Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 250 |
| Programming | 102 |
| Language | 97 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Wed, 20 Sep 2006
The world's worst macro preprocessor
Last week I added another plugin to my Blosxom installation. As I wrote before, the sole
benefit of Blosxom is that it's incredibly simple and lightweight. So
when I write plugins for it, I try to keep them incredibly simple and
lightweight, lest I spoil the single major benefit of Blosxom.
Sometimes I'm more successful, sometimes less so. This time I think I
did a good job.
The goal last time was a macro processor. I write a lot of math articles. I get tired of writing <sup>2</sup> every time I want a superscript 2. Even if I bind a function key to that sequence of characters, it's hard to read. But now, with my new Blosxom macro processor, I just insert a line into my article that says:
#define ^2 <sup>2</sup>
and for the rest of the article, ^2 is expanded to <sup>2</sup>.
This has turned out really well, and I'm using it for all sorts of stuff. I use it for math notations, such as for making -> an abbreviation for → (→), and for making ~ an abbreviation for ¬ (¬).
But I've also used it to #define Godel Gödel. I've used it to #define KK <b>K</b> and #define SS <b>S</b>, which makes an article I'm writing about combinatory logic readable, where it wasn't readable before. In my recent article about job hunting, I used it to #define CV résumé, which saved me from having to interrupt my train of thought several times in the article.
There are some important points about the design that I think I got right on the first try. Whenever you write a macro system, you have to ask about escape sequences: what do you do if you don't want a macro expanded? For example, in the combinatory logic article I defined a macro SS. This meant that if I had written MOUSSE in the article somewhere, it would have turned into MOUSE. How should I prevent that kind of error?
Answer: I don't. I'm unlikely to do that. But if I do, I'll pick it up during the article proofreading phase. If I can't avoid writing MOUSSE, I have two choices: I can change the name of the SS macro to something easier to avoid—like S*, say, or I can define a second macro: #define !MOUSSE MOUSSE. But so far, it hasn't come up.
One alternative solution is to say that macros are expanded only in certain contexts. For example, SS might only be expanded when it is a complete word, not when it is in the middle of a word, as MOUSSE. I resisted this solution. It is much simpler to remember that every macro is expanded everywhere. And it it is much easier to fix the problem of a macro being expanded when I don't want it than it is to fix the problem of a macro not being expanded when I do want it. So every macro is expanded no matter where it appears.
Related to the unintentional-expansion issue is that each article has its own private macro set. I don't have to worry that by defining a macro named -> in one article that I might be sabotaging my opportunity to actually write -> in some unknown future article. Each set of macros can be totally ad hoc. I don't have to worry about global tradeoffs. Do I #define --- —, knowing that that will foreclose my opportunity to use --- in any other way? I can make the decision based on simple, local information.
It would have been tempting to over-engineer the system and add all sorts of complex escape facilities. I think I made the right choice here by not doing any of that.
Another escaping issue: What if I want to write something that looks like a definition but isn't? Here I avoided the problem by choosing a definition syntax that I was unlikely to write in any other context: #define in the leftmost column indicates a definition. In this article, I had to write some similar text. It was no trouble to indent it a couple of spaces, disabling the special meaning. But HTML is already full of escape mechanisms, and it would have been no trouble to write #define instead of #define if for some reason I had really needed it to appear in the leftmost column. (Unlikely anyway, since HTML has no column semantics.)
Another right choice I think I made was not to parametrize the macros. An article on algebra might well have:
#define ^2 <sup>2</sup> #define ^3 <sup>3</sup>and it might be oh-so-tempting to try to eliminate the duplication à la C:
#define ^(\w+) <sup>$1</sup>I did not do this. It would have complicated the processing substantially. It would also have complicated the use of the package substantially: I would have to worry a lot more than I do about invoking macros unintentionally. And it is not needed. Not so far, anyway. Because macro definitions only last for the duration of the article, there is no pressure to make a complete or consistent set of definitions. If an article happens to use the notations 2, i, and N, I can define macros for those and only those notations.
Also tempting is to extend the macro system to support something like this:
#define BF(.*) <b>$1</b>I have so far resisted this. My feeling is that if I want to do anything like this, I should take it as a sign that I should be writing the articles in some markup system other than HTML. Choice of that markup system should be made carefully, and not organically as an ad-hoc overburdening of the macro system.
I did run into one trouble with the macro system. Originally, it was invoked before some of my other plugins and after others. The earlier plugins automatically inserted certain text into the article that sometimes accidentally triggered my macros. I have not had any trouble with this since I changed the plugin order to invoke the macro processor before any of the other plugins.
The macro-processing code is about 19 lines long, of which three are diagnostic. It is the world's worst macro system. It has exactly one feature. It is, I think the simplest thing that could possibly work, and so a good companion to Blosxom. For this application, the world's worst macro system is the world's best.
[ Addendum 20071004: There's now a one-year retrospective analysis. ]
[Other articles in category /prog] permanent link
Tue, 19 Sep 2006
Job hunting stories
A guy named Jonathan Rentzsch bookmarked my article about creeping
featurism and the ratchet effect, saying "I'd like to hire this
guy just so I could fire him." Since I was looking for a new job last
month, I sent him my résumé, inquiring about his company's severance
package. He didn't reply.
