials which present
monads by explaining how monads are like burritos.
At first I thought the choice of burritos was only a facetious reference to the peculiar and sometimes strained analogies these tutorials make. But then I realized that monads are like burritos.
I will explain.
A monad is a special kind of a functor. A functor F takes each type T and maps it to a new type FT. A burrito is like a functor: it takes a type, like meat or beans, and turns it into a new type, like beef burrito or bean burrito.
A functor must also be equipped with a map function that lifts functions over the original type into functions over the new type. For example, you can add chopped jalapeños or shredded cheese to any type, like meat or beans; the lifted version of this function adds chopped jalapeños or shredded cheese to the corresponding burrito.
A monad must also possess a unit function that takes a regular value, such as a particular batch of meat, and turns it into a burrito. The unit function for burritos is obviously a tortilla.
Finally, a monad must possess a join function that takes a ridiculous burrito of burritos and turns them into a regular burrito. Here the obvious join function is to remove the outer tortilla, then unwrap the inner burritos and transfer their fillings into the outer tortilla, and throw away the inner wrappings.
The map, join, and unit functions must satisfy certain laws. For example, if B is already a burrito, and not merely a filling for a burrito, then join(unit(B)) must be the same as B. This means that if you have a burrito, and you wrap it in a second tortilla, and then unwrap the contents into the outer tortilla, the result is the same as what you started with.
This is true because tortillas are indistinguishable.
I know you are going to point out that some tortillas have the face of Jesus. But those have been toasted, and so are unsuitable for burrito-making, and do not concern us here.
So monads are indeed like burritos.
I asked Brent if this was actually what he had in mind when he first suggested the idea of tutorials explaining monads in terms of burritos, and if everyone else had understood this right away.
But he said no, I was the lone genius.
[ Addendum 20120106: Chris Done has presented this theory in cartoon form. ]
[ Addendum 20201025: Eugenia Cheng tweets this page! But the last word, “stupid”, is inexplicably misspelled. ]
[ Addendum 20260410: Enjoy this profusely illustrated presentation by T.P. Wong and Canna Wen. ]
[Other articles in category /prog] permanent link
Fri, 31 Jul 2009
Dijkstra was not insane
Recently, a reader on the Higher-Order Perl
discussion mailing list made a remark about Edsger Dijkstra and
his well-known opposition to the break construction (in Perl,
last) that escapes prematurely from a loop. People often use
this as an example to show that Dijkstra was excessively doctrinaire,
and out of touch with the reality of programming[1], but usually it's
because they don't know what his argument was.
I wrote a response, explaining where Dijkstra was coming from, and I am very happy with how it came out, so I'm reposting it here.
The list subscriber said, in part:
On a side note, I never read anything by Dijkstra that wasn't noticeably out of touch with the reality of programming, which qualifies them as screeds to me.A lot of people bring up the premature-loop-exit prohibition without understanding why Dijkstra suggested it; it wasn't just that he was a tightassed Dutchman.And I say that as a former Pascal programmer, and as one who has read, and bought into, things like Kernighan's "Why Pascal is Not My Favorite Programming Language" and the valid rants about how some form of breaking out of a loop without having to proceed to the end is very useful, without destroying structure (except by Dijkstra's definition of structure)...
Dijkstra's idea was this: suppose you want to prove, mathematically, that your program does what it is supposed to do. Please, everyone, suspend your judgment of this issue for a few paragraphs, and bear with me. Let's really suppose that we want to do this.
Dijkstra's idea is that the program is essentially a concatenation of blocks, each of which is trying to accomplish something or other, and each of which does not make sense to run unless some part of the program state is set up for it ahead of time. For example, the program might be to print a sorted list of links from a web page. Then the obvious blocks are:
- A
- get the web page and store it in a variable
- B
- extract the links from the text in the variable into an array
- C
- sort the array
- D
- print out the array contents
We say that the "precondition" for C is that the array be populated with URLs, and the "postcondition" is that the array be in sorted order. What you would want to prove about C is that if the precondition holds—that is, if the array is properly populated before C begins—then the postcondition will hold too—that is, the array will be in sorted order when C completes.
It occurs to me that calling this a "proof" is probably biasing everyone's thinking. Let's forget about mathematical proofs and just think about ordinary programmers trying to understand if the program is correct. If the intern in the next cubicle handed you his code for this program, and you were looking it over, you would probably think in very much this way: you would identify block C (maybe it's a subroutine, or maybe not) and then you would try to understand if C, given an array of URLs, would produce a properly sorted array by the time it was done.
C itself might depend on some sub-blocks or subroutines that performed sub-parts of the task; you could try to understand them similarly.
Having proved (or convinced yourself) that C will produce the postcondition "array contains sorted list of URLs", you are in an excellent position to prove (or convince yourself) that block D prints out a sorted array of URLs, which is what you want. Without that belief about C, you are building on sand; you have almost nothing to go on, and you can conclude hardly anything useful about the behavior of D.
Now consider a more complex block, one of the form:
if (q) { E; }
else { F; }
Suppose you believe that code E, given precondition x, is
guaranteed to produce postcondition y. And suppose you believe
the same thing about F. Then you can conclude the same thing about
the entire if-else block: if x was true before it began
executing, then y will be true when it is done.[2] So you can build up proofs (or beliefs)
about small bits of code into proofs (or beliefs) about larger ones.We can understand while loops similarly. Suppose we know that condition p is true prior to the commencement of some loop, and that if p is true before G executes, then p will also be true when G finishes. Then what can we say about this loop?
while (q) { G; }
We can conclude that if p was true before the loop began, then p will
still be true, and q will be false, when the loop ends.BUT BUT BUT BUT if your language has break, then that guarantee goes out the window and you can conclude nothing. Or at the very least your conclusions will become much more difficult. You can no longer treat G atomically; you have to understand its contents in detail.
So this is where Dijkstra is coming from: features like break[3] tend to sabotage the benefits of structured programming, and prevent the programmer from understanding the program as a composition of independent units. The other subscriber made a seemingly disparaging reference to "Dijkstra's idea of structure", but I hope it is clear that it was not an arbitrary idea. Dijkstra's idea of structure is what will allow you to understand a large program as a collection of modules.
Regardless of your opinion about formal verification methods, or correctness proofs, or the practicality of omitting break from your language, it should at least be clear that Dijkstra was not being doctrinaire just for the sake of doctrine.
Some additional notes
Here are some interesting peripheral points that I left out of my main discussion because I wanted to stick to the main point, which was: "Dijkstra was not insane".
- I said in an earlier post that "I often find
Dijkstra's innumerable screeds very tiresome in their unkind,
unforgiving, and unrealistic attitudes toward programmers." But
despite this, I believe he was a brilliant thinker, and almost every
time he opened his mouth it was to make a carefully-considered
argument. You may not like him, and you may not agree with him, but
you'll be better off listening to him.
An archive of Dijkstra's miscellaneous notes and essays (a pre-blogging blog, if you like) is maintained at the University of Texas. I recommend it.
- I said:
Actually, your job is slightly easier. Let's write this:if (q) { E; } else { F; }Suppose you believe that code E, given precondition x, is guaranteed to produce postcondition y. And suppose you believe the same thing about F. Then you can conclude the same thing about the entire if-else block.[x] E [y]
to mean that code E, given precondition x, produces postcondition y. That is, if we know that x is true when E begins execution, then we know that y is true when E finishes. Then my quoted paragraph above says that from these:[x] E [y]
we can conclude this:
[x] F [y][x] if (q) {E} else {F} [y]
But actually we can make a somewhat stronger statement. We can make the same conclusion from weaker assumptions. If we believe these:[x and q] E [y]
then we can conclude this:
[x and not q] F [y][x] if (q) {E} else {F} [y]
In fact this precisely expresses the complete semantics of the if-else construction. Why do we use if-else blocks anyway? This is the reason: we want to be able to write code to guarantee something like this:[x] BLAH [y]
but we only know how to guarantee[x and q] FOO [y]
and[x and not q] BAR [y]
for some q. So we write two blocks of code, each of which accomplishes y under some circumstances, and use if-else to make sure that the right one is selected under the right circumstances. - Similar to break (but worse), in the presence of goto you are on very shaky ground in trying to conclude anything about whether the program is correct. Suppose you know that C is correct if its precondition (an array of URLs) is satisfied. And you know that B will set up that precondition (that is, the array) if its precondition is satisfied, so it seems like you are all right. But no, because block W somewhere else might have goto C; and transfer control to C without setting up the precondition, and then C could cause winged demons to fly out of your nose.
Further reading
-
For a quick overview, see the Wikipedia article
on Hoare logic. Hoare logic is the
[x] E [y] notation I used above, and a set of
rules saying how to reason with claims of that form. For example,
one rule of Hoare logic defines the meaning of the null statement: if ; is the null
statement, then [p] ; [p] for all conditions
p.
Hoare logic was invented by Tony Hoare, who also invented the Quicksort algorithm.
-
For further details, see Dijkstra's book "A Discipline of
Programming". Dijkstra introduces a function called wp for
"weakest precondition".
Given a piece of code C and a desired postcondition
q, wp(C, q) is the weakest precondition
that is sufficient for code C to accomplish q. That
is, it's the minimum prerequisite for C to accomplish
q. Most of the book is about how to figure out what these
weakest preconditions are, and, once you know them, how they can
guide you to through the implementation of your program.
I have an idea that the Dijkstra book might be easier to follow after having read this introduction than without it.
- No discussion of structured programming and goto is
complete without a mention of Donald Knuth's wonderful paper
Stuctured Programming with go to Statements.
This is my single all-time favorite computer science paper. Download it here.
- Software Tools in Pascal is a book by Kernighan and
Plauger that tries to translate the tool suite of their earlier
Software Tools book into Pascal. They were repeatedly
screwed by deficiencies in the Pascal language, and this was the
inspiration for Kernighan's famous "Why Pascal is not my Favorite
Programming Language" paper. In effect, Software Tools in
Pascal is a book-length case study of the deficiencies of
Pascal for practical programming tasks.


[Other articles in category /prog] permanent link
Tue, 16 Jun 2009
Haskell logo fail
The Haskell folks have chosen a new logo.
![]()
![]()
[Other articles in category /prog/haskell] permanent link
Thu, 14 May 2009
Product types in Java
Recently I wanted a Java function that would return two Person
objects. Java functions return only a single value. I could, of
course, make a class that encapsulates two Persons:
class Persons2 {
Person personA, personB;
Persons2(Person a, Person b) {
personA = a; personB = b;
}
Person getPersonA() { return personA; }
...
}
Java is loathsome in its verbosity, and this sort of monkey code is
Java's verbosity at its most loathsome. So I did not do this.Haskell functions return only one value also, but this is no limitation, because Haskell has product types. And starting in Java 5, the Java type system is a sort of dented, bolted-on version of the type systems that eventually evolved into the Haskell type system. But product types are pretty simple. I can make a generic product type in Java:
class Pair<A,B> {
A a; B b;
Pair(A a, B b) { this.a = a; this.b = b; }
A fst() { return a; }
B snd() { return b; }
}
Then I can declare my function to return a
Pair<Person,Person>:
Pair<Person,Person> findMatch() {
...
return new Pair(husband, wife);
}
Okay, that worked just fine. The
boilerplate is still there, but you only have to do it once. This
trick seems sufficiently useful that I can imagine that I will use it
again, and that someone else reading this will want to use it too.I've been saying for a while that up through version 1.4, Java was a throwback to the languages of the 1970s, but that with the introduction of generics in Java 5, it took a giant step forward into the 1980s. I think this is a point of evidence in favor of that claim.
I wonder why this class isn't in the standard library. I was not the first person to think of doing this; web search turns up several others, who also wonder why this class isn't in the standard library.
I wrote a long, irrelevant coda regarding my use of the identifiers husband and wife in the example, but, contrary to my usual practice, I will publish it another day.
[ Addendum 20090517: Here's the long, irrelevant coda. ]
I gratefully acknowledge the gift of Petr Kiryakov. Thank you!
[Other articles in category /prog/java] permanent link
Sun, 22 Mar 2009
Worst error messages this month
This month's winner is:
Line 319 in XML document from class path resource [applicationContext-standalone.xml] is invalid; nested exception is org.xml.sax.SAXParseException: cvc-complex-type.2.3: Element 'beans' cannot have character [children], because the type's content type is element-only.Experienced technicians will of course want to look at line 319. Silly! If looking at line 319 were any help, this would not be this month's lucky winner. Line 319 is the last line of the document, and says, in whole, "</beans>".
What this actually means is that there is a stray plus sign at the end of line 54.
Well, that is the ultimate cause. The Fregean Bedeutung, as it were.
What it really means (the Sinn) is that the <beans>...</beans> element is allowed to contain sub-elements, but not naked text ("content type is element-only") and the stray plus sign is naked text.
The mixture of weird jargon ("cvc-complex-type.2.3") and obscure anaphora ("character [children]" for "plus sign") got this message nominated for the competition. The totally wrong line number is a bonus. But what won this message the prize is that even if you somehow understand what it means, it doesn't help you find the actual problem! You get to grovel over the 319-line XML file line-by-line, looking for the extra character.
Come on, folks, it's a SAX parser, so how hard is it to complain about the plus sign as soon as it shows up?

You'll be flown to lovely Centralia, Pennsylvania, where you'll enjoy four days and three nights of solitude in an abandoned coal mine being flogged with holly branches and CAT-5 ethernet cable by the cast of "The Hills"!Thank you, Johnny. And there is a runner-up! The badblocks utility that is distributed as part of the Linux e2fsprogs package, produces the following extremely useful error message:
% badblocks /home badblocks: invalid starting block (0): must be less than 0Apparently this is Linux-speak for "This program needs the name of a device file, and the programmer was too lazy to have it detect that you supplied the name of the mount point instead".
Happy spring, everyone!
[Other articles in category /prog] permanent link
Thu, 12 Feb 2009
More Uzi-clubbing: a counterexample
Last year I wrote an
article about iterating over a hash, searching for a certain key.
Larry Wall called said this was like "clubbing someone to death with a
loaded Uzi", because the whole point of a hash is that you don't have
to scan all the keys to find the one you want.
I ended the article by saying:
I had already realized that you could, in principle, commit this error with a regular array instead of with a hash, but I had never seen an example until...Just recently I saw another example, which I think is interesting because it seems to be a counterexample. It's part of a somewhat longer Java program. The crucial section is:
...
LINE: while ( ( line = in.readLine()) != null ) {
String[] fields = line.split("\t");
...
for ( int i = 0; i < fields.length; i++ ) {
if ( ! isEmpty(fields[i]) ) {
switch(i) {
case 0: citation.setCitationType(fields[i]); break;
case 1: setAuthors(citation,fields[i],personHome,false); break;
case 2: citation.setPublishYear(Integer.parseInt(fields[i])); break;
case 3: citation.setTitle(fields[i]); break;
...
case 19: citation.setURL(fields[i]); break;
case 20: citation.setDoi(fields[i]); break;
default: warn("Empty field expected, found: " + fields[i] + " for line: " + line); break;
}
}
}
}
...
The Perlishness of this Java code might lead you to think that I wrote
it, but I did not.My temptation here was to replace the loop and the switch with code like this:
citation.setCitationType(fields[0]);
setAuthors(citation,fields[1],personHome,false);
citation.setPublishYear(Integer.parseInt(fields[2]));
citation.setTitle(fields[3]);
...
citation.setURL(fields[19]);
citation.setDoi(fields[20]);
We lost the warnings, but there were only 4 of those, so we can add
them back explicitly:
if (! isEmpty(fields[13])) warn("Empty field expected...");
This might have been an improvement, except that we also lost the
isEmpty tests on the nonempty fields. To get them back we
must spend at least all our gains, possibly more:
if (! isEmpty(fields[0])) citation.setCitationType(fields[0]);
if (! isEmpty(fields[1])) setAuthors(citation,fields[1],personHome,false);
if (! isEmpty(fields[2])) citation.setPublishYear(Integer.parseInt(fields[2]));
if (! isEmpty(fields[3])) citation.setTitle(fields[3]);
...
if (! isEmpty(fields[13])) warn("Empty field expected...");
...
if (! isEmpty(fields[19])) citation.setURL(fields[19]);
if (! isEmpty(fields[20])) citation.setDoi(fields[20]);
So at least in this case, my instinct to eliminate the loop-switch was
not helpful. There are plenty of Java-esque techniques for cutting up
the complexity and sweeping each little piece underneath its own
little carpet ("Replace fields with an object! Or with a
series of 20 objects!") but nothing that actually reduces the entia
multiplicantis. There may be ways to easily improve this code, but
I have not been able to think of any.
[Other articles in category /prog] permanent link
Sat, 24 Jan 2009
Higher-Order Perl: nonmemoizing streams
The first version of tail() in the streams chapter looks like this:
sub tail {
my $s = shift;
if (is_promise($s->[1])) {
return $s->[1]->(); # Force promise
} else {
return $s->[1];
}
}
But this is soon replaced with a version that caches the value
returned by the promise:
sub tail {
my $s = shift;
if (is_promise($s->[1])) {
$s->[1] = $s->[1]->(); # Force and save promise
}
return $s->[1];
}
The reason that I give for this in the book is a performance reason.
It's accompanied by an extremely bad explanation. But I couldn't do
any better at the time.There are much stronger reasons for the memoizing version, also much easier to explain.
Why use streams at all instead of the iterators of chapter 4? The most important reason, which I omitted from the book, is that the streams are rewindable. With the chapter 4 iterators, once the data comes out, there is no easy way to get it back in. For example, suppose we want to process the next bit of data from the stream if there is a carrot coming up soon, and a different way if not. Consider:
# Chapter 4 iterators
my $data = $iterator->();
if (carrot_coming_soon($iterator)) {
# X
} else {
# Y
}
sub carrot_coming_soon {
my $it = shift;
my $soon = shift || 3;
while ($soon-- > 0) {
my $next = $it->();
return 1 if is_carrot($next);
}
return; # No carrot
}
Well, this probably doesn't work, because the carrot_coming_soon()
function extracts and discards the upcoming data from the iterator,
including the carrot itself, and now that data is lost.One can build a rewindable iterator:
sub make_rewindable {
my $it = shift;
my @saved; # upcoming values in LIFO order
return sub {
my $action = shift || "next";
if ($action eq "put back") {
push @saved, @_;
} elsif ($action eq "next") {
if (@saved) { return pop @saved; }
else { return $it->(); }
}
};
}
But it's kind of a pain in the butt to use:
sub carrot_coming_soon {
my $it = shift;
my $soon = shift || 3;
my @saved;
my $saw_carrot;
while ($soon-- > 0) {
push @saved, $it->();
$saw_carrot = 1, last if is_carrot($saved[-1]);
}
$it->("put back", @saved);
return $saw_carrot;
}
Because you have to explicitly restore the data you extracted.With the streams, it's all much easier:
sub carrot_coming_soon {
my $s = shift;
my $soon = shift || 3;
while ($seen-- > 0) {
return 1 if is_carrot($s->head);
drop($s);
}
return;
}
The working version of carrot_coming_soon() for streams looks just like
the non-working version for iterators.But this version of carrot_coming_soon() only works for memoizing streams, or for streams whose promise functions are pure. Let's consider a counterexample:
my $bad = filehandle_stream(\*DATA);
sub filehandle_stream {
my $fh = shift;
return node(scalar <$fh>,
promise { filehandle_stream($fh) });
}
__DATA__
fish
dog
carrot
goat rectum
Now consider what happens if I do this:
$carrot_soon = carrot_coming_soon($bad);
print "A carrot appears soon after item ", head($bad), "\n"
if $carrot_soon;
It says "A carrot appears soon after item fish". Fine.
That's because $bad is a node whose head contains
"fish". Now let's see what's after the fish:
print "After ", head($bad), " is ", head(tail($bad)), "\n";
This should print After fish is dog, and for the memoizing
streams I used in the book, it does. But a non-memoizing stream will
print "After fish is goat rectum". Because
tail($bad) invokes the promise function, which, since the
next() was not saved after carrot_coming_soon()
examined it, builds a new node, which reads the next item from the
filehandle, which is "goat rectum".I wish I had explained the rewinding property of the streams in the book. It's one of the most significant omissions I know about. And I wish I'd appreciated sooner that the rewinding property only works if the tail() function autosaves the tail node returned from the promise.
[Other articles in category /prog/perl] permanent link
Wed, 12 Nov 2008
Flag variables in Bourne shell programs
Who the heck still programs in Bourne shell? Old farts like me,
occasionally. Of course, almost every time I do I ask myself why I
didn't write it in Perl. Well, maybe this will be of some value
to some fart even older than me..
Suppose you want to set a flag variable, and then later you want to test it. You probably do something like this:
if some condition; then
IS_NAKED=1
fi
...
if [ "$IS_NAKED" == "1" ]; then
flag is set
else
flag is not set
fi
Or maybe you use ${IS_NAKED:-0} or some such
instead of "$IN_NAKED". Whatever.Today I invented a different technique. Try this on instead:
IS_NAKED=false
if some condition; then
IS_NAKED=true
fi
...
if $IS_NAKED; then
flag is set
else
flag is not set
fi
The arguments both for and against it seem to be obvious, so I won't
make them.I have never seen this done before, but, as I concluded and R.J.B. Signes independently agreed, it is obvious once you see it.
[ Addendum 20090107: some followup notes ]
[Other articles in category /prog] permanent link
Thu, 18 Sep 2008
data Mu f = In (f (Mu f))
Last week I wrote about one
of two mindboggling pieces of code that appears in the paper Functional
Programming with Overloading and Higher-Order Polymorphism, by
Mark P. Jones. Today I'll write about the other one. It looks like
this:
data Mu f = In (f (Mu f)) -- (???)
I bet a bunch of people reading this on Planet Haskell are nodding and
saying "Oh, that!"When I first saw this I couldn't figure out what it was saying at all. It was totally opaque. I still have trouble recognizing in Haskell what tokens are types, what tokens are type constructors, and what tokens are value constructors. Code like (???) is unusually confusing in this regard.
Normally, one sees something like this instead:
data Maybe f = Nothing | Just f
Here f is a type variable; that is, a variable that ranges over
types. Maybe is a type constructor, which is like a function
that you can apply to a type to get another type. The most familiar
example of a type constructor is List:
data List e = Nil | Cons e (List e)
Given any type f, you can apply the type constructor
List to f to get a new type List f.
For example, you can apply List to Int to get the
type List Int. (The Haskell built-in list type constructor
goes by the funny name of [], but works the same way. The
type [Int] is a synonym for ([] Int).)Actually, type names are type constructors also; they're argumentless type constructors. So we have type constructors like Int, which take no arguments, and type constructors like List, which take one argument. Haskell also has type constructors that take more than one argument. For example, Haskell has a standard type constructor called Either for making union types:
data Either a b = Left a | Right b;
Then the type Either Int String contains values like Left
37 and Right "Cotton Mather".To keep track of how many arguments a type constructor has, one can consider the, ahem, type, of the type constructor. But to avoid the obvious looming terminological confusion, the experts use the word "kind" to refer to the type of a type constructor. The kind of List is * → *, which means that it takes a type and gives you back a type. The kind of Either is * → * → *, which means that it takes two types and gives you back a type. Well, actually, it is curried, just like regular functions are, so that Either Int is itself a type constructor of kind * → * which takes a type a and returns a type which could be either an Int or an a. The nullary type constructor Int has kind *.
Continuing the "Maybe" example above, f is a type, or a constructor of kind *, if you prefer. Just is a value constructor, of type f → Maybe f. It takes a value of type f and produces a value of type Maybe f.
Now here is a crucial point. In declarations of type constructors, such as these:
data Either a b = ...
data List e = ...
data Maybe f = ...
the type variables a, b, e, and f actually
range over type constructors, not over types. Haskell can infer the
kinds of the type constructors Either, List, and
Maybe, and also the kinds of the type variables, from the
definitions on the right of the = signs. In this case, it
concludes that all four variables must have kind *, and so really do
represent types, and not higher-order type constructors. So you can't
ask for Either Int List because List is known to
have kind * → *, and Haskell needs a type constructor of kind * to
serve as an argument to Either. But with a different definition, Haskell might infer that a type variable has a higher-order kind. Here is a contrived example, which might be good for something, perhaps. I'm not sure:
data TyCon f = ValCon (f Int)
This defines a type constructor TyCon with kind (* → *) → *,
which can be applied to any type constuctor f that has kind *
→ *, to yield a type. What new type? The new type TyCon
f is isomorphic to the type f of Int. For
example, TyCon List is basically the same as List
Int. The value Just 37 has type Maybe Int,
and the value ValCon (Just 37) has type TyCon
Maybe.Similarly, the value [1, 2, 3] has type [Int], which, you remember, is a synonym for [] Int. And the value ValCon [1, 2, 3] has type TyCon [].
Now that the jargon is laid out, let's look at (???) again:
data Mu f = In (f (Mu f)) -- (???)
When I was first trying to get my head around this, I had trouble
seeing what the values were going to be. It looks at first like it
has no bottom. The token f here, like in the TyCon
example, is a variable that ranges over type constructors with kind *
→ *, so could be List or Maybe or [],
something that takes a type and yields a new type. Mu itself
has kind (* → *) → *, taking something like f and yielding a
type. But what's an actual value? You need to apply the value
constructor In to a value of type f (Mu
f), and it's not immediately clear where to get such a
thing.I asked on #haskell, and Cale Gibbard explained it very clearly. To do anything useful you first have to fix f. Let's take f = Maybe. In that particular case, (???) becomes:
data Mu Maybe = In (Maybe (Mu Maybe))
So the In value constructor will take a value of type
Maybe (Mu Maybe) and return a value of type
Mu Maybe. Where do we get a value of type
Maybe (Mu Maybe)? Oh, no problem: the value Nothing
is polymorphic, and has type Maybe a for all a,
so in particular it has type Maybe (Mu Maybe). Whatever
Maybe (Mu Maybe) is, it is a Maybe-type, so it has a
Nothing value. So we do have something to get started
with.Since Nothing is a Maybe (Mu Maybe) value, we can apply the In constructor to it, yielding the value In Nothing, which has type Mu Maybe. Then applying Just, of type a → Maybe a, to In Nothing, of type Mu Maybe, produces Just (In Nothing), of type Maybe (Mu Maybe) again. We can repeat the process as much as we want and produce as many values of type Mu Maybe as we want; they look like these:
In Nothing
In (Just (In Nothing))
In (Just (In (Just (In Nothing))))
In (Just (In (Just (In (Just (In Nothing))))))
...
And that's it, that's the type Mu Maybe, the set of those
values. It will look a little simpler if we omit the In
markers, which don't really add much value. We can just agree to omit
them, or we can get rid of them in the code by defining some semantic
sugar:
nothing = In Nothing
just = In . Just
Then the values of Mu Maybe look like this:
nothing
just nothing
just (just nothing)
just (just (just nothing))
...
It becomes evident that what the Mu operator does is to close
the type under repeated application. This is analogous to the way the
fixpoint combinator works on values. Consider the usual definition of
the fixpoint combinator:
Y f = f (Y f)
Here f is a function of type a → a. Y f
is a fixed point of f. That is, it is a value x of type
a such that f x = x. (Put x = Y
f in the definition to see this.)The fixed point of a function f can be computed by considering the limit of the following sequence of values:
⊥
f(⊥)
f(f(⊥))
f(f(f(⊥)))
...
This actually finds the least fixed point of f, for a certain definition of "least". For many functions f, like x → x + 1, this finds the uninteresting fixed point ⊥, but for many f, like x → λ n. if n = 0 then 1 else n * x(n - 1), it's something better.
Mu is analogous to Y. Instead of operating on a function f from values to values, and producing a single fixed-point value, it operates on a type constructor f from types to types, and produces a fixed-point type. The resulting type T is the least fixed point of the type constructor f, the smallest set of values such that f T = T.
Consider the example of f = Maybe again. We want to find a type T such that T = Maybe T. Consider the following sequence:
{ ⊥ }
Maybe { ⊥ }
Maybe(Maybe { ⊥ })
Maybe(Maybe(Maybe { ⊥ }))
...
