Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 250 |
| Programming | 102 |
| Language | 97 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Thu, 31 Jan 2008
Unnecessary imprecision
This
article contains the following sentence:
McCain has won all of the state's 57 delegates, and the last primary before voters in more than 20 states head to the polls next Tuesday.Why "more than 20 states"? Why not just say "23 states", which is shorter and conveys more information?
I'm not trying to pick on CTV here. A Google News search finds 42,000 instances of "more than 20", many of which could presumably be replaced with "26" or whatever. Well, I had originally written "most of which", but then I looked at some examples, and found that the situation is better than I thought it would be. Here are the first ten matches:
- Australian Stocks Complete Worst Month in More Than 20 Years
- It said the US air force committed more than 20 cases of aerial espionage by U-2 strategic espionage planes this month.
- Farmland prices have climbed more than 20% over the past year in many Midwestern states...
- "We have had record-breaking growth in our monthly shipments, as much as more than 20 percent improvements per month," said Christopher Larkins, President...
- More than 20 people, including a district officer, were injured when two bombs exploded outside a stadium in the town yesterday...
- By a vote of 14-7, the Senate Finance Committee last night voted to deliver $500 tax rebates to more than 20 million American senior citizens...
- 9 killed, more than 20 injured in bus accident
- While Tuesday's results may not lock up the nomination for either candidate, Democrats will have their say in more than 20 states...
- Facing the potential anointment of his rival, John McCain, Romney has less than a week to convince voters in more than 20 states that...
- More than 20 Aberdeen citizens qualified for elections as April ...
#2 may be legitimate, if the number of cases of aerial espionage is not known with certitude, or if the anonymous source really did say "more than 20". Similarly #4 is entirely off the hook since it is a quotation.
#3 may be legitimate if the price of farmland is uncertain and close to 20%. #5 is probably a loser. #7 is definitely a loser: it was the headline of an article that began "Nine people were killed and at least 22 injured when...". The headline could certainly have been "9 killed, 22 injured in bus accident".
#8 and #9 are losers, but they are the same example with which I began the article, so they don't count. #10 is a loser.
So I have, of eight examples (disregarding #8 and #9) three certain or near-certain failures (#5, #7, and #10), one certain non-failure (#4), and four cases to which I am willing to extend the benefit of the doubt. This is not as bad as I feared. I like when things turn out better than I thought they would.
But I really wonder what is going on with all these instances of "more than 20 states". Is it just sloppy writing? Or is there some benefit that I am failing to appreciate?
[Other articles in category /lang] permanent link
Ramanujan's congruences
Let p(n) be the number of partitions of the integer
n. For example, p(4) = 5 because there are 5 partitions
of the integer 4, namely {4, 3+1, 2+2, 2+1+1, 1+1+1+1}.
Ramanujan's congruences state that:
| p(5k+4) | =0 | (mod 5) |
| p(7k+5) | =0 | (mod 7) |
| p(11k+6) | =0 | (mod 11) |
Looking at this, anyone could conjecture that p(13k+7) = 0 (mod 13), but it isn't so; p(7) = 15 and p(20) = 48·13+3.
But there are other such congruences. For example, according to Partition Congruences and the Andrews-Garvan-Dyson Crank:
$$ p(17\cdot41^4k + 1122838) = 0 \pmod{17} $$
Isn't mathematics awesome?
[Other articles in category /math] permanent link
Tue, 29 Jan 2008
The Census Bureau's data file
Last week I posted an article about calculations
with data provided by the U.S. Census Bureau. I'm thinking about
writing that up in more detail, but today I learned something so
astonishing that I couldn't wait to mention it.
The data is available from the Census Bureau's web site. It is a CSV file. Most of the file contains actual data, like this:
20220,,"Dubuque, IA",Metropolitan Statistical Area,"92,384","91,603","91,223","90,635","89,571","89,216","89,265","89,156","89,143"Experienced data mungers will feel a sense of foreboding as they look at the commas in those numerals. Commas are for people, and if the data file is written for people, rather than for computers, then getting the computer to read it is going to require at least a little bit of suffering. Indeed, the rest of the data is rather dirty. There is a useless header:
table with row headers in column A and column headers in rows 3 through 4 (leading dots indicate sub-parts),,,,,,,,,,,,^M "Table 1. Annual Estimates of the Population of Metropolitan and Micropolitan Statistical Areas: April 1, 2000 to July 1, 2006",,,,,,,,,,,,^M CBSA Code,"Metro Division Code",Geographic area,"Legal/statistical area description",Population estimates,,,,,,,"April 1, 2000",^M ,,,,"July 1, 2006","July 1, 2005","July 1, 2004","July 1, 2003","July 1, 2002","July 1, 2001","July 1, 2000",Estimates base,Census^M ,,Metropolitan statistical areas,,,,,,,,,,^MAnd there is a similarly useless footer on the bottom of the file. Any program that wants to use this data has to trim off the header and the footer, or ignore them, or the user will have to trim them off manually.
(I've translated ASCII CR characters to ^M sequences so that you can see that although the lines of the file are CR-LF terminated, some of the items contain extra LFs for no particular reason.)
Well, all this is minor. My real complaint is that some of the state name abbreviations are garbled:
19740,,"Denver-Aurora, CO1",Metropolitan Statistical Area,"2,408,750","2,361,778","2,326,126","2,299,879","2,276,592","2,245,030","2,193,737","2,179,320","2,179,240"
Notice that it says CO1 rather than CO, short for
"Colorado". I was fortunate to notice this garbling. Since it
occurred on the line for Denver (among others) the result was that the
program was unable to locate the population of Denver, which is the
capital of Colorado, and a mandatory part of the program's output. So
it raised a warning. Then I went in and manually corrected the
CO1 to say CO. I also added a check to the program
to make sure that it recognized all the state abbreviations; I should
have had this in there in the first place.Then I sent email to an acquaintance who works for the Census Bureau (identity suppressed to protect the innocent), pointing out the errors so that they could be corrected.
My contact checked with the people who produced the data, and informed me that, according to them, CO1 was not an error. Rather, the 1 was a footnote mark, directing me to a footnote at the bottom of the file:
"1Broomfield, CO was formed from parts of Adams, Boulder, Jefferson, and Weld Counties, CO on November 15, 2001 and was coextensive with Broomfield city.",,,,,,,,,,,,^M "For purposes of presenting data for metropolitan and micropolitan statistical areas for Census 2000, Broomfield is treated as if it were a county at the time of the 2000 census.",,,,,,,,,,,,^MA footnote.

I would like to suggest the following as a basic principle of computerized data processing:
Data files should contain data.
Not metadata. Not explanations. Not little essays. And not footnotes. Just the data.There's a larger issue here about confusing content and presentation. But "Data files should contain data" is simpler and easier to remember.
I suspect that this file was exported from a spreadsheet program, probably Excel. Spreadsheet programs desperately want you to confuse content and presentation. This is why one should not use a spreadsheet as a database.
I now recall another occasion when I had to deal with data that was exported from a spreadsheet that was pretending to be a database. It was a database of products made by a large cosmetics company. A typical record looked like this:
"Soft-Pressed Powder Blusher","618J-05","Warm, natural-looking powder colour for all skins. Wide range of shades-subtle to vibrant. With applicator brush.","Cheeks","Nudes","Chestnut Blush","All","","19951201","Yes","","14.5",""The 618J-05 here is a product code. Bonus points if you see what's coming next.
"Water-Dissolve Cream Cleanser","6.61E+01","Creamy cleanser for drier, more sensitive skins. Dissolves even the most tenacious makeups.","Cleansers","","","","Sub I, I, II","19951201","Yes","1","14.5",""
That 6.61E+01 should have been 661E-01, but Excel
decided that it was a numeral, in scientific notation, and put it into
normal form.Back to the Census Bureau, which almost screwed me by putting a footnote on a state name. What if they had decided to put footnotes on the population figures? Then I would have been really screwed, because it would have been completely undetectable.
No, wait! It's all become clear. That's why they put the commas in the numerals!
[ Addendum 20080129: My Census Bureau contact tells me that the authors of the data file have seen the wisdom of my point of view, in spite of my unconstructive and unhelpful feedback (I said "Wow, that is an incredibly terrible idea") and are planning to address the issue in the next release of the data. Hooray for happy endings! ]
[ Addendum 20080129: My Census Bureau contact tells me that they do sometimes put footnotes on the data items, so don't laugh too hard at my remark about the commas. ]
[Other articles in category /misc] permanent link
Fri, 25 Jan 2008
Nonstandard adjectives in mathematics
Ranjit Bhatnagar once propounded the notion of a "nonstandard"
adjective. This is best explained by an example. "Red" is not usually
a nonstandard adjective, because a red boat is still a boat, a red hat
is still a hat, and a red flag is still a flag. But "fake" is
typically nonstandard, because a fake diamond is not a diamond, a fake
Gucci handbag is not a Gucci handbag.
