Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2024: | JFMA |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 238 |
| Programming | 99 |
| Language | 92 |
| Miscellaneous | 67 |
| Book | 49 |
| Tech | 48 |
| Etymology | 34 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 23 |
| Physics | 21 |
| Law | 21 |
| Perl | 17 |
| Biology | 15 |



Comments disabled
Fri, 24 Feb 2023
American things with foreign-language names
Last week I wrote an article about Korean street signs that “would use borrowed English words even when there was already a perfectly good word already in Korean”. And giving an example, I said:
Apparently this giant building does not have a Korean name.

(The giant building is named “트레이드타워” (teu-re-i-deu ta-wŏ, a hangeulization of the English “Trade Tower”.)
Jesse Chen objected to my claim that the Trade Tower does not have a Korean name, giving as analogous examples “Los Angeles” (Spanish loanwords) or “Connecticut” (Mohegan-Pequot). She suggested that I would not argue that Los Angeles has no English name.
I felt that these examples weren't apposite, because those places had already had those names, before the Anglophones showed up and continued using the names that already existed. The analogous situation would be if Americans had built a “Trade Tower” in Seoul, called it that for a while and then Koreans had taken it over and kept the name, even though the original English meaning wasn't apparent. But that's not what happened. Koreans built a whole new building in Seoul, and made up a whole new name for it, not a Korean name but an English one, which they then wrote in the not-quite suitable Korean script.
In the earlier article I had tried to think of an analogous example with Korea replaced by the U.S., and English replaced by some other language, and admitted:
all I could come up with was this little grocery store in Philadelphia's Chinatown…

This was a spectacularly funny failure on my part. Here's why.
In 1682, some English people came to North America and built a whole new city. They decided not to give their city an English name. Instead, they used borrowed Greek words even though there were perfectly good words already in English that meant the same thing.
And to this day, this giant city does not have an English name.

The city is named “Philadelphia”, a romanization of the Greek Φιλαδέλφεια. This is a compound of φίλος “beloved” and αδελφός “brother”. Philadelphia is often called the City of Brotherly Love, but its official name is in Greek, not English.
To those 17th-century English colonists, Greek must have seemed cool in a way similar to the way English seems cool to 21st-century Koreans. Someday maybe the Pirahã will build buildings and found cities and give them Korean names because Korean seems cool to them also.
I came so close to getting it!
“Welcome to Philadelphia” sign cropped from photograph by Famartin, CC BY-SA 4.0, via Wikimedia Commons
_just_south_of_Farwood_Road_along_the_border_of_Philadelphia_and_Haverford_Township,_Delaware_County_in_Pennsylvania.jpg){kind=link}
[Other articles in category /oops] permanent link
Thu, 27 Jan 2022
Yet another software archaeology failure
I have this nice little utility program called
menupick.
It's a filter that reads a list of items on standard input, prompts
the user to select one or more of them, then prints the selected items
on standard output. So for example:
emacs $(ls *.blog | menupick)
displays a list of those files and a prompt:
0. Rocketeer.blog
1. Watchmen.blog
2. death-of-stalin.blog
3. old-ladies.blog
4. self-esteem.blog
>
Then I can type 1 2 4 to select items 1, 2, and 4, or 1-4 !3 (“1
through 4, but not 3”) similarly. It has some other features I use
less commonly. It's a useful component in other commands, such as
this oneliner
git-addq
that I use every day:
git add $(git dirtyfiles "$@" | menupick -1)
(The -1 means that if the standard input contains only a single item,
just select it without issuing a prompt.)
The interactive prompting runs in a loop, so that if the menu is long
I can browse it a page at a time, adding items, or maybe removing
items that I have added before, adjusting the selection until I have
what I want. Then entering a blank line terminates the interaction.
This is useful when I want to ponder the choices, but for some of the
most common use cases I wanted a way to tell menupick “I am only
going to select a single item, so don't loop the interaction”. I have
wanted that for a long time but never got around to implementing it
until this week. I added a -s flag which tells it to terminate the
interaction instantly, once a single item has been selected.
I modified the copy in $HOME/bin/menupick, got it working the way I
wanted, then copied the modified code to my utils git repository to commit
and push the changes. And I got a very sad diff, shown here only in part:
diff --git a/bin/menupick b/bin/menupick
index bc3967b..b894652 100755
--- a/bin/menupick
+++ b/bin/menupick
@@ -129,7 +129,7 @@ sub usage {
-1: if there is only one item, select it without prompting
-n pagesize: maximum number of items on each page of the menu
(default 30)
- -q: quick mode: exit as soon as at least one item has been selected
+ -s: exit immediately once a single item has been selected
Commands:
Each line of input is a series of words of the form
I had already implemented almost the exact same feature, called it
-q, and completely forgotten to use it, completely failed to install
it, and then added the new -s feature to the old version of the
program 18 months later.
(Now I'm asking myself: how could I avoid this in the future? And the clear answer is: many people have a program that downloads and installs their utiities and configuration from a central repository, and why don't I have one of those myself? Double oops.)
[ Previously; previouslier ]
[Other articles in category /oops] permanent link
Sat, 13 Nov 2021
I said it was obvious but it was false
In a recent article about Norbert Wiener's construction of ordered pairs, I wrote:
The first thing I thought of was $$\pi_2(p) = \bigcup \{x\in p: |x| = 1\}$$ (“give me the contents of the singleton elements of !!p!!”) but one could also do $$\pi_2(p) = \{x: \{\{x\}\} \in p\},$$ and it's obvious that both of these are correct.
I said “it's obvious that both are correct”, but actually no! The first one certainly seems correct, but when I thought about it more carefully, I realized that the first formula is extremely complex, vastly moreso than the second. That !!|x|!! notation, so intuitive and simple-seeming, is hiding a huge amount of machinery. It denotes the cardinality of the set !!x!!, and cardinality is not part of the base language of set theory. Normally we don't worry about this much, but in this context, where we are trying to operate at the very bottom bare-metal level of set theory, it is important.
To define !!|x|!! requires a lot of theoretical apparatus. First we have to define the class of ordinals. Then we can show that every well-ordered set is order-isomorphic to some ordinal. Zermelo's theorem says that !!x!! has a well-ordering !!W!!, and then !!\langle x, W\rangle!! is order-isomorphic to some ordinal. There might be multiple such ordinals, but Zermelo's theorem guarantees there is at least one, and we can define !!|x|!! to be the smallest such ordinal. Whew! Are we done yet?
We are not. There is still more apparatus hiding in the phrases “well-ordering” and “order-isomorphic”: a well-ordering is certain kind of relation, and an order isomorphism is a certain kind of function. But we haven't defined relations and functions yet, and we can't, because we still don't have ordered pairs! And what is that !!\langle x, W\rangle!! notation supposed to mean anyway? Oh, it's just the… um… whoops.
So the !!|x|=1!! idea is not just inconveniently complex, but circular.
We can get rid of some of the complexity if we restrict the notion to finite sets (that eliminates the need for the full class of ordinals, for the axiom of choice and the full generality of Zermelo's theorem, and we can simplify it even more if we strip down our definition to the minimum requirements, which is that we only need to recognize cardinalities as large as 2.
But if we go that way we may as well dispense with a general notion of cardinality entirely, which is what the second definition does. Even without cardinality, we can still define a predicate which is true if and only if !!x!! is a singleton. That's simply: $$\operatorname{singleton}(x) \equiv_{def} \exists y. x = \{y\}.$$
One might want to restrict the domain of !!y!! here, depending on context.¹
To say that !!x!! has exactly two elements² we proceed analogously: $$\exists y. \exists z. z\ne y \land x = \{y, z\}.$$ And similarly we can define a predicate “has exactly !!n!! elements” for any fixed number !!n!!, even for infinite !!n!!. But a general definition of cardinality at this very early stage is far out of reach.
[ Addendum 20220414: I have no idea what I was thinking of when I said “… even for infinite !!n!!” in the previous paragraph, and I suspect that it is false. ]
¹ This issue is not as complex as it might appear. Although it appears that !!y!! must range over all possible sets, we can sidestep this by restricting our investigation to some particular universe of discourse, which can be any set of sets that we like. The restricted version of !!x\mapsto |x|!! is a true function, an actual set in the universe, rather than a class function.
² There does not seem to be any standard jargon for a set with exactly two elements . As far as I can tell, “doubleton” is not used. “Unordered pair” is not quite right, because the unordered pair !!\{a, a\}!! has only one element, not two.
[Other articles in category /oops] permanent link
Wed, 29 Jul 2020Toph left the cap off one of her fancy art markers and it dried out, so I went to get her a replacement. The marker costs $5.85, plus tax, and the web site wanted a $5.95 shipping fee. Disgusted, I resolved to take my business elsewhere.
On Wednesday I drove over to a local art-supply store to get the marker. After taxes the marker was somehow around $8.50, but I also had to pay $1.90 for parking. So if there was a win there, it was a very small one.
But also, I messed up the parking payment app, which has maybe the worst UI of any phone app I've ever used. The result was a $36 parking ticket.
Lesson learned. I hope.
[Other articles in category /oops] permanent link
Tue, 05 May 2020
Article explodes at the last moment
I wrote a really great blog post over the last couple of days. Last year I posted about the difference between !!\frac10!! and !!\frac00!! and this was going to be a followup. I had a great example from linear regression, where the answer comes out as !!\frac10!! in situations where the slope of computed line is infinite (and you can fix it, by going into projective space and doing everything in homogeneous coordinates), and as !!\frac00!! in situations where the line is completely indeterminite, and you can't fix it, but instead you can just pick any slope you want and proceed from there.
Except no, it never does come out !!\frac10!!. It always comes out !!\frac00!!, even in the situations I said were !!\frac10!!.
I think maybe I can fix it though, I hope, maybe. If so, then I will be able to write a third article.
Maybe.
It could have been worse. I almost published the thing, and only noticed my huge mistake because I was going to tack on an extra section at the end that it didn't really need. When I ran into difficulties with the extra section, I was tempted to go ahead and publish without it.
[Other articles in category /oops] permanent link
Sun, 16 Feb 2020Over on the other blog I said “Midichlorians predated The Phantom Menace.” No, the bacterium was named years after the movie was released.
Thanks to Eyal Joseph Minsky-Fenick and Shreevatsa R. for (almost simultaneously) pointing out this mistake.
[Other articles in category /oops] permanent link
Wed, 08 Jan 2020
Unix bc command and its -l flag
In a recent article about Unix utilities, I wrote:
We need the
-lflag onbcbecause otherwise it stupidly does integer arithmetic.
This is wrong, as was kindly pointed out to me by Luke Shumaker. The
behavior of bc is rather more complicated than I said, and less
stupid. In the application I was discussing, the input was a string
like 0.25+0.37, and it's easy to verify that bc produces the
correct answer even without -l:
$ echo 0.25+0.37 | bc
.62
In bc, each number is
represented internally as !!m·10^{-s}!!, where !!m!! is in base 10 and
!!s!! is called the “scale”, essentially the number of digits after
the decimal point. For addition, subtraction, and multiplication, bc
produces a result with the correct scale for an exact result. For
example, when multiplying two numbers with scales a and b, the
result always has scale a + b, so the operation is performed with
exact precision.
But for division, bc doesn't know what scale it should use for the
result. The result of !!23÷7!! can't
be represented exactly, regardless of the scale used. So how should
bc choose how many digits to retain? It can't retain all of them,
and it doesn't know how many you
will want. The answer is: you tell it, by setting a special variable,
called scale. If you set scale=3 then !!23÷7!! will produce the
result !!3.285!!.
Unfortunately, if you don't set it — this is the stupid part — scale defaults to zero. Then
bc will discard everything after the decimal point, and tell you that
!!23÷7 = 3!!.
Long, long ago I was in the habit of manually entering scale=20 at
the start of every bc session. I eventually learned about -l,
which, among other things, sets the default scale to 20 instead of 0.
And I have used -l habitually ever since, even in cases like this,
where it isn't needed.
Many thanks to Luke Shumaker for pointing this out. M. Shumaker adds:
I think the mis-recollection/understanding of
-lsays something about your "memorized trivia" point, but I'm not quite sure what.
Yeah, same.
[Other articles in category /oops] permanent link
Sat, 25 Aug 2018
A software archaeology screwup
This week I switched from using the konsole terminal program to using gnome-terminal,
because the former gets all sorts of font widths and heights wrong for
high-bit characters like ⇒ and ③, making it very difficult to edit
such text, and the latter, I discovered doesn't. Here's how konsole
displays the text ☆☆★★★ “Good” as I move the cursor rightwards
through it:


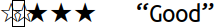
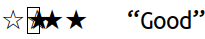
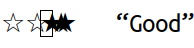




Uggggggh. Why did I put up with this bullshit for so long?
