Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| J | |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 251 |
| Programming | 102 |
| Language | 98 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Tue, 28 Jan 2020
Today I learned that James Blaine (U.S. Speaker of the House, senator, perennial presidential candidate, and Secretary of State under Presidents Cleveland, Garfield, and Arthur; previously) was the namesake of the notorious “Blaine Amendments”. These are still an ongoing legal issue!
The Blaine Amendment was a proposed U.S. constitutional amendment rooted in anti-Catholic, anti-immigrant sentiment, at a time when the scary immigrant bogeymen were Irish and Italian Catholics.
The amendment would have prevented the U.S. federal government from providing aid to any educational institution with a religious affiliation; the specific intention was to make Catholic parochial schools ineligible for federal education funds. The federal amendment failed, but many states adopted it and still have it in their state constitutions.
Here we are 150 years later and this is still an issue! It was the subject of the 2017 Supreme Court case Trinity Lutheran Church of Columbia, Inc. v. Comer. My quick summary is:
The Missouri state Department of Natural Resources had a program offering grants to licensed daycare facilities to resurface their playgrounds with shredded tires.
In 2012, a daycare facility operated by Trinity Lutheran church ranked fifth out of 44 applicants according to the department’s criteria.
14 of the 44 applicants received grants, but Trinity Lutheran's daycare was denied, because the Missouri constitution has a Blaine Amendment.
The Court found (7–2) that denying the grant to an otherwise qualified daycare just because of its religious affiliation was a violation of the Constitution's promises of free exercise of religion. (Full opinion)
It's interesting to me that now that Blaine is someone I recognize, he keeps turning up. He was really important, a major player in national politics for thirty years. But who remembers him now?
[Other articles in category /law] permanent link
Fri, 17 Jan 2020As Middle English goes, Pylgremage of the Sowle (unknown author, 1413) is much easier to read than Chaucer:
He hath iourneyed by the perylous pas of Pryde, by the malycious montayne of Wrethe and Enuye, he hath waltred hym self and wesshen in the lothely lake of cursyd Lechery, he hath ben encombred in the golf of Glotony. Also he hath mysgouerned hym in the contre of Couetyse, and often tyme taken his rest whan tyme was best to trauayle, slepyng and slomeryng in the bed of Slouthe.
I initially misread “Enuye” as “ennui”, understanding it as sloth. But when sloth showed up at the end, I realized that it was simpler than I thought, it's just “envy”.
[Other articles in category /book] permanent link
Thu, 16 Jan 2020
A serious proposal to exploit the loophole in the U.S. Constitution
In 2007 I described an impractical scheme to turn the U.S. into a dictatorship, or to make any other desired change to the Constitution, by having Congress admit a large number of very small states, which could then ratify any constitutional amendments deemed desirable.
An anonymous writer (probably a third-year law student) has independently discovered my scheme, and has proposed it as a way to “fix” the problems that they perceive with the current political and electoral structure. The proposal has been published in the Harvard Law Review in an article that does not appear to be an April Fools’ prank.
The article points out that admission of new states has sometimes been done as a political hack. It says:
Republicans in Congress were worried about Lincoln’s reelection chances and short the votes necessary to pass the Thirteenth Amendment. So notwithstanding the traditional population requirements for statehood, they turned the territory of Nevada — population 6,857 — into a state, adding Republican votes to Congress and the Electoral College.
Specifically, the proposal is that the new states should be allocated out of territory currently in the District of Columbia (which will help ensure that they are politically aligned in the way the author prefers), and that a suitable number of new states might be one hundred and twenty-seven.
[Other articles in category /law] permanent link
Tue, 14 Jan 2020
More about triple border points
[ Previously ]
A couple of readers wrote to discuss tripoints, which are places where three states or other regions share a common border point.
Doug Orleans told me about the Tri-States Monument near Port Jervis, New York. This marks the approximate location of the Pennsylvania - New Jersey - New York border. (The actual tripoint, as I mentioned, is at the bottom of the river.)
