Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFM |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 246 |
| Programming | 100 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Thu, 15 Dec 2016
Let's decipher a thousand-year-old magic square
The Parshvanatha temple in Madhya Pradesh, India was built around 1,050 years ago. Carved at its entrance is this magic square:

The digit signs have changed in the past thousand years, but it's a quick and fun puzzle to figure out what they mean using only the information that this is, in fact, a magic square.
A solution follows. No peeking until you've tried it yourself!
There are 9 one-digit entries




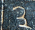
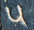
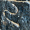

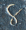
and 7 two-digit entries
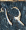

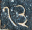
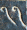


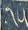
so we can guess
that the entries are the numbers 1 through 16, as is usual, and the
magic sum is 34. The appears in the
same position in all the two-digit numbers, so it's the digit 1. The
other digit of the numeral is  , and this must be zero. If it were
otherwise, it would appear on its own, as does for example the
from or the
from .
, and this must be zero. If it were
otherwise, it would appear on its own, as does for example the
from or the
from .
It is tempting to imagine that is 4.
But we can see it's not so. Adding up the rightmost column, we get
+ + + =
+ 11 + + =
(10 + ) + 11 + +
= 34,
so that must be an odd number. We
know it isn't 1 (because is 1), and it
can't be 7 or 9 because appears in the
bottom row and there is no 17 or 19. So
must be 3 or 5.
Now if were 3, then would be 13, and the third column would be
+ + + =
1 + + 10 + 13 = 34,
and then would be 10, which is too big. So must be 5, and this means that is 4 and is 8.
( appears only a as a single-digit
numeral, which is consistent with it being 8.)
The top row has
+ + + =
+ + 1 + 14 =
+ (10 + ) + 1 + 14 = 34
so that +
= 9. only appears as a single digit and
we already used 8 so must be 7 or 9.
But 9 is too big, so it must be 7, and then is 2.
is the only remaining unknown single-digit
numeral, and we already know 7 and 8, so
is 9. The leftmost column tells us
that is 16, and the last two entries,
and are
easily discovered to be 13 and 3. The decoded square is:
|
|
I like that people look at the right-hand column and immediately see 18 + 11 + 4 + 8 but it's actually 14 + 11 + 5 + 4.
This is an extra-special magic square: not only do the ten rows, columns, and diagonals all add up to 34, so do all the four-cell subsquares, so do any four squares arranged symmetrically about the center, and so do all the broken diagonals that you get by wrapping around at the edges.
[ Addendum: It has come to my attention that the digit symbols in the magic square are not too different from the current forms of the digit symbols in the Gujarati script. ]
[ Addendum 20161217: The temple is not very close to Gujarat or to the area in which Gujarati is common, so I guess that the digit symbols in Indian languages have evolved in the past thousand years, with the Gujarati versions remaining closest to the ancient forms, or else perhaps Gujarati was spoken more widely a thousand years ago. I would be interested to hear about this from someone who knows. ]
[ Addendum 20170130: Shreevatsa R. has contributed a detailed discussion of the history of the digit symbols. ]
[Other articles in category /math] permanent link
Mon, 12 Dec 2016
Another Git catastrophe cleaned up
My co-worker X had been collaborating with a front-end designer on a very large change, consisting of about 406 commits in total. The sum of the changes was to add 18 new files of code to implement the back end of the new system, and also to implement the front end, a multitude of additions to both new and already-existing files. Some of the 406 commits modified just the 18 back-end files, some modified just the front-end files, and many modified both.
X decided to merge and deploy just the back-end changes, and then, once that was done and appeared successful, to merge the remaining front-end changes.
His path to merging the back-end changes was unorthodox: he checked
out the current master, and then, knowing that the back-end changes
were isolated in 18 entirely new files, did
git checkout topic-branch -- new-file-1 new-file-2 … new-file-18
He then added the 18 files to the repo, committed them, and published
the resulting commit on master. In due course this was deployed to
production without incident.
The next day he wanted to go ahead and merge the front-end changes,
but he found himself in “a bit of a pickle”. The merge didn't go
forward cleanly, perhaps because of other changes that had been made
to master in the meantime. And trying to rebase the branch onto the
new master was a complete failure. Many of those 406 commits included
various edits to the 18 back-end files that no longer made sense now
that the finished versions of those files were in the master branch
he was trying to rebase onto.
So the problem is: how to land the rest of the changes in those 406 commits, preferably without losing the commit history and messages.
The easiest strategy in a case like this is usually to back in time:
If the problem was caused by the unorthodox checkout-add-commit, then
reset master to the point before that happened and try doing it a
different way. That strategy wasn't available because X had already
published the master with his back-end files, and a hundred other
programmers had copies of them.
The way I eventually proceeded was to rebase the 406-commit work
branch onto the current master, but to tell Git meantime that
conflicts in the 18 back-end files should be ignored, because the
version of those files on the master branch was already perfect.
Merge drivers
There's no direct way to tell Git to ignore merge conflicts in exactly
18 files, but there is a hack you can use to get the same effect.
The repo can contain a .gitattributes file that lets you specify
certain per-file options. For example, you can use .gitattributes
to say that the files in a certain directory are text, that when they
are checked out the line terminators should be converted to whatever
the local machine's line terminator convention is, and they should be
converted back to NLs when changes are committed.
