Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 250 |
| Programming | 102 |
| Language | 97 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Thu, 29 Jan 2009
A simple trigonometric identity
A few nights ago I was writing up notes for my
category theory reading group, and I wanted to include a commutative
diagram on three objects. I was using Paul Taylor's stupendously good
diagrams.sty
package, which lets you put the vertices of the diagram in the cells
of a LaTeX table, and then draw arrows between them. I had drawn the
following diagram:
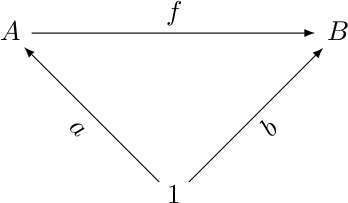
So that night as I was waiting to fall asleep, I thought about the problem of finding lattice points that are at the vertices of an equilateral triangle. This is a sort of two-dimensional variation on the problem of finding rational approximations to surds, which is a topic that has turned up here many times over the years.
Or rather, I wanted to find lattice points that are almost at the vertices of an equilateral triangle, because I was pretty sure that there were no equilateral lattice triangles. But at the time I could not remember a proof. I started doing some calculations based on the law of cosines, which was a mistake, because nobody but John Von Neumann can do calculations like that in their head as they wait to fall asleep, and I am not John Von Neumann, in case you hadn't noticed.
A simple proof that there are no equilateral lattice triangles has just now occurred to me, though, and I am really pleased with it, so we are about to have a digression.
The area A of an equilateral triangle is s√3/2, where s is the length of the side. And s has the form √t because of the Pythagorean theorem, so A = √(3t)/2, where t is a sum of two squares, because the endpoints of the side are lattice points.
By Pick's theorem, the area of any lattice triangle is a half-integer. So 3t is a perfect square, and thus there are an odd number of threes in t's prime factorization.
But t is a sum of two squares, and by the sum of two squares theorem, its prime factorization must have an even number of threes. We now have a contradiction, so there was no such triangle.
Wasn't that excellent? That is just the sort of thing that I could have thought up while waiting to fall asleep, so it proves even more conclusively that starting with the law of cosines was a mistake.
Okay, end of digression. Back to the law of cosines. We have a triangle with sides a, b, and c, and opposite angles A, B, and C, and you no doubt recall from high school that c2 = a2 + b2 - 2ab cos C. We'll call this "law C".
Before I fell alseep, it occurred to me that you could take the analogous law B, which is b2 = a2 + c2 - 2ac cos B, and substitute the right-hand side for the b2 term in law C. Then a bunch of stuff will cancel out and you should either get something interesting or something tautological. Von Neumann would have known right away which it was, but I needed paper.
So today I got out the paper and did the thing, and came up with the very simple relation that:
c = a cos B + b cos AWhich holds in any triangle. But somehow I had never seen this before, or, if I had, I had completely forgotten it.
The thing is so simple that I thought that it must be wrong, or I would have known it already. But no, it checked out for the easy cases (right triangles, equilateral triangles, trivial triangles) and the geometric proof is easy: Just drop a perpendicular from C. The foot of the perpendicular divides the base c into two segments, which, by the simplest possible trigonometry, have lengths a cos B and b cos A, respectively. QED.
Perhaps that was anticlimactic. Have I mentioned that I have a sign on the door of my office that says "Penn Institute of Lower Mathematics"? This is the kind of thing I'm talking about.
I will let you all know if I come up with anything about the almost-equilateral lattice triangles. Clearly, you can approximate the equilateral triangle as closely as you like by making the lattice coordinates sufficiently large, just as you can approximate √3 as closely as you like with rationals by making the numerator and denominator sufficiently large. Proof: Your computer draws equilateral-seeming triangles on the screen all the time.
I note also that it is important that the lattice is two-dimensional. In three or more dimensions the triangle (1,0,0,0...), (0,1,0,0...), (0,0,1,0...) is a perfectly equilateral lattice triangle with side √2.