The property is not really attached to the adjective itself. Red emeralds are not emeralds, so "red" is nonstandard when applied to emeralds. Fake expressions of sympathy are still expressions of sympathy, however insincere. "Toy" often goes both ways: a toy fire engine is not a fire engine, but a toy ball is a ball and a toy dog is a dog.
Adjectives in mathematics are rarely nonstandard. An Abelian group is a group, a second-countable topology is a topology, an odd integer is an integer, a partial derivative is a derivative, a well-founded order is an order, an open set is a set, and a limit ordinal is an ordinal.
When mathematicians want to express that a certain kind of entity is similar to some other kind of entity, but is not actually some other entity, they tend to use compound words. For example, a pseudometric is not (in general) a metric. The phrase "pseudo metric" would be misleading, because a "pseudo metric" sounds like some new kind of metric. But there is no such term.
But there is one glaring exception. A partial function is not (in general) a function. The containment is in the other direction: all functions are partial functions, but not all partial functions are functions. The terminology makes more sense if one imagines that "function" is shorthand for "total function", but that is not usually what people say.
If I were more quixotic, I would propose that partial functions be called "partialfunctions" instead. Or perhaps "pseudofunctions". Or one could go the other way and call them "normal relations", where "normal" can be replaced by whatever adjective you prefer—ejective relations, anyone?
I was about to write "any of these would be preferable to the current confusion", but actually I think it probably doesn't matter very much.
[ Addendum 20080201: Another example, and more discussion of "partial". ]
[ Addendum 20081205: A contravariant functor is not a functor. ]
[ Addendum 20090121: A hom-set is not a set. ]
[ Addendum 20110905: A skew field is not a field. The Wikipedia article about division rings observes that this use of "skew" is counter to the usual behavior of adjectives in mathematics. ]
[ Addendum 20120819: A snub cube is not a cube. Several people have informed me that a quantum group is not a group. ]
[ Addendum 20140708: nLab refers to the red herring principle, that “in mathematics, a ‘red herring’ need not, in general, be either red or a herring”. ]
[ Addendum 20160505: The gaussian integers contain the integers, not vice versa, so a gaussian integer is not in general an integer. ]
[ Addendum 20190503: Timon Salar Gutleb points out that affine spaces were at one time called “affine vector spaces” so that every vector space was an affine vector space, but not vice versa. ]
[ Addendum 20221106: the standard term for this appears to be “privative adjective”. ]
[ Addendum 20240508: [Robin Houston asks if there is such a thing as an incorrect proof](https://mathstodon.xyz/@robinhouston/112401229287518162). [Simon Tatham points out](https://mathstodon.xyz/@simontatham@hachyderm.io/112404198589351199) that a “manifold with boundary” is not a manifold. ]
[Other articles in category /math] permanent link
Thu, 24 Jan 2008
Emacs and alists
[ This article is a few weeks old now. I wrote it and forgot to publish it
at the time. ]
Yesterday I upgraded Emacs, and since it was an upgrade, something that had been working for me for fifteen years stopped working, because that's what "upgrade" means. My .emacs file contains:
(aput 'auto-mode-alist "\\.pl\\'" (function cperl-mode))
(aput 'auto-mode-alist "\\.t\\'" (function cperl-mode))
(aput 'auto-mode-alist "\\.cgi\\'" (function cperl-mode))
(aput 'auto-mode-alist "\\.pm\\'" (function cperl-mode))
(aput 'auto-mode-alist "\\.blog\\'" (function text-mode))
(aput 'auto-mode-alist "\\.sml\\'" (function sml-mode))
I should explain this, since I imagine that most readers of this blog
are like me in that they touch Emacs Lisp only once a year on Saint
Vibrissa's Day. An alist ("association list") is a common data
structure in Lisp programs. It is a list of pairs; the first element
of each pair is a key, and the second element is an associated value.
The pairs in the special auto-mode-alist variable have regexes
as their keys and functions as their values. Whenever Emacs opens a
new file, it scans this alist, until it finds a regex that matches the
name of the file. It then executes the associated function. Thus the
effect of the first line above is to have Emacs enable the
cperl-mode function on any file whose name ends in ".pl".
The aput function is for maintaining alists. It takes an alist, a key, and a value, scans the alist looking for a matching key, and then if it finds it, it amends the corresponding value. Otherwise, it appends a new association onto the front of the alist.
When I upgraded emacs, this broke. The aput function was moved into a separate package, which I now had to load with (require 'assoc).
I asked about this on IRC, and was told that the correct way to do this, if I did not want to (require 'assoc), was to use the following abomination:
(mapc (lambda (x) (when (eq 'perl-mode (cdr x)) (setcdr x 'cperl-mode)))
(append auto-mode-alist interpreter-mode-alist))
The effect of this is to scan over auto-mode-alist (and also
interpreter-mode-alist, a related variable) looking for any
association whose value was the perl-mode function, and
using setcdr to replace perl-mode with
cperl-mode.(This does not address the issue of what to do with .t files or .blog files, for which no association exists yet, presumably, but I did not ask about those specifically on IRC.)
I was totally boggled. Choosing the right editing mode for a file is a basic function of emacs. I could not believe that the best and simplest way to add or change associations was to use mapc lambda gobhorn oleo potatopudding quote potrzebie. I was assured that this was indeed the only correct method. Struck almost speechless, I managed to come up with "Bullshit."
Apparently the issue was that if auto-mode-alist already contains an association for ".pl", there is no guarantee that my new association will be found and preferred to the old one, unless I somehow remove the old one, or edit it to be the way I want.
This seemed very unlikely to me. You see, an alist is a list. This means that it is searched from head to tail, because this is the only way a list can be searched. So in particular, if you cons a second association to the front of the list, which has the same key as a later (older) association, the search will find the new one first, and the older one becomes inoperative. I asked if there was not a guarantee that the alist would be searched from front to back. I was told that there is not.
I looked in the manual, and reported that the assoc function, which is the getter that corresponds to aput, taking an alist and a key, and returning the corresponding value, is expressly guaranteed to return the first matching item. I was told that there was no guarantee that assoc would be used.
I pondered the manual some more and found this passage:
However, association lists have their own advantages. Depending on your application, it may be faster to add an association to the front of an association list than to update a property.That is, it is expressly endorsing the technique of adding a new item to the front of an alist in order to override any later item that might have the same key.
After finding that the add-to-the-front technique really did work, I reasoned that if someday Emacs stopped searching alists sequentially, I would not be in any more trouble than I had been today when they removed the aput function.
So I did not take the advice I was given. Instead, I left it pretty much the way it was. I did take the opportunity to clean up the code a bit:
(push '("\\.pl\\'" . cperl-mode) auto-mode-alist)
(push '("\\.t\\'" . cperl-mode) auto-mode-alist)
(push '("\\.cgi\\'" . cperl-mode) auto-mode-alist)
(push '("\\.pm\\'" . cperl-mode) auto-mode-alist)
(push '("\\.blog\\'" . text-mode) auto-mode-alist)
(push '("\\.sml\\'" . sml-mode) auto-mode-alist)
The push function simply appends an element to the front of a
list, modifying the list in-place.But wow, the advice I got was phenomenally bad. It was bad in a really interesting way, too. It reminded me of the advice people get on the #math channel, where some guy comes in with some question about triangles and gets the category-theoretic viewpoint on triangles as natural transformations of something or other. The advice was bad because although it was correct, it was completely devoid of common sense.
[ Addendum 20080124: It has been brought to my attention that the Emacs FAQ endorses my solution, which makes the category-theoretic advice proposed by the #emacs blockheads even less defensible. ]
[ Addendum 20080201: Steve Vinoski suggests replacing the aput function. ]
[Other articles in category /prog] permanent link
Wed, 23 Jan 2008
Smallest state capitals
I think it was James Kushner who first suggested that I consider the
question of which U.S. state capital had the smallest population in
relation to its state's largest city. For example, New York City is
the largest city in the United States, but the state capital of New
York State is Albany, with a population of about 850,000. The
population of New York City exceeds that of Albany by a factor of
around 20.
At the other end of the scale, of course, we have state capitals like Boston, Denver, Atlanta, and Honolulu that are their state's largest cities. For these states, the population quotient is 1, its theoretical minimum.
Well, James, it only took me thirty years, but here it is.
