Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2024: | JFMA |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 238 |
| Programming | 99 |
| Language | 92 |
| Miscellaneous | 67 |
| Book | 49 |
| Tech | 48 |
| Etymology | 34 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 23 |
| Physics | 21 |
| Law | 21 |
| Perl | 17 |
| Biology | 15 |



Comments disabled
Wed, 11 Jul 2018
Here is another bit of Perl code:
sub function {
my ($self, $cookie) = @_;
$cookie = ref $cookie && $cookie->can('value') ? $cookie->value : $cookie;
...
}
The idea here is that we are expecting $cookie to be either a
string, passed directly, or some sort of cookie object with a value
method that will produce the desired string.
The ref … && … condition
distinguishes the two situations.
A relatively minor problem is that if someone passes an object with no
value method, $cookie will be set to that object instead of to a
string, with mysterious results later on.
But the real problem here is that the function's interface is not simple enough. The function needs the string. It should insist on being passed the string. If the caller has the string, it can pass the string. If the caller has a cookie object, it should extract the string and pass the string. If the caller has some other object that contains the string, it should extract the string and pass the string. It is not the job of this function to know how to extract cookie strings from every possible kind of object.
I have seen code in which this obsequiousness has escalated to
absurdity. I recently saw a function whose job was to send an email.
It needs an EmailClass object, which encapsulates the message
template and some of the headers. Here is how it obtains that object:
12 my $stash = $args{stash} || {};
…
16 my $emailclass_obj = delete $args{emailclass_obj}; # isn't being passed here
17 my $emailclass = $args{emailclass_name} || $args{emailclass} || $stash->{emailclass} || '';
18 $emailclass = $emailclass->emailclass_name if $emailclass && ref($emailclass);
…
60 $emailclass_obj //= $args{schema}->resultset('EmailClass')->find_by_name($emailclass);
Here the function needs an EmailClass object. The caller can pass
one in $args{emailclass_obj}. But maybe the caller doesn't have
one, and only knows the name of the emailclass it wants to use. Very
well, we will allow it to pass the string and look it up later.
But that string could be passed in any of $args{emailclass_name}, or
$args{emailclass}, or $args{stash}{emailclass} at the caller's
whim and we have to rummage around hoping to find it.
Oh, and by the way, that string might not be a string! It might be the actual object, so there are actually seven possibilities:
$args{emailclass}
$args{emailclass_obj}
$args{emailclass_name}
$args{stash}{emailclass}
$args{emailclass}->emailclass_name
$args{emailclass_name}->emailclass_name
$args{stash}{emailclass}->emailclass_name
Notice that if $args{emailclass_name} is actually an emailclass
object, the name will be extracted from that object on line 18, and
then, 42 lines later, the name may be used to perform a database
lookup to recover the original object again.
We hope by the end of this rigamarole that $emailclass_obj will
contain an EmailClass object, and $emailclass will contain its
name. But can you find any combinations of arguments where this turns
out not to be true? (There are several.) Does the existing code
exercise any of these cases? (I don't know. This function is called
in 133 places.)
All this because this function was not prepared to insist firmly that its arguments be passed in a simple and unambiguous format, say like this:
my $emailclass = $args->{emailclass}
|| $self->look_up_emailclass($args->{emailclass_name})
|| croak "one of emailclass or emailclass_name is required";
I am not certain why programmers think it is a good idea to have functions communicate their arguments by way of a round of Charades. But here's my current theory: some programmers think it is discreditable for their function to throw an exception. “It doesn't have to die there,” they say to themselves. “It would be more convenient for the caller if we just accepted either form and did what they meant.” This is a good way to think about user interfaces! But a function's calling convention is not a user interface. If a function is called with the wrong arguments, the best thing it can do is to drop dead immediately, pausing only long enough to gasp out a message explaining what is wrong, and incriminating its caller. Humans are deserving of mercy; calling functions are not.
Allowing an argument to be passed in seven different ways may be
convenient for the programmer writing the call, who can save a few
seconds looking up the correct spelling of emailclass_name, but
debugging what happens when elaborate and inconsistent arguments are
misinterpreted will be eat up the gains many times over. Code is
written once, and read many times, so we should be willing to spend
more time writing it if it will save trouble reading it again later.
Novice programmers may ask “But what if this is business-critical code? A failure here could be catastrophic!”
Perhaps a failure here could be catastrophic. But if it is a catastrophe to throw an exception, when we know the caller is so confused that it is failing to pass the required arguments, then how much more catastrophic to pretend nothing is wrong and to continue onward when we are surely ignorant of the caller's intentions? And that catastrophe may not be detected until long afterward, or at all.
There is such a thing as being too accommodating.
[Other articles in category /prog/perl] permanent link
Fri, 06 Jul 2018[ This article has undergone major revisions since it was first published yesterday. ]
Here is a line of Perl code:
if ($self->fidget && blessed $self->fidget eq 'Widget::Fidget') {
This looks to see if $self has anything in its fidget slot, and if
so it checks to see if the value there is an instance of the class
Widget::Fidget. If both are true, it runs the following block.
That blessed check is bad practice for several reasons.
It duplicates the declaration of the
fidgetmember data:has fidget => ( is => 'rw', isa => 'Widget::Fidget', init_arg => undef, );So the
fidgetslot can't contain anything other than aWidget::Fidget, because the OOP system is already enforcing that. That means that theblessed…eqtest is not doing anything — unless someone comes along later and changes the declared type, in which case the test will then be checking the wrong condition.Actually, that has already happened! The declaration, as written, allows
fidgetto be an instance not just ofWidget::Fidgetbut of any class derived from it. But theblessed…eqcheck prevents this. This reneges on a major promise of OOP, that if a class doesn't have the behavior you need, you can subclass it and modify or extend it, and then use objects from the subclass instead. But if you try that here, theblessed…eqcheck will foil you.So this is a prime example of “… in which case the test will be checking the wrong condition” above. The test does not match the declaration, so it is checking the wrong condition. The
blessed…eqcheck breaks the ability of the class to work with derived classes ofWidget::Fidget.Similarly, the check prevents someone from changing the declared type to something more permissive, such as
“either
Widget::FidgetorGidget::Fidget”or
“any object that supports
wiggleandwagglemethods”or
“any object that adheres to the specification of
Widget::Interface”and then inserting a different object that supports the same interface. But the whole point of object-oriented programming is that as long as an object conforms to the required interface, you shouldn't care about its internal implementation.
In particular, the check above prevents someone from creating a mock
Widget::Fidgetobject and injecting it for testing purposes.We have traded away many of the modularity and interoperability guarantees that OOP was trying to preserve for us. What did we get in return? What are the purported advantages of the
blessed…eqcheck? I suppose it is intended to detect an anomalous situation in which some completely wrong object is somehow stored into theself.fidgetmember. The member declaration will prevent this (that is what it is for), but let's imagine that it has happened anyway. This could be a very serious problem. What will happen next?With the check in place, the bug will go unnoticed because the function will simply continue as if it had no fidget. This could cause a much more subtle failure much farther down the road. Someone trying to debug this will be mystified: At best “it's behaving as though it had no fidget, but I know that one was set earlier”, and at worst “why is there two years of inconsistent data in the database?” This could take a very long time to track down. Even worse, it might never be noticed, and the method might quietly do the wrong thing every time it was used.
Without the extra check, the situation is much better: the function will throw an exception as soon as it tries to call a fidget method on the non-fidget object. The exception will point a big fat finger right at the problem: “hey, on line 2389 you tried to call the
rotatemethod on aSkunk::Stinkyobject, but that class has no such method`. Someone trying to debug this will immediately ask the right question: “Who put a skunk in there instead of a widget?”
It's easy to get this right. Instead of
if ($self->fidget && blessed $self->fidget eq 'Widget::Fidget') {
one can simply use:
if ($self->fidget) {
Moral of the story: programmers write too much code.
I am reminded of something chess master Aron Nimzovitch once said, maybe in Chess Praxis, that amateur chess players are always trying to be Doing Something.
[Other articles in category /prog/perl] permanent link
Wed, 16 Jul 2014
Guess what this does (solution)
A few weeks ago I asked people to predict, without trying it first, what this would print:
perl -le 'print(two + two == five ? "true" : "false")'
(If you haven't seen this yet, I recommend that you guess, and then test your guess, before reading the rest of this article.)
People familiar with Perl guess that it will print true; that is
what I guessed. The reasoning is as follows: Perl is willing to treat
the unquoted strings two and five as strings, as if they had been
quoted, and is also happy to use the + and == operators on them,
converting the strings to numbers in its usual way. If the strings
had looked like "2" and "5" Perl would have treated them as 2 and
5, but as they don't look like decimal numerals, Perl interprets them
as zeroes. (Perl wants to issue a warning about this, but the warning is not enabled by default.
Since the two and five are treated as
zeroes, the result of the == comparison are true, and the string
"true" should be selected and printed.
So far this is a little bit odd, but not excessively odd; it's the
sort of thing you expect from programming languages, all of which more
or less suck. For example, Python's behavior, although different, is
about equally peculiar. Although Python does require that the strings
two and five be quoted, it is happy to do its own peculiar thing
with "two" + "two" == "five", which happens to be false: in Python
the + operator is overloaded and has completely different behaviors
on strings and numbers, so that while in Perl "2" + "2" is the
number 4, in Python is it is the string 22, and "two" + "two"
yields the string "twotwo". Had the program above actually printed
true, as I expected it would, or even false, I would not have
found it remarkable.
However, this is not what the program does do. The explanation of two paragraphs earlier is totally wrong. Instead, the program prints nothing, and the reason is incredibly convoluted and bizarre.
First, you must know that print has an optional first argument. (I
have plans for an article about how optional first arguments are almost
always a bad move, but contrary to my usual practice I will not insert
it here.) In Perl, the print function can be invoked in two ways:
print HANDLE $a, $b, $c, …;
print $a, $b, $c, …;
The former prints out the list $a, $b, $c, … to the filehandle
HANDLE; the latter uses the default handle, which typically points
at the terminal. How does Perl decide which of these forms is being
used? Specifically, in the second form, how does it know that $a is
one of the items to be printed, rather than a variable containing the filehandle
to print to?