(I know, someone is going to write in and say the problem isn't in konsole,
it's in the settings for the KooKooFont 3.7.1 package, and I can
easily fix this by adding, removing, or adjusting the appropriate
directives in
/usr/share/config/fontk/config/fontulator-compat.d/04-spatulation,
and… I don't care, gnome-terminal works and konsole doesn't.)
So I switched terminals, but this introduced a new problem: konsole would
detect when a shell command had been run, and automatically retitle
the tab it was run in, until the command exited. I didn't realize until this
feature went away how much I had been depending on it to tell the tabs
apart. Under gnome-terminal all the tabs just said Terminal.
Reaching back into my memory, to a time even before there were tabs, I
recalled that there used to be a simple utility I could run on the
command line to set a terminal title. I did remember xsetname,
which sets the X window title, but I didn't want that in this
case. I looked around through the manual and my bin directory and
didn't find it, so I decided to write it fresh.
It's not hard. There's an escape sequence which, if received by the terminal, should cause it to retitle itself. If the terminal receives
ESC ] 0 ; pyrzqxgl \cG
it will change its title to pyrzqxgl. (Spaces in the display above
are for clarity only and should be ignored.)
It didn't take long to write the program:
#!/usr/bin/python3
from sys import argv, stderr
if len(argv) != 2:
print("Usage: title 'new title'", file=stderr)
exit(-2)
print("\033]0;{}\a".format(argv[1]), end="")
The only important part here is the last line. I named the program
title, installed it in ~/bin, and began using it
immediately.
A few minutes later I was looking for the tab that had an SSH session
to the machine plover.com, and since the title was still Terminal,
once I found it, I ran title plover, which worked. Then I stopped
and frowned. I had not yet copied the program to Plover. What just
happened?
Plover already had a ~/bin/title that I wrote no less than
14½ years ago:
-rwxr-xr-x 1 mjd mjd 138 Feb 11 2004 /home/mjd/bin/title
Here it is:
#!/usr/bin/perl
my $title = join " ", @ARGV;
$title = qx{hostname -s || hostname} if $title eq "";
chomp $title;
print "\e]0;$title\cG";
Why didn't I find that before I wrote the other one?
The old program is better-written too. Instead of wasting code to print a usage message if I didn't use it right, I had spent that code in having it do something useful instead.
This is not the first time I have done something like this.
Oh well, at least I can reacquire the better UI now that I know about it.
[ Addendum 20220127: I did it again ]
[Other articles in category /oops] permanent link
Mon, 19 Feb 2018
Composition of utility pole ID tags
In a recent article discussing utility poles, and the metal ID plates they carry, I wondered what the plates were made of:
Steel would rust; and I thought even stainless steel wouldn't last as long as these tags need to. Aluminum is expensive. Tin degrades at low temperatures. … I will go test the tags with a magnet to see if they are ferrous.
They are not ferrous. Probably they are aluminum. My idea that aluminum is too expensive to use for the plates was ridiculous. The pole itself costs a lot of money. The sophisticated electrical equipment on the pole costs thousands of dollars. The insulated wire strung from the pole is made of copper. Compared with all this, a ten-centimeter oval of stamped aluminum is not a big deal.
1.8mm aluminum sheet costs $100 per square meter even if you don't buy it in great quantity. Those aluminum tags probably cost no more than fifty cents each.
[Other articles in category /oops] permanent link
Sat, 20 Jan 2018
I forgot there are party conventions
Yesterday I made a huge mistake in my article about California's bill requiring presidential candidates to disclose their tax returns. I asked:
Did I miss anything?
Yes, yes I did. I forgot that party nominees are picked not by per-state primary elections, but by national conventions. Even had Ronnie won the California Republican primary election, rather than Trump, that would not be enough the get him on the ballot in the general election.
In the corrected version of my scenario, California sends many Ronnie supporters to the Republican National Convention, where the other delegates overwhelmingly nominate Trump anyway. Trump then becomes the Republican party candidate and appears on the California general election ballot in November. Whoops.
I had concluded that conceding California couldn't hurt Trump, and it could actually a huge benefit to him. After correcting my mistake, most of the benefit evaporates.
I wonder if Trump might blow off California in 2020 anyway. The upside would be that he could spend the resources in places that might give him some electoral votes. (One reader pointed out that Trump didn't blow off California in the 2016 election, but of course the situation was completely different. In 2016 he was not the incumbent, he was in a crowded field, and he did not yet know that he was going to lose California by 30%.)
Traditionally, candidates campaign even in states they expect to lose. One reason is to show support for candidates in local elections. I can imagine many California Republican candidates would prefer that Trump didn't show up. Another reason is to preserve at least a pretense that they are representatives of the whole people. Newly-elected Presidents have often upheld the dignity of the office by stating the need for unity after a national election and promising (however implausibly) to work for all Americans. I don't care to write the rest of this paragraph.
The major downside that I can think of (for Trump) is that Republican voters in California would be infuriated, and while they can't directly affect the outcome of the presidential election, they can make it politically impossible for their congressional representatives to work with Trump once he is elected. A California-led anti-Trump bloc in Congress would probably cause huge problems for him.
Wild times we live in.
[Other articles in category /oops] permanent link
Sun, 07 Jan 2018Well, yesterday I wrote an article about the drinking contest in the Gylfaginning and specifically about what was in the horn. I was very pleased with it. In the article, I said several times:
Obviously, the horn was full of mead.
A couple of my Gentle Readers have gently pointed out that I was wrong, wrong, wrong. I am deeply embarrassed.
The punch line of the story is that the end of the horn is attached to the ocean, and Thor cannot empty it, because he is trying to drink the ocean. The horn is therefore not filled with mead; it is filled with seawater.
How could I make such a dumb mistake? As I mentioned, the version I read first as a child stated that the horn was full of milk. And as a child I wondered: how could the horn be full of milk if it was attached to the sea? I decided that whatever enchantment connected the horn to the sea also changed the water to milk as it came into the horn. Later, when I realized that the milk was a falsehood, I retained my idea that there was an enchantment turning the seawater into something else.
But there is nothing in the text to support this. The jötunns don't tell Thor that the horn is full of mead. Adam Sjøgren pointed out that if they had, Thor would have known immediately that something was wrong. But as the story is, they bring the horn, they say that even wimps can empty it in three draughts, and they leave it at that. Wouldn't Thor notice that he is not drinking mead (or milk)? I think certainly, and perhaps he is initially surprised. But he is in a drinking contest and this is what they have brought him to drink, so he drinks it. The alternative is to put down the horn and complain, which would be completely out of character.
And the narrator doesn't say, and mustn't, that the horn was full of mead, because it wasn't; that would be in impermissible deceit of the audience. (“Hey, wait, you told us before that the horn was full of mead!”)
I wrote:
The story does not say what was in the horn. Because why would they bother to say what was in the horn? It was obviously mead.
No, it's not. It's because the narrator wants us to assume it is obviously mead, and then to spring the surprise on us as it was sprung on Thor: it was actually the ocean. The way it is told is a clever piece of misdirection. The two translators I quoted picked up on this, and I completely misunderstood it.
I have mixed feelings about Neil Gaiman, but Veit Heller pointed out that Gaiman understood this perfectly. In his Norse Mythology he tells the story this way:
He raised the brimming horn to his lips and began to drink. The mead of the giants was cold and salty…
In yesterday's article I presented a fantasy of Marion French, the author of my childhood “milk” version, hearing Snorri tell the story:
“Utgarða-Loki called his skutilsveinn, and requested him to bring the penalty-horn that his hirðmen were wont to drink from…”
“Excuse me! Excuse me, Mr. Sturluson! Just what were they wont to drink from it?”
“Eh, what's that?”
”What beverage was in the horn?”
“Why, mead, of course. What did you think it was, milk?”
But this couldn't have been how it went down. I now imagine it was more like this:
“Excuse me! Excuse me, Mr. Sturluson! Just what were they wont to drink from it?”
“Shhh! I'm getting to that! Stop interrupting!”
Thanks again to Adam Sjøgren and Veit Heller for pointing out my error, and especially for not wounding my pride any more than they had to.
[Other articles in category /oops] permanent link
Thu, 02 Nov 2017
I missed an easy solution to a silly problem
A few years back I wrote a couple of articles about the extremely poor macro plugin I wrote for Blosxom. ([1] [2]). The feature-poorness of the macro system is itself the system's principal feature, since it gives the system simple behavior and simple implementation. Sometimes this poverty means I have to use odd workarounds to get it to do what I want, but they are always simple workarounds and it is never hard to figure out why it didn't do what I wanted.
Yesterday, though, I got stuck. I had defined a macro, ->, which
the macro system would replace with →. Fine. But later in the
file I had an HTML comment:
<!-- blah blah -->
and the macro plugin duly transformed this to
<!-- blah blah -→
creating an unterminated comment.
Normally the way I would deal with this would be to change the name of
the macro from -> to something else that did not conflict with HTML
syntax, but I was curiously resistant to this. I could not think of
anything I wanted to use instead. (After a full night's sleep, it
seems to me that => would have been just fine.)
I then tried replacing --> with -->. I didn't expect
this to work, and indeed it didn't. Those &# escapes only work for
text parts of an HTML document, and cannot be used for HTML syntax.
They remove the special meaning of character sequences, which is the opposite
of what I need here.
Eventually, I just deleted the comment and moved on. That worked, although it was obviously suboptimal. I was too tired to think, and I just wanted the problem out of the way. I wish I had been a little less impulsive, because there are at least two other solutions I overlooked:
I could have defined an
END-HTML-COMMENTmacro that expanded to-->and then used it at the end of the comment. The results of macro expansion are never re-expanded, so the resulting-->would not have been subject to further replacement. This is ugly, but would have done the job, and I have used this sort of technique before.Despite its smallness, the macro plugin has had feature creep over the years, and some of these features I put in and then forgot about. (Bad programmer! No cookie!) One of these lost features is the directive
#undefall, which instructs the plugin to forget all the macro definitions. I could have solved the problem by sticking this in just before the broken comment.(The plugin does not (yet) have a selective
#undef. It would be easy to add, but the module has too many features already.)
Yesterday morning I asked my co-workers if there was an alternative HTML comment syntax, or some way to modify the comment ending sequence so that the macro plugin wouldn't spoil it. (I think there isn't, and a short look at the HTML 5.0 standard didn't suggest any workaround.)
One of the co-workers was Tye McQueen. He said that as far as he knew
there was no fix to the HTML comments that was like what I had asked
for. He asked whether I could define a second macro, -->, which
would expand to -->.
I carefully explained why this wouldn't work: when two macro definitions share a prefix, and they both match, the macro system does not make any guarantee about which substitution it will perform. If there are two overlapping macros, say:
#define pert curt
#define per bloods
then the string pertains might turn into curtains (if the first
substitution is performed) or into bloodstains (if the second is).
But you don't know which it will be, and it might be different each
time. I could fix this, but at present I prefer the answer to be
“don't define a macro that is a prefix of another macro.”
Then M. McQueen gently pointed out that -> is not a prefix of -->.
It is a suffix. My objection does not apply, and his suggestion
solves the problem.
When I write an Oops post I try to think about what lesson I can learn from the mistake. This time there isn't too much, but I do have a couple of ideas:
Before giving up on some piece of software I've written, look to see if I foresaw the problem and put in a feature to deal with it. I have a notion that this would work surprisingly often.
There are two ways to deal with the problem of writing software with too many features, and I have worked on this problem for many years from only one direction: try to write fewer features. But I could also come at it from the opposite direction: try to make better use of the features that I do write.
It feels odd that this should seem to me like a novel idea, but there it is.
Try to get more sleep.
(I haven't published an oops article in far too long, and it certainly isn't because I haven't been making mistakes. I will try to keep it in mind.)
[Other articles in category /oops] permanent link
Mon, 13 Feb 2017
How I got three errors into one line of code
At work we had this script that was trying to report how long it had
taken to run, and it was using DateTime::Duration:
my $duration = $end_time->subtract_datetime($start_time);
my ( $hours, $minutes, $seconds ) =
$duration->in_units( 'hours', 'minutes', 'seconds' );
log_info "it took $hours hours $minutes minutes and $seconds seconds to run"
This looks plausible, but because
DateTime::Duration is shit,
it didn't work. Typical output:
it took 0 hours 263 minutes and 19 seconds to run
I could explain to you why it does this, but it's not worth your time.