I tried to resolve the question manually a few weeks ago, by browsing Wikipedia for the populations of likely candidates. Today I took a more methodical approach, downloading the U.S. Census Bureau's July 2006 estimates for populations of metropolitan areas, and writing a couple of little programs to grovel the data.
I had to augment the Census Bureau's data with two items: Annapolis, MD, and Montpelier, VT are not large enough to be included in the metropolitan area data file. I used U.S. Census 2006 estimates for these cities as well.
I discarded one conurbation: the Census Bureau includes a "Metropolitan Division" in New Hampshire that consists of Rockingham and Strafford counties; this was the most populous identified area in New Hampshire. It didn't seem entirely germane to the question, so I took it out. On the other hand, including it doesn't change the results much: its population is 416,000, compared with Manchester-Nashua's 402,000.
The results follow.
| State | Capital and its Population | Largest metropolitan area and its population | Quotient | |||
|---|---|---|---|---|---|---|
| MD | Annapolis | 36,408 | Baltimore-Towson | 2,658,405 | 73 | .02 |
| IL | Springfield | 206,112 | Chicago-Naperville-Joliet | 9,505,748 | 46 | .12 |
| NV | Carson City | 55,289 | Las Vegas-Paradise | 1,777,539 | 32 | .15 |
| VT | Montpelier | 7,954 | Burlington-South Burlington | 206,007 | 25 | .90 |
| NY | Albany | 850,957 | New York-Northern New Jersey-Long Island | 18,818,536 | 22 | .11 |
| MO | Jefferson City | 144,958 | St. Louis | 2,796,368 | 19 | .29 |
| KY | Frankfort | 69,068 | Louisville-Jefferson County | 1,222,216 | 17 | .70 |
| FL | Tallahassee | 336,502 | Miami-Fort Lauderdale-Miami Beach | 5,463,857 | 16 | .24 |
| WA | Olympia | 234,670 | Seattle-Tacoma-Bellevue | 3,263,497 | 13 | .91 |
| AK | Juneau | 30,737 | Anchorage | 359,180 | 11 | .69 |
| PA | Harrisburg | 525,380 | Philadelphia-Camden-Wilmington | 5,826,742 | 11 | .09 |
| SD | Pierre | 19,761 | Sioux Falls | 212,911 | 10 | .77 |
| MI | Lansing | 454,044 | Detroit-Warren-Livonia | 4,468,966 | 9 | .84 |
| NJ | Trenton | 367,605 | Edison | 2,308,777 | 6 | .28 |
| CA | Sacramento | 2,067,117 | Los Angeles-Long Beach-Santa Ana | 12,950,129 | 6 | .26 |
| NM | Santa Fe | 142,407 | Albuquerque | 816,811 | 5 | .74 |
| OR | Salem | 384,600 | Portland-Vancouver-Beaverton | 2,137,565 | 5 | .56 |
| DE | Dover | 147,601 | Wilmington | 691,688 | 4 | .69 |
| VA | Richmond | 1,194,008 | Washington-Arlington-Alexandria | 5,290,400 | 4 | .43 |
| ME | Augusta | 121,068 | Portland-South Portland-Biddeford | 513,667 | 4 | .24 |
| TX | Austin | 1,513,565 | Dallas-Fort Worth-Arlington | 6,003,967 | 3 | .97 |
| AL | Montgomery | 361,748 | Birmingham-Hoover | 1,100,019 | 3 | .04 |
| NE | Lincoln | 283,970 | Omaha-Council Bluffs | 822,549 | 2 | .90 |
| WI | Madison | 543,022 | Milwaukee-Waukesha-West Allis | 1,509,981 | 2 | .78 |
| NH | Concord | 148,085 | Manchester-Nashua | 402,789 | 2 | .72 |
| KS | Topeka | 228,894 | Wichita | 592,126 | 2 | .59 |
| MT | Helena | 70,558 | Billings | 148,116 | 2 | .10 |
| ND | Bismarck | 101,138 | Fargo | 187,001 | 1 | .85 |
| NC | Raleigh | 994,551 | Charlotte-Gastonia-Concord | 1,583,016 | 1 | .59 |
| LA | Baton Rouge | 766,514 | New Orleans-Metairie-Kenner | 1,024,678 | 1 | .34 |
| OH | Columbus | 1,725,570 | Cleveland-Elyria-Mentor | 2,114,155 | 1 | .23 |
| AR | Little Rock | 652,834 | Little Rock-North Little Rock | 652,834 | 1 | .00 |
| AZ | Phoenix | 4,039,182 | Phoenix-Mesa-Scottsdale | 4,039,182 | 1 | .00 |
| CO | Denver | 2,408,750 | Denver-Aurora | 2,408,750 | 1 | .00 |
| CT | Hartford | 1,188,841 | Hartford-West Hartford-East Hartford | 1,188,841 | 1 | .00 |
| GA | Atlanta | 5,138,223 | Atlanta-Sandy Springs-Marietta | 5,138,223 | 1 | .00 |
| HI | Honolulu | 909,863 | Honolulu | 909,863 | 1 | .00 |
| IA | Des Moines | 534,230 | Des Moines-West Des Moines | 534,230 | 1 | .00 |
| ID | Boise | 567,640 | Boise City-Nampa | 567,640 | 1 | .00 |
| IN | Indianapolis | 1,666,032 | Indianapolis-Carmel | 1,666,032 | 1 | .00 |
| MA | Boston | 4,455,217 | Boston-Cambridge-Quincy | 4,455,217 | 1 | .00 |
| MN | St. Paul | 3,175,041 | Minneapolis-St. Paul-Bloomington | 3,175,041 | 1 | .00 |
| MS | Jackson | 529,456 | Jackson | 529,456 | 1 | .00 |
| OK | Oklahoma City | 1,172,339 | Oklahoma City | 1,172,339 | 1 | .00 |
| RI | Providence | 1,612,989 | Providence-New Bedford-Fall River | 1,612,989 | 1 | .00 |
| SC | Columbia | 703,771 | Columbia | 703,771 | 1 | .00 |
| TN | Nashville | 1,455,097 | Nashville-Davidson--Murfreesboro | 1,455,097 | 1 | .00 |
| UT | Salt Lake City | 1,067,722 | Salt Lake City | 1,067,722 | 1 | .00 |
| WV | Charleston | 305,526 | Charleston | 305,526 | 1 | .00 |
| WY | Cheyenne | 85,384 | Cheyenne | 85,384 | 1 | .00 |
Vermont is an interesting outlier here. It makes fourth place not because it has a large city, but because its capital, Montpelier, is so very small. I tried doing some scatter plots, to see if anything else jumped out, but they weren't very illuminating. If anything, the data is suprisingly evenly distributed. Here's an example:
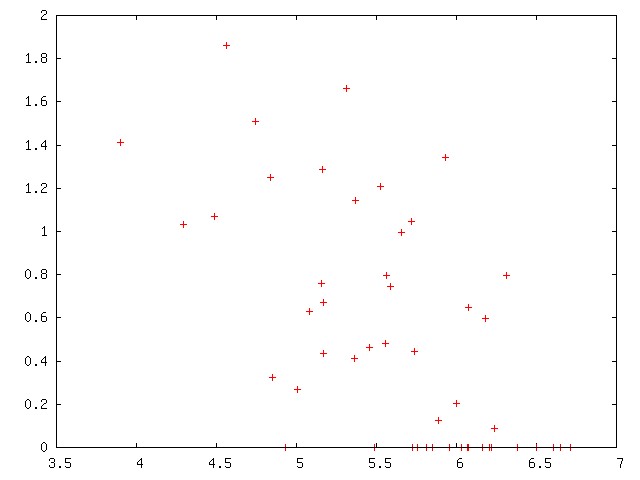
[ Addendum 20080129: Some remarks about the format of the Census Bureau's data file. ]
[ Addendum 20090217: A comparison of the relative sizes of each state's largest and second-largest cities. ]
[Other articles in category /misc] permanent link
Sun, 20 Jan 2008
Utterly Useless Book Reviews (#1 in a series?)
This month I'm reading Robert Graves' awesome novel King
Jesus. Here's the utterly useless review I wanted to write: It
does for the Bible what I, Claudius did for Suetonius.
And yeah, if you've read I, Claudius and Suetonius, then
that's all you need to know about King Jesus, and you'll
rush out to read it. But how many of you have read I,
Claudius and Suetonius? Hands? Anyone? Yeah, I didn't think so.