The answer to this question is further complicated by the fact that
the HANDLE in the first form could be either an unquoted string,
which is the name of the handle to print to, or it could be a variable
containing a filehandle value. Both of these prints should do the
same thing:
my $handle = \*STDERR;
print STDERR $a, $b, $c;
print $handle $a, $b, $c;
Perl's method to decide whether a particular print uses an explicit
or the default handle is a somewhat complicated heuristic. The basic
rule is that the filehandle, if present, can be distinguished because
its trailing comma is omitted. But if the filehandle were allowed to
be the result of an arbitrary expression, it might be difficult for
the parser to decide where there was a a comma; consider the
hypothetical expression:
print $a += EXPRESSION, $b $c, $d, $e;
Here the intention is that the $a += EXPRESSION, $b expression
calculates the filehandle value (which is actually retrieved from $b, the
$a += … part being executed only for its side effect) and the
remaining $c, $d, $e are the values to be printed. To allow this
sort of thing would be way too confusing to both Perl and to the
programmer. So there is the further rule that the filehandle
expression, if present, must be short, either a simple scalar
variable such as $fh, or a bare unquoted string that is in the right
format for a filehandle name, such as HANDLE. Then the parser need
only peek ahead a token or two to see if there is an upcoming comma.
So for example, in
print STDERR $a, $b, $c;
the print is immediately followed by STDERR, which could be a
filehandle name, and STDERR is not followed by a comma, so STDERR
is taken to be the name of the output handle. And in
print $x, $a, $b, $c;
the print is immediately followed by the simple scalar value $x,
but this $x is followed by a comma, so is considered one of the
things to be printed, and the target of the print is the default
output handle.
In
print STDERR, $a, $b, $c;
Perl has a puzzle: STDERR looks like a filehandle, but it is
followed by a comma. This is a compile-time error; Perl complains “No
comma allowed after filehandle” and aborts. If you want to print the
literal string STDERR, you must quote it, and if you want to print A, B,
and C to the standard error handle, you must omit the first comma.
Now we return to the original example.
perl -le 'print(two + two == five ? "true" : "false")'
Here Perl sees the unquoted string two which could be a filehandle
name, and which is not followed by a comma. So it takes the first
two to be the output handle name. Then it evaluates the expression
+ two == five ? "true" : "false"
and obtains the value true. (The leading + is a unary plus
operator, which is a no-op. The bare two and five are taken to be
string constants, which, compared with the numeric == operator, are
considered to be numerically zero, eliciting the same warning that I
mentioned earlier that I had not enabled. Thus the comparison Perl
actually does is is 0 == 0, which is true, and the resulting string is
true.)
This value, the string true, is then printed to the filehandle named
two. Had we previously opened such a filehandle, say with
open two, ">", "output-file";
then the output would have been sent to the filehandle as usual.
Printing to a non-open filehandle elicits an optional warning from
Perl, but as I mentioned, I have not enabled warnings, so the print
silently fails, yielding a false value.
Had I enabled those optional warnings, we would have seen a plethora of them:
Unquoted string "two" may clash with future reserved word at -e line 1.
Unquoted string "two" may clash with future reserved word at -e line 1.
Unquoted string "five" may clash with future reserved word at -e line 1.
Name "main::two" used only once: possible typo at -e line 1.
Argument "five" isn't numeric in numeric eq (==) at -e line 1.
Argument "two" isn't numeric in numeric eq (==) at -e line 1.
print() on unopened filehandle two at -e line 1.
(The first four are compile-time warnings; the last three are issued
at execution time.) The crucial warning is the one at the end,
advising us that the output of print was directed to the filehandle
two which was never opened for output.
[ Addendum 20140718: I keep thinking of the following remark of Edsger W. Dijkstra:
[This phenomenon] takes one of two different forms: one programmer places a one-line program on the desk of another and … says, "Guess what it does!" From this observation we must conclude that this language as a tool is an open invitation for clever tricks; and while exactly this may be the explanation for some of its appeal, viz., to those who like to show how clever they are, I am sorry, but I must regard this as one of the most damning things that can be said about a programming language.
But my intent is different than what Dijkstra describes. His programmer is proud, but I am disgusted. Incidentally, I believe that Dijkstra was discussing APL here. ]
[ Addendum 20150508: I never have much sympathy for the school of thought that says that you should always always enable warnings in every Perl program; I think Perl produces too many spurious warnings for that. But I also think this example is part of a cogent argument in the other direction. ]
[Other articles in category /prog/perl] permanent link
Here's a Perl quiz that I confidently predict nobody will get right. Without trying it first, what does the following program print?
perl -le 'print(two + two == five ? "true" : "false")'
(I will discuss the surprising answer tomorrow.)
[Other articles in category /prog/perl] permanent link
Fri, 10 Jan 2014
DateTime::Moonpig, a saner interface to DateTime
(This article was previously published at the Perl Advent Calendar on 2013-12-23.)
The DateTime suite is an impressive tour de force, but I hate its interface. The methods it provides are usually not the ones you want, and the things it makes easy are often things that are not useful.
Mutators
The most obvious example is that it has too many mutators. I believe
that date-time values are a kind of number, and should be treated like
numbers. In particular they should be immutable. Rik Signes has
a hair-raising story
about an accidental mutation that caused a hard to diagnose bug,
because the add_duration method modifies the object on which it is
called, instead of returning a new object.
DateTime::Duration
But the most severe example, the one that drives me into a rage, is
that the subtract_datetime method returns a DateTime::Duration object,
and this object is never what you want, because it is impossible to
use it usefully.
For example, suppose you would like to know how much time elapses between 1969-04-02 02:38:17 EST and 2013-12-25 21:00:00 EST. You can set up the two DateTime objects for the time, and subtract them using the overloaded minus operator:
#!perl
my ($a) = DateTime->new( year => 1969, month => 04, day => 02,
hour => 2, minute => 38, second => 17,
time_zone => "America/New_York" ) ;
my ($b) = DateTime->new( year => 2013, month => 12, day => 25,
hour => 21, minute => 0, second => 0,
time_zone => "America/New_York" ) ;
my $diff = $b - $a;
Internally this invokes subtract_datetime to yield a
DateTime::Duration object for the difference. The
DateTime::Duration object $diff will contain the information
that this is a difference of 536 months, 23 days, 1101 minutes, and 43
seconds, a fact which seems to me to be of very limited usefulness.
You might want to know how long this interval is, so you can compare
it to similar intervals. So you might want to know how many seconds
this is. It happens that the two times are exactly 1,411,669,328
seconds apart, but there's no way to get the $diff object to
tell you this.
It seems like there are methods that will get you the actual
elapsed time in seconds, but none of them will do it. For example,
$diff->in_units('seconds') looks promising, but will
return 43, which is the 43 seconds left over after you've thrown away
the 536 months, 23 days, and 1101 minutes. I don't know what the use
case for this is supposed to be.
And indeed, no method can tell you how long the duration really is, because the subtraction has thrown away all the information about how long the days and months and years were—days, months and years vary in length—so it simply doesn't know how much time this object actually represents.
Similarly if you want to know how many days there are between the two dates, the DateTime::Duration object won't tell you because it can't tell you. If you had the elapsed seconds difference, you could convert it to the correct number of days simply by dividing by 86400 and rounding off. This works because, even though days vary in length, they don't vary by much, and the variations cancel out over the course of a year. If you do this you find that the elapsed number of days is approximately 16338.7653, which rounds off to 16338 or 16339 depending on how you want to treat the 18-hour time-of-day difference. This result is not quite exact, but the error is on the order of 0.000002%. So the elapsed seconds are useful, and you can compute other useful values with them, and get useful answers. In contrast, DateTime::Duration's answer of "536 months and 23 days" is completely useless because months vary in length by nearly 10% and DateTime has thrown away the information about how long the months were. The best you can do to guess the number of days from this is to multiply the 536 months by 30.4375, which is the average number of days in a month, and add 23. This is clumsy, and gets you 16337.5 days—which is close, but wrong.
To get what I consider a useful answer out of the DateTime objects you must not use the overloaded subtraction operator; instead you must do this:
#!perl
$b->subtract_datetime_absolute($a)->in_units('seconds')
What's DateTime::Moonpig for?
DateTime::Moonpig
attempts to get rid of the part of DateTime I don't like and keep the
part I do like, by changing the interface and leaving the internals
alone. I developed it for the Moonpig billing system that Rik
Signes and I did; hence the
name.
DateTime::Moonpig introduces five main changes to the interface of DateTime:
Most of the mutators are gone. They throw fatal exceptions if you try to call them.
The overridden addition and subtraction operators have been changed to eliminate DateTime::Duration entirely. Subtracting two DateTime::Moonpig objects yields the difference in seconds, as an ordinary Perl number. This means that instead of
#!perl $x = $b->subtract_datetime_absolute($a)->in_units('seconds')one can write
#!perl $x = $b - $aFrom here it's easy to get the approximate number of days difference: just divide by 86400. Similarly, dividing this by 3600 gets the number of hours difference.
An integer number of seconds can be added to or subtracted from a DateTime::Moonpig object; this yields a new object representing a time that is that many seconds later or earlier. Writing
$date + 2is much more convenient than writing$date->clone->add( seconds => 2 ).If you are not concerned with perfect exactness, you can write
#!perl sub days { $_[0] * 86400 } my $tomorrow = $now + days(1);This might be off by an hour if there is an intervening DST change, or by a second if there is an intervening leap second, but in many cases one simply doesn't care.
There is nothing wrong with the way DateTime overloads
<and>, so DateTime::Moonpig leaves those alone.The constructor is extended to accept an epoch time such as is returned by Perl's built-in
time()orstat()functions. This means that one can abbreviate this:#!perl DateTime->from_epoch( epoch => $epoch )to this:
#!perl DateTime::Moonpig->new( $epoch )The default time zone has been changed from DateTime's "floating" time zone to UTC. I think the "floating" time zone is a mistake, and best avoided. It has bad interactions with
set_time_zone, whichDateTime::Moonpigdoes not disable, because it is not actually a mutator—unless you use the "floating" time zone. An earlier blog article discusses this.I added a few additional methods I found convenient. For example there is a
$date->stthat returns the date and time in the formatYYYY-MM-DD HH:MM::SS, which is sometimes handy for quick debugging. (Thestis for "string".)