[ Addendum 20090130: Vilhelm Sjöberg points out that the area of an equilateral triangle is s2√3/4, not s√3/2. Whoops. This spoils my lovely proof, because the theorem now follows immediately from Pick's: s2 is an integer by Pythagoras, so the area is irrational rather than a half-integer as Pick's theorem requires. ]
[ Addendum 20140403: As a practical matter, one can draw a good lattice approximation to an equilateral triangle by choosing a good rational approximation to !!\sqrt3!!, say !!\frac ab!!, and then drawing the points !!(0,0), (b,a),!! and !!(2b, 0)!!. The rational approximations to !!\sqrt3!! quickly produce triangles that are indistinguishable from equilateral. For example, the rational approximation !!\frac74!! gives the isosceles triangle with vertices !!(0,0), (4,7), (8,0)!! which has one side of length 8 and two sides of length !!\sqrt{65}\approx 8.06!!, an error of less than one percent. The next such approximation, !!\frac{26}{15}!!, gives a triangle that is correct to about 1 part in 1800. (For more about rational approximations to !!\sqrt3!!, see my article on Archimedes and the square root of 3.) ]
[ Addendum 20181126: Even better ways to make 60-degree triangles on lattice points. ]
[Other articles in category /math] permanent link
Tue, 27 Jan 2009
Amusements in Hyperspace
[ Michael
Lugo's post on n-spheres today reminded me that I've been
wanting for some time to repost this item that I wrote back in
1999. ]
This evening I tried to imagine life in a 1000-dimensional universe. I didn't get too far, but what I did get seemed pretty interesting.
What's it like? Well, it's very dark. Lamps wouldn't work very well, because if the illumination one foot from the source is I, then the illumination two feet from the source is I · 9.3·10-302.
Actually it's even worse than that; there's a double whammy. Suppose you had a cubical room ten feet across. If you thought it was hard to light up the dark corners of a big room in Boston in February, imagine how much worse it is in hyperspace where the corners are 158 feet away.
There are some upsides, however. Rooms won't have to be ten feet on a side because everything will be smaller. You take up about 70,000 cubic centimeters of space; in hyperspace that is just not a lot of room, because a box barely more than a centimeter on a side takes up 70,000 hypercentimeters. In fact, a box barely more than a centimeter on a side can hold as much as you want; an 11 millimeter box already contains 2.5·1041 hypercentimeters.
It's hard to put people in prison in hyperspace, because there are so many directions that you can go to get out. Flatland prison cells have four walls; ours have six, if you count the ceiling and the floor. Hyperspace prison cells have 2000 walls, and each one is very expensive to build.
So that's hyperspace: Big, dark, and easy to get around.
Addenda
20120510
An anonymous commenter on Colm Mulcahy's blog observed that "high dimension cubes are qualitatively more like hedgehogs than building blocks". And recently someone asked on stackexchange.math for "What are some examples of a mathematical result being counterintuitive?"; the top-scoring reply concerned the bizarre behavior of high-dimension cubes. ]
20200325
More about this on the Matrix67 blog. (In Chinese.)
20240808
Reddit user `ink_atom` has drawn a cartoon on this topic.
[Other articles in category /math] permanent link
Sat, 24 Jan 2009
Higher-Order Perl: nonmemoizing streams
The first version of tail() in the streams chapter looks like this:
sub tail {
my $s = shift;
if (is_promise($s->[1])) {
return $s->[1]->(); # Force promise
} else {
return $s->[1];
}
}
But this is soon replaced with a version that caches the value
returned by the promise:
sub tail {
my $s = shift;
if (is_promise($s->[1])) {
$s->[1] = $s->[1]->(); # Force and save promise
}
return $s->[1];
}
The reason that I give for this in the book is a performance reason.
It's accompanied by an extremely bad explanation. But I couldn't do
any better at the time.There are much stronger reasons for the memoizing version, also much easier to explain.