Okay, here's the explanation. Robert Graves was a novelist and a poet. (He himself said he was a poet who wrote novels so that he could earn enough money to write poetry.) I, Claudius is his best-known work. It is a history of the Roman emperors from the end of the reign of Julius Caesar up to the coronation of Claudius, told from the point of view of Claudius, who, though most of the book, is viewed by most of the other characters as harmless and inept, perhaps mentally deficient, or perhaps merely a doofus. It is this inept doofosity that explains his survival and eventual ascension to the Imperial throne at a time when everyone else in line for it was being exiled, burnt, poisoned, or disemboweled. The book is still in print, and in the 1970s, the BBC turned it into an extremely successful TV miniseries starring Derek Jacobi (as Claudius, obviously) and a lot of other actors who subsequently became people you have heard of. (Patrick Stewart! With hair!)

Graves was a classical scholar, and based his novel on the historical accounts available, principally The Twelve Caesars of Suetonius. Suetonius wrote his history after all the people involved were dead, and his book reads like a collection of anecdotes placed in approximately chronological order. Suetonius seems to have dug up and recorded as fact every scurrilous rumor he could find. Some of the rumors are contradictory, and some merely implausible. When Graves turned The Twelve Caesars into I, Claudius, he resolved this mass of unprocessed material into a coherent product. The puzzling trivialities are explained. The contradictions are cleared up. Sometimes the scurrilous rumors are explained as scurrilous rumors; sometimes Claudius explains the grain of truth that lies at their center. Other times the true story, as related by Claudius, is even worse than the watered-down version that came to Suetonius's ears. Suetonius mentions that, as emperor, Claudius tried to introduce three new letters into the alphabet. Huh? In Graves' novel, this is foreshadowed early, and when it finally happens, it makes sense.
In King Jesus, then, Graves has done for the Bible what he did for Suetonius in I, Claudius. He takes a mass of material, much of it misreported, or partly-forgotten stories written down a generation later, and reconstructs a plausible history from which that mass of material could have developed. The miracles are explained, without requiring anything supernatural or magical, but, at the same time, without becoming any less miraculous.

There is a story that Borges tells about the miracles performed by the Buddha, who generally eschewed miracles as being too showy. But Borges tells the story that one day the Buddha had to cross a desert, and seven different gods each gave him a parasol to shade his head. The Buddha did not want to offend any of the gods, so he split himself into seven Buddhas, and each one crossed the desert using a different parasol. He performed a miracle of politeness.
(The trouble with Borges's stories is that you never know which ones he read in some obscure 17th-century book, and which ones he made up himself. I spent a whole year thinking how clever Borges had been to have invented the novelist Adolfo Bioy Casares, with his alphabetical initials, and then one day I was in the bookstore and came upon the Adolfo Bioy Casares section. Oops.)
Anyway, Graves lets Jesus have the miracles, and they are indeed miraculous, but they are miracles of kindness and insight, not miracles of stage magic. When Graves explains the miracles, you say "oh, of course", without then saying "is that all?" I have not yet gotten to the part where Jesus silences the storm and walks on water, but I am looking forward to it. I did get to the loaves and fishes, and it was quite satisfactory. I am not going to spoil the surprise.
I recommend it. Check it out.
[ Addendum 20080201: James
Russell has read both I, Claudius and Twelve
Caesars. ]
[Other articles in category /book]
permanent link
Help, help!
Przemek Klosowski wrote to offer me physics help, and also to ask
about introspection on Perl objects. Specifically, he said that if
you called a nonexistent method on a TCL object, the error message
would include the names of all the methods that would have worked. He
wanted to know if there was a way to get Perl to do something
similar.
There isn't, precisely, because Perl has only a conventional
distinction between methods and subroutines, and you Just Have To Know
which is which, and avoid calling the subroutines as methods, because
the Perl interpreter has no idea which is which. But it does have
enough introspection features that you can get something like what you
want. This article will explain how to do that.
Here is a trivial program that invokes an undefined method on an
object:
Now consider the following program instead:
Some of the items may be intended to be called as functions, and not
as methods. Some may be functions imported from some other module. A
common offender here is Carp, which places a carp
function into another module's namespace; this function will show up
in a list like the one above, without even an "inherited from" note,
even though it is not a method and it does not make sense to call it
on an object at all.
Even when the items in the list really are methods, they may be
undocumented, internal-use-only methods, and may disappear in future
versions of the YAML module.
But even with all these warnings, Help is at least a partial
solution to the problem.
The real reason for this article is to present the code for
Help.pm, not because the module is so intrinsically useful
itself, but because it is almost a catalog of weird-but-useful Perl
module hackery techniques. A full and detailed tour of this module's
30 lines of code would probably make a decent 60- or 90-minute class
for intermediate Perl programmers who want to become wizards. (I have
given many classes on exactly that topic.)
Here's the code:
Typically, a module's import method is inherited from
Exporter, which gets control at this point and arranges to
make some of the module's functions available in the caller's
namespace. So, for example, when you invoke use YAML
'freeze' in your module, Exporter's import
method gets control and puts YAML's "freeze"
function into your module's namespace. But that is not what we are
doing here. Instead, Help has its own import
method:
@Foo::ISA is the array that is searched whenever a method call on a
Foo objects fails because the method doesn't exist. Perl
will search the classes named in @Foo::ISA, in order. It
will search the Help class last. That's important, because
we don't want Help to interfere with Foo's ordinary
inheritance.
Notice the way the variable name Foo::ISA is generated
dynamically by concatenating the value of $class with the
literal string ::ISA. This is how you access a variable
whose name is not known at compile time in Perl. We will see this
technique over and over again in this module.
The backslash in @{"$class\::ISA"} is necessary, because if
we wrote @{"$class::ISA"} instead, Perl would try to
interpolate the value of $ISA variable from the package named
class. We could get around this by writing something like
@{$class . '::ISA'}, but the backslash is easier to read.
But when method search fails, Perl doesn't give up right away.
Instead, it tries the method search a second time, this time looking
for a method named AUTOLOAD. If it finds one, it calls it.
It only throws an exception of there is no AUTOLOAD.
The Help class doesn't have a nosuchmethod method
either, but it does have AUTOLOAD. If Foo or one of
its other parent classes defines an AUTOLOAD, one of those
will be called instead. But if there's no other AUTOLOAD,
then Help's AUTOLOAD will be called as a last
resort.
This pattern match dismantles the contents of $AUTOLOAD into
a class name and a method name:
The AUTOLOAD function is now going to accumulate a table of
all the methods that could have been called on the target
object, print out a report, and throw a fatal exception.
The accumulated table will reside in the private hash
%known_method. Keys in this hash will be method names.
Values will be the classes in which the names were found.
Before the loop actually looks at the methods in the current class
it's searching, it looks to see if the class has any base classes. If
there are any, it pushes them onto the stack to be searched next:
To find out if a name denotes a subroutine, we use
defined(&{subroutine_name}) for each name in the
package symbol table. If there is a subroutine by that name, the program
inserts it and the class name into %known_method. Otherwise,
the name is a variable or filehandle name and is ignored:
If you have any clever techniques for identifying other stuff that
should be omitted from the output, this is where you would put them.
For example, many authors use the convention that functions whose
names have a leading underscore are private to the implementation, and
should not be called by outsiders. We might omit such items from the
output by
adding a line here:
The output for my example would look like this:
You can always force the help message by calling
$object->Help::help. This calls a method named
help, and it starts the inheritance search in the
Help package. Control is transferred to the following
help method:
Calling AUTOLOAD in the normal way, without goto,
would have worked also. I did it this way just to be a fusspot.
It is very common for objects to lack a DESTROY method;
usually nothing additional needs to be done when the object's lifetime
is over. But we do not want the
Help::AUTOLOAD function to be invoked automatically whenever
such an object is destroyed! So Help defines a last-resort
DESTROY method that is called instead; this prevents Perl
from trying the AUTOLOAD search when an object with no
DESTROY method is
destroyed:
Well, this code will not run with "use strict". It does a lot of
stuff on purpose that "strict" was put in specifically to keep you
from doing by accident.
At some point you have to take off the training wheels, kiddies.
Share and enjoy.
[Other articles in category /prog/perl]
permanent link
Major screwups in mathematics
There are many examples of statements that were believed without
proof that turned out to be false, such as any number of decidability
and completeness (non-)theorems. If it turns out that P=NP, this will
be one of those type, but as yet there is no generally accepted proof
to the contrary, so it is not an example. Similarly, if would be
quite surprising to learn that the Goldbach conjecture was false, but
at present mathematicians do not generally believe that it has been
proved to be true, so the Goldbach conjecture is not an example of
this type, and is unlikely ever to be.
There are a lot of results that could have gone one way or another,
such as the three-dimensional kissing number problem. In this case
some people believing they could go one way and some the other, and
then they found that it was one way, but no proof to the contrary was
ever widely accepted.