Under the covers, it is all just DateTime objects, which seem to do
what one needs. Other than the mutators, all the many DateTime
methods work just the same; you are even free to use
->subtract_datetime to obtain a DateTime::Duration object if you
enjoy being trapped in an absurdist theatre production.
When I first started this module, I thought it was likely to be a failed experiment. I expected that the Moonpig::DateTime objects would break once in a while, or that some operation on them would return a DateTime instead of a Moonpig::DateTime, which would cause some later method call to fail. But to my surprise, it worked well. It has been in regular use in Moonpig for several years.
I recently split it out of Moonpig, and released it to CPAN. I will be interested to find out if it works well in other contexts. I am worried that disabling the mutators has left a gap in functionality that needs to be filled by something else. I will be interested to hear reports from people who try.
[Other articles in category /prog/perl] permanent link
Mon, 23 Dec 2013
Two reasons I don't like DateTime's "floating" time zone
(This is a companion piece to my article about
DateTime::Moonpig
on the Perl Advent Calendar today. One
of the ways DateTime::Moonpig differs from DateTime is by
defaulting to UTC time instead of to DateTime's "floating" time
zone. This article explains some of the reasons why.)
Perl's DateTime module lets you create time values in a so-called
"floating" time zone. What this means really isn't clear. It would
be coherent for it to mean a time with an unknown or unspecified time
zone, but it isn't treated that way. If it were, you wouldn't be
allowed to compare "floating" times with regular times, or convert
"floating" times to epoch times. If "floating" meant "unspecified
time zone", the computer would have to honestly say that it didn't
know what to do in such cases. But it doesn't.
Unfortunately, this confused notion is the default.
Here are two demonstrations of why I don't like "floating" time zones.
1.
The behavior of the set_time_zone method may not be what you were
expecting, but it makes sense and it is useful:
my $a = DateTime->new( second => 0,
minute => 0,
hour => 5,
day => 23,
month => 12,
year => 2013,
time_zone => "America/New_York",
);
printf "The time in New York is %s.\n", $a->hms;
$a->set_time_zone("Asia/Seoul");
printf "The time in Seoul is %s.\n", $a->hms;
Here we have a time value and we change its time zone from New York to Seoul. There are at least two reasonable ways to behave here. This could simply change the time zone, leaving everything else the same, so that the time changes from 05:00 New York time to 05:00 Seoul time. Or changing the time zone could make other changes to the object so that it represents the same absolute time as it did before: If I pick up the phone at 05:00 in New York and call my mother-in-law in Seoul, she answers the call at 19:00 in Seoul, so if I change the object's time zone from New York to Seoul, it should change from 05:00 to 19:00.
DateTime chooses the second of these: setting the time zone retains
the absolute time stored by the object, so this program prints:
The time in New York is 05:00:00. The time in Seoul is 19:00:00.
Very good. And we can get to Seoul by any route we want:
$a->set_time_zone("Europe/Berlin");
$a->set_time_zone("Chile/EasterIsland");
$a->set_time_zone("Asia/Seoul");
printf "The time in Seoul is still %s.\n", $a->hms;
This prints:
The time in Seoul is still 19:00:00.
We can hop all around the globe, but the object always represents 19:00 in Seoul, and when we get back to Seoul it's still 19:00.
But now let's do the same thing with floating time zones:
my $b = DateTime->new( second => 0,
minute => 0,
hour => 5,
day => 23,
month => 12,
year => 2013,
time_zone => "America/New_York",
);
printf "The time in New York is %s.\n", $b->hms;
$b->set_time_zone("floating");
$b->set_time_zone("Asia/Seoul");
printf "The time in Seoul is %s.\n", $b->hms;
Here we take a hop through the imaginary "floating" time zone. The output is now:
The time in New York is 05:00:00.
The time in Seoul is 05:00:00.
The time has changed! I said there were at least two reasonable ways
to behave, and that set_time_zone behaves in the second reasonable
way. Which it does, except that conversions to the "floating" time
zone behave the first reasonable way. Put together, however, they are
unreasonable.
2.
use DateTime;
sub dec23 {
my ($hour, $zone) = @_;
return DateTime->new( second => 0,
minute => 0,
hour => $hour,
day => 23,
month => 12,
year => 2013,
time_zone => $zone,
);
}
my $a = dec23( 8, "Asia/Seoul" );
my $b = dec23( 6, "America/New_York" );
my $c = dec23( 7, "floating" );
printf "A is %s B\n", $a < $b ? "less than" : "not less than";
printf "B is %s C\n", $b < $c ? "less than" : "not less than";
printf "C is %s A\n", $c < $a ? "less than" : "not less than";
With DateTime 1.04, this prints:
A is less than B
B is less than C
C is less than A
There are non-transitive relations in the world, but comparison of
times is not among them. And if your relation is not transitive, you
have no business binding it to the < operator.
However...
Rik Signes points out that the manual says:
If you are planning to use any objects with a real time zone, it is strongly recommended that you do not mix these with floating datetimes.
However, while a disclaimer in the manual can document incorrect
behavior, it does not annul it. A bug doesn't stop being a bug just
because you document it in the manual. I think it would have been
possible to implement floating times sanely, but DateTime didn't do
that.
[ Addendum: Rik has now brought to my attention that while the main
->new constructor defaults to the "floating" time zone, the ->now
method always returns the current time in the UTC zone, which seems to
me to be a mockery of the advice not to mix the two. ]
[Other articles in category /prog/perl] permanent link
Thu, 09 Feb 2012
Testing for exceptions
The Test::Fatal
module makes it very easy to test code that is supposed to throw
an exception. It provides an exception function that takes a
code block. If the code completes normally, exception {
code } returns undefined; if the code throws an exception,
exception { code } returns the exception value that
was thrown. So for example, if you want to make sure that some
erroneous call is detected and throws an exception, you can use
this:
isnt( exception { do_something( how_many_times => "W" ) },
undef,
"how_many_times argument requires a number" );
which will succeed if do_something(…) throws an exception,
and fail if it does not. You can also write a stricter test, to look
for the particular exception you expect:
like( exception { do_something( how_many_times => "W" ) },
qr/how_many_times is not numeric/,
"how_many_times argument requires a number" );
which will succeed if do_something(…) throws an exception
that contains how_many_times is not numeric, and fail
otherwise.Today I almost made the terrible mistake of using the first form instead of the second. The manual suggests that you use the first form, but it's a bad suggestion. The problem is that if you completely screw up the test and write a broken code block that dies, the first test will cheerfully succeed anyway. For example, suppose you make a typo in the test code:
isnt( exception { do_something( how_many_tims => "W" ) },
undef,
"how_many_times argument requires a number" );
Here the do_something(…) call throws some totally different
exception that we are not interested in, something like unknown
argument 'how_many_tims' or mandatory 'how_many_times'
argument missing, but the exception is swallowed and the test
reports success, even though we know nothing at all about the feature
we were trying to test. But the test looks like it passed.In my example today, the code looked like this:
isnt( exception {
my $invoice = gen_invoice();
$invoice->abandon;
}, undef,
"Can't abandon invoice with no abandoned charges");
});
The abandon call was supposed to fail, for reasons you don't
care about. But in fact, the execution never got that far, because
there was a totally dumb bug in gen_invoice() (a missing
required constructor argument) that caused it to die with a completely
different exception.I would never have noticed this error if I hadn't spontaneously decided to make the test stricter:
like( exception {
my $invoice = gen_invoice();
$invoice->abandon;
}, qr/Can't.*with no abandoned charges/,
"Can't abandon invoice with no abandoned charges");
});
This test failed, and the failure made clear that
gen_invoice(), a piece of otherwise unimportant test
apparatus, was completely broken, and that several other tests I had
written in the same style appeared to be passing but weren't actually
running the code I thought they were.So the rule of thumb is: even though the Test::Fatal manual suggests that you use isnt( exception { … }, undef, …), do not.
I mentioned this to Ricardo Signes, the author of the module, and he released a new version with revised documentation before I managed to get this blog post published.
[Other articles in category /prog/perl] permanent link
Fri, 27 Aug 2010
A dummy generator for mock objects
I am not sure how useful this actually is, but I after having used it
once it was not yet obvious that it was a bad idea, so I am writing it
up here.
Suppose you are debugging some method, say someMethod, which accepts as one of its arguments complicated, annoying objects $annoying that you either can't or don't want to instantiate. This might be because $annoying is very complicated, with many sub-objects to set up, or perhaps you simply don't know how to build $annoying and don't care to find out.
That is okay, because you can get someMethod to run without the full behavior of $annoying. Say for example someMethod calls $annoying->foo_manager->get_foo(...)->get_user_id. You don't understand or care about the details because for debugging someMethod it is enough to suppose that the end result is the user ID 3. You could supply a mock object, or several, that implement the various methods, but that requires some work up front.
Instead, use this canned Dummy class. Instead of instantiating a real $annoying (which is difficult) or using a bespoke mock object, use Dummy->new("annoying"):
package Dummy;
use Data::Dumper;
$Data::Dumper::Terse = 1;
our $METHOD;
my @names = qw(bottle corncob euphonium octopus potato slide);
my $NAME = "aaa";
sub new {
my ($class, $name) = @_;
$name ||= $METHOD || shift(@names) || $NAME++;
bless { N => $name } => $class;
}
The call Dummy->new("annoying") will generate an ad-hoc mock
object; whenever any method is called on this dummy object, the call
will be caught by an AUTOLOAD that will prompt you for the
return value you want it to produce:
sub AUTOLOAD {
my ($self, @args) = @_;
my ($p, $m) = $AUTOLOAD =~ /(.*)::(.*)/;
local $METHOD = $m;
print STDERR "<< $_[0]{N}\->$m >>\n";
print STDERR "Arguments: " . Dumper(\@args) . "\n";
my $v;
do {
print STDERR "Value? ";
chomp($v = <STDIN>);
} until eval "$v; 1";
return(eval $v);
}
sub DESTROY { }
1;
The prompt looks like this:
<< annoying->foo_manager >> Arguments: [] Value?If the returned value should be a sub-object, no problem: just put in new Dummy and it will make a new Dummy object named foo_manager, and the next prompt will be:
<< foo_manager->get_foo >> Arguments: ... ... Value?Now you can put in new Dummy "(Fred's foo)" or whatever. Eventually it will ask you for a value for (Fred's foo)->id and you can have it return 4.