I had independently been thinking about taking a drive around the entire border of Pennsylvania, and this is just one more reason to do that. (Also, I would drive through the Delaware Water Gap, which is lovely.) Looking into this I learned about the small town of North East, so-named because it's in the northeast corner of Erie County. It's also the northernmost point in Pennsylvania.
(I got onto a tangent about whether it was the northeastmost point in Pennsylvania, and I'm really not sure. It is certainly an extreme northeast point in the sense that you can't travel north, east, or northeast from it without leaving the state. But it would be a very strange choice, since Erie County is at the very western end of the state.)
My putative circumnavigation of Pennsylvanias would take me as close as possible to Pennsylvania's only international boundary, with Ontario; there are Pennsylvania - Ontario tripoints with New York and with Ohio. Unfortunately, both of them are in Lake Erie. The only really accessible Pennsylvania tripoints are the one with West Virginia and Maryland (near Morgantown) and Maryland and Delaware (near Newark).
These points do tend to be marked, with surveyors’ markers if nothing else. Loren Spice sent me a picture of themselves standing at the tripoint of Kansas, Missouri, and Oklahoma, not too far from Joplin, Missouri.
While looking into this, I discovered the Kentucky Bend, which is an exclave of Kentucky, embedded between Tennessee and Missouri:
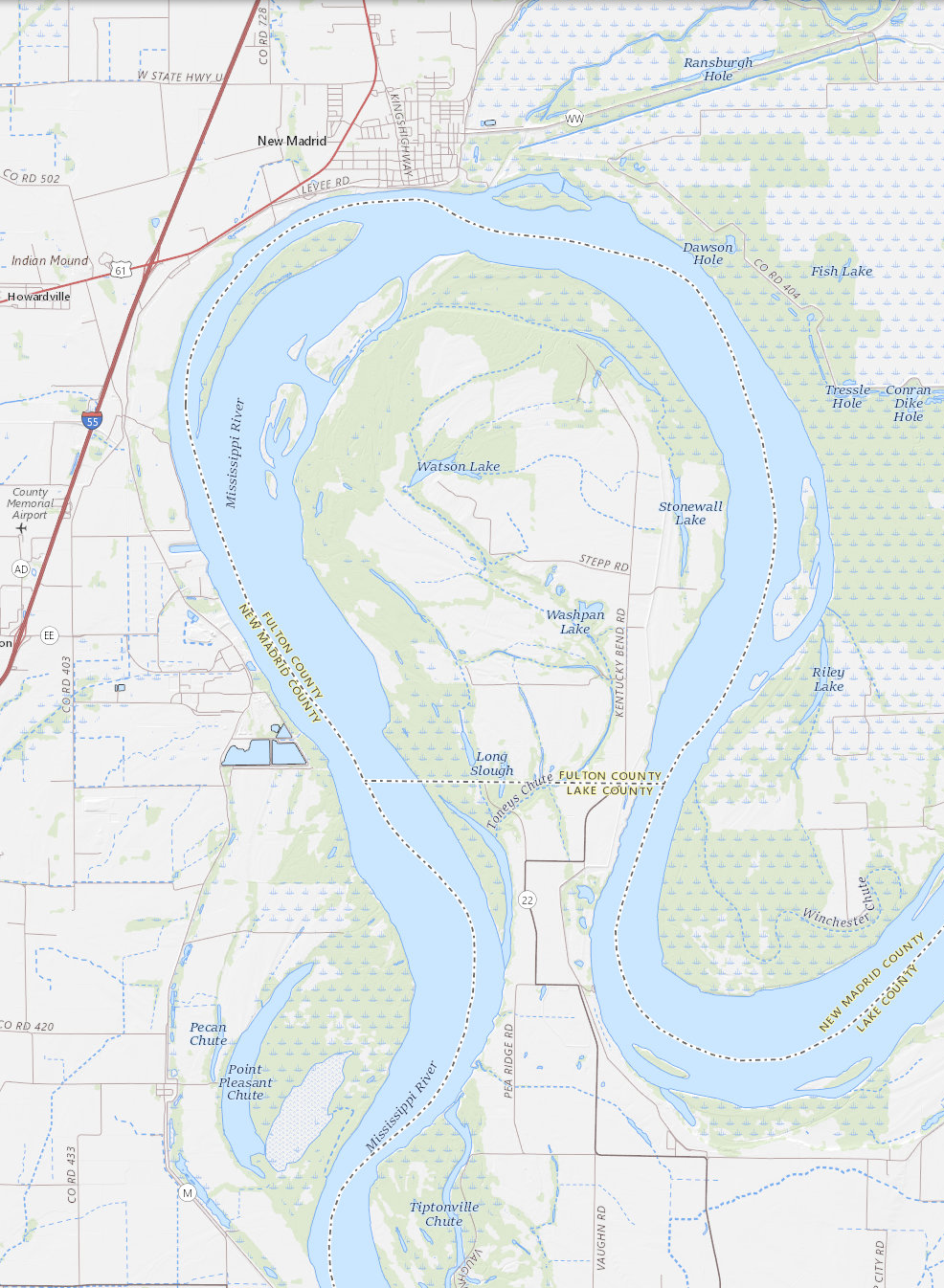
The “bubble” here is part of Fulton County, Kentucky. North, across the river, is New Madrid County, Missouri. The land border of the bubble is with Lake County, Tennessee.