Also in the said-it-but-didn't-mean-it department, Anil Dash gave a plenary talk at OSCON in which he mentioned that sixapart was hiring, and "looking for Perl gods". I looked for the Perl god positions on the "jobs" part of their web site, and saw nothing relevant, but I sent my résumé anyway. They didn't reply.
A few years ago I was contacted by a headhunter who was offering me a one-year contract in Milford, Iowa. I said I did not want to work in Milford, Iowa. He tried to sell me on the job anyway. I said I did not want to work in Milford, Iowa. He would not take "no". He said, "Look, I understand you are reluctant to consider this. But I would like you to take a few days and think it over, and tell me what it would take to get you to agree." Okay.
I talked it over with my wife, and we decided that for $750,000 we would be willing for me to spend the year working in Milford, Iowa. $500,000, we decided, would not be sufficient, but $750,000 would. I forget by now how we arrived at this figure, but we took some care in coming up with it.
The headhunter called back. "Have you thought it over?" Yes, I had, I said. I had decided that $750,000 would be required to get me to Milford, Iowa.
He was really angry that I had wasted his time.
I really hate commuting. I had a job once in which I had to commute from Philadelphia (where I live) to New York. I told them when I took the job that if I liked it, I'd move to New York, and if not, I'd quit and move to Taiwan. Commuting to New York wrecked me. For years afterward I couldn't get onto a train without falling asleep immediately. After I quit, I didn't move to Taiwan; I stayed in Philadelphia and became a consultant. Every day I would wake up, put on my trousers, shuffle downstairs, and sit down at the computer. "Ahhh," I would say, "my morning commute is complete!" The novelty of this did not wear off for years.
One day I was on a five-week business trip to Asia. (I hate commuting, but I like travelling.) I got email from a headhunter who was offering me a long-term contract in Elkton, Maryland. I had told this headhunter's company repeatedly that I was only interested in working in the Philadelphia area. (Elkton, Maryland is about as close to Philadelphia as you can get and still be in Maryland, which means that the only thing between Elkton and Philadelphia is the state of Delaware.)
I wrote back, from Tokyo, and said that his company should stop contacting me, because I had told them over and over that I would only work in Philadelphia, and they kept sending me offers of employment in places like Elkton. I said it was a shame that we should waste each others' time like this.
He suggested that the problem could be solved if I could just give him a "courtesy call". From Tokyo.
Instead, I solved the problem by putting his company in my spam filter file.
When I was about nineteen, a friend of mine asked me to comment on his résumé. I told him it was too long (it was three pages long) and that no prospective employer would care that he had held a job washing dishes for his fraternity.
He didn't like my advice. I still think it was good advice. No nineteen-year-old needs a three-page résumé. I wonder if he eventually figured this out. You'd think so, but now that I have to read the résumés of people who are applying to me for jobs, it seems that hardly any of the applicants have figured out that you should leave out the job where you washed dishes for your fraternity.
I once explained to someone that I change my résumé and send a different one with each job application. He was really shocked, and said he would consider that dishonest. Huh.
I've talked to a couple of people lately who tell me that it's very rare to get a cover letter from an applicant that actually helps their chances of getting the job. At best, it's neutral. At worst, you get to see all their spelling and grammar errors.
I think most people don't know how to write a letter, or that they write one letter and send it with every application. Maybe they think it would be dishonest to send a different letter with every application.
There's a story about how Robert A. Heinlein became a writer: he needed money, and saw that some magazine was offering a $50.00 prize for the best story by a new author. He wrote a story, but concluded that that magazine would be swamped with submissions, so he sent it to a different magazine, which bought the story for $70.00.
I became a conference speaker and teacher of Perl classes in a similar way. I wanted to go to the second Perl conference, but I couldn't afford it. Someone mentioned to me that there was a $1,000 prize for the best user paper. I thought I could write a good paper, but I also thought that the best paper often doesn't win the prize. But I also found out that conference tutorial speakers were paid $1,500 and given free conference admission and airfare and hotel fees.
When you're submitting a proposal for a tutorial, it's perfectly honorable to go talk to the program committee behind the scenes and lobby them to accept your proposal instead of someone else's. If you do that with the contest judges, it's cheating. So I ignored the user paper contest and submitted a proposal for a tutorial, which was accepted.
I once applied for a sysadmin job at the College of Staten Island, which is the school they send you to if you aren't qualified for any of the City University schools but they have to let you go to college because the City University system guarantees to admit anyone who can pay the tuition.
I got back a peevish letter telling me that I wasn't qualified and to stop wasting the search committee's time. It was signed, in pen, "The Search Committee".
I accepted a job with the University of Pennsylvania instead.
[Other articles in category ] permanent link
Wed, 13 Sep 2006
More about automorphisms
In a recent article, I asserted
that "there aren't even any reasonable [automorphisms of R]
that preserve addition.". This is patently untrue.
My proof started by referring to a previous result that any such automorphism f must have f(1) = 1. But actually, I had only proved this for automorphisms that must preserve multiplication. For automorphisms that preserve addition only, f(1) need not be 1; it can be anything. In fact, x → kx is an automorphism of R for all k except zero. It is not hard to show, following the technique in the earlier article, that every continuous automorphism has this form.