It's tempting to add caching, so that it won't ask you twice for the results of the same method call. But that would foreclose the option to have the call return different results twice. Better, I think, is for the user to cache the results themselves if they plan to use them again; there is nothing stopping the user from entering a value expression like $::val = ....
This may turn out to be one of those things that is mildly useful, but not useful enough to actually use; we'll see.
[Other articles in category /prog/perl] permanent link
Sat, 24 Jan 2009
Higher-Order Perl: nonmemoizing streams
The first version of tail() in the streams chapter looks like this:
sub tail {
my $s = shift;
if (is_promise($s->[1])) {
return $s->[1]->(); # Force promise
} else {
return $s->[1];
}
}
But this is soon replaced with a version that caches the value
returned by the promise:
sub tail {
my $s = shift;
if (is_promise($s->[1])) {
$s->[1] = $s->[1]->(); # Force and save promise
}
return $s->[1];
}
The reason that I give for this in the book is a performance reason.
It's accompanied by an extremely bad explanation. But I couldn't do
any better at the time.There are much stronger reasons for the memoizing version, also much easier to explain.
Why use streams at all instead of the iterators of chapter 4? The most important reason, which I omitted from the book, is that the streams are rewindable. With the chapter 4 iterators, once the data comes out, there is no easy way to get it back in. For example, suppose we want to process the next bit of data from the stream if there is a carrot coming up soon, and a different way if not. Consider:
# Chapter 4 iterators
my $data = $iterator->();
if (carrot_coming_soon($iterator)) {
# X
} else {
# Y
}
sub carrot_coming_soon {
my $it = shift;
my $soon = shift || 3;
while ($soon-- > 0) {
my $next = $it->();
return 1 if is_carrot($next);
}
return; # No carrot
}
Well, this probably doesn't work, because the carrot_coming_soon()
function extracts and discards the upcoming data from the iterator,
including the carrot itself, and now that data is lost.One can build a rewindable iterator:
sub make_rewindable {
my $it = shift;
my @saved; # upcoming values in LIFO order
return sub {
my $action = shift || "next";
if ($action eq "put back") {
push @saved, @_;
} elsif ($action eq "next") {
if (@saved) { return pop @saved; }
else { return $it->(); }
}
};
}
But it's kind of a pain in the butt to use:
sub carrot_coming_soon {
my $it = shift;
my $soon = shift || 3;
my @saved;
my $saw_carrot;
while ($soon-- > 0) {
push @saved, $it->();
$saw_carrot = 1, last if is_carrot($saved[-1]);
}
$it->("put back", @saved);
return $saw_carrot;
}
Because you have to explicitly restore the data you extracted.With the streams, it's all much easier:
sub carrot_coming_soon {
my $s = shift;
my $soon = shift || 3;
while ($seen-- > 0) {
return 1 if is_carrot($s->head);
drop($s);
}
return;
}
The working version of carrot_coming_soon() for streams looks just like
the non-working version for iterators.But this version of carrot_coming_soon() only works for memoizing streams, or for streams whose promise functions are pure. Let's consider a counterexample:
my $bad = filehandle_stream(\*DATA);
sub filehandle_stream {
my $fh = shift;
return node(scalar <$fh>,
promise { filehandle_stream($fh) });
}
__DATA__
fish
dog
carrot
goat rectum
Now consider what happens if I do this:
$carrot_soon = carrot_coming_soon($bad);
print "A carrot appears soon after item ", head($bad), "\n"
if $carrot_soon;
It says "A carrot appears soon after item fish". Fine.
That's because $bad is a node whose head contains
"fish". Now let's see what's after the fish:
print "After ", head($bad), " is ", head(tail($bad)), "\n";
This should print After fish is dog, and for the memoizing
streams I used in the book, it does. But a non-memoizing stream will
print "After fish is goat rectum". Because
tail($bad) invokes the promise function, which, since the
next() was not saved after carrot_coming_soon()
examined it, builds a new node, which reads the next item from the
filehandle, which is "goat rectum".I wish I had explained the rewinding property of the streams in the book. It's one of the most significant omissions I know about. And I wish I'd appreciated sooner that the rewinding property only works if the tail() function autosaves the tail node returned from the promise.
[Other articles in category /prog/perl] permanent link
Fri, 21 Mar 2008
Closed file descriptors: the answer
This is the answer to yesterday's article about a
small program that had a mysterious error.
my $command = shift;
for my $file (@ARGV) {
if ($file =~ /\.gz$/) {
my $fh;
unless (open $fh, "<", $file) {
warn "Couldn't open $file: $!; skipping\n";
next;
}
my $fd = fileno $fh;
$file = "/proc/self/fd/$fd";
}
}
exec $command, @ARGV;
die "Couldn't run command '$command': $!\n";
When the loop exits, $fh is out of scope, and the
filehandle it contains is garbage-collected, closing the file."Duh."
Several people suggested that it was because open files are not preserved across an exec, or because the meaning of /proc/self would change after an exec, perhaps because the command was being run in a separate process; this is mistaken. There is only one process here. The exec call does not create a new process; it reuses the same one, and it does not affect open files, unless they have been flagged with FD_CLOEXEC.
Abhijit Menon-Sen ran a slightly different test than I did:
% z cat foo.gz bar.gz
cat: /proc/self/fd/3: No such file or directory
cat: /proc/self/fd/3: No such file or directory
As he said, this makes it completely obvious what is wrong, since
the two files are both represented by the same file descriptor.
[Other articles in category /prog/perl] permanent link
Thu, 20 Mar 2008
Closed file descriptors
I wasn't sure whether to file this on the /oops
section. It is a mistake, and I spent a lot longer chasing the bug
than I should have, because it's actually a simple bug. But it isn't
a really big conceptual screwup of the type I like to feature in the
/oops section.
It concerns a
program that I'll discuss in detail tomorrow. In the meantime, here's
a stripped-down summary, and a stripped-down version of the code:
my $command = shift;
for my $file (@ARGV) {
if ($file =~ /\.gz$/) {
my $fh;
unless (open $fh, "<", $file) {
warn "Couldn't open $file: $!; skipping\n";
next;
}
my $fd = fileno $fh;
$file = "/proc/self/fd/$fd";
}
}
exec $command, @ARGV;
die "Couldn't run command '$command': $!\n";
The idea here is that this program, called z, will preprocess
the arguments of some command, and then run the command
with the modified arguments. For some of the command-line arguments,
here the ones named *.gz, the original file will be replaced
by the output of some file descriptor. In the example above, the
descriptor is attached to the original file, which is pointless. But
once this part of the program was working, I planned to change the code
so that the descriptor would be
attached to a pipe instead.Having written something like this, I then ran a test, which failed:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directory"Aha," I said instantly. "I know what is wrong. Perl set the close-on-exec flag on file descriptor 3."
You see, after a successful exec, the kernel will automatically close all file descriptors that have the close-on-exec flag set, before the exec'ed image starts running. Perl normally sets the close-on-exec flag on all open files except for standard input, standard output, and standard error. Actually it sets it on all open files whose file descriptor is greater than the value of $^F, but $^F defaults to 2.
So there is an easy fix for the problem: I just set $^F = 100000 at the top of the program. That is not the best solution, but it can be replaced with a better one once the program is working properly. Which I expected it would be:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directoryHuh, something is still wrong.
Maybe I misspelled /proc/self/fd? No, it is there, and contains the special files that I expected to find.
Maybe $^F did not work the way I thought it did? I checked the manual, but it looked okay.
Nevertheless I put in use Fcntl and used the fcntl function to remove the close-on-exec flags explicitly. The code to do that looks something like this:
use Fcntl;
....
my $flags = fcntl($fh, F_GETFD, 0);
fcntl($fh, F_SETFD, $flags & ~FD_CLOEXEC);
And try it again:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directoryHuh.
I then wasted a lot of time trying to figure out an easy way to tell if the file descriptor was actually open after the exec call. (The answer turns out to be something like this: perl -MPOSIX=fstat -le 'print "file descriptor 3 is ", fstat(3) ? "open" : "closed"'.) This told me whether the error from cat meant what I thought it meant. It did: descriptor 3 was indeed closed after the exec.
Now your job is to figure out what is wrong. It took me a shockingly long time. No need to email me about it; I have it working now. I expect that you will figure it out faster than I did, but I will also post the answer on the blog tomorrow. Sometime on Friday, 21 March 2008, this link will start working and will point to the answer.
[ Addendum 20080321: I posted the answer. ]
[Other articles in category /prog/perl] permanent link
Fri, 14 Mar 2008
Drawing lines
As part of this thing I sometimes do when I'm not writing in my
blog—what is it called?—oh, now I remember.
As part of my job I had to produce the following display:
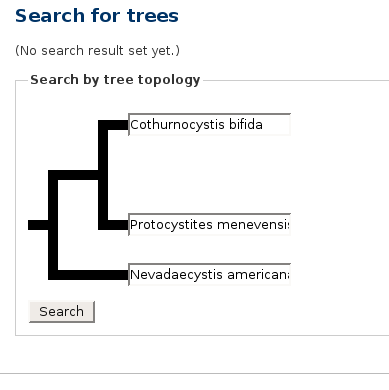
If you wanted to hear more about phylogeny, Java programming, or tree algorithms, you are about to be disappointed. The subject of my article today is those fat black lines.
