Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 250 |
| Programming | 102 |
| Language | 97 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Sun, 30 Apr 2023
Why use cycle notation for permutations?
Katara is taking a discrete mathematics course this semester, and was asked to prove that if !!D_n!! is the number of derangements of !!n!! objects, then !!D!! satisfies the recurrence $$D_n = (n-1)D_{n-1} + (n-1)D_{n-2}\tag{$\star$}$$ for !!n\gt 2!!. (A derangement is a permutation with no fixed points.) This is OEIS A000166. (We also have !!D_0=1, D_1=0!!).
She was struggling with this task, and I learned why: She was still thinking of permutations like this:
$$\begin{align} 1 & \to 2 \\ 2 & \to 4 \\ 3 & \to 5 \\ 4 & \to 1 \\ 5 & \to 3 \end{align} $$
when she should have been thinking of them like this:
$$(1\; 2\; 4)(3\; 5).$$
“Didn't they teach you about cycle notation?” I asked. Apparently not. (I'm not sure it's a very good class, but it's also possible that this was discussed in one of the lectures that she did not attend.)
Anyway the proof is not difficult, if you think of the cycle structure of the permutations. Let !!p!! be a derangement of size !!n>1!! and consider the location of !!n!! in its cycle structure. The element !!n!! is in some cycle, say one with length !!c!!. !!p!! has no fixed points, so !!c!! is at least !!2!!. If !!c!! is at least !!3!!, we can drop !!n!! from its cycle and still have a derangement of size !!n-1!!:
$$(n\; \ldots)c_2c_3\cdots \Rightarrow (\ldots)c_2c_3\cdots.\tag1$$
If !!n!! is in a cycle of length !!c=2!! and we drop it, then we no longer have a derangement, because we have a permutation which has the fixed point !!p(n)!!. Dropping this also does give us another derangement, of size !!n-2!!:
$$(n\; p(n))c_2c_3\cdots \Rightarrow \underbrace{\color{darkred}{(p(n))}}_{\text{fixed point!}} c_2c_3\cdots \Rightarrow c_2c_3\cdots.\tag2$$
In the former case !!(1)!! there are !!n-1!! positions at which we can insert !!n!! back into the smaller derangement, and each one produces a different permutation, so there are !!(n-1)D_{n-1}!! derangements we can obtain in this way. In the latter case !!(2)!! there are !!n-1!! choices for !!p(n)!!, the element that will share the !!2!!-cycle with !!n!!, so !!(n-1)D_{n-2}!! derangements we can obtain in this way. The total is the sum of these, given by !!(\star)!!.
But if you don't know about permutation cycle structure, you are missing the basic tool that lets you find this argument. To find it, you will probably end up reinventing the idea of cycle structure.
And if you don't know about the representation of permutations in cycle notation, you will have trouble thinking about the cycle structure.
Katara asked me about this in the parking lot outside her dorm just as I was about to drop her off at night, so I was not able to intelligently explain why the cycle structure is nearly always the right way to think about permutations. “It's just better,” I asserted baldly and unconvincingly. After I got home, I tried to think: why is the cycle notation better? It is better, but this is an empirical observation. What is the theoretical cause of its being better?
Most obviously, it's more compact, but this is not the main reason.
A permutation is a bijective function on some carrier set of labels: $$p: S\to S$$ so the only things you need to know about it are: what is !!S!!, and what is !!p!!? In some applications, !!S!! matters. For example, we might want to think of permutations of the English alphabet that leave the set !!\{A, E, I , O, U\}!! fixed.
But typically !!S!! is unimportant, as it is in the derangements problem. In counting derangements, we don't care whether the things being deranged are letters or numbers or hats or fruits or whatever; the identity of !!S!! is completely irrelevant and we took it to be !!\{1, 2, 3, \ldots, n\}!! only because the positive integers are a plentiful supply of items with short names.
And:
If you aren't interested in the labels, the cycle structure of a permutation is the only remaining property it has, because two permutations with the same cycle structure are identical under some change of labels.
Or in jargon, if you are thinking of the permutations as elements of the abstract symmetric group !!S_n!!, relabeling is a conjugation of !!S_n!!, and the cycle classes are exactly the conjugacy classes.