Then we have results like the independence of the parallel postulate,
where people thought for a long time that it should be implied by the
rest of Euclidean geometry, and tried to prove it, but couldn't, and
eventually it was determined to be independent. But again, there was
no generally accepted proof that it was implied by the other
postulates. So mathematics got the right answer in this case: the
mathematicians tried to prove a false statement, and failed, and then
eventually figured it out.
Alfred Kempe is famous for producing an erroneous proof of the
four-color map theorem, which was accepted for eleven years before the
error was detected. But the four-color map theorem is true. I
want an example of a false statement that was believed for
years because of an erroneous proof.
If there isn't one, that is an astonishing declaration of success for
all of mathematics and for its deductive methods. 2300 years without
one major screwup!
It seems too good to be true. Is it?
(Readers of Planet Haskell
may want to avert their eyes from this compendium of Perl
introspection techniques. Moreover, a very naughty four-letter word
appears, a word that begins with "g" and ends with "o". Let's just
leave it at that.)
use YAML;
my $obj = YAML->new;
$obj->nosuchmethod;
When run, this produces the fatal error:
Can't locate object method "nosuchmethod" via package "YAML" at test.pl line 4.
(YAML in this article is just an example; you don't have to
know what it does. In fact, I don't know what it does.)
use YAML;
use Help 'YAML';
my $obj = YAML->new;
$obj->nosuchmethod;
Now any failed method calls to YAML objects, or objects of
YAML's subclasses, will produce a more detailed error
message:
Unknown method 'nosuchmethod' called on object of class YAML
Perhaps try:
Bless
Blessed
Dump
DumpFile
Load
LoadFile
VALUE
XXX
as_heavy (inherited from Exporter)
die (inherited from YAML::Base)
dumper_class
dumper_object
export (inherited from Exporter)
export_fail (inherited from Exporter)
export_ok_tags (inherited from Exporter)
export_tags (inherited from Exporter)
export_to_level (inherited from Exporter)
field
freeze
global_object
import (inherited from Exporter)
init_action_object
loader_class
loader_object
new (inherited from YAML::Base)
node_info (inherited from YAML::Base)
require_version (inherited from Exporter)
thaw
warn (inherited from YAML::Base)
ynode
Aborting at test.pl line 5
Some of the methods in this list are bogus. For example, the stuff
inherited from Exporter should almost certainly not be
called on a YAML object.
package Help;
use Carp 'croak';
sub import {
my ($selfclass, @classes) = @_;
for my $class (@classes) {
push @{"$class\::ISA"}, $selfclass;
}
}
sub AUTOLOAD {
my ($bottom_class, $method) = $AUTOLOAD =~ /(.*)::(.*)/;
my %known_method;
my @classes = ($bottom_class);
while (@classes) {
my $class = shift @classes;
next if $class eq __PACKAGE__;
unshift @classes, @{"$class\::ISA"};
for my $name (keys %{"$class\::"}) {
next unless defined &{"$class\::$name"};
$known_method{$name} ||= $class;
}
}
warn "Unknown method '$method' called on object of class $bottom_class\n";
warn "Perhaps try:\n";
for my $name (sort keys %known_method) {
warn " $name " .
($known_method{$name} eq $bottom_class
? ""
: "(inherited from $known_method{$name})") .
"\n";
}
croak "Aborting";
}
sub help {
$AUTOLOAD = ref($_[0]) . '::(none)';
goto &AUTOLOAD;
}
sub DESTROY {}
1;
use Help 'Foo'
When any part of the program invokes use Help 'Foo', this
does two things. First, it locates Help.pm, loads it in, and
compiles it, if that has not been done already. And then it
immediately calls Help->import('Foo').
sub import {
my ($selfclass, @classes) = @_;
for my $class (@classes) {
push @{"$class\::ISA"}, $selfclass;
}
}
The $selfclass variable becomes Help and @classes
becomes ('Foo'). Then the module does its first tricky
thing. It puts itself into the @ISA list of another class.
The push line adds Help to @Foo::ISA.AUTOLOAD
So what happens when the program calls $foo->nosuchmethod?
If one of Foo's base classes includes a method with that
name, it will be called as usual. $AUTOLOAD
When Perl calls an AUTOLOAD function, it sets the value of
$AUTOLOAD to include the full name of the method it was
trying to call, the one that didn't exist. In our example,
$AUTOLOAD is set to "Foo::nosuchmethod".
sub AUTOLOAD {
my ($bottom_class, $method) = $AUTOLOAD =~ /(.*)::(.*)/;
The $bottom_class variable contains Foo, and the
$method variable contains nosuchmethod.Accumulating the table of method names
The AUTOLOAD function accumulates this hash by doing a
depth-first search on the @ISA tree, just like Perl's method
resolution does internally. The @classes variable is a stack
of classes that need to be searched for methods but that have not yet
been searched. Initially, it includes only the class on which the
method was actually called, Foo in this case:
my @classes = ($bottom_class);
As long as some class remains unsearched, this loop will continue to
look for more methods. It begins by grabbing the next class off the
stack:
while (@classes) {
my $class = shift @classes;
Foo inherits from Help too, but we don't want our
error message to mention that, so the search skips Help:
next if $class eq __PACKAGE__;
(__PACKAGE__ expands at compile time to the name of the
current package.)
unshift @classes, @{"$class\::ISA"};
Now the real meat of the loop: there is a class name in
$class, say Foo,
and we want the program to find all the methods in that class. Perl
makes the symbol table for the Foo package available in the
hash %Foo::. Keys in this hash are variable, subroutine, and
filehandle names.
for my $name (keys %{"$class\::"}) {
next unless defined &{"$class\::$name"};
$known_method{$name} ||= $class;
}
}
The ||= sets a new value for $name in the hash only
if there was not one already. If a method name appears in more than
one class, it is recorded as being in the first one found in the
search. Since the search is proceeding in the same order that Perl
uses, the one recorded is the one that Perl will actually find. For
example, if Foo inherits from Bar, and both classes
define a this method, the search will find Foo::this
before Bar::this, and that is what will be recorded in the
hash. This is correct, because Foo's this method
overrides Bar's.
next if $name =~ /^_/;
After the loop finishes searching all the base classes, the
%known_method hash looks something like this:
(
this => Foo,
that => Foo,
new => Base,
blookus => Mixin::Blookus,
other => Foo
)
This means that methods this, that, and
other were defined in Foo itself, but that
new is inherited from Base and that blookus
was inherited from Mixin::Blookus.Printing the report
The AUTOLOAD function then prints out some error messages:
warn "Unknown method '$method' called on object of class $bottom_class\n";
warn "Perhaps try:\n";
And at last the payoff: It prints out the list of methods that the
programmer could have called:
for my $name (sort keys %known_method) {
warn " $name " .
($known_method{$name} eq $bottom_class
? ""
: "(inherited from $known_method{$name})") .
"\n";
}
croak "Aborting";
}
Each method name is printed. If the class in which the method was
found is not the bottom class, the name is annotated with the message
(inherited from wherever).
Unknown method 'nosuchmethod' called on object of class Foo:
Perhaps try:
blookus (inherited from Mixin::Blookus)
new (inherited from Base)
other
that
this
Aborting at YourErroneousModule.pm line 679
Finally the function throws a fatal exception. If we had used
die here, the fatal error message would look like
Aborting at Help.pm line 34, which is extremely unhelpful.
Using croak instead of die makes the message look
like Aborting at test.pl line 5 instead. That is, it reports
the error as coming from the place where the erroneous method was
actually called.Synthetic calls
 Suppose you want to force the help message to come out. One way is to
call $object->fgsfds, since probably the object does not
provide a fgsfds method. But this is ugly, and it might not
work, because the object might provide a fgsfds
method. So Help.pm provides another way.
Suppose you want to force the help message to come out. One way is to
call $object->fgsfds, since probably the object does not
provide a fgsfds method. But this is ugly, and it might not
work, because the object might provide a fgsfds
method. So Help.pm provides another way.
sub help {
$AUTOLOAD = ref($_[0]) . '::(none)';
goto &AUTOLOAD;
}
The Help::help method sets up a fake $AUTOLOAD
value and then uses "magic goto" to transfer control to the real
AUTOLOAD function. "Magic goto" is not the evil bad goto
that is Considered Harmful. It is more like a function call. But
unlike a regular function call, it erases the calling function
(help) from the control stack, so that to subsequently
executed code it appears that AUTOLOAD was called directly in
the first place.DESTROY
Whenever a Perl object is destroyed, its DESTROY method is
called, if it has one. If not, method search looks for an
AUTOLOAD method, if there is one, as usual. If this lookup
fails, no fatal exception is thrown; the object is sliently destroyed
and execution continues.
sub DESTROY {}
This DESTROY method restores the default
behavior, which is to do nothing.Living dangerously
Perl has a special package, called UNIVERSAL.