The first draft of the page did not have the fat black lines. It had some incredibly awful ASCII-art that was not even properly aligned. Really it was terrible; it would have been better to have left it out completely. I will not make you look at it.
I needed the lines, so I popped down the "graphics" menu on my computer and looked for something suitable. I tried the Gimp first. It seems that the Gimp has no tool for drawing straight lines. If someone wants to claim that it does, I will not dispute the claim. The Gimp has a huge and complex control panel covered with all sorts of gizmos, and maybe one of those gizmos draws a straight line. I did not find one. I gave up after a few minutes.
Next I tried Dia. It kept selecting the "move the line around on the page" tool when I thought I had selected the "draw another line" tool. The lines were not constrained to a grid by default, and there was no obvious way to tell it that I wanted to draw a diagram smaller than a whole page. I would have had to turn the thing into a bitmap and then crop the bitmap. "By Zeus's Beard," I cried, "does this have to be so difficult?" Except that the oath I actually uttered was somewhat coarser and less erudite than I have indicated. I won't repeat it, but it started with "fuck" and ended with "this".
Here's what I did instead. I wrote a program that would read an input like this:
>-v-<
'-+-`
and produce a jpeg file that looks like this:
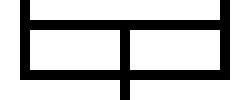
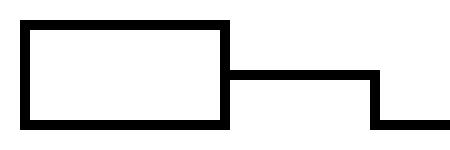
.---,
| >--,
'---` '-
Becomes this:
Now I know some of you are just itching to write to me and ask "why didn't you just use...?", so before you do that, let me remind you of two things. First, I had already wasted ten or fifteen minutes on "just use..." that didn't work. And second, this program only took twenty minutes to write.
The program depends on one key insight, which is that it is very, very easy to write a Perl program that generates a graphic output in "PBM" ("portable bitmap") format. Here is a typical PBM file:
P1
10 10
1111111111
1000000001
1000000001
1001111001
1001111001
1001111001
1001111001
1000000001
1000000001
1111111111
The P1 is a magic number that identifies the file format; it
is always the same. The 10 10 warns the processor that the
upcoming bitmap is 10 pixels wide and 10 pixels high. The following
characters are the bitmap data.
I'm not going to insult you by showing the 10×10 bitmap image
that this represents.PBM was invented about twenty years ago by Jef Poskanzer. It was intended to be an interchange format: say you want to convert images from format X to format Y, but you don't have a converter. You might, however, have a converter that turns X into PBM and then one that turns PBM into Y. Or if not, it might not be too hard to produce such converters. It is, in the words of the Extreme Programming guys, the Simplest Thing that Could Possibly Work.
There are also PGM (portable graymap) and PPM (portable pixmap) formats for grayscale and 24-bit color images as well. They are only fractionally more complicated.
Because these formats are so very, very simple, they have been widely adopted. For example, the JPEG reference implementation includes a sample cjpeg program, for converting an input to a JPEG file. The input it expects is a PGM or PPM file.
Writing a Perl program to generate a P?M file, and then feeding the output to pbmtoxbm or ppmtogif or cjpeg is a good trick, and I have used it many times. For example, I used this technique to generate a zillion little colored squares in this article about the Pólya-Burnside counting lemma. Sure, I could have drawn them one at a time by hand, and probably gone insane and run amuck with an axe immediately after, but the PPM technique was certainly much easier. It always wins big, and this time was no exception.
The program may be interesting as an example of this technique, and possibly also as a reminder of something else. The Perl community luminaries invest a lot of effort in demonstrating that not every Perl program looks like a garbage heap, that Perl can be as bland and aseptic as Java, that Perl is not necessarily the language that most closely resembles quick-drying shit in a tube, from which you can squirt out the contents into any shape you want and get your complete, finished artifact in only twenty minutes and only slightly smelly.
No, sorry, folks. Not everything we do is a brilliant, diamond-like jewel, polished to a luminous gloss with pages torn from one of Donald Knuth's books. This line-drawing program was squirted out of a tube, and a fine brown piece of engineering it is.
#!/usr/bin/perl
my ($S) = shift || 50;
$S here is "size". The default is to turn every character in
the input into a 50×50 pixel tile. Here's the previous example
with $S=10: 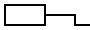
my ($h, $w);
my $output = [];
while (<>) {
chomp;
$w ||= length();
$h++;
push @$output, convert($_);
}
The biggest defect in the program is right here: it assumes that each
line will have the same width $w. Lines all must be
space-padded to the same width. Fixing this is left as an easy
exercise, but it wasn't as easy as padding the inputs, so I didn't do it.The magic happens here:
open STDOUT, "| pnmscale 1 | cjpeg" or die $!;
print "P1\n", $w * $S, " ", $h * $S, "\n";
print $_, "\n" for @$output;
exit;
The output is run through cjpeg to convert the PBM data to
JPEG. For some reason cjpeg doesn't accept PBM data, only
PGM or PPM, however, so the output first goes through
pnmscale, which resizes a P?M input. Here the scale factor
is 1, which is a no-op, except that pnmscale happens to turn
a PBM input into a PGM output. This is what is known in the business
as a "trick". (There is a pbmtopgm program, but it does
something different.)If we wanted gif output, we could have used "| ppmtogif" instead. If we wanted output in Symbolics Lisp Machine format, we could have used "| pgmtolispm" instead. Ah, the glories of interchange formats.
I'm going to omit the details of convert, which just breaks each line into characters, calls convert_ch on each character, and assembles the results. (The complete source code is here if you want to see it anyway.) The business end of the program is convert_ch:
#
sub convert_ch {
my @rows;
my $ch = shift;
my $up = $ch =~ /[<|>^'`+]/i;
my $dn = $ch =~ /[<|>V.,+]/i;
my $lt = $ch =~ /[-<V^,`+]/i;
my $rt = $ch =~ /[->V^.'+]/i;
These last four variables record whether the tile has a line from its
center going up, down, left, or right respectively. For example,
"|" produces a tile with lines coming up and down from the
center, but not left or right. The /i in the regexes is
because I kept writing v instead of V in the
inputs.
my $top = int($S * 0.4);
my $mid = int($S * 0.2);
my $bot = int($S * 0.4);
The tile is divided into three bands, of the indicated widths. This
probably looks bad, or fails utterly, unless $S is a multiple
of 5. I haven't tried it. Do you think I care? Hint: I haven't tried
it.
my $v0 = "0" x $S;
my $v1 = "0" x $top . "1" x $mid . "0" x $bot;
push @rows, ($up ? $v1 : $v0) x $top;
This assembles the top portion of the tile, including the "up" line,
if there is one. Note that despite their names, $top also
determines the width of the left portion of the tile, and
$bot determines the width of the right portion. The letter
"v" here is for "vertical".Perhaps I should explain for the benefit of the readers of Planet Haskell (if any of them have read this far and not yet fainted with disgust) that "$a x $b" in Perl is like concat (replicate b a) in the better sorts of languages.
my $ls = $lt ? "1" : "0";
my $ms = ($lt || $rt || $up || $dn) ? "1" : "0";
my $rs = $rt ? "1" : "0";
push @rows, ($ls x $top . $ms x $mid . $rs x $bot) x $mid;
This assembles the middle section, including the "left" and "right"
lines.
push @rows, ($dn ? $v1 : $v0) x $bot;
This does the bottom section.
return @rows;
}
And we are done.
Nothing to it. Adding diagonal lines would be a fairly simple matter.Download the complete source code if you haven't seen enough yet.
There is no part of this program of which I am proud. Rather, I am proud of the thing as a whole. It did the job I needed, and it did it by 5 PM. Larry Wall once said that "a Perl script is correct if it's halfway readable and gets the job done before your boss fires you." Thank you, Larry.
No, that is not quite true. There is one line in this program that I'm proud of. I noticed after I finished that there is exactly one comment in this program, and it is blank. I don't know how that got in there, but I decided to leave it in. Who says program code can't be funny?
[Other articles in category /prog/perl] permanent link
Fri, 11 Jan 2008
Help, help!
(Readers of Planet Haskell
may want to avert their eyes from this compendium of Perl
introspection techniques. Moreover, a very naughty four-letter word
appears, a word that begins with "g" and ends with "o". Let's just
leave it at that.)
Przemek Klosowski wrote to offer me physics help, and also to ask about introspection on Perl objects. Specifically, he said that if you called a nonexistent method on a TCL object, the error message would include the names of all the methods that would have worked. He wanted to know if there was a way to get Perl to do something similar.
There isn't, precisely, because Perl has only a conventional distinction between methods and subroutines, and you Just Have To Know which is which, and avoid calling the subroutines as methods, because the Perl interpreter has no idea which is which. But it does have enough introspection features that you can get something like what you want. This article will explain how to do that.
Here is a trivial program that invokes an undefined method on an object:
use YAML;
my $obj = YAML->new;
$obj->nosuchmethod;
When run, this produces the fatal error:
Can't locate object method "nosuchmethod" via package "YAML" at test.pl line 4.
(YAML in this article is just an example; you don't have to
know what it does. In fact, I don't know what it does.)Now consider the following program instead:
use YAML;
use Help 'YAML';
my $obj = YAML->new;
$obj->nosuchmethod;
Now any failed method calls to YAML objects, or objects of
YAML's subclasses, will produce a more detailed error
message:
Unknown method 'nosuchmethod' called on object of class YAML
Perhaps try:
Bless
Blessed
Dump
DumpFile
Load
LoadFile
VALUE
XXX
as_heavy (inherited from Exporter)
die (inherited from YAML::Base)
dumper_class
dumper_object
export (inherited from Exporter)
export_fail (inherited from Exporter)
export_ok_tags (inherited from Exporter)
export_tags (inherited from Exporter)
export_to_level (inherited from Exporter)
field
freeze
global_object
import (inherited from Exporter)
init_action_object
loader_class
loader_object
new (inherited from YAML::Base)
node_info (inherited from YAML::Base)
require_version (inherited from Exporter)
thaw
warn (inherited from YAML::Base)
ynode
Aborting at test.pl line 5
Some of the methods in this list are bogus. For example, the stuff
inherited from Exporter should almost certainly not be
called on a YAML object.Some of the items may be intended to be called as functions, and not as methods. Some may be functions imported from some other module. A common offender here is Carp, which places a carp function into another module's namespace; this function will show up in a list like the one above, without even an "inherited from" note, even though it is not a method and it does not make sense to call it on an object at all.