The first item is the set that contains nothing but the bottom value, which we might call t0. But t0 is not a fixed point of Maybe, because Maybe { ⊥ } also contains Nothing. So Maybe { ⊥ } is a different type from t0, which we can call t1 = { Nothing, ⊥ }.
The type t1 is not a fixed point of Maybe either, because Maybe t1 evidently contains both Nothing and Just Nothing. Repeating this process, we find that the limit of the sequence is the type Mu Maybe = { ⊥, Nothing, Just Nothing, Just (Just Nothing), Just (Just (Just Nothing)), ... }. This type is fixed under Maybe.
It might be worth pointing out that this is not the only such fixed point, but is is the least fixed point. One can easily find larger types that are fixed under Maybe. For example, postulate a special value Q which has the property that Q = Just Q. Then Mu Maybe ∪ { Q } is also a fixed point of Maybe. But it's easy to see (and to show, by induction) that any such fixed point must be a superset of Mu Maybe. Further consideration of this point might take me off to co-induction, paraconsistent logic, Peter Aczel's nonstandard set theory, and I'd never get back again. So let's leave this for now.
So that's what Mu really is: a fixed-point operator for type constructors. And having realized this, one can go back and look at the definition and see that oh, that's precisely what the definition says, how obvious:
Y f = f (Y f) -- ordinary fixed-point operator
data Mu f = In (f (Mu f)) -- (???)
Given f, a function from values to values, Y(f)
calculates a value x such that x = f(x).
Given f, a function from types to types, Mu(f) calculates
a type T such that f(T) = T. That's why the
definitions are identical. (Except for that annoying In
constructor, which really oughtn't to be there.)You can use this technique to construct various recursive datatypes. For example, Mu Maybe turns out to be equivalent to the following definition of the natural numbers:
data Number = Zero | Succ Number;
Notice the structural similarity with the definition of Maybe:
data Maybe a = Nothing | Just a;
One can similarly define lists:
data Mu f = In (f (Mu f))
data ListX a b = Nil | Cons a b deriving Show
type List a = Mu (ListX a)
-- syntactic sugar
nil :: List a
nil = In Nil
cons :: a → List a → List a
cons x y = In (Cons x y)
-- for example
ls = cons 3 (cons 4 (cons 5 nil)) -- :: List Integer
lt = (cons 'p' (cons 'y' (cons 'x' nil))) -- :: List Char
Or you could similarly do trees, or whatever. Why one might want to
do this is a totally separate article, which I am not going to write
today.Here's the point of today's article: I find it amazing that Haskell's type system is powerful enough to allow one to defined a fixed-point operator for functions over types.
We've come a long way since FORTRAN, that's for sure.
A couple of final, tangential notes: Google search for "Mu f = In (f (Mu f))" turns up relatively few hits, but each hit is extremely interesting. If you're trying to preload your laptop with good stuff to read on a plane ride, downloading these papers might be a good move.
The Peter Aczel thing seems to be less well-known that it should be. It is a version of set theory that allows coinductive definitions of sets instead of inductive definitions. In particular, it allows one to have a set S = { S }, which standard set theory forbids. If you are interested in co-induction you should take a look at this. You can find a clear explanation of it in Barwise and Etchemendy's book The Liar (which I have read) and possibly also in Aczel's book Non Well-Founded Sets (which I haven't read).
[Other articles in category /prog] permanent link
Thu, 11 Sep 2008
Return return
Among the things I read during the past two months was the paper Functional
Programming with Overloading and Higher-Order Polymorphism, by
Mark P. Jones. I don't remember why I read this, but it sure was
interesting. It is an introduction to the new, cool features of
Haskell's type system, with many examples. It was written in 1995
when the features were new. They're no longer new, but they are still
cool.
There were two different pieces of code in this paper that wowed me. When I started this article, I was planning to write about #2. I decided that I would throw in a couple of paragraphs about #1 first, just to get it out of the way. This article is that couple of paragraphs.
[ Addendum 20080917: Here's the article about #2. ]
Suppose you have a type that represents terms over some type v of variable names. The v type is probably strings but could possibly be something else:
data Term v = TVar v -- Type variable | TInt -- Integer type | TString -- String type | Fun (Term v) (Term v) -- Function typeThere's a natural way to make the Term type constructor into an instance of Monad:
instance Monad Term where
return v = TVar v
TVar v >>= f = f v
TInt >>= f = TInt
TString >>= f = TString
Fun d r >>= f = Fun (d >>= f) (r >>= f)
That is, the return operation just lifts a variable name to
the term that consists of just that variable, and the bind
operation just maps its argument function over the variable names in
the term, leaving everything else alone.Jones wants to write a function, unify, which performs a unification algorithm over these terms. Unification answers the question of whether, given two terms, there is a third term that is an instance of both. For example, consider the two terms a → Int and String → b, which are represented by Fun (TVar "a") TInt and Fun TString (TVar "b"), respectively. These terms can be unified, since the term String → Int is an instance of both; one can assign a = TString and b = TInt to turn both terms into Fun TString TInt.
The result of the unification algorithm should be a set of these bindings, in this example saying that the input terms can be unified by replacing the variable "a" with the term TString, and the variable "b" with the term TInt. This set of bindings can be represented by a function that takes a variable name and returns the term to which it should be bound. The function will have type v → Term v. For the example above, the result is a function which takes "a" and returns TString, and which takes "b" and returns TInt. What should this function do with variable names other than "a" and "b"? It should say that the variable named "c" is "replaced" by the term TVar "c", and similarly other variables. Given any other variable name x, it should say that the variable x is "replaced" by the term TVar x.
The unify function will take two terms and return one of these substitutions, where the substition is a function of type v → Term v. So the unify function has type:
unify :: Term v → Term v → (v → Term v)
Oh, but not quite. Because unification can also fail. For example,
if you try to unify the terms a → b and Int,
represented by Fun (TVar "a") (TVar "b") and TInt
respectively, the unfication should fail, because there is no term
that is an instance of both of those; one represents a function and
the other represents an integer. So unify does not actually
return a substitution of type v → Term v. Rather, it
returns a monad value, which might contain a substitution, if the
unification is successful, and otherwise contains an error value. To handle
the example above, the unify function will contain a case
like this:
unify TInt (Fun _ _) = fail ("Cannot unify" ....)
It will fail because it is not possible to unify functions and
integers.If unification is successful, then instead of using fail, the unify function will construct a substitution and then return it with return. Let's consider the result of unifying TInt with TInt. This unification succeeds, and produces a trivial substitition with no bindings. Or more precisely, every variable x should be "replaced" by the term TVar x. So in this case the substitution returned by unify should be the trivial one, a function which takes x and returns TVar x for all variable names x.
But we already have such a function. This is just what we decided that Term's return function should do, when we were making Term into a monad. So in this case the code for unify is:
unify TInt TInt = return returnYep, in this case the unify function returns the return function.
Wheee!
At this point in the paper I was skimming, but when I saw return return, I boggled. I went back and read it more carefully after that, you betcha.
That's my couple of paragraphs. I was planning to get to this point and then say "But that's not what I was planning to discuss. What I really wanted to talk about was...". But I think I'll break with my usual practice and leave the other thing for tomorrow.
Happy Diada Nacional de Catalunya, everyone!
[ Addendum 20080917: Here's the article about the other thing. ]
[Other articles in category /prog] permanent link
Sat, 12 Jul 2008
runN revisited
Exactly one year ago I discussed
runN, a utility that I invented for running the same
command many times, perhaps in parallel. The program continues to be
useful to me, and now Aaron Crane has reworked it and significantly
improved the interface. I found his discussion enlightening. He put
his finger on a lot of problems that had been bothering me that I had
not quite been able to pin down.
Check it out. Thank you, M. Crane.
[Other articles in category /prog] permanent link
Tue, 17 Jun 2008
Defunctionalization and Java
A couple of weeks ago I was introduced to the notion of defunctionalization by this
article on Ken
Knowles' blog. Defunctionalization is a program transformation that removes the
higher-order functions from a program. The idea is that you replace
something like λx.x+y with a data structure that
encapsulates a value of y somewhere, say (HOLD y). And
instead of using the language's built-in function application to
apply this object directly to an argument x, you write a
synthetic applicator that takes (HOLD y) and x and
returns x + y. And anyone who wanted to apply
λx.x+y to some argument x in some context
in which y was bound should first construct (HOLD y),
then use the synthetic applicator on (HOLD y) and x.
Consider, for example, the following Haskell program:
-- Haskell
aux f = f 1 + f 10
res x = aux (λz -> z + x)
The defunctionalization of this example is:
-- Haskell
data Hold = HOLD Int
fake_apply (HOLD a) b = a + b
aux held = fake_apply held 1 + fake_apply held 10
res x = aux (HOLD x)
I hope this will make the idea clear.M. Knowles cites the paper Defunctionalization at work by Olivier Danvy and Lasse R. Nielsen, which was lots of fun. (My Haskell example above is a simplification of the example from page 5 of Danvy and Nielsen.) Among other things, Danvy and Nielsen point out that this defunctionalization transformation is in a certain sense dual to the transformation that turns ordinary data structures into λ-terms in Church encoding. Church encloding turns data items like pairs or booleans into higher-order functions; defunctionalization turns them back again.
Section 1.4 of the Danvy and Nielsen paper lists a whole bunch of contexts in which this technique has been studied and used, but one thing I didn't think I saw there is that this is essentially the transformation that Java programmers use when they want to use closures.
For example, suppose a Java programmer wants to write something like aux in:
-- Haskell
aux f = f 1 + f 10
res x = aux (λz -> z + x)
But they can't, because Java doesn't have closures.So instead, they do this:
/* Java */
class Hold {
private int a;
public Hold(int a) {
this.a = a;
}
public int fake_apply(int b) {
return this.a + b;
}
}
private static int aux(Hold h) {
return h.fake_apply(1) + h.fake_apply(10);
}
static int res(int x) {
Hold h = new Hold(x);
return aux(h);
}
Where the class Hold corresponds directly to the
data type Hold in the defunctionalized Haskell code.Here is a real example. Consider GNU Emacs. When I enter text-mode in Emacs, I want a bunch of subsystems to be notified. Emacs has a text-mode-hook variable, which is basically a list of functions, and when an Emacs buffer is put into text-mode, Emacs invokes the hooks. Any subsystem that wants to be notified puts its own hook function into that variable. If I wanted to accomplish something similar in Haskell or SML, I would similarly use a list of functions.
In Java, the corresponding facility is called java.util.Observable. Were one implementing Emacs in Java (perish the thought!) the mode object would inherit from Observable, and so would provide an addObserver method for adding a hook to a list somewhere. When the mode was switched to text-mode, the mode object would call notifyObservers, which would loop over the hook list, calling the hooks. So far this is just like Emacs Lisp.
But in Java the hooks are not functions, as they are in Emacs, because in Java functions are not first-class entities. Instead, the hooks are objects which conform to the Observer interface specification, and instead of invoking functions directly, the notifyObservers method calls the update method on each hook object.
Here's another example. I wrote a recursive descent parser in Java a while back. An ActionParser is just like a Parser, except that if its parse succeeds, it invokes a callback. If I were programming in SML or Haskell or Perl, an ActionParser would be nothing but a Parser with an associated closure, something like this:
# Perl
package ActionParser;
sub new {
my ($class, $parser, $action) = @_;
bless { Parser => $parser,
Action => $action } => $class;
}
# Just like the embedded parser, but invoke the action on success
sub parse {
my $self = shift;
my $input = shift;
my $result = $self->{Parser}->parse($input);
if ($result->success)
$self->{Action}->($result); # Invoke action
}
return $result;
}
Here the Action member is expected to be a closure, which is
automatically invoked if the parse succeeds. To use this, I would
write something like this:
# Perl
my $missiles;
...
my $parser = ActionParser->new($otherParser,
sub { $missiles->launch() }
);
$parser->parse($input);
And then if the input parses correctly, the parser launches the
missiles from the anonymous closure, which has captured the local
$missiles object.But in Java, you have no closures. Instead, you defunctionalize, and represent closures with objects:
/* Java */
abstract class Action {
void invoke(ParseResults results) {}
}
class ActionParser extends Parser {
Action action;
Parser parser;
ActionParser(Parser p, Action a) {
action = a;
parser = p;
}
ParseResults Parse(Input input) {
ParseResults res = this.parser.Parse(input);
if (res.isSuccess) {
this.action.invoke(res);
}
return res;
}
}
To use this, one writes something like this:
/* Java */
class LaunchMissilesAction extends Action {
Missiles m;
LaunchMissilesAction(Missiles m) { this.m = m; }
void invoke(ParseResults results) {
m.launch();
}
}
...
Action a = new LaunchMissilesAction(missiles);
Parser p = new ActionParser(otherParser, a);
p.parse(input);
The constructor argument missiles takes the place of a free
variable in a closure. The closure itself has been replaced with
an object from an ad hoc class, just as in Danvy and Nielsen's
formulation, the closure is replaced with a synthetic data object that
holds the values of the free variables. The invoke method
plays the role of fake_apply.Now, it's not a particularly interesting observation that this can be done. The interesting part, I think, is that this is what Java programmers actually do. And also, perhaps, that Danvy and Nielsen didn't mention it in their paper, because I think the technique is pretty widespread.
[Other articles in category /prog] permanent link
Fri, 30 May 2008
Glade
Last week I needed to mock up a dialog box I was talking
about in this article:
Glade lets you design a window interface, by positioning buttons and sliders and things, and then does something or other. At the time I didn't know what it would do, but I knew I could mock up the window I wanted, and I thought maybe I could screenshot the mockup for the blog article.
The Glade thing was so easy to use that the easiest way to get a mockup of the dialog was to have Glade generate a complete, working windowing application, compile and run the application, and then screenshot the application. I got this done in about fifteen minutes.
The application I made doesn't actually do anything, but it does compile, run, and pop up the dialog box I designed. I'm confident that I could get it to do something pretty easily, if I wanted. The auto-generated code, and some of the Glade controls, are very suggestive.
I give Glade a big gold star. I went from having never heard of it to a working (although trivial) window application in one two-minute session and one fifteen-minute session. Maybe two big gold stars and a "Good work!" sticker.
[ Addendum 20080530: I went ahead with making an application that actually does something. It worked. ]
[Other articles in category /prog] permanent link
More Glade
After writing about Glade Interface
Designer today, I decided to go ahead and see if it would be as
easy to make a working application as I hoped it would be.
The outcome: big success.
The application has a window with two input fields, a "+" button, and an output field that shows the sum of the input fields when you press the "+" button. It took about half an hour from start to finish, and the only thing I had to look up in the manual was the names of the functions that read and write the values of the text fields. Everything else I got through bricolage and tinkering with the autogenerated monkey code.
The biggest problem that I encountered was that the application didn't exit when I clicked the close box, although the window disappeared. I figured out that the close box was sending a "delete" event and not a "destroy" event and fixed it up right quick.
Gtk+ and Glade Interface Designer get at least two gold stars. Maybe three. Maybe fifty-three.
[Other articles in category /prog] permanent link
Fri, 28 Mar 2008
Suffering from "make install"
I am writing application X, which uses the nonstandard perl
modules DBI, DBD::SQLite, and Template.
These might not be available on the target system, so I got the idea
to include them in the distribution for X and have the build
process for X build and install the modules. X
already carries its own custom Perl modules in X/lib anyway,
so I can just install DBI and the others into X/lib
and everything will Just Work. Or so I thought.
After building DBI, for example, how do you get it to install itself into X/lib instead of the default system-wide location, which only the super-user has permission to modify?
There are at least five solutions to this common problem.
Uh-oh. If solution #1 had worked, people would not have needed to invent solution #2. If solution #2 had worked, people would not have needed to invent solution #3. Since there are five solutions, there is a good chance that none of them work.
You can, I am informed:
- Set PREFIX=X when building the Makefile
- Set INSTALLDIRS=vendor and VENDORPREFIX=X when
building the Makefile
- Or maybe instead of VENDORPREFIX you need to set INSTALLVENDORLIB or something
- Or maybe instead of setting them while building the Makefile you need to set them while running the make install target
- Set LIB=X/lib when building the Makefile
- Use PAR
- Use local::lib
Some of these items fail because they just plain fail. For example, the first thing everyone says is that you can just set PREFIX to X. No, because then the module Foo does not go into X/lib/Foo.pm. It goes into X/Foo/lib/perl5/site_perl/5.12.23/Foo.pm. Which means that if X does use lib 'X/lib'; it will not be able to find Foo.
 The manual (which goes by the marvelously
obvious and easily-typed name of ExtUtils::MakeMaker, by the
way) is of limited help. It recommends solving the problem by
travelling to Paterson, NJ, gouging your eyes out with your mom's
jewelry, and then driving over the Passaic River falls. Ha ha, just
kidding. That would be a big improvement on what it actually
suggests, for three reasons. First, it is clear and straightforward.
Second, it would feel better than the stuff it does suggest. And
third, it would actually solve your problem, although obliquely.
The manual (which goes by the marvelously
obvious and easily-typed name of ExtUtils::MakeMaker, by the
way) is of limited help. It recommends solving the problem by
travelling to Paterson, NJ, gouging your eyes out with your mom's
jewelry, and then driving over the Passaic River falls. Ha ha, just
kidding. That would be a big improvement on what it actually
suggests, for three reasons. First, it is clear and straightforward.
Second, it would feel better than the stuff it does suggest. And
third, it would actually solve your problem, although obliquely.
It turns out there is a simple solution that doesn't involve travelling to New Jersey. The first thing you have to do is give up entirely on trying to use make install to install the modules. It is completely broken for this application, because even if the destination could somehow be forced to be what you wanted—and, after all, why would you expect that make install would let you configure the destination directory in a simple fashion?—it would still install not only the contents of MODULE/lib, but also the contents of MODULE/bin, MODULE/man, MODULE/share, MODULE/pus, MODULE/dork, MODULE/felch, and MODULE/scrotum, some of which you probably didn't want.
So no. But the solution is actually simple. The normal module build process (as distinct from the install process) puts all this crap under MODULE/blib. The test suite is run against the blib installation. So the test programs have the same problem that X has. If they can find the stuff under blib, so can X, by replicating the layout under blib and then doing what the test suite does.
In fact, the modules are installed into the proper subdirectories of MODULE/blib/lib. So the simple solution is just to build the module and then, instead of trying to get the installer to put the right stuff in the right place, use cp -pr MODULE/blib/lib/* X/lib. Problem solved.
For modules with a shared library, you need to copy MODULE/blib/arch/auto/* into X/lib/auto also.
I remember suffering over this at least ten years ago, when a student in a class I was teaching asked me how to do it and I let ExtUtils::MakeMaker make a monkey of me. I was amazed to find myself suffering over it once again. I am relieved to have found the right answer.
This is one of those days when I am not happy with software. It sometimes surprises me how many of those days involve make.
Dennis Ritchie once said that "make is like Pascal. Everybody likes it, so they go in and change it." I never really thought about this before, but it now occurs to me that probably Ritchie meant that they like make in about the same way that they like bladder stones. Because Dennis Ritchie probably does not like Pascal, and actually nobody else likes Pascal either. They may say they do, and they may even think they do, but if you look a little closer it always turns out that the thing they like is not actually Pascal, but some language that more or less resembles Pascal. Unfortunately, the changes people make to make tend to make it bigger and wartier, and this improves make about as much as it would improve a bladder stone.
I would like to end this article on a positive note. If you haven't already, please read Recursive make Considered Harmful and be prepared to be blinded by the Glorious Truth therein.
[Other articles in category /prog] permanent link
Fri, 21 Mar 2008
Closed file descriptors: the answer
This is the answer to yesterday's article about a
small program that had a mysterious error.
my $command = shift;
for my $file (@ARGV) {
if ($file =~ /\.gz$/) {
my $fh;
unless (open $fh, "<", $file) {
warn "Couldn't open $file: $!; skipping\n";
next;
}
my $fd = fileno $fh;
$file = "/proc/self/fd/$fd";
}
}
exec $command, @ARGV;
die "Couldn't run command '$command': $!\n";
When the loop exits, $fh is out of scope, and the
filehandle it contains is garbage-collected, closing the file."Duh."
Several people suggested that it was because open files are not preserved across an exec, or because the meaning of /proc/self would change after an exec, perhaps because the command was being run in a separate process; this is mistaken. There is only one process here. The exec call does not create a new process; it reuses the same one, and it does not affect open files, unless they have been flagged with FD_CLOEXEC.
Abhijit Menon-Sen ran a slightly different test than I did:
% z cat foo.gz bar.gz
cat: /proc/self/fd/3: No such file or directory
cat: /proc/self/fd/3: No such file or directory
As he said, this makes it completely obvious what is wrong, since
the two files are both represented by the same file descriptor.
[Other articles in category /prog/perl] permanent link
Thu, 20 Mar 2008
Closed file descriptors
I wasn't sure whether to file this on the /oops
section. It is a mistake, and I spent a lot longer chasing the bug
than I should have, because it's actually a simple bug. But it isn't
a really big conceptual screwup of the type I like to feature in the
/oops section.
It concerns a
program that I'll discuss in detail tomorrow. In the meantime, here's
a stripped-down summary, and a stripped-down version of the code:
my $command = shift;
for my $file (@ARGV) {
if ($file =~ /\.gz$/) {
my $fh;
unless (open $fh, "<", $file) {
warn "Couldn't open $file: $!; skipping\n";
next;
}
my $fd = fileno $fh;
$file = "/proc/self/fd/$fd";
}
}
exec $command, @ARGV;
die "Couldn't run command '$command': $!\n";
The idea here is that this program, called z, will preprocess
the arguments of some command, and then run the command
with the modified arguments. For some of the command-line arguments,
here the ones named *.gz, the original file will be replaced
by the output of some file descriptor. In the example above, the
descriptor is attached to the original file, which is pointless. But
once this part of the program was working, I planned to change the code
so that the descriptor would be
attached to a pipe instead.Having written something like this, I then ran a test, which failed:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directory"Aha," I said instantly. "I know what is wrong. Perl set the close-on-exec flag on file descriptor 3."
You see, after a successful exec, the kernel will automatically close all file descriptors that have the close-on-exec flag set, before the exec'ed image starts running. Perl normally sets the close-on-exec flag on all open files except for standard input, standard output, and standard error. Actually it sets it on all open files whose file descriptor is greater than the value of $^F, but $^F defaults to 2.
So there is an easy fix for the problem: I just set $^F = 100000 at the top of the program. That is not the best solution, but it can be replaced with a better one once the program is working properly. Which I expected it would be:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directoryHuh, something is still wrong.
Maybe I misspelled /proc/self/fd? No, it is there, and contains the special files that I expected to find.
Maybe $^F did not work the way I thought it did? I checked the manual, but it looked okay.
Nevertheless I put in use Fcntl and used the fcntl function to remove the close-on-exec flags explicitly. The code to do that looks something like this:
use Fcntl;
....
my $flags = fcntl($fh, F_GETFD, 0);
fcntl($fh, F_SETFD, $flags & ~FD_CLOEXEC);
And try it again:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directoryHuh.
I then wasted a lot of time trying to figure out an easy way to tell if the file descriptor was actually open after the exec call. (The answer turns out to be something like this: perl -MPOSIX=fstat -le 'print "file descriptor 3 is ", fstat(3) ? "open" : "closed"'.) This told me whether the error from cat meant what I thought it meant. It did: descriptor 3 was indeed closed after the exec.
Now your job is to figure out what is wrong. It took me a shockingly long time. No need to email me about it; I have it working now. I expect that you will figure it out faster than I did, but I will also post the answer on the blog tomorrow. Sometime on Friday, 21 March 2008, this link will start working and will point to the answer.
[ Addendum 20080321: I posted the answer. ]
[Other articles in category /prog/perl] permanent link
Fri, 14 Mar 2008
Drawing lines
As part of this thing I sometimes do when I'm not writing in my
blog—what is it called?—oh, now I remember.
As part of my job I had to produce the following display:
If you wanted to hear more about phylogeny, Java programming, or tree algorithms, you are about to be disappointed. The subject of my article today is those fat black lines.
The first draft of the page did not have the fat black lines. It had some incredibly awful ASCII-art that was not even properly aligned. Really it was terrible; it would have been better to have left it out completely. I will not make you look at it.
I needed the lines, so I popped down the "graphics" menu on my computer and looked for something suitable. I tried the Gimp first. It seems that the Gimp has no tool for drawing straight lines. If someone wants to claim that it does, I will not dispute the claim. The Gimp has a huge and complex control panel covered with all sorts of gizmos, and maybe one of those gizmos draws a straight line. I did not find one. I gave up after a few minutes.
Next I tried Dia. It kept selecting the "move the line around on the page" tool when I thought I had selected the "draw another line" tool. The lines were not constrained to a grid by default, and there was no obvious way to tell it that I wanted to draw a diagram smaller than a whole page. I would have had to turn the thing into a bitmap and then crop the bitmap. "By Zeus's Beard," I cried, "does this have to be so difficult?" Except that the oath I actually uttered was somewhat coarser and less erudite than I have indicated. I won't repeat it, but it started with "fuck" and ended with "this".
Here's what I did instead. I wrote a program that would read an input like this:
>-v-<
'-+-`
and produce a jpeg file that looks like this:
.---,
| >--,
'---` '-
Becomes this:
Now I know some of you are just itching to write to me and ask "why didn't you just use...?", so before you do that, let me remind you of two things. First, I had already wasted ten or fifteen minutes on "just use..." that didn't work. And second, this program only took twenty minutes to write.
The program depends on one key insight, which is that it is very, very easy to write a Perl program that generates a graphic output in "PBM" ("portable bitmap") format. Here is a typical PBM file:
P1
10 10
1111111111
1000000001
1000000001
1001111001
1001111001
1001111001
1001111001
1000000001
1000000001
1111111111
The P1 is a magic number that identifies the file format; it
is always the same. The 10 10 warns the processor that the
upcoming bitmap is 10 pixels wide and 10 pixels high. The following
characters are the bitmap data.
I'm not going to insult you by showing the 10×10 bitmap image
that this represents.PBM was invented about twenty years ago by Jef Poskanzer. It was intended to be an interchange format: say you want to convert images from format X to format Y, but you don't have a converter. You might, however, have a converter that turns X into PBM and then one that turns PBM into Y. Or if not, it might not be too hard to produce such converters. It is, in the words of the Extreme Programming guys, the Simplest Thing that Could Possibly Work.
There are also PGM (portable graymap) and PPM (portable pixmap) formats for grayscale and 24-bit color images as well. They are only fractionally more complicated.
Because these formats are so very, very simple, they have been widely adopted. For example, the JPEG reference implementation includes a sample cjpeg program, for converting an input to a JPEG file. The input it expects is a PGM or PPM file.
Writing a Perl program to generate a P?M file, and then feeding the output to pbmtoxbm or ppmtogif or cjpeg is a good trick, and I have used it many times. For example, I used this technique to generate a zillion little colored squares in this article about the Pólya-Burnside counting lemma. Sure, I could have drawn them one at a time by hand, and probably gone insane and run amuck with an axe immediately after, but the PPM technique was certainly much easier. It always wins big, and this time was no exception.
The program may be interesting as an example of this technique, and possibly also as a reminder of something else. The Perl community luminaries invest a lot of effort in demonstrating that not every Perl program looks like a garbage heap, that Perl can be as bland and aseptic as Java, that Perl is not necessarily the language that most closely resembles quick-drying shit in a tube, from which you can squirt out the contents into any shape you want and get your complete, finished artifact in only twenty minutes and only slightly smelly.
No, sorry, folks. Not everything we do is a brilliant, diamond-like jewel, polished to a luminous gloss with pages torn from one of Donald Knuth's books. This line-drawing program was squirted out of a tube, and a fine brown piece of engineering it is.