Some of the per-file attributes control how merge conflicts are resolved. We were already using this feature for a certain frequently-edited file that was a list of processes to be performed in a certain order:
do A
then do B
Often different people would simultaneously add different lines to the end of this file:
# Person X's change:
do A
then do B
then do X
# Person Y's change:
do A
then do B
then do Y
X would land their version on master and later there would be a
conflict when Y tried to land their own version:
do A
then do B
<<<<<<<<
then do X
--------
then do Y
>>>>>>>>
Git was confused: did you want new line X or new line Y at the end of the file, or both, and if both then in what order? But the answer was always the same: we wanted both, X and then Y, in that order:
do A
then do B
then do X
then do Y
With the merge attribute set to union for this file, Git
automatically chooses the correct resolution.
So, returning to our pickle, I wanted to set the merge attribute for
the 18 back-end files to tell Git to always choose the version already
in master, and always ignore the changes from the branch I was
merging.
There is not exactly a way to do this, but the mechanism that is provided is extremely general, and it is not hard to get it to do what we want in this case.
The merge attribute in .gitattributes specifies the name of a
“driver” that resolves merge conflicts. The driver can be one of a
few built-in drivers, such as the union driver I just described, or
it can be the name of a user-supplied driver, configured in
.gitconfig. The first step is to use .gitattributes to tell Git
to use our private, special-purpose driver for the 18 back-end files:
new-file-1 merge=ours
new-file-2 merge=ours
…
new-file-18 merge=ours
(The name ours here is completely arbitrary. I chose it because its
function was analogous to the -s ours and -X ours options of
git-merge.)
Then we add a section to .gitconfig to say what the
ours driver should do:
[merge "ours"]
name = always prefer our version to the one being merged
driver = true
The name is just a human-readable description and is ignored by Git.
The important part is the deceptively simple-appearing driver = true
line. The driver is actually a command that is run when there is
a merge conflict. The command is run with the names of three files
containing different versions of the target file: the main file
being merged into, and temporary files containing the version with the
conflicting changes and the common ancestor of the first two files. It is
the job of the driver command to examine the three files, figure out how to
resolve the conflict, and modify the main file appropriately.
In this case merging the two or three versions of the file is very
simple. The main version is the one on the master branch, already
perfect. The proposed changes are superfluous, and we want to ignore
them. To modify the main file appropriately, our merge driver command
needs to do exactly nothing. Unix helpfully provides a command that
does exactly nothing, called true, so that's what we tell Git to use
to resolve merge conflicts.
With this configured, and the changes to .gitattributes checked in,
I was able to rebase the 406-commit topic branch onto the current
master. There were some minor issues to work around, so it was not
quite routine, but the problem was basically solved and it wasn't a
giant pain.
I didn't actually use git-rebase
I should confess that I didn't actually use git-rebase at this
point; I did it semi-manually, by generating a list of commit IDs and
then running a loop that cherry-picked them one at a time:
tac /tmp/commit-ids |
while read commit; do
git cherry-pick $commit || break
done
I don't remember why I thought this would be a better idea than just
using git-rebase, which is basically the same thing. (Superstitious anxiety,
perhaps.) But I think the process and the result were pretty much the
same. The main drawback of my approach is that if one of the
cherry-picks fails, and the loop exits prematurely, you have to
hand-edit the commit-ids file before you restart the loop, to remove the commits that were
successfully picked.
Also, it didn't work on the first try
My first try at the rebase didn't quite work. The merge driver was
working fine, but some commits that it wanted to merge modified only
the 18 back-end files and nothing else. Then there were merge
conflicts, which the merge driver said to ignore, so that the net
effect of the merged commit was to do nothing. But git-rebase
considers that an error, says something like
The previous cherry-pick is now empty, possibly due to conflict resolution.
If you wish to commit it anyway, use:
git commit --allow-empty
and stops and waits for manual confirmation. Since 140 of the 406 commits modified only the 18 perfect files I was going to have to intervene manually 140 times.
I wanted an option that told git-cherry-pick that empty commits were
okay and just to ignore them entirely, but that option isn't in
there. There is something almost as good though; you can supply
--keep-redundant-commits and instead of failing it will go ahead and create commits
that make no changes. So I ended up with a branch with 406 commits of
which 140 were empty. Then a second git-rebase eliminated them,
because the default behavior of git-rebase is to discard empty
commits. I would have needed that final rebase anyway, because I had
to throw away the extra commit I added at the beginning to check in
the changes to the .gitattributes file.
A few conflicts remained
There were three or four remaining conflicts during the giant rebase, all resulting from the following situation: Some of the back-end files were created under different names, edited, and later moved into their final positions. The commits that renamed them had unresolvable conflicts: the commit said to rename A to B, but to Git's surprise B already existed with different contents. Git quite properly refused to resolve these itself. I handled each of these cases manually by deleting A.
I made this up as I went along
I don't want anyone to think that I already had all this stuff up my sleeve, so I should probably mention that there was quite a bit of this I didn't know beforehand. The merge driver stuff was all new to me, and I had to work around the empty-commit issue on the fly.
Also, I didn't find a working solution on the first try; this was my second idea. My notes say that I thought my first idea would probably work but that it would have required more effort than what I described above, so I put it aside planning to take it up again if the merge driver approach didn't work. I forget what the first idea was, unfortunately.
Named commits
This is a minor, peripheral technique which I think is important for everyone to know, because it pays off far out of proportion to how easy it is to learn.
There were several commits of interest that I referred to repeatedly while investigating and fixing the pickle. In particular:
- The last commit on the topic branch
- The first commit on the topic branch that wasn't on
master - The commit on
masterfrom which the topic branch diverged
Instead of trying to remember the commit IDs for these I just gave
them mnemonic names with git-branch: last, first, and base,
respectively. That enabled commands like git log base..last … which
would otherwise have been troublesome to construct. Civilization
advances by extending the number of important operations which we can
perform without thinking of them. When you're thinking "okay, now I
need to rebase this branch" you don't want to derail the train of
thought to remember where the bottom of the branch is every time.