Even when the items in the list really are methods, they may be undocumented, internal-use-only methods, and may disappear in future versions of the YAML module.
But even with all these warnings, Help is at least a partial solution to the problem.
The real reason for this article is to present the code for Help.pm, not because the module is so intrinsically useful itself, but because it is almost a catalog of weird-but-useful Perl module hackery techniques. A full and detailed tour of this module's 30 lines of code would probably make a decent 60- or 90-minute class for intermediate Perl programmers who want to become wizards. (I have given many classes on exactly that topic.)
Here's the code:
package Help;
use Carp 'croak';
sub import {
my ($selfclass, @classes) = @_;
for my $class (@classes) {
push @{"$class\::ISA"}, $selfclass;
}
}
sub AUTOLOAD {
my ($bottom_class, $method) = $AUTOLOAD =~ /(.*)::(.*)/;
my %known_method;
my @classes = ($bottom_class);
while (@classes) {
my $class = shift @classes;
next if $class eq __PACKAGE__;
unshift @classes, @{"$class\::ISA"};
for my $name (keys %{"$class\::"}) {
next unless defined &{"$class\::$name"};
$known_method{$name} ||= $class;
}
}
warn "Unknown method '$method' called on object of class $bottom_class\n";
warn "Perhaps try:\n";
for my $name (sort keys %known_method) {
warn " $name " .
($known_method{$name} eq $bottom_class
? ""
: "(inherited from $known_method{$name})") .
"\n";
}
croak "Aborting";
}
sub help {
$AUTOLOAD = ref($_[0]) . '::(none)';
goto &AUTOLOAD;
}
sub DESTROY {}
1;
use Help 'Foo'
When any part of the program invokes use Help 'Foo', this does two things. First, it locates Help.pm, loads it in, and compiles it, if that has not been done already. And then it immediately calls Help->import('Foo').Typically, a module's import method is inherited from Exporter, which gets control at this point and arranges to make some of the module's functions available in the caller's namespace. So, for example, when you invoke use YAML 'freeze' in your module, Exporter's import method gets control and puts YAML's "freeze" function into your module's namespace. But that is not what we are doing here. Instead, Help has its own import method:
sub import {
my ($selfclass, @classes) = @_;
for my $class (@classes) {
push @{"$class\::ISA"}, $selfclass;
}
}
The $selfclass variable becomes Help and @classes
becomes ('Foo'). Then the module does its first tricky
thing. It puts itself into the @ISA list of another class.
The push line adds Help to @Foo::ISA.@Foo::ISA is the array that is searched whenever a method call on a Foo objects fails because the method doesn't exist. Perl will search the classes named in @Foo::ISA, in order. It will search the Help class last. That's important, because we don't want Help to interfere with Foo's ordinary inheritance.
Notice the way the variable name Foo::ISA is generated dynamically by concatenating the value of $class with the literal string ::ISA. This is how you access a variable whose name is not known at compile time in Perl. We will see this technique over and over again in this module.
The backslash in @{"$class\::ISA"} is necessary, because if we wrote @{"$class::ISA"} instead, Perl would try to interpolate the value of $ISA variable from the package named class. We could get around this by writing something like @{$class . '::ISA'}, but the backslash is easier to read.
AUTOLOAD
So what happens when the program calls $foo->nosuchmethod? If one of Foo's base classes includes a method with that name, it will be called as usual.But when method search fails, Perl doesn't give up right away. Instead, it tries the method search a second time, this time looking for a method named AUTOLOAD. If it finds one, it calls it. It only throws an exception of there is no AUTOLOAD.
The Help class doesn't have a nosuchmethod method either, but it does have AUTOLOAD. If Foo or one of its other parent classes defines an AUTOLOAD, one of those will be called instead. But if there's no other AUTOLOAD, then Help's AUTOLOAD will be called as a last resort.
$AUTOLOAD
When Perl calls an AUTOLOAD function, it sets the value of $AUTOLOAD to include the full name of the method it was trying to call, the one that didn't exist. In our example, $AUTOLOAD is set to "Foo::nosuchmethod".This pattern match dismantles the contents of $AUTOLOAD into a class name and a method name:
sub AUTOLOAD {
my ($bottom_class, $method) = $AUTOLOAD =~ /(.*)::(.*)/;
The $bottom_class variable contains Foo, and the
$method variable contains nosuchmethod.The AUTOLOAD function is now going to accumulate a table of all the methods that could have been called on the target object, print out a report, and throw a fatal exception.
The accumulated table will reside in the private hash %known_method. Keys in this hash will be method names. Values will be the classes in which the names were found.
Accumulating the table of method names
The AUTOLOAD function accumulates this hash by doing a depth-first search on the @ISA tree, just like Perl's method resolution does internally. The @classes variable is a stack of classes that need to be searched for methods but that have not yet been searched. Initially, it includes only the class on which the method was actually called, Foo in this case:
my @classes = ($bottom_class);
As long as some class remains unsearched, this loop will continue to
look for more methods. It begins by grabbing the next class off the
stack:
while (@classes) {
my $class = shift @classes;
Foo inherits from Help too, but we don't want our
error message to mention that, so the search skips Help:
next if $class eq __PACKAGE__;
(__PACKAGE__ expands at compile time to the name of the
current package.)Before the loop actually looks at the methods in the current class it's searching, it looks to see if the class has any base classes. If there are any, it pushes them onto the stack to be searched next:
unshift @classes, @{"$class\::ISA"};
Now the real meat of the loop: there is a class name in
$class, say Foo,
and we want the program to find all the methods in that class. Perl
makes the symbol table for the Foo package available in the
hash %Foo::. Keys in this hash are variable, subroutine, and
filehandle names.To find out if a name denotes a subroutine, we use defined(&{subroutine_name}) for each name in the package symbol table. If there is a subroutine by that name, the program inserts it and the class name into %known_method. Otherwise, the name is a variable or filehandle name and is ignored:
for my $name (keys %{"$class\::"}) {
next unless defined &{"$class\::$name"};
$known_method{$name} ||= $class;
}
}
The ||= sets a new value for $name in the hash only
if there was not one already. If a method name appears in more than
one class, it is recorded as being in the first one found in the
search. Since the search is proceeding in the same order that Perl
uses, the one recorded is the one that Perl will actually find. For
example, if Foo inherits from Bar, and both classes
define a this method, the search will find Foo::this
before Bar::this, and that is what will be recorded in the
hash. This is correct, because Foo's this method
overrides Bar's.If you have any clever techniques for identifying other stuff that should be omitted from the output, this is where you would put them. For example, many authors use the convention that functions whose names have a leading underscore are private to the implementation, and should not be called by outsiders. We might omit such items from the output by adding a line here:
next if $name =~ /^_/;
After the loop finishes searching all the base classes, the
%known_method hash looks something like this:
(
this => Foo,
that => Foo,
new => Base,
blookus => Mixin::Blookus,
other => Foo
)
This means that methods this, that, and
other were defined in Foo itself, but that
new is inherited from Base and that blookus
was inherited from Mixin::Blookus.
Printing the report
The AUTOLOAD function then prints out some error messages:
warn "Unknown method '$method' called on object of class $bottom_class\n";
warn "Perhaps try:\n";
And at last the payoff: It prints out the list of methods that the
programmer could have called:
for my $name (sort keys %known_method) {
warn " $name " .
($known_method{$name} eq $bottom_class
? ""
: "(inherited from $known_method{$name})") .
"\n";
}
croak "Aborting";
}
Each method name is printed. If the class in which the method was
found is not the bottom class, the name is annotated with the message
(inherited from wherever).The output for my example would look like this:
Unknown method 'nosuchmethod' called on object of class Foo:
Perhaps try:
blookus (inherited from Mixin::Blookus)
new (inherited from Base)
other
that
this
Aborting at YourErroneousModule.pm line 679
Finally the function throws a fatal exception. If we had used
die here, the fatal error message would look like
Aborting at Help.pm line 34, which is extremely unhelpful.
Using croak instead of die makes the message look
like Aborting at test.pl line 5 instead. That is, it reports
the error as coming from the place where the erroneous method was
actually called.
Synthetic calls
 Suppose you want to force the help message to come out. One way is to
call $object->fgsfds, since probably the object does not
provide a fgsfds method. But this is ugly, and it might not
work, because the object might provide a fgsfds
method. So Help.pm provides another way.
Suppose you want to force the help message to come out. One way is to
call $object->fgsfds, since probably the object does not
provide a fgsfds method. But this is ugly, and it might not
work, because the object might provide a fgsfds
method. So Help.pm provides another way.You can always force the help message by calling $object->Help::help. This calls a method named help, and it starts the inheritance search in the Help package. Control is transferred to the following help method:
sub help {
$AUTOLOAD = ref($_[0]) . '::(none)';
goto &AUTOLOAD;
}
The Help::help method sets up a fake $AUTOLOAD
value and then uses "magic goto" to transfer control to the real
AUTOLOAD function. "Magic goto" is not the evil bad goto
that is Considered Harmful. It is more like a function call. But
unlike a regular function call, it erases the calling function
(help) from the control stack, so that to subsequently
executed code it appears that AUTOLOAD was called directly in
the first place.Calling AUTOLOAD in the normal way, without goto, would have worked also. I did it this way just to be a fusspot.