#!/usr/bin/perl
my ($S) = shift || 50;
$S here is "size". The default is to turn every character in
the input into a 50×50 pixel tile. Here's the previous example
with $S=10: 
my ($h, $w);
my $output = [];
while (<>) {
chomp;
$w ||= length();
$h++;
push @$output, convert($_);
}
The biggest defect in the program is right here: it assumes that each
line will have the same width $w. Lines all must be
space-padded to the same width. Fixing this is left as an easy
exercise, but it wasn't as easy as padding the inputs, so I didn't do it.The magic happens here:
open STDOUT, "| pnmscale 1 | cjpeg" or die $!;
print "P1\n", $w * $S, " ", $h * $S, "\n";
print $_, "\n" for @$output;
exit;
The output is run through cjpeg to convert the PBM data to
JPEG. For some reason cjpeg doesn't accept PBM data, only
PGM or PPM, however, so the output first goes through
pnmscale, which resizes a P?M input. Here the scale factor
is 1, which is a no-op, except that pnmscale happens to turn
a PBM input into a PGM output. This is what is known in the business
as a "trick". (There is a pbmtopgm program, but it does
something different.)If we wanted gif output, we could have used "| ppmtogif" instead. If we wanted output in Symbolics Lisp Machine format, we could have used "| pgmtolispm" instead. Ah, the glories of interchange formats.
I'm going to omit the details of convert, which just breaks each line into characters, calls convert_ch on each character, and assembles the results. (The complete source code is here if you want to see it anyway.) The business end of the program is convert_ch:
#
sub convert_ch {
my @rows;
my $ch = shift;
my $up = $ch =~ /[<|>^'`+]/i;
my $dn = $ch =~ /[<|>V.,+]/i;
my $lt = $ch =~ /[-<V^,`+]/i;
my $rt = $ch =~ /[->V^.'+]/i;
These last four variables record whether the tile has a line from its
center going up, down, left, or right respectively. For example,
"|" produces a tile with lines coming up and down from the
center, but not left or right. The /i in the regexes is
because I kept writing v instead of V in the
inputs.
my $top = int($S * 0.4);
my $mid = int($S * 0.2);
my $bot = int($S * 0.4);
The tile is divided into three bands, of the indicated widths. This
probably looks bad, or fails utterly, unless $S is a multiple
of 5. I haven't tried it. Do you think I care? Hint: I haven't tried
it.
my $v0 = "0" x $S;
my $v1 = "0" x $top . "1" x $mid . "0" x $bot;
push @rows, ($up ? $v1 : $v0) x $top;
This assembles the top portion of the tile, including the "up" line,
if there is one. Note that despite their names, $top also
determines the width of the left portion of the tile, and
$bot determines the width of the right portion. The letter
"v" here is for "vertical".Perhaps I should explain for the benefit of the readers of Planet Haskell (if any of them have read this far and not yet fainted with disgust) that "$a x $b" in Perl is like concat (replicate b a) in the better sorts of languages.
my $ls = $lt ? "1" : "0";
my $ms = ($lt || $rt || $up || $dn) ? "1" : "0";
my $rs = $rt ? "1" : "0";
push @rows, ($ls x $top . $ms x $mid . $rs x $bot) x $mid;
This assembles the middle section, including the "left" and "right"
lines.
push @rows, ($dn ? $v1 : $v0) x $bot;
This does the bottom section.
return @rows;
}
And we are done.
Nothing to it. Adding diagonal lines would be a fairly simple matter.Download the complete source code if you haven't seen enough yet.
There is no part of this program of which I am proud. Rather, I am proud of the thing as a whole. It did the job I needed, and it did it by 5 PM. Larry Wall once said that "a Perl script is correct if it's halfway readable and gets the job done before your boss fires you." Thank you, Larry.
No, that is not quite true. There is one line in this program that I'm proud of. I noticed after I finished that there is exactly one comment in this program, and it is blank. I don't know how that got in there, but I decided to leave it in. Who says program code can't be funny?
[Other articles in category /prog/perl] permanent link
Thu, 24 Jan 2008
Emacs and alists
[ This article is a few weeks old now. I wrote it and forgot to publish it
at the time. ]
Yesterday I upgraded Emacs, and since it was an upgrade, something that had been working for me for fifteen years stopped working, because that's what "upgrade" means. My .emacs file contains:
(aput 'auto-mode-alist "\\.pl\\'" (function cperl-mode))
(aput 'auto-mode-alist "\\.t\\'" (function cperl-mode))
(aput 'auto-mode-alist "\\.cgi\\'" (function cperl-mode))
(aput 'auto-mode-alist "\\.pm\\'" (function cperl-mode))
(aput 'auto-mode-alist "\\.blog\\'" (function text-mode))
(aput 'auto-mode-alist "\\.sml\\'" (function sml-mode))
I should explain this, since I imagine that most readers of this blog
are like me in that they touch Emacs Lisp only once a year on Saint
Vibrissa's Day. An alist ("association list") is a common data
structure in Lisp programs. It is a list of pairs; the first element
of each pair is a key, and the second element is an associated value.
The pairs in the special auto-mode-alist variable have regexes
as their keys and functions as their values. Whenever Emacs opens a
new file, it scans this alist, until it finds a regex that matches the
name of the file. It then executes the associated function. Thus the
effect of the first line above is to have Emacs enable the
cperl-mode function on any file whose name ends in ".pl".
The aput function is for maintaining alists. It takes an alist, a key, and a value, scans the alist looking for a matching key, and then if it finds it, it amends the corresponding value. Otherwise, it appends a new association onto the front of the alist.
When I upgraded emacs, this broke. The aput function was moved into a separate package, which I now had to load with (require 'assoc).
I asked about this on IRC, and was told that the correct way to do this, if I did not want to (require 'assoc), was to use the following abomination:
(mapc (lambda (x) (when (eq 'perl-mode (cdr x)) (setcdr x 'cperl-mode)))
(append auto-mode-alist interpreter-mode-alist))
The effect of this is to scan over auto-mode-alist (and also
interpreter-mode-alist, a related variable) looking for any
association whose value was the perl-mode function, and
using setcdr to replace perl-mode with
cperl-mode.(This does not address the issue of what to do with .t files or .blog files, for which no association exists yet, presumably, but I did not ask about those specifically on IRC.)
I was totally boggled. Choosing the right editing mode for a file is a basic function of emacs. I could not believe that the best and simplest way to add or change associations was to use mapc lambda gobhorn oleo potatopudding quote potrzebie. I was assured that this was indeed the only correct method. Struck almost speechless, I managed to come up with "Bullshit."
Apparently the issue was that if auto-mode-alist already contains an association for ".pl", there is no guarantee that my new association will be found and preferred to the old one, unless I somehow remove the old one, or edit it to be the way I want.
This seemed very unlikely to me. You see, an alist is a list. This means that it is searched from head to tail, because this is the only way a list can be searched. So in particular, if you cons a second association to the front of the list, which has the same key as a later (older) association, the search will find the new one first, and the older one becomes inoperative. I asked if there was not a guarantee that the alist would be searched from front to back. I was told that there is not.
I looked in the manual, and reported that the assoc function, which is the getter that corresponds to aput, taking an alist and a key, and returning the corresponding value, is expressly guaranteed to return the first matching item. I was told that there was no guarantee that assoc would be used.
I pondered the manual some more and found this passage:
However, association lists have their own advantages. Depending on your application, it may be faster to add an association to the front of an association list than to update a property.That is, it is expressly endorsing the technique of adding a new item to the front of an alist in order to override any later item that might have the same key.
After finding that the add-to-the-front technique really did work, I reasoned that if someday Emacs stopped searching alists sequentially, I would not be in any more trouble than I had been today when they removed the aput function.
So I did not take the advice I was given. Instead, I left it pretty much the way it was. I did take the opportunity to clean up the code a bit:
(push '("\\.pl\\'" . cperl-mode) auto-mode-alist)
(push '("\\.t\\'" . cperl-mode) auto-mode-alist)
(push '("\\.cgi\\'" . cperl-mode) auto-mode-alist)
(push '("\\.pm\\'" . cperl-mode) auto-mode-alist)
(push '("\\.blog\\'" . text-mode) auto-mode-alist)
(push '("\\.sml\\'" . sml-mode) auto-mode-alist)
The push function simply appends an element to the front of a
list, modifying the list in-place.But wow, the advice I got was phenomenally bad. It was bad in a really interesting way, too. It reminded me of the advice people get on the #math channel, where some guy comes in with some question about triangles and gets the category-theoretic viewpoint on triangles as natural transformations of something or other. The advice was bad because although it was correct, it was completely devoid of common sense.
[ Addendum 20080124: It has been brought to my attention that the Emacs FAQ endorses my solution, which makes the category-theoretic advice proposed by the #emacs blockheads even less defensible. ]
[ Addendum 20080201: Steve Vinoski suggests replacing the aput function. ]
[Other articles in category /prog] permanent link
Fri, 11 Jan 2008
Help, help!
(Readers of Planet Haskell
may want to avert their eyes from this compendium of Perl
introspection techniques. Moreover, a very naughty four-letter word
appears, a word that begins with "g" and ends with "o". Let's just
leave it at that.)
Przemek Klosowski wrote to offer me physics help, and also to ask about introspection on Perl objects. Specifically, he said that if you called a nonexistent method on a TCL object, the error message would include the names of all the methods that would have worked. He wanted to know if there was a way to get Perl to do something similar.
There isn't, precisely, because Perl has only a conventional distinction between methods and subroutines, and you Just Have To Know which is which, and avoid calling the subroutines as methods, because the Perl interpreter has no idea which is which. But it does have enough introspection features that you can get something like what you want. This article will explain how to do that.
Here is a trivial program that invokes an undefined method on an object:
use YAML;
my $obj = YAML->new;
$obj->nosuchmethod;
When run, this produces the fatal error:
Can't locate object method "nosuchmethod" via package "YAML" at test.pl line 4.
(YAML in this article is just an example; you don't have to
know what it does. In fact, I don't know what it does.)Now consider the following program instead:
use YAML;
use Help 'YAML';
my $obj = YAML->new;
$obj->nosuchmethod;
Now any failed method calls to YAML objects, or objects of
YAML's subclasses, will produce a more detailed error
message:
Unknown method 'nosuchmethod' called on object of class YAML
Perhaps try:
Bless
Blessed
Dump
DumpFile
Load
LoadFile
VALUE
XXX
as_heavy (inherited from Exporter)
die (inherited from YAML::Base)
dumper_class
dumper_object
export (inherited from Exporter)
export_fail (inherited from Exporter)
export_ok_tags (inherited from Exporter)
export_tags (inherited from Exporter)
export_to_level (inherited from Exporter)
field
freeze
global_object
import (inherited from Exporter)
init_action_object
loader_class
loader_object
new (inherited from YAML::Base)
node_info (inherited from YAML::Base)
require_version (inherited from Exporter)
thaw
warn (inherited from YAML::Base)
ynode
Aborting at test.pl line 5
Some of the methods in this list are bogus. For example, the stuff
inherited from Exporter should almost certainly not be
called on a YAML object.Some of the items may be intended to be called as functions, and not as methods. Some may be functions imported from some other module. A common offender here is Carp, which places a carp function into another module's namespace; this function will show up in a list like the one above, without even an "inherited from" note, even though it is not a method and it does not make sense to call it on an object at all.
Even when the items in the list really are methods, they may be undocumented, internal-use-only methods, and may disappear in future versions of the YAML module.
But even with all these warnings, Help is at least a partial solution to the problem.
The real reason for this article is to present the code for Help.pm, not because the module is so intrinsically useful itself, but because it is almost a catalog of weird-but-useful Perl module hackery techniques. A full and detailed tour of this module's 30 lines of code would probably make a decent 60- or 90-minute class for intermediate Perl programmers who want to become wizards. (I have given many classes on exactly that topic.)
Here's the code:
package Help;
use Carp 'croak';
sub import {
my ($selfclass, @classes) = @_;
for my $class (@classes) {
push @{"$class\::ISA"}, $selfclass;
}
}
sub AUTOLOAD {
my ($bottom_class, $method) = $AUTOLOAD =~ /(.*)::(.*)/;
my %known_method;
my @classes = ($bottom_class);
while (@classes) {
my $class = shift @classes;
next if $class eq __PACKAGE__;
unshift @classes, @{"$class\::ISA"};
for my $name (keys %{"$class\::"}) {
next unless defined &{"$class\::$name"};
$known_method{$name} ||= $class;
}
}
warn "Unknown method '$method' called on object of class $bottom_class\n";
warn "Perhaps try:\n";
for my $name (sort keys %known_method) {
warn " $name " .
($known_method{$name} eq $bottom_class
? ""
: "(inherited from $known_method{$name})") .
"\n";
}
croak "Aborting";
}
sub help {
$AUTOLOAD = ref($_[0]) . '::(none)';
goto &AUTOLOAD;
}
sub DESTROY {}
1;
use Help 'Foo'
When any part of the program invokes use Help 'Foo', this does two things. First, it locates Help.pm, loads it in, and compiles it, if that has not been done already. And then it immediately calls Help->import('Foo').Typically, a module's import method is inherited from Exporter, which gets control at this point and arranges to make some of the module's functions available in the caller's namespace. So, for example, when you invoke use YAML 'freeze' in your module, Exporter's import method gets control and puts YAML's "freeze" function into your module's namespace. But that is not what we are doing here. Instead, Help has its own import method:
sub import {
my ($selfclass, @classes) = @_;
for my $class (@classes) {
push @{"$class\::ISA"}, $selfclass;
}
}
The $selfclass variable becomes Help and @classes
becomes ('Foo'). Then the module does its first tricky
thing. It puts itself into the @ISA list of another class.
The push line adds Help to @Foo::ISA.@Foo::ISA is the array that is searched whenever a method call on a Foo objects fails because the method doesn't exist. Perl will search the classes named in @Foo::ISA, in order. It will search the Help class last. That's important, because we don't want Help to interfere with Foo's ordinary inheritance.
Notice the way the variable name Foo::ISA is generated dynamically by concatenating the value of $class with the literal string ::ISA. This is how you access a variable whose name is not known at compile time in Perl. We will see this technique over and over again in this module.
The backslash in @{"$class\::ISA"} is necessary, because if we wrote @{"$class::ISA"} instead, Perl would try to interpolate the value of $ISA variable from the package named class. We could get around this by writing something like @{$class . '::ISA'}, but the backslash is easier to read.
AUTOLOAD
So what happens when the program calls $foo->nosuchmethod? If one of Foo's base classes includes a method with that name, it will be called as usual.But when method search fails, Perl doesn't give up right away. Instead, it tries the method search a second time, this time looking for a method named AUTOLOAD. If it finds one, it calls it. It only throws an exception of there is no AUTOLOAD.
The Help class doesn't have a nosuchmethod method either, but it does have AUTOLOAD. If Foo or one of its other parent classes defines an AUTOLOAD, one of those will be called instead. But if there's no other AUTOLOAD, then Help's AUTOLOAD will be called as a last resort.
$AUTOLOAD
When Perl calls an AUTOLOAD function, it sets the value of $AUTOLOAD to include the full name of the method it was trying to call, the one that didn't exist. In our example, $AUTOLOAD is set to "Foo::nosuchmethod".This pattern match dismantles the contents of $AUTOLOAD into a class name and a method name:
sub AUTOLOAD {
my ($bottom_class, $method) = $AUTOLOAD =~ /(.*)::(.*)/;
The $bottom_class variable contains Foo, and the
$method variable contains nosuchmethod.The AUTOLOAD function is now going to accumulate a table of all the methods that could have been called on the target object, print out a report, and throw a fatal exception.
The accumulated table will reside in the private hash %known_method. Keys in this hash will be method names. Values will be the classes in which the names were found.
Accumulating the table of method names
The AUTOLOAD function accumulates this hash by doing a depth-first search on the @ISA tree, just like Perl's method resolution does internally. The @classes variable is a stack of classes that need to be searched for methods but that have not yet been searched. Initially, it includes only the class on which the method was actually called, Foo in this case:
my @classes = ($bottom_class);
As long as some class remains unsearched, this loop will continue to
look for more methods. It begins by grabbing the next class off the
stack:
while (@classes) {
my $class = shift @classes;
Foo inherits from Help too, but we don't want our
error message to mention that, so the search skips Help:
next if $class eq __PACKAGE__;
(__PACKAGE__ expands at compile time to the name of the
current package.)Before the loop actually looks at the methods in the current class it's searching, it looks to see if the class has any base classes. If there are any, it pushes them onto the stack to be searched next:
unshift @classes, @{"$class\::ISA"};
Now the real meat of the loop: there is a class name in
$class, say Foo,
and we want the program to find all the methods in that class. Perl
makes the symbol table for the Foo package available in the
hash %Foo::. Keys in this hash are variable, subroutine, and
filehandle names.To find out if a name denotes a subroutine, we use defined(&{subroutine_name}) for each name in the package symbol table. If there is a subroutine by that name, the program inserts it and the class name into %known_method. Otherwise, the name is a variable or filehandle name and is ignored:
for my $name (keys %{"$class\::"}) {
next unless defined &{"$class\::$name"};
$known_method{$name} ||= $class;
}
}
The ||= sets a new value for $name in the hash only
if there was not one already. If a method name appears in more than
one class, it is recorded as being in the first one found in the
search. Since the search is proceeding in the same order that Perl
uses, the one recorded is the one that Perl will actually find. For
example, if Foo inherits from Bar, and both classes
define a this method, the search will find Foo::this
before Bar::this, and that is what will be recorded in the
hash. This is correct, because Foo's this method
overrides Bar's.If you have any clever techniques for identifying other stuff that should be omitted from the output, this is where you would put them. For example, many authors use the convention that functions whose names have a leading underscore are private to the implementation, and should not be called by outsiders. We might omit such items from the output by adding a line here:
next if $name =~ /^_/;
After the loop finishes searching all the base classes, the
%known_method hash looks something like this:
(
this => Foo,
that => Foo,
new => Base,
blookus => Mixin::Blookus,
other => Foo
)
This means that methods this, that, and
other were defined in Foo itself, but that
new is inherited from Base and that blookus
was inherited from Mixin::Blookus.
Printing the report
The AUTOLOAD function then prints out some error messages:
warn "Unknown method '$method' called on object of class $bottom_class\n";
warn "Perhaps try:\n";
And at last the payoff: It prints out the list of methods that the
programmer could have called:
for my $name (sort keys %known_method) {
warn " $name " .
($known_method{$name} eq $bottom_class
? ""
: "(inherited from $known_method{$name})") .
"\n";
}
croak "Aborting";
}
Each method name is printed. If the class in which the method was
found is not the bottom class, the name is annotated with the message
(inherited from wherever).The output for my example would look like this:
Unknown method 'nosuchmethod' called on object of class Foo:
Perhaps try:
blookus (inherited from Mixin::Blookus)
new (inherited from Base)
other
that
this
Aborting at YourErroneousModule.pm line 679
Finally the function throws a fatal exception. If we had used
die here, the fatal error message would look like
Aborting at Help.pm line 34, which is extremely unhelpful.
Using croak instead of die makes the message look
like Aborting at test.pl line 5 instead. That is, it reports
the error as coming from the place where the erroneous method was
actually called.
Synthetic calls
 Suppose you want to force the help message to come out. One way is to
call $object->fgsfds, since probably the object does not
provide a fgsfds method. But this is ugly, and it might not
work, because the object might provide a fgsfds
method. So Help.pm provides another way.
Suppose you want to force the help message to come out. One way is to
call $object->fgsfds, since probably the object does not
provide a fgsfds method. But this is ugly, and it might not
work, because the object might provide a fgsfds
method. So Help.pm provides another way.You can always force the help message by calling $object->Help::help. This calls a method named help, and it starts the inheritance search in the Help package. Control is transferred to the following help method:
sub help {
$AUTOLOAD = ref($_[0]) . '::(none)';
goto &AUTOLOAD;
}
The Help::help method sets up a fake $AUTOLOAD
value and then uses "magic goto" to transfer control to the real
AUTOLOAD function. "Magic goto" is not the evil bad goto
that is Considered Harmful. It is more like a function call. But
unlike a regular function call, it erases the calling function
(help) from the control stack, so that to subsequently
executed code it appears that AUTOLOAD was called directly in
the first place.Calling AUTOLOAD in the normal way, without goto, would have worked also. I did it this way just to be a fusspot.
DESTROY
Whenever a Perl object is destroyed, its DESTROY method is called, if it has one. If not, method search looks for an AUTOLOAD method, if there is one, as usual. If this lookup fails, no fatal exception is thrown; the object is sliently destroyed and execution continues.It is very common for objects to lack a DESTROY method; usually nothing additional needs to be done when the object's lifetime is over. But we do not want the Help::AUTOLOAD function to be invoked automatically whenever such an object is destroyed! So Help defines a last-resort DESTROY method that is called instead; this prevents Perl from trying the AUTOLOAD search when an object with no DESTROY method is destroyed:
sub DESTROY {}
This DESTROY method restores the default
behavior, which is to do nothing.
Living dangerously
Perl has a special package, called UNIVERSAL. Every class inherits from UNIVERSAL. If you want to apply Help to every class at once, you can try:
use Help 'UNIVERSAL';
but don't blame me if something weird happens.
About use strict
Whenever I present code like this, I always get questions (or are they complaints?) from readers about why I omitted "use strict". "Always use strict!" they say.Well, this code will not run with "use strict". It does a lot of stuff on purpose that "strict" was put in specifically to keep you from doing by accident.
At some point you have to take off the training wheels, kiddies.
License
Code in this article is hereby placed in the public domain.Share and enjoy.
[Other articles in category /prog/perl] permanent link
Tue, 08 Jan 2008
Clubbing someone to death with a loaded Uzi
I once had an intern who wrote wrote the following code to process a
web survey form. The form input widgets were named q1,
q2, and so forth:
foreach $k (keys %in) {
if ($k eq q1) {
if ($in{$k} eq agree) {
$count{q10} = $count{q10} + 1;
}
if ($in{$k} eq disaagree) {
$count{q11} = $count{q11} + 1;
}
}
if ($k eq q2) {
@q2split = split(/\0/, $in{$k});
foreach (@q2split) {
$count{$_} = $count{$_} + 1;
}
}
if ($k eq q3) {
$count{$in{$k}} = $count{$in{$k}} + 1;
}
...
}
There is a lot wrong with this code, but it's all trivial compared
with the one big problem, which is the wholly unnecessary loop and
tests. The whole thing could be (and should be, and was) rewritten
as:
if ($in{q1} eq agree) {
$count{q10} = $count{q10} + 1;
}
if ($in{q1} eq disaagree) {
$count{q11} = $count{q11} + 1;
}
@q2split = split(/\0/, $in{q2});
foreach (@q2split) {
$count{$_} = $count{$_} + 1;
}
$count{$in{q3}} = $count{$in{q3}} + 1;
...
After which one could start addressing the smaller problems, like the
fact that "disagree" is misspelled.This is the sort of mistake you expect from an intern. I chuckled and corrected him. But I've seen it several times since from non-interns.
Here's another example. I am not making this up. Whether it's more or less odious than the intern code is up to you to decide:
foreach $location_name (%LOCATION ) {
$location_code = $LOCATION{$location_name};
if ($location_name eq $location ) {
printf FILE "$location_code\,";
printf FILE "%4s", "$min3\,";
printf FILE "%4s", "$max3\,";
printf FILE "%1s", "$wx3\n";
}
}
It could have been written like this:
printf FILE "$LOCATION{$location}\,";
printf FILE "%4s", "$min3\,";
printf FILE "%4s", "$max3\,";
printf FILE "%1s", "$wx3\n";
I started using this problem as an interview question. I'll present
the subject with trivial code like this:
for my $k (keys %hash) {
if ($k eq "name") {
$hash{$k}++;
}
}
and then ask if they have any comments about it. One nice thing about
the question is that it translates naturally into whatever imperative
language they claim expertise in.It's appalling how many supposedly professional programmers see nothing wrong here. They squint at the code, and say "I think you need parentheses around %hash there", or they criticize the choice of variable names.
I first used this as an interview question because the Python code sample submitted by a job applicant contained an example of it. "Weird," I thought, "but maybe she's outgrown that." Since she claimed to be an expert Perl user, I asked her about it in Perl, using code like the example above. After she made a syntactic suggestion, I said "It's not a syntax problem, and it's not a trick question." She criticized the syntax some more. Finally I told her the answer: "Couldn't you just use $hash{name}++?"
"Oh, yeah, I guess so," she said.
A few minutes later we were going over her Python code sample and I pointed out the place where she had done the exact same thing, and asked if she was happy with that loop and wanted to change it. No, she thought it was just fine.
"Doesn't this look like the example I showed you on the whiteboard a little while ago?"
"Oh, I guess it does."
We didn't hire her.
Larry Wall once said that iterating over the keys of a hash is like clubbing someone to death with a loaded Uzi.
I had already realized that you could, in principle, commit this error with a regular array instead of with a hash, but I had never seen an example until today's episode of the Daily WTF. The Daily WTF code is so awful, all the way through, that I was afraid that people might miss this slightly-more subtle gem lurking in the middle, and that was what motivated me to write this article in the first place. Here's the gem:
// Java
for (int a=1;a<=params.size();a++) switch (a)
{
case 1 : if (params.get(0) != null)
this.one=params.get(0).toString();
break;
case 2 : if (params.get(1) != null)
this.two=params.get(1).toString();
break;
...
case 14 : if (params.get(13) != null)
this.fourteen=params.get(13).toString();
break;
}
}
Wow, that is just, uh, stunning.[ Addendum 20080201: A bit more. ]
[ Addendum 20090213: A counterexample. ]
[Other articles in category /prog] permanent link
Thu, 03 Jan 2008
Note on point-free programming style
This old
comp.lang.functional article by Albert Y. C. Lai, makes
the point that Unix shell pipeline programming is done in an
essentially "point-free" style, using the shell example:
grep '^X-Spam-Level' | sort | uniq | wc -l
and the analogous Haskell code:
length . nub . sort . filter (isPrefixOf "X-Spam-Level")
Neither one explicitly mentions its argument, which is why this is
"point-free". In "point-free" programming, instead of defining a
function in terms of its effect on its arguments, one defines it by
composing the component functions themselves, directly, with
higher-order operators. For example, instead of:
foo x y = 2 * x + yone has, in point-free style:
foo = (+) . (2 *)where (2 *) is the function that doubles its argument, and (+) is the (curried) addition function. The two definitions of foo are entirely equivalent.
As the two examples should make clear, point-free style is sometimes natural, and sometimes not, and the example chosen by M. Lai was carefully selected to bias the argument in favor of point-free style.
Often, after writing a function in pointful style, I get the computer to convert it automatically to point-free style, just to see what it looks like. This is usually educational, and sometimes I use the computed point-free definition instead. As I get better at understanding point-free programming style in Haskell, I am more and more likely to write certain functions point-free in the first place. For example, I recently wrote:
soln = int 1 (srt (add one (neg (sqr soln))))
and then scratched my head, erased it, and replaced it with the equivalent:
soln = int 1 ((srt . (add one) . neg . sqr) soln)
I could have factored out the int 1 too:
soln = (int 1 . srt . add one . neg . sqr) soln
I could even have removed soln from the right-hand side:
soln = fix (int 1 . srt . add one . neg . sqr)
but I am not yet a perfect sage.Sometimes I opt for an intermediate form, one in which some of the arguments are explicit and some are implicit. For example, as an exercise I wrote a function numOccurrences which takes a value and a list and counts the number of times the value occurs in the list. A straightforward and conventional implementation is:
numOccurrences x [] = 0
numOccurrences x (y:ys) =
if (x == y) then 1 + rest
else rest
where rest = numOccurrences x ys
but the partially point-free version I wrote was much better:
numOccurrences x = length . filter (== x)
Once you see this, it's easy to go back to a fully pointful
version:
numOccurrences x y = length (filter (== x) y)
Or you can go the other way, to a point-free version:
numOccurrences = (length .) . filter . (==)
which I find confusing.Anyway, the point of this note is not to argue that the point-free style is better or worse than the pointful style. Sometimes I use the one, and sometimes the other. I just want to point out that the argument made by M. Lai is deceptive, because of the choice of examples. As an equally biased counterexample, consider:
bar x = x*x + 2*x + 1
which the automatic converter informs me can be written in point-free
style as:
bar = (1 +) . ap ((+) . join (*)) (2 *)
Perusal of this example will reveal much to the attentive reader,
including the definitions of join and ap. But I
don't think many people would argue that it is an improvement on the
original. (Maybe I'm wrong, and people would argue that it was an
improvement. I won't know for sure until I have more experience.)For some sort of balance, here is another example where I think the point-free version is at least as good as the pointful version: a recent comment on Reddit suggested a >>> operator that composes functions just like the . operator, but in the other order, so that:
f >>> g = g . f
or, if you prefer:
(>>>) f g x = g(f(x))
The point-free definition of >>> is:
(>>>) = flip (.)
where the flip operator takes a function of two arguments and
makes a new function that does the same thing, but with the arguments
in the opposite order. Whatever your feelings about point-free style,
it is undeniable that the point-free definition makes perfectly clear
that >>> is nothing but . with its arguments in
reverse order.