Being able to refer to it as first is a big help.
Other approaches
After it was all over I tried to answer the question “What should X
have done in the first place to avoid the pickle?” But I couldn't
think of anything, so I asked Rik Signes. Rik immediately said that
X should have used git-filter-branch to separate the 406 commits
into two branches, branch A with just the changes to the 18 back-end
files and branch B with just the changes to the other files. (The
two branches together would have had more than 406 commits, since a
commit that changed both back-end and front-end files would be
represented in both branches.) Then he would have had no trouble
landing branch A on master and, after it was deployed, landing
branch B.
At that point I realized that git-filter-branch also provided a less
peculiar way out of the pickle once we were in: Instead of using my
merge driver approach, I could have filtered the original topic branch
to produce just branch B, which would have rebased onto master
just fine.
I was aware that git-filter-branch was not part of my personal
toolkit, but I was unaware of the extent of my unawareness. I would
have hoped that even if I hadn't known exactly how to use it, I would
at least have been able to think of using it. I plan to
set aside an hour or two soon to do nothing but mess around with
git-filter-branch so that next time something like this happens I
can at least consider using it.
It occurred to me while I was writing this that it would probably have
worked to make one commit on master to remove the back-end files
again, and then rebase the entire topic branch onto that commit. But
I didn't think of it at the time. And it's not as good as what I did
do, which left the history as clean as was possible at that point.
I think I've written before that this profusion of solutions is the sign of a well-designed system. The tools and concepts are powerful, and can be combined in many ways to solve many problems that the designers didn't foresee.
[Other articles in category /prog] permanent link
Thu, 08 Dec 2016An earlier article discussed how I discovered that a hoax item in a Wikipedia list had become the official name of a mountain, Ysolo Mons, on the planet Ceres.
I contacted the United States Geological Survey to point out the hoax, and on Wednesday I got the following news from their representative:
Thank you for your email alerting us to the possibility that the name Ysolo, as a festival name, may be fictitious.
After some research, we agreed with your assessment. The IAU and the Dawn Team discussed the matter and decided that the best solution was to replace the name Ysolo Mons with Yamor Mons, named for the corn/maize festival in Ecuador. The WGPSN voted to approve the change.
Thank you for bringing the matter to our attention.
(“WGPSN” is the IAU's Working Group for Planetary System Nomenclature. Here's their official announcement of the change, the USGS record of the old name and the USGS record of the new name.)
This week we cleaned up a few relevant Wikipedia articles, including one on Italian Wikipedia, and Ysolo has been put to rest.
I am a little bit sad to see it go. It was fun while it lasted. But I am really pleased about the outcome. Noticing the hoax, following it up, and correcting the name of this mountain is not a large or an important thing, but it's a thing that very few people could have done at all, one that required my particular combination of unusual talents. Those opportunities are seldom.
[ Note: The USGS rep wishes me to mention that the email I quoted above is not an official IAU communication. ]
[Other articles in category /wikipedia] permanent link
Thu, 24 Nov 2016
Imaginary Albanian eggplant festivals… IN SPACE
Wikipedia has a list of harvest festivals which includes this intriguing entry:
Ysolo: festival marking the first day of harvest of eggplants in Tirana, Albania
(It now says “citation needed“; I added that yesterday.)
I am confident that this entry, inserted in July 2012 by an anonymous user, is a hoax. When I first read it, I muttered “Oh, what bullshit,” but then went looking for a reliable source, because you never know. I have occasionally been surprised in the past, but this time I found clear evidence of a hoax: There are only a couple of scattered mentions of Ysolo on a couple of blogs, all from after 2012, and nothing at all in Google Books about Albanian eggplant celebrations. Nor is there an article about it in Albanian Wikipedia.
But reality gave ground before I arrived on the scene. Last September NASA's Dawn spacecraft visited the dwarf planet Ceres. Ceres is named for the Roman goddess of the harvest, and so NASA proposed harvest-related names for Ceres’ newly-discovered physical features. It appears that someone at NASA ransacked the Wikipedia list of harvest festivals without checking whether they were real, because there is now a large mountain at Ceres’ north pole whose official name is Ysolo Mons, named for this spurious eggplant festival. (See also: NASA JPL press release; USGS Astrogeology Science Center announcement.)
To complete the magic circle of fiction, the Albanians might begin to celebrate the previously-fictitious eggplant festival. (And why not? Eggplants are lovely.) Let them do it for a couple of years, and then Wikipedia could document the real eggplant festival… Why not fall under the spell of Tlön and submit to the minute and vast evidence of an ordered planet?
Happy Ysolo, everyone.
[ Addendum 20161208: Ysolo has been canceled ]
[Other articles in category /wikipedia] permanent link
Fri, 11 Nov 2016
The worst literature reference ever
I think I may have found the single worst citation on Wikipedia. It's in the article on sausage casing. There is the following very interesting claim:
Reference to a cooked meat product stuffed in a goat stomach like a sausage was known in Babylon and described as a recipe in the world’s oldest cookbook 3,750 years ago.
That was exciting, and I wanted to know more. And there was a citation, so I could follow up!
The citation was:
(Yale Babylonian collection, New Haven Connecticut, USA)
I had my work cut out for me. All I had to do was drive up to New Haven and start translating their 45,000 cuneiform tablets until I found the cookbook.