In hopes of salvaging something from my embarrassing error, I thought I'd spend a little time talking about the other automorphisms of R, the ones that aren't "reasonable". They are unreasonable in at least two ways: they are everywhere discontinuous, and they cannot be exhibited explicitly.
To manufacture the function, we first need a mathematical horror called a Hamel basis. A Hamel basis is a set of real numbers Hα such that every real number r has a unique representation in the form:
$$r = \sum_{i=1}^n q_i H_{\alpha_i}$$
where all the qi are rational. (It is called a Hamel basis because it makes the real numbers into a vector space over the rationals. If this explanation makes no sense to you, please ignore it.)The sum here is finite, so only a finite number of the uncountably many Hα are involved for any particular r; this is what characterizes it as a Hamel basis.
Leaving aside the proof that the Hamel basis exists at all, if we suppose we have one, we can easily construct an automorphism of R. Just pick some rational numbers mα, one for each Hα. Then if as above, we have:
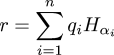
$$f(r) = \sum_{i=1}^n q_i H_{\alpha_i}m_{\alpha_i}$$
At this point I should probably prove that this is an automorphism. But it seems unwise, because I think that in the unlikely case that you have understood everything so far, you will find the statement that this is an automorphism both clear and obvious, and will be able to imagine the proof yourself, and for me to spell it out will only confuse the issue. And I think that if you have not understood everything so far, the proof will not help. So I should probably just say "clearly, this is an automorphism" and move on.
But against my better judgement, I'll give it a try. Let r and s be real numbers. We want to show that f(s) + f(r) = f(s + r). Represent r and s using the Hamel basis. For each element H of the Hamel basis, let's say that cH(r) is the (rational) coefficient of H in the representation of r. That is, it's the qi in the definition above.
By a simple argument involving commutativity and associativity of addition, cH(r+s) = cH(r) + cH(s) for all r, s, and H.
Also, cH(f(r)) = m·cH(r), for all r and H, where m is the multiplier we chose for H back when we were making up the automorphism, because that's how we defined f.
Then cH(f(r+s)) = m·cH(r+s) = m·(cH(r) + cH(s)) = m·cH(r) + m·cH(s) = cH(f(r)) + cH(f(s)) = cH(f(r) + f(s)), for all H.
This means that f(r+s) and f(r) + f(s) have the same Hamel basis representation. They are therefore the same number. This is what we wanted to show.
If anyone actually found that in the least enlightening, I would be really interested to hear about it.
One property of a Hamel basis is that exactly one of its uncountably many elements is rational. Say it's H0. Then every rational number q is represented as q = (q/H0)·H0. Then f(q) = (q/H0)·H0m0 = m0q for all rational numbers q. But in general, an irrational number x will not have f(x) = m0x, so the automorphism is discontinuous everywhere, unless all the mα are equal, in which case it's just x → mx again.
The problem with this construction is that it is completely abstract. Nobody can exhibit an example of a Hamel basis, being, as it is, an uncountably infinite set of mainly irrational numbers. So the discontinuous automorphisms constructed here are among the most utterly useless of all mathematical examples.
I think that is the full story about additive automorphisms of R. I hope I got everything right this time.
I should add, by the way, that there seems to be some disagreement about what is called a Hamel basis. Some people say it is what I said: a basis for the reals over the rationals, with the properties I outlined above. However, some people, when you say this, will sniff, adjust their pocket protectors, and and correct you, saying that that a Hamel basis is any basis for any vector space, as long as it has the analogous property that each vector is representable as a combination of a finite subset of the basis elements. Some say one, some the other. I have taken the definition that was convenient for the exposition of this article.
[ Thanks to James Wetterau for pointing out the error in the earlier article. ]
[ Previous articles in this series: Part 1 Part 2 Part 3 Part 4 ]
[Other articles in category /math] permanent link
Automorphisms of the complex numbers
In
an earlier article,
I wrote a proof that the only automorphisms of the complex numbers are
the identity function and the function
a + bi → a - bi.
Robert C. Helling points out that there is a much simpler proof that this is the case. Suppose that f is an automorphism, and that x2 = y. Then f(x2) = (f(x))2 = f(y), so that if x is a square root of y, then f(x) is a square root of f(y).
As I pointed out, f(1) = 1. Since -1 is a square root of 1, f(-1) must be a square root of 1, and so it must be -1. (It can't be 1, since automorphisms may not map two different arguments to the same value.) Since i is a square root of -1, f(i) must also be a square root of -1. So f(i) must be either ±i, and the theorem is proved.
This is a nice example of why I am not a mathematician. When I want to find the automorphisms of C, my first idea is to explicitly write down the general automorphism and then start bashing away on the algebra. This sort of mathematical pig-slaughtering gets the pig cut up all right, but mathematicians are not interested in slaughtering pigs. By which I mean that the approach gets the result I want, usually, but not new or mathematically interesting results.
In computer programming, the pig-slaughtering approach often works really well. Most programs are oversubtle, and can be easily improved by doing the necessary tasks in the simplest and most straightforward possible way, rather than in whatever baroque way the original programmer dreamed up.