So the cycle structure is exactly the structure of a permutation that remains if you ignore the actual labels, and the cycle notation brings that structure to the foreground.
[Other articles in category /math] permanent link
Fri, 28 Apr 2023
Show how the student could have solved it
A few days ago I offered these maxims about pedagogy:
It's not enough to show the student the answer; you should try to show them how to find the answer.
It's not enough to show the student how you can find the answer; you should try to show them how they could have found the answer.
A nice illustration popped up on Math SE this morning. OP asks:
If all eigenvalues of a matrix are 0 or 1, does that imply the matrix is idempotent?
Shortly afterward a comment from PrincessEev said, opaquely:
The matrices $$\left[\begin{matrix} 0&x\\ 0&0 \end{matrix}\right]$$ are obvious counterexamples for !!x\ne 0!!.
Uh, they are? It wasn't obvious to me. I mean, I think I see why the eigenvalues must be zero, without doing the calculation. But where did this example come from?
But then later they redeemed themselves by adding another comment:
it was just my first instinct to try a few examples with what felt like a bold claim: matrices with enough well-placed zeroes tend to vanish when raising them to powers
I understand now! Yeah, I could have thought of that, but didn't. So the second comment actually taught me something, not what the answer is, which not very useful, because who cares?, but how to find the answer, which contains knowledge that might be generally useful.
[Other articles in category /math/se] permanent link
Mon, 24 Apr 2023Cynicism seems to many people like an unlimited resource. But it is like fiat currency in that it becomes valueless and contemptible when there is too much in circulation.
Cynicism should be saved, and used only when necessary.
[Other articles in category /misc] permanent link
Thu, 20 Apr 2023
Math SE report 2023-04: Simplest-possible examples, pointy regions, and nearly-orthogonal vectors
Polyhedra has more corners than facets
This one was a bit puzzling because it asked:
Is it true that [a polyhedron] has always more/as many corners than facets? I haven't found a counterexample…
(By ‘facets’ I assume OP meant ‘faces’.)
This is puzzling because there are so many counterexamples. For example, every dipyramid has this property. A dipyramid is what you get if you take two pyramids and glue their bases together. Maybe you want to say this is obscure, but an octahedron is a dipyramid and one might expect anyone asking about polyhedra to know about octahedra. I wonder what examples this person did consider?
In fact, for any polyhedron with !!F!! faces and !!V!! vertices, there is a corresponding “dual” polyhedron with !!V!! faces and !!F!! vertices, so for almost any polyhedron you can think of, if that polyhedron is not already a counterexample, then its dual is. A cube is not, but its dual is — this is the octahedron again.
Finding sets !!A!!, !!B!!, and !!C!! such that !!A\in B!!, !!B \in C!!, but !!A \notin C!!
I thought this one was pedagogically interesting. OP made a mistake in their approach that is quite common:
The problem tells us !!B = \{A,b_1,b_2,\ldots\}!! and !!C = \{B,c_1,c_2\}!!.
The mistake OP made here was to start by trying to find the most general possible example. Yes, if !!A\in B!! then in general !!B = \{A,b_1,b_2,\ldots\}!!. This might be a more helpful observation if the question had asked for some universal property of all such !!A, B, C!!. Then you could add constraints to the general case and see if you had anything left at the end. But this problem only asked for one example. So instead of considering the most general case of !!A\in B!!, and therefore the most complex form of the idea, the first thing one should try is the simplest possible example of !!A\in B!!, which is just !!B = \{A\}.!!
Then similarly one should try !!C = \{B\}!!. Obviously the required properties !!A\in B!! and !!B\in C!! are satisfied. What about !!A\notin C!!?
Since the only element of !!C!! is !!B!!, the answer is easy: !!A\notin C!! unless !!A=B = \{A\}!!
So now we just have to avoid !!A=\{A\}!!. Again let's try the simplest thing that could possibly work: !!A=\emptyset!!. And then we win, because indeed !!\emptyset\ne \{\emptyset\}!!, since the left side is empty and the right side isn't.
Did we get lucky here? No! The axiom of foundation guarantees that literally any !!A!! will work. But you don't have to know that to find an example, because literally any !!A!! will work.