Every class
inherits from UNIVERSAL. If you want to apply Help
to every class at once, you can try:
use Help 'UNIVERSAL';
but don't blame me if something weird happens.About use strict
Whenever I present code like this, I always get questions (or are they
complaints?) from readers about why I omitted "use strict". "Always
use strict!" they say.License
Code in this article is hereby placed in the public domain.
I don't remember how I got thinking about this, but for the past week
or so I've been trying to think of a major screwup in mathematics.
Specifically, I want a statement S such that:
I cannot think of an example.Glossary for non-mathematicians
[ Addendum 20080205: Readers suggested some examples, and I happened
upon one myself. For a summary, see this month's addenda. I also
wrote a detailed article
about a mistake of Kurt Gödel's. ]
[ Addendum 20080206: Another article in this series, asking readers for examples of a different type of screwup. ]
[Other articles in category /math] permanent link
Tue, 08 Jan 2008
Clubbing someone to death with a loaded Uzi
I once had an intern who wrote wrote the following code to process a
web survey form. The form input widgets were named q1,
q2, and so forth:
foreach $k (keys %in) {
if ($k eq q1) {
if ($in{$k} eq agree) {
$count{q10} = $count{q10} + 1;
}
if ($in{$k} eq disaagree) {
$count{q11} = $count{q11} + 1;
}
}
if ($k eq q2) {
@q2split = split(/\0/, $in{$k});
foreach (@q2split) {
$count{$_} = $count{$_} + 1;
}
}
if ($k eq q3) {
$count{$in{$k}} = $count{$in{$k}} + 1;
}
...
}
There is a lot wrong with this code, but it's all trivial compared
with the one big problem, which is the wholly unnecessary loop and
tests. The whole thing could be (and should be, and was) rewritten
as:
if ($in{q1} eq agree) {
$count{q10} = $count{q10} + 1;
}
if ($in{q1} eq disaagree) {
$count{q11} = $count{q11} + 1;
}
@q2split = split(/\0/, $in{q2});
foreach (@q2split) {
$count{$_} = $count{$_} + 1;
}
$count{$in{q3}} = $count{$in{q3}} + 1;
...
After which one could start addressing the smaller problems, like the
fact that "disagree" is misspelled.This is the sort of mistake you expect from an intern. I chuckled and corrected him. But I've seen it several times since from non-interns.
Here's another example. I am not making this up. Whether it's more or less odious than the intern code is up to you to decide:
foreach $location_name (%LOCATION ) {
$location_code = $LOCATION{$location_name};
if ($location_name eq $location ) {
printf FILE "$location_code\,";
printf FILE "%4s", "$min3\,";
printf FILE "%4s", "$max3\,";
printf FILE "%1s", "$wx3\n";
}
}
It could have been written like this:
printf FILE "$LOCATION{$location}\,";
printf FILE "%4s", "$min3\,";
printf FILE "%4s", "$max3\,";
printf FILE "%1s", "$wx3\n";
I started using this problem as an interview question. I'll present
the subject with trivial code like this:
for my $k (keys %hash) {
if ($k eq "name") {
$hash{$k}++;
}
}
and then ask if they have any comments about it. One nice thing about
the question is that it translates naturally into whatever imperative
language they claim expertise in.It's appalling how many supposedly professional programmers see nothing wrong here. They squint at the code, and say "I think you need parentheses around %hash there", or they criticize the choice of variable names.
I first used this as an interview question because the Python code sample submitted by a job applicant contained an example of it. "Weird," I thought, "but maybe she's outgrown that." Since she claimed to be an expert Perl user, I asked her about it in Perl, using code like the example above. After she made a syntactic suggestion, I said "It's not a syntax problem, and it's not a trick question." She criticized the syntax some more. Finally I told her the answer: "Couldn't you just use $hash{name}++?"
"Oh, yeah, I guess so," she said.
A few minutes later we were going over her Python code sample and I pointed out the place where she had done the exact same thing, and asked if she was happy with that loop and wanted to change it. No, she thought it was just fine.
"Doesn't this look like the example I showed you on the whiteboard a little while ago?"
"Oh, I guess it does."
We didn't hire her.
Larry Wall once said that iterating over the keys of a hash is like clubbing someone to death with a loaded Uzi.
I had already realized that you could, in principle, commit this error with a regular array instead of with a hash, but I had never seen an example until today's episode of the Daily WTF. The Daily WTF code is so awful, all the way through, that I was afraid that people might miss this slightly-more subtle gem lurking in the middle, and that was what motivated me to write this article in the first place. Here's the gem:
// Java
for (int a=1;a<=params.size();a++) switch (a)
{
case 1 : if (params.get(0) != null)
this.one=params.get(0).toString();
break;
case 2 : if (params.get(1) != null)
this.two=params.get(1).toString();
break;
...
case 14 : if (params.get(13) != null)
this.fourteen=params.get(13).toString();
break;
}
}
Wow, that is just, uh, stunning.[ Addendum 20080201: A bit more. ]
[ Addendum 20090213: A counterexample. ]
[Other articles in category /prog] permanent link
Sun, 06 Jan 2008
Squillions
A while back I looked up "zillion" in Wikipedia, which is an alias for
the
Wikipedia article about "Indefinite and fictitious numbers". The
article includes a large number of synonyms for "zillion", such as
bajillion, kajillion, gazillion, and so forth. For some reason the
word "squillion" caught my eye, and I noticed that the citation was
from Terry Pratchett: "And you owe me a million billion trillion
zillion squillion dollars." This suggested to me that "squillion"
might be a nonce-word, one made up on the spot by Pratchett for that
one sentence, in which case it should not be in the Wikipedia
article.
Google book search is a good way to answer questions like that, because if "squillion" is widely used, you will find a lot of examples of it. And indeed it is widely used, and I did find a lot of examples of it. So there was no need to remove it from the article.
One of the Google hits was from the Cormac Ó Cuilleanáin translation of Giovanni Boccaccio's Decameron. The Decameron is a great classic of Italian Renaissance literature, probably the greatest classic that Italian has, after Dante's Divine Comedy. It was written around 1350. In this particular chapter (the tenth story on the sixth day, if you want to look it up) Guccio, a priest, is trying to seduce a hideous kitchen-maid:
He sat himself down by the fire—although this was August—and struck up a conversation with the wench in question (Nuta by name), informing her that he was by rights a member of the gentry and had more than a squillion florins in the bank, not counting those he had to give to other people...
The kitchen-maid, by the way, is described as having "a pair of tits like two baskets of manure".
This was amusing, and as I had never read the Decameron, I wanted to read more, and learn how it turned out. But the Google excerpt was limited, so I asked the library to get me a copy of that version of the Decameron. Of course they have many copies on the shelf, but not that particular translation. So I asked the interlibrary loan people for it, and they got it for me.
When it arrived, I was rather dismayed. The ILL people get the book from the most convenient place, and that means that it often comes from the Drexel library, up the street, or the Temple library, across town, or the West Chester Community College library, or Lehigh University, about an hour away in Bethlehem. (Steel Bethlehem, of course, not Jesus Bethlehem.) The farthest I had ever gotten a book from was an extremely obscure quilting manual that Lorrie asked for; it eventually arrived from the Sno-Isles regional library system of Marysville, Washington.
But this copy of the Decameron came from the Sloman library of the University of Essex. I was so shocked that I had to look it up online to make sure that it was not Essex, New Jersey, or something like that. I was not. It was East Saxony. I was upset because I felt that the trouble and effort had been wasted. If I had known that the nearest available copy of Cormac Ó Cuilleanáin's translation was in Essex, I would have been happy to take a different version that was on the shelf. And then to top it off, I had hardly begun to read it before it came due and had to be sent back to Essex.
So I went to the library and got another Decameron, this one translated by Mark Musa and Peter Bondanella. Here is the corresponding passage:
Although it was still August, he took a seat near the fire and began to talk with the girl, whose name was Nuta, telling her that he was a gentleman by procuration, that he had more than a thousand hundreds of florins (not counting those he had to give away to others), ...
And there is a footnote on "thousand hundreds" explaining "Guccio invents this amount, as well as the previous phrase 'by procuration,' in order to impress his lady." By the way, in this version, Nuta has "a pair of tits that looked like two clumps of cowshit".
Anyway, I think I liked "squillions" better than "thousand hundreds", although I suppose "thousand hundreds" is probably a more literal translation.