(I tried to find a better reference, and turned up the book The Oldest Cuisine in the World: Cooking in Mesopotamia. The author, Jean Bottéro, was the discoverer of the cookbook, or rather he was the person who recognized that this tablet was a cookbook and not a pharmacopoeia or whatever. If the Babylonian haggis recipe is anywhere, it is probably there.)
[ Addendum 20230516: Renan Gross has brought to my attention that the Yale tablets are now available online, so it is no longer necessary to go all the way to New Haven. There are several tablets of cluinary recipes. ]
[Other articles in category /wikipedia] permanent link
Fri, 29 Jul 2016
Decomposing a function into its even and odd parts
As I have mentioned before, I am not a sudden-flash-of-insight person. Every once in a while it happens, but usually my thinking style is to minutely examine a large mass of examples and then gradually synthesize some conclusion about them. I am a penetrating but slow thinker. But there have been a few occasions in my life when the solution to a problem struck me suddenly out of the blue.
One such occasion was on the first day of my sophomore honors physics class in 1987. This was one of the best classes I took in my college career. It was given by Professor Stephen Nettel, and it was about resonance phenomena. I love when a course has a single overarching theme and proceeds to examine it in detail; that is all too rare. I deeply regret leaving my copy of the course notes in a restaurant in 1995.
The course was very difficult, But also very satisfying. It was also somewhat hair-raising, because of Professor Nettel's habit of saying, all through the second half “Don't worry if it doesn't seem to make any sense, it will all come together for you during the final exam.” This was not reassuring. But he was right! It did all come together during the final exam.
The exam had two sets of problems. The problems on the left side of the exam paper concerned some mechanical system, I think a rod fixed at one end and free at the other, or something like that. This set of problems asked us to calculate the resonant frequency of the rod, its rate of damping at various driving frequencies, and related matters. The right-hand problems were about an electrical system involving a resistor, capacitor, and inductor. The questions were the same, and the answers were formally identical, differing only in the details: on the left, the answers involved length, mass and stiffness of the rod, and on the right, the resistance, capacitance, and inductance of the electrical components. It was a brilliant exam, and I have never learned so much about a subject during the final exam.
Anyway, I digress. After the first class, we were assigned homework. One of the problems was
Show that every function is the sum of an even function and an odd function.
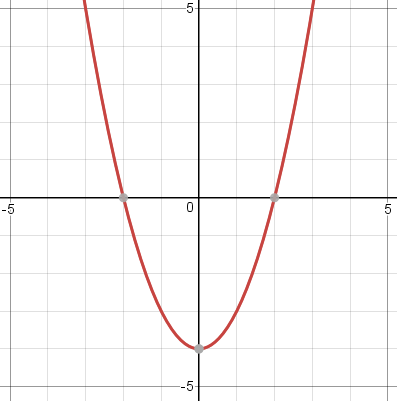
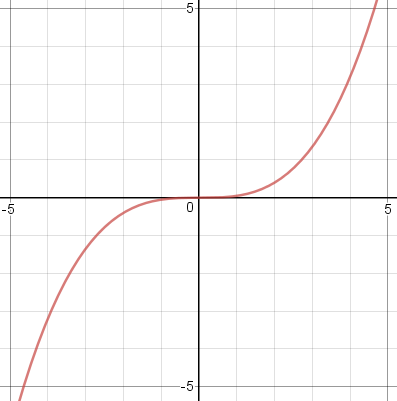
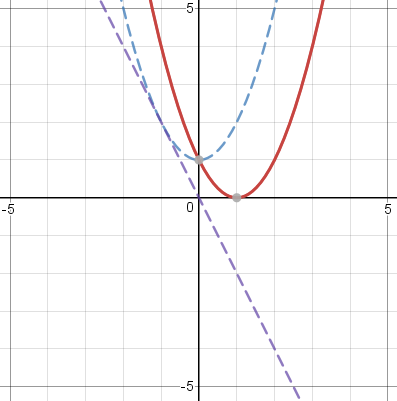
(Maybe I should explain that an even function is one which is symmetric across the !!y!!-axis; formally it is a function !!f!! for which !!f(x) = f(-x)!! for every !!x!!. For example, the function !!x^2-4!!, shown below left. An odd function is one which is symmetric under a half-turn about the origin; formally it satisfies !!f(x) = -f(-x)!! for all !!x!!. For example !!\frac{x^3}{20}!!, shown below right.)
I found this claim very surprising, and we had no idea how to solve it. Well, not quite no idea: I knew that functions could be expanded in Fourier series, as the sum of a sine series and a cosine series, and the sine part was odd while the cosine part was even. But this seemed like a bigger hammer than was required, particularly since new sophomores were not expected to know about Fourier series.
I had the privilege to be in that class with Ron Buckmire, and I remember we stood outside the class building in the autumn sunshine and discussed the problem. I might have been thinking that perhaps there was some way to replace the negative part of !!f!! with a reflected copy of the positive part to make an even function, and maybe that !!f(x) + f(-x)!! was always even, when I was hit from the blue with the solution:
$$ \begin{align} f_e(x) & = \frac{f(x) + f(-x)}2 \text{ is even},\\ f_o(x) & = \frac{f(x) - f(-x)}2 \text{ is odd, and}\\ f(x) &= f_e(x) + f_o(x) \end{align} $$
So that was that problem solved. I don't remember the other three problems in that day's homework, but I have remembered that one ever since.
But for some reason, it didn't occur to me until today to think about what those functions actually looked like. Of course, if !!f!! itself is even, then !!f_e = f!! and !!f_o = 0!!, and similarly if !!f!! is odd. But most functions are neither even nor odd.