[Other articles in category /prog/haskell] permanent link
Sun, 30 Dec 2007
Welcome to my ~/bin
In the previous article I
mentioned "a conference tutorial about the contents of my
~/bin directory". Usually I have a web page about each
tutorial, with a description, and some sample slides, and I wanted to
link to the page about this tutorial. But I found to my surprise that
I had forgotten to make the page about this one.
So I went to fix that, and then I couldn't decide which sample slides to show. And I haven't given the tutorial for a couple of years, and I have an upcoming project that will prevent me from giving it for another couple of years. Eh, figuring out what to put online is more trouble than it's worth. I decided it would be a lot less toil to just put the whole thing online.
The materials are copyright © 2004 Mark Jason Dominus, and are not under any sort of free license.
But please enjoy them anyway.
I think the title is an accidental ripoff of an earlier class by Damian Conway. I totally forgot that he had done a class on the same subject, and I think he used the same title. But that just makes us even, because for the past few years he has been making money going around giving talks on "Conference Presentation Aikido", which is a blatant (and deliberate) ripoff of my 2002 Perl conference talk on Conference Presentation Judo. So I don't feel as bad as I might have.
Welcome to my ~/bin complete slides and other materials.
I hereby wish you a happy new year, unless you don't want one, in which case I wish you a crappy new year instead.
[Other articles in category /prog/perl] permanent link
Thu, 20 Dec 2007
Another trivial utility: accumulate
As usual, whenever I write one of these things, I wonder why it took
me so long to get off my butt and put in the five minutes of work that
were actually required. I've wanted something like this for
years. It's called accumulate. It reads an input of
this form:
k1 v1
k1 v2
k2 v3
k1 v4
k2 v5
k3 v6
and writes it out in this format:
k1 v1 v2 v4
k2 v3 v5
k3 v6
I wanted it this time because I had a bunch of files that included some
duplicates, and wanted to get rid of the duplicates. So:
md5sum * | accumulate | perl -lane 'unlink @F[2..$#F]'
(Incidentally, people sometimes argue that Perl's .. operator
should count backwards when the left operand exceeds the right one.
These people are wrong. There is only one argument that needs to be
made to refute this idea; maybe it is the only argument that
can be made. And examples of it abound. The code above is one
such example.)I'm afraid of insulting you by showing the source code for accumulate, because of course it is so very trivial, and you could write it in five minutes, as I did. But who knows; maybe seeing the source has some value:
#!/usr/bin/perl
use Getopt::Std;
my %opt = (k => 1, v => 2);
getopts('k:v:', \%opt) or usage();
for (qw(k v)) {
$opt{$_} -= 1 if $opt{$_} > 0;
}
while (<>) {
chomp;
my @F = split;
push @{$K{$F[$opt{k}]}}, $F[$opt{v}];
}
for my $k (keys %K) {
print "$k @{$K{$k}}\n";
}
It's tempting to add a -F option to tell it that the input is
not delimited by white space, or an option to change the output
format, or blah blah blah, but I managed to restrain myself, mostly.Several years ago I wrote a conference tutorial about the contents of my ~/bin directory. The clearest conclusion that transpired from my analysis was that the utilities I write have too many features that I don't use. The second-clearest was that I waste too much time writing custom argument-parsing code instead of using Getopt::Std. I've tried to learn from this. One thing I found later is that a good way to sublimate the urge to put in some feature is to put in the option to enable it, and to document it, but to leave the feature itself unimplemented. This might work for you too if you have the same problem.
I did put in -k and -v options to control which input columns are accumulated. These default to the first and second columns, naturally. Maybe this was a waste of time, since it occurs to me now that accumulate -k k -v v could be replaced by cut -fk,v | accumulate, if only cut didn't suck quite so badly. Of course one could use awk {print "$k $v" } | accumulate to escape cut's suckage. And some solution of this type obviates the need for accumulate's putative -F option also. Well, I digress.
The accumulate program itself reminds me of a much more ambitious project I worked on for a while between 1998 and 2001, as does the yucky line:
push @{$K{$F[$opt{k}]}}, $F[$opt{v}];
The ambitious project was tentatively named "twingler".Beginning Perl programmers often have trouble with compound data structures because Perl's syntax for the nested structures is so horrendous. Suppose, for example, that you have a reference to a two-dimensional array $aref, and you want to produce a hash, such that each value in the array appears as a key in the hash, associated with a list of strings in the form "m,n" indicating where in the array that value appeared. Well, of course it is obviously nothing more than:
for my $a1 (0 .. $#$aref) {
for my $a2 (0 .. $#{$aref->[$a1]}) {
push @{$hash{$aref->[$a1][$a2]}}, "$a1,$a2";
}
}
Obviously. <sarcasm>Geez, a child could see
that.</sarcasm>The idea of twingler was that you would specify the transformation you wanted declaratively, and it would then write the appropriate Perl code to perform the transformation. The interesting part of this project is figuring out the language for specifying the transformation. It must be complex enough to be able to express most of the interesting transformations that people commonly want, but if it isn't at the same time much simpler than Perl itself, it isn't worth using. Nobody will see any point in learning a new declarative language for expressing Perl data transformations unless it is itself simpler to use than just writing the Perl would have been.
[ Addendum 20150508: I dumped all my Twingler notes on the blog last year. ]
There are some hard problems here: What do people need? What subset of this can be expressed simply? How can we design a simple, limited language that people can use to express their needs? Can the language actually be compiled to Perl?
I had to face similar sorts of problems when I was writing linogram, but in the case of linogram I was more successful. I tinkered with twingler for some time and made several pages of (typed) notes but never came up with anything I was really happy with.
[ Addendum 20150508: I dumped all my Twingler notes on the blog last year. ]
At one point I abandoned the idea of a declarative language, in favor of just having the program take a sample input and a corresponding sample output, and deduce the appropriate transformation from there. For example, you would put in:
[ [ A, B ],
[ C, B ],
[ D, E ] ]
and
{ B => [A, C],
E => [D],
}
and it would generate:
for my $a1 (@$input) {
my ($e1, $e2) = @$a1;
push @{$output{$e2}}, $e1;
}
And then presumably you could eyeball this, and if what you really
wanted was @{$a1}[0, -1] instead of @$a1 you could
tinker it into the form you needed without too much extra trouble.
This is much nicer from a user-experience point of view, but at the
same time it seems more difficult to implement. I had some ideas. One idea was to have it generate a bunch of expressions for mapping single elements from the input to the output, and then to try to unify those expressions. But as I said, I never did figure it out.
It's a shame, because it would have been pretty cool if I had gotten it to work.
The MIT CS grad students' handbook used to say something about how you always need to have several projects going on at once, because two-thirds of all research projects end in failure. The people you see who seem to have one success after another actually have three projects going on all the time, and you only see the successes. This is a nice example of that.
[Other articles in category /prog] permanent link
Mon, 29 Oct 2007
Undefined behavior in Perl and other languages
Miles Gould wrote what I thought was an interesting
article on implementation-defined languages, and cited Perl as an
example. One of his points was that a language that is defined by its
implementation, as Perl is, rather than by a standards document,
cannot have any "undefined behavior".
- Undefined behavior
- Perl: the static variable hack
- Perl: modifying a hash in a loop
- Perl: modifying an array in a loop
- Haskell: n+k patterns
- XML screws up
Undefined behavior
For people unfamiliar with this concept, I should explain briefly. The C standard is full of places that say "if the program contains x, the behavior is undefined", which really means "C programs do not contain x, so If the program contains x, it is not written in C, and, as this standard only defines the meaning of programs in C, it has nothing to say about the meaning of your program." There are around a couple of hundred of these phrases, and a larger number of places where it is implied.For example, everyone knows that it means when you write x = 4;, but what does it mean if you write 4 = x;? According to clause 6.3.2.1[#1], it means nothing, and this is not a C program. The non-guarantee in this case is extremely strong. The C compiler, upon encountering this locution, is allowed to abort and spontaneously erase all your files, and in doing so it is not violating the requirements of the standard, because the standard does not require any particular behavior in this case.
The memorable phrase that the comp.lang.c folks use is that using that construction might cause demons to fly out of your nose.
[ Addendum 20071030: I am informed that I misread the standard here, and that the behavior of this particular line is not undefined, but requires a compiler diagnostic. Perhaps a better example would have been x = *(char *)0. ]
I mentioned this in passing in one of my recent articles about a C program I wrote:
unsigned strinc(char *s)
{
char *p = strchr(s, '\0') - 1;
while (p >= s && *p == 'A' + colors - 1) *p-- = 'A';
if (p < s) return 0;
(*p)++;
return 1;
}
Here the pointer p starts at the end of the string s,
and the loop might stop when p points to the position just
before s. Except no, that is forbidden, and the program might
at that moment cause demons to fly out of your nose. You are allowed
to have a pointer that points to the position just after an
object, but not one that points just before. Well anyway, I seem to have digressed. My point was that M. Gould says that one advantage of languages like Perl that are defined wholly by their (one) implementation is that you never have "undefined behavior". If you want to know what some locution does, you type it in and see what it does. Poof, instant definition.
Although I think this is a sound point, it occurred to me that that is not entirely correct. The manual is a specification of sorts, and even if the implementation does X in situation Y, the manual might say "The implementation does X in situation Y, but this is unsupported and may change without warning in the future." Then what you have is not so different from Y being undefined behavior. Because the manual is (presumably) a statement of official policy from the maintainers, and, as a communiqué from the people with the ultimate authority to define the future meaning of the language, it has some of the same status that a formal specification would.
Perl: the static variable hack
Such disclaimers do appear in the Perl documentation. Probably the most significant example of this is the static variable hack. For various implementation reasons, the locution my $static if 0 has a strange and interesting effect:
sub foo {
my $static = 42 if 0;
print "static is now $static\n";
$static++;
}
foo() for 1..5;
This makes $static behave as a "static" variable, and persist
from call to call of foo(). Without the ... if 0,
the code would print "static is now 42" five times. But with
... if 0, it prints:
static is now
static is now 1
static is now 2
static is now 3
static is now 4
This was never an intentional feature. It arose accidentally, and
then people discovered it and started using it. Since the behavior
was the result of a strange quirk of the implementation, caused by the
surprising interaction of several internal details, it was officially
decided by the support group that this behavior would not be supported
in future versions. The manual was amended to say that this behavior
was explicitly undefined, and might change in the future. It can be
used in one-off programs, but not in any important program, one that
might have a long life and need to be run under several different
versions of Perl. Programs that use pointers that point outside the
bounds of allocated storage in C are in a similar position. It might
work on today's system, with today's compiler, today, but you can't do
that in any larger context.Having the "undefined behavior" be determined by the manual, instead of by a language standard, has its drawbacks. The language standard is fretted over by experts for months. When the C standard says that behavior is undefined, it is because someone like Clive Feather or Doug Gwyn or P.J. Plauger, someone who knows more about C than you ever will, knows that there is some machine somewhere on which the behavior is unsupported and unsupportable. When the Perl manual says that some behavior is undefined, you might be hearing from the Perl equivalent of Doug Gwyn, someone like Nick Clark or Chip Salzenberg or Gurusamy Sarathy. Or you might be hearing from a mere nervous-nellie who got their patch into the manual on a night when the release manager had stayed up too late.
Perl: modifying a hash in a loop
Here is an example of this that has bothered me for a long time. One can use the each() operator to loop lazily over the contents of a hash:
while (my $key = each %hash) {
# do something with $key and $hash{$key}
}
What happens if you modify the hash in the middle of the loop? For
various implementation reasons, the manual forbids this.For example, suppose the loop code adds a new key to the hash. The hash might overflow as a result, and this would trigger a reorganization that would move everything around, destroying the ordering information. The subsequent calls to each() would continue from the same element of the hash, but in the new order, making it likely that the loop would visit some keys more than once, or some not at all. So the prohibition in that case makes sense: The each() operator normally guarantees to produce each key exactly once, and adding elements to a hash in the middle of the loop might cause that guarantee to be broken in an unpredictable way. Moreover, there is no obvious way to fix this without potentially wrecking the performance of hashes.
But the manual also forbids deleting keys inside the loop, and there the issue does not come up, because in Perl, hashes are never reorganized as the result of a deletion. The behavior is easily described: Deleting a key that has already been visited will not affect the each() loop, and deleting one that has not yet been visited will just cause it to be skipped when the time comes.
Some people might find this general case confusing, I suppose. But the following code also runs afoul of the "do not modify a hash inside of an each loop" prohibition, and I don't think anyone would find it confusing:
while (my $key = each %hash) {
delete $hash{$key} if is_bad($hash{$key});
}
Here we want to delete all the bad items from the hash. We do this by
scanning the hash and deleting the current item whenever it is bad.
Since each key is deleted only after it is scanned by each,
we should expect this to visit every key in the hash, as indeed it
does. And this appears to be a useful thing to write. The only
alternative is to make two passes, constructing a list of bad keys on
the first pass, and deleting them on the second pass. The code would
be more complicated and the time and memory performance would be much
worse.There is a potential implementation problem, though. The way that each() works is to take the current item and follow a "next" pointer from it to find the next item. (I am omitting some unimportant details here.) But if we have deleted the current item, the implementation cannot follow the "next" pointer. So what happens?
In fact, the implementation has always contained a bunch of code, written by Larry Wall, to ensure that deleting the current key will work properly, and that it will not spoil the each(). This is nontrivial. When you delete an item, the delete() operator looks to see if it is the current item of an each() loop, and if so, it marks the item with a special flag instead of deleting it. Later on, the next time each() is invoked, it sees the flag and deletes the item after following the "next" pointer.
So the implementation takes some pains to make this work. But someone came along later and forbade all modifications of a hash inside an each loop, throwing the baby out with the bathwater. Larry and perl paid a price for this feature, in performance and memory and code size, and I think it was a feature well bought. But then someone patched the manual and spoiled the value of the feature. (Some years later, I patched the manual again to add an exception for this case. Score!)
Perl: modifying an array in a loop
Another example is the question of what happens when you modify an array inside a loop over the array, as with:
@a = (1..3);
for (@a) {
print;
push @a, $_ + 3 if $_ % 2 == 1;
}
(This prints 12346.) The internals are simple, and the semantics are
well-defined by the implementation, and straightforward, but the
manual has the heebie-jeebies about it, and most of the Perl community
is extremely superstitious about this, claiming that it is "entirely
unpredictable". I would like to support this with a quotation from
the manual, but I can't find it in the enormous and disorganized mass
that is the Perl documentation.[ Addendum: Tom Boutell found it. The perlsyn page says "If any part of LIST is an array, foreach will get very confused if you add or remove elements within the loop body, for example with splice. So don't do that." ]
The behavior, for the record, is quite straightforward: On the first iteration, the loop processes the first element in the array. On the second iteration, the loop processes the second element in the array, whatever that element is at the time the second iteration starts, whether or not that was the second element before. On the third iteration, the loop processes the third element in the array, whatever it is at that moment. And so the loop continues, terminating the first time it is called upon to process an element that is past the end of the array. We might imagine the following pseudocode:
index = 0;
while (index < array.length()) {
process element array[index];
index += 1;
}
There is nothing subtle or difficult about this, and claims that the
behavior is "entirely unpredictable" are probably superstitious
confessions of ignorance and fear.Let's try to predict the "entirely unpredictable" behavior of the example above:
@a = (1..3);
for (@a) {
print;
push @a, $_ + 3 if $_ % 2 == 1;
}
Initially the array contains (1, 2, 3), and so the first iteration
processes the first element, which is 1. This prints 1, and, since 1
is odd, pushes 4 onto the end of the array.The array now contains (1, 2, 3, 4), and the loop processes the second element, which is 2. 2 is printed. The loop then processes the third element, printing 3 and pushing 6 onto the end. The array now contains (1, 2, 3, 4, 6).
On the fourth iteration, the fourth element (4) is printed, and on the fifth iteration, the fifth element (6) is printed. That is the last element, so the loop is finished. What was so hard about that?
Haskell: n+k patterns
My blog was recently inserted into the feed for planet.haskell.org, and of course I immediately started my first streak of posting code-heavy articles about C and Perl. This is distressing not just because the articles were off-topic for Planet Haskell—I wouldn't give the matter two thoughts if I were posting my usual mix of abstract math and stuff—but it's so off-topic that it feels weird to see it sitting there on the front page of Planet Haskell. So I thought I'd make an effort to talk about Haskell, as a friendly attempt to promote good relations between tribes. I'm not sure what tribe I'm in, actually, but what the heck. I thought about Haskell a bit, and a Haskell example came to mind.Here is a definition of the factorial function in Haskell:
fact 0 = 1
fact n = n * fact (n-1)
I don't need to explain this to anyone, right?Okay, now here is another definition:
fact 0 = 1
fact (n+1) = (n+1) * fact n
Also fine, and indeed this is legal Haskell. The pattern n+1
is allowed to match an integer that is at least 1, say 7, and doing so binds n to
the value 6. This is by a rather peculiar special case in the
specification of Haskell's pattern-matcher. (It is section 3.17.2#8
of Haskell 98 Language and Libraries: The Revised
Report, should you want to look it up.) This peculiar
special case is known sometimes as a "successor pattern" but more
often as an "n+k pattern".The spec explicitly deprecates this feature:
Many people feel that n+k patterns should not be used. These patterns may be removed or changed in future versions of Haskell.
(Page 33.) One wonders why they put it in at all, if they were going to go ahead and tell you not to use it. The Haskell committee is usually smarter than this.
 I have a vague recollection that there was an argument between people
who wanted to use Haskell as a language for teaching undergraduate
programming, and those who didn't care about that, and that this was
the compromise result. Like many compromises, it is inferior to both
of the alternatives that it interpolates between. Putting the feature
in complicates the syntax and the semantics of the language, disrupts
its conceptual purity, and bloats the
spec—see the Perlesque yikkity-yak on pages 57–58 about
how x + 1 = ... binds a meaning to +, but (x +
1) = ... binds a meaning to x. Such complication is
worth while only if there is a corresponding payoff in terms of
increased functionality and usability in the language. In this case,
the payoff is a feature that can only be used in one-off programs.
Serious programs must avoid it, since the patterns "may be removed or
changed in future versions of Haskell". The Haskell committee
purchased this feature at a certain cost, and it is debatable whether
they got their money's worth. I'm not sure which side of that issue I
fall on. But having purchased the feature, the committee then threw
it in the garbage, squandering their sunk costs. Oh well. Not even
the Haskell committee is perfect.
I have a vague recollection that there was an argument between people
who wanted to use Haskell as a language for teaching undergraduate
programming, and those who didn't care about that, and that this was
the compromise result. Like many compromises, it is inferior to both
of the alternatives that it interpolates between. Putting the feature
in complicates the syntax and the semantics of the language, disrupts
its conceptual purity, and bloats the
spec—see the Perlesque yikkity-yak on pages 57–58 about
how x + 1 = ... binds a meaning to +, but (x +
1) = ... binds a meaning to x. Such complication is
worth while only if there is a corresponding payoff in terms of
increased functionality and usability in the language. In this case,
the payoff is a feature that can only be used in one-off programs.
Serious programs must avoid it, since the patterns "may be removed or
changed in future versions of Haskell". The Haskell committee
purchased this feature at a certain cost, and it is debatable whether
they got their money's worth. I'm not sure which side of that issue I
fall on. But having purchased the feature, the committee then threw
it in the garbage, squandering their sunk costs. Oh well. Not even
the Haskell committee is perfect.
I think it might be worth pointing out that the version of the program with the n+k pattern is technically superior to the other version. Given a negative integer argument, the first version recurses forever, possibly taking a long time to fail and perhaps taking out the rest of the system on which it is running. But the n+k version fails immediately, because the n+1 pattern will only match an integer that is at least 1.
XML screws up
The "nasal demons" of the C standard are a joke, but a serious one. The C standard defines what C compilers must do when presented with C programs; it does not define what they do when presented with other inputs, nor what other software does when presented with C programs. The authors of C standard clearly understood the standard's role in the world.Earlier versions of the XML standard were less clear. There was a particularly laughable clause in the first edition of the XML 1,0 standard:
XML documents may, and should, begin with an XML declaration which specifies the version of XML being used. For example, the following is a complete XML document, well-formed but not valid:
<?xml version="1.0"?> <greeting>Hello, world!</greeting>...
The version number "1.0" should be used to indicate conformance to this version of this specification; it is an error for a document to use the value "1.0" if it does not conform to this version of this specification.
(Emphasis is mine.) The XML 1.0 spec is just a document. It has no power, except to declare that certain files are XML 1.0 and certain files are not. A file that complies with the requirements of the spec is XML 1.0; all other files are not XML 1.0. But in the emphasized clause, the spec says that certain behavior "is an error" if it is exhibited by documents that do not conform to the spec. That is, it is declaring certain non-XML-1.0 documents "erroneous". But within the meaning of the spec, "erroneous" simply means that the documents are not XML 1.0. So the clause is completely redundant. Documents that do not conform to the spec are erroneous by definition, whether or not they use the value "1.0".
It's as if the Catholic Church issued an edict forbidding all rabbis from wearing cassocks, on pain of excommunication.
I am happy to discover that this dumb error has been removed from the most recent edition of the XML 1.0 spec.
[Other articles in category /prog/perl] permanent link
Sun, 14 Oct 2007
Van der Waerden's problem: programs 3 and 4
In this series of articles I'm analyzing five versions of a
program that I wrote around 1988, and then another program that does
the same thing that I wrote last month without referring to the 1988
code. (I said before that it was four versions, but apparently I'm not so
good at counting to five.)
If you don't remember what the program does, here's an explanation.
Here is program 1, which was an earlier attempt to do the same thing. Here's program 2.
Program 3
Complete source code for this version.I said of the previous program:
The problem is all in the implementation. You see, this program actually constructs the entire tree in memory.Somewhere along the line it dawned on me that constructing the tree was unnecessary, so I took that machinery out, and the result was version 3.
Consequently, this program is easy to explain once you have seen the previous version: almost all I have to do is list the stuff that I took out.
Since this program does not construct a tree of node structures, it omits the definition of the node structure and the macro for manufacturing nodes. Since it gets rid of the node allocation, it also gets rid of the memory leak of the previous version, and so omits the customized memory allocation functions Malloc and Free that performed memory tracking.
The previous program had a compiled-in limit on the number of colors it would handle, because at the time I didn't know how to do a dynamic array. In this program, I got rid of the node structures, so there was no array of node structures, so no need for a limit on the number of node structures in the array. And all the code that enforced the limit is gone.
The apchk function, which checks to see if a string is good, remains unchanged from the previous version.
The makenodes function, which was the principal function in the previous program, remains, but has lost a lot of code. It is simpler to call, too; the node argument is gone:
makenodes(maxlen,"");
I got rid of the silly !howfar test in favor of a more
easily-understood howfar == 0 test. There are lots of times
when ! is appropriate, but testing whether a non-negative
integer has reached zero is not one of them. I was going to comment
earlier about what a novice error this is, and I'm glad to see that I
fixed it.The main use of apchk in the previous program had if (!apchk(...)) { ... }. That was okay, because apchk returns a Boolean result. But the negation is annoying. It suggests that apchk's return value is backward. (Instead of returning true for a bad string, it should return true for a good string.) This is not very much a big deal, and I only brought it up so that I could diffidently confess that these days I would probably have done:
#define unless(c) if(!(c))
...
unless (is_bad(...)) {
}
There are a lot of stories of doofus Pascal programmers who do:
#define begin {
#define end }
and Fortran programmers who do:
#define GT >
#define GE >=
#define LT <
#define LE <=
and I find, to my shame, that I have become one of them. Anyone
seeing #define unless(c) if(!(c)) would snort and say "Oh,
this was obviously written by a Perl programmer."But at least I was a C programmer first.
Actually I was a Fortran programmer first. But I was never a big enough doofus to #define GE >=.
The big flaw in the current program is the string argument to makenodes. Each call to makenodes copies this string so that it can append a character to the end. I discussed this at some length in the previous article, so I don't want to make too much of it now; I'll just say that a better technique would have reused the string buffer from call to call. This obviously saves a little memory, and since most of the contents of the string doesn't change, it also saves a lot of time.
This might be worth seeing, since it seems to me now to be a marvel of wasted code:
ls = strlen(s);
newarg = STRING(ls + 1);
if (!newarg)
{
fprintf(stderr,"Couldn't get %d bytes for newarg in makenodes\n",ls+2);
fprintf(stderr,"Total get was %d.\n",gotten);
fprintf(stderr,"P\n L\n O\n P\n !\n");
abort();
}
strcpy(newarg,s);
newarg[ls+1] = '\0';
newarg[ls] = 'A' + i;
makenodes(howfar-1,newarg);
free(newarg);
The repeated strlen, for example, when ls could be
calculated as maxlen - howfar. The excessively verbose
failure message, which should be inside the STRING macro
anyway. (The code that maintains gotten has gone away with
the debugging allocation routines, so the second fprintf is
superfluous.) And why did I think abort was the right
thing to call on an out-of-memory condition?Oh well, you live and learn.
Program 4
Complete source code for this version.The fourth version of the program is even more trimmed-down. In this version of the program I did get the idea to reuse the string buffer instead of copying the string on every recursive call. But I also got an even better idea, and eliminated the recursive call. The makenodes function is now down to one argument, which tells it how deep a tree to search.
void
makenodes(maxdepth)
int maxdepth;
{
int apchk(), depth = 0;
char curlet, *curstring = STRING(maxdepth);
curstring[0] = '\0';
curlet = 'A';
while (depth >= 0)
{
while (curlet <= 'A' - 1 + colors)
{
#ifdef DIAG
printf("%s makenoding with string %s%c, depth %d.\n",
TABS+12-depth,curstring,curlet,depth);
#endif
if (apchk(curstring,curlet))
curlet++;
else
if (depth < maxdepth)
{
curstring[depth] = curlet;
curstring[depth+1] = '\0';
depth += 1;
curlet = 'A';
}
else
{
printf("%s%c\n",curstring,curlet);
curlet++;
}
}
depth -= 1;
curlet = curstring[depth] + 1;
curstring[depth] = '\0';
}
}
This is a better job all around, and not very different from what I
wrote last month to do the same thing. I was going to title this
series of articles "I have become a better programmer!", and now that
I see this version, I'm glad I didn't, because there's no evidence
here that I am much better. This version of the program gets a solid
A from my older self.The value depth scans forward in the string when the search is going well, and is decremented again when the search needs to backtrack. If depth == maxdepth, a witness of the desired length has been found, and is printed out.
The curlet ("current letter") variable tracks which branch of the current tree node we are "recursing" down. After the function recurses down, by incrementing depth, curlet is set to 'A' to visit the first sub-node of the new current node. The curstring buffer tracks the path through the tree to the current node. When the function needs to backtrack, it restores the state of curlet from the last character in the buffer and then trims that character off the end of the path.