It appears that what happened here is that the border between Kentucky and Missouri is the river, with Kentucky getting the territory on the left bank, here the south side. And the border between Kentucky and Tennessee is a straight line, following roughly the 36.5 parallel, with Kentucky getting the territory north of the line. The bubble is south of the river but north of the line.
So these three states have not one tripoint, but three, all only a few miles apart!

Finally, I must mention the Lakes of Wada, which are not real lakes, but rather are three connected subsets of the unit disc which have the property that every point on their boundaries is a tripoint.
[Other articles in category /misc] permanent link
Thu, 09 Jan 2020I'm a fan of geographic oddities, and a few years back when I took a road trip to circumnavigate Chesapeake Bay, I planned its official start in New Castle, DE, which is noted for being the center of the only circular state boundary in the U.S.:

The red blob is New Castle. Supposedly an early treaty allotted to Delaware all points west of the river that were within twelve miles of the State House in New Castle.
I drove to New Castle, made a short visit to the State House, and then began my road trip in earnest. This is a little bit silly, because the border is completely invisible, whether you are up close or twelve miles away, and the State House is just another building, and would be exactly the same even if the border were actually a semicubic parabola with its focus at the second-tallest building in Wilmington.
Whatever, I like going places, so I went to New Castle to check it out. Perhaps it was silly, but I enjoyed going out of my way to visit a point of purely geometric significance. The continuing popularity of Four Corners as a tourist destination shows that I'm not the only one. I don't have any plans to visit Four Corners, because it's far away, kinda in the middle of nowhere, and seems like rather a tourist trap. (Not that I begrudge the Navajo Nation whatever they can get from it.)