Well, I can find this out. Of course, one can find the Decameron online in Italian; the copyright expired about five hundred years ago. Here it is in Italian, courtesy of Brown University:
E ancora che d'agosto fosse, postosi presso al fuoco a sedere, cominciò con costei, che Nuta aveva nome, a entrare in parole e dirle che egli era gentile uomo per procuratore e che egli aveva de' fiorini piú di millantanove, senza quegli che egli aveva a dare altrui,...I think the word that is being translated here is "millantanove", although I can't be entirely sure, because I don't know Italian. Once again, though, I am surprised at how easy it is to read a passage in an unintelligible foreign language when I already know what it is going to say. (I wrote about this back in April 2006, and it occurs to me now that that would be a fun topic for an article.)
 The 1903 translation that Brown University provides is "more florins than could be
reckoned", which does not seem to me to capture the flavor of the
original, and does not seem to be a literal translation either.
"Millantanove" seems to me to be a made-up word resembling "mille" =
"thousand". But as I said, I don't know Italian.
The 1903 translation that Brown University provides is "more florins than could be
reckoned", which does not seem to me to capture the flavor of the
original, and does not seem to be a literal translation either.
"Millantanove" seems to me to be a made-up word resembling "mille" =
"thousand". But as I said, I don't know Italian.
Nuta in this version has "a pair of breasts that shewed as two buckets of muck". Feh. The Italian is "con un paio di poppe che parean due ceston da letame". The operative phrase here seems to be "ceston da letame". I don't know what those words mean, but, happily, Italian Wikipedia has an article about letame, and as the picture makes clear, it is indeed manure.
Oh, did you want this article to have a point? Too bad.
I recommend the Decameron. It is funny and salacious. There are a lot of stories about women cheating on their husbands, and then getting away with it through some clever trick, and then everyone who hears the story laughs and admires the cleverness of the ladies. (The counterpoint to this is that there are a number of stories of wife-beating, in which everyone who hears the story laughs and admires the wisdom of the husbands. I don't like that so much.)
There are farcical stories of bed-swapping and wife-swapping, and one story about an abbess who comes out of her cell to berate a nun for having her lover in to visit, but the abbess is wearing a pair of men's trousers on her head instead of her wimple. Oops.
This reminds me of when I was in high school, I was talking to one of my friends, who opted to study French, and this friend told me studying French is fun, because when you get to the third year and start reading real French literature, you read that great classic of French Literature, La Vie de Gargantua et de Pantagruel. If you have not read this master treasure of French culture, I should explain that the first chapter is mainly taken up with Gargantua and Pantagruel having a discussion about what is the best sort of thing to wipe your ass with, and it goes on from there.
I took Latin, and in third-year Latin we read the orations of Cicero against Cataline. Fun stuff, but not the sort of thing that has you rushing to translate the next word.
 I was going to write an article about symmetries of the dodecahedron,
and an interesting problem suggested to me by these balloon displays
that I saw at the local Mazda dealership, but eh, this was a lot
easier.
I was going to write an article about symmetries of the dodecahedron,
and an interesting problem suggested to me by these balloon displays
that I saw at the local Mazda dealership, but eh, this was a lot
easier.
Gargantua and Pantagruel eventually agree that the answer is a live goose.
[ Addendum 20080201: More about 'milliantanove'. ]
[Other articles in category /lang] permanent link
Sat, 05 Jan 2008
Pepys' footballs explained
Walt Mankowski wrote to me with the explanation of Samuel Pepys' footballs: They
are not clods of mud, as I guessed, nor horse droppings, as another
correspondent suggested, but... footballs.
Walt found a reference in Montague Shearman's 1887 book on the history of football in England that specifically mentions this. Folks were playing football in the street, and because of this, Pepys took his coach to Sir Philip Warwicke's, rather than walking.
I didn't ask, but I presume Walt found this by doing some straightforward Google search for "pepys footballs" or something of the sort. For some reason, this did not even occur to me. Once Big Dictionary failed me, I was stumped. Perhaps this marks me as a member of the pre-Internet generation. I imagined this morning that this episode would be repeated, with my daughter Katara in place of Walt. "Oh, Daddy! You're so old-fashioned. Just use a Google search."
Anyway, inspired by Walt's example, or by what I imagined Walt's example to be, I did the search myself, and found the Shearman reference, as well as the following discussion in William Carew Hazlitt's Faiths and Folklore of 1905:
Mission, writing about 1690, says: "In winter foot-ball is a useful and charming exercise. It is a leather ball about as big as one's head, fill'd with wind. This is kick'd about from one to t'other in the streets, by him that can get at it, and that is all the art of it."This book looks like it would be good reading in general. [ Addendum 20080106: This is not the William Hazlitt, but his grandson. Thank you, Wikipedia. ]
Thanks very much, Walt.
[Other articles in category /lang] permanent link
Fri, 04 Jan 2008
Footballs?
The diary of Samuel Pepys for Tuesday, 3 January 1664/5 says:
Up, and by coach to Sir Ph. Warwicke's, the streete being full of footballs, it being a great frost, and found him and Mr. Coventry walking in St. James's Parke."The street being full of footballs?" Huh? I tried looking in the Big Dictionary, and it was no help at all.
My best guess is that it's big chunks of frozen mud that you have to kick out of the way. Do any gentle readers know for sure?
The Diary of Samuel Pepys has a syndication feed you can subscribe to. You get a diary entry every day or so, with all the names and places linked to a glossary. It's fun reading.
[ Addendum 20080105: The answer. ]
[Other articles in category /lang] permanent link
Katara is not a vegetarian
I just had a long vacation and got to spend a lot of time with Katara,
which is why she's popping up so much all of a sudden. I seem to have
gotten into Mimi Smartypants mode. I will return to the
regularly-scheduled discussions of programming and mathematics
shortly. But since I seem to have written two articles in a row
([1] [2])
on the subject of telling kids the difficult truth, I thought I'd try to
finish up this one, which has been mostly done for months now. Also
there was a recent episode that got me thinking about it again.
I went to visit Katara at school last week, and stayed for lunch. I was seated with Katara and three other little girls. As the food was served, one of the girls, Riley, made some joke about how the food cart contained guinea pigs instead. This sort of joke is very funny to preschoolers.
My sense of humor is very close to a preschooler's, and I would have thought that this was funny if she had said that the food cart contained clocks, or nose hairs, or a speech in defense of the Corn Laws, or the Trans-Siberian Railroad, or fish-shaped solid waste. But she said guinea pigs, and instead of laughing, I mused aloud that I had never eaten a guinea pig.
Riley informed me that "You can't eat guinea pigs! They're animals, not food."
"Sure you can," I said. "Meat is made from animals."
Riley got this big grin on her face, the one that preschoolers get when they know that the adults are teasing them, and said "Nawww!"
"Yes," I said. "Meat comes from animals."
Riley shook her head. She knew I was joking. A general discussion ensued, with Katara taking my side, and another girl, Flora, taking Riley's. In the end, I did not convince them.
"Well," I said, mostly to myself, at the end, "you girls are in for a rude awakening someday."
Now, I know that not everyone is as direct as I am. And I know that not all non-vegetarians are as concerned as I am about the ethics of eating meat. But wow. I would have thought that someone would have explained to these girls where meat came from, just as a point of interest if nothing else. Or maybe they would have made the connection between chicken-the-food and chicken-the-farm-animal. I mean, they are constantly getting all these stories set on farms. Since three-year-olds ask about a billion questions a day. they must ask around a thousand questions a day about the farms, so how is it that the subject never came up?
Katara was accidentally exposed to a movie version of Charlotte's Web on an airplane, and the plot of Charlotte's Web is that Charlotte is trying to save Wilbur from being turned into smoked ham. Left to myself I wouldn't have exposed Katara to Charlotte's Web so soon—it is too long for her, for one thing—but my point here is that the world is full of reminders of the true nature of meat, and they can be hard to avoid. So I was very surprised when it turned out that these two age-mates of Katara's were so completely unaware of it.
Anyway, Katara has known from a very early age where meat comes from. Early in her meat-eating career, probably before she was two years old, I specifically explained it to her. I wanted to make sure that she understood that meat comes from animals. Because there are serious ethical issues involved when one eats animals, and I think they must be considered. We may choose to kill and destroy thinking beings to make food, but we should at least be aware that that is what is happening. I'm not sure I think it is evil, but I want to at least be aware of the possibility.
I have never been a vegetarian, but I want to try to face the ethical results of that choice head on, and not pretend that they are not there. I did not want Katara growing up to identify meat with sterile packages in the supermarket. Meat was once alive, moving around with its own agenda, and I think it is important to understand this.