I'd only want to make two changes to this code. One would be to make depth a pointer into the curstring buffer instead of an index into it. Then again, the compiler may well have optimized it into one anyway. But it would also allow me to eliminate curlet in favor of just using *depth everywhere.
The other change would address a more serious defect: the contents of curstring are kept properly zero-terminated at all times, whenever depth is advanced or retracted. This zero-termination is unnecessary, since curstring is never used as a string except when depth == maxdepth. When printfing curstring, I could have used something like:
printf("%.*s%c\n",curstring,maxlen,curlet);
which prints exactly maxlen characters from the buffer,
regardless of whether it is zero-terminated. It would, however, have required that I know about %.*s, which I'm sure I did not. Was %.*s even available in 1988? I forget, and my copy of K&R First Edition is in a box somewhere since my recent move. Anyway, if %.*s was unavailable for whatever reason, the code could have had a single curstring[maxdepth] = 0 up front, which would have been quite sufficient for the one printf it needed to do.
Coming next: one very different program to solve the same problem, and a comparison with last month's effort.
[Other articles in category /prog] permanent link
Fri, 05 Oct 2007
Van der Waerden's problem: program 2
In this series of articles I'm going to analyze four versions of a
program that I wrote around 1988, and then another program that does
the same thing that I wrote last month without referring to the 1988
code.
If you don't remember what the program does, here's an explanation.
Here is program 1, which was an earlier attempt to do the same thing.
Program 2
In yesterday's article I wrote about a crappy program to search for "good" strings in van der Waerden's problem. It was crappy because it searched the entire space of all 327 strings, with no pruning.I can't remember whether I expected this to be practical at the time. Did I really think it would work? Well, there was some sense to it. It does work just fine for the 29 case. I think probably my idea was to do the simplest thing that could possibly work, and get as much information out of it as I could. On my current machine, this method proves that V(3,3) > 19 by finding a witness (RRBRRBBYYRRBRRBBYYB) in under 10 seconds. If we estimate that the computer I had then was 10,000 times slower, then I could have produced the same result in about 28 hours. I was at college, and there was plenty of free computing power available, so running a program for 28 hours was easily done. While I was waiting for it to finish, I could work on a better program.
Excerpts of the better program follow. The complete source code is here.
The idea behind this program is that the strings of length less than V form a tree, with the empty string as the root, and the children of string s are obtained from s by appending a single character to the end of s. If the string at a node is bad, so will be all the strings under it, and we can prune the entire branch at that node. This leaves us with a tree of all the good strings. The ones farthest from the root will be the witnesses we seek for the values of V(n, C), and we can find these by doing depth-first search on the tree,
There is nothing wrong with this idea in principle; that's the way my current program works too. The problem is all in the implementation. You see, this program actually constructs the entire tree in memory:
#define NEWN ((struct tree *) Malloc(sizeof(struct tree)));\
printf("*")
struct tree {
char bad;
struct tree *away[MAXCOLORS];
} *root;
struct tree is a tree node structure. It represents a
string s, and has a flag to record whether s is bad. It
also has pointers to its subnodes, which will represents strings
sA,
sB,
and so on.MAXCOLORS is a compiled-in limit on the number of different symbols the strings can contain, an upper bound on C. Apparently I didn't know the standard technique for avoiding this inflexibility. You declare the array as having length 1, but then when you allocate the structure, you allocate enough space for the array you are actually planning to use. Even though the declared size of the array is 1, you are allowed to refer to node->away[37] as long as there is actually enough space in the allocated chunk. The implementation would look like this:
struct tree {
char bad;
struct tree *away[1];
} ;
struct tree *make_tree_node(char bad, unsigned n_subnodes)
{
struct tree *t;
unsigned i;
t = malloc(sizeof(struct tree)
+ (n_subnodes-1) * sizeof(struct tree *));
if (t == NULL) return NULL;
t->bad = bad;
for (i=0; i < n_subnodes; i++) t->away[i] = NULL;
return t;
}
(Note for those who are not advanced C programmers: I give you my
solemn word of honor that I am not doing anything dodgy or bizarre
here; it is a standard, widely-used, supported technique, guaranteed
to work everywhere.)(As before, this code is in a pink box to indicate that it is not actually part of the program I am discussing.)
Another thing I notice is that the NEWN macro is very weird. Note that it may not work as expected in a context like this:
for(i=0; i<10; i++)
s[i] = NEWN;
This allocates ten nodes but prints only one star, because it expands
to:
for(i=0; i<10; i++)
s[i] = ((struct tree *) Malloc(sizeof(struct tree)));
printf("*");
and the for loop does not control the printf. The
usual fix for multiline macros like this is to wrap them in
do...while(0), but that is not appropriate here.
Had I been writing this today, I would have made NEWN a
function, not a macro. Clevermacroitis is a common disorder of
beginning C programmers, and I was no exception.The main business of the program is in the makenodes function; the main routine does some argument processing and then calls makenodes. The arguments to the makenodes function are the current tree node, the current string that that node represents, and an integer howfar that says how deep a tree to construct under the current node.
There's a base case, for when nothing needs to be constructed:
if (!howfar)
{
for (i=0; i<colors; i++)
n->away[i] = NULL;
return;
}
But in general the function calls itself recursively:
for (i=0; i<colors; i++)
{
n->away[i] = NEWN;
n->away[i]->bad = 0;
if (apchk(s,'A'+i))
{
n->away[i]->bad = 1;
}
else
...
Recall that apchk checks a string for an arithmetic
progression of equal characters. That is, it checks to see if a
string is good or bad. If the string is bad, the function prunes the
tree at the current node, and doesn't recurse further.Unlike the one in the previous program, this apchk doesn't bother checking all the possible arithmetic progressions. It only checks the new ones: that is, the ones involving the last character. That's why it has two arguments. One is the old string s and the other is the new symbol that we want to append to s.
If s would still be good with symbol 'A'+i appended to the end, the function recurses:
...
else
{
ls = strlen(s);
newarg = STRING(ls + 1);
strcpy(newarg,s);
newarg[ls+1] = '\0';
newarg[ls] = 'A' + i;
makenodes(n->away[i],howfar-1,newarg);
Free(newarg,ls+2);
Free(n->away[i],sizeof(struct tree));
}
}
}
The entire string is copied here into a new buffer. A better
technique sould have been to allocate a single buffer back up in
main, and to reuse that buffer over again on each call to
makenodes. It would have looked something like this:
char *s = String(maxlen);
memset(s, 0, maxlen+1);
makenodes(s, s, maxlen);
void
makenodes(char *start, char *end, unsigned howfar)
{
...
for (i=0; i<colors; i++) {
*end = 'A' + i;
makenodes(start, end+1, howfar-1);
}
*end = '\0';
...
}
This would have saved a lot of consing, ahem, I mean a lot of
mallocing. Also a lot of string copying. We could avoid the
end pointer by using start+maxlen-howfar instead,
but this way is easier to understand.I was thinking this afternoon how it's intersting the way I wrote this. It's written the way it would have been done, had I been using a functional programming language. In a functional language, you would never mutate the same string for each function call; you always copy the old structure and construct a new one, just as I did in this program. This is why C programmers abominate functional languages.
Had I been writing makenodes today, I would probably have eliminated the other argument. Instead of passing it a node and having it fill in the children, I would have had it construct and return a complete node. The recursive call would then have looked like this:
struct tree *new = NEWN;
...
for (i=0; i<colors; i++) {
new->away[i] = makenodes(...);
...
}
return new;
One thing I left out of all this was the diagnostic printfs;
you can see them in the complete code if you want. But there's one I
thought was worth mentioning anyway:
#define TABS " "
....
#ifdef DIAG
printf("%s makenoding with string %s, depth %d.\n",
TABS+12-maxlen+howfar,s,maxlen-howfar);
#endif
The interesting thing here is the
TABS+12-maxlen+howfar
argument, which indents the display depending on how far the recursion
has progressed. In Perl, which has nonaddressable strings, I usually
do something like this:
my $TABS = " " x (maxlen - howfar);
print $TABS, "....";
The TABS trick here is pretty clever, and I'm a bit surprised
that I thought of it in 1988, when I had been programming in C for
only about a year. It makes an interesting contrast to my failure to
reuse the string buffer in makenodes earlier.(Peeking ahead, I see that in the next version of the program, I did reuse the string buffer in this way.)
TABS is actually forty spaces, not tabs. I suspect I used tabs when I tested it with V(2, 3), where maxlen was only 9, and then changed it to spaces for calculating V(3, 3), where maxlen was 27.
The apchk function checks to see if a string is good. Actually it gets a string, qq, and a character, q, and checks to see if the concatenation of qq and q would be good. This reduces its running time to O(|qq|) rather than O(|qq|2).
int
apchk(qq,q)
char *qq ,q;
{
int lqq, f, s, t;
t = lqq = strlen(qq);
if (lqq < 2) return NO;
for (f=lqq % 2; f <= lqq - 2; f += 2)
{
s = (f + t) / 2;
if ((qq[f] == qq[s]) && (qq[s] == q))
return YES;
}
return NO;
}
It's funny that it didn't occur to me to include an extra parameter to
avoid the strlen, or to use q instead of
qq[s] in the first == test. Also, as in the previous
program, I seem unaware of the relative precedences of
&& and ==. This is probably a hangover from
my experience with Pascal, where the parentheses are required.It seems I hadn't learned yet that predicate functions like apchk should be named something like is_bad, so that you can understand code like if (is_bad(s)) { ... } without having to study the code of is_bad to figure out what it returns.
I was going to write that I hated this function, and that I could do it a lot better now. But then I tried to replace it, and wasn't as successful as I expected I would be. My replacement was:
unsigned
is_bad(char *qq, int q)
{
size_t qql = strlen(qq);
char *f = qq + qql%2;
char *s = f + qql/2;
while (f < s) {
if (*f == q && *s == q) return 1;
f += 2; s += 1;
}
return 0;
}
I could simplify the initializations of f and s,
which are the parts I dislike most here, by making the pointers move
backward instead of forward, but then the termination test becomes
more complicated:
unsigned
is_bad(char *qq, int q)
{
char *s = strchr(qq, '\0')-1;
char *f = s-1;
while (1) {
if (*f == q && *s == q) return 1;
if (f - qq < 2) break;
f -= 2; s -= 1;
}
return 0;
}
Anyway, I thought I could improve it, but I'm not sure I did. On the
one hand, I like the
f -= 2; s -= 1;, which I think is pretty clear. On the other
hand, s = (f + t) / 2 is pretty clear too; s is
midway between f and t. I'm willing to give
teenage Dominus a passing grade on this one.Someone probably wants to replace the while loop here with a for loop. That person is not me.
The Malloc and Free functions track memory usage and were presumably introduced when I discovered that my program used up way too much memory and crashed—I think I remember that the original version omitted the calls to free. They aren't particularly noteworthy, except perhaps for this bit, in Malloc:
if (p == NULL)
{
fprintf(stderr,"Couldn't get %d bytes.\n",c);
fprintf(stderr,"Total get was %d.\n",gotten);
fprintf(stderr,"P\n L\n O\n P\n !\n");
abort();
}
Plop!It strikes me as odd that I was using void in 1988 (this is before the C90 standard) but still K&R-style function declarations. I don't know what to make of that.
Behavior
This program works, almost. On my current machine, it can find the length-26 witnesses for V(3, 3) in no time. (In 1998, it took several days to run on a Sequent Balance 21000.) The major problem is that it gobbles memory: the if (!howfar) base case in makenodes forgets to release the memory that was allocated for the new node. I wonder if the Malloc and Free functions were written in an unsuccessful attempt to track this down.Sometime after I wrote this program, while I was waiting for it to complete, it occurred to me that it never actually used the tree for anything, and I could take it out.
I have this idea that one of the principal symptoms of novice programmers is that they take the data structures too literally, and always want to represent data the way it will appear when it's printed out. I haven't developed the idea well enough to write an article about it, but I hope it will show up here sometime in the next three years. This program, which constructs an entirely unnecessary tree structure, may be one of the examples of this idea.
I'll show the third version sometime in the next few days, I hope.
[ Addendum 20071014: Here is part 3. ]
[Other articles in category /prog] permanent link
Thu, 04 Oct 2007
The world's worst macro preprocessor: postmortem
I see that the world's worst macro processor, subject of a previous
article, is a little over a year old. A year ago I said that it
was a huge success. I think it's time for a
postmortem analysis.
My overall assessment is that it has been a huge success, and that if I were doing it over I would do it the same way.
A recent article contained a bunch of red and blue dots:
Well, clearly you can do four: • • • •. And then you can add another red one on the end: • • • • •. And then another that could be either red or blue: • • • • • •. And then the next can be either color, say blue: • • • • • • •.I typed this using these macros:
#define R* <span style="color: red">•</span>
#define B* <span style="color: blue">•</span>
#define Y* <span style="color: yellow">•</span>
Without the macro processor, I would have had to suffer a lot. Then,
a little while later, I needed to prepare this display:
•••••••••••••••••••••••••• •••••••••••••••••••••••••• •••••••••••••••••••••••••• •••••••••••••••••••••••••• •••••••••••••••••••••••••• •••••••••••••••••••••••••• •••••••••••••••••••••••••• ••••••••••••••••••••••••••No problem; the lines just look like R*R*B*B*R*R*B*Y*B*Y*Y*R*Y*R*R*B*R*B*B*Y*R*Y*Y*B*Y*B*.
Some time later I realized that this display would be totally illegible to the blind, the color-blind, and people using text-only browsers. So I just changed the macros:
#define R* <span style="color: red">R</span>
#define B* <span style="color: blue">B</span>
#define Y* <span style="color: yellow">Y</span>
Problem solved. • • • • • • • instantly becomes
R R B B R B B. And a good thing, too, because I
discovered afterward that a lot of aggregators, like bloglines and
feedburner, discard the color information.I find that I've used the macro feature 114 times so far. The most common use has been:
#define ^2 <sup>2</sup>But I also have files with:
#define r2 √2
#define R2 √2
#define s2 √2
#define S2 √2
That last one appears in three files. Clearly, making the macros
local to files was a good decision.Those uses are pretty typical. A less typical one is:
#define <OVL> <span style="text-decoration: overline">
#define </OVL> </span>
This is the sort of thing that you can get away with on a one-time
basis, but which you wouldn't want to make a convention of. Since the
purpose of the macro processor is to enable such hacks for the
duration of a single article, it's all good.I did run into at least one problem: I was writing an article in which I had defined ^i to abbreviate <sup><i>i</i></sup>. And then several paragraphs later I had a TeX formula that contained the ^i sequence in its TeX meaning. This was being replaced with a bunch of HTML, which was then passed to TeX, which then produced the wrong output.
One can solve this by reordering the plugins. If I had put the TeX plugin before the macro plugin, the problem would have gone away, because the TeX plugin would have replaced the TeX formula with an image element before the macro plugin ever saw the ^i.
This approach has many drawbacks. One is that it would no longer have been possible to use Blosxom macros in a TeX formula. I wasn't willing to foreclose this possibility, and I also wasn't sure that I hadn't done it somewhere. If I had, the TeX formula that depended on the macro expansion would have broken. And this is a risk whenever you move the macro plugin: if you move it from before plugin X to after plugin X, you have to worry that maybe something in some article depended on the text passed to X having been macro-processed.
When I installed the macro processor, I placed it first in plugin order for precisely this reason. Moving the macro substitution later would have required me to remember which plugins would be affected by the macro substitutions and which not. With the macro processing first, the question has a simple answer: all of them are affected.
Also, I didn't ever want to have to worry that some macro definition might mangle the output of some plugin. What if you are hacking on some plugin, and you change it to return <span style="Foo"> instead of <span style="foo">, and then discover that three articles you wrote back in 1997 are now totally garbled because they contained #define Foo >WUGGA<? It's just too unpredictable. Having the macro processing occur first means that you can always see in the original article file just what might be macro-replaced.
So I didn't reorder the plugins.
Another way to solve the TeX ^i problem would have been to do something like this:
#define ^i <sup><i>i</i></sup>
#define ^*i ^i
with the idea that I could write ^*i in the TeX formula, and
the macro processor would replace it with ^i after it
was done replacing all the ^i's. At present the macro processor does not define any order to macro replacements, but it does guarantee to replace each string only once. That is, the results of macro replacement are not themselves searched for macro replacement. This limits the power of the macro system, but I think that is a good thing. One of the powers that is thus proscribed is the power to get stuck in an infinite loop.
It occurs to me now that although I call it the world's worst macro system, perhaps that doesn't give me enough credit for doing good design that might not have been obvious. I had forgotten about my choice of single-substituion behavior, but looking back on it a year later, I feel pleased with myself for it, and imagine that a lot of people would have made the wrong choice instead.
(A brief digression: unlimited, repeated substitution is a bad move here because it is complex—much more complex than it appears. A macro system with single substitution is nothing much, but a macro system with repeated substitution is a programming language. The semantics of the λ-calculus is nothing more than simple substitution, repeated as necessary, and the λ-calculus is a maximally complex computational engine. Term-rewriting systems are a more obvious theoretical example, and TeX is a better-known practical example of this phenomenon. I was sure I did not want my macro system to be a programming language, so I avoided repeated substitution.)
Because each input text is substituted at most once, the processor's refusal to define the order of the replacements is not something you have to think about, as long as your macros are prefix-unique. (That is, as long as none is a prefix of another.) So you shouldn't define:
#define foo bar #define fool idiotbecause then you don't know if foolish turns into barlish or idiotish. This is not a big deal in practice.
Well, anyway, I did not solve the problem with #define ^*i ^i. I took a much worse solution, which was to hack a #undefall directive into the macro processor. In my original article, I boasted that the macro processor "has exactly one feature". Now it has two, and it's not an improvement. I disliked the new feature at the time, and now that I'm reviewing the decision, I think I'm going to take it out.
I see that I did use the double-macro solution elsewhere. In the article about Gödel and the U.S. Constitution, I macroed an abbreviation for the umlaut:
#define Godel Gödel
But this sequence also ocurred in the URLs in the link elements, and
the substitution broke the links. I should probably have changed this
to:
#define Go:del Gödel
But instead I added:
#define GODEL Godel
and then used GODEL in the URLs. Oh well, whatever works, I
guess.Perhaps my favorite use so far is in an (unfinished) article about prosopagnosia. I got tired of writing about prosopagnosia and prosopagnosiacs, so
#define PAa prosopagnosia
#define PAic prosopagnosiac
Note that with these definitions, I get PAa's,
and PAics for free. I could use PAac instead of defining
PAic, but that would prevent me from deciding later that
prosopagnosiac should be spelled "prosopagnosic".
[Other articles in category /prog] permanent link
Wed, 03 Oct 2007
Van der Waerden's problem: program 1
In this series of articles I'm going to analyze four versions of a
program that I wrote around 1988, and then another program that does
the same thing that I wrote last month without referring to the 1988
code.
If you don't remember what the program does, here's an explanation.
Program 1
I'm going to discuss the program a bit at a time. The complete program is here.This program does an unpruned exhaustive search of the string space. Since for V(3, 3) the string space contains 327 = 7,625,597,484,987 strings, it takes a pretty long time to finish. I quickly realized that I was wasting my time with this program.
The program is invoked with a length argument and an optional colors argument, which defaults to 2. It then looks for good strings of the specified length, printing those it finds. If there are none, one then knows that V(3, colors) > length. Otherwise, one knows that V(3, colors) ≤ length, and has witness strings to prove it.
I don't want to spend a lot of time on it because there are plenty of C programming style guides you can read if you care for that. But already on lines 4–5 we have something I wouldn't write today:
#define NO 0
#define YES !NO
Oh well.The program wants to iterate through all Cn strings. How does it know when it's done? It's not easy to make a program as slow as this one even slower, but I found a way to do it.
last = STRING(length);
stuff(last,'A' - 1 + colors);
for (i=0; i<colors; i++)
last[i] = 'A' + i;
for (; strcmp(seq,last); strinc(seq))
...
It manufactures the string ABCDDDDDDDDD....D and compares the
current string to that one every time through the loop. A much simpler
method is to detect completion while incrementing the target string.
The function that does the increment looks like this:
void
strinc(s)
char *s;
{
int i;
for (i= length - 1; i>=0; i--)
{
if (s[i] != 'A' - 1 + colors)
{
s[i]++;
return;
}
s[i] = 'A';
}
return;
}
Had I been writing it today, it would have looked more like this:
unsigned strinc(char *s)
{
char *p = strchr(s, '\0') - 1;
while (p >= s && *p == 'A' + colors - 1) *p-- = 'A';
if (p < s) return 0;
(*p)++;
return 1;
}
(This code is in a pink box to show that it is not actually part of
the program I am discussing in this article.)The function returns true on success and false on failure. A false return can be taken by the caller as the signal to terminate the program.
This replacement function invokes undefined behavior, because there is no guarantee that p is allowed to run off the beginning of the string in the way that it does. But there is no need to check the strings in lexicographic order. Instead of scanning the strings in the order AAA, AAB, ABA, ABB, BAA, etc., one can scan them in reverse lexicographic order: AAA, BAA, ABA, BBA, AAB, etc. Then instead of running off the beginning of the string, p runs off the end, which is allowed. This fixes the undefined behavior problem and also eliminates the call to strchr that finds the end of the string. This is likely to produce a significant speedup:
unsigned strinc(char *s)
{
while (*s == 'A' + colors - 1) *s++ = 'A';
if (!*s) return 0;
(*s)++;
return 1;
}
Here we're depending on the optimizer to avoid recomputing the value
of 'A' + colors - 1 every time through the loop.The heart of the program is the apchk() function, which checks whether a string q contains an arithmetic progression of length 3:
int
apchk(q)
char *q;
{
int f, s, t;
for (f=0; f <= length - 3; f++)
for (s=f+1; s <= length - 2; s++)
{
t = s+s-f;
if (t >= length) break;
if ((q[f] == q[s]) && (q[s] == q[t])) return YES;
}
return NO;
}
I hesitate to say that this is the biggest waste of time in the whole
program, since after all it is a program whose job is to examine
7,625,597,484,987 strings. But look. 2/3 of the
calls to this function are asking it to check a string that differs
from the previous string in the final character only. Nevertheless,
it still checks all 49 possible arithmetic progressions, even the ones
that didn't change.The t ≥ length test is superfluous, or if it isn't, it should be.
Also notice that I wasn't sure of the precendence in the final test.
It didn't take me long to figure out that this program was not going to finish in time. I wrote a series of others, which I hope to post here in coming days. The next one sucks too, but in a completely different way.
[ Addendum 20071005: Here is part 2. ]
[ Addendum 20071014: Here is part 3. ]
[Other articles in category /prog] permanent link
Tue, 02 Oct 2007
Van der Waerden's problem
In this series of articles I'm going to analyze four versions of a
program that I wrote around 1988, and then another program that does
the same thing that I wrote last month without referring to the 1988
code.
First I'll explain what the programs are about.
Van der Waerden's problem
Color each of a row of dots red or blue, so that no three evenly-spaced dots are the same color. (That is, if dots n and n+i are the same color, dot n+2i must be a different color.) How many dots can you do?Well, clearly you can do four: R R B B. And then you can add another red one on the end: R R B B R. And then another that could be either red or blue: R R B B R B. And then the next can be either color, say blue: R R B B R B B.
But now you are at the end, because if you make the next dot red, then dots 2, 5, and 8 will all be red (R R B B R B B R), and if you make the next dot blue then dots 6, 7, and 8 will be blue (R R B B R B B B).
But maybe we made a mistake somewhere earlier, and if the first seven dots were colored differently, we could have made a row of more than 7 that obeyed the no-three-evenly-spaced-dots requirement. In fact, this is so: R R B B R R B B is an example.
But this is the end of the line. Any coloring of a row of 9 dots contains three evenly-spaced dots of the same color. (I don't know a good way to prove this, short of an enumeration of all 512 possible arrangements of dots. Well, of course it is sufficient to enumerate the 256 that begin with R, but that is pretty much the same thing.)
[Addendum 20141208: In this post I give a simple argument that !!V(3,2)\le 9!!.]
Van der Waerden's theorem says that for any number of colors, say C, a sufficiently-long row of colored dots will contain n evenly-spaced same-color dots for any n. Or, put another way, if you partition the integers into C disjoint classes, at least one class will contain arbitrarily long arithmetic progressions.The proof of van der Waerden's theorem works by taking C and n and producing a number V such that a row of V dots, colored with C colors, is guaranteed to contain n evenly-spaced dots of a single color. The smallest such V is denoted V(n, C). For example V(3, 2) is 9, because any row of 9 dots of 2 colors is guaranteed to contain 3 evenly-spaced dots of the same color, but this is not true of such row of only 8 dots.
Van der Waerden's theorem does not tell you what V(n, C) actually is; it provides only an upper bound. And here's the funny thing about van der Waerden's theorem: the upper bound is incredibly bad.
For V(3, 2), the theorem tells you only that V(3, 2) ≤ 325. That is, it tells you that any row of 325 red and blue dots must contain three evenly spaced dots of the same color. This is true, but oh, so sloppy, since the same is true of any row of 9 dots.
For V(3, 3), the question is how many red, yellow, and blue dots do you need to guarantee three evenly-spaced same-colored dots. The theorem helpfully suggests that:
$$V(3,3) \leq 7(2\cdot3^7+1)(2\cdot3^{7(2\cdot3^7+1)}+1)$$
This is approximately 5.79·1014613. But what is the actual value of V(3, 3)? It's 27. Urgggh.In fact, there is a rather large cash prize available to be won by the first person who comes up with a general upper bound for V(n, C) that is smaller than a tower of 2's of height n. (That's 222... with n 2's.)
In the rest of this series, a string which does not contain three evenly-spaced equal symbols will be called good, and one which does contain three such symbols will be called bad. Then a special case of Van der Waerden's theorem, with n=3, says that, for any fixed number of symbols, all sufficiently long strings are bad.
In college I wanted to investigate this a little more. In particular, I wanted to calculate V(3, 3). These days you can just look it up on Wikipedia, but in those benighted times such information was hard to come by. I also wanted to construct the longest possible good strings, witnesses of length V(3, 3)-1. Although I did not know it at the time, V(3, 3) = 27, so a witness should have length 26. It turns out that there are exactly 48 witnesses of length 26. Here are the 1/6 of them that begin with RB or RRB:
RRBBRRBYBYYRYRRBRBBYRYYBYB RRBBYRRYRYBBYYBBYRYRRYBBRR RRBYBRRYRYBBYYBBYRYRRBYBRR RBRRBRBYYBBYYBRBRRBYYRRYRY RBRBBRRYBBYBYRRYYRRYBYBBYR RBRBBRRYBBYBYRRYYRRYBYBBYB RBRBBYBRRYRYYBYBBRBRYYRRYY RBYYBYBRRBBRRBYBYYBRRYYRYR
The rest of the witnesses may be obtained by permuting the colors in these eight.
I wrote a series of C programs around 1988 to exhaustively search for good strings. Last month I was in a meeting and I decided to write the program again for some reason. I wrote a much better program. This series of articles will compare the five programs. I will post the first one tomorrow.
[ Addendum 20071003: Here is part 1. ]
[ Addendum 20071005: Here is part 2. ]
[ Addendum 20071005: I made a mistake in the expression I gave for the upper bound on V(3,3) and left out a factor of 7 in the exponent on the last 3. I had said that the upper bound was around 102092, but actually it is more like the seventh power of this. ]
[ Addendum 20071014: Here is part 3. ]
[Other articles in category /prog] permanent link
Sat, 28 Jul 2007
Lightweight Database Strategies for Perl
Several years ago I got what I thought was a great idea for a
three-hour conference tutorial: lightweight data storage techniques.
When you don't have enough data to be bothered using a
high-performance database, or when your data is simple enough that you
don't want to bother with a relational database, you stick it in a
flat file and hack up some file code to read it. This is the sort of
thing that people do all the time in Perl, and I thought it
would be a big seller. I was wrong.