[ Previous articles in this series: Part 1 Part 2 Part 3 Followup article: Part 5 ]
[Other articles in category /math] permanent link
Russell and Whitehead or Whitehead and Russell?
In an earlier article, I asked:
Everyone always says "Russell and Whitehead". Google results for "Russell and Whitehead" outnumber those for "Whitehead and Russell" by two to one, for example. Why? The cover and the title page [of Principia Mathematica] say "Alfred North Whitehead and Bertrand Russell, F.R.S.". How and when did Whitehead lose out on top billing?
I was going to write that I thought the answer was that when Whitehead died, he left instructions to his family that they destroy his papers; this they did. So Whitehead's work was condemned to a degree of self-imposed obscurity that Russell's was not.
I was planning to end this article there. But now, on further reflection, I think that this theory is oversubtle. Russell was a well-known political and social figure, a candidate for political office, a prolific writer, a celebrity, a famous pacifist. Whitehead was none of these things; he was a professor of philosophy, about as famous as other professors of philosophy.
The obvious answer to my question above would be "Whitehead lost out on top billing on 10 December, 1950, when Russell was awarded the Nobel Prize."
Oh, yeah. That.
I'm reminded of the advertising for the movie Space Jam. The posters announced that it starred Bugs Bunny and Michael Jordan, in that order. I reflected for a while on the meaning of this. Was Michael Jordan incensed at being given second billing to a fictitious rabbit? (Probably not, I think; I imagine that Michael Jordan is entirely unthreatened by the appurtenances of any else's fame, and least of all by the fame of a fictitious rabbit.) Why does Bugs Bunny get top billing over Michael Jordan? I eventually decided that while Michael Jordan is a hero, Bugs Bunny is a god, and gods outrank heroes.
[Other articles in category /math] permanent link
Tue, 12 Sep 2006
Imaginary units, again
In my earlier discussion of i
and -i I said " The point about the
square roots of -1 is that there is no corresponding criterion
for distinguishing the two roots. This is a theorem."
The proof of the theorem is not too hard. What we're looking for is what's called an automorphism of the complex numbers. This is a function, f, which "relabels" the complex numbers, so that arithmetic on the new labels is the same as the arithmetic on the old labels. For example, if 3×4 = 12, then f(3) × f(4) should be f(12).
Let's look at a simpler example, and consider just the integers, and just addition. The set of even integers, under addition, behaves just like the set of all integers: it has a zero; there's a smallest positive number (2, whereas it's usually 1) and every number is a multiple of this smallest positive number, and so on. The function f in this case is simply f(n) = 2n, and it does indeed have the property that if a + b = c, then f(a) + f(b) = f(c) for all integers a, b, and c.
Another automorphism on the set of integers has g(n) = -n. This just exchanges negative and positive. As far as addition is concerned, these are interchangeable. And again, for all a, b, and c, g(a) + g(b) = g(c).
What we don't get with either of these examples is multiplication. 1 × 1 = 1, but f(1) × f(1) = 2 × 2 = 4 ≠ f(1) = 2. And similarly g(1) × g(1) = -1 × -1 = 1 ≠ g(1) = -1.
In fact, there are no interesting automorphisms on the integers that preserve both addition and multiplication. To see this, consider an automorphism f. Since f is an automorphism that preserves multiplication, f(n) = f(1 × n) = f(1) × f(n) for all integers n. The only way this can happen is if f(1) = 1 or if f(n) = 0 for all n.
The latter is clearly uninteresting, and anyway, I neglected to mention that the definition of automorphism rules out functions that throw away information, as this one does. Automorphisms must be reversible. So that leaves only the first possibility, which is that f(1) = 1. But now consider some positive integer n. f(n) = f(1 + 1 + ... + 1) = f(1) + f(1) + ... + f(1) = 1 + 1 + ... + 1 = n. And similarly for 0 and negative integers. So f is the identity function.
One can go a little further: there are no interesting automorphisms of the real numbers that preserve both addition and multiplication. In fact, there aren't even any reasonable ones that preserve addition. The proof is similar. First, one shows that f(1) = 1, as before. Then this extends to a proof that f(n) = n for all integers n, as before. Then suppose that a and b are integers. b·f(a/b) = f(b)f(a/b) = f(b·a/b) = f(a) = a, so f(a/b) = a/b for all rational numbers a/b. Then if you assume that f is continuous, you can fill in f(x) = x for the irrational numbers also.
(Actually this is enough to show that the only continuous addition-preserving automorphism of the reals is the identity function. There are discontinuous addition-preserving functions, but they are very weird. I shouldn't need to drag in the continuity issue to show that the only addition-and-multiplication-preserving automorphism is the identity, but it's been a long day and I'm really fried.)
[ Addendum 20060913: This previous paragraph is entirely wrong; any function x → kx is an addition-preserving automorphism, except of course when k=0. For more complete details, see this later article. ]
But there is an interesting automorphism of the complex numbers; it has f(a + bi) = a - bi for all real a and b. (Note that it leaves the real numbers fixed, as we just showed that it must.) That this function f is an automorphism is precisely the content of the statement that i and -i are numerically indistinguishable.