Four Corners is famously the only point in the U.S. where four state borders coincide. But a couple of weeks ago as I was falling asleep, I had the thought that there are many triple-border points, and it might be fun to visit some. In particular, I live in southeastern Pennsylvania, so the Pennsylvania-New Jersey-Delaware triple point must be somewhere nearby. I sat up and got my phone so I could look at the map, and felt foolish:
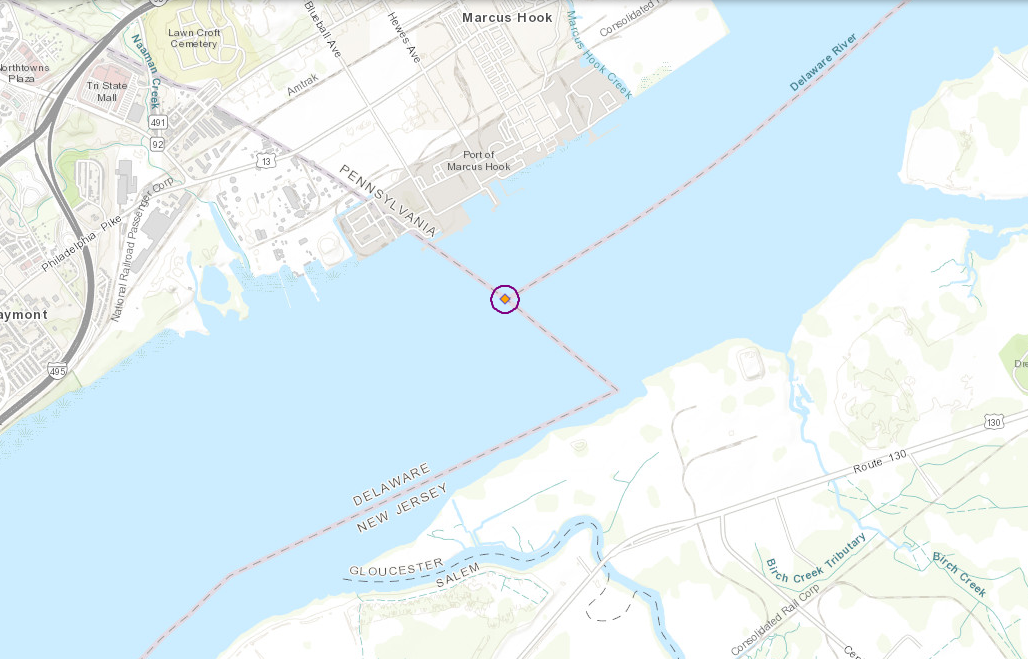
As you can see, the triple point is in the middle of the Delaware River, as of course it must be; the entire border between Pennsylvania and New Jersey, all the hundreds of miles from its northernmost point (near Port Jervis) to its southernmost (shown above), runs right down the middle of the Delaware.
I briefly considered making a trip to get as close as possible, and photographing the point from land. That would not be too inconvenient. Nearby Marcus Hook is served by commuter rail. But Marcus Hook is not very attractive as a destination. Having been to Marcus Hook, it is hard for me to work up much enthusiasm for a return visit.
But I may look into this further. I usually like going places and being places, and I like being surprised when I get there, so visting arbitrarily-chosen places has often worked out well for me. I see that the Pennsylvania-Delaware-Maryland triple border is near White Clay Creek State Park, outside of Newark, DE. That sounds nice, so perhaps I will stop by and take a look, and see if there really is white clay in the creek.
Who knows, I may even go back to Marcus Hook one day.
Addenda
20190114
More about nearby tripoints and related matters.
20201209
I visited the tripoint marker in White Clay Creek State Park.
20220422
More about how visting arbitrarily-chosen places has often worked out well for me. I have a superstitious belief in the power of Fate to bring me to where I am supposed to be, but rationally I understand that the true explanation is that random walks are likely to bring me to an interesting destination simply because I am easily interested and so find most destinations interesting.
20240831
I have now gone back to Marcus Hook to view the tripoint.
20250215
I somehow forgot to mention that back in August 2022 I made the drive up to Port Jervis to visit the NJ-NY-PA tripoint. It's in the river, of course, but there is a marker nearby on a tiny island that is used as a support for the I84 crossing of the Delaware River. As I recall, I saw a flock of geese.