I got tired of seeing 0 hours 263 minutes show up in my cron email
every morning, so I went to fix it. Here's what I changed it to:
my $duration = $end_time->subtract_datetime_absolute($start_time)->seconds;
my ( $hours, $minutes, $minutes ) = (int(duration/3600), int($duration/60)%60, $duration%3600);
I was at some pains to get that first line right, because getting
DateTime to produce a useful time interval value is a tricky
proposition. I did get the first line right. But the second line is
just simple arithmetic, I have written it several times before, so I
dashed it off, and it contains a syntax error, that duration/3600 is
missing its dollar sign, which caused the cron job to crash the next
day.
A co-worker got there before I did and fixed it for me. While he was
there he also fixed the $hours, $minutes, $minutes that should have
been $hours, $minutes, $seconds.
I came in this morning and looked at the cron mail and it said
it took 4 hours 23 minutes and 1399 seconds to run
so I went back to fix the third error, which is that $duration%3600
should have been $duration%60. The thrice-corrected line has
my ( $hours, $minutes, $seconds ) = (int($duration/3600), int($duration/60)%60, $duration%60);
What can I learn from this? Most obviously, that I should have tested my code before I checked it in. Back in 2013 I wrote:
Usually I like to draw some larger lesson from this sort of thing. … “Just write the tests, fool!”
This was a “just write the tests, fool!” moment if ever there was one. Madame Experience runs an expensive school, but fools will learn in no other.
I am not completely incorrigible. I did at least test the fixed code before I checked that in. The test program looks like this:
sub dur {
my $duration = shift;
my ($hours, $minutes, $seconds ) = (int($duration/3600), int($duration/60)%60, $duration%60);
sprintf "%d:%02d:%02d", $hours, $minutes, $seconds;
}
use Test::More;
is(dur(0), "0:00:00");
is(dur(1), "0:00:01");
is(dur(59), "0:00:59");
is(dur(60), "0:01:00");
is(dur(62), "0:01:02");
is(dur(122), "0:02:02");
is(dur(3599), "0:59:59");
is(dur(3600), "1:00:00");
is(dur(10000), "2:46:40");
done_testing();
It was not necessary to commit the test program, but it was necessary to write it and to run it. By the way, the test program failed the first two times I ran it.
Three errors in one line isn't even a personal worst. In 2012 I posted here about getting four errors into a one-line program.
[ Addendum 20170215: I have some further thoughts on this. ]
[Other articles in category /oops] permanent link
Sat, 01 Mar 2014This week there has been an article floating around about “What happens when placeholder text doesn't get replaced. This reminds me of the time I made this mistake myself.
In 1996 I was programming a web site for a large company which sold cosmetics and skin care products in hundreds of department stores and malls around the country. The technology to actually buy the stuff online wasn't really mature yet, and the web was new enough that the company was worried that selling online would anger the retail channels. They wanted a web page where you would put in your location and it would tell you where the nearby stores were.
The application was simple; it accepted a city and state, looked them
up in an on-disk hash table, and then returned a status code to the
page generator. The status code was for internal use only. For
example, if you didn't fill in the form completely, the program would
return the status code MISSING, which would trigger the templating
engine to build a page with a suitable complaint message.
If the form was filled out correctly, but there was no match in the
database, the program would return a status code that the front end
translated to a suitably apologetic message. The status code I
selected for this was BACKWATER.
Which was all very jolly, until one day there was a program bug and
some user in Podunk, Iowa submitted the form and got back a page with
BACKWATER in giant letters.
Anyone could have seen that coming; I have no excuse.
[Other articles in category /oops] permanent link
Thu, 17 Apr 2008
Is blood a transitive relation?
When you're first teaching high school students about the idea of a
relation, you give examples of the important properties of relations.
Relations can be some, none, or all of reflexive, symmetric,
antisymmetric, or transitive. You start with examples that everyone
is already familiar with, such as the identity relation, which is
reflexive, symmetric, and transitive, and the ≤ relation, which is
antisymmetric and transitive. Other good examples include familial
relations: "sister-in-law of" is symmetric on the set of women, but
not on the larger set of people; "ancestor of" is transitive but not
symmetric.
It might seem at first glance that "is related to" is transitive, but, at least under conventional definitions, it isn't, because my wife is not related to my cousins.
(I was once invited to speak at Haverford College, and, since I have no obvious qualifications in the topic on which I was speaking, I was asked how I had come to be there. I explained that it was because my wife's mother's younger brother's daughter's husband's older brother's wife was the chair of the mathematics department. Remember, it's not what you know, it's who you know.)
I think I had sometimes tried to turn "related to" into a transitive relation by restricting it to "is related to by blood". This rules out the example above of my wife being unrelated to my cousins, because my relationship with my wife is not one of blood. I don't quite remember using "related by blood" as an example of a transitive relation, but I think I might have, because I was quite surprised when I realized that it didn't work. I spent a lot of time that morning going over my counterexample in detail, writing it up in my head, as it were. I was waiting around in Trevose for the mechanic to finish examining my car, and had nothing better to do that morning. If I had had a blog then, I would probably have posted it. But it is a good thing that I didn't, because in spite of all my thought about it, I missed something important.
The example is as follows. A and B have a child, X. (You may suppose that they marry beforehand, and divorce afterward, if your morality requires it.) Similarly, C and D have a child, Z. Then B and C have a child Y. Y is now the half-sibling of both X and Z, and so is unquestionably a blood relative of both, but X and Z are entirely unrelated. They are not even step-siblings.
Well, this is all very well, but the reason I have filed it under oops/, and the reason it's a good thing I didn't post it on my (then nonexistent) blog is that this elaborate counterexample contains a much simpler one: X is the child and hence the blood relative of both A and B, who are not in general related to each other. C, D, Y, and Z are wholly unnecessary.
I wish I had some nice conclusion to draw here, but if there's something I could learn from it I can't think would it might be.
[Other articles in category /oops] permanent link
Sun, 02 Mar 2008[ Note: You are cautioned that this article is in the oops section of my blog, and so you should understand it as a description of a mistake that I have made. ]
For more than a year now my day job has involved work on a large project written entirely in Java. I warned my employers that I didn't have any professional experience in Java, but they hired me anyway. So I had to learn Java. Really learn it, I mean. I hadn't looked at it closely since version 1.2 or so.
Java 1.5 has parametrized types, which they call "generics". These looked pretty good to me at first, and a big improvement on the cruddy 1975-style type system Java had had before. But then I made a shocking discovery: If General is a subtype of Soldier, then List<General> is not a subtype of List<Soldier>.
In particular, you cannot:
List<General> listOfGenerals = ...
List<Soldier> listOfSoldiers = listOfGenerals;
For a couple of weeks I went around muttering to myself about what
idiots the Java people must be. "Geez fuckin' Louise," I said. "The
Hindley-Milner languages have had this right for twenty years. How
hard would it have been for those Java idiots to pick up a damn book
or something?" I was, of course, completely wrong in all respects. The assignment above leads to problems that are obvious if you think about it a bit, and that should have been obvious to me, and would have been, except that I was so busy exulting in my superiority to the entire Java community that I didn't bother to think about it a bit.
You would like to be able to do this:
Soldier someSoldier = ...;
listOfSoldiers.add(someSoldier);
But if you do, you are setting up a type failure:
General someGeneral = listOfGenerals.getLast();
someGeneral.orderAttack(...);
Here listOfSoldiers and listOfGenerals refer to the
same underlying object, so we put a common soldier into that object
back on line 4, and then took it out again on line 5. But line 5 is
expecting it to be a General, and it is not. So we either have a type
failure right there, or else we have a General variable that holds a
a Soldier
object, and then on line 6 a mere private is
allowed to order an attack, causing a run-time type failure. If we're
lucky.The language designers must forbid one of these operations, and the best choice appears to be to forbid the assignment of the List<General> object to the List<Soldier> variable on line 2. The other choices seem clearly much worse.
The canonical Java generics tutorial has an example just like this one, to explain precisely this feature of Java generics. I would have known this, and I would have saved myself two weeks of grumbling, if I had picked up a damn book or something.
Furthermore, my premise was flawed. The H-M languages (SML, Haskell, Miranda, etc.) have not had this right for twenty years. It is easy to get right in the absence of references. But once you add references the problem becomes notoriously difficult, and SML, for example, has gone through several different strategies for dealing with it, as the years passed and more was gradually learned about the problem.
The naive approach for SML is simple. It says that if α is any type, then there is a type ref α, which is the type of a reference that refers to a storage cell that contains a value of type α. So for example ref int is the type of a reference to an int value. There are three functions for manipulating reference types:
ref : α → ref α
! : ref α → α
:= : (ref α * α) → unit
The ref function takes a value and produces a reference to
it, like & in C; if the original value had type α then
the result has type ref α. The ! function takes a reference
of type ref α and dereferences it, returning the value of type α that
it refers to, like * in C. And the := function,
usually written infix, takes a reference and a value, stores the value
into the place that the reference points to, replacing what was there
before, and returns nothing. So for example:
val a = "Kitty cat"; (* a : string *)
val r = ref a; (* r : ref string *)
r := "Puppy dog";
print !r;
This prints Puppy dog. But this next example fails, as you
would hope and expect:
val a = "Kitty cat";
val r = ref a;
r := 37; (* fails *)
because r has type ref string, but 37
has type int, and := requires that the type of
the value on the right match the type referred to by the reference on
the left. That is the obvious, naive approach. What goes wrong, though? The canonical example is:
fun id x = x (* id : α → α *)
val a = ref id; (* a : ref (α → α) *)
fun not true = false
| not false = true ; (* not: bool → bool *)
a := not;
(!a) 13
The key here is that a is a variable of type ref (α → α), that is,
a reference to a cell that can hold a function whose argument is any
type α and whose return value is the same type. Here it holds a
reference to id, which is the identity function.Then we define a logical negation function, not, which has type bool → bool, that is, it takes a boolean argument and returns a boolean result. Since this is a subtype of α → α, we can store this function in the cell referenced by a.
Then we dereference a, recovering the value it points to, which, since the assignment, is the not function. But since a has type ref (α → α), !a has type α → α, and so should be applicable to any value. So the application of !a to the int value 13 passes the type checker, and SML blithely applies the not function to 13.
I've already talked about SML way longer than I planned to, and I won't belabor you further with explanations of the various schemes that were hatched over the years to try to sort this out. Suffice it to say that the problem is still an open research area.
Java, of course, is all references from top to bottom, so this issue obtrudes. The Java people do not know the answer either.
The big error that I made here was to jump to the conclusion that the Java world must be populated with idiots who know nothing about type theory or Haskell or anything else that would have tipped them off to the error I thought they had committed. Probably most of them know nothing about that stuff, but there are a lot of them, and presumably some of them have a clue, and perhaps some of them even know a thing or two that I don't. I said a while back that people who want to become smarter should get in the habit of assuming that everything is more complex than they imagine. Here I assumed the opposite.
As P.J. Plauger once said in a similar circumstance, there is a name for people who are so stupid that they think everyone else is stupid instead.
Maybe I won't be that person next time.
[ Addendum 20201021: [Here's the original post by Plauger](https://groups.google.com/g/comp.std.c/c/aPENvL9wZFw/m/II24s61rOcoJ), in case I want to find it again, or someone else is interested. ]
[Other articles in category /oops] permanent link
Thu, 12 Apr 2007
A security problem in a CGI program: addenda
Shell-less piping in Perl
In my previous article, I said:
Unfortunately, there is no easy way to avoid the shell when running a command that is attached to the parent process via a pipe. Perl provides open "| command arg arg arg...", which is what I used, and which is analogous to [system STRING], involving the shell. But it provides nothing analogous to [system ARGLIST], which avoids the shell. If it did, then I probably would have used it, writing something like this:Several people wrote to point out that, as of Perl 5.8.0, Perl does provide this, with a syntax almost identical to what I proposed:
open M, "|", $MAILER, "-fnobody\@plover.com", $addre;and the whole problem would have been avoided.
open M, "|-", $MAILER, "-fnobody\@plover.com", $addre;
Why didn't I use this? The program was written in late 2002, and Perl
5.8.0 was released in July 2002, so I expect it's just that I wasn't
familiar with the new feature yet. Why didn't I mention it in the
original article? As I said, I just got back from Asia, and I am
still terribly jetlagged.(Jet lag when travelling with a toddler is worse than normal jet lag, because nobody else can get over the jet lag until the toddler does.)