I don't know why. I tried giving the class a snappier title, but that didn't help. I'm really bad at titles. Maybe people are embarrassed to think about all the lightweight data storage hackery they do in Perl, and feel that they "should" be using a relational database, and don't want to commit more resources to lightweight database techniques. Or maybe they just don't think there is very much to know about it.
But there is a lot to know; with a little bit of technique you can postpone the day when you need to go to an RDB, often for quite a long time, and often forever. Many of the techniques fall into the why-didn't-I-think-of-that category, stuff that isn't too weird to write or maintain, but that you might not have thought to try.
I think it's a good class, but since it never sold well, I've decided it would do more good (for me and for everyone else) if I just gave away the materials for free.
Table of Contents
The class is in three sections. The first section is about using plain text files and talks about a bunch of useful techniques, such as how to do binary search on sorted text files (this is nontrivial) and how to replace records in-place, when they might not fit.The second section is about the Tie::File module, which associates a flat text file with a Perl array.
The third section is about DBM files, with a comparison of the five major implementations. It finishes up with a discussion of some of Berkeley DB's lesser-known useful features, such as its DB_BTREE file type, which offers fast access like a hash but keeps the records in sorted order
- Text Files
- Rotating log file; deleting a user
- Copy the File
- -i.bak
- Using -i inside a program
- Problems with -i
- Atomicity issues
- Essential problem with files; fundamental operations; seeking
- Sorted files
- In-place modification of records
- Overwriting records
- Bytes vs. positions
- Gappy Files
- Fixed-length records
- Numeric indices
- Case study: lastlog
- Indexing
- Void fields
- Generic text indices
- Packed offsets
- Tie::File
- Tie::File Examples
- delete_user revisited
- uppercase_username revisited
- Rotating log file revisited
- Most important thing to know about Tie::File
- Indexing with Tie::File
- Tie::File Internals
- Caching
- Record modification
- Immediate vs. Deferred Writing
- Autodeferring
- Miscellaneous Features
- DBM
- Common DBM Implementations
- What DBM Does
- Small DBMs: ODBM, NDBM, and SDBM
- GDBM
- DB_File
- Indexing revisited
- Ordered hashes
- Partial matching
- Sequential access
- Multiple values
- Filters
- BerkeleyDB
Online materials
- Class slides:

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 License.- PDF files:
- Browse slides online
- Sample source code referred to in the class:

Example source code from Lightweight Databases class is licensed under a Creative Commons Public Domain License. - People sometimes ask what use Tie::File is when Berkeley DB has a DB_RECNO option that appears to be the same thing. This document explains why.
[Other articles in category /prog/perl] permanent link
Fri, 20 Jul 2007
"More intuitive" programming language syntax
Chromatic wrote an article today about The
Broken Metric of "Intuitive to the Uneducated" Language
Syntax in which he addresses the very common argument that
some language syntax is better than some other because it is "more
intuitive" or "easier for beginners to understand".
Chromatic says that these arguments are bunk because programming language syntax is much less important than programming language semantics. But I think that is straining at a gnat and swallowing a camel.
To argue that a certain programming language feature is bad because it is confusing to beginners, you have to do two things. You have to successfully argue that being confusing to beginners is an important metric. Chromatic's article tries to refute this, saying that it is not an important metric.
But before you even get to that stage, you first have to show that the programming language feature actually is confusing to beginners.
But these arguments are never presented with any evidence at all, because no such evidence exists. They are complete fabrications, pulled out of the asses of their propounders, and made of equal parts wishful thinking and bullshit.
Addendum 20070720:
|
To support my assertion that nobody knows what makes programming hard
for beginners, I wanted to cite this paper, The
camel has two humps, by Dehnadi and Bornat, which I was
rereading recently, but I couldn't find my copy and couldn't remember
the title or authors. Happily, I eventually remembered. The abstract begins:
Learning to program is notoriously difficult. A substantial minority of students fails in every introductory programming course in every UK university. Despite heroic academic effort, the proportion has increased rather than decreased over the years. Despite a great deal of research into teaching methods and student responses, we have no idea of the cause.But the situation isn't completely hopeless; the abstract also says:
We have found a test for programming aptitude, of which we give details. We can predict success or failure even before students have had any contact with any programming language with very high accuracy, and by testing with the same instrument after a few weeks of exposure, with extreme accuracy. We present experimental evidence to support our claim. certain to succeed.What's the secret? Read and learn. |
http://retractionwatch.com/2014/07/18/the-camel-doesnt-have-two-humps-programming-aptitude-test-canned-for-overzealous-conclusion/ Addendum 20160518: Bornat has retracted the paper mentioned above, which was never published. He says:
In 2006 I wrote an intemperate description of the results of an experiment carried out by Saeed Dehnadi. Many of the extravagant claims I made were insupportable, and I retract them. I continue to believe, however, that Dehnadi had uncovered the first evidence of an important phenomenon in programming learners. Later research seems to confirm that belief.In particular, Bornat says “There wasn’t and still isn’t an aptitude test for programming based on Dehnadi’s work.” This retracts the specific claim that I quoted above. The entire retraction is worth reading.
[Other articles in category /prog] permanent link
Thu, 12 Jul 2007
Another useful utility
Every couple of years I get a good idea for a simple utility that will
make my life easier. Last time it was the following triviality, which
I call f:
#!/usr/bin/perl
my $field = shift or usage();
$field -= 1 if $field > 0;
$|=1;
while (<>) {
chomp;
my @f = split;
print $f[$field], "\n";
}
sub usage {
print STDERR "$0 fieldnumber\n";
exit 1;
}
I got tired of writing awk '{print $11}' when I wanted to
extract the 11th field of some stream of data in a Unix pipeline,
which is something I do about six thousand times a day. So
I wrote this tiny thing. It was probably the most useful piece of
software I wrote in that calendar year, and as you can see from the
length, it certainly had the best cost-to-benefit ratio. I use it
every day.The point here is that you can replace awk '{print $11}' with just f 11. For example, f 11 access_log finds out the referrer URLs from my Apache httpd log. I also frequently use f -1, which prints the last field in each line. ls -l | grep '^l' | f -1 prints out the targets of all the symbolic links in the current directory.
Programs like this won't win me any prizes, but they certainly are useful.
Anyway, today's post was inspired by another similarly tiny utility that I expect will be similarly useful that I just finished. It's called runN:
#!/usr/bin/perl
use Getopt::Std;
my %opt;
getopts('r:n:c:v', \%opt) or usage();
$opt{n} or usage();
$opt{c} or usage();
@ARGV = shuffle(@ARGV) if $opt{r};
my $N = $opt{n};
my %pid;
while (@ARGV) {
if (keys(%pid) < $N) {
$pid{spawn($opt{c}, split /\s+/, shift @ARGV)} = 1;
} else {
delete $pid{wait()};
}
}
1 while wait() >= 0;
sub spawn {
my $pid = fork;
die "fork: $!" unless defined $pid;
return $pid if $pid;
exec @_;
die "exec: $!";
}
You can tell I just finished it because the shuffle() and
usage() functions are unimplemented.The idea is that you execute the program like this:
runN -n 3 -c foo arg1 arg2 arg3 arg4...and it runs the commands foo arg1, foo arg2, foo arg3, foo arg4, etc., simultaneously, but with no more than 3 running at a time.
The -n option says how many commands to run simultaneously; after running that many the main control waits until one has exited before starting another.
If I had implemented shuffle(), then -r would run the commands in random order, instead of in the order specified. Probably I should get rid of -c and just have the program take the first argument as the command name, so that the invocation above would become runN -n 3 foo arg1 arg2 arg3 arg4.... The -v flag, had I implemented it, would put the program into verbose mode.
I find that it's best to defer the implementation of features like -r and -v until I actually need them, which might be never. In the past I've done post-analyses of the contents of ~mjd/bin, and what I found was that my tendency was to implement a lot more features than I needed or used.
In the original implementation, the -n is mandatory, because I couldn't immediately think of a reasonable default. The only obvious choice is 1, but since the point of the program was to run programs concurrently, 1 is not reasonable. But it occurs to me now that if I let -n default to 1, then this command would replace many of my current invocations of:
for i in ...; do cmd $i donewhich I do quite a lot. Typing runN cmd ... would be a lot quicker and easier. As I've written before, when a feature you put in turns out to have unanticipated uses, it's a sign of a good, modular design.
The code itself makes me happy for two reasons. One is that the program worked properly on the first try, which does not happen very often for me. When I was in elementary school, my teachers always complained that although I was very bright, I made a lot of careless mistakes because I was not methodical enough. They tried hard to fix this personality flaw. They did not succeed.
The other thing I like about the code is that it's so very brief. Not to say that it is any briefer than it should be; I think it's just about perfect. One of the recurring themes of my study of programming for the last few years is that beginner programmers use way more code than is necessary, just like beginning writers use way too many words. The process and concurrency management turned out to be a lot easier than I thought they would be: the default Unix behavior was just exactly what I needed. I am particularly pleased with delete $pid{wait()}. Sometimes these things just come together.
The 1 while wait() >= 0 line is a non-obfuscated version of something I wrote in my prize-winning obfuscated program, of all places. Sometimes the line between the sublime and the ridiculous is very fine indeed.
Despite my wariness of adding unnecessary features, there is at least one that I will put in before I deploy this to ~mjd/bin and start using it. I'll implement usage(), since experience has shown that I tend to forget how to invoke these things, and reading the usage message is a quicker way to figure it out than is rereading the source code. In the past, usage messages have been good investments.
I'm tempted to replace the cut-rate use of split here with something more robust. The problem I foresee is that I might want to run a command with an argument that contains a space. Consider:
runN -n 2 -c ls foo bar "-l baz"This runs ls foo, then ls bar, then ls -l baz. Without the split() or something like it, the third command would be equivalent to ls "-l baz" and would fail with something like -l baz: no such file or directory. (Actually it tries to interpret the space as an option flag, and fails for that reason instead.) So I put the split in to enable this usage. (Maybe this was a you-ain't-gonna-need-it moment; I'm not sure.) But this design makes it difficult or impossible to apply the command to an argument with a space in it. Suppose I'm trying to do ls on three directories, one of which is called old stuff. The natural thing to try is:
runN -n 2 -c ls foo bar "old stuff"But the third command turns into ls old stuff and produces:
ls: old: No such file or directory ls: stuff: No such file or directoryIf the split() were omitted, it would just work, but then the ls -l baz example above would fail. If the split() were replaced by the correct logic, I would be able to get what I wanted by writing something like this:
runN -n 2 -c ls foo bar "'old stuff'"But as it is this just produces another error:
ls: 'old: No such file or directory ls: stuff': No such file or directoryPerl comes standard with a library called ShellWords that is probably close to what I want here. I didn't use it because I wasn't sure I'd actually need it—only time will tell—and because shell parsing is very complicated and error-prone, more so when it is done synthetically rather than by the shell, and even more so when it is done multiple times; you end up with horrible monstrosities like this:
s='q=`echo "$s" | sed -e '"'"'s/'"'"'"'"'"'"'"'"'/'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'/g'"'"'`; echo "s='"'"'"$q"'"'"'"; echo $s' q=`echo "$s" | sed -e 's/'"'"'/'"'"'"'"'"'"'"'"'/g'`; echo "s='"$q"'"; echo $sSo my fear was that by introducing a double set of shell-like interpretation, I'd be opening a horrible can of escape character worms and weird errors, and my hope was that if I ignored the issue the problems might be simpler, and might never arise in practice. We'll see.
[ Addendum 20080712: Aaron Crane wrote a thoughtful followup. Thank you, M. Crane. ]
[Other articles in category /prog] permanent link
Wed, 21 Feb 2007
A bug in HTML generation
A few days ago I hacked on the TeX plugin I wrote for Blosxom so that
it would put the TeX source code into the ALT attributes of the image
elements it generated.
But then I started to see requests in the HTTP error log for URLs like this:
/pictures/blog/tex/total-die-rolls.gif$${6/choose%20k}k!{N!/over%20/prod%20{i!}^{n_i}{n_i}!}/qquad%20/hbox{/rm%20where%20$k%20=%20/sum%20n_i$}$$.gif
Someone must be referring people to these incorrect URLs, and it is
presumably me. The HTML version of the blog looked okay, so I checked
the RSS and Atom files, and found that, indeed, they were malformed.
Instead of <img src="foo.gif" alt="$TeX$">, they
contained codes for <img src="foo.gif$TeX$">.I tracked down and fixed the problem. Usually when I get a bug like this, I ask myself what I could learn from it. This one is unusual. I can't think of much. Here's the bug.
The <img> element is generated by a function called imglink. The arguments to imglink are the filename that contains the image (for use in the SRC attribute) and the text for the ALT attribute. The ALT text is optional. If it is omitted, the function tries to locate the TeX source code and fetch it. If this attempt fails, it continues anyway, and omits the ALT attribute. Then it generates and returns the HTML:
sub imglink {
my $file = shift;
...
my $alt = shift || fetch_tex($file);
...
$alt = qq{alt="$alt"} if $alt;
qq{<img $alt border=0 src="$url">};
}
This function is called from several places in the plugin. Sometimes
the TeX source code is available at the place from which the call
comes, and the code has return imglink($file, $tex);
sometimes it isn't and the code has
return imglink($file) and hopes that the imglink
function can retrieve the TeX.One such place is the branch that handles generation of tags for every type of output except HTML. When generating the HTML output, the plugin actually tries to run TeX and generate the resulting image file. For other types of output, it assumes that the image file is already prepared, and just calls imglink to refer to an image that it presumes already exists:
return imglink($file, $tex) unless $blosxom::flavour eq "html";The bug was that I had written this instead:
return imglink($file. $tex) unless $blosxom::flavour eq "html";The . here is a string concatenation operator.
It's a bit surprising that I don't make more errors like this than I do. I am a very inaccurate typist.
Stronger type checking would not have saved me here. Both arguments are strings, concatenation of strings is perfectly well-defined, and the imglink function was designed and implemented to accept either one or two arguments.
The function did note the omission of the $tex argument, attempted to locate the TeX source code for the bizarrely-named file, and failed, but I had opted to have it recover and continue silently. I still think that was the right design. But I need to think about that some more.
The only lesson I have been able to extract from this so far is that I need a way of previewing the RSS and Atom outputs before publishing them. I do preview the HTML output, but in this case it was perfectly correct.
[Other articles in category /prog/bug] permanent link
Wed, 14 Feb 2007
Subtlety or sawed-off shotgun?
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
There's a line in one of William Gibson's short stories about how some situations call for a subtle and high-tech approach, and others call for a sawed-off shotgun. I think my success as a programmer, insofar as I have any, comes from knowing when to deploy each kind of approach.
In a recent article I needed to produce the table that appears at left.This was generated by a small computer program. I learned a long time ago that although it it tempting to hack up something like this by hand, you should usually write a computer program to do it instead. It takes a little extra time up front, and that time is almost always amply paid back when you inevitably decide that that table should have three columns instead of two, or the lines should alternate light and dark gray, or that you forgot to align the right-hand column on the decimal points, or whatever, and then all you have to do is change two lines of code and rerun the program, instead of hand-editing all 34 lines of the output and screwing up two of them and hand-editing them again. And again. And again.
When I was making up the seating chart for my wedding, I used this approach. I wrote a raw data file, and then a Perl program to read the data file and generate LaTeX output. The whole thing was driven by make. I felt like a bit of an ass as I wrote the program, wondering if I wasn't indulging in an excessive use of technology, and whether I was really going to run the program more than once or twice. How often does the seating chart need to change, anyway?
Gentle readers, that seating chart changed approximately one million and six times.
The Nth main division of the table at left contains one line for every partition of the integer N. The right-hand entry in each line (say 144) is calculated by a function permcount, which takes the left-hand entry (say [5, 1]) as input. The permcount function in turn calls upon fact to calculate factorials and choose to calculate binomial coefficients.

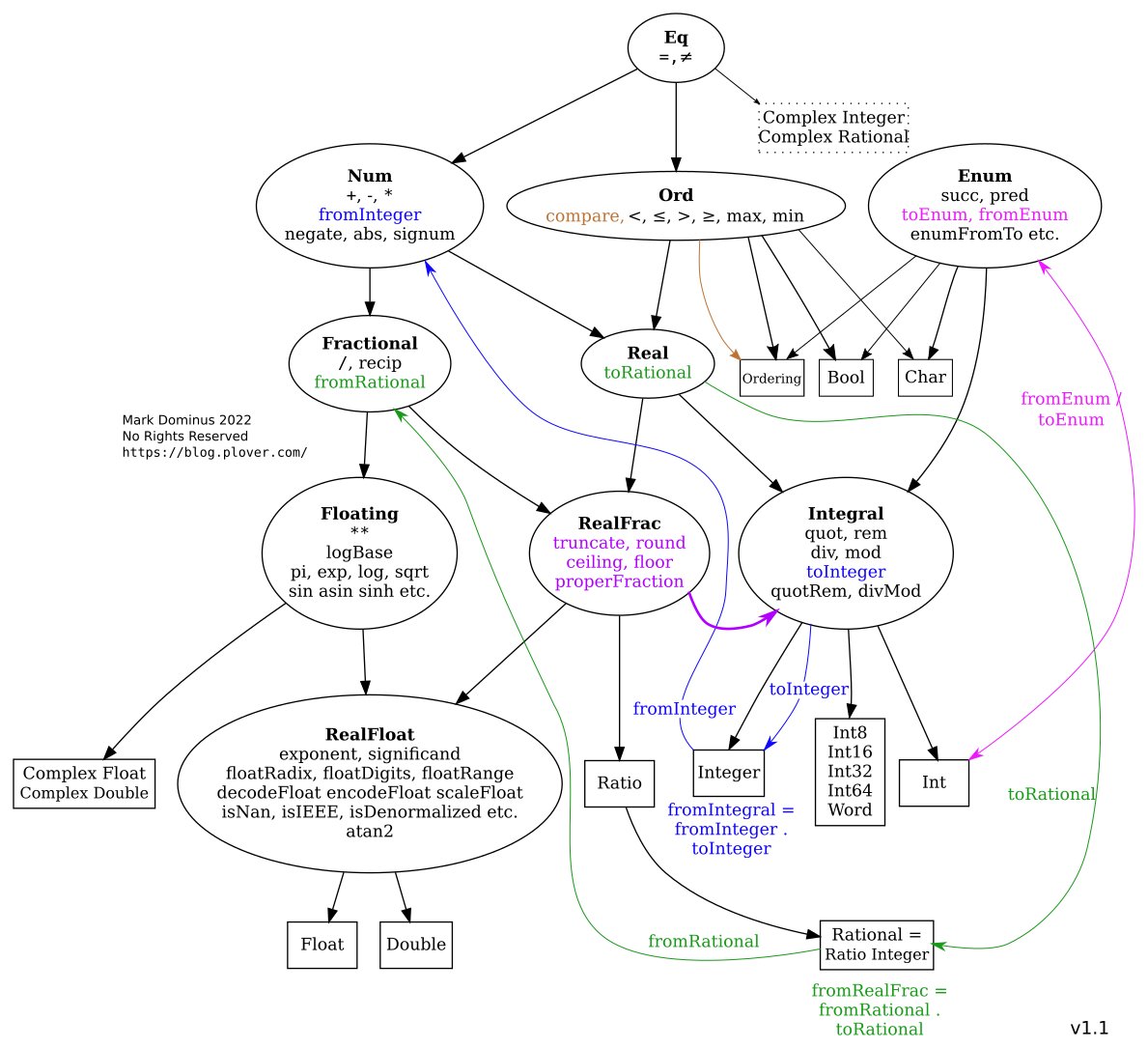{kind=link}
But how is the left-hand column generated? In my book, I spent quite a lot of time discussing generation of partitions of an integer, as an example of iterator techniques. Some of these techniques are very clever and highly scalable. Which of these clever partition-generating techniques did I use to generate the left-hand column of the table?
Why, none of them, of course! The left-hand column is hard-wired into
the program:
while (<DATA>) {
chomp;
my @p = split //;
...
}
...
__DATA__
1
11
2
111
12
3
...
51
6
I guessed that it would take a lot longer to write code to generate
partitions, or even to find it already written and use it, than it
would just to generate the partitions out of my head and type them in.
This guess was correct.
The only thing wrong with my approach is that it doesn't scale. But
it doesn't need to scale.
The sawed-off shotgun wins!
[ Addendum 20190920: The Gibson story is Johnny Mnemonic, which begins:
I put the shotgun in an Adidas bag and padded it out with four pairs of tennis socks, not my style at all, but that was what I was aiming for: If they think you're crude, go technical; if they think you're technical, go crude. I'm a very technical boy. So I decided to get as crude as possible.The rest of the paragraph somewhat undercuts my point: Shotguns were so long obsolete that Johnny had to manufacture the cartridges himself. ]
[Other articles in category /prog] permanent link
Tue, 03 Oct 2006
Ralph Johnson on design patterns
Last month I wrote an
article about design patterns which attracted a lot of favorable
attention in blog world. I started by paraphrasing Peter
Norvig's observation that:
"Patterns" that are used recurringly in one language may be invisible or trivial in a different language.
and ended by concluding:
Patterns are signs of weakness in programming languages.Ralph Johnson, one of the four authors of the famous book Design Patterns, took note of my article and responded. I found Johnson's response really interesting, and curious in a number of ways. I think everyone who was interested in my article should read his too. [ Addendum 20070127: The link above to Ralph Johnson's response is correct, but your client will be rejected if you are referred from here. To see his blog page, visit the page without clicking on the link. ]When we identify and document one, that should not be the end of the story. Rather, we should have the long-term goal of trying to understand how to improve the language so that the pattern becomes invisible or unnecessary.
Johnson raises several points. First there is a meta-issue to deal with. Johnson says:
He clearly thinks that what he says is surprising. And other people think it is surprising, too. That is surprising to me.I did think that what I had to say was interesting and worth saying, of course, or I would not have said it. And I was not surprised to find that other people agreed with me.
One thing that I did find surprising is the uniformity of other people's surprise and interest. There were dozens of blog posts and comments in the following two weeks, all pretty much saying what a great article I had written and how right I was. I tracked the responses as carefully as I could, and I did not see any articles that called me a dumbass; I did not see any except for Johnson's that suggested that what I was saying was unsurprising.
We can't conclude from this that I am right, of course; people agree with all sorts of stupid crap. But we can conclude that that what I said was surprising and interesting, since people were surprised and interested by it, even people who already have some knowledge of this topic. Johnson is right to be surprised by this, because he thought this was obvious and well-known, and that it was clearly laid out in his book, and he was mistaken. Many or most of the readers of his book have completely missed this point. I didn't miss it, but I didn't get it from the book, either.
Johnson and his three co-authors wrote this book, Design Patterns, which has had a huge influence on the way that programming is practiced. I think a lot of that influence has been malign. Any practice can be corrupted, of course, by being reduced to its formal aspects and applied in a rote fashion. (There's a really superb discussion of this in A. Ya. Khinchin's essay On the Teaching of Mathematics, and a shorter discussion in Polya's How to Solve It, in the section on "Pedantry and Mastery".) That will happen to any successful movement, and the Gang of Four can't take all the blame for that.
But if they really intended that everyone should understand that each design pattern is a demonstration of a weakness in its target language, then they blew it, because it appears that hardly anyone understood that.
Let's pause for a moment to imagine an alternate universe in which the subtitle of the Design Patterns book was not "Elements of Reusable Object-Oriented Software" but "Solutions for Recurring Problems in Object-Oriented Languages". And let's imagine that in each section, after "Pattern name", "Intent", "Motivation", "Applicability", and so forth, there was another subsection titled "Prophylaxis" that went something like this: "The need for the Iterator pattern in C++ appears to be due partly to its inflexible type system and partly to its lack of abstract iteration structures. The iterator pattern is unnecessary in the Python language, which avoids these defects as follows: ... at the expense of ... . In Common Lisp, on the other hand, ... (etc.)".
I would have liked to have seen that universe, but I suppose it's too late now. Oh well.
Anyway, moving on from meta-issues to the issues themselves, Johnson continues:
At the very end, he says that patterns are signs of weakness in programming languages. This is wrong.This is interesting, and I was going to address it later, but I now think that it's the first evidence of a conceptual mistake that Johnson has made that underlies his entire response to my article, so I'll take it up now.
At the very end of his response, Johnson says:
No matter how complicated your language will be, there will always be things that are not in the language. These things will have to be patterns. So, we can eliminate one set of patterns by moving them into the language, but then we'll just have to focus on other patterns. We don't know what patterns will be important 50 years from now, but it is a safe bet that programmers will still be using patterns of some sort.Here we are in complete agreement. So, to echo Johnson, I was surprised that he would think this was surprising. But how can we be in complete agrement if what I said was "wrong"? There must be a misunderstanding somewhere.
I think I know where it is. When I said "[Design] Patterns are signs of weakness in programming languages," what I meant was something like "Each design pattern is a sign of a weakness in the programming language to which it applies." But it seems that Johnson thinks that I meant that the very existence of design patterns, at all, is a sign of weakness in all programming languages everywhere.
If I thought that the existence of design patterns, at all, was a sign that current programming languages are defective, as a group, I would see an endpoint to programming language development: someday, we would have a perfect überlanguage in which it would be unnecessary to use patterns because all possible patterns would have been built in already.
I think Johnson thinks this was my point. In the passage quoted above, I think he is addressing the idea of the überlanguage that incorporates all patterns everywhere at all levels of abstraction. And similarly:
Some people like languages with a lot of features. . . . I prefer simple languages.And again:
No matter how complicated your language will be, there will always be things that are not in the language.But no, I don't imagine that someday we will have the ultimate language, into which every conceivable pattern has been absorbed. So a lot of what Johnson has to say is only knocking down a straw man.
What I imagine is that when pattern P applies to language L, then, to the extent that some programmer on some project finds themselves needing to use P in their project, the use of P indicates a deficiency in language L for that project.
The absence of a convenient and simple way to do P in language L is not always a problem. You might do a project in language L that does not require the use of pattern P. Then the problem does not manifest, and, whatever L's deficiencies might be for other projects, it is not deficient in that way for your project.
This should not be difficult for anyone to understand. Perl might be a very nice language for writing a program to compile a bioinformatic data file into a more reasonable form; it might be a terrible language for writing a real-time missile guidance system. Its deficiencies operate in the missile guidance project in a way that they may not in the data munging project.
But to the extent that some deficiency does come up in your project, it is a problem, because you are implementing the same design over and over, the same arrangement of objects and classes, to accomplish the same purpose. If the language provided more support for solving this recurring design problem, you wouldn't need to use a "pattern". Consider again the example of the "subroutine" pattern in assembly language: don't you have anything better to do than redesign and re-implement the process of saving the register values in a stack frame, over and over? Well, yes, you do. And that is why you use a language that has that built in. Consider again the example of the "object-oriented class" pattern in C: don't you have anything better to do than redesign and re-implement object-oriented method dispatch with inheritance, over and over? Yes, you do. And that is why you use a language that has that built in, if that is what you need.
By Gamma, Helm, Johnson, and Vlissides' own definition, the problems solved by patterns are recurring problems, and programmers must address them recurringly.
If these problems recurred in every language, we might conclude that they were endemic to programming itself. We might not, but it's hard to say, since if there are any such problems, they have not yet been brought to my attention. Every pattern discovered so far seems to be specific to only a small subset of the world's languages.
So it seems a small step to conclude that these recurring, language-specific problems are actually problems with the languages themselves. No problem is a problem in every language, but rather each problem is a red arrow, pointing at a design flaw in the language in which it appears.
Johnson continues:
Patterns might be a sign of weakness, but they might be a sign of simplicity. . . .I think this argument fails, in light of the examples I brought up in my original article. The argument is loaded by the use of the word "simplicity". As Einstein said, things should be as simple as possible, but no simpler. In assembly language, "subroutine call" is a pattern. Does Johnson or anyone seriously think that C++ or Smalltalk or Common Lisp or Java would be improved by having the "subroutine call" pattern omitted? The languages might be "simpler", but would they be better?