This is Lower Mathematics in action. The abstract approach is useful if you are trying to prove some theorem, but if all you want is to find an example, the abstract approach is overkill.
Volume obtained by rotating a region around two different lines
OP considered the region bounded by the curves !!y=x^2!! and !!y=\sqrt x!! for !!0\le x, y\le 1!!, and then the solids of revolution obtained by revolving this region around the lines !!y=0!! and !!y=1!!. They said:
I expected the volume obtained by rotating about !!y=1!! to be identical with the volume obtained by rotating about the !!x!!-axis. To my surprise, calculation shows different results.
Many people would have posted an answer to this that simply did the calculation, sometimes one with no words in it. But I think this misses the point of the question, which is about OP's intuition. Why were they wrong?
Something that has been on my mind lately is an elaboration of a certain principle of pedagogy. Everyone knows the principle:
It's not enough to show the student the answer; you should try to show them how to find the answer.
Not everyone follows this, but at least most people are aware of it.
But my decades of experience watching people teach math have led me to believe that this is insufficient. There's a higher-order version of this principle that is also important:
It's not enough to show the student how you can find the answer; you should try to show them how they could have found the answer.
And by ‘they’ I don't mean ‘a student’; I mean the student, the specific one sitting in front of you, who knows what they know and can do what they can do.
This is hard.
(I think the !!A\in B, B\in C, A\notin C!! thing above is another example of this. Three people answered that question by pulling solutions out of thin air, but how much does that help OP solve the next problem of this type?)
Anyway, I digress. The region in question looks like this:
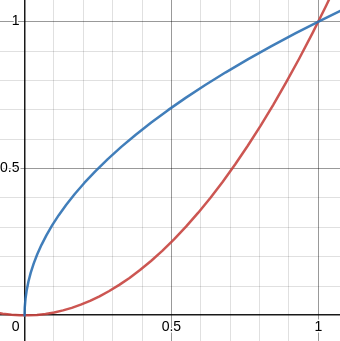
I observed that the upper end is much narrower than the lower end. You could count boxes to verify this, but I think it's obvious, and said:
Which end would you rather be poked with?
Then I pointed out that if you revolve the region around !!y=1!!, the thick end travels a long way and sweeps out a large volume, whereas if you revolve it around !!y=0!! the thick end is closer to the axis of revolution, so does not sweep out so much volume. So just from looking at the picture, one might guess that the volume will be larger when revolved around !!y=1!!, which is what OP originally reported.
I did not actually do the calculation, so it's conceivable that I was utterly wrong, but I suspect not.
Definition of Graph Isomorphism
This was not that interesting, but it is a demonstration of a couple of things:
Finding the simplest possible example
Because it's usually easier for someone to understand a simple example well enough to generalize it than it is for them to understand an abstract, general construction well enough to specialize it to an example.
Math SE will often ignore subtle answers to challenging questions, while giving many upvotes to trivialities
This post and the octahedron one were my most upvoted posts of the month and also the most trivial. This is why one should ignore upvotes: they are not correlated with anything of real importance.
Help understanding proof: classifying groups of order 21
I may have kinda blown this one. My answer was way too long. OP was asking about specific steps in some group theory proof, ultimately related to the formula $$(aba^{-1})^n = ab^na^{-1}.$$
Algebraically this is quite easy to show, and I did. But it also has deep and essential intuitive content, which I summarized like this:
It says that if you are going to repeat several times the operation of turning your head, then doing !!b!!, then turning your head back, you can skip some of the head-turning and just turn your head once, do operation !!b!! repeatedly, and turn your head back at the end.
This !!aba^{-1}!! thing, called “conjugation”, is incredibly important in group theory, and I have often felt that my group theory course did not make this clear. As I recall the course observed that the mapping !!\varphi_a : x\mapsto axa^{-1}!! is always a group automorphism, went on from there. Which indeed it is, but so what? Why do we care about that particular transformation, anyway?
But the intuitive content of the statement about the automophism is that the symmetries of an object don't change when you turn your head. That's why it's important!
When are two rotations of a sphere conjugate? Exactly when they rotate by the same amount around their respective axes. (“Turn your head!”)
Why are two permutations conjugate if and only if they have the same cycle structure? Because this exactly when they are equivalent under renaming of the objects being permuted; renaming the objects is analogous to "turning your head" for this kind of symmetry.