Jeff Weisberg also pointed out that even prior to 5.8.0, you can write:
open(F, "|-") || exec("program", "arg", "arg", "arg");
Why didn't I use this construction? I have run out of excuses.
Perhaps I was jetlagged in 2002 also.
RFC 822
John Berthels wrote to point out that my proposed fix, which rejects all inputs containing spaces, also rejects some RFC822-valid addresses. Someone whose address was actually something like "Mark Dominus"@example.com would be unable to use the web form to subscribe to the mailing list.Quite so. Such addresses are extremely rare, and people who use them are expected to figure out how to subscribe by email, rather than using the web form.
qmail
Nobody has expressed confusion on this point, but I want to expliticly state that, in my opinion, the security problem I described was entirely my fault, and was not due to any deficiency in the qmail mail system, or in its qmail-inject or qmail-queue components.Moreover, since I have previously been paid to give classes at large conferences on how to avoid exactly this sort of problem, I deserve whatever scorn and ridicule comes my way because of this.
Thanks to everyone who wrote in.
[Other articles in category /oops] permanent link
Wed, 11 Apr 2007
A security problem in a CGI program
<sarcasm>No! Who could possibly have predicted such a
thing?</sarcasm>
I was away in Asia, and when I got back I noticed some oddities in my mail logs. Specifically, Yahoo! was rejecting mail.plover.com's outgoing email. In the course of investigating the mail logs, I discovered the reason why: mail.plover.com had been relaying a ton of outgoing spam.
It took me a little while to track down the problem. It was a mailing list subscription form on perl.plover.com:
The form took the input email address and used it to manufacture an email message, requesting that that address be subscribed to the indicated lists:
my $MAILER = '/var/qmail/bin/qmail-inject';
...
for (@lists) {
next unless m|^perl-qotw[\-a-z]*|;
open M, "|$MAILER" or next;
print M "From: nobody\@plover.com\n";
print M "To: $_-subscribe-$addre\@plover.com\n";
print M "\nRequested by $ENV{REMOTE_ADDR} at ", scalar(localtime), "\n";
close M or next;
push @DONE, $_;
}
The message was delivered to the list management software, which
interpreted it as a request to subscribe, and generated an appropriate
confirmation reply. In theory, this doesn't open any new security
holes, because a malicious remote user could also forge an identical
message to the list management software without using the form.The problem is the interpolated $addre variable. The value of this variable is essentially the address from the form. Interpolating user input into a string like this is always fraught with peril. Daniel J. Bernstein has one of the most succinct explanantions of this that I have ever seen:
The essence of user interfaces is parsing: converting an unstructured sequence of commands, in a format usually determined more by psychology than by solid engineering, into structured data.In this case, I interpolated user data without quoting, and suffered the consequences.When another programmer wants to talk to a user interface, he has to quote: convert his structured data into an unstructured sequence of commands that the parser will, he hopes, convert back into the original structured data.
This situation is a recipe for disaster. The parser often has bugs: it fails to handle some inputs according to the documented interface. The quoter often has bugs: it produces outputs that do not have the right meaning. Only on rare joyous occasions does it happen that the parser and the quoter both misinterpret the interface in the same way.
When the original data is controlled by a malicious user, many of these bugs translate into security holes.
The malicious remote user supplied an address of the following form:
into9507@plover.com
Content-Transfer-Encoding: quoted-printable
Content-Type: text/plain
From: Alwin Bestor <Morgan@plover.com>
Subject: Enhance your love life with this medical marvel
bcc: hapless@example.com,recipients@example.com,of@example.net,
spam@example.com,...
Attention fellow males..
If you'd like to have stronger, harder and larger erections,
more power and intense orgasms, increased stamina and
ejaculatory control, and MUCH more,...
.
(Yes, my system was used to send out penis enlargement spam. Oh, the
embarrassment.) The address contained many lines of data, separated by CRNL, and a complete message header. Interpolated into the subscription message, the bcc: line caused the qmail-inject user ineterface program to add all the "bcc" addresses to the outbound recipient list.
Several thoughts occur to me about this.
User interfaces and programmatic interfaces
The problem would probably not have occurred had I used the qmail-queue progam, which provides a programmatic interface, rather than qmail-inject, which provides a user interface. I originally selected qmail-inject for convenience: it automatically generates Date and Message-ID fields, for example. The qmail-queue program does not try to parse the recipient information from the message header; it takes recipient information in an out-of-band channel.
Perl piped open is deficient
Perl's system and exec functions have two modes. One mode looks like this:
system "command arg arg arg...";
If the argument string contains shell metacharacters or certain other
constructions, Perl uses the shell to execute the command; otherwise
it forks and execs the command directly. The shell is the cause of
all sorts of parsing-quoting problems, and is best avoided in programs
like this one. But Perl provides an alternative:
system "command", "arg", "arg", "arg"...;
Here Perl never uses the shell; it always forks and execs the command
directly. Thus, system "cat *" prints the contents of all
the files in the current working directory, but system "cat",
"*" prints only the contents of the file named "*", if
there is one.qmail-inject has an option to take the envelope information from an out-of-band channel: you can supply it in the command-line arguments. I did not use this option in the original program, because I did not want to pass the user input through the Unix shell, which is what Perl's open FH, "| command args..." construction would have required.
Unfortunately, there is no easy way to avoid the shell when running a command that is attached to the parent process via a pipe. Perl provides open "| command arg arg arg...", which is what I used, and which is analogous to the first construction, involving the shell. But it provides nothing analogous to the second construction, which avoids the shell. If it did, then I probably would have used it, writing something like this:
open M, "|", $MAILER, "-fnobody\@plover.com", $addre;
and the whole problem would have been avoided.A better choice would have been to set up the pipe myself and use Perl's exec function to execute qmail-inject, which bypasses the shell. The qmail-inject program would always have received exactly one receipient address argument. In the event of an attack like the one above, it would have tried to send mail to into9507@plover.com^M^JContent-Transfer-Encoding:..., which would simply have bounced.
Why didn't I do this? Pure laziness.
qmail-queue more vulnerable than qmail-inject in this instance
Rather strangely, an partial attack is feasible with qmail-queue, even though it provides a (mostly) non-parsing interface. The addresses to qmail-queue are supplied to it on file descriptor 1 in the form:
Taddress1@example.com^@Taddress2@example.com^@Taddress3@example.com^@...^@
If my program were to talk to qmail-queue instead of to qmail-inject, the program would have
contained code that looked like this:
print QMAIL_QUEUE_ENVELOPE "T$addre\0";
qmail-queue parses only to the extent of dividing up its input at the ^@
characters. But even this little bit of parsing is a problem.
By supplying an appropriately-formed address string, a malicious user
could still have forced my program to send mail to many addresses. But still the recipient addresses would have been out of the content of the message. If the malicious user is unable to affect the content of the message body, the program is not useful for spamming.
But using qmail-queue, my program would have had to generate the To field itself, and so it would have had to insert the user-supplied address into the content of the message. This would have opened the whole can of worms again.
My program attacked specifically
I think some human put real time into attacking this particular program. There are bots that scour the web for email submission forms, and then try to send spam through them. Those bots don't successfully attack this program, because the recipient address is hard-wired. Also, the program refuses to send email unless at least one of the checkboxes is checked, and form-spam bots don't typically check boxes. Someone had to try some experiments to get the input format just so. I have logs of the experiments.A couple of days after the exploit was discovered, a botnet started using it to send spam; 42 different IP addresses sent requests. I fixed the problem last night around 22:30; there were about 320 more requests, and by 09:00 this morning the attempts to send spam stopped.
Perl's "taint" feature would not have prevented this
Perl offers a feature that is designed specifically for detecting and preventing exactly this sort of problem. It tracks which data are possibly under control of a malicious user, and whether they are used in unsafe operations. Unsafe operations include most file and process operations.One of my first thoughts was that I should have enabled the tainting feature to begin with. However, it would not have helped in this case. Although the user-supplied address would have been flagged as "tainted" and so untrustworthy; by extension, the email message string into which it was interpolated would have been tainted. But Perl does not consider writing a tainted string to a pipe to be an "unsafe" operation and so would not have signalled a failure.
The fix
The short-range fix to the problem was simple:
my $addr = param('addr');
$addr =~ s/^\s+//;
$addr =~ s/\s+$//;
...
if ($addr =~ /\s/) {
sleep 45 + rand(45);
print p("Sorry, addresses are not allowed to contain spaces");
fin();
}
Addresses are not allowed to contain whitespace, except leading or
trailing whitespace, which is ignored. Since whitespace inside an
address is unlikely to be an innocent mistake, the program waits
before responding, to slow down the attacker.
Summary
Dammit.[ Addendum 20070412: There is a followup article to this one. ]
[Other articles in category /oops] permanent link
Thu, 05 Apr 2007[ Note: because this article is in the oops section of my blog, I intend that you understand it as a description of a mistake that I have made. ]
Abhijit Menon-Sen wrote to me to ask for advice in finding the smallest triangular number that has at least 500 divisors. (That is, he wants the smallest n such that both n = (k2 + k)/2 for some integer k and also ν(n) ≥ 500, where ν(n) is the number of integers that divide n.) He said in his note that he believed that brute-force search would take too long, and asked how I might trim down the search.
The first thing that occurred to me was that ν is a multiplicative function, which means that ν(ab) = ν(a)ν(b) whenever a and b are relatively prime. Since n and n-1 are relatively prime, we have that ν(n(n-1)) = ν(n)·ν(n-1), and so if T is triangular, it should be easy to calculate ν(T). In particular, either n is even, and ν(T) = ν(n/2)·ν(n-1), or n is odd, and ν(T) = ν(n)·ν((n-1)/2).
So I wrote a program to run through all possible values of n, calculating a table of ν(n), and then the corresponding ν(n(n-1)/2), and then stopping when it found one with sufficiently large ν.
my $N = 1;
my $max = 0;
while (1) {
my $n = $N % 2 ? divisors($N) : divisors($N/2);
my $np1 = $N % 2 ? divisors(($N+1)/2) : divisors($N+1);
if ($n * $np1 > $max) {
$max = $n * $np1;
print "N=$N; T=", $N*($N+1)/2, "; nd()=$max\n";
}
last if $max >= 500;
$N++;
}
There may be some clever way to quickly calculate ν(n) in
general, but I don't know it. But if you have the prime factorization
of n, it's easy: if n =
p1a1p2a2...
then ν(n) = (a1 + 1)(a2
+ 1)... . This is a consequence of the multiplicativity of ν and
the fact that ν(pn) is clearly
n+1. Since I expected that n wouldn't get too big, I
opted to factor n and to calculate ν from the prime
factorization:
my @nd;
sub divisors {
my $n = shift;
return $nd[$n] if $nd[$n];
my @f = factor($n);
my $ND = 1;
my $cur = 0;
my $curct = 0;
while (@f) {
my $next = shift @f;
if ($next != $cur) {
$cur = $next;
$ND *= $curct+1;
$curct = 1;
} else {
$curct++;
}
}
$ND *= $curct+1;
return $ND;
}
Unix comes with a factor program that factors numbers pretty
quickly, so I used that:
sub factor {
my $r = qx{factor $_[0]};
my @f = split /\s+/, $r;
shift @f;
return @f;
}
This found the answer, 76,576,500, in about a minute and a half.
(76,576,500 = 1 + 2 + ... + 12,375, and has 576 factors.) I sent this
off to Abhijit.I was rather pleased with myself, so I went onto IRC to boast about my cleverness. I posed the problem, and rather than torment everyone there with a detailed description of the mathematics, I just said that I had come up with some advice about how to approach the problem that turned out to be good advice.
A few minutes later one of the gentlemen on IRC, who goes by "jeek", (real name T.J. Eckman) asked me if 76,576,500 was the right answer. I said that I thought it was and asked how he'd found it. I was really interested, because I was sure that jeek had no idea that ν was multiplicative or any of that other stuff. Indeed, his answer was that he used the simplest possible brute force search. Here's jeek's program:
$x=1; $y=0;
while(1) {
$y += $x++; $r=0;
for ($z=1; $z<=($y ** .5); $z++) {
if (($y/$z) == int($y/$z)) {
$r++;
if (($y/$z) != ($z)) { $r++; }
}
}
if ($r>499) {print "$y\n";die}
}
(I added whitespace, but changed nothing else.)In this program, the variable $y holds the current triangular number. To calculate ν(y), this program just counts $z from 1 up to √y, incrementing a counter every time it discovers that z is a divisor of y. If the counter exceeds 499, the program prints y and stops. This takes about four and a half minutes.