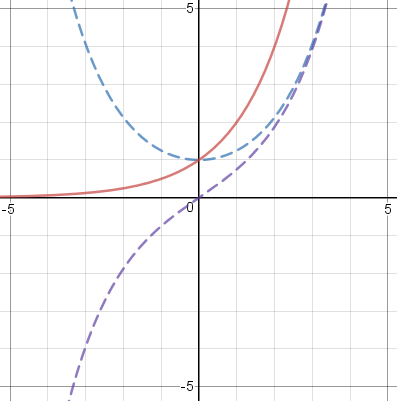
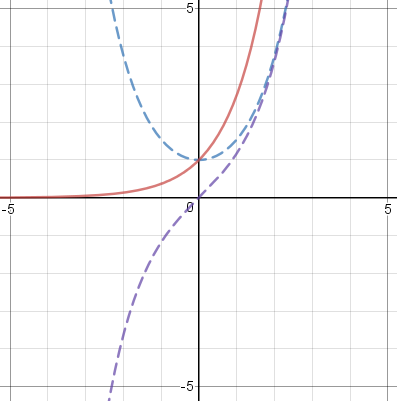
For example, consider the function !!2^x!!, which is neither even nor odd. Then we get
$$ \begin{align} f_e(x) & = \frac{2^x + 2^{-x}}2\\ f_o(x) & = \frac{2^x - 2^{-x}}2 \end{align} $$
The graph is below left. The solid red line is !!2^x!!, and the blue and purple dotted lines are !!f_e!! and !!f_o!!. The red line is the sum of the blue and purple lines. I thought this was very interesting-looking, but a little later I realized that I had already known what these graphs would look like, because !!2^x!! is just like !!e^x!!, and for !!e^x!! the even and odd components are exactly the familiar !!\cosh!! and !!\sinh!! functions. (Below left, !!2^x!!; below right, !!e^x!!.)
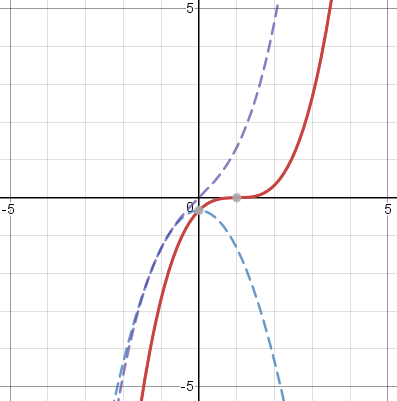
I wasn't expecting polynomials to be more interesting, but they were. (Polynomials whose terms are all odd powers of !!x!!, such as !!x^{13} - 4x^5 + x!!, are always odd functions, and similarly polynomials whose terms are all even powers of !!x!! are even functions.) For example, consider !!(x-1)^2!!, which is neither even nor odd. We don't even need the !!f_e!! and !!f_o!! formulas to separate this into even and odd parts: just expand !!(x-1)^2!! as !!x^2 - 2x + 1!! and separate it into odd and even powers, !!-2x!! and !!x^2 + 1!!:
Or we could do !!\frac{(x-1)^3}3!! similarly, expanding it as !!\frac{x^3}3 - x^2 + x -\frac13!! and separating this into !!-x^2 -\frac13!! and !!\frac{x^3}3 + x!!:
I love looking at these and seeing how the even blue line and the odd purple line conspire together to make whatever red line I want.
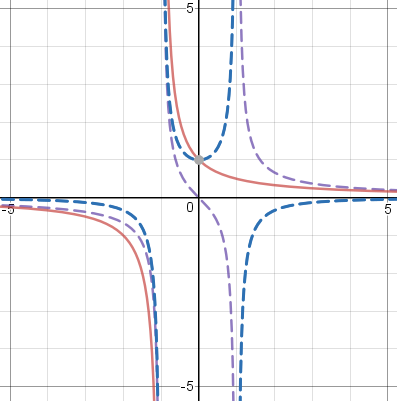
I kept wanting to try familiar simple functions, like !!\frac1x!!, but many of these are either even or odd, and so are uninteresting for this application. But you can make an even or an odd function into a neither-even-nor-odd function just by translating it horizontally, which you do by replacing !!x!! with !!x-c!!. So the next function I tried was !!\frac1{x+1}!!, which is the translation of !!\frac 1x!!. Here I got a surprise. I knew that !!\frac1{x+1}!! was undefined at !!x=-1!!, so I graphed it only for !!x>-1!!. But the even component is !!\frac12\left(\frac1{1+x}+\frac1{1-x}\right)!!, which is undefined at both !!x=-1!! and at !!x=+1!!. Similarly the odd component is undefined at two points. So the !!f = f_o + f_e!! formula does not work quite correctly, failing to produce the correct value at !!x=1!!, even though !!f!! is defined there. In general, if !!f!! is undefined at some !!x=c!!, then the decomposition into even and odd components fails at !!x=-c!! as well. The limit $$\lim_{x\to -c} f(x) = \lim_{x\to -c} \left(f_o(x) + f_e(x)\right)$$ does hold, however. The graph below shows the decomposition of !!\frac1{x+1}!!.
Vertical translations are uninteresting: they leave !!f_o!! unchanged and translate !!f_e!! by the same amount, as you can verify algebraically or just by thinking about it.