DESTROY
Whenever a Perl object is destroyed, its DESTROY method is called, if it has one. If not, method search looks for an AUTOLOAD method, if there is one, as usual. If this lookup fails, no fatal exception is thrown; the object is sliently destroyed and execution continues.It is very common for objects to lack a DESTROY method; usually nothing additional needs to be done when the object's lifetime is over. But we do not want the Help::AUTOLOAD function to be invoked automatically whenever such an object is destroyed! So Help defines a last-resort DESTROY method that is called instead; this prevents Perl from trying the AUTOLOAD search when an object with no DESTROY method is destroyed:
sub DESTROY {}
This DESTROY method restores the default
behavior, which is to do nothing.
Living dangerously
Perl has a special package, called UNIVERSAL. Every class inherits from UNIVERSAL. If you want to apply Help to every class at once, you can try:
use Help 'UNIVERSAL';
but don't blame me if something weird happens.
About use strict
Whenever I present code like this, I always get questions (or are they complaints?) from readers about why I omitted "use strict". "Always use strict!" they say.Well, this code will not run with "use strict". It does a lot of stuff on purpose that "strict" was put in specifically to keep you from doing by accident.
At some point you have to take off the training wheels, kiddies.
License
Code in this article is hereby placed in the public domain.Share and enjoy.
[Other articles in category /prog/perl] permanent link
Sun, 30 Dec 2007
Welcome to my ~/bin
In the previous article I
mentioned "a conference tutorial about the contents of my
~/bin directory". Usually I have a web page about each
tutorial, with a description, and some sample slides, and I wanted to
link to the page about this tutorial. But I found to my surprise that
I had forgotten to make the page about this one.
So I went to fix that, and then I couldn't decide which sample slides to show. And I haven't given the tutorial for a couple of years, and I have an upcoming project that will prevent me from giving it for another couple of years. Eh, figuring out what to put online is more trouble than it's worth. I decided it would be a lot less toil to just put the whole thing online.
The materials are copyright © 2004 Mark Jason Dominus, and are not under any sort of free license.
But please enjoy them anyway.
I think the title is an accidental ripoff of an earlier class by Damian Conway. I totally forgot that he had done a class on the same subject, and I think he used the same title. But that just makes us even, because for the past few years he has been making money going around giving talks on "Conference Presentation Aikido", which is a blatant (and deliberate) ripoff of my 2002 Perl conference talk on Conference Presentation Judo. So I don't feel as bad as I might have.
Welcome to my ~/bin complete slides and other materials.
I hereby wish you a happy new year, unless you don't want one, in which case I wish you a crappy new year instead.
[Other articles in category /prog/perl] permanent link
Mon, 29 Oct 2007
Undefined behavior in Perl and other languages
Miles Gould wrote what I thought was an interesting
article on implementation-defined languages, and cited Perl as an
example. One of his points was that a language that is defined by its
implementation, as Perl is, rather than by a standards document,
cannot have any "undefined behavior".
- Undefined behavior
- Perl: the static variable hack
- Perl: modifying a hash in a loop
- Perl: modifying an array in a loop
- Haskell: n+k patterns
- XML screws up
Undefined behavior
For people unfamiliar with this concept, I should explain briefly. The C standard is full of places that say "if the program contains x, the behavior is undefined", which really means "C programs do not contain x, so If the program contains x, it is not written in C, and, as this standard only defines the meaning of programs in C, it has nothing to say about the meaning of your program." There are around a couple of hundred of these phrases, and a larger number of places where it is implied.For example, everyone knows that it means when you write x = 4;, but what does it mean if you write 4 = x;? According to clause 6.3.2.1[#1], it means nothing, and this is not a C program. The non-guarantee in this case is extremely strong. The C compiler, upon encountering this locution, is allowed to abort and spontaneously erase all your files, and in doing so it is not violating the requirements of the standard, because the standard does not require any particular behavior in this case.
The memorable phrase that the comp.lang.c folks use is that using that construction might cause demons to fly out of your nose.
[ Addendum 20071030: I am informed that I misread the standard here, and that the behavior of this particular line is not undefined, but requires a compiler diagnostic. Perhaps a better example would have been x = *(char *)0. ]
I mentioned this in passing in one of my recent articles about a C program I wrote:
unsigned strinc(char *s)
{
char *p = strchr(s, '\0') - 1;
while (p >= s && *p == 'A' + colors - 1) *p-- = 'A';
if (p < s) return 0;
(*p)++;
return 1;
}
Here the pointer p starts at the end of the string s,
and the loop might stop when p points to the position just
before s. Except no, that is forbidden, and the program might
at that moment cause demons to fly out of your nose. You are allowed
to have a pointer that points to the position just after an
object, but not one that points just before. Well anyway, I seem to have digressed. My point was that M. Gould says that one advantage of languages like Perl that are defined wholly by their (one) implementation is that you never have "undefined behavior". If you want to know what some locution does, you type it in and see what it does. Poof, instant definition.
Although I think this is a sound point, it occurred to me that that is not entirely correct. The manual is a specification of sorts, and even if the implementation does X in situation Y, the manual might say "The implementation does X in situation Y, but this is unsupported and may change without warning in the future." Then what you have is not so different from Y being undefined behavior. Because the manual is (presumably) a statement of official policy from the maintainers, and, as a communiqué from the people with the ultimate authority to define the future meaning of the language, it has some of the same status that a formal specification would.
Perl: the static variable hack
Such disclaimers do appear in the Perl documentation. Probably the most significant example of this is the static variable hack. For various implementation reasons, the locution my $static if 0 has a strange and interesting effect:
sub foo {
my $static = 42 if 0;
print "static is now $static\n";
$static++;
}
foo() for 1..5;
This makes $static behave as a "static" variable, and persist
from call to call of foo(). Without the ... if 0,
the code would print "static is now 42" five times. But with
... if 0, it prints:
static is now
static is now 1
static is now 2
static is now 3
static is now 4
This was never an intentional feature. It arose accidentally, and
then people discovered it and started using it. Since the behavior
was the result of a strange quirk of the implementation, caused by the
surprising interaction of several internal details, it was officially
decided by the support group that this behavior would not be supported
in future versions. The manual was amended to say that this behavior
was explicitly undefined, and might change in the future. It can be
used in one-off programs, but not in any important program, one that
might have a long life and need to be run under several different
versions of Perl. Programs that use pointers that point outside the
bounds of allocated storage in C are in a similar position. It might
work on today's system, with today's compiler, today, but you can't do
that in any larger context.Having the "undefined behavior" be determined by the manual, instead of by a language standard, has its drawbacks. The language standard is fretted over by experts for months. When the C standard says that behavior is undefined, it is because someone like Clive Feather or Doug Gwyn or P.J. Plauger, someone who knows more about C than you ever will, knows that there is some machine somewhere on which the behavior is unsupported and unsupportable. When the Perl manual says that some behavior is undefined, you might be hearing from the Perl equivalent of Doug Gwyn, someone like Nick Clark or Chip Salzenberg or Gurusamy Sarathy. Or you might be hearing from a mere nervous-nellie who got their patch into the manual on a night when the release manager had stayed up too late.
Perl: modifying a hash in a loop
Here is an example of this that has bothered me for a long time. One can use the each() operator to loop lazily over the contents of a hash:
while (my $key = each %hash) {
# do something with $key and $hash{$key}
}
What happens if you modify the hash in the middle of the loop? For
various implementation reasons, the manual forbids this.For example, suppose the loop code adds a new key to the hash. The hash might overflow as a result, and this would trigger a reorganization that would move everything around, destroying the ordering information. The subsequent calls to each() would continue from the same element of the hash, but in the new order, making it likely that the loop would visit some keys more than once, or some not at all. So the prohibition in that case makes sense: The each() operator normally guarantees to produce each key exactly once, and adding elements to a hash in the middle of the loop might cause that guarantee to be broken in an unpredictable way. Moreover, there is no obvious way to fix this without potentially wrecking the performance of hashes.
But the manual also forbids deleting keys inside the loop, and there the issue does not come up, because in Perl, hashes are never reorganized as the result of a deletion. The behavior is easily described: Deleting a key that has already been visited will not affect the each() loop, and deleting one that has not yet been visited will just cause it to be skipped when the time comes.
Some people might find this general case confusing, I suppose. But the following code also runs afoul of the "do not modify a hash inside of an each loop" prohibition, and I don't think anyone would find it confusing:
while (my $key = each %hash) {
delete $hash{$key} if is_bad($hash{$key});
}
Here we want to delete all the bad items from the hash. We do this by
scanning the hash and deleting the current item whenever it is bad.
Since each key is deleted only after it is scanned by each,
we should expect this to visit every key in the hash, as indeed it
does. And this appears to be a useful thing to write. The only
alternative is to make two passes, constructing a list of bad keys on
the first pass, and deleting them on the second pass. The code would
be more complicated and the time and memory performance would be much
worse.There is a potential implementation problem, though. The way that each() works is to take the current item and follow a "next" pointer from it to find the next item. (I am omitting some unimportant details here.) But if we have deleted the current item, the implementation cannot follow the "next" pointer. So what happens?
In fact, the implementation has always contained a bunch of code, written by Larry Wall, to ensure that deleting the current key will work properly, and that it will not spoil the each(). This is nontrivial. When you delete an item, the delete() operator looks to see if it is the current item of an each() loop, and if so, it marks the item with a special flag instead of deleting it. Later on, the next time each() is invoked, it sees the flag and deletes the item after following the "next" pointer.
So the implementation takes some pains to make this work. But someone came along later and forbade all modifications of a hash inside an each loop, throwing the baby out with the bathwater. Larry and perl paid a price for this feature, in performance and memory and code size, and I think it was a feature well bought. But then someone patched the manual and spoiled the value of the feature. (Some years later, I patched the manual again to add an exception for this case. Score!)