Why use streams at all instead of the iterators of chapter 4? The most important reason, which I omitted from the book, is that the streams are rewindable. With the chapter 4 iterators, once the data comes out, there is no easy way to get it back in. For example, suppose we want to process the next bit of data from the stream if there is a carrot coming up soon, and a different way if not. Consider:
# Chapter 4 iterators
my $data = $iterator->();
if (carrot_coming_soon($iterator)) {
# X
} else {
# Y
}
sub carrot_coming_soon {
my $it = shift;
my $soon = shift || 3;
while ($soon-- > 0) {
my $next = $it->();
return 1 if is_carrot($next);
}
return; # No carrot
}
Well, this probably doesn't work, because the carrot_coming_soon()
function extracts and discards the upcoming data from the iterator,
including the carrot itself, and now that data is lost.One can build a rewindable iterator:
sub make_rewindable {
my $it = shift;
my @saved; # upcoming values in LIFO order
return sub {
my $action = shift || "next";
if ($action eq "put back") {
push @saved, @_;
} elsif ($action eq "next") {
if (@saved) { return pop @saved; }
else { return $it->(); }
}
};
}
But it's kind of a pain in the butt to use:
sub carrot_coming_soon {
my $it = shift;
my $soon = shift || 3;
my @saved;
my $saw_carrot;
while ($soon-- > 0) {
push @saved, $it->();
$saw_carrot = 1, last if is_carrot($saved[-1]);
}
$it->("put back", @saved);
return $saw_carrot;
}
Because you have to explicitly restore the data you extracted.With the streams, it's all much easier:
sub carrot_coming_soon {
my $s = shift;
my $soon = shift || 3;
while ($seen-- > 0) {
return 1 if is_carrot($s->head);
drop($s);
}
return;
}
The working version of carrot_coming_soon() for streams looks just like
the non-working version for iterators.But this version of carrot_coming_soon() only works for memoizing streams, or for streams whose promise functions are pure. Let's consider a counterexample:
my $bad = filehandle_stream(\*DATA);
sub filehandle_stream {
my $fh = shift;
return node(scalar <$fh>,
promise { filehandle_stream($fh) });
}
__DATA__
fish
dog
carrot
goat rectum
Now consider what happens if I do this:
$carrot_soon = carrot_coming_soon($bad);
print "A carrot appears soon after item ", head($bad), "\n"
if $carrot_soon;
It says "A carrot appears soon after item fish". Fine.
That's because $bad is a node whose head contains
"fish". Now let's see what's after the fish:
print "After ", head($bad), " is ", head(tail($bad)), "\n";
This should print After fish is dog, and for the memoizing
streams I used in the book, it does. But a non-memoizing stream will
print "After fish is goat rectum". Because
tail($bad) invokes the promise function, which, since the
next() was not saved after carrot_coming_soon()
examined it, builds a new node, which reads the next item from the
filehandle, which is "goat rectum".I wish I had explained the rewinding property of the streams in the book. It's one of the most significant omissions I know about. And I wish I'd appreciated sooner that the rewinding property only works if the tail() function autosaves the tail node returned from the promise.
[Other articles in category /prog/perl] permanent link
Thu, 22 Jan 2009
Archimedes and the square root of 3, revisited
Back in 2006 I discussed
Archimedes' calculation of the approximate value of π. In the
calculation, he needed rational approximations to several irrational
quantities, such as √3, and pulled approximations like 265/153
apparently out of thin air.
I pointed out that although the approximations seem to come out of thin air, a little thought reveals where they probably did come from; it's not very hard. Briefly, you tabulate a2 and 3b2, and look for numbers from one column that are close to numbers from the other; see the previous article for details. But Dr. Chuck Lindsey, the author of a superb explanation of Archimedes' methods, and a professor at Florida Gulf Coast University, seemed mystified by the appearance of the fraction 265/153:
Throughout this proof, Archimedes uses several rational approximations to various square roots. Nowhere does he say how he got those approximations—they are simply stated without any explanation—so how he came up with some of these is anybody's guess.I left it there for a few years, but just recently I got puzzled email from a gentleman named Peter Nockolds. M. Nockolds was not puzzled by the 265/153. Rather, he wanted to know why so many noted historians of mathematics should be so puzzled by the 265/153.
This was news to me. I did not know anyone else had been puzzled by the 265/153. I had assumed that nearly everyone else saw it the same way that M. Nockolds and I did. But M. Nockolds provided me with a link to an extensive discussion of the matter, which included quotations from several noted mathematicians and historians of mathematics:
It would seem...that [Archimedes] had some (at present unknown) method of extracting the square root of numbers approximately.