It takes three times as long, but uses only one-third the code. Beginners may not see this as a win, but it is a huge win. It is a lot easier to reduce run time than it is to reduce code size. A program one-third the size of another is almost always better—a lot better.
In this case, we can trim up some obvious inefficiencies and make the program even smaller. For example, the tests here can be omitted:
if (($y/$z) != ($z)) { $r++; }
It can yield false only if
y is the square of z. But y is triangular, and
triangular numbers are never square. And we can optimize away the
repeated square root in the loop test, and use a cheaper and simpler
$y % $z == 0 divisibility test in place of the complicated one.
while(1) {
$y += $x++; $r=0;
for $z (1 .. sqrt($y)) {
$y % $z == 0 and $r+=2;
}
if ($r>499) {print "$x $y\n";die}
}
The program is now one-fifth the size of mine and runs in 75
seconds. That is, it is now smaller and faster than mine.This shows that jeek's approach was the right one and mine was wrong, wrong, wrong. Simple programs are a lot easier to speed up than complicated ones. And I haven't even consider the cost of the time I wasted writing my complicated program when I could have written Jeek's six-liner that does the same thing.
So! I had to write back to my friend to tell him that my good advice was actually bad advice.
The sawed-off shotgun wins again!
[ Addendum 20070405: Robert Munro pointed out an error in the final version of the program, which I have since corrected. ]
[ Addendum 20070405: I said that triangular numbers are never square, which is manifestly false, since 1 is both, as is 36. I should have remembered this, since some time in the past three years I investigated this exact question and found the answer. But it hardly affects the program. The only way it could cause a failure is if there were a perfect square triangular number with exactly 499 factors; such a number would be erroneously reported as having 500 factors instead. But the program reports a number with 576 factors instead. Conceivably this could actually be a misreported perfect square with only 575 factors, but regardless, the reported number is correct. ]
[ Addendum 20060617: I have written an article about triangular numbers that are also square. ]
[Other articles in category /oops] permanent link
Tue, 12 Dec 2006
ssh-agent
When you do a remote login with ssh, the program needs to use your
secret key to respond to the remote system's challenge. The secret
key is itself kept scrambled on the disk, to protect it from being
stolen, and requires a passphrase to be unscrambled. So the remote
login process prompts you for the passphrase, unscrambles the secret
key from the disk, and then responds to the challenge.
Typing the passphrase every time you want to do a remote login or run a remote process is a nuisance, so the ssh suite comes with a utility program called "ssh-agent". ssh-agent unscrambles the secret key and remembers it; it then provides the key to any process that can contact it through a certain network socket.
The process for login is now:
plover% eval `ssh-agent`
Agent pid 23918
plover% ssh-add
Need passphrase for /home/mjd/.ssh/identity
Enter passphrase for mjd@plover: (supply passphrase here)
plover% ssh remote-system-1
(no input required here)
...
plover% ssh remote-system-2
(no input required here either)
...
The important thing here is that once ssh-agent is started up and
supplied with the passphrase, which need be done only once, ssh itself
can contact the agent through the socket and get the key as many times
as needed.How does ssh know where to contact the agent process? ssh-agent prints an output something like this one:
SSH_AUTH_SOCK=/tmp/ssh-GdT23917/agent.23917; export SSH_AUTH_SOCK;
SSH_AGENT_PID=23918; export SSH_AGENT_PID;
echo Agent pid 23918;
The eval `...` command tells the shell to execute this output
as code; this installs two variables into the shell's environment,
whence they are inherited by programs run from the shell, such as ssh.
When ssh runs, it looks for the SSH_AUTH_SOCK variable. Finding it, it
connects to the specified socket, in
/tmp/ssh-GdT23917/agent.23917, and asks the agent for the
required private key.Now, suppose I log in to my home machine, say from work. The new login shell does not have any environment settings pertaining to ssh-agent. I can, of course, run a new agent for the new login shell. But there is probably an agent process running somewhere on the machine already. If I run another every time I log in, the agent processes will proliferate. Also, running a new agent requires that the new agent be supplied with the private key, which would require that I type the passphrase, which is long.
Clearly, it would be more convenient if I could tell the new shell to contact the existing agent, which is already running. I can write a command which finds an existing agent and manufactures the appropriate environment settings for contacting that agent. Or, if it fails to find an already-running agent, it can just run a new one, just as if ssh-agent had been invoked directly. The program is called ssh-findagent.
I put a surprising amount of work into this program. My first idea was that it can look through /tmp for the sockets. For each socket, it can try to connect to the socket; if it fails, the agent that used to be listening on the other end is dead, and ssh-findagent should try a different socket. If none of the sockets are live, ssh-findagent should run the real ssh-agent. But if there is an agent listening on the other end, ssh-findagent can print out the appropriate environment settings. The socket's filename has the form /tmp/ssh-XXXPID/agent.PID; this is the appropriate value for the SSH_AUTH_SOCK variable.
The SSH_AGENT_PID variable turned out to be harder. I thought I would just get it from the SSH_AUTH_SOCK value with a pattern match. Wrong. The PID in the SSH_AUTH_SOCK value and in the filename is not actually the pid of the agent process. It is the pid of the parent of the agent process, which is typically, but not always, 1 less than the true pid. There is no reliable way to calculate the agent's pid from the SSH_AUTH_SOCK filename. (The mismatch seems unavoidable to me, and the reasons why seem interesting, but I think I'll save them for another blog article.)
After that I had the idea of having ssh-findagent scan the process table looking for agents. But this has exactly the reverse problem: You can find the agent processes in the process table, but you can't find out which socket files they are attached to.
My next thought was that maybe linux supports the getpeerpid system call, which takes an open file descriptor and returns the pid of the peer process on other end of the descriptor. Maybe it does, but probably not, because support for this system call is very rare, considering that I just made it up. And anyway, even if it were supported, it would be highly nonportable.
I had a brief hope that from a pid P, I could have ssh-findagent look in /proc/P/fd/* and examine the process file descriptor table for useful information about which process held open which file. Nope. The information is there, but it is not useful. Here is a listing of /proc/31656/fd, where process 31656 is an agent process:
lrwx------ 1 mjd users 64 Dec 12 23:34 3 -> socket:[711505562]
File descriptors 0, 1, and 2 are missing. This is to be expected; it
means that the agent process has closed stdin, stdout, and stderr.
All that remains is descriptor 3, clearly connected to the socket.
Which file represents the socket in the filesystem? No telling. All
we have here is 711595562, which is an index into some table of
sockets inside the kernel. The kernel probably doesn't know the
filename either. Filenames appear in directories, where they are
associated with file ID numbers (called "i-numbers" in Unix jargon.)
The file ID numbers can be looked up in the kernel "inode" table to
find out what kind of files they are, and, in this case, what socket
the file represents. So the kernel can follow the pointers from the
filesystem to the inode table to the open socket table, or from the
process's open file table to the open socket table, but not from the
process to the filesystem.Not easily, anyway; there is a program called lsof which grovels over the kernel data structures and can associate a process with the names of the files it has open, or a filename with the ID numbers of the processes that have it open. My last attempt at getting ssh-findagent to work was to have it run lsof over the possible socket files, getting a listing of all processes that had any of the socket files open, and, for each process, which file. When it found a process-file pair in the output of lsof, it could emit the appropriate environment settings.
The final code was quite simple, since lsof did all the heavy lifting. Here it is:
#!/usr/bin/perl
open LSOF, "lsof /tmp/ssh-*/agent.* |"
or die "couldn't run lsof: $!\n";
<LSOF>; # discard header
my $line = <LSOF>;
if ($line) {
my ($pid, $file) = (split /\s+/, $line)[1,-1];
print "SSH_AUTH_SOCK=$file; export SSH_AUTH_SOCK;
SSH_AGENT_PID=$pid; export SSH_AGENT_PID;
echo Agent pid $pid;
";
exit 0;
} else {
print "echo starting new agent\n";
exec "ssh-agent";
die "Couldn't run new ssh-agent: $!\n";
}
I complained about the mismatch between the agent's pid and the pid in
the socket filename on IRC, and someone there mentioned offhandedly
how they solve the same problem. It's hard to figure out what the settings should be. So instead of trying to figure them out, one should save them to a file when they're first generated, then load them from the file as required.
Oh, yeah. A file. Duh.
It looks like this: Instead of loading the environment settings from ssh-agent directly into the shell, with eval `ssh-agent`, you should save the settings into a file:
plover% ssh-agent > ~/.ssh/agent-env
Then tell the shell to load the
settings from the file:
plover% . ~/.ssh/agent-env
Agent pid 23918
plover% ssh remote-system-1
(no input required here)
The . command reads the file and acquires the settings. And
whenever I start a fresh login shell, it has no settings, but I can
easily acquire them again with . ~/.ssh/agent-env,
without running another agent process.
I wonder why I didn't think of this before I started screwing around
with sockets and getpeerpid and /proc/*/fd and
lsof and all that rigmarole.Oh well, I'm not yet a perfect sage.
[ Addendum 20070105: I have revisited this subject and the reader's responses. ]
[Other articles in category /oops] permanent link
Thu, 30 Nov 2006
Trivial calculations
Back in September, I wrote about how I
tend to plunge ahead with straightforward calculations whenever
possible, grinding through the algebra, ignoring the clever shortcut.
I'll go back and look for the shortcut, but only if the
hog-slaughtering approach doesn't get me what I want. This is often
an advantage in computer programming, and often a disadvantage in
mathematics.
This occasionally puts me in the position of feeling like a complete ass, because I will grind through some big calculation to reach a simple answer which, in hindsight, is completely obvious.
One early instance of this that I remember occurred more than twenty years ago when a friend of mine asked me how many spins of a slot machine would be required before you could expect to hit the jackpot; assume that the machine has three wheels, each of which displays one of twenty symbols, so the chance of hitting the jackpot on any particular spin is 1/8,000. The easy argument goes like this: since the expected number of jackpots per spin is 1/8,000, and expectations are additive, 8,000 spins are required to get the expected number of jackpots to 1, and this is in fact the answer.
But as a young teenager, I did the calculation the long way. The chance of getting a jackpot in one spin is 1/8000. The chance of getting one in exactly two spins is (1 - 1/8000)·(1/8000). The chance of getting one in exactly three spins is (1 - 1/8000)2·(1/8000). And so on; so you sum the infinite series:
$$\sum_{i=1}^\infty {i{\left({k-1\over k}\right)^{i-1}} {1\over k}}$$
And if you do it right, you do indeed get exactly k. Well, I was young, and I didn't know any better.I'd like to be able say I never forgot this. I wish it were true. I did remember it a lot of the time. But I can think of a couple of times when I forgot, and then felt like an ass when I did the problem the long way.
One time was in 1996. There is a statistic in baseball called the on-base percentage or "OBP"—please don't all go to sleep at once. This statistic measures, for each player, the fraction of his plate appearances in which he is safe on base, typically by getting a hit, or by being walked. It is typically around 1/3; exceptional players have an OBP as high as 2/5 or even higher. You can also talk about the OBP of a team as a whole.
A high OBP is a very important determiner of the number of runs a baseball team will score, and therefore of how many games it will win. Players with a higher OBP are more likely to reach base, and when a batter reaches base, another batter comes to the plate. Teams with a high overall OBP therefore tend to bring more batters to the plate and so have more chances to score runs, and so do tend to score runs, than teams with a low overall OBP.
I wanted to calculate the relationship between team OBP and the expected number of batters coming to the plate each inning. I made the simplifying assumption that every batter on the team had an OBP of p, and calculated the expected number of batters per inning. After a lot of algebra, I had the answer: 3/(1-p). Which makes perfect sense: There are only two possible outcomes for a batter in each plate appearance: he can reach base, or he can be put out; these are exclusive. A batter who reaches base p of the time is put out 1-p of the time, consuming, on average, 1-p of an out. A team gets three outs in an inning; the three outs are therefore consumed after 3/(1-p) batters. Duh.
This isn't the only baseball-related mistake I've made. I once took a whole season's statistics and wrote a program to calculate the average number of innings each pitcher pitched. Okay, no problem yet. But then I realized that the average was being depressed by short relievers; I really wanted the average only for starting pitchers. But how to distinguish starting pitchers from relievers? Simple: the statistics record the number of starts for each pitcher, and relievers never start games. But then I got too clever. I decided to weight each pitcher's contribution to the average by his number of starts. Since relievers never start, this ignores relievers; it allows pitchers who do start a lot of games to influence the result more than those who only pitched a few times. I reworked the program to calculate the average number of innings pitched per start.