Following the same strategy I tried a cosine wave. The evenness of the cosine function is one of its principal properties, so I translated it and used !!\cos (x+1)!!. The graph below is actually for !!5\cos(x+1)!! to prevent the details from being too compressed:
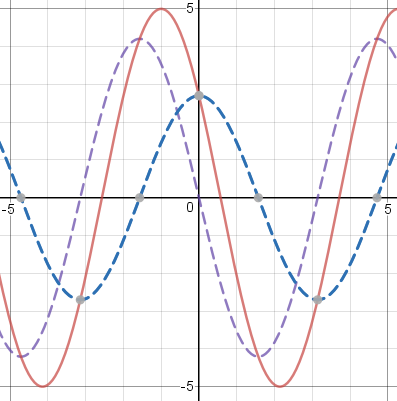
This reminded me of the time I was fourteen and graphed !!\sin x + \cos x!! and was surprised to see that it was another perfect sinusoid. But I realized that there was a simple way to understand this. I already knew that !!\cos(x + y) = \sin x\cos y + \sin y \cos x!!. If you take !!y=\frac\pi4!! and multiply the whole thing by !!\sqrt 2!!, you get $$\sqrt2\cos\left(x + \frac\pi4\right) = \sqrt2\sin x\cos\frac\pi4 + \sqrt2\cos x\sin\frac\pi4 = \sin x + \cos x$$ so that !!\sin x + \cos x!! is just a shifted, scaled cosine curve. The decomposition of !!\cos(x+1)!! is even simpler because you can work forward instead of backward and find that !!\cos(x+1) = \sin x\cos 1 + \cos x \sin 1!!, and the first term is odd while the second term is even, so that !!\cos(x+1)!! decomposes as a sum of an even and an odd sinusoid as you see in the graph above.
Finally, I tried a Poisson distribution, which is highly asymmetric. The formula for the Poisson distribution is !!\frac{\lambda^xe^\lambda}{x!}!!, for some constant !!\lambda!!. The !!x! !! in the denominator is only defined for non-negative integer !!x!!, but you can extend it to fractional and negative !!x!! in the usual way by using !!\Gamma(x+1)!! instead, where !!\Gamma!! is the Gamma function. The !!\Gamma!! function is undefined at zero and negative integers, but fortunately what we need here is the reciprocal gamma function !!\frac1{\Gamma(x)}!!, which is perfectly well-behaved. The results are spectacular. The graph below has !!\lambda = 0.8!!.
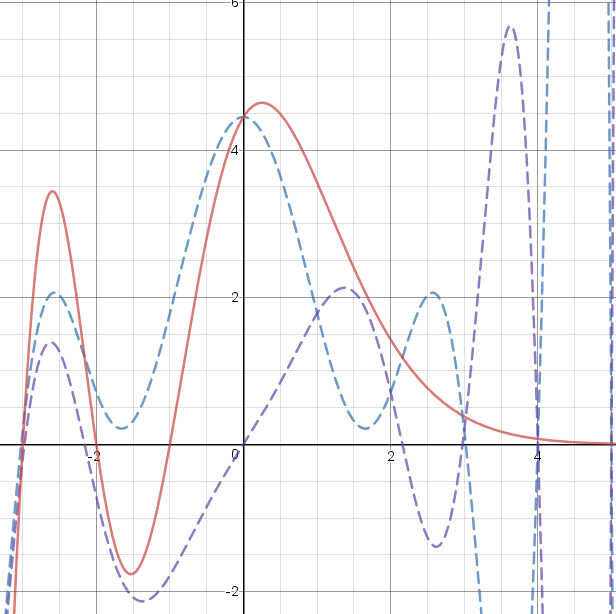
The part of this with !!x\ge 0!! is the most interesting to me, because the Poisson distribution has a very distinctive shape, and once again I like seeing the blue and purple !!\Gamma!! functions working together to make it. I think it's just great how the red line goes gently to zero as !!x!! increases, even though the even and the odd components are going wild. (!!x! !! increases rapidly with !!x!!, so the reciprocal !!\Gamma!! function goes rapidly to zero. But the even and odd components also have a !!\frac1{\Gamma(-x)}!! part, and this is what dominates the blue and purple lines when !!x >4!!.)
On the !!x\lt 0!! side it has no meaning for me, and it's just wiggly lines. It hadn't occurred to me before that you could extend the Poisson distribution function to negative !!x!!, and I still can't imagine what it could mean, but I suppose why not. Probably some statistician could explain to me what the Poisson distribution is about when !!x<0!!.
You can also consider the function !!\sqrt x!!, which breaks down completely, because either !!\sqrt x!! or !!\sqrt{-x}!! is undefined except when !!x=0!!. So the claim that every function is the sum of an even and an odd function fails here too. Except perhaps not! You could probably consider the extension of the square root function to the complex plane, and take one of its branches, and I suppose it works out just fine. The geometric interpretation of evenness and oddness are very different, of course, and you can't really draw the graphs unless you have four-dimensional vision.
I have no particular point to make, except maybe that math is fun, even elementary math (or perhaps especially elementary math) and it's fun to see how it works out.
The beautiful graphs in this article were made with Desmos. I had dreaded having to illustrate my article with graphs from Gnuplot (ugh) or Wolfram|α (double ugh) and was thrilled to find such a handsome alternative.
[ Addendum: I've just discovered that in Desmos you can include a parameter in the functions that it graphs, and attach the parameter to a slider. So for example you can arrange to have it display !!(x+k)^3!! or !!e^{-(x+k)^2}!!, with the value of !!k!! controlled by the slider, and have the graph move left and right on the plane as you adjust the slider, with its even and odd parts changing in real time to match. ]
[ For example, check out travelling Gaussians or varying sinusoid. ]
[Other articles in category /math] permanent link
Thu, 28 Jul 2016
Controlling the KDE screen locking works now
Yesterday I wrote about how I was trying to control the KDE screenlocker's timeout from a shell script and all the fun stuff I learned along the way. Then after I published the article I discovered that my solution didn't work. But today I fixed it and it does work.