—W.W Rouse Ball, Short Account of The History of Mathematics, 1908
...the calculation [of π] starts from a greater and lesser limit to the value of √3, which Archimedes assumes without remark as known, namely 265/153 < √3 < 1351/780. How did Archimedes arrive at this particular approximation? No puzzle has exercised more fascination upon writers interested in the history of mathematics... The simplest supposition is certainly [the "Babylonian method"; see Kline below]. Another suggestion...is that the successive solutions in integers of the equations x2-3y2=1 and x2-3y2=-2 may have been found...in a similar way to...the Pythagoreans. The rest of the suggestions amount for the most part to the use of the method of continued fractions more or less disguised.Heath said "The simplest supposition is certainly ..." and then followed with the "Babylonian method", which is considerably more complicated than the extremely simple method I suggested in my earlier article. Morris Kline explains the Babylonian method:
—T. Heath, A History of Greek Mathematics, 1921
He also obtained an excellent approximation to √3, namely 1351/780 > √3 > 265/153, but does not explain how he got this result. Among the many conjectures in the historical literature concerning its derivation the following is very plausible. Given a number A, if one writes it as a2 ± b where a2 is the rational square nearest to A, larger or smaller, and b is the remainder, then a ± b/2a > √A > a ± b/(2a±1). Several applications of this procedure do produce Archimedes' result.And finally:
—M. Kline, Mathematical Thought From Ancient To Modern Times, 1972
Archimedes approximated √3 by the slightly smaller value 265/153... How he managed to extract his square roots with such accuracy...is one of the puzzles that this extraordinary man has bequeathed to us.Nockolds asked me "Have you had any feedback from historians of maths who explain why it wasn't so easy to arrive at 265/153 or even 1351/780? Have you any idea why they make such a big deal out of this?"
—P. Beckmann, A History of π, 1977
No, I'm mystified. Even working with craptastic Greek numerals, it would not take Archimedes very long to tabulate kn2 far enough to discover that 3·7802 = 13512 - 1. Or, if you don't like that theory, try this one: He tabulated n2 and 3n2 far enough to discover the following approximations:
| 2 | / | 1 |
| 5 | / | 3 |
| 7 | / | 4 |
| 19 | / | 11 |
| 26 | / | 15 |
| 71 | / | 41 |
| 97 | / | 56 |
I know someone wants to claim that this is nothing more than the Babylonian method. But this is missing an important point. Although this sort of numeric tinkering might well lead you to discover the Babylonian method, especially if you were Archimedes, it is not the Babylonian method, and it can be done in complete ignorance of the Babylonian method. But it yields the required approximations anyway.
So I will echo Nockolds' puzzlement here. There are a lot of things that Archimedes did that were complex and puzzling, but this is not one of them. You do not need sophisticated algebraic technique to find approximations to surds. You only need to do (at most) a few hours of integer calculation. The puzzle is why people like Rouse Ball and Heath think it is puzzling.
There's an explanation I'm groping for but can't quite articulate, but which goes something like this: Perhaps mathematicians of the late Victorian age lent too much weight to theory and analysis, and not enough to heuristic and simple technique. As a lifelong computer programmer, I have a great appreciation for what can be accomplished by just grinding out the numbers. See my anecdote about the square root algorithm used by the ENIAC, for example. I guessed then that perhaps computer science professors know more about mathematics than I expect, but less about computation. I can imagine the same thing of Victorian mathematicians—but not of Archimedes.
One thing you often hear about pre-19th-century mathematicians is that they were great calculators. I wonder if appreciation of simple arithmetic technique might not have been sometimes lost to the mathematicans from the very end of the pre-computation age, say 1880–1940.
Then again, perhaps I'm not giving them enough credit. Maybe there's something going on that I missed. I haven't checked the original sources to see what they actually say, so who knows? Perhaps Heath discusses the technique I suggested, and then rejects it for some fascinating reason that I, not being an expert in Greek mathematics, can't imagine. If I find out anything else, I will report further.
[Other articles in category /math] permanent link
Wed, 21 Jan 2009
The loophole in the U.S. Constitution: recent developments
Some time ago I wrote a couple of articles [1]
[2]
on the famous story that
Kurt Gödel claimed to have found a loophole in the United States
Constitution through which the U.S. could have become a dictatorship. I
proposed a couple of speculations about what Gödel's loophole
might have been, and reported on another one by
Peter Suber.
Recently Jeffrey Kegler wrote to inform me of some startling new developments on this matter. Although it previously appeared that the story was probably true, there was no firsthand evidence that it had actually occurred. The three witnesses would have been Philip Forman (the examining judge), Oskar Morgenstern and Albert Einstein. But, although Morgenstern apparently wrote up an account of the epsiode, it was lost.
Until now, that is. The Institute for Advanced Study (where Gödel, Einstein, and Morgenstern were all employed) posted an account on its web site, and M. Kegler was perceptive enough to realize that this account was probably written by someone who had access to the lost Morgenstern document but did not realize its significance. M. Kegler followed up the lead, and it turned out to be correct.
Kegler's Morgenstern website has a lot of additional detail, including the original document itself.