The proof that f is an automorphism is very simple. We need to show that if f(a + bi) + f(c + di) = f((a + bi) + (c + di)) for all complex numbers a+bi and c+di, and similarly f(a + bi) × f(c + di) = f((a + bi) × (c + di)). This is really easy; you can grind out the algebra in about two steps.
What's more interesting is that this is the only nontrivial automorphism of the complex numbers. The proof of this is also straightforward, but a little more involved. The purpose of this article is to present the proof.
Let's suppose that f is an automorphism of the complex numbers that preserves both addition and multiplication. Let's say that f(i) = p + qi. Then f(a + bi) = f(a) + f(b)f(i) = a + bf(i) (because f must leave the real numbers fixed) = a + b(p + qi) = (a + bp) + bqi.
Now we want f(a + bi) + f(c + di) = f((a + bi) + (c + di)) for all real numbers a, b, c, and d. That is, we want (a + bp + bqi) + (c + dp + dqi) = (a + c) + (b + d)(p + qi). It is, so that part is just fine.
We also want f(a + bi) × f(c + di) = f((a + bi) × (c + di)) for all real numbers a, b, c, and d. That means we need:
| (a + b(p + qi)) × (c + d(p + qi)) | = | f((ac-bd) + (ad+bc)i) |
| (a + bp + bqi) × (c + dp + dqi) | = | ac - bd + (ad + bc)(p + qi) |
| ac + adp + adqi + bcp + bdp2 + 2bdpqi + bcqi - bdq2 | = | ac - bd + adp + bcp + adqi + bcqi |
| bdp2 + 2bdpqi - bdq2 | = | - bd |
| p2 + 2pqi - q2 | = | -1 |
Equating the real and imaginary parts gives us two equations:
- p2 - q2 = -1
- 2pq = 0
Equation 2 implies that either p or q is 0. If they're both zero, then f(a + bi) = a, which is not reversible and so not an automorphism.
Trying q=0 renders equation 1 insoluble because there is no real number p with p2 = -1. But p=0 gives two solutions. One has p=0 and q=1, so f(a+bi) = a+bi, which is the identity function, and not interesting. The other has p=0 and q=-1, so f(a+bi) = a-bi, which is the one we already knew about. But we now know that there are no others, which is what I wanted to show.
[ Previous articles in this series: Part 1 Part 2 Followup articles: Part 4 Part 5 ]
[Other articles in category /math] permanent link
Mon, 11 Sep 2006
Design patterns of 1972
"Patterns" that are used recurringly in one language may be invisible
or trivial in a different language.
Extended Example: "object-oriented class"
C programmers have a pattern that might be called "Object-oriented class". In this pattern, an object is an instance of a C struct.
struct st_employee_object *emp;
Or, given a suitable typedef:
EMPLOYEE emp;
Some of the struct members are function pointers. If "emp" is an
object, then one calls a method on the object by looking up the
appropriate function pointer and calling the pointed-to function:
emp->method(emp, args...);
Each struct definition defines a class; objects in the same class have
the same member data and support the same methods. If the structure
definition is defined by a header file, the layout of the structure
can change; methods and fields can be added, and none of the code that
uses the objects needs to know.There are a bunch of variations on this. For example, you can get opaque implementation by defining two header files for each class. One defines the implementation:
struct st_employee_object {
unsigned salary;
struct st_manager_object *boss;
METHOD fire, transfer, competence;
};
The other defines only the interface:
struct st_employee_object {
char __SECRET_MEMBER_DATA_DO_NOT_TOUCH[4];
struct st_manager_object *boss;
METHOD fire, transfer, competence;
};
And then files include one or the other as appropriate. Here "boss"
is public data but "salary" is private.You get abstract classes by defining a constructor function that sets all the methods to NULL or to:
void _abstract() { abort(); }
If you want inheritance, you let one of the structs be a prefix of
another:
struct st_manager_object; /* forward declaration */
#define EMPLOYEE_FIELDS \
unsigned salary; \
struct st_manager_object *boss; \
METHOD fire, transfer, competence;
struct st_employee_object {
EMPLOYEE_FIELDS
};
struct st_manager_object {
EMPLOYEE_FIELDS
unsigned num_subordinates;
struct st_employee_object **subordinate;
METHOD delegate_task, send_to_conference;
};
And if obj is a manager object, you can still treat
it like an employee and call employee methods on
it.This may seem weird or contrived, but the technique is widely used. The C standard contains guarantees that the common fields of struct st_manager_object and struct st_employee_object will be laid out identically in memory, specifically so that this object-oriented class technique can work. The code of the X window system has this structure. The code of the Athena widget toolkit has this structure. The code of the Linux kernel filesystem has this structure.
Rob Pike, one of the primary architects of the Plan 9 operating system (the Bell Labs successor to Unix) and co-author (with Brian Kernighan) of The Unix Programming Environment, recommends this technique in his article "Notes on Programming in C".
This is a pattern
There's only one way in which this technique doesn't qualify as a pattern according to the definition of Gamma, Helm, Johnson, and Vlissides. They say:
A design pattern systematically names, motivates, and explains a general design that addresses a recurring design problem in object-oriented systems. It describes the problem, the solution, when to apply the solution, and its consequences. It also gives implementation hints and examples. The solution is a general arrangement of objects and classes that solve the problem. The solution is customized and implemented to solve the problem in a particular context.Their definition arbitrarily restricts "design patterns" to addressing recurring design problems "in object-oriented systems", and to being general arrangements of "objects and classes". If we ignore this arbitrary restriction, the "object-oriented class" pattern fits the description exactly.