The alternative, remember, is to require the programmer to use a "pattern": to make them consult a manual of "patterns" to implement a "general arrangement of objects and classes" to solve the subroutine-call problem every time it comes up.
I guess you could interpret that as a sign of "simplicity", but it's the wrong kind of simplicity. Language designers have a hard problem to solve. If they don't put enough stuff into the language, it'll be too hard to use. But if they put in too much stuff, it'll be confusing and hard to program, like C++. One reason it's hard to be a language designer is that it's hard to know what to put in and what to leave out. There is an extremely complex tradeoff between simplicity and functionality.
But in the case of "patterns", it's much easier to understand the tradeoff. A pattern, remember, is a general method for solving "a recurring design problem". Patterns might be a sign of "simplicity", but if so, they are a sign of simplicity in the wrong place, a place where the language needs to be less simple and more featureful. Because patterns are solutions to recurring design problems.
If you're a language designer, and a "pattern" comes to your attention, then you have a great opportunity. The programmers using your language have a recurring problem. They have to implement the same solution to it, over and over. Clearly, this is a good place to try to expend some design effort; perhaps you can trade off a little simplicity for some functionality and fix the language so that the problem is a problem no longer.
Getting rid of one recurring design problem might create new ones. But if the new problems are operating at a higher level of abstraction, you may have a win. Getting rid of the need for the "subroutine call" pattern in assembly language opened up all sorts of new problems: when and how do I do recursion? When and how do I do coroutines?
Getting rid of the "object-oriented class" pattern in C created a need for higher-level patterns, including the ones described in the Design Patterns book. When people didn't have to worry about implementing inheritance themselves, a lot of their attention was freed up, and they could notice patterns like Façade.
As Alfred North Whitehead says, civilization advances by extending the number of important operations which we can perform without thinking about them. The Design Patterns approach seems to be to identify the important operations and then to think about them over and over and over and over and over.
Or so it seems to me. Johnson's next paragraph makes me wonder if I've completely missed his point, because it seems completely senseless to me:
There is a trade-off between putting something in your programming language and making it be a convention, or perhaps putting it in the library. Smalltalk makes "constructor" be a convention. Arithmetic is in the library, not in the language. Control structures and exception handling are from the library, not in the language.Huh? Why does "library" matter? Unless I have missed something essential, whether something is in the "language" or the "library" is entirely an implementation matter, to be left to the discretion of the compiler writer. Is printf part of the C language, or its library? The library, everyone knows that. Oh, well, except that its behavior is completely standardized by the language standard, and it is completely permissible for the compiler writer to implement printf by putting a special case into the compiler that is enabled when the compiler happens to see the directive #include <stdio.h>. There is absolutely no requirement that printf be loaded from a separate file or anything like that.
Or consider Perl's dbmopen function. Prior to version 5.000, it was part of the "language", in some sense; in 5.000 and later, it became part of the "library". But what's the difference, really? I can't find any.
Is Johnson talking about some syntactic or semantic difference here? Maybe if I knew more about Smalltalk, I would understand his point. As it is, it seems completely daft, which I interpret to mean that there's something that went completely over my head.
Well, the whole article leaves me wondering if maybe I missed his point, because Johnson is presumably a smart guy, but his argument about the built-in features vs. libraries makes no sense to me, his argument about simplicity seems so clearly and obviously dismantled by his own definition of patterns, and his apparent attack on a straw man seems so obviously erroneous.
But I can take some consolation in the thought that if I did miss his point, I'm not the only one, because the one thing I can be sure of in all of this is that a lot of other people have been missing his point for years.
Johnson says at the beginning that he "wasn't sure whether to be happy or unhappy". If I had written a book as successful and widely read as Design Patterns and then I found out that everyone had completely misunderstood it, I think I would be unhappy. But perhaps that's just my own grumpy personality.
[ Addendum 20080303: Miles Gould wrote a pleasant and insightful article on Johnson's point about libraries vs. language features. As I surmised, there was indeed a valuable point that went over my head. I said I couldn't find any difference between "language" and "library", but, as M. Gould explains, there is an important difference that I did not appreciate in this context. ]
[Other articles in category /prog] permanent link
Really real examples of HOP techniques in action
I recently stopped working for the University of Pennsylvannia's
Informations Systems and Computing group, which is the organization
that provides computer services to everyone on campus that doesn't
provide it for themselves.
I used HOP stuff less than I might have if I hadn't written the HOP book myself. There's always a tradeoff with the use of any advanced techniques: it might provide some technical benefit, like making the source code smaller, but the drawback is that the other people you work with might not be able to maintain it. Since I'm the author of the book, I can be expected to be biased in favor of the techniques. So I tried to compensate the other way, and to use them only when I was absolutely sure it was the best thing to do.
There were two interesting uses of HOP techniques. One was in the username generator for new accounts. The other was in a generic server module I wrote.
Name generation
The name generator is used to offer account names to incoming students and faculty. It is given the user's full name, and optionally some additional information of the same sort. It then generates a bunch of usernames to offer the user. For example, if the user's name is "George Franklin Bauer, Jr.", it might generate usernames like:
george bauer georgef fgeorge fbauer bauerf
gf georgeb fg fb bauerg bf
georgefb georgebf fgeorgeb fbauerg bauergf bauerfg
ge ba gef gbauer fge fba
bgeorge baf gfbauer gbauerf fgbauer fbgeorge
bgeorgef bfgeorge geo bau geof georgeba
fgeo fbau bauerge bauf fbauerge bauergef
bauerfge geor baue georf gb fgeor
fbaue bg bauef gfb gbf fgb
fbg bgf bfg georg georgf gebauer
fgeorg bageorge gefbauer gebauerf fgebauer
The code that did this, before I got to it, was extremely long and
convoluted. It was also extremely slow. It would generate a zillion
names (slowly) and then truncate the list to the required length.It was convoluted because people kept asking that the generation algorithm be tweaked in various ways. Each tweak was accompanied by someone hacking on the code to get it to do things a little differently.
I threw it all away and replaced it with a lazy generator based on the lazy stream stuff of Chapter 6. The underlying stream library was basically the same as the one in Chapter 6. Atop this, I built some functions that generated streams of names. For example, one requirement was that if the name generator ran out of names like the examples above, it should proceed by generating names that ended with digits. So:
sub suffix {
my ($s, $suffix) = @_;
smap { "$_$suffix" } $s;
}
# Given (a, b, c), produce a1, b1, c1, a2, b2, c2, a3...
sub enumerate {
my $s = shift;
lazyappend(smap { suffix($s, $_) } iota());
}
# Given (a, b, c), produce a, b, c, a1, b1, c1, a2, b2, c2, a3...
sub and_enumerate {
my $s = shift;
append($s, enumerate($s));
}
# Throw away names that are already used
sub available_filter {
my ($s, $pn) = @_;
$pn ||= PennNames::Generate::InUse->new;
sgrep { $pn->available($_) } $s;
}
The use of the stream approach was strongly indicated here for two
reasons. First, the number of names to generate wasn't known in
advance. It was convenient for the generation module to pass back a
data structure that encapsulated an unlimited number of names, and let
the caller mine it for as many names as were necessary. Second, the frequent changes and tinkerings to the name generation algorithm in the past suggested that an extremely modular approach would be a benefit. In fact, the requirements for the generation algorithm chanced several times as I was writing the code, and the stream approach made it really easy to tinker with the order in which names were generated, by plugging together the prefabricated stream modules.
Generic server
For a different project, I wrote a generic forking server module. The module would manage a listening socket. When a new connection was made to the socket, the module would fork. The parent would go back to listening; the child would execute a callback function, and exit when the callback returned.The callback was responsible for communicating with the client. It was passed the client socket:
sub child_callback {
my $socket = shift;
# ... read and write the socket ...
return; # child process exits
}
But typically, you don't want to have to manage the socket manually.
For example, the protocol might be conversational: read a request
from the client, reply to it, and so forth:
# typical client callback:
sub child_callback {
my $socket = shift;
while (my $request = <$socket>) {
# generate response to request
print $socket $response;
}
}
The code to handle the loop and the reading and writing was
nontrivial, but was going to be the same for most client functions.
So I provided a callback generator. The input to the callback
generator is a function that takes requests and returns appropriate
responses:
sub child_behavior {
my $request = shift;
if ($request =~ /^LOOKUP (\w+)/) {
my $input = $1;
if (my $result = lookup($input)) {
return "OK $input $result";
} else {
return "NOK $input";
}
} elsif ($request =~ /^QUIT/) {
return;
} elsif ($request =~ /^LIST/) {
my $N = my @N = all_names();
return join "\n", "OK $N", @N, ".";
} else {
return "HUH?";
}
}
This child_behavior function is not suitable as a callback,
because the argument to the callback is the socket handle. But the
child_behavior function can be turned into a callback:
$server->run(CALLBACK => make_callback(\&child_behavior));
make_callback() takes a function like
child_behavior() and wraps it up in an I/O loop to turn it
into a callback function. make_callback() looks something
like this:
sub make_callback {
my $behavior = shift;
return sub {
my $socket = shift;
while (my $request = <$socket>) {
chomp $request;
my $response = $behavior->($request);
return unless defined $response;
print $socket $response;
}
};
}
I think this was the right design; it kept the design modular and
flexible, but also simple.
[Other articles in category /prog] permanent link
Wed, 20 Sep 2006
The world's worst macro preprocessor
Last week I added another plugin to my Blosxom installation. As I wrote before, the sole
benefit of Blosxom is that it's incredibly simple and lightweight. So
when I write plugins for it, I try to keep them incredibly simple and
lightweight, lest I spoil the single major benefit of Blosxom.
Sometimes I'm more successful, sometimes less so. This time I think I
did a good job.
The goal last time was a macro processor. I write a lot of math articles. I get tired of writing <sup>2</sup> every time I want a superscript 2. Even if I bind a function key to that sequence of characters, it's hard to read. But now, with my new Blosxom macro processor, I just insert a line into my article that says:
#define ^2 <sup>2</sup>
and for the rest of the article, ^2 is expanded to <sup>2</sup>.
This has turned out really well, and I'm using it for all sorts of stuff. I use it for math notations, such as for making -> an abbreviation for → (→), and for making ~ an abbreviation for ¬ (¬).
But I've also used it to #define Godel Gödel. I've used it to #define KK <b>K</b> and #define SS <b>S</b>, which makes an article I'm writing about combinatory logic readable, where it wasn't readable before. In my recent article about job hunting, I used it to #define CV résumé, which saved me from having to interrupt my train of thought several times in the article.
There are some important points about the design that I think I got right on the first try. Whenever you write a macro system, you have to ask about escape sequences: what do you do if you don't want a macro expanded? For example, in the combinatory logic article I defined a macro SS. This meant that if I had written MOUSSE in the article somewhere, it would have turned into MOUSE. How should I prevent that kind of error?
Answer: I don't. I'm unlikely to do that. But if I do, I'll pick it up during the article proofreading phase. If I can't avoid writing MOUSSE, I have two choices: I can change the name of the SS macro to something easier to avoid—like S*, say, or I can define a second macro: #define !MOUSSE MOUSSE. But so far, it hasn't come up.
One alternative solution is to say that macros are expanded only in certain contexts. For example, SS might only be expanded when it is a complete word, not when it is in the middle of a word, as MOUSSE. I resisted this solution. It is much simpler to remember that every macro is expanded everywhere. And it it is much easier to fix the problem of a macro being expanded when I don't want it than it is to fix the problem of a macro not being expanded when I do want it. So every macro is expanded no matter where it appears.
Related to the unintentional-expansion issue is that each article has its own private macro set. I don't have to worry that by defining a macro named -> in one article that I might be sabotaging my opportunity to actually write -> in some unknown future article. Each set of macros can be totally ad hoc. I don't have to worry about global tradeoffs. Do I #define --- —, knowing that that will foreclose my opportunity to use --- in any other way? I can make the decision based on simple, local information.
It would have been tempting to over-engineer the system and add all sorts of complex escape facilities. I think I made the right choice here by not doing any of that.
Another escaping issue: What if I want to write something that looks like a definition but isn't? Here I avoided the problem by choosing a definition syntax that I was unlikely to write in any other context: #define in the leftmost column indicates a definition. In this article, I had to write some similar text. It was no trouble to indent it a couple of spaces, disabling the special meaning. But HTML is already full of escape mechanisms, and it would have been no trouble to write #define instead of #define if for some reason I had really needed it to appear in the leftmost column. (Unlikely anyway, since HTML has no column semantics.)
Another right choice I think I made was not to parametrize the macros. An article on algebra might well have:
#define ^2 <sup>2</sup> #define ^3 <sup>3</sup>and it might be oh-so-tempting to try to eliminate the duplication à la C:
#define ^(\w+) <sup>$1</sup>I did not do this. It would have complicated the processing substantially. It would also have complicated the use of the package substantially: I would have to worry a lot more than I do about invoking macros unintentionally. And it is not needed. Not so far, anyway. Because macro definitions only last for the duration of the article, there is no pressure to make a complete or consistent set of definitions. If an article happens to use the notations 2, i, and N, I can define macros for those and only those notations.
Also tempting is to extend the macro system to support something like this:
#define BF(.*) <b>$1</b>I have so far resisted this. My feeling is that if I want to do anything like this, I should take it as a sign that I should be writing the articles in some markup system other than HTML. Choice of that markup system should be made carefully, and not organically as an ad-hoc overburdening of the macro system.
I did run into one trouble with the macro system. Originally, it was invoked before some of my other plugins and after others. The earlier plugins automatically inserted certain text into the article that sometimes accidentally triggered my macros. I have not had any trouble with this since I changed the plugin order to invoke the macro processor before any of the other plugins.
The macro-processing code is about 19 lines long, of which three are diagnostic. It is the world's worst macro system. It has exactly one feature. It is, I think the simplest thing that could possibly work, and so a good companion to Blosxom. For this application, the world's worst macro system is the world's best.
[ Addendum 20071004: There's now a one-year retrospective analysis. ]
[Other articles in category /prog] permanent link
Mon, 11 Sep 2006
Design patterns of 1972
"Patterns" that are used recurringly in one language may be invisible
or trivial in a different language.
Extended Example: "object-oriented class"
C programmers have a pattern that might be called "Object-oriented class". In this pattern, an object is an instance of a C struct.
struct st_employee_object *emp;
Or, given a suitable typedef:
EMPLOYEE emp;
Some of the struct members are function pointers. If "emp" is an
object, then one calls a method on the object by looking up the
appropriate function pointer and calling the pointed-to function:
emp->method(emp, args...);
Each struct definition defines a class; objects in the same class have
the same member data and support the same methods. If the structure
definition is defined by a header file, the layout of the structure
can change; methods and fields can be added, and none of the code that
uses the objects needs to know.There are a bunch of variations on this. For example, you can get opaque implementation by defining two header files for each class. One defines the implementation:
struct st_employee_object {
unsigned salary;
struct st_manager_object *boss;
METHOD fire, transfer, competence;
};
The other defines only the interface:
struct st_employee_object {
char __SECRET_MEMBER_DATA_DO_NOT_TOUCH[4];
struct st_manager_object *boss;
METHOD fire, transfer, competence;
};
And then files include one or the other as appropriate. Here "boss"
is public data but "salary" is private.You get abstract classes by defining a constructor function that sets all the methods to NULL or to:
void _abstract() { abort(); }
If you want inheritance, you let one of the structs be a prefix of
another:
struct st_manager_object; /* forward declaration */
#define EMPLOYEE_FIELDS \
unsigned salary; \
struct st_manager_object *boss; \
METHOD fire, transfer, competence;
struct st_employee_object {
EMPLOYEE_FIELDS
};
struct st_manager_object {
EMPLOYEE_FIELDS
unsigned num_subordinates;
struct st_employee_object **subordinate;
METHOD delegate_task, send_to_conference;
};
And if obj is a manager object, you can still treat
it like an employee and call employee methods on
it.This may seem weird or contrived, but the technique is widely used. The C standard contains guarantees that the common fields of struct st_manager_object and struct st_employee_object will be laid out identically in memory, specifically so that this object-oriented class technique can work. The code of the X window system has this structure. The code of the Athena widget toolkit has this structure. The code of the Linux kernel filesystem has this structure.
Rob Pike, one of the primary architects of the Plan 9 operating system (the Bell Labs successor to Unix) and co-author (with Brian Kernighan) of The Unix Programming Environment, recommends this technique in his article "Notes on Programming in C".
This is a pattern
There's only one way in which this technique doesn't qualify as a pattern according to the definition of Gamma, Helm, Johnson, and Vlissides. They say:
A design pattern systematically names, motivates, and explains a general design that addresses a recurring design problem in object-oriented systems. It describes the problem, the solution, when to apply the solution, and its consequences. It also gives implementation hints and examples. The solution is a general arrangement of objects and classes that solve the problem. The solution is customized and implemented to solve the problem in a particular context.Their definition arbitrarily restricts "design patterns" to addressing recurring design problems "in object-oriented systems", and to being general arrangements of "objects and classes". If we ignore this arbitrary restriction, the "object-oriented class" pattern fits the description exactly.
The definition in Wikipedia is:
In software engineering, a design pattern is a general solution to a common problem in software design. A design pattern isn't a finished design that can be transformed directly into code; it is a description or template for how to solve a problem that can be used in many different situations.And the "object-oriented class" solution certainly qualifies.
Codification of patterns
Peter Norvig's presentation on "Design Patterns in Dynamic Languages" describes three "levels of implementation of a pattern":
- Invisible
- So much a part of language that you don't notice
- Formal
- Implement pattern itself within the language
Instantiate/call it for each use
Usually implemented with macros - Informal
- Design pattern in prose; refer to by name, but
Must be reimplemented from scratch for each use
The single major driver for the invention of C++ was to codify this pattern into the language so that it was "invisible". In C++, you don't have to think about the structs and you don't have to worry about keeping data and methods private. You just declare a "class" (using syntax that looks almost exactly like a struct declaration) and annotate the items with "public" and "private" as appropriate.
But underneath, it's doing the same thing. The earliest C++ compilers simply translated the C++ code into the equivalent C code and invoked the C compiler on it. There's a reason why the C++ method call syntax is object->method(args...): it's almost exactly the same as the equivalent code when the pattern is implemented in plain C. The only difference is that the object is passed implicitly, rather than explicitly.
In C, you have to make a conscious decision to use OO style and to implement each feature of your OOP system as you go. If a program has fifty modules, you need to decide, fifty times, whether you will make the next module an OO-style module. In C++, you don't have to make a decision about whether or not you want OO programming and you don't have to implement it; it's built into the language.
Sherman, set the wayback machine for 1957
If we dig back into history, we can find all sorts of patterns. For example:
Recurring problem: Two or more parts of a machine language program need to perform the same complex operation. Duplicating the code to perform the operation wherever it is needed creates maintenance problems when one copy is updated and another is not.This is a "pattern"-style description of the pattern we now know as "subroutine". It addresses a recurring design problem. It is a general arrangement of machine instructions that solve the problem. And the solution is customized and implemented to solve the problem in a particular context. Variations abound: "subroutine with passed parameters". "subroutine call with returned value". "Re-entrant subroutine".Solution: Put the code for the operation at the end of the program. Reserve some extra memory (a "frame") for its exclusive use. When other code (the "caller") wants to perform the operation, it should store the current values of the machine registers, including the program counter, into the frame, and transfer control to the operation. The last thing the operation does is to restore the register values from the values saved in the frame and jump back to the instruction just after the saved PC value.
For machine language programmers of the 1950s and early 1960's, this was a pattern, reimplemented from scratch for each use. As assemblers improved, the pattern became formal, implemented by assembly-language macros. Shortly thereafter, the pattern was absorbed into Fortran and Lisp and their successors, and is now invisible. You don't have to think about the implementation any more; you just call the functions.
Iterators and model-view-controller
The last time I wrote about design patterns, it was to point out that although the movement was inspired by the "pattern language" work of Christopher Alexander, it isn't very much like anything that Alexander suggested, and that in fact what Alexander did suggest is more interesting and would probably be more useful for programmers than what the design patterns movement chose to take.One of the things I pointed out was essentially what Norvig does: that many patterns aren't really addressing recurring design problems in object-oriented programs; they are actually addressing deficiencies in object-oriented programming languages, and that in better languages, these problems simply don't come up, or are solved so trivially and so easily that the solution doesn't require a "pattern". In assembly language, "subroutine call" may be a pattern; in C, the solution is to write result = function(args...), which is too simple to qualify as a pattern. In a language like Lisp or Haskell or even Perl, with a good list type and powerful primitives for operating on list values, the Iterator pattern is to a great degree obviated or rendered invisible. Henry G. Baker took up this same point in his paper "Iterators: Signs of Weakness in Object-Oriented Languages".
I received many messages about this, and curiously, some made the same point in the same way: they said that although I was right about Iterator, it was a poor example because it was a very simple pattern, but that it was impossible to imagine a more complex pattern like Model-View-Controller being absorbed and made invisible in this way.
This remark is striking for several reasons. It is an example of what is perhaps the most common philosophical fallacy: the writer cannot imagine something, so it must therefore be impossible. Well, perhaps it is impossible—or perhaps the writer just doesn't have enough imagination. It is worth remembering that when Edgar Allan Poe was motivated to investigate and expose Johann Maelzel's fraudulent chess-playing automaton, it was because he "knew" it had to be fraudulent because it was inconceivable that a machine could actually exist that could play chess. Not merely impossible, but inconceivable! Poe was mistaken, and the people who asserted that MVC could not be absorbed into a programming language were mistaken too. Since I gave my talk in 2002, several programming systems, such as Ruby on Rails and Subway have come forward that attempt to codify and integrate MVC in exactly the way that I suggested.
Progress in programming languages
Had the "Design Patterns" movement been popular in 1960, its goal would have been to train programmers to recognize situations in which the "subroutine" pattern was applicable, and to implement it habitually when necessary. While this would have been a great improvement over not using subroutines at all, it would have been vastly inferior to what really happened, which was that the "subroutine" pattern was codified and embedded into subsequent languages.Identification of patterns is an important driver of progress in programming languages. As in all programming, the idea is to notice when the same solution is appearing repeatedly in different contexts and to understand the commonalities. This is admirable and valuable. The problem with the "Design Patterns" movement is the use to which the patterns are put afterward: programmers are trained to identify and apply the patterns when possible. Instead, the patterns should be used as signposts to the failures of the programming language. As in all programming, the identification of commonalities should be followed by an abstraction step in which the common parts are merged into a single solution.
Multiple implementations of the same idea are almost always a mistake in programming. The correct place to implement a common solution to a recurring design problem is in the programming language, if that is possible.
The stance of the "Design Patterns" movement seems to be that it is somehow inevitable that programmers will need to implement Visitors, Abstract Factories, Decorators, and Façades. But these are no more inevitable than the need to implement Subroutine Calls or Object-Oriented Classes in the source language. These patterns should be seen as defects or missing features in Java and C++. The best response to identification of these patterns is to ask what defects in those languages cause the patterns to be necessary, and how the languages might provide better support for solving these kinds of problems.
With Design Patterns as usually understood, you never stop thinking about the patterns after you find them. Every time you write a Subroutine Call, you must think about the way the registers are saved and the return value is communicated. Every time you build an Object-Oriented Class, you must think about the implementation of inheritance.
People say that it's all right that Design Patterns teaches people to do this, because the world is full of programmers who are forced to use C++ and Java, and they need all the help they can get to work around the defects of those languages. If those people need help, that's fine. The problem is with the philosophical stance of the movement. Helping hapless C++ and Java programmers is admirable, but it shouldn't be the end goal. Instead of seeing the use of design patterns as valuable in itself, it should be widely recognized that each design pattern is an expression of the failure of the source language.
If the Design Patterns movement had been popular in the 1980's, we wouldn't even have C++ or Java; we would still be implementing Object-Oriented Classes in C with structs, and the argument would go that since programmers were forced to use C anyway, we should at least help them as much as possible. But the way to provide as much help as possible was not to train people to habitually implement Object-Oriented Classes when necessary; it was to develop languages like C++ and Java that had this pattern built in, so that programmers could concentrate on using OOP style instead of on implementing it.
Summary
Patterns are signs of weakness in programming languages.When we identify and document one, that should not be the end of the story. Rather, we should have the long-term goal of trying to understand how to improve the language so that the pattern becomes invisible or unnecessary.
[ Thanks to Garrett Rooney for pointing out some minor errors that I have since corrected. - MJD ]
[ Addendum 20061003: There is a followup article to this one, replying to a response by Ralph Johnson, one of the authors of the "Design Patterns" book. This link URL is correct, but Johnson's website will refuse it if you come from here. ]
[Other articles in category /prog] permanent link
Sat, 08 Jul 2006
A programmer had a problem...
A while back, I wrote an
article in which I mentioned a programmer who had a problem, tried
to solve it with weak references, and, as a result, had two problems.
I said that weak references work unusually well in that little
formula.
Yesterday I was about to make the same mistake. I had a problem, and weak references seemed like the solution. Fortunately, it was time to go home, which is a two-mile walk. Taking a two-mile walk is a great way to fix mistakes, especially the ones you haven't made yet. On this particular walk, I came to my senses and avoided the weak references.
The problem concerns the following classes and methods. You have a database object $db. You can call @rec = $db->lookup, which may return some record objects that represent records. You then call methods on the records, say $rec[3]->get_color, to extract data from them, or $rec[3]->set_color("purple"), to modify the data in the records. The updating is done in-memory only, and a later call to $db->flush writes all the updates back to the database.
The database object needs to store the changes that have been made but not yet written out. The easy way to do this is to have it store a change log of the modified record objects. So set_color first makes its change to the target record object, and then calls an internal _update method on the original database object to attach the record to the change log. Later on, flush will process this array, writing out the indicated changes.
In order for set_color to know which database to direct the _update call to, each record object must have a pointer back to the database that created it. This is convenient for other purposes too. Fine. But then if the record object is stored in the change log inside the database object, we now have a reference loop: the database contains a change log with a pointer to the record, which contains a pointer back to the database itself. This means that neither the database nor the record will ever be garbage collected. (This problem is common in complex Perl programs, and would simply vanish if Perl had even a slightly less awful garbage collector. Improvement is unlikely to occur before the release of Perl 6, now scheduled for October 28, 2073.)
My first reaction when faced with a problem like this one is to gurgle contentedly in my sleep, turn over, and pull the blankets over my head. This strategy is the primary contributor to my success as a programmer; it is somewhat superior to the typical programmer's response, which is to swing into action, overthink the problem, and come up with an elaborate solution. Aron Nimzovitch once said that the problem chess novices have is the irrepressible urge to always be doing something. Programmers are similar. They are all very bright people, very good at solving problems, and they solve problems all the time, even the ones that don't need to be solved.
I seem to be digressing. How unusual. In any case, this problem really did have to be solved. One wants the database object to flush out its pending changes at the time it becomes inacessible. If the object is never garbage collected, then the programmer must always remember to flush out the changes manually. Miss one call to flush, and your updates are lost. This is unacceptable. The primary purpose of a database is to record the updates. So I had to take my head out from under the covers, like it or not.
I thought about several solutions, and even tried one out, but it was too complicated and got me into a horrible tar pit, so I threw it away and started over. (That is another superior strategy that programmers don't exercise as often as they should. As Erik Naggum says, they will drive a hundred miles through a forest, stopping every five feet to cut down another tree, instead of pausing to wonder if maybe they shouldn't have driven off the road in the first place.)
Then I got the bright idea to use weak references, which seemed like just the thing. That's what weak references are for: breaking dependency loops so that things that need to be garbage collected can be. Fortunately, it was time to go, so I walked home instead of diving into the chyme-filled swimming pool of weak references.
With the weak references, you need to decide which reference to weaken. There is a reference to the record object, in the change log inside the database object. And there is a reference to the database object, in the record object. Which do you weaken?