Now came an exciting development. [Gödel] rather excitedly told me that in looking at the Constitution, to his distress, he had found some inner contradictions, and he could show how in a perfectly legal manner it would be possible for somebody to become a dictator and set up a Fascist regime, never intended by those who drew up the Constitution.But before I let you get too excited about this, a warning: Morgenstern doesn't tell us what Gödel's loophole was! (Kegler's reading is that Morgenstern didn't care.) So although the truth of story has finally been proved beyond doubt, the central mystery remains.
The document is worth reading anyway. It's only three pages long, and it paints a fascinating picture of both Gödel, who is exactly the sort of obsessive geek that you always imagined he was, and of Einstein, who had a cruel streak that he was careful not to show to the public. Kegler's website is also worth reading for its insightful analysis of the lost document and its story.
[Other articles in category /law] permanent link
Tue, 20 Jan 2009
Triples and Closure
Lately I've been reading Lambek and Scott's Introduction to
Higher-Order Categorical Logic, which is too advanced for me.
(Yoneda Lemma on page 10. Whew!) But you can get some value out of
books that are too hard if you pay attention. Last night I learned
that monads are analogous to closure operators.
In topology, we have the idea of a "closure" of a set, which is essentially the union of the set with its boundary. For example, consider an open disk D, say the set of all points less than one mile from my house. The boundary of this set is a circle with radius one mile, centered at my house. The closure of D is the union of D with its boundary, and so is closed disk consisting of all points less than or equal to one mile from my house.
Representing the closure of a set S as C(S), we have the obvious theorem that S ⊂ C(S), because the closure includes everything in S, plus the boundary.
Another easy, but not quite obvious theorem is that C(C(S)) ⊂ C(S). This says that once you take the closure, you have included the boundary, and you do not get any more boundary by taking the closure again. The closure of a set is "closed"; the closure of a "closed" set C is just C.
A third fundamental theorem about closures is that A⊂ B → C(A) ⊂ C(B).
Now we turn to monads. A monad is first of all a functor, which, if you restrict your attention to programming languages, means that a monad is a type constructor M with an associated function fmap such that for any function f of type α → β, fmap f has type M α → M β.
But a monad is also equipped with two other functions. There is a return function, which has type α → M α, and a join function, which has type M M α → M α.
Haskell provides monads with a "bind" function, written >>=, which is interdefinable with join:
join x = x >>= id
a >>= b = join (fmap b a)
but we are going to forget about >>= for now.So the monad is equipped with three fundamental operations:
fmap :: (a → b) → (M a → M b)
join :: M M a → M a
return :: a → M a
The three basic theorems about topological closures are:
(A ⊂ B) → (C(A) ⊂ C(B)If we imagine that ⊂ is a special kind of implication, the similarity with the monad laws is clear. And ⊂ is a special kind of implication, since (A ⊂ B) is just an abbreviation for (x ∈ A → x ∈ B).
C(C(A)) ⊂ C(A)
A ⊂ C(A)
If we name the three closure theorems "fmap", "join", and "return", we might guess that "bind" also turns out to be a theorem. And it is, because >>= has the type M a → (a → M b) → M b. The corresponding theorem is:
x ∈ C(A) → (A ⊂ C(B)) → x ∈ C(B)If the truth of this is hard to see, it is partly because the implications are in an unnatural order. The theorem is stated in the form P → Q → R, but it would be easier to understand as the equivalent Q → P → R:
A ⊂ C(B) → x ∈ C(A) → x ∈ C(B)Or more briefly:
A ⊂ C(B) → C(A) ⊂ C(B)This is quite true. We can prove it from the other three theorems as follows. Suppose A ⊂ C(B). Then by "fmap", C(A) ⊂ C(C(B)). By "join", C(C(B)) ⊂ C(B). By transitivity of ⊂, C(A) ⊂ C(B). This is what we wanted.
Haskell defines a =<< operator which is the same as >>= except with the arguments forwards instead of backwards:
=<< :: (a → M b) → M a → M b
a =<< b = b >>= a
The type of this function is analogous to the bind theorem, and I have
seen claims in the literature that the argument order is in some ways
more natural. Where the >>= function takes a value first, and then
feeds it to a given function, the =<< function makes more sense as a
curried function, taking a function of type a → M
b and yielding the corresponding function of type
M a → M
b.I think it's also worth noticing that the structure of the proof of the bind theorem (invoke "fmap" and then "join") is exactly the same as the structure of the code that defines "bind".