I don't have the photos handy but I did at least save these screenshots:

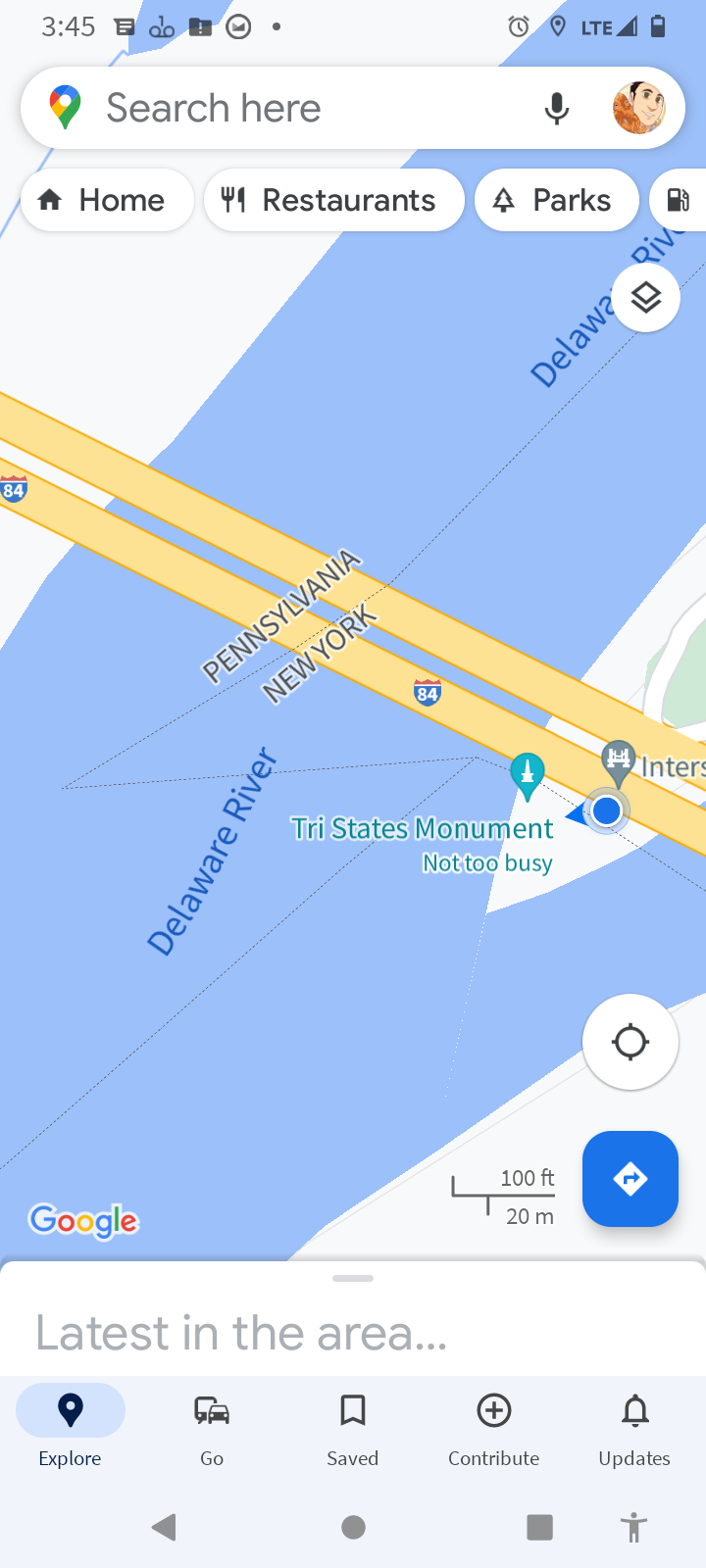
The marker is not as hard to get to as it might appear. The rest of the little island is a graveyard, and has a footpath from which you can easily reach the marker. The marker itself is a stone column about four feet high.
[Other articles in category /misc] permanent link
Wed, 08 Jan 2020
Unix bc command and its -l flag
In a recent article about Unix utilities, I wrote:
We need the
-lflag onbcbecause otherwise it stupidly does integer arithmetic.
This is wrong, as was kindly pointed out to me by Luke Shumaker. The
behavior of bc is rather more complicated than I said, and less
stupid. In the application I was discussing, the input was a string
like 0.25+0.37, and it's easy to verify that bc produces the
correct answer even without -l:
$ echo 0.25+0.37 | bc
.62
In bc, each number is
represented internally as !!m·10^{-s}!!, where !!m!! is in base 10 and
!!s!! is called the “scale”, essentially the number of digits after
the decimal point. For addition, subtraction, and multiplication, bc
produces a result with the correct scale for an exact result. For
example, when multiplying two numbers with scales a and b, the
result always has scale a + b, so the operation is performed with
exact precision.
But for division, bc doesn't know what scale it should use for the
result. The result of !!23÷7!! can't
be represented exactly, regardless of the scale used. So how should
bc choose how many digits to retain? It can't retain all of them,
and it doesn't know how many you
will want. The answer is: you tell it, by setting a special variable,
called scale. If you set scale=3 then !!23÷7!! will produce the
result !!3.285!!.