The definition in Wikipedia is:
In software engineering, a design pattern is a general solution to a common problem in software design. A design pattern isn't a finished design that can be transformed directly into code; it is a description or template for how to solve a problem that can be used in many different situations.And the "object-oriented class" solution certainly qualifies.
Codification of patterns
Peter Norvig's presentation on "Design Patterns in Dynamic Languages" describes three "levels of implementation of a pattern":
- Invisible
- So much a part of language that you don't notice
- Formal
- Implement pattern itself within the language
Instantiate/call it for each use
Usually implemented with macros - Informal
- Design pattern in prose; refer to by name, but
Must be reimplemented from scratch for each use
The single major driver for the invention of C++ was to codify this pattern into the language so that it was "invisible". In C++, you don't have to think about the structs and you don't have to worry about keeping data and methods private. You just declare a "class" (using syntax that looks almost exactly like a struct declaration) and annotate the items with "public" and "private" as appropriate.
But underneath, it's doing the same thing. The earliest C++ compilers simply translated the C++ code into the equivalent C code and invoked the C compiler on it. There's a reason why the C++ method call syntax is object->method(args...): it's almost exactly the same as the equivalent code when the pattern is implemented in plain C. The only difference is that the object is passed implicitly, rather than explicitly.
In C, you have to make a conscious decision to use OO style and to implement each feature of your OOP system as you go. If a program has fifty modules, you need to decide, fifty times, whether you will make the next module an OO-style module. In C++, you don't have to make a decision about whether or not you want OO programming and you don't have to implement it; it's built into the language.
Sherman, set the wayback machine for 1957
If we dig back into history, we can find all sorts of patterns. For example:
Recurring problem: Two or more parts of a machine language program need to perform the same complex operation. Duplicating the code to perform the operation wherever it is needed creates maintenance problems when one copy is updated and another is not.This is a "pattern"-style description of the pattern we now know as "subroutine". It addresses a recurring design problem. It is a general arrangement of machine instructions that solve the problem. And the solution is customized and implemented to solve the problem in a particular context. Variations abound: "subroutine with passed parameters". "subroutine call with returned value". "Re-entrant subroutine".Solution: Put the code for the operation at the end of the program. Reserve some extra memory (a "frame") for its exclusive use. When other code (the "caller") wants to perform the operation, it should store the current values of the machine registers, including the program counter, into the frame, and transfer control to the operation. The last thing the operation does is to restore the register values from the values saved in the frame and jump back to the instruction just after the saved PC value.
For machine language programmers of the 1950s and early 1960's, this was a pattern, reimplemented from scratch for each use. As assemblers improved, the pattern became formal, implemented by assembly-language macros. Shortly thereafter, the pattern was absorbed into Fortran and Lisp and their successors, and is now invisible. You don't have to think about the implementation any more; you just call the functions.
Iterators and model-view-controller
The last time I wrote about design patterns, it was to point out that although the movement was inspired by the "pattern language" work of Christopher Alexander, it isn't very much like anything that Alexander suggested, and that in fact what Alexander did suggest is more interesting and would probably be more useful for programmers than what the design patterns movement chose to take.One of the things I pointed out was essentially what Norvig does: that many patterns aren't really addressing recurring design problems in object-oriented programs; they are actually addressing deficiencies in object-oriented programming languages, and that in better languages, these problems simply don't come up, or are solved so trivially and so easily that the solution doesn't require a "pattern". In assembly language, "subroutine call" may be a pattern; in C, the solution is to write result = function(args...), which is too simple to qualify as a pattern. In a language like Lisp or Haskell or even Perl, with a good list type and powerful primitives for operating on list values, the Iterator pattern is to a great degree obviated or rendered invisible. Henry G. Baker took up this same point in his paper "Iterators: Signs of Weakness in Object-Oriented Languages".
I received many messages about this, and curiously, some made the same point in the same way: they said that although I was right about Iterator, it was a poor example because it was a very simple pattern, but that it was impossible to imagine a more complex pattern like Model-View-Controller being absorbed and made invisible in this way.
This remark is striking for several reasons. It is an example of what is perhaps the most common philosophical fallacy: the writer cannot imagine something, so it must therefore be impossible. Well, perhaps it is impossible—or perhaps the writer just doesn't have enough imagination. It is worth remembering that when Edgar Allan Poe was motivated to investigate and expose Johann Maelzel's fraudulent chess-playing automaton, it was because he "knew" it had to be fraudulent because it was inconceivable that a machine could actually exist that could play chess. Not merely impossible, but inconceivable! Poe was mistaken, and the people who asserted that MVC could not be absorbed into a programming language were mistaken too. Since I gave my talk in 2002, several programming systems, such as Ruby on Rails and Subway have come forward that attempt to codify and integrate MVC in exactly the way that I suggested.