We can go the other way also, and prove the "join" theorem from the "bind" theorem. The definition of join in terms of >>= is:
join a = a >>= id
Following the program again, id in the
program code corresponds to the theorem that B ⊂ B
for any B. A special case of this theorem is that
C(B) ⊂ C(B) for any B. Then in
the "bind" theorem:
A ⊂ C(B) → C(A) ⊂ C(B)take A = C(B):
C(B) ⊂ C(B) → C(C(B)) ⊂ C(B)The left side of the implication is satisfied, so we conclude the consequent, C(C(B)) ⊂ C(B), which is what we wanted.
But wait, monad operations are also required to satisfy some monad laws. For example, join (return x) = x. How does this work out in topological closure world?
In programming language world, x here is required to have monad type. Monad types correspond to closed sets, so this is a theorem about closed sets. The theorem says that if X is a closed set, then the closure of X is the same as x. This is true.
The identity between these two things can be found in (surprise) category theory. In category theory, a monad is a (categorial) functor equipped with two natural transformations, the "return" and "join" operations. The categorial version of a closure operator is essentially the same.
Closure operations have a natural opposite. In topology, it is the "interior of" operation. The interior of a set is what you get if you discard the boundary of the set. The interior of a closed disc is an open disc; the interior of an open disc is the same open disc. Interior operations satisfy laws analogous but opposite to those enjoyed by closures:
Notice that the third theorem does not get turned around. I think this is because it comes from the functor itself, which goes the same way, not from the natural transformations, which go the other way. But I have not finished thinking abhout it carefully yet.
S ⊂ C(S) I(T) ⊂ T C(C(S)) ⊂ C(S) I(T) ⊂ I(I(T)) A⊂ B → C(A) ⊂ C(B) A⊂ B → I(A) ⊂ I(B)
Sooner or later I am going to program in Haskell with comonads, and it gives me a comfortable feeling to know that I am pre-equipped with a way to understand them as interior operations.
I have an idea that the power of mathematics comes principally from the places where it succeeds in understanding two different things as aspects of the same thing. For example, why is group theory so useful? Because it understands transformations of objects (say, rotations of a polyhedron) and algebraic operations as essentially the same thing. If you have a hard problem about one, you can often make it into an easier problem about the other one. Similarly analytic geometry transforms numerical problems into geometric problems and back again. Most often the geometry is harder than the numerical problem, and you use it in that direction, but often you go in the other direction instead.
It is quite possible that this notion is too vague to qualify as an actual theory. But category theory fits the description. Category theory lets you say that types are objects, type constructors are functors, and polymorphic functions are natural transformations. Then you can understand natural transformations as structure-preserving maps of something or other and get some insight into polymorphic functions, or vice-versa.
Category theory is a large agglomeration of such identities. Lambek and Scott's book starts with several slogans about category theory. One of these is that many objects of interest to mathematicians form categories, such as the category of sets. Another is that many objects of interest to mathematicians are categories. (For example, each set is a discrete category.) So one of the reasons category theory is so extremely useful is that it sets up these multiple entities as different aspects of the same thing.
I went to lunch and found more to say on the subject, but it will have to wait until another time.
[Other articles in category /math] permanent link
Wed, 07 Jan 2009
Addenda to recent articles 200811
- Earlier I discussed an interesting technique for flag variables in
Bourne shell programs. I did a little followup research.
I looked into several books on Unix shell programs, including:
- Linux Shell Scripting with Bash (Burtch)
- Unix Shell Programming 3ed. (Kochan and Wood)
- Mastering UNIX Shell Scripting (Michael)
But two readers sent me puzzled emails, to tell me that they had been using the true/false technique for years are were surprised that I found it surprising. Brooks Moses says that at his company they have a huge build system in Bourne shell, and they are trying to revise the boolean tests to the style I proposed. And Tom Limoncelli reports that code by Bill Cheswick and Hal Burch (Bell Labs guys) often use this technique. Tom speculates that it's common among the old farts from Bell Labs. Also, Adrián Pérez writes that he has known about this for years.
It's tempting to write to Kernighan to ask about it, but so far I have been able to resist.
- My first meta-addendum: In October's
addenda I summarized the results of a paper of Coquand,
Hancock, and Setzer about the inductive strength of various theories.
This summary was utterly wrong. Thanks to Charles Stewart and to
Peter Hancock for correcting me.
The topic was one I had hoped to get into anyway, so I may discuss it at more length later on.
[Other articles in category /addenda] permanent link