So I made an effort to bring up the subject at home, and then one day when Katara was around twenty months old we went to a Chinese restaurant that has live fish in tanks at the front of the restaurant, and you can ask them to take one of these fish into the kitchen to be cooked for your dinner. Katara has loved to eat fish since she was a tiny baby.
We ordered a striped bass, and then I took Katara to look at the fish in the tanks. I explained to her that these fish swimming in the tanks were for people to eat, and that when we ordered our fish for dinner, a waiter came out and caught one of the fish in a net, took it back to the kitchen, and they killed it and were cooking it for us.
As I said, I had made the point before, but never so directly. We had never before seen the live animals that were turned into food for us. I really did not know how Katara would respond to this. Some people have a very strong negative response when they first learn that meat comes from animals, so negative that they never eat meat again. But I thought Katara should know the truth and make her own decision about how to respond.
Katara's response was to point at one of the striped bass and say "I want to eat that one."
Then she took me to each tank in turn, and told me me which kind of fish she wanted to eat and which ones she did not want to eat. (She favored the fish-looking fish, and rejected the crabs, shrimp, and eels.)
Then when the fish arrived on our table Katara asked if it had been swimming in the tank, and I said it had. "Yum yum," said Katara, and dug in.
Addendum 20250621
I wrote a followup to this, never published, in which I mentioned that the working title for the article was “Katara is not _yet_ a vegetarian”:But the matter is not yet settled. Katara has many opportunities before her to change her mind, perhaps several times. I changed the article title several times before releasing it. The alternate title was "Katara is not yet a vegetarian". The story is not over. And I think Katara should get lots of practice thinking about everything as early as possible, so that she stays in the habit of doing that as she gets older.I am proud to announce that Katara is, 17 years later, not merely a vegetarian but a vegan.
[Other articles in category /food] permanent link
Thu, 03 Jan 2008
Note on point-free programming style
This old
comp.lang.functional article by Albert Y. C. Lai, makes
the point that Unix shell pipeline programming is done in an
essentially "point-free" style, using the shell example:
grep '^X-Spam-Level' | sort | uniq | wc -l
and the analogous Haskell code:
length . nub . sort . filter (isPrefixOf "X-Spam-Level")
Neither one explicitly mentions its argument, which is why this is
"point-free". In "point-free" programming, instead of defining a
function in terms of its effect on its arguments, one defines it by
composing the component functions themselves, directly, with
higher-order operators. For example, instead of:
foo x y = 2 * x + yone has, in point-free style:
foo = (+) . (2 *)where (2 *) is the function that doubles its argument, and (+) is the (curried) addition function. The two definitions of foo are entirely equivalent.
As the two examples should make clear, point-free style is sometimes natural, and sometimes not, and the example chosen by M. Lai was carefully selected to bias the argument in favor of point-free style.
Often, after writing a function in pointful style, I get the computer to convert it automatically to point-free style, just to see what it looks like. This is usually educational, and sometimes I use the computed point-free definition instead. As I get better at understanding point-free programming style in Haskell, I am more and more likely to write certain functions point-free in the first place. For example, I recently wrote:
soln = int 1 (srt (add one (neg (sqr soln))))
and then scratched my head, erased it, and replaced it with the equivalent:
soln = int 1 ((srt . (add one) . neg . sqr) soln)
I could have factored out the int 1 too:
soln = (int 1 . srt . add one . neg . sqr) soln
I could even have removed soln from the right-hand side:
soln = fix (int 1 . srt . add one . neg . sqr)
but I am not yet a perfect sage.Sometimes I opt for an intermediate form, one in which some of the arguments are explicit and some are implicit. For example, as an exercise I wrote a function numOccurrences which takes a value and a list and counts the number of times the value occurs in the list. A straightforward and conventional implementation is:
numOccurrences x [] = 0
numOccurrences x (y:ys) =
if (x == y) then 1 + rest
else rest
where rest = numOccurrences x ys
but the partially point-free version I wrote was much better:
numOccurrences x = length . filter (== x)
Once you see this, it's easy to go back to a fully pointful
version:
numOccurrences x y = length (filter (== x) y)
Or you can go the other way, to a point-free version:
numOccurrences = (length .) . filter . (==)
which I find confusing.Anyway, the point of this note is not to argue that the point-free style is better or worse than the pointful style. Sometimes I use the one, and sometimes the other. I just want to point out that the argument made by M. Lai is deceptive, because of the choice of examples. As an equally biased counterexample, consider:
bar x = x*x + 2*x + 1
which the automatic converter informs me can be written in point-free
style as:
bar = (1 +) . ap ((+) . join (*)) (2 *)
Perusal of this example will reveal much to the attentive reader,
including the definitions of join and ap. But I
don't think many people would argue that it is an improvement on the
original. (Maybe I'm wrong, and people would argue that it was an
improvement. I won't know for sure until I have more experience.)For some sort of balance, here is another example where I think the point-free version is at least as good as the pointful version: a recent comment on Reddit suggested a >>> operator that composes functions just like the . operator, but in the other order, so that:
f >>> g = g . f
or, if you prefer:
(>>>) f g x = g(f(x))
The point-free definition of >>> is:
(>>>) = flip (.)
where the flip operator takes a function of two arguments and
makes a new function that does the same thing, but with the arguments
in the opposite order. Whatever your feelings about point-free style,
it is undeniable that the point-free definition makes perfectly clear
that >>> is nothing but . with its arguments in
reverse order.
[Other articles in category /prog/haskell] permanent link
Tue, 01 Jan 2008
Santa Claus
A few years ago I was talking to a woman I worked with, who told me
that she told her kids that Santa Claus was real, "because how could
you not?". She thought she would have been depriving her kids by not
telling them the story. And maybe she would have been; I honestly
don't know. I don't remember what it was like to believe literally in
Santa Claus or how I felt when I learned the truth.
My vocabulary here is failing me. "Telling them the story" is not what I want, because the Santa Claus thing is deceptive, and telling stories is not normally deceptive: "fiction" and "lies" mean different things. When I tell Katara the story of the Little Red Hen, there is no presumption that there is an actual, literal Red Hen. Katara might think there is, or not, or might not think about it at all; I don't know which. Ditto Cinderella, or Olivia the Pig, or any other story I tell or read to her. But when people tell their kids about Santa Claus, they present it not as a story, but as a literal truth. They present it in a way that is calculated to make the kids believe there is actually a fat, benevolent, white-bearded immortal, manufacturing toys in a secret arctic workshop. This is no longer mere fiction; it is a lie. So what I want to say is that this lady thought she would be depriving her kids of the magic of Santa Claus by not telling them this lie.
But I really don't want to use the word "lie" here, because it's so pejorative. It makes it sound as though I think badly of this good woman for telling her kids that Santa Claus was real. But I don't, at all. She is generally wise and honest and I respect her. Parents tell their kids all sorts of awful, appalling lies, which upsets me a lot, but this lie is quite benign by comparison, and bothers me not at all.
Let me be perfectly clear: I have nothing, absolutely nothing, against the Santa Claus story. I have an article in progress about how much I hate the way parents routinely lie to their kids, to manipulate them, and this one isn't in the article, because it doesn't even register. It's just for fun, or nearly so.
Santa Claus seems pretty harmless to me. Unlike many of the pernicious lies children are told, Santa Claus is a great story. It would be really wonderful to believe that I would get presents every year because there was a fat guy manufacturing toys at the North Pole. Delightful! And the only thing wrong with it is that it isn't true. Oh well. There are a lot of pretty stories that aren't true.
Anyway, at the time I had this conversation about Santa Claus, Katara was too young to have heard about Santa Claus anyway, and my co-worker asked if I was planning to tell Katara the Santa Claus story.
Now that I've written this article, it occurs to me what she meant to ask, was not whether I was going to tell Katara the story, but whether I was going to tell her that it was true. Having realized that now, my reply seems a lot more obvious in retrospect than it did at the time.
I hadn't thought about it before, but I said I didn't think I would.
"But what are you going to tell her?"
"The truth, I guess."
The truth, though, is pretty wonderful, although less astonishing. You don't get presents because of the fat guy in the red suit, which is a shame, because wouldn't it be fun if it were true? But you do get them anyway, and it's because your family loves you. As consolation prizes go, that one's pretty good.
So we did tell her the truth. Santa Claus is just a story. Katara will have to grow up without that piece of childhood delight. Sorry, Katara. But she'll also grow up knowing that her parents respect her enough to tell her the truth instead of a pretty lie, and maybe that will be enough of a consolation prize to make up for it.
[Other articles in category /kids] permanent link