Perl: modifying an array in a loop
Another example is the question of what happens when you modify an array inside a loop over the array, as with:
@a = (1..3);
for (@a) {
print;
push @a, $_ + 3 if $_ % 2 == 1;
}
(This prints 12346.) The internals are simple, and the semantics are
well-defined by the implementation, and straightforward, but the
manual has the heebie-jeebies about it, and most of the Perl community
is extremely superstitious about this, claiming that it is "entirely
unpredictable". I would like to support this with a quotation from
the manual, but I can't find it in the enormous and disorganized mass
that is the Perl documentation.[ Addendum: Tom Boutell found it. The perlsyn page says "If any part of LIST is an array, foreach will get very confused if you add or remove elements within the loop body, for example with splice. So don't do that." ]
The behavior, for the record, is quite straightforward: On the first iteration, the loop processes the first element in the array. On the second iteration, the loop processes the second element in the array, whatever that element is at the time the second iteration starts, whether or not that was the second element before. On the third iteration, the loop processes the third element in the array, whatever it is at that moment. And so the loop continues, terminating the first time it is called upon to process an element that is past the end of the array. We might imagine the following pseudocode:
index = 0;
while (index < array.length()) {
process element array[index];
index += 1;
}
There is nothing subtle or difficult about this, and claims that the
behavior is "entirely unpredictable" are probably superstitious
confessions of ignorance and fear.Let's try to predict the "entirely unpredictable" behavior of the example above:
@a = (1..3);
for (@a) {
print;
push @a, $_ + 3 if $_ % 2 == 1;
}
Initially the array contains (1, 2, 3), and so the first iteration
processes the first element, which is 1. This prints 1, and, since 1
is odd, pushes 4 onto the end of the array.The array now contains (1, 2, 3, 4), and the loop processes the second element, which is 2. 2 is printed. The loop then processes the third element, printing 3 and pushing 6 onto the end. The array now contains (1, 2, 3, 4, 6).
On the fourth iteration, the fourth element (4) is printed, and on the fifth iteration, the fifth element (6) is printed. That is the last element, so the loop is finished. What was so hard about that?
Haskell: n+k patterns
My blog was recently inserted into the feed for planet.haskell.org, and of course I immediately started my first streak of posting code-heavy articles about C and Perl. This is distressing not just because the articles were off-topic for Planet Haskell—I wouldn't give the matter two thoughts if I were posting my usual mix of abstract math and stuff—but it's so off-topic that it feels weird to see it sitting there on the front page of Planet Haskell. So I thought I'd make an effort to talk about Haskell, as a friendly attempt to promote good relations between tribes. I'm not sure what tribe I'm in, actually, but what the heck. I thought about Haskell a bit, and a Haskell example came to mind.Here is a definition of the factorial function in Haskell:
fact 0 = 1
fact n = n * fact (n-1)
I don't need to explain this to anyone, right?Okay, now here is another definition:
fact 0 = 1
fact (n+1) = (n+1) * fact n
Also fine, and indeed this is legal Haskell. The pattern n+1
is allowed to match an integer that is at least 1, say 7, and doing so binds n to
the value 6. This is by a rather peculiar special case in the
specification of Haskell's pattern-matcher. (It is section 3.17.2#8
of Haskell 98 Language and Libraries: The Revised
Report, should you want to look it up.) This peculiar
special case is known sometimes as a "successor pattern" but more
often as an "n+k pattern".The spec explicitly deprecates this feature:
Many people feel that n+k patterns should not be used. These patterns may be removed or changed in future versions of Haskell.
(Page 33.) One wonders why they put it in at all, if they were going to go ahead and tell you not to use it. The Haskell committee is usually smarter than this.
 I have a vague recollection that there was an argument between people
who wanted to use Haskell as a language for teaching undergraduate
programming, and those who didn't care about that, and that this was
the compromise result. Like many compromises, it is inferior to both
of the alternatives that it interpolates between. Putting the feature
in complicates the syntax and the semantics of the language, disrupts
its conceptual purity, and bloats the
spec—see the Perlesque yikkity-yak on pages 57–58 about
how x + 1 = ... binds a meaning to +, but (x +
1) = ... binds a meaning to x. Such complication is
worth while only if there is a corresponding payoff in terms of
increased functionality and usability in the language. In this case,
the payoff is a feature that can only be used in one-off programs.
Serious programs must avoid it, since the patterns "may be removed or
changed in future versions of Haskell". The Haskell committee
purchased this feature at a certain cost, and it is debatable whether
they got their money's worth. I'm not sure which side of that issue I
fall on. But having purchased the feature, the committee then threw
it in the garbage, squandering their sunk costs. Oh well. Not even
the Haskell committee is perfect.
I have a vague recollection that there was an argument between people
who wanted to use Haskell as a language for teaching undergraduate
programming, and those who didn't care about that, and that this was
the compromise result. Like many compromises, it is inferior to both
of the alternatives that it interpolates between. Putting the feature
in complicates the syntax and the semantics of the language, disrupts
its conceptual purity, and bloats the
spec—see the Perlesque yikkity-yak on pages 57–58 about
how x + 1 = ... binds a meaning to +, but (x +
1) = ... binds a meaning to x. Such complication is
worth while only if there is a corresponding payoff in terms of
increased functionality and usability in the language. In this case,
the payoff is a feature that can only be used in one-off programs.
Serious programs must avoid it, since the patterns "may be removed or
changed in future versions of Haskell". The Haskell committee
purchased this feature at a certain cost, and it is debatable whether
they got their money's worth. I'm not sure which side of that issue I
fall on. But having purchased the feature, the committee then threw
it in the garbage, squandering their sunk costs. Oh well. Not even
the Haskell committee is perfect.
I think it might be worth pointing out that the version of the program with the n+k pattern is technically superior to the other version. Given a negative integer argument, the first version recurses forever, possibly taking a long time to fail and perhaps taking out the rest of the system on which it is running. But the n+k version fails immediately, because the n+1 pattern will only match an integer that is at least 1.
XML screws up
The "nasal demons" of the C standard are a joke, but a serious one. The C standard defines what C compilers must do when presented with C programs; it does not define what they do when presented with other inputs, nor what other software does when presented with C programs. The authors of C standard clearly understood the standard's role in the world.Earlier versions of the XML standard were less clear. There was a particularly laughable clause in the first edition of the XML 1,0 standard:
XML documents may, and should, begin with an XML declaration which specifies the version of XML being used. For example, the following is a complete XML document, well-formed but not valid:
<?xml version="1.0"?> <greeting>Hello, world!</greeting>...
The version number "1.0" should be used to indicate conformance to this version of this specification; it is an error for a document to use the value "1.0" if it does not conform to this version of this specification.
(Emphasis is mine.) The XML 1.0 spec is just a document. It has no power, except to declare that certain files are XML 1.0 and certain files are not. A file that complies with the requirements of the spec is XML 1.0; all other files are not XML 1.0. But in the emphasized clause, the spec says that certain behavior "is an error" if it is exhibited by documents that do not conform to the spec. That is, it is declaring certain non-XML-1.0 documents "erroneous". But within the meaning of the spec, "erroneous" simply means that the documents are not XML 1.0. So the clause is completely redundant. Documents that do not conform to the spec are erroneous by definition, whether or not they use the value "1.0".
It's as if the Catholic Church issued an edict forbidding all rabbis from wearing cassocks, on pain of excommunication.
I am happy to discover that this dumb error has been removed from the most recent edition of the XML 1.0 spec.
[Other articles in category /prog/perl] permanent link
Sat, 28 Jul 2007
Lightweight Database Strategies for Perl
Several years ago I got what I thought was a great idea for a
three-hour conference tutorial: lightweight data storage techniques.
When you don't have enough data to be bothered using a
high-performance database, or when your data is simple enough that you
don't want to bother with a relational database, you stick it in a
flat file and hack up some file code to read it. This is the sort of
thing that people do all the time in Perl, and I thought it
would be a big seller. I was wrong.
I don't know why. I tried giving the class a snappier title, but that didn't help. I'm really bad at titles. Maybe people are embarrassed to think about all the lightweight data storage hackery they do in Perl, and feel that they "should" be using a relational database, and don't want to commit more resources to lightweight database techniques. Or maybe they just don't think there is very much to know about it.
But there is a lot to know; with a little bit of technique you can postpone the day when you need to go to an RDB, often for quite a long time, and often forever. Many of the techniques fall into the why-didn't-I-think-of-that category, stuff that isn't too weird to write or maintain, but that you might not have thought to try.
I think it's a good class, but since it never sold well, I've decided it would do more good (for me and for everyone else) if I just gave away the materials for free.
Table of Contents
The class is in three sections. The first section is about using plain text files and talks about a bunch of useful techniques, such as how to do binary search on sorted text files (this is nontrivial) and how to replace records in-place, when they might not fit.The second section is about the Tie::File module, which associates a flat text file with a Perl array.
The third section is about DBM files, with a comparison of the five major implementations. It finishes up with a discussion of some of Berkeley DB's lesser-known useful features, such as its DB_BTREE file type, which offers fast access like a hash but keeps the records in sorted order
- Text Files
- Rotating log file; deleting a user
- Copy the File
- -i.bak
- Using -i inside a program
- Problems with -i
- Atomicity issues
- Essential problem with files; fundamental operations; seeking
- Sorted files
- In-place modification of records
- Overwriting records
- Bytes vs. positions
- Gappy Files
- Fixed-length records
- Numeric indices
- Case study: lastlog
- Indexing
- Void fields
- Generic text indices
- Packed offsets
- Tie::File
- Tie::File Examples
- delete_user revisited
- uppercase_username revisited
- Rotating log file revisited
- Most important thing to know about Tie::File
- Indexing with Tie::File
- Tie::File Internals
- Caching
- Record modification
- Immediate vs. Deferred Writing
- Autodeferring
- Miscellaneous Features
- DBM
- Common DBM Implementations
- What DBM Does
- Small DBMs: ODBM, NDBM, and SDBM
- GDBM
- DB_File
- Indexing revisited
- Ordered hashes
- Partial matching
- Sequential access
- Multiple values
- Filters
- BerkeleyDB
Online materials
- Class slides:

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 License.- PDF files:
- Browse slides online
- Sample source code referred to in the class:

Example source code from Lightweight Databases class is licensed under a Creative Commons Public Domain License. - People sometimes ask what use Tie::File is when Berkeley DB has a DB_RECNO option that appears to be the same thing. This document explains why.
[Other articles in category /prog/perl] permanent link