The answer was 9. (Not exactly, but very close.)
It was obviously 9. There was no other possible answer. There is exactly one start per game, and there are 9 innings per game,1 and some pitcher pitches in every inning, so the number of innings pitched per start is 9. Duh.
Anyway, the real point of this article is to describe a more sophisticated mistake of the same general sort that I made a couple of weeks ago. I was tinkering around with a problem in pharmacology. Suppose Joe has some snakeoleum pills, and is supposed to take one capsule every day. He would like to increase the dosage to 1.5 pills every day, but he cannot divide the capsules. On what schedule should he take the pills to get an effect as close as possible to the effect of 1.5 pills daily?
I assumed that we could model the amount of snakeoleum in Joe's body as a function f(t), which normally decayed exponentially, following f(t) = ae-kt for some constant k that expresses the rate at which Joe's body metabolizes and excretes the snakeoleum. Every so often, Joe takes a pill, and at these times d0, d1, etc., the function f is discontinuous, jumping up by 1. The value a here is the amount of snakeoleum in Joe's body at time t=0. If Joe takes one pill every day, the (maximum) amount of snakeoleum in his body will tend toward 1/(1-e-k) over time, as in the graph below:
I wanted to compare this with what happens when Joe takes the pill on various other schedules. For some reason I decided it would be a good idea to add up the total amount of pill-minutes for a particular dosage schedule, by integrating f. That is, I was calculating !!\int_a^b f(t) dt!! for various a and b; for want of better values, I calculated the total amount !!\int_0^\infty f(t) dt!!.
Doing this for the case in which Joe takes a single pill at time 0 is simple; it's just !!\int_0^\infty e^{-kt} dt!!, which is simply 1/k.
But then I wanted to calculate what happens when Joe takes a second pill, say at time M. At time M, the amount of snakeoleum left in Joe's body from the first pill is e-kM, so the function f has f(t) = e-kt for 0 ≤ t ≤ M and f(t) = (e-kM+1)e-k(t-M) for M ≤ t < ∞. The graph looks like this:
$$\halign{ \hfil$#$ & $= # \hfil $ & $+ #\hfil$ \cr \int_0^\infty f(t) dt & \int_0^M f(t) dt & \int_M^\infty f(t) dt \cr & \int_0^M e^{-kt} dt & \int_M^\infty (e^{-kM} + 1)e^{-k(t-M)} dt \cr & {1 \over k }(1-e^{-kM}) & {1\over k}(e^{-kM} + 1)\cr & \ldots & \omit \cr }$$.
Well, you get the idea. The answer was 2/k.In retrospect, this is completely obvious.
This is because of the way I modeled the pills. When the decay of f(t) is exponential, as it is here, that means that the rate at which the snakeoleum is metabolized is proportional to the amount: twice as much snakeoleum means that the decay is twice as fast. or, looked at another way, each pill decays independently of the rest. Put two pills in, and an hour later you'll find that you have twice as much left as if you had only put one pill in.
Since the two pills are acting independently, you can calculate their effect independently. That is, f(t) can be decomposed into f1(t) + f2(t), where f1 is the contribution from the first pill:
Anyway, I think what I really want is to find !!\int_0^\infty {\left(f_1(t) - f_{1.5}(t, d)\right)}^2 dt!!, where f1 is the function that describes the amount of snakeoleum when Joe takes one pill a day, and f1.5 is the function that describes the amount when Joe takes 1.5 pills every d days. But if there's one thing I think you should learn from a dumbass mistake like this, it's that it's time to step back and try to consider the larger picture for a while, so I've decided to do that before I go on.
1[ Addendum 20070124: There is a brief explanation of why the average baseball game has almost exactly 9 innings. ]
[Other articles in category /oops] permanent link
Thu, 13 Jul 2006
Someone else's mistake
I don't always screw up, and here's a story about mistake I
could have made, but didn't.
Long ago, I was fresh out of college, looking for work. I got a lead on what sounded like a really excellent programming job, working for a team at University of Maryland that was preparing a scientific experiment that would be sent up into space in the Space Shuttle. That's the kind of work you dream about at twenty-one.
I went down for an interview, and met the folks working on the project. All except for the principal investigator, who was out of town.
The folks there were very friendly and helpful, and answered all my questions, except for two. I asked each person I met what the experiment was about, and what my programs would need to do. And none of them could tell me. They kept saying what a shame it was that the principal investigator was out of town, since he would have been able to explain it all to my satisfaction. After I got that answer a few times, I started to get nervous.
I'm sure it wasn't quite that simple at the time. I imagine, for example, that there was someone there who didn't really understand what was going on, but was willing to explain it to me anyway. I think they probably showed me some other stuff they were working on, impressed me with a tour of the lab, and so on. But at the end of the day, I knew that I still didn't know what they were doing or what they wanted me to do for them.
If that happened to me today, I would probably just say to them at 5PM that their project was doomed and that I wouldn't touch it with a ten-foot pole. At the time, I didn't have enough experience to be sure. Maybe what they were saying was true, maybe it really wasn't a problem that nobody seemed to have a clue as to what was going on? Maybe it was just me that was clueless? I had never seen anything like the situation there, and I wasn't sure what to think.
I didn't have the nerve to turn the job down. At twenty-one, just having gotten out of school, with no other prospects at the time, I didn't have enough confidence to be quite sure to throw away this opportunity. But I felt in my guts that something was wrong, and I never got back to them about the job.
A few years afterward I ran into one of those guys again, and asked him what had become of the project. And sure enough, it had been a failure. They had missed the deadline for the shuttle launch, and the shuttle had gone up with a box of lead in it where their experiment was supposed to have been.
Looking back on it with a lot more experience, I know that my instincts were right on, even though I wasn't sure at the time. Even at twenty-one, I could recognize the smell of disaster.
[Other articles in category /oops] permanent link
Sun, 09 Apr 2006
Convenience foods
Today I bought a box of Kraft "Deluxe" Macaroni and Cheese Dinner. I
also bought a box of San Giorgio rotini and a half pound of cheap
cheddar cheese. The Kraft kit contains 12 ounces of low-quality elbow
macaroni and a foil pouch continaing two ounces of nasty cheese
sauce.
The cheddar cheese cost $1.69 per half pound. The rotini cost $1.39 for one pound. Scaling these values to the amounts in the Kraft kit, we get $.42 for cheese plus $1.05 for pasta, totalling $1.47. The Kraft kit, however, cost $2.79.
What did my $1.32 get me? Certainly not better quality; the cheese substance in the Kraft kit is considerably lower quality than even low-quality cheese. I could substitute high-quality Vermont cheddar for only about $.80 extra.
Did I get a time or convenience win? The Kraft instructions are: boil two quarts of water, add pasta, stir, cook for eight to ten minutes, drain, return to pot, add cheese sauce, stir again. To make macaroni and cheese "from scratch" requires only one extra step: grate or cube the cheese. The time savings for the kit is minimal. If Kraft were going to charge me a 90% premium for thirty-second ready-to-eat microwave mac-and-cheese, I might consider it a good deal. As it is, my primary conclusion is that I was suckered.
Secondary conclusion: Fool me once, shame on you. Fool me twice, shame on me.
[Other articles in category /oops] permanent link
Thu, 30 Mar 2006
Blog Posts Escape from Lab
Yesterday I decided to put my blog posts into CVS. As part of doing
that, I copied the blog articles tree. I must have made a mistake,
because not all the files were copied in the way I wanted.
To prevent unfinished articles from getting out before they are ready, I have a Blosxom plugin that suppresses any article whose name is title.blog if it is accompanied by a title.notyet file. I can put the draft of an article in the .notyet file and then move it to .blog when it's ready to appear, or I can put the draft in .blog with an empty or symbolic-link .notyet alongside it, and then remove the .notyet file when the article is ready.
I also use this for articles that will never be ready. For example, a while back I got the idea that it might be funny if I were to poſt ſome articles with long medial letter 'ſ' as one ſees in Baroque printing and writing. To try out what this would look like I copied one of my articles---the one on Baroque writing ſtyle ſeemed appropriate---and changed the filename from baroque-style.blog to baroque-ftyle.blog. Then I created baroque-ftyle.notyet ſo that nobody would ever ſee my ſtrange experiment.
But somehow in the big shakeup last night, some of the notyet files got lost, and so this post and one other escaped from my laboratory into the outside world. As I explained in an earlier post, I can remove these from my web site, but aggregators like Bloglines.com will continue to display my error. it's tempting to blame this on Blosxom, or on CVS, or on the sysadmin, or something like that, but I think the most likely explanation for this one is that I screwed up all by myself.
The other escapee was an article about the optional second argument in Perl's built-in bless function, which in practice is never omitted. This article was so dull that I abandoned it in the middle, and instead addressed the issue in passing in an article on a different subject.
So if your aggregator is displaying an unfinished and boring article about one-argument bless, or a puzzling article that seems like a repeat of an earlier one, but with all the s's replaced with ſ's, that is why.
These errors might be interesting as meta-information about how I work. I had hoped not to discuss any such meta-issues here, but circumstances seem to have forced me to do it at least a little. One thing I think might be interesting is what my draft articles look like. Some people rough out an article first, then go back and fix it it. I don't do that. I write one paragraph, and then when it's ready, I write another paragraph. My rough drafts look almost the same as my finished product, right up to the point at which they stop abruptly, sometimes in the middle of a sentence.
Another thing you might infer from these errors is that I have a lot of junk sitting around that is probably never going to be used for anything. Since I started the blog, I've written about 85,000 words of articles that were released, and about 20,000 words of .notyet. Some of the .notyet stuff will eventually see the light of day, of course. For example, I have about 2500 words of addenda to this month's posts that are scheduled for release tomorrow, 1000 words about this month's Google queries and the nature of "authority" on the Web, 1000 words about the structure of the real numbers, 1300 words about the Grelling-Nelson paradox, and so on.
But I alſo have that 1100-word experiment about what happens to an article when you use long medial s's everywhere. (Can you believe I actually conſidered doing this in every one of my poſts? It's tempting, but just a little too idioſyncratic, even for me.) I have 500 words about why to attend a colloquium, how to convince everyone there that you're a genius, and what's wrong with education in general. I have 350 words that were at the front of my article about the 20 most important tools that explained in detail why most criticism of Forbes' list would be unfair; it wasted a whole page at the beginning of that article, so I chopped it out, but I couldn't bear to throw it away. I have two thirds of a 3000-word article written about why my brain is so unusual and how I've coped with its peculiar limitations. That one won't come out unless I can convince myself that anyone else will find it more than about ten percent as interesting as I find it.
[Other articles in category /oops] permanent link
Mon, 20 Mar 2006
Blosxom sucks
Several people were upset at my recent
discussion of Blosxom. Specifically, I said that it sucked.
Strange to say, I meant this primarily as a compliment. I am going to
explain myself here.
Before I start, I want to set your expectations appropriately. Bill James tells a story about how he answered the question "What is Sparky Anderson's strongest point as a [baseball team] manager?" with "His won-lost record". James was surprised to discover that when people read this with the preconceived idea that he disliked Anderson's management, they took "his record" as a disparagement, when he meant it as a compliment.
I hope that doesn't happen here. This article is a long compliment to Blosxom. It contains no disparagement of Blosxom whatsoever. I have technical criticisms of Blosxom; I left them out of this article to avoid confusion. So if I seem at any point to be saying something negative about Blosxom, please read it again, because that's not the way I meant it.
As I said in the original article, I made some effort to seek out the smallest, simplest, lightest-weight blogging software I could. I found Blosxom. It far surpassed my expectations. The manual is about three pages long. It was completely trivial to set up. Before I started looking, I hypothesized that someone must have written blog software where all you do is drop a text file in a directory somewhere and it magically shows up on the blog. That was exactly what Blosxom turned out to be. When I said it was a smashing success, I was not being sarcastic. It was a smashing success.
The success doesn't end there. As I anticipated, I wasn't satisfied for long with Blosxom's basic feature set. Its plugin interface let me add several features without tinkering with the base code. Most of these have to do with generating a staging area where I could view posts before they were generally available to the rest of the world. The first of these simply suppressed all articles whose filenames contained test. This required about six lines of code, and took about fifteen minutes to implement, most of which was time spent reading the plugin manual. My instance of Blosxom is now running nine plugins, of which I wrote eight; the ninth generates the atom-format syndication file.
The success of Blosxom continued. As I anticipated, I eventually reached a point at which the plugin interface was insufficient for what I wanted, and I had to start hacking on the base code. The base code is under 300 lines. Hacking on something that small is easy and rewarding.