Unfortunately, if you don't set it — this is the stupid part — scale defaults to zero. Then
bc will discard everything after the decimal point, and tell you that
!!23÷7 = 3!!.
Long, long ago I was in the habit of manually entering scale=20 at
the start of every bc session. I eventually learned about -l,
which, among other things, sets the default scale to 20 instead of 0.
And I have used -l habitually ever since, even in cases like this,
where it isn't needed.
Many thanks to Luke Shumaker for pointing this out. M. Shumaker adds:
I think the mis-recollection/understanding of
-lsays something about your "memorized trivia" point, but I'm not quite sure what.
Yeah, same.
[Other articles in category /oops] permanent link
Tue, 07 Jan 2020
Social classes identified by letters
Looking up the letter E in the Big Dictionary, I learned that British sociologists were dividing social classes into lettered strata long before Aldous Huxley did it in Brave New World (1932). The OED quoted F. G. D’Aeth, “Present Tendencies of Class Differentiation”, The Sociological Review, vol 3 no 4, October, 1910:
The present class structure is based upon different standards of life…
A. The Loafer
B. Low-skilled labour
C. Artizan
D. Smaller Shopkeeper and clerk
E. Smaller Business Class
F. Professional and Administrative Class
G. The Rich
The OED doesn't quote further, but D’Aeth goes on to explain:
A. represents the refuse of a race; C. is a solid, independent and valuable class in society. … E. possesses the elements of refinement; provincialisms in speech are avoided, its sons are selected as clerks, etc., in good class businesses, e.g., banking, insurance.
Notice that in D’Aeth's classification, the later letters are higher classes. According to the OED this was typical; they also quote a similar classification from 1887 in which A was the lowest class. But the OED labels this sort of classification, with A at the bottom, as “obsolete”.
In Brave New World, you will recall, it is the in the other direction, with the Alphas (administrators and specialists), at the top, and the Epsilons (menial workers with artificially-induced fetal alcohol syndrome) at the bottom.
The OED's later quotations, from 1950–2014, all follow Huxley in putting class A at the top and E at the bottom. They also follow Huxley in having only five classes instead of seven or eight. (One has six classes, but two of them are C1 and C2.)
I wonder how much influence Brave New World had on this sort of classification. Was anyone before Huxley dividing British society into five lettered classes with A at the top?
[ By the way, I have been informed that this paper, which I have linked above, is “Copyright © 2020 by The Sociological Review Publication Limited. All rights are reserved.” This is a bald lie. Sociological Review Publication Limited should be ashamed of themselves. ]
[Other articles in category /lang] permanent link
Fri, 03 Jan 2020
Benchmarking shell pipelines and the Unix “tools” philosophy
Sometimes I look through the HTTP referrer logs to see if anyone is
talking about my blog. I use the f 11 command to extract the
referrer field from the log files, count up the number of occurrences
of each referring URL, then discard the ones that are internal
referrers from elsewhere on my blog. It looks like this:
f 11 access.2020-01-0* | count | grep -v plover
(I've discussed f before. The f 11 just
prints the eleventh field of each line. It is
essentially shorthand for awk '{print $11}' or perl -lane 'print
$F[10]'. The count utility is even simpler; it counts the number
of occurrences of each distinct line in its input, and emits a report
sorted from least to most frequent, essentially a trivial wrapper
around sort | uniq -c | sort -n. Civilization advances by extending the number of
important operations which we can perform without thinking about
them.)
This has obvious defects, but it works well enough. But every time I
used it, I wondered: is it faster to do the grep before the count,
or after? I didn't ever notice a difference. But I still wanted to
know.