So whenever the topic of conjugation comes up, I am tempted to launch into a long explanation of the significance of conjugation and its intuitive understanding. Which might have been helpful in this case, but it might have been a completely unnecessary distraction, and I should probably have resisted.
What definition of "nearly orthogonal" would result in "In a 10,000-dimensional space there are millions of nearly orthogonal vectors"?
This was one of those cases where OP asked a very slightly under-baked question and several people jumped in to say it made no mathematical sense at all. (“It's a figure of speech” says one comment. No, it isn't. “I doubt that reference is to a precisely defined concept”, says another. There are more things in heaven and earth, Horatio… “I call bullshit, or imprecise speech,” says a third. Heavens, such foul language!)
I have complained about this at length in the past: I think Math SE persons are too quick to jump from “I have not heard of that” to “it does not exist” and then to “it cannot exist”, or from “I don't quite understand that” to “nobody can understand that” and then to “that is incomprehensible nonsense”.
Two vectors !!u!! and !!v!! are said to be orthogonal if their inner product !!\langle u,v\rangle!! is exactly zero. So if you don't know what “nearly orthogonal” means, you might guess that it means that the inner product is nearly zero: $$\left\lvert \langle u,v\rangle \right\rvert < \epsilon$$ for some small specified !!\epsilon!!. The angle between !!u!! and !!v!! would then be approximately between !!\frac\pi2 - \epsilon!! and !!\frac\pi2 + \epsilon!!, which is nearly a right angle; hence “nearly orthogonal”. This is not exactly subtle thinking.
Another user helpfully linked to a Math Overflow post that discussed essentially the same question, with the title “Almost orthogonal vectors”. So bullshit it isn't, and the question there was sufficiently clear that six people thought it was worth answering, including some guy named Tim Gowers.
I didn't know the answer (although I do now!), but if you don't know the answer, you can still sometimes be useful by writing up the answers of other people who are smarter than yourself, that is called “scholarship”.
In writing it up I almost made a horrible mistake. At one point my draft said something like:
The top answer there gives a bound and claims it is implied by the Johnson-Lindenstrauss lemma. I think the bound might not be quite correct, because the Johnson-Lindenstrauss lemma seems to apply to a somewhat different situation, and…
Fortunately, I realized before posting that that person who had written that answer that was in fact William B. Johnson after whom the Johnson-Lindenstrauss lemma was named, and there was quite a good chance that he did not misapply his own theorem. Heh. Yikes.
It's funny now, but if I had actually made that mistake I would have been mortified.
Also
I have an article with pretty diagrams about how to expand a Taylor series around !!x=\pi!!, with a nice Desmos demonstration that you might enjoy playing with. Press the little ▶️ button in the box that defines the parameter !!a!! and watch the cubic polynomials whip back and forth.
[ Addendum 20230421: Eric Roode says that the animation reminds him of “the robot from Lost in Space sliding back and forth, waving its arms wildly, and saying ‘Danger, Will Robinson! Danger!’”. Same. ]
I have already written a separate article about this post that asks how to compute the integral $$\int_0^{2000} e^{x/2-\lfloor x/2\rfloor}\; dx$$
which you might like to read if you didn't already.
[Other articles in category /math/se] permanent link
Sat, 15 Apr 2023
I liked this simple calculus exercise
A recent Math SE question asked for help computing the value of $$\int_0^{2000} e^{x/2-\left\lfloor x/2\right\rfloor}\; dx.\tag{$\star$}$$
(!!\left\lfloor \frac x2 \right\rfloor!! means !!\frac x2!! rounded down to the nearest integer.)
Often when I see someone's homework problems I exclaim “what blockhead TA assigned this?” But I think this is a really good exercise. Here's why.
In a calculus class, some people will have learned to integrate common functions by rote manipulatation of the expressions. They have learned a set of rules for converting $$\int_a^b x^k\; dx$$ to $$\left.\frac{x^{k+1}}{k+1}\right\rvert_a^b$$ and then to $$\frac{b^{k+1}}{k+1}- \frac{a^{k+1}}{k+1}$$ and such like, and they grind through the algebra. If this is all someone knows how to do, they are going to have a lot of trouble with !!(\star)!!. They might say “But nobody ever taught us how to integrate functions with !!\left\lfloor \frac x2\right\rfloor!!”.
