Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
Subtopics:
| Mathematics | 250 |
| Programming | 102 |
| Language | 97 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Fri, 17 Feb 2012
It came from... the HOLD SPACE
Since 2002, I've given a talk almost every December for the Philadelphia Linux Users'
Group. It seems like most of their talks are about the newest and
best developments in Linux applications, which is a topic I don't know
much about. So I've usually gone the other way, talking about the
oldest and worst stuff. I gave a couple of pretty good talks about
how files work, for example, and what's in the inode structure.
I recently posted about my work on Zach Holman's spark program, which culminated in a ridiculous workaround for the shell's lack of fractional arithmetic. That work inspired me to do a talk about all the awful crap we had to deal with before we had Perl. (And the other 'P' languages that occupy a similar solution space.) Complete materials are here. I hope you check them out, because i think they are fun. This post is a bunch of miscellaneous notes about the talk.
One example of awful crap we had to deal with before Perl etc. were invented was that some people used to write 'sed scripts', although I am really not sure how they did it. I tried once, without much success, and then for this talk I tried again, and again did not have much success.



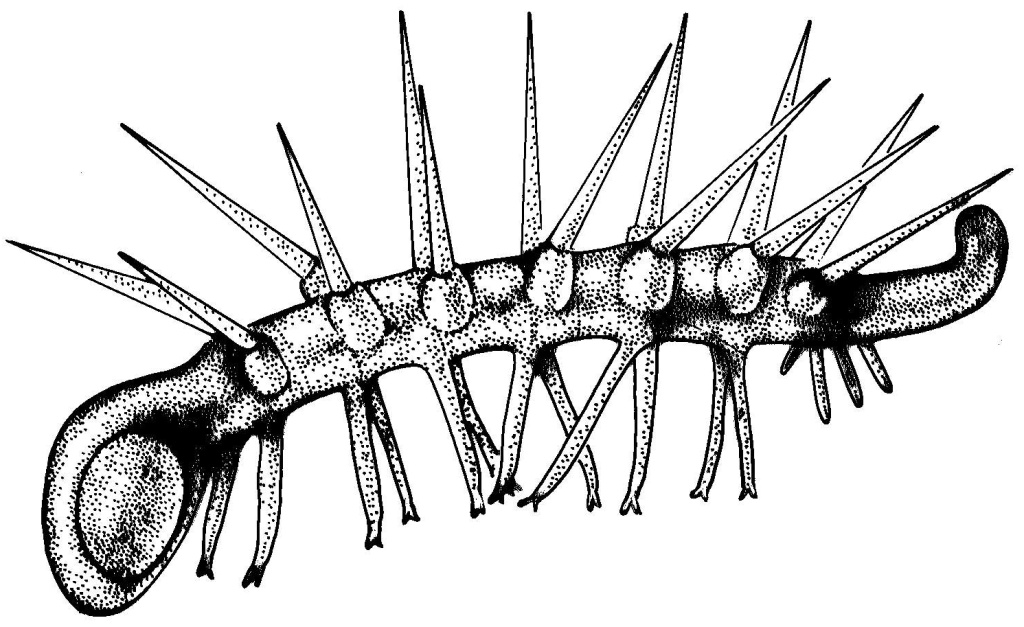 The little guy to the right is known
as hallucigenia. It is a creature so peculiar that when
the paleontologists first saw the fossils, they could not even agree
on which side was uppermost. It has nothing to do with Unix, but I
put it on the slide to illustrate "alien horrors from the dawn of
time".
The little guy to the right is known
as hallucigenia. It is a creature so peculiar that when
the paleontologists first saw the fossils, they could not even agree
on which side was uppermost. It has nothing to do with Unix, but I
put it on the slide to illustrate "alien horrors from the dawn of
time".
Between slides 9 and 10 (about the ed line editor) I did a
quick demo of editing with ed. You will just have to imagine
this. I first learned to program with a line editor like ed,
on a teletypewriter just like the one on slide 8.
Modern editors are much better. But it used to
be that Unix sysadmins were expected to know at least a little ed,
because if your system got into some horrible state where it couldn't
mount the /usr partition, you wouldn't be able to run
/usr/bin/vi or /usr/local/bin/emacs, but you would
still be able to use /bin/ed to fix /etc/fstab or
whatever else was broken. Knowing ed saved my bacon several
times.
 (Speaking of
teletypewriters, ours had an attachment for punching paper tape, which
you can see on the left side of the picture. The punched chads fell
into a plastic chad box (which is missing in the picture), and when I
was about three I spilled the chad box. Chad was everywhere, and it
was nearly impossible to pick up. There were still chads stuck
in the cracks in the floorboards when we moved out three years
later. That's why, when the contested election of 2000 came around, I
was one of the few people in North America who was not bemused to
learn that there was a name for the little punched-out bits.)
(Speaking of
teletypewriters, ours had an attachment for punching paper tape, which
you can see on the left side of the picture. The punched chads fell
into a plastic chad box (which is missing in the picture), and when I
was about three I spilled the chad box. Chad was everywhere, and it
was nearly impossible to pick up. There were still chads stuck
in the cracks in the floorboards when we moved out three years
later. That's why, when the contested election of 2000 came around, I
was one of the few people in North America who was not bemused to
learn that there was a name for the little punched-out bits.)
Anyway, back to ed. ed has one and only one diagnostic: if you do something it didn't like, it prints ?. This explains the ancient joke on slide 10, which first appeared circa 1982 in the 4.2BSD fortune program.
I really wanted to present a tour de force of sed mastery, but as slides 24–26 say, I was not clever enough. I tried really hard and just could not do it. If anyone wants to fix my not-quite-good-enough sed script, I will be quite grateful.
On slide 28 I called awk a monster. This was a slip-up; awk is not a monster and that is why it does not otherwise appear in this talk. There is nothing really wrong with awk, other than being a little old, a little tired, and a little underpowered.
If you are interested in the details of the classify program, described on slide 29, the sources are still available from the comp.sources.unix archive. People often say "Why don't you just use diff for that?" so I may as well answer that here: You use diff if you have two files and you want to see how they differ. You use classify if you have 59 files, of which 36 are identical, 17 more are also identical to each other but different from the first 36, and the remaining 6 are all weirdos, and you want to know which is which. These days you would probably just use md5sum FILES | accumulate, and in hindsight that's probably how I should have implemented classify. We didn't have md5sum but we had something like it, or I could have made a checksum program. The accumulate utility is trivial.
Several people have asked me to clarify my claim to have invented netcat. It seems that a similar program with the same name is attributed to someone called "Hobbit". Here is the clarification: In 1991 I wrote a program with the functionality I described and called it "netcat". You would run netcat hostname port and it would open a network socket to the indicated address, and transfer data from standard input into the socket, and data from the socket to standard output. I still have the source code; the copyright notice at the top says "21 October 1991". Wikipedia says that the same-named program by the other guy was released on 20 March 1996. I do not claim that the other guy stole it from me, got the idea from me, or ever heard of my version. I do not claim to be the first or only person to have invented this program. I only claim to have invented mine independently.
My own current version of the spark program is on GitHub, but I think Zach Holman's current version is probably simpler and better now.
[ Addendum 20170325: I have revised this talk a couple of times since this blog article was written. Links to particular slides go to the 2011 versions, but the current version is from 2017. There are only minor changes. For example, I removed `awk` from the list of “monsters”. ]
[Other articles in category /Unix] permanent link