What didn't work
I had written this script:
timeout=${1:-3600}
perl -i -lpe 's/^Enabled=.*/Enabled=False/' $HOME/.kde/share/config/kscreensaverrc
qdbus org.freedesktop.ScreenSaver /MainApplication reparseConfiguration
sleep $timeout
perl -i -lpe 's/^Enabled=.*/Enabled=True/' $HOME/.kde/share/config/kscreensaverrc
qdbus org.freedesktop.ScreenSaver /MainApplication reparseConfiguration
The strategy was: use perl to rewrite the screen locker's
configuration file, and then use qdbus to send a D-Bus message to
the screen locker to order it to load the updated configuration.
This didn't work. The System Settings app would see the changed
configuration, and report what I expected, but the screen saver itself
was still behaving according to the old configuration. Maybe the
qdbus command was wrong or maybe the whole theory was bad.
More strace
For want of anything else to do (when all you have is a hammer…), I
went back to using strace to see what else I could dig up, and tried
strace -ff -o /tmp/ss/s /usr/bin/systemsettings
which tells strace to write separate files for each process or
thread.
I had a fantasy that by splitting the trace for each process into a
separate file, I might solve the mysterious problem of the missing
string data. This didn't come true, unfortunately.
I then ran tail -f on each of the output files, and used
systemsettings to update the screen locker configuration, looking to
see which the of the trace files changed. I didn't get too much out
of this. A great deal of the trace was concerned with X protocol
traffic between the application and the display server. But I did
notice this portion, which I found extremely suggestive, even with the
filenames missing:
3106 open(0x2bb57a8, O_RDWR|O_CREAT|O_CLOEXEC, 0666) = 18
3106 fcntl(18, F_SETFD, FD_CLOEXEC) = 0
3106 chmod(0x2bb57a8, 0600) = 0
3106 fstat(18, {...}) = 0
3106 write(18, 0x2bb5838, 178) = 178
3106 fstat(18, {...}) = 0
3106 close(18) = 0
3106 rename(0x2bb5578, 0x2bb4e48) = 0
3106 unlink(0x2b82848) = 0
You may recall that my theory was that when I click the “Apply” button
in System Settings, it writes out a new version of
$HOME/.kde/share/config/kscreensaverrc and then orders the screen
locker to reload the configuration. Even with no filenames, this part
of the trace looked to me like the replacement of the configuration
file: a new file is created, then written, then closed, and then the
rename replaces the old file with the new one. If I had been
thinking about it a little harder, I might have thought to check if
the return value of the write call, 178 bytes, matched the length of
the file. (It does.) The unlink at the end is deleting the
semaphore file that System Settings created to prevent a second
process from trying to update the same file at the same time.
Supposing that this was the trace of the configuration update, the next section should be the secret sauce that tells the screen locker to look at the new configuration file. It looked like this:
3106 sendmsg(5, 0x7ffcf37e53b0, MSG_NOSIGNAL) = 168
3106 poll([?] 0x7ffcf37e5490, 1, 25000) = 1
3106 recvmsg(5, 0x7ffcf37e5390, MSG_CMSG_CLOEXEC) = 90
3106 recvmsg(5, 0x7ffcf37e5390, MSG_CMSG_CLOEXEC) = -1 EAGAIN (Resource temporarily unavailable)
3106 sendmsg(5, 0x7ffcf37e5770, MSG_NOSIGNAL) = 278
3106 sendmsg(5, 0x7ffcf37e5740, MSG_NOSIGNAL) = 128
There is very little to go on here, but none of it is inconsistent with the theory that this is the secret sauce, or even with the more advanced theory that it is the secret suace and that the secret sauce is a D-Bus request. But without seeing the contents of the messages, I seemed to be at a dead end.
Thrashing
Browsing random pages about the KDE screen locker, I learned that the lock screen configuration component could be run separately from the rest of System Settings. You use
kcmshell4 --list
to get a list of available components, and then
kcmshell4 screensaver
to run the screensaver component. I started running strace on this
command instead of on the entire System Settings app, with the idea
that if nothing else, the trace would be smaller and perhaps simpler,
and for some reason the missing strings appeared. That suggestive
block of code above turned out to be updating the configuration file, just
as I had suspected:
open("/home/mjd/.kde/share/config/kscreensaverrcQ13893.new", O_RDWR|O_CREAT|O_CLOEXEC, 0666) = 19
fcntl(19, F_SETFD, FD_CLOEXEC) = 0
chmod("/home/mjd/.kde/share/config/kscreensaverrcQ13893.new", 0600) = 0
fstat(19, {st_mode=S_IFREG|0600, st_size=0, ...}) = 0
write(19, "[ScreenSaver]\nActionBottomLeft=0\nActionBottomRight=0\nActionTopLeft=0\nActionTopRight=2\nEnabled=true\nLegacySaverEnabled=false\nPlasmaEnabled=false\nSaver=krandom.desktop\nTimeout=60\n", 177) = 177
fstat(19, {st_mode=S_IFREG|0600, st_size=177, ...}) = 0
close(19) = 0