After years of idly wondering this, I have finally looked into it. The point of this article is that the investigation produced the following pipeline, which I think is a great example of the Unix “tools” philosophy:
for i in $(seq 20); do
TIME="%U+%S" time \
sh -c 'f 11 access.2020-01-0* | grep -v plover | count > /dev/null' \
2>&1 | bc -l ;
done | addup
I typed this on the command line, with no backslashes or newlines, so it actually looked like this:
for i in $(seq 20); do TIME="%U+%S" time sh -c 'f 11 access.2020-01-0* | grep -v plover |count > /dev/null' 2>&1 | bc -l ; done | addup
Okay, what's going on here? The pipeline I actually want to analyze,
with f | grep| count, is
there in the middle, and I've already explained it, so let's elide it:
for i in $(seq 20); do
TIME="%U+%S" time \
sh -c '¿SOMETHING? > /dev/null' 2>&1 | bc -l ;
done | addup
Continuing to work from inside to out, we're going to use time to
actually do the timings. The time command is standard. It runs a
program, asks the kernel how long the program took, then prints
a report.
The time command will only time a single process (plus its
subprocesses, a crucial fact that is inexplicably omitted from the man
page). The ¿SOMETHING? includes a pipeline, which must be set up by
the shell, so we're actually timing a shell command sh -c '...'
which tells time to run the shell and instruct it to run the pipeline we're
interested in. We tell the shell to throw away the output of
the pipeline, with > /dev/null, so that the output doesn't get mixed
up with time's own report.
The default format for the report printed by time is intended for human consumption. We can
supply an alternative format in the $TIME variable. The format I'm using here is %U+%S, which comes out as something
like 0.25+0.37, where 0.25 is the user CPU time and 0.37 is the
system CPU time. I didn't see a format specifier that would emit the
sum of these directly. So instead I had it emit them with a + in
between, and then piped the result through the bc command, which performs the requested arithmetic
and emits the result. We need the -l flag on bc
because otherwise it stupidly does integer arithmetic. The time command emits its report to
standard error, so I use 2>&1
to redirect the standard error into the pipe.
[ Addendum 20200108: We don't actually need -l here; I was mistaken. ]
Collapsing the details I just discussed, we have:
for i in $(seq 20); do
(run once and emit the total CPU time)
done | addup
seq is a utility I invented no later than 1993 which has since
become standard in most Unix systems. (As with
netcat, I am not claiming to be the
first or only person to have invented this, only to have invented it
independently.) There are many variations of seq, but
the main use case is that seq 20 prints
1
2
3
…
19
20
Here we don't actually care about the output (we never actually use
$i) but it's a convenient way to get the for loop to run twenty
times. The output of the for loop is the twenty total CPU
times that were emitted by the twenty invocations of bc. (Did you know that
you can pipe the output of a loop?) These twenty lines of output are
passed into addup, which I wrote no later than 2011. (Why did it
take me so long to do this?) It reads a list of numbers and prints the
sum.
All together, the command runs and prints a single number like 5.17,
indicating that the twenty runs of the pipeline took 5.17 CPU-seconds
total. I can do this a few times for the original pipeline, with
count before grep, get times between 4.77 and 5.78, and then try
again with the grep before the count, producing times between 4.32
and 5.14. The difference is large enough to detect but too small to
notice.
(To do this right we also need to test a null command, say
sh -c 'sleep 0.1 < /dev/null'
because we might learn that 95% of the reported time is spent in running the shell, so the actual difference between the two pipelines is twenty times as large as we thought. I did this; it turns out that the time spent to run the shell is insignificant.)
What to learn from all this? On the one hand, Unix wins: it's
supposed to be quick and easy to assemble small tools to do whatever it is
you're trying to do. When time wouldn't do the arithmetic I needed
it to, I sent its output to a generic arithmetic-doing utility. When
I needed to count to twenty, I had a utility for doing that; if I
hadn't there are any number of easy workarounds. The
shell provided the I/O redirection and control flow I needed.
On the other hand, gosh, what a weird mishmash of stuff I had to
remember or look up. The -l flag for bc. The fact that I needed
bc at all because time won't report total CPU time. The $TIME
variable that controls its report format. The bizarro 2>&1 syntax
for redirecting standard error into a pipe. The sh -c trick to get
time to execute a pipeline. The missing documentation of the core
functionality of time.
Was it a win overall? What if Unix had less compositionality but I could use it with less memorized trivia? Would that be an improvement?