A calculus tyro trying to deal with this analytically might also try rewriting $$e^{x/2-\left\lfloor x/2\right\rfloor}$$ as $$\frac{e^{x/2}}{e^{\left\lfloor x/2\right\rfloor}}$$ but that makes the problem harder, not easier.
To solve this, the student has to actually understand what the integral is computing, and if they don't they will have to learn something about it. The integral is computing the area under a curve. if you graph the function $$\frac x2-\left\lfloor \frac x2\right\rfloor$$
you find that it looks like this:
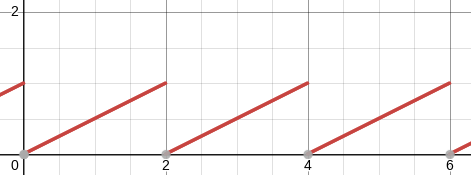
If the interval of integration in !!(\star)!! were only !!(0,2)!! instead of !!(0, 2000)!!, the problem would be very easy because, on this interval, the complicated exponent is identically equal to !!\frac x2!!:
$$\begin{align} \int_0^2 e^{x/2-\left\lfloor x/2\right\rfloor}\; dx & = \int_0^2 e^{x/2}\; dx \\ & = \left. 2e^{x/2} \right\rvert_0^2 \\ & = 2e-2 \end{align} $$
Since the function is completely periodic, integrating over any of the !!1000!! intervals of length !!2!! will produce the same value, so the final answer is simply $$1000\cdot (2e-2).$$
But just pushing around the symbols won't get you there, to solve this problem you have to actually know something about calculus.
The student who overcomes this problem might learn the following useful techniques:
If some expression looks complicated, try graphing it and see if you get any insight into how it behaves.
Some complicated functions can be understood by breaking them into simple parts and dealing with the parts separately.
Piecewise-continuous functions can be integrated by breaking them into continuous intervals and integrating the intervals separately.
You can exploit symmetry to reduce the amount of calculation required.
None of this is deep stuff, but it's all valuable technique. Also they might make the valuable observation that not every problem should be solved by pushing around the symbols.
[Other articles in category /math/se] permanent link
Thu, 13 Apr 2023A New Yorker magazine profile of The Simpsons writer George Meyer says:
He is especially interested in examples of ad copy in which the word-to-falsehood ratio approaches one. He once showed me a magazine advertisement for a butter substitute called Country Crock. “It’s not from the country; there is no crock,” he said. “Two words, two lies.”
I think of this every time I am in the supermarket and see the Country Crock. I have always felt it was a weak example.
A lie is intended to deceive, and I believe the marketing people at Country Crock never expected anyone to think that it was actually from the country or actually in a crock. Most adults understand that brand names are not literally descriptive and are only intended to be fanciful and evocative. Meyer is being kind of a putz here.
I was going to include a list of non-descriptive brand names, but I don't think it would persuade anyone who disagrees with me. If you would like one anyway, consider Log Cabin pancake syrup. If you want to claim this is a ‘lie’, what is the lie? If not, what is the practical difference between Log Cabin pancake syrup and Country Crock margarine?
I would like to help out George Meyer by proposing a genuinely dishonest example.
How about “Moral Majority”?
[ Addendum 20230509: A followup. ]
[ Addendum 20230805: Three lies in one. ]
[Other articles in category /misc] permanent link
Sun, 02 Apr 2023
Recent addenda to articles 202303
I added some notes to the article about mutating consonants in Spanish, about the Spanish word llevar and its connection with Levant, Catalan llevant, the east, the orient, and Latin orior.
I unexpectedly got to use my weird divisibility trick a second time.
John Wiersba informed me that the auction game I described is called “Goofspiel”.
I added a note to my article about spires of the Sagrada Família that mentions that the number twelve (of disciples) symbolizes perfection and is the number of stars in the flag of the European Union.