Progress in programming languages
Had the "Design Patterns" movement been popular in 1960, its goal would have been to train programmers to recognize situations in which the "subroutine" pattern was applicable, and to implement it habitually when necessary. While this would have been a great improvement over not using subroutines at all, it would have been vastly inferior to what really happened, which was that the "subroutine" pattern was codified and embedded into subsequent languages.Identification of patterns is an important driver of progress in programming languages. As in all programming, the idea is to notice when the same solution is appearing repeatedly in different contexts and to understand the commonalities. This is admirable and valuable. The problem with the "Design Patterns" movement is the use to which the patterns are put afterward: programmers are trained to identify and apply the patterns when possible. Instead, the patterns should be used as signposts to the failures of the programming language. As in all programming, the identification of commonalities should be followed by an abstraction step in which the common parts are merged into a single solution.
Multiple implementations of the same idea are almost always a mistake in programming. The correct place to implement a common solution to a recurring design problem is in the programming language, if that is possible.
The stance of the "Design Patterns" movement seems to be that it is somehow inevitable that programmers will need to implement Visitors, Abstract Factories, Decorators, and Façades. But these are no more inevitable than the need to implement Subroutine Calls or Object-Oriented Classes in the source language. These patterns should be seen as defects or missing features in Java and C++. The best response to identification of these patterns is to ask what defects in those languages cause the patterns to be necessary, and how the languages might provide better support for solving these kinds of problems.
With Design Patterns as usually understood, you never stop thinking about the patterns after you find them. Every time you write a Subroutine Call, you must think about the way the registers are saved and the return value is communicated. Every time you build an Object-Oriented Class, you must think about the implementation of inheritance.
People say that it's all right that Design Patterns teaches people to do this, because the world is full of programmers who are forced to use C++ and Java, and they need all the help they can get to work around the defects of those languages. If those people need help, that's fine. The problem is with the philosophical stance of the movement. Helping hapless C++ and Java programmers is admirable, but it shouldn't be the end goal. Instead of seeing the use of design patterns as valuable in itself, it should be widely recognized that each design pattern is an expression of the failure of the source language.
If the Design Patterns movement had been popular in the 1980's, we wouldn't even have C++ or Java; we would still be implementing Object-Oriented Classes in C with structs, and the argument would go that since programmers were forced to use C anyway, we should at least help them as much as possible. But the way to provide as much help as possible was not to train people to habitually implement Object-Oriented Classes when necessary; it was to develop languages like C++ and Java that had this pattern built in, so that programmers could concentrate on using OOP style instead of on implementing it.
Summary
Patterns are signs of weakness in programming languages.When we identify and document one, that should not be the end of the story. Rather, we should have the long-term goal of trying to understand how to improve the language so that the pattern becomes invisible or unnecessary.
[ Thanks to Garrett Rooney for pointing out some minor errors that I have since corrected. - MJD ]
[ Addendum 20061003: There is a followup article to this one, replying to a response by Ralph Johnson, one of the authors of the "Design Patterns" book. This link URL is correct, but Johnson's website will refuse it if you come from here. ]
[Other articles in category /prog] permanent link
Sat, 09 Sep 2006
Imaginary units, revisited
Last night, shortly after posting my article about the fact that i and -i are
mathematically indistinguishable, I thought of what I should have
said about it—true to form, forty-eight hours too late. Here's
what I should have said.
The two square roots of -1 are indistinguishable in the same way that the top and bottom faces of a cube are. Sure, one is the top, and one is the bottom, but it doesn't matter, and it could just as easily be the other way around.
Sure, you could say something like this: "If you embed the cube in R3, then the top face is the set of points that have z-coordinate +1, and the bottom face is the set of points that have z-coordinate -1." And indeed, once you arbitrarily designate that one face is on the top and the other is on the bottom, then one is on the top, and one is on the bottom—but that doesn't mean that the two faces had any a priori difference, that one of them was intrinsically the top, or that the designation wasn't completely arbitrary; trying to argue that the faces are distinguishable, after having made an arbitrary designation to distinguish them, is begging the question.
Now can you imagine anyone seriously arguing that the top and bottom faces of a cube are mathematically distinguishable?
[ Previous article in this series: Part 1 Followup articles: Part 3 Part 4 Part 5 ]
[Other articles in category /math] permanent link
Fri, 08 Sep 2006
I get a new job
Where did my blog go for the past six weeks? Well, I was busy with
another project. Usually, when I am busy with a project, it shows up
here, because I am thinking about it, and I want to write about what I
am thinking. As Hans Arp said, it grows out of me and I keep cutting
it off, like toenails. But in this case I could not write about the
project here, because it was a secret. I was looking for a new job,
and I did not want my old job to find out before I was ready.
(Many people have been surprised to learn that I have a job; they remember that for many years I was intermittently a software consultant and itinerant programming trainer. But since January 2004 I have been regularly employed to do maintenance programming for the University of Pennsylvania's Networking and Telecommunications group.)
Anyway, the job hunt has come to a close. I accepted a new job, put in my resignation letters at the old one, and can stop thinking about it for a while. The new work will be head software engineer at the Penn Genomics Institute. I will try to develop software for genetic biologists to use in their research. I expect that the new job will suit me somewhat better than the old one. I like that it is connected to science, and that I will be working with scientists. The work itself is important; genomics is going to change everything in the world. Also, it pays rather more than the old one, although that was not the principal concern.