I don't know. I rather suspect that there's no way to actually reach that hypothetical universe. The bizarre mishmash of weirdness exists because so many different people invented so many tools over such a long period. And they wouldn't have done any of that inventing if the compositionality hadn't been there. I think we don't actually get to make a choice between an incoherent mess of composable paraphernalia and a coherent, well-designed but noncompositional system. Rather, we get a choice between a incoherent but useful mess and an incomplete, limited noncompositional system.
(Notes to self: (1) In connection with Parse::RecDescent, you once wrote
about open versus closed systems. This is another point in that
discussion. (2) Open systems tend to evolve into messes. But closed
systems tend not to evolve at all, and die. (3) Closed systems are
centralized and hierarchical; open systems, when they succeed, are
decentralized and organic. (4) If you are looking for another
example of a successful incoherent mess of composable paraphernalia,
consider Git.)
[ Addendum: Add this to the list of “weird mishmash of trivia”: There are two
time commands. One, which I discussed above, is a separate
executable, usually in /usr/bin/time. The other is built into the
shell. They are incompatible. Which was I actually using? I would
have been pretty confused if I had accidentally gotten the built-in
one, which ignores $TIME and uses a $TIMEFORMAT that is
interpreted in a completely different way. I was fortunate, and got
the one I intended to get. But it took me quite a while to understand
why I had! The appearance of the TIME=… assignment at the start of
the shell command disabled the shell's special builtin treatment of the
keyword time, so it really did use /usr/bin/time. This computer stuff
is amazingly complicated. I don't know how anyone gets anything done. ]
[ Addenda 20200104: (1) Perl's module ecosystem is another example of a
successful incoherent mess of composable paraphernalia. (2) Of the
seven trivia I included in my “weird mishmash”, five were related to
the time command. Is this a reflection on time, or is it just
because time was central to this particular example? ]
[ Addendum 20200104: And, of course, this is exactly what Richard Gabriel was thinking about in Worse is Better. Like Gabriel, I'm not sure. ]
[Other articles in category /Unix] permanent link
Thu, 02 Jan 2020
A sticky problem that evaporated
Back in early 1995, I worked on an incredibly early e-commerce site.
The folks there were used to producing shopping catalogs for
distribution in airplane seat-back pockets and such like, and they
were going to try bringing a catalog to this World-Wide Web thing
that people were all of a sudden talking about.
One of their clients was Eddie Bauer. They wanted to put up a product catalog with a page for each product, say a sweatshirt, and the page should show color swatches for each possible sweatshirt color.
“Sure, I can do that,” I said. “But you have to understand that the user may not see the color swatches exactly as you expect them to.” Nobody would need to have this explained now, but in early 1995 I wasn't sure the catalog folks would understand. When you have a physical catalog you can leaf through a few samples to make sure that the printer didn't mess up the colors.
But what if two months down the line the Eddie Bauer people were shocked by how many complaints customers had about things being not quite the right color, “Hey I ordered mulberry but this is more like maroonish.” Having absolutely no way to solve the problem, I didn't want to to land in my lap, I wanted to be able to say I had warned them ahead of time. So I asked “Will it be okay that there will be variations in how each customer sees the color swatches?”
The catalog people were concerned. Why wouldn't the colors be the same? And I struggled to explain: the customer will see the swatches on their monitor, and we have no idea how old or crappy it might be, we have no idea how the monitor settings are adjusted, the colors could be completely off, it might be a monochrome monitor, or maybe the green part of their RGB video cable is badly seated and the monitor is displaying everything in red, blue, and purple, blah blah blah… I completely failed to get the point across in a way that the catalog people could understand.
They looked more and more puzzled, but then one of them brightened up suddenly and said “Oh, just like on TV!”
“Yes!” I cried in relief. “Just like that!”
“Oh sure, that's no problem.” Clearly, that was what I should have said in the first place, but I hadn't thought of it.
I no longer have any idea who it was that suddenly figured out what Geek Boy's actual point was, but I'm really grateful that they did.
[Other articles in category /tech] permanent link