I fully expect that the success of Blosxom will continue. Back in January, when I set it up, I foresaw that I would start with the basic features, that later I would need to write some plugins, and still later I would need to start hacking on the core. I also foresaw that the next stage would be that I would need to throw the whole thing away and rewrite it from scratch to work the way I wanted to. I'm almost at that final stage. And when I get there, I won't have to throw away my plugins. Blosxom is so small and simple that I'll be able to write a Blosxom-compatible replacement for Blosxom. Even in death, the glory of Blosxom will live on.
So what did I mean by saying that Blosxom sucks? I will explain.
Following Richard Gabriel, I think there are essentially two ways to do a software design:
- You can try to do the Right Thing, where the Right Thing is very complex, subtle, and feature-complete.
- You can take the "Worse-is-Better" approach, and try to cover most of the main features, more or less, while keeping the implementation as simple as possible.
Worse, because the Right Thing is very difficult to achieve, and very complex and subtle, it is rarely achieved. Instead, you get a complex and subtle system that is complexly and subtly screwed up. Often, the designer shoots for something complex, subtle, and correct, and instead ends up with a big pile of crap. I could cite examples here, but I think I've offended enough people for one day.
In contrast, with the "Worse-is-Better" approach, you do not try to do the Right Thing. You try to do the Good Enough Thing. You bang out something short and simple that seems like it might do the job, run it up the flagpole, and see if it flies. If not, you bang on it some more.
Whereas the Right Thing approach is hard to get correct, the Worse-is-Better approach is impossible to get correct. But it is very often a win, because it is much easier to achieve "good enough" than it is to achieve the Right Thing. You expend less effort in doing so, and the resulting system is often simple and easy to manage.
If you screw up with the Worse-is-Better approach, the end user might be able to fix the problem, because the system you have built is small and simple. It is hard to screw it up so badly that you end with nothing but a pile of crap. But even if you do, it will be a much smaller pile of crap than if you had tried to construct the Right Thing. I would very much prefer to clean up a small pile of crap than a big one.
Richard Gabriel isn't sure whether Worse-is-Better is better or worse than The Right Thing. As a philosophical question, I'm not sure either. But when I write software, I nearly always go for Worse is Better, for the usual reasons, which you might infer from the preceding discussion. And when I go looking for other people's software, I look for Worse is Better, because so very few people can carry out the Right Thing, and when they try, they usually end up with a big pile of crap.
When I went looking for blog software back in January, I was conscious that I was looking for the Worse-is-Better software to an even greater degree than usual. In addition to all the reasons I have given above, I was acutely conscious of the fact that I didn't really know what I wanted the software to do. And if you don't know what you want, the Right Thing is the Wrong Thing, because you are not going to understand why it is the Right Thing. You need some experience to see the point of all the complexity and subtlety of the Right Thing, and that was experience I knew I did not have. If you are as ignorant as I was, your best bet is to get some experience with the simplest possible thing, and re-evaluate your requirements later on.
When I found Blosxom, I was delighted, because it seemed clear to me that it was Worse-is-Better through and through. And my experience has confirmed that. Blosxom is a triumph of Worse-is-Better. I think it could serve as a textbook example.
Here is an example of a way in which Blosxom subscribes to the Worse-is-Better philosophy. A program that handles plugins seems to need some way to let the plugins negotiate amongst themselves about which ones will run and in what order. Consider Blosxom's filter callback. What if one plugin wants to force Blosxom to run its filter callback before the other plugins'? What if one plugin wants to stop all the subsequent plugins from applying their filters? What if one plugin filters out an article, but a later plugin wants to rescue it from the trash heap? All these are interesting and complex questions. The Apache module interface is an interesting and complex answer to some of these questions, an attempt to do The Right Thing. (A largely successful attempt, I should add.)
Faced with these interesting and complex questions, Blosxom sticks its head in the sand, and I say that without any intent to disparage Blosxom. The Blosxom answer is:
- Plugins run in alphabetic order.
- Each one gets its crack at a data structure that contains the articles.
- When all the plugins have run, Blosxom displays whatever's left in the data structure.
So Blosxom is a masterpiece of Worse-is-Better. I am a Worse-is-Better kind of guy anyway, and Worse-is-Better was exactly what I was looking for in this case, so I was very pleased with Blosxom, and I still am. I got more and better Worse-is-Better for my software dollar than usual.
When I stuck a "BLOSXOM SUX" icon on my blog pages, I was trying to express (in 80×15 pixels) my evaluation of Blosxom as a tremendously successful Worse-is-Better design. Because it might be the Wrong Thing instead of the Right Thing, but it was the Right Wrong Thing, and I'd sure rather have the Right Wrong Thing than the Wrong Right Thing.
And when I said that "Blosxom really sucks... in the best possible way", that's what I meant. In a world full of bloated, grossly over-featurized software that still doesn't do quite what you want, Blosxom is a spectacular counterexample. It's a slim, compact piece of software that doesn't do quite what you want---but because it is slim and compact, you can scratch your head over it for couple of minutes, take out the hammer and tongs, and get it adjusted the way you want.
Thanks, Rael. I think you did a hell of a job. I am truly sorry that was not clear from my earlier article.
[Other articles in category /oops] permanent link
Sat, 18 Mar 2006
Who farted?
The software that generates these web pages from my blog entries is Blosxom. When I decided I wanted
to try blogging, I did a web search for something like "simplest
possible blogging software", and found a page that discussed Bryar.
So I located the Bryar manual. The first sentence in the Bryar manual
says "Bryar is a piece of blog production software, similar in style
to (but considerably more complex than) Rael Dornfest's
blosxom." So I dropped Bryar and got Blosxom. This was a
smashing success: It was running within ten minutes. Now, two months
later, I'm thinking about moving everything to Bryar, because Blosxom
really sucks. .
But for me it was a huge success, and I probably wouldn't have started
a blog if I hadn't found it. It sucks in the best possible way:
because it's drastically under-designed and excessively lightweight.
That is much better than sucking because it is drastically
over-designed and excessively heavyweight. It also sucks in some
less ambivalent ways, but I'm not here (today) to criticize Blosxom,
so let's move on.
Until the big move to Bryar, I've been writing plugins for Blosxom. When I was shopping for blog software, one of my requirements that that the thing be small and simple enough to be hackable, since I was sure I would inevitably want to do something that couldn't be accomplished any other way. With Blosxom, that happened a lot sooner than it should have (the plugin interface is inadequate), but the fallback position of hacking the base code worked quite well, because it is fairly small and fairly simple.
Most recently, I had to hack the Blosxom core to get the menu you can see on the left side of the page, with the titles of the recent posts. This should have been possible with a plugin. You need a callback (story) in the plugin that is invoked once per article, to accumulate a list of title-URL pairs, and then you need another callback (stories_done) that is invoked once after all the articles have been scanned, to generate the menu and set up a template variable for insertion into the template. Then, when Blosxom fills the template, it can insert the menu that was set up by the plugin.
With stock Blosxom, however, this is impossible. The first problem you encounter is that there is no stories_done callback. This is only a minor problem, because you can just have a global variable that holds the complete menu so far at all times; each time story is invoked, it can throw away the incomplete menu that it generated last time and replace it with a revised version. After the final call to story, the complete menu really is complete:
sub story {
my ($pkg, $path, $filename, $story_ref, $title_ref, $body_ref,
$dir, $date) = @_;
return unless $dir eq "" && $date eq "";
return unless $blosxom::flavour eq "html";
my $link = qq{<a href="$blosxom::url$path/$filename.$blosxom::flavour">} .
qq{<span class=menuitem>$$title_ref</span></a>};
push @menu, $link;
$menu = join " / ", @menu;
}
That strategy is wasteful of CPU time, but not enough to notice. You
could also fix it by hacking the base code to add a
stories_done callback, but that strategy is wasteful of
programmer time.But it turns out that this doesn't work, and I don't think there is a reasonable way to get what I wanted without hacking the base code. (Blosxom being what it is, hacking the base code is a reasonable solution.) This is because of a really bad architecture decision inside of Blosxom. The page is made up of three independent components, called the "head", the "body", and the "foot". There are separate templates of each of these. And when Blosxom generates a page, it does so in this sequence:
- Fill "head" template and append result to output
- Process articles
- Fill "body" template and append result to output
- Fill "foot" template and append result to output
So I had to go in and hack the Blosxom core to make it fractionally less spiky:
- Process articles
- Fill "head" template and append result to output
- Fill "body" template and append result to output
- Fill "foot" template and append result to output
- Process articles
- Fill and output templates:
- Fill "head" template and append result to output
- Fill "body" template and append result to output
- Fill "foot" template and append result to output
#include head
#include body
#include foot
But if I were to finish the article with that discussion, then
the first half of the article would have been relevant and to the
point, and as regular readers know, We Don't Do That Here. No, there
must come a point about a third of the way through each article at
which I say "But anyway, the real point of this note is...".Anyway, the real point of this note is to discuss was the debugging technique I used to fix Blosxom after I made this core change, which broke the output. The menu was showing up where I wanted, but now all the date headers (like the "Sat, 18 Mar 2006" one just above) appeared at the very top of the page body, before all the articles.
The way Blosxom generates output is by appending it to a variable $output, which eventually accumulates all the output, and is printed once, right at the very end. I had found the code that generated the "head" part of the output; this code ended with $output .= $head to append the head part to the complete output. I moved this section down, past the (much more complicated) section that scanned the articles themselves, so that the "head" template, when filled, would have access to information (such as menus) accumulated while scanning the articles.
But apparently some other part of the program was inserting the date headers into the output while scanning the articles. I had to find this. The right thing to do would have been just to search the code for $output. This was not sure to work: there might have been dozens of appearances of $output, making it a difficult task to determine which one was the responsible appearance. Also, any of the plugins, not all of which were written by me, could have been modifying $output, so it would not have been enough just to search the base code.
Still, I should have started by searching for $output, under the look-under-the-lamppost principle. (If you lose your wallet in a dark street start by looking under the lamppost. The wallet might not be there, but you will not waste much time on the search.) If I had looked under the lamppost, I would have found the lost wallet:
$curdate ne $date and $curdate = $date and $output .= $date;
That's not what I did. Daunted by the theoretical difficulties, I
got out a big hammer. The hammer is of some technical interest, and
for many problems it is not too big, so there is some value in
presenting it.Perl has a feature called tie that allows a variable to be enchanted so that accesses to it are handled by programmer-defined methods instead of by Perl's usual internal processes. When a tied variable $foo is stored into, a STORE method is called, and passed the value to be stored; it is the responsibility of STORE to put this value somewhere that it can be accessed again later by its counterpart, the FETCH method.
There are a lot of problems with this feature. It has an unusually strong risk of creating incomprehensible code by being misused, since when you see something like $this = $that you have no way to know whether $this and $that are tied, and that what you think is an assignment expression is actually STORE($this, FETCH($that)), and so is invoking two hook functions that could have completely arbitrary effects. Another, related problem is that the compiler can't know that either, which tends to disable the possibility of performing just about any compile-time optimization you could possibly think of. Perhaps you would like to turn this:
for (1 .. 1000000) { $this = $that }
into just this:
$this = $that;
Too bad; they are not the same, because $that might be tied
to a FETCH function that will open the pod bay doors the
142,857th time it is called. The unoptimized code opens the pod bay
doors; the "optimized" code does not.But tie is really useful for certain kinds of debugging. In this case the question is "who was responsible for inserting those date headers into $output?" We can answer the question by tieing $output and supplying a STORE callback that issues a report whenever $output is modified. The code looks like this:
package who_farted;
sub TIESCALAR {
my ($package, $fh) = @_;
my $value = "";
bless { value => \$value, fh => $fh } ;
}
This is the constructor; it manufactures an object to which the
FETCH and STORE methods can be directed. It is the
responsibility of this object to track the value of $output,
because Perl won't be tracking the value in the usual way. So the
object contains a "value" member, holding the value that is stored in
$object. It also contains a filehandle for printing
diagnostics. The FETCH method simply returns the current
stored value:
sub FETCH {
my $self = shift;
${$self->{value}};
}
The basic STORE method is simple:
sub STORE {
my ($self, $val) = @_;
my $fh = $self->{fh};
print $fh "Someone stored '$val' into \$output\n";
${$self->{value}} = $val;
}
It issues a diagnostic message about the new value, and stores the new
value into the object so that FETCH can get it later. But
the diagnostic here is not useful; all it says is that "someone"
stored the value; we need to know who, and where their code is. The
function st() generates a stack trace:
sub st {
my @stack;
my $spack = __PACKAGE__;
my $N = 1;
while (my @c = caller($N)) {
my (undef, $file, $line, $sub) = @c;
next if $sub =~ /^\Q$spack\E::/o;
push @stack, "$sub ($file:$line)";
} continue { $N++ }
@stack;
}
Perl's built-in caller() function returns information about
the stack frame N levels up. For clarity, st() omits
information about frames in the who_farted class itself.