If you weaken the reference to the record, you get a disaster:
{
my ($rec) = $db->lookup(...);
$rec->set_color("purple");
}
$db->flush;
When the block is exited, the last strong reference to the record goes
away, and the modified record evaporates, leaving nothing inside the
database object. The flush method can see by the lingering
ghost that there was something there it was supposed to deal with, but
it no longer knows what. So that choice is doomed.What if you weaken the reference inside the record, the one that points back to the database? That is hardly any better:
my $rec;
{
my $db = FlatFile->new(...);
($rec) = $db->lookup(...);
}
$rec->set_color("purple");
We would like the database object to hang around as long as there are
still some extant records from it. But because we weakened the
references from the records to the database, it doesn't; it evaporates
at the end of the block, leaving the record orphaned. The
set_color method then fails, because the database to which it
is supposed to write changes has evaporated.Conclusion: I've heard it before, and it wasn't funny the first time.
On the walk home, I realized something else: actually storing the database data inside the record objects is a bad move. The general advice under which this is a bad move is something like Don't store the same data in two places. The specific problems in this instance are exemplified by this:
my ($a) = $db->lookup(unique_id => "142857");
my ($b) = $db->lookup(unique_id => "142857");
$a->set_color("red");
$b->set_color("purple");
$a->color eq "purple"; # True or false?
Since $a and $b represent the same record, the
answer should be true. But in the implementation I had (and still
have, actually; I haven't fixed this yet) it is false. The
set_color method on $b updates the data that is
cached in object $b, but has no idea that it should also
update the data cached in $a.To work properly, $a and $b should be identical objects. One way to do this is to store an object in memory for every record in the database, and hand out these preconstructed objects as needed; then both calls to lookup return the same object. This is time- and memory-intensive. Another way to do this is to cache the record objects as they are constructed, and arrange for lookup to return the cached objects when appropriate. This is more complicated.
A simpler solution is not to store the data in memory at all. Record objects are always created as needed, but contain nothing but a database handle and some sort of locator information that says how to get the record data, should it be asked for. ("Any problem can be solved by another layer of indirection," they say, although it's not really true. Still, there are several classes of problems that can be solved by adding another layer of indirection, and this particular object identity problem could serve well as an exemplar of one of those classes.) Then modifications don't go into the record objects themselves. Instead, they go into the database object as an instruction to modify a certain record in a certain way.
This solution, however, presupposes that there is a good way to build locator information for a flat file and update it as needed. Fortunately, there is. I did a really good job of solving this problem a few years ago when I wrote the Tie::File module. It represents a text file as a Perl array, so a record locator can simply be an index into the array, and a record object then becomes something like:
{
db => $db,
recno => 37,
}
The change log inside the database object looks something like:
{ 0 => no change,
1 => no change,
2 => "color" field was set to "purple",
3 => no change,
4 => "size" field was set to "unusually large",
...
}
This happily gets rid of the garbage collection problem I had been
trying to solve in the first place.Using Tie::File also eliminates a lot of I/O issues that I had solved before, and gets all the I/O code out of the database module. I had already been thinking about getting rid of the explicit I/O and having the database module depend on Tie::File, and when I recognized the lurking record object identity problem, I was convinced that it had to happen sooner rather than later. Having done it, I'm really pleased with the outcome.
[Other articles in category /prog] permanent link
Fri, 07 Jul 2006
On design
I'm writing this Perl module called FlatFile, which is
supposed to provide lightweight simple access to flat-file databases,
such as the Unix password file. An interesting design issue came up,
and since I think that understanding is usually best served by
minuscule examination
of specific examples, that's what I'm going to do.
The basic usage of the module is as follows: You create a database object that represents the entire database:
my $db = FlatFile->new(FILE => "/etc/passwd",
FIELDS => ['username', 'password', 'uid', 'gid',
'gecos', 'homedir', 'shell'],
FIELDSEP => ':',
) or die ...;
Then you can do queries on the database:
my @roots = $db->lookup(uid => 0);
This returns a list of Record objects. (Actually it returns
a list of FlatFile::Record::A objects, where
FlatFile::Record::A is a dynamically-generated class that was
manufactured at the time you did the new call, and which
inherits from FlatFile::Record, but we can ignore that here.)
Once we have the Record objects, we can query them or modify
them:
for my $root (@roots) {
if ($root->username eq 'root') {
$root->set_shell('/bin/false');
} else {
$root->delete;
}
}
This loops over the records that were selected in the earlier call and
examines the username field in each one. if the username is
root, the program sets the shell in the record to
/bin/false; otherwise it deletes the record entirely.Since lookup returns all the matching records, there is the question of what this should do:
my $root = $db->lookup(uid => 0);
Here we have provided enough room for at most one root user. What if
there is more than one?Every Perl function needs to make a decision about this issue. The function could be called in list context or in scalar context, and you need to choose the two behaviors sensibly. Here are some possibilities for what lookup might do if called in scalar context:
- die unconditionally
- return the number of matching records, analogous to the builtin
grep function or the @array syntax
- return the single matching record, if there is only one, and die
if there is more than one.
- return the first matching record, and discard the others
- return a reference to an array of all matching records
- return an iterator object which can be used to access all the
matching records
How to decide on the best behavior? This is the kind of problem that I really enjoy. What will people expect? What will they want? What do they need?
Two important criteria are:
- Difficulty: Whatever I provide should be something that's not easy to get any
other way.
- Usefulness: Whatever I provide should be something that people will use a lot.
my $ref = [ $db->lookup(...) ];
Or they can subclass the Record module and add a new one-line
method that does the same:
sub lookup_ref {
my $self = shift;
[ $self->lookup(@_) ];
}
Similarly, behavior #2 (return a count) is so easy to get that
supporting it directly would probably not be a good use of my code or
my precious interface space:
my $N_recs = () = $db->lookup(...);
I had originally planned to do #3 (require that the query produce a
single record, on pain of death), and here's why: in my first forays
into programming with this module, I frequently found myself writing
things like my $rec = $db->lookup(...) without meaning to,
and in spite of the fact that I had documented the behavior in scalar
context as being undefined. I kept doing it unintentionally in cases
where I expected only one record to be returned. So each time I wrote
this code, I was putting in an implicit assumption that there would be
only one match. I would have been quite surprised in each case if
there had actually been multiple matches. That's the sort of
assumption that you might like to have automatically checked.I ran the question by the folks on IRC, and reaction against this design was generally negative. Folks said that it's not the module's job to try to discern the programmer's intention and enforce this inference by committing suicide.
I can certainly get behind that point of view. I once wrote an article complaining bitterly about modules that call die. I said it was like when you're having tea and crumpets on your 112-piece Spode china set, and you accidentally chip the teacup, and the butler comes running in, crying "Don't worry, Master! I'll take care of that for you!" and then he whips out a hammer and smashes all 112 pieces of china to tiny bits.
I don't think the point applies here, though. I had mentioned it in connection with the Text::ParseWords module, which would throw an exception if the input string was unparseable, hardly an uncommon occurrence, and one that was entirely unavoidable: if I knew that the string would be unparseable, I wouldn't be calling Text::ParseWords to parse it.
Folks on IRC said that when the method might call die, you have to wrap every call to it in an exception handler, which I certainly agree is a pain in the ass. But in this example, you do not have to do that. Here, to prevent the function from dying is very easy: just call it in list context; then it will never die. If what you want is behavior #4, to have it discard all the records but the first one, that is easy to get, regardless of the design I adopt for scalar context behavior:
my ($rec) = $db->lookup(...);
This argues against #4 (return the first matching record) in the same
way that we argued against #2 and #5 already: it's so very easy to do
already, maybe we don't need an even easier way to do it. But if so,
couldn't the programmer just:
sub lookup_first {
my $self = shift;
my ($rec) = $self->lookup(@_);
return $rec;
}
A counterargument in favor of #4 might be based on the usefulness
criterion: perhaps this behavior is so commonly wanted that we
really do need an even easier way to do it.I was almost persuaded by the strong opinion in favor of #4, but then Roderick Schertler spoke up in favor of #3, for basically the reasons I set forth. I consider M. Schertler to have higher-than-normal reliability on matters of this type, so his opinion counterbalances several of the counteropinions on the other side. #3 is not too difficult to get, but still scores higher than most of the others on the difficulty scale. There doesn't seem to be a trivial inline expression of it, as there was with #2, #4, and #5. You would have to actually write a method, or else do something nasty like:
(my ($rec) = $db->lookup(...)) < 2 or die ...;
What about the other proposed behaviors? #1 (unconditional fatality)
is simple, but both criteria seem to argue against it. It does,
however, have the benefit of being a good temporary solution since it
is easy to change without breaking backward compatibility. Were I to
adopt it, it would be very unlikely (although not impossible) that
anyone would write a program that would depend on that behavior; I
would then be able to change it later on. #6 (return an iterator object) is very tempting, because it is the only one that scores high on the difficulty criterion scale: it is difficult or impossible to do this any other way, so by providing it, I am providing a real service to users of the module, rather than yet another way to do the same thing. The module's user cannot implement a good iterator interface as a wrapper around lookup, because lookup always searches the entire database before it returns, and allocates enough memory to store every returned record, whereas a good iterator interface will search only as far as is necessary to find the next matching record, and will store only one record at a time.
This performance argument would be more important if we expected the databases to be very large. But since this is a module for manipulating plain text files, we can expect that they will not be too big, and perhaps the time and memory costs of searching them will be relatively small, so perhaps this design will score fairly low on the usefulness scale.
I still haven't made up my mind, although writing this article has pushed me strongly toward #6. I would be glad to receive email on the matter.
[Other articles in category /prog] permanent link
Mon, 15 May 2006
Creeping featurism and the ratchet effect
"Creeping featurism" is a well-known phenomenon in the software
world. It refers to the tendency of software to acquire more and more
features, to the ultimate detriment of its usability. Software with
more and more features is harder to learn to use; it's harder to
document effectively. Perhaps most important, it is harder to
maintain; the more complicated software is, the more likely it is to
have bugs. Partly this is because the different features interact
with one another in unanticipated ways; partly it is just that there
is more stuff to spend the maintenance budget on.
But the concept of "creeping featurism" his wider applicability than just to program features. We can recognize it in other contexts.
For example, someone is reading the Perl manual. They read the section on the unpack function and they find it confusing. So they propose a documentation patch to add a couple of sentences, explicating the confusing point in more detail.
It seems like a good idea at the time. But if you do it over and over—and we have—you end up with a 2,000 page manual—and we did.
The real problem is that it's easy to see the benefit of any proposed addition. But it is much harder to see the cost of the proposed addition, that the manual is now 0.002% larger.
The benefit has a poster child, an obvious beneficiary. You can imagine a confused person in your head, someone who happens to be confused in exactly the right way, and who is miraculously helped out by the presence of the right two sentences in the exact right place.
The cost has no poster child. Or rather, the poster child is much harder to imagine. This is the person who is looking for something unrelated to the two-sentence addition. They are going to spend a certain amount of time looking for it. If the two-sentence addition hadn't been in there, they would have found what they were looking for. But the addition slowed them down just enough that they gave up without finding what they needed. Although you can grant that such a person might exist, they really aren't as compelling as the confused person who is magically assisted by timely advice.
Even harder to imagine is the person who's kinda confused, and for whom the extra two sentences, clarifying some obscure point about some feature he wasn't planning to use in the first place, are just more confusion. It's really hard to understand the cost of that.
But the benefit, such as it is, comes in one big lump, whereas the cost is distributed in tiny increments over a very large population. The benefit is clear, and the cost is obscure. It's easy to make a specific argument in favor of any particular addition ("people might be confused by X, so I'm going to explain it in more detail") and it's hard to make such an argument against the addition. And conversely: it's easy to make the argument that any particular bit of text should stay in, hard to argue that it should be removed.
As a result, there's what I call a "ratchet effect": you can make the manual bigger, one tiny notch at a time, and people do. But having done so, you can't make it smaller again; someone will object to almost any proposed deletion. The manual gets bigger and bigger, worse and worse organized, more and more unusable, until finally it collapses under its own weight and all you can do is start over again.
You see the same thing happen in software, of course. I maintain the Text::Template Perl module, and I frequently get messages from people saying that it should have some feature or other. And these people sometimes get quite angry when I tell them I'm not going to put in the feature they want. They're angry because it's easy to see the benefit of adding another feature, but hard to see the cost. "If other people don't like it," goes the argument, "they don't have to use it." True, but even if they don't use it, they still pay the costs of slightly longer download times, slightly longer compile times, a slightly longer and more confusing manual, slightly less frequent maintenance updates, slightly less prompt bug fix deliveries, and so on. It is so hard to make this argument, because the cost to any one person is so very small! But we all know where the software will end up if I don't make this argument every step of the way: on the slag heap.
This has been on my mind on and off for years. But I just ran into it in a new context.
Lately I've been working on a book about code style and refactoring in Perl. One thing you see a lot in Perl programs written by beginners is superfluous parentheses. For example:
next if ($file =~ /^\./);
next if !($file =~ (/[0-9]/));
next if !($file =~ (/txt/));
Or:
die $usage if ($#ARGV < 0);
There are a number of points I want to make about this. First, I'd
like to express my sympathy for Perl programmers, because Perl has
something like 95 different operators at something like 17 different
levels of precedence, and so nobody knows what all the precedences are
and whether parentheses are required in all circumstances. Does the
** operator have higher or lower precedence than the
<<= operator? I really have no idea.So the situation is impossible, at least in principle, and yet people have to deal with it somehow. But the advice you often hear is "if you're not sure of the precedence, just put in the parentheses." I think that's really bad advice. I think better advice would be "if you're not sure of the precedence, look it up."
Because Perl's Byzantine operator table is not responsible for all the problems. Notice in the examples above, which are real examples, taken from real code written by other people: Many of the parentheses there are entirely superfluous, and are not disambiguating the precedence of any operators. In particular, notice the inner parentheses in:
next if !($file =~ (/txt/));
Inside the inner parentheses, there are no operators! So they cannot
be disambiguating any precedence, and they are completely unnecessary:
next if !($file =~ /txt/);
People sometimes say "well, I like to put them in anyway, just to be
sure." This is pure superstition, and we should not tolerate it in
people who purport to be engineers. Engineers should be capable of
making informed choices, based on technical realities, not on some
creepy feeling in their guts that perhaps a failure to sprinkle enough
parentheses over their program will invite the wrath the Moon God.By saying "if you're not sure, just avoid the problem" we are encouraging this kind of fearful, superstitious approach to the issue. That approach would be appropriate if it were the only way to deal with the issue, but fortunately it is not. There is a more rational approach: you can look it up, or even try an experiment, and then you will know whether the parentheses are required in a particular case. Then you can make an informed decision about whether to put them in.
But when I teach classes on this topic, people sometimes want to take the argument even further: they want to argue that even if you know the precedence, and even if you know that the parentheses are not required, you should put them in anyway, because the next person to see the code might not know that.
And there we see the creeping featurism argument again. It's easy to see the potential benefit of the superfluous parentheses: some hapless novice maintenance programmer might misunderstand the expression if I don't put them in. It's much harder to see the cost: The code is fractionally harder for everyone to read and understand, novice or not. And again, the cost of the extra parentheses to any particular person is so small, so very small, that it is really hard to make the argument against it convincingly. But I think the argument must be made, or else the code will end up on the slag heap much faster than it would have otherwise.
Programming cannot be run on the convoy system, with the program code written to address the most ignorant, uneducated programmer. I think you have to assume that the next maintenance programmer will be competent, and that if they do not know what the expression means, they will look up the operator precedence in the manual. That assumption may be false, of course; the world is full of incompetent programmers. But no amount of parentheses are really going to help this person anyway. And even if they were, you do not have to give in, you do not have to cater to incompetence. If an incompetent programmer has trouble understanding your code, that is not your fault; it is their fault for being incompetent. You do not have to take special steps to make your code understandable even by incompetents, and you certainly should not do so at the expense of making it harder for competent programmers to read and understand, no, not to the tiniest degree.
The advice that one should always put in the parentheses seems to me to be going in the wrong direction. We should be struggling for higher standards, both for ourselves and for our associates. The conventional advice, it seems to me, is to give up.
[Other articles in category /prog] permanent link
Sat, 04 Mar 2006
Structured BASIC
Aristotle Pagaltzis
reminisces about programming microcomputers in BASIC in the
1980s:
That's what I started with, on the Acorn Electron. And I remember being excited about finding and understanding DEF FN. I also remember my disappointment about how limited it was. I remember my frustration whenever BASIC forced me into writing messy code.I remember my frustration with this too. I realized fairly early on that it was important to organize one's code in a modular fashion. My clearest memory of this was in developing an Adventure-style program. Each of the locations in the world was assigned a sequence number. Location #23 was handled by lines 2300--2399 of the program. Lines 2300--2319 would print the description of the location. Line 2320 would set the variables that recorded the player's location, and called the subroutine to print the descriptions of the other objects at that location. Line 2380 would call the subroutine that prompted the user for their next command. Other lines in between would provide the implementation of whatever special effects were required for that location.
All the important utility subroutines were at mnemonic line numbers; the main loop was at line 50000, and the command processing was at 51000. Special handling for objects was in the 40000 range, with one hundred statement numbers reserved for each object.
After each user command was processed, control was dispatched back to the appropriate part of the program, depending on where the player was now. Microsoft BASIC didn't have a computed GOTO, so the dispatch was performed by a jump table. I was unhappy with the jump table, recognizing that it didn't scale well.
Object sizes and descriptions were stored in a table. I don't know why I didn't store the location descriptions in the table in the same way, but I suspect that I tried and found that my microcomputer didn't have enough string memory. I also discovered that the algorithm that mapped statement numbers to code did not scale well to programs with a lot of numbered statements; editing the program grew intolerably slow once the world contained more than about fifty locations.
Still, I was pleased with the outcome. My goal (at the tender age of sixteen, or whatever) had been to adopt conventions that made it easy to extend or modify the world and to add new locations or objects, and I felt at the time that I had achieved that.
M. Pagaltzis says:
I guess I have a natural penchant for structured code. Penchant? Instinct.I think anyone who is really interested in writing programs in BASIC and who reflects on the results of his projects is going to come to the conclusion that BASIC is a very poor tool for the job. These problems force themselves on everyone, and if you are thoughtful you will see the problems and try to come up with some techniques to solve them.
I really wish I could see those old programs again. I'm sure I would learn a lot from them.
I do have some code I wrote in C as long ago as 1987. I remember that shortly after that I got sick of programming and took a vacation from it for a year.
One day the following year I was reading netnews, and I overheard a colleague complaining about his CS homework. He had to write a program in C to count the number of occurrences of each word in its input, using a binary tree to store the words. I said he was complaining about nothing and that I, a math major, could turn out such a program in two hours. I don't know why I said this, since I hadn't done any C programming in a year, and I didn't have any significant experience with C, but I was inspired, and I did finish it quickly, and it worked. I have been programming regularly ever since. I still have the source code for that program.
Here's the funny thing about the programs from that time: when I look at the pre-vacation programs, they look to me as though they were written by someone else. When I look at the tree-sort program or any other program I have written since then, I recognize it as my own code.
I don't know what happened in my brain during my one-year vacation, but my current programming style first emerged in that tree-sort program, and the code from after the break has all been a lot better than the code I wrote before.
I'd like to take another vacation, but I can't now, because I have to earn a living.
[Other articles in category /prog] permanent link
Mon, 30 Jan 2006
Rotten code in a ProFTPD plugin module
One of my work colleagues asked me to look at a piece of C source code
today. He was tracking down a bug in the FTP server. He thought he
had traced it to this spot, and wanted to know if I concurred and if I
agreed with his suggested change.
Here's the (exceptionally putrid) (relevant portion of the) code:
static int gss_netio_write_cb(pr_netio_stream_t *nstrm, char *buf,size_t buflen) {
int count=0;
int total_count=0;
char *p;
OM_uint32 maj_stat, min_stat;
OM_uint32 max_buf_size;
...
/* max_buf_size = maximal input buffer size */
p=buf;
while ( buflen > total_count ) {
/* */
if ( buflen - total_count > max_buf_size ) {
if ((count = gss_write(nstrm,p,max_buf_size)) != max_buf_size )
return -1;
} else {
if ((count = gss_write(nstrm,p,buflen-total_count)) != buflen-total_count )
return -1;
}
total_count = buflen - total_count > max_buf_size ? total_count + max_buf_size : buflen;
p=p+total_count;
}
return buflen;
}
(You know there's something wrong when the comment says "maximal input
buffer size", but the buffer is for performing output. I have not
looked at any of the other code in this module, which is 2,800 lines
long, so I do not know if this chunk is typical.)
Mr. Colleague suggested that p=p+total_count was wrong, and
should be replaced with p=p+max_buf_size. I agreed that it
was wrong, and that his change would fix the problem, although I
suggested that p += count would be a better change.
Mr. Colleague's change, although it would no longer manifest the bug,
was still "wrong" in the sense that it would leave p pointing
to a garbage location (and incidentally invokes behavior not defined
by the C language standard) whereas my change would leave p
pointing to the end of the buffer, as one would expect.Since this is a maintenance programming task, I recommended that we not touch anything not directly related to fixing the bug at hand. But I couldn't stop myself from pointing out that the code here is remarkably badly written. Did I say "exceptionally putrid" yet? Oh, I did.
Good. It stinks like a week-old fish.
The first thing to notice is that the expression buflen - total_count appears four times in only nine lines of code—five if you count the buflen > total_count comparison. This strongly suggests that the algorithm would be more clearly expressed in terms of whatever buflen - total_count really is. Since buflen is the total number of characters to be written, and total_count is the number of characters that have been written, buflen - total_count is just the number of characters remaining. Rather than computing the same expression four times, we should rewrite the loop in terms of the number of characters remaining.
size_t left_to_write = buflen;
while ( left_to_write > 0 ) {
/* */
if ( left_to_write > max_buf_size ) {
if ((count = gss_write(nstrm,p,max_buf_size)) != max_buf_size )
return -1;
} else {
if ((count = gss_write(nstrm,p,left_to_write)) != left_to_write )
return -1;
}
total_count = left_to_write > max_buf_size ? total_count + max_buf_size : buflen;
p=p+total_count;
left_to_write -= count;
}
Now we should notice that the two calls to gss_write are
almost exactly the same. Duplicated code like this can almost always
be eliminated, and eliminating it almost always produces a favorable
result. In this case, it's just a matter of introducing an auxiliary
variable to record the amount that should be written:
size_t left_to_write = buflen, write_size;
while ( left_to_write > 0 ) {
write_size = left_to_write > max_buf_size ? max_buf_size : left_to_write;
if ((count = gss_write(nstrm,p,write_size)) != write_size )
return -1;
total_count = left_to_write > max_buf_size ? total_count + max_buf_size : buflen;
p=p+total_count;
left_to_write -= count;
}
At this point we can see that write_size is going to be
max_buf_size for every write except possibly the last one, so
we can simplify the logic the maintains it:
size_t left_to_write = buflen, write_size = max_buf_size;
while ( left_to_write > 0 ) {
if (left_to_write < max_buf_size)
write_size = left_to_write;
if ((count = gss_write(nstrm,p,write_size)) != write_size )
return -1;
total_count = left_to_write > max_buf_size ? total_count + max_buf_size : buflen;
p=p+total_count;
left_to_write -= count;
}
Even if we weren't here to fix a bug, we might notice something fishy:
left_to_write is being decremented by count, but
p, the buffer position, is being incremented by
total_count instead. In fact, this is exactly the bug that
was discovered by Mr. Colleague. Let's fix it:
size_t left_to_write = buflen, write_size = max_buf_size;
while ( left_to_write > 0 ) {
if (left_to_write < max_buf_size)
write_size = left_to_write;
if ((count = gss_write(nstrm,p,write_size)) != write_size )
return -1;
total_count = left_to_write > max_buf_size ? total_count + max_buf_size : buflen;
p += count;
left_to_write -= count;
}
We could fix up the line the maintains the total_count
variable so that it would be correct, but since total_count
isn't used anywhere else, let's just delete it.
size_t left_to_write = buflen, write_size = max_buf_size;
while ( left_to_write > 0 ) {
if (left_to_write < max_buf_size)
write_size = left_to_write;
if ((count = gss_write(nstrm,p,write_size)) != write_size )
return -1;
p += count;
left_to_write -= count;
}
Finally, if we change the != write_size test to <
0, the function will correctly handle partial writes, should
gss_write be modified in the future to perform them:
size_t left_to_write = buflen, write_size = max_buf_size;
while ( left_to_write > 0 ) {
if (left_to_write < max_buf_size)
write_size = left_to_write;
if ((count = gss_write(nstrm,p,write_size)) < 0 )
return -1;
p += count;
left_to_write -= count;
}
We could trim one more line of code and one more state change by
eliminating the modification of p:
size_t left_to_write = buflen, write_size = max_buf_size;
while ( left_to_write > 0 ) {
if (left_to_write < max_buf_size)
write_size = left_to_write;
if ((count = gss_write(nstrm,p+buflen-left_to_write,write_size)) < 0 )
return -1;
left_to_write -= count;
}
I'm not sure I think that is an improvement. (My idea is that if we
do this, it would be better to create a p_end variable up
front, set to p+buflen, and then use p_end -
left_to_write in place of p+buflen-left_to_write. But
that adds back another variable, although it's a constant one, and the
backward logic in the calculation might be more confusing than the
thing we were replacing. Like I said, I'm not sure. What do you
think?)Anyway, I am sure that the final code is a big improvement on the original in every way. It has fewer bugs, both active and latent. It has the same number of variables. It has six lines of logic instead of eight, and they are simpler lines. I suspect that it will be a bit more efficient, since it's doing the same thing in the same way but without the redundant computations, although you never know what the compiler will be able to optimize away.
Right now I'm engaged in writing a book about this sort of cleanup and renovation for Perl programs. I've long suspected that the same sort of processes could be applied to C programs, but this is the first time I've actually done it.
The funny thing about this code is that it's performing a task that I thought every C programmer would already have known how to do: block-writing of a bufferfull of data. Examples of the right way to do this are all over the place. I first saw it done in Marc J. Rochkind's superb book Advanced Unix Programming around 1989. (I learned from the first edition, but the link to the right is for the much-expanded second edition that came out in 2004.) I'm sure it must pop up all over the Stevens books.
But the really exciting thing I've learned about code like this is that it doesn't matter if you don't already know how to do it right, because you can turn the wrong code into the right code, as we did here, by noticing a few common problems, like duplicate tests and repeated subexpressions, and applying a few simple refactorizations to get rid of them. That's what my book will be about.
(I am also very pleased that it has taken me 37 blog entries to work around to discussing any programming-related matters.)
[Other articles in category /prog] permanent link
Wed, 31 Dec 1969I often write about Git but the Git articles are mixed in with everything else. Someday I will rearrange everything. In the meantime I will try to keep a list of links on this page.
- Another Git catastrophe cleaned up
- Another trivial utility:
git-q - Automatically checking for syntax errors with Git's
pre-commithook git log --author=...confused megit log --followenthusiastically tracks empty files- And what happened when I tried to fix this: Perils of hacking on mature software
- Git PSA:
git-rev-parse - Git remote branches and Git's missing terminology
- Git wishlist: aggregate changes across non-contiguous commits
- Git's rejected push error
- A hack for getting the email address Git will use for a commit
- Hacking the
gitshell prompt - How I got four errors into a one-line program (
prepare-commit-hook)) - How to recover lost files added to Git but not committed
- I wish people would stop insisting that Git branches are nothing but refs
- Notes on using
git-replaceto get rid of giant objects - Reordering git commits (not patches) with interactive rebase
- Reordering git commits with
git-commit-tree - Rewriting published history in Git
- Things I wish everyone knew about Git:
- Srtst vrsn: Two things everyone should know about Git
- Part I: General strategy and READ THIS
- Part II: It's hard to lose stuff and if you do you can find it again
- Part III: Misc (Branches are fictitious, committing partial changes; push and fetch; tracking branches)
- Why didn't
git add -pwork?
[Other articles in category /prog/git] permanent link
You might be interested in the Recurse Center, one of my favorite programming communities. Here's what Julia Evans has written about it.