rename("/home/mjd/.kde/share/config/kscreensaverrcQ13893.new", "/home/mjd/.kde/share/config/kscreensaverrc") = 0
unlink("/home/mjd/.kde/share/config/kscreensaverrc.lock") = 0
And the following secret sauce was revealed as:
sendmsg(7, {msg_name(0)=NULL, msg_iov(2)=[{"l\1\0\1\30\0\0\0\v\0\0\0\177\0\0\0\1\1o\0\25\0\0\0/org/freedesktop/DBus\0\0\0\6\1s\0\24\0\0\0org.freedesktop.DBus\0\0\0\0\2\1s\0\24\0\0\0org.freedesktop.DBus\0\0\0\0\3\1s\0\f\0\0\0GetNameOwner\0\0\0\0\10\1g\0\1s\0\0", 144}, {"\23\0\0\0org.kde.screensaver\0", 24}], msg_controllen=0, msg_flags=0}, MSG_NOSIGNAL) = 168
sendmsg(7, {msg_name(0)=NULL, msg_iov(2)=[{"l\1\1\1\206\0\0\0\f\0\0\0\177\0\0\0\1\1o\0\25\0\0\0/org/freedesktop/DBus\0\0\0\6\1s\0\24\0\0\0org.freedesktop.DBus\0\0\0\0\2\1s\0\24\0\0\0org.freedesktop.DBus\0\0\0\0\3\1s\0\10\0\0\0AddMatch\0\0\0\0\0\0\0\0\10\1g\0\1s\0\0", 144}, {"\201\0\0\0type='signal',sender='org.freedesktop.DBus',interface='org.freedesktop.DBus',member='NameOwnerChanged',arg0='org.kde.screensaver'\0", 134}], msg_controllen=0, msg_flags=0}, MSG_NOSIGNAL) = 278
sendmsg(7, {msg_name(0)=NULL, msg_iov(2)=[{"l\1\0\1\0\0\0\0\r\0\0\0j\0\0\0\1\1o\0\f\0\0\0/ScreenSaver\0\0\0\0\6\1s\0\23\0\0\0org.kde.screensaver\0\0\0\0\0\2\1s\0\23\0\0\0org.kde.screensaver\0\0\0\0\0\3\1s\0\t\0\0\0configure\0\0\0\0\0\0\0", 128}, {"", 0}], msg_controllen=0, msg_flags=0}, MSG_NOSIGNAL) = 128
sendmsg(7, {msg_name(0)=NULL,
msg_iov(2)=[{"l\1\1\1\206\0\0\0\16\0\0\0\177\0\0\0\1\1o\0\25\0\0\0/org/freedesktop/DBus\0\0\0\6\1s\0\24\0\0\0org.freedesktop.DBus\0\0\0\0\2\1s\0\24\0\0\0org.freedesktop.DBus\0\0\0\0\3\1s\0\v\0\0\0RemoveMatch\0\0\0\0\0\10\1g\0\1s\0\0",
144},
{"\201\0\0\0type='signal',sender='org.freedesktop.DBus',interface='org.freedesktop.DBus',member='NameOwnerChanged',arg0='org.kde.screensaver'\0",
134}]
(I had to tell give strace the -s 256 flag to tell it not to
truncate the string data to 32 characters.)
Binary gibberish
A lot of this is illegible, but it is clear, from the frequent
mentions of DBus, and from the names of D-Bus objects and methods,
that this is is D-Bus requests, as theorized. Much of it is binary
gibberish that we can only read if we understand the D-Bus line
protocol, but the object and method names are visible. For example,
consider this long string:
interface='org.freedesktop.DBus',member='NameOwnerChanged',arg0='org.kde.screensaver'
With qdbus I could confirm that there was a service named
org.freedesktop.DBus with an object named / that supported a
NameOwnerChanged method which expected three QString arguments.
Presumably the first of these was org.kde.screensaver and the others
are hiding in other the 134 characters that strace didn't expand.
So I may not understand the whole thing, but I could see that I was on
the right track.
That third line was the key:
sendmsg(7, {msg_name(0)=NULL,
msg_iov(2)=[{"… /ScreenSaver … org.kde.screensaver … org.kde.screensaver … configure …", 128}, {"", 0}],
msg_controllen=0,
msg_flags=0},
MSG_NOSIGNAL) = 128
Huh, it seems to be asking the screensaver to configure itself. Just
like I thought it should. But there was no configure method, so what
does that configure refer to, and how can I do the same thing?
But org.kde.screensaver was not quite the same path I had been using
to talk to the screen locker—I had been using
org.freedesktop.ScreenSaver, so I had qdbus list the methods at
this new path, and there was a configure method.
When I tested
qdbus org.kde.screensaver /ScreenSaver configure
I found that this made the screen locker take note of the updated configuration. So, problem solved!
(As far as I can tell, org.kde.screensaver and
org.freedesktop.ScreenSaver are completely identical. They each
have a configure method, but I had overlooked it—several times in a
row—earlier when I had gone over the method catalog for
org.freedesktop.ScreenSaver.)
The working script is almost identical to what I had yesterday:
timeout=${1:-3600}
perl -i -lpe 's/^Enabled=.*/Enabled=False/' $HOME/.kde/share/config/kscreensaverrc
qdbus org.freedesktop.ScreenSaver /ScreenSaver configure
sleep $timeout
perl -i -lpe 's/^Enabled=.*/Enabled=True/' $HOME/.kde/share/config/kscreensaverrc
qdbus org.freedesktop.ScreenSaver /ScreenSaver configure
That's not a bad way to fail, as failures go: I had a correct idea
about what was going on, my plan about how to solve my problem would
have worked, but I was tripped up by a trivium; I was calling
MainApplication.reparseConfiguration when I should have been calling
ScreenSaver.configure.
What if I hadn't been able to get strace to disgorge the internals
of the D-Bus messages? I think I would have gotten the answer anyway.
One way to have gotten there would have been to notice the configure
method documented in the method catalog printed out by qdbus. I
certainly looked at these catalogs