So with any luck blog posts will resume here, and eventually some genomics-related articles may start appearing.
[Other articles in category /bio] permanent link
Imaginary units
Yesterday I had a phenomenally annoying discussion with the pedants on
the IRC #math channel. Someone was talking about square roots, and
for some reason I needed to point out that when you are considering
square roots of negative numbers, it is important not to forget that
there are two square roots.
I should back up and discuss square roots in more detail. The square root of x, written √x, is defined to be the number y such that y2 = x. Well, no, that actually contains a subtle error. The error is in the use of the word "the". When we say "the number y such that...", we imply that there is only one. But every number (except zero) has two square roots. For example, the square roots of 16 are 4 and -4. Both of these are numbers y with the property that y2 = 16.
In many contexts, we can forget about one of the square roots. For example, in geometry problems, all quantities are positive. (I'm using "positive" here to mean "≥ 0".) When we consider a right triangle whose legs have lengths a and b, we say simply that the hypotenuse has length √(a2 + b2), and we don't have to think about the fact that there are actually two square roots, because one of them is negative, and is nonsensical when discussing hypotenuses. In such cases we can talk about the square root function, sqrt(x), which is defined to be the positive number y such that y2 = x. There the use of "the" is justified, because there is only one such number. But pinning down which square root we mean has a price: the square root function applies only to positive arguments. We cannot ask for sqrt(-1), because there is no positive number y such that y2 = -1. For negative arguments, this simplification is not available, and we must fall back to using √ in its full generality.
In high school algebra, we all learn about a number called i, which is defined to be the square root of -1. But again, the use of the word "the" here is misleading, because "the" square root is not unique; -1, like every other number (except 0) has two square roots. We cannot avail ourselves of the trick of taking the positive one, because neither root is positive. And in fact there is no other trick we can use to distinguish the two roots; they are mathematically indistinguishable.
The annoying discussion was whether it was correct to say that the two roots are mathematically indistinguishable. It was annoying because it's so obviously true. The number i is, by definition, a number such that i2 = -1. This is its one and only defining property. Since there is another number which shares this single defining property, it stands to reason that this other root is completely interchangeable with i—mathematically indistinguishable from it, in other words.
This other square root is usually written "-i", which suggests that it's somehow secondary to i. But this is not the case. Every numerical property possessed by i is possessed by -i as well. For example, i3 = -i. But we can replace i with -i and get (-i)3 = -(-i), which is just as true. Euler's famous formula says that eix = cos x + i sin x. But replacing i with -i here we get e-ix = cos x + -i sin x, which is also true.
Well, one of them is i, and the other is -i, so can't you distinguish them that way? No; those are only expressions that denote the numbers, not the numbers themselves. There is no way to know which of the numbers is denoted by which expression, and, in fact, it does not even make much sense to ask which number is denoted by which expression, since the two numbers are entirely interchangeable. One is i, and one is -i, sure, but this is just saying that one is the negative of the other. But so too is the other the negative of the one.
One of the #math people pointed out that there is a well-known Im() function, the "imaginary part" function, such that Im(i) = 1, but Im(-i) = -1, and suggested, rather forcefully, that they could be distinguished that way. This, of course, is hopeless. Because in order to define the "imaginary part" function in the first place, you must start by making an entirely arbitrary choice of which square root of -1 you are using as the unit, and then define Im() in terms of this choice. For example, one often defines Im(z) as !!z - \bar{z} \over 2i!!. But in order to make this definition, you have to select one of the imaginary units and designate it as i and use it in the denominator, thus begging the question. Had you defined Im() with -i in place of i, then Im(i) would have been -1, and vice versa.
Similarly, one #math inhabitant suggested that if one were to define the complex numbers as pairs of reals (a, b), such that (a, b) + (c, d) = (a + c, b + d), (a, b) × (c, d) = (ac - bd, ad + bc), then i is defined as (0,1), not (0,-1). This is even more clearly begging the question, since the definition of i here is solely a traditional and conventional one; defining i as (0, -1) instead of (0,1) works exactly as well; we still have i2 = -1 and all the other important properties.
As IRC discussions do, this one then started to move downwards into straw man attacks. The #math folks then argued that i ≠ -i, and so the two numbers are indeed distinguishable. This would have been a fine counterargument to the assertion that i = -i, but since I was not suggesting anything so silly, it was just stupid. When I said that the numbers were indistinguishable, I did not mean to say that they were numerically equal. If they were, then -1 would have only one square root. Of course, it does not; it has two unequal, but entirely interchangeable, square roots.
The that the square roots of -1 are indistinguishable has real content. 1 has two square roots that are not interchangeable in this way. Suppose someone tells you that a and b are different square roots of 1, and you have to figure out which is which. You can do that, because among the two equations a2 = a, b2 = b, only one will be true. If it's the former, then a=1 and b=-1; if the latter, then it's the other way around. The point about the square roots of -1 is that there is no corresponding criterion for distinguishing the two roots. This is a theorem. But the result is completely obvious if you just recall that i is merely defined to be a square root of -1, no more and no less, and that -1 has two square roots.
Oh well, it's IRC. There's no solution other than to just leave. [ Addenda: Part 2 Part 3 Part 4 Part 5 ]
[Other articles in category /math] permanent link