(That's the next if... line.)The real STORE dumps the stack trace, and takes some pains to announce whether the value of $output was entirely overwritten or appended to:
sub STORE {
my ($self, $val) = @_;
my $old = $ {$self->{value}};
my $olen = length($old);
my ($act, $what) = ("set to", $val);
if (substr($val, 0, $olen) eq $old) {
($act, $what) = ("appended", substr($val, $olen));
}
$what =~ tr/\n/ /;
$what =~ s/\s+$//;
my $fh = $self->{fh};
print $fh "var $act '$what'\n";
print $fh " $_\n" for st();
print $fh "\n";
${$self->{value}} = $val;
}
To use this, you just tie $output at the top of the base
code:
open my($DIAGNOSTIC), ">", "/tmp/who-farted" or die $!;
tie $output, 'who_farted', $DIAGNOSTIC;
This worked well enough. The stack trace informed me that the
modification of interest was occurring in the
blosxom::generate function at line 290 of
blosxom.cgi. That was the precise location of the lost
wallet. It was, as I said, a big hammer to use to squash a mosquito of
a problem---but the mosquito is dead.A somewhat more useful version of this technique comes in handy in situations where you have some program, say a CGI program, that is generating the wrong output; maybe there is a "1" somewhere in the middle of the output and you don't know what part of the program printed "1" to STDOUT. You can adapt the technique to watch STDOUT instead of a variable. It's simpler in some ways, because STDOUT is written to but never read from, so you can eliminate the FETCH method and the data store:
package who_farted;
sub rig_fh {
my ($handle, $diagnostic) = shift;
my $mode = shift || "<";
open my($aux_handle), "$mode&=", $handle or die $!;
tie *$handle, __PACKAGE__, $aux_handle, $diagnostic;
}
sub TIEHANDLE {
my ($package, $aux_handle, $diagnostic) = @_;
bless [$aux_handle, $diagnostic] => $package;
}
sub PRINT {
my ($aux_handle, $diagnostic) = @$self;
print $aux_handle @_;
my $str = join("", @_);
print $diagnostic "$str:\n";
print $diagnostic " $_\n" for st();
print $diagnostic "\n";
}
To use this, you put something like rig_fh(\*STDOUT,
$DIAGNOSTIC, ">") in the main code. The only tricky part is that some
part of the code (rig_fh here) must manufacture a new, untied
handle that points to the same place that STDOUT did before
it was tied, so that the output can actually be printed.Something it might be worth pointing out about the code I showed here is that it uses the very rare one-argument form of bless:
package who_farted;
sub TIESCALAR {
my ($package, $fh) = @_;
my $value = "";
bless { value => \$value, fh => $fh } ;
}
Normally the second argument should be $package, so that the
object is created in the appropriate package; the default is to create
it in package who_farted. Aren't these the same? Yes,
unless someone has tried to subclass who_farted and inherit
the TIESCALAR method. So the only thing I have really gained
here is to render the TIESCALAR method uninheritable.
<sarcasm>Gosh, what a tremendous
benefit</sarcasm>. Why did I do it this way? In
regular OO-style code, writing a method that cannot be inherited is
completely idiotic. You very rarely have a chance to write a
constructor method in a class that you are sure will never be
inherited. This seemed like such a case. I decided to take advantage
of this non-feature of Perl since I didn't know when the opportunity would come by again."Take advantage of" is the wrong phrase here, because, as I said, there is not actually any advantage to doing it this way. And although I was sure that who_farted would never be inherited, I might have been wrong; I have been wrong about such things before. A smart programmer requires only ten years to learn that you should not do things the wrong way, even if you are sure it will not matter. So I violated this rule and potentially sabotaged my future maintenance efforts (on the day when the class is subclassed) and I got nothing, absolutely nothing in return.
Yes. It is completely pointless. A little Dada to brighten your day. Anyone who cannot imagine a lobster-handed train conductor sleeping in a pile of celestial globes is an idiot.
[Other articles in category /oops] permanent link
Fri, 24 Feb 2006
Blog Post Escapes from Lab
My blog pages get regenerated when I run Blosxom. Also, I have a cron
job that runs it every night at 12:10.
Files named something.blog turn into blog posts. While posts are under construction, I name them something.notyet. Then when they're done, I rename them to something.blog and either rerun Blosxom or wait until 12:10.
Sometimes I get a little cocky, and I figure that I'm going to finish the post quickly. Then I name the file something.blog right from the start.
Sometimes I'm mistaken about finishing the post quickly. Then I have to fix the name before 12:10 so that the unfinished post doesn't show up on the blog.
Because if it does show up, I can't really retract it. I can remove it from the main blog pages at plover.com. But bloglines.com won't remove it until another twelve posts have come in, no matter what I do with the syndication files.
And that's why there's a semi-finished post about Simplified Poker on bloglines.com today.
[Other articles in category /oops] permanent link
Thu, 02 Feb 2006
More on multiple SMTP connections
[ The previous
article is here. ]
Two people so far have written in to ask why I didn't just have the SMTP server delete the lock files when it was done with them. Well, more accurately, one person wrote in to ask that, one other person just said that it would solve my problem to do it.
But I thought of that, and I didn't do it; here's why. The lock directory contains up to 16,843,009 directories that cannot, typically, be deleted. Thus deleting the lock files does not solve the problem; at best it postpones it.
John Macdonald had a better suggestion: To lock address a.b.c.d, open file a/b and lock byte 256·c+d. This might work.
But at this point my thinking on the project is that if a thing's not worth doing at all, it's not worth doing well.
[Other articles in category /oops] permanent link
Preventing multiple SMTP connections
As I believe I said somewhere else, I have a lot of ideas, and only
about one in ten turns out really well in the end. About seven-tenths
get abandoned before the development stage, and then of the three that
survive to development, two don't work.
The MIT CS graduate student handbook used to have a piece of advice in it that I think is very wise. It said that two-thirds of all research projects are failures. The people that you (as a grad student at MIT) see at MIT who seem to have one success after another are not actually successful all the time. It's just that they always have at least three projects going on at once, and you don't hear about the ones that are flops. So the secret of success is to always be working on several projects at once. (I wish I could find this document again. It used to be online.)
Anyway, this note is about one of those projects that I carried through to completion, but that was a failure.
The project was based in the observation that spam computers often make multiple simultaneous connections to my SMTP server and use all the connections to send spam at once. It's very rare to get multiple legitimate simultaneous connections from the same place. So rejecting or delaying simultaneous connections may reduce incoming spam and load on the SMTP server.
My present SMTP architecture spawns a separate process for each incoming SMTP connection. So an IPC mechanism is required for the separate processes to communicate with each other to determine that several of them are servicing the same remote IP address. Then all but one of the processes can commit suicide. If the incoming email is legitimate, the remote server will try the other messages later.
The IPC mechanism I chose was this: Whenever an SMTP server starts up, servicing a connection from address a.b.c.d, it creates an empty file named smtplock/a/b/c/d and gets an exclusive file lock on it. It's OK if the file already exists. But if the file is already locked, the server should conclude that some other server is already servicing that address, and commit suicide.
This worked really well for a few weeks. Then one day I came home from work and found my system all tied into knots. The symptoms were similar to those that occurred the time I used up all the space on the root partition, so I checked the disk usage right away. But none of the disks were full. A minute later, I realized what the problem was: creating a file for each unique IP address that sent mail had used up all the inodes, and no new files could be created.
The IPC strategy I had chosen gobbled up about twenty thousand inodes a day. At the time I had implemented it, I had had a few hundred thousand inodes free on the root partition. Whoops.
Compounding this mistake, I had made another. I didn't provide any easy way to shut off the feature! It would have been trivial to do so. All I had to do was predicate its use on the existence of the smtplock directory. Then I could have moved the directory aside and the servers would have instantly stopped consuming inodes. I would then have been able to remove the directory at my convenience. Instead, the servers "gracefully" handle the non-existence of smtplock by reporting a temporary failure back to the remote system and aborting the transmission. To shut off the feature, I had to modify, recompile, and re-install the server software.
Duh.
[ Addendum 20060202: There is a brief followup to this article. ]
[Other articles in category /oops] permanent link
Sat, 28 Jan 2006
An unusually badly designed bit of software
I am inaugurating this new
section of my blog, which will contain articles detailing things I
have screwed up.
Back on 19 January, I decided that readers might find it convenient if, when I mentioned a book, there was a link to buy the book. I was planning to write a lot about what books I was reading, and perhaps if I was convincing enough about how interesting they were, people would want their own copies.
The obvious way to do this is just to embed the HTML for the book link directly into each entry in the appropriate place. But that is a pain in the butt, and if you want to change the format of the book link, there is no good way to do it. So I decided to write a Blosxom plugin module that would translate some sort of escape code into the appropriate HTML. The escape code would only need to contain one bit of information about the book, say its ISBN, and then the plugin could fetch the other information, such as the title and price, from a database.
The initial implementation allowed me to put <book>1558607013</book> tags into an entry, and the plugin would translate this to the appropriate HTML. (There's an example on the right.
) The 1558607013 was the ISBN. The plugin would look up this key in a Berkeley DB database, where it would find the book title and Barnes and Noble image URL. Then it would replace the <book> element with the appropriate HTML. I did a really bad job with this plugin and had to rewrite it.Since Berkeley DB only maps string keys to single string values, I had stored the title and image URL as a single string, with a colon character in between. That was my first dumb mistake, since book titles frequently include colons. I ran into this right away, with Voyages and Discoveries: Selections from Hakluyt's Principal Navigations.
This, however, was a minor error. I had made two major errors. One was that the <book>1558607013</book> tags were unintelligible. There was no way to look at one and know what book was being linked without consulting the database.
But even this wouldn't have been a disaster without the other big mistake, which was to use Berkeley DB. Berkeley DB is a great package. It provides fast keyed lookup even if you have millions of records. I don't have millions of records. I will never have millions of records. Right now, I have 15 records. In a year, I might have 200.
[ Addendum 20180201: Twelve years later, I have 122. ] The price I paid for fast access to the millions of records I don't have is that the database is not a text file. If it were a text file, I could look up <book>1558607013</book> by using grep. Instead, I need a special tool to dump out the database in text form, and pipe the output through grep. I can't use my text editor to add a record to the database; I had to write a special tool to do that. If I use the wrong ISBN by mistake, I can't just correct it; I have to write a special tool to delete an item from the database and then I have to insert the new record.
When I decided to change the field separator from colon to \x22, I couldn't just M-x replace-string; I had to write a special tool. If I later decided to add another field to the database, I wouldn't be able to enter the new data by hand; I'd have to write a special tool.
On top of all that, for my database, Berkeley DB was probably slower than the flat text file would have been. The Berkeley DB file was 12,288 bytes long. It has an index, which Berkeley DB must consult first, before it can fetch the data. Loading the Berkeley DB module takes time too. The text file is 845 bytes long and can be read entirely into memory. Doing so requires only builtin functions and only a single trip to the disk.
I redid the plugin module to use a flat text file with tab-separated columns:
HOP 1558607013 Higher-Order Perl 9072008
DDI 068482471X Darwin's Dangerous Idea 1363778
Autobiog 0760768617 Franklin's Autobiography 9101737
VoyDD 0486434915 The Voyages of Doctor Dolittle 7969205
Brainstorms 0262540371 Brainstorms 1163594
Liber Abaci 0387954198 Liber Abaci 6934973
Perl Medic 0201795264 Perl Medic 7254439
Perl Debugged 0201700549 Perl Debugged 3942025
CLTL2 1555580416 Common Lisp: The Language 3851403
Frege 0631194452 The Frege Reader 8619273
Ingenious Franklin 0812210670 Ingenious Dr. Franklin 977000
The columns are a nickname ("HOP" for Higher-Order Perl,
for example), the ISBN, the full title, and the image URL. The plugin
will accept either <book>1558607013</book> or
<book>HOP</book> to designate Higher-Order
Perl. I only use the nicknames now, but I let it accept ISBNs
for backward compatibility so I wouldn't have to go around changing
all the <book> elements I had already done.Now I'm going to go off and write "just use a text file, fool!" a hundred times.
[Other articles in category /oops] permanent link