Lukas Epple wrote to point out that back in 2006 I cited the wrong section for the proof of !!1+1=2!! from the Principia Mathematica. This inspired me to hunt up the actual theorem. My article about this only discussed the precursor theorem ∗54.3. Here's what the !!1+1=2!! proof looks like:

[Other articles in category /addenda] permanent link
Sat, 01 Apr 2023
Human organ trafficking in Indiana
The Indiana General Assembly has an excellent web site for the Indiana state code. Looking up something else, I learned the following useful tidbit:
IC 35-46-5-1 Human organ trafficking
Sec. 1. (a) As used in this section, "human organ" means the kidney, liver, heart, lung, cornea, eye, bone marrow, bone, pancreas, or skin of a human body.
So apparently, the trafficking of human gall bladders is A-OK in Indiana.
[Other articles in category /law] permanent link
United States first names of newborns 1960–2021
Various United States government agencies keep statistics of forenames and surnames, which I have often found useful, but which can be hard to find. I am storing them here for future convenience. The data is in the public domain. Share and enjoy.
- 3162 CSV files in
.tgzformat (3.1 MB) - 3162 CSV files in Zip format (4.6 MB)
- To retrieve individual files, browse the directory
What's here?
A collection of 62×51 = 3162 CSV files with names dddd-XX.csv, where
dddd is a four-digit year between 1960 and 2021, and XX is a
standard two-letter state abbreviation, or DC. (Information for
Puerto Rico and other U.S. territories was
available from the SSA
but I did not collect it.)
By the way, !!3162\approx\sqrt{1000000}!!.
File format
Each file contains at least 200 records in the following format:
1960,AK,M,David,152
1960,AK,F,Mary,79
The fields are: year; state; sex; name; count. The (year, state, sex, name) tuple is a unique key over the entire data set.
The count is the number of babies with the specified name and sex born that year in that state. For example, the records above indicate that there were 152 male babies named David born in Alaska in year 1960, and 79 female babies named Mary.
At least the 100 most common names for each year-state-sex triple are included. I believe that the extra records are included when the least common names are tied for frequency.
Provenance
The United States social security administration (SSA) provides a web form that will deliver data for one year-state pair. I automated 3162 requests to this form and then scraped the HTML output.
(A couple of months ago I found a source for the raw data, as a single easy download, and then forgot where it was. Hence this post.)
Caution: data contains errors
There are several possible sources of error in these files. Most obviously, I might have made a mistake in the extraction, scraping, or recording.
But also it seems to me that the SSA itself provided some bad data. The data for Kentucky for year 2004 is clearly incorrect.
The name “Jacob” for girls is not to be found in the data — except in
the 2004-KY.csv file. The SSA claims that there were 130 baby girls
in Kentucky that year named Jacob,
making it the 17th most common female name, ahead of Anna and just
behind Lauren.
The same file contains
many similar oddities.
For example, it claims that there were
dozens of boys named Hannah and Emily, and
dozens of girls named Michael, Joseph, and Christopher,
but only that year and only in Kentucky.
I've added a comment to the top of the 2004-KY.csv file, which I
hope will cause a processing failure so that nobody uses it accidentally.
I have contacted the SSA web site but I am not hopeful that this will be corrected. [ Update 20230413: Here is their completely nonresponsive reply to my bug report. ]
Update 20230812: I recently discovered that some of the files contain entries for people named “Unknown”, and the 1989 Wisconsin file contains entries for 158 people named “Unnamed”. Also, there are no other names in any of files that begin with letter ‘U’. Really? Hundreds of Xaviers and Ximenas, but no significant numbers of Ulysseses or Ursulas? I don't know whether this is another error.
If you notice other likely errors, please bring them to my attention.
Data limitations
The SSA has a page of qualifications about the data.
Since I expect this page will outlast the SSA's, here is an archived copy.
What for?
A coworker recently mentioned that, of the 37 people who attended the most recent meeting of his (California) church youth group, no two had the same name. He asked if this was remarkable. (My conclusion: only somewhat; the computed probability was around 1 in 5, and would be higher if I hadn't had to ignore the long tail of names that aren't in the files.)
More recently, I had an argument with ChatGPT about whether the name “James” was commonly used for women. It is not listed as one of the top 100 names in any state for the last 60 years, except in the obviously erroneous Kentucky 2004 data, as I mentioned above.
[Other articles in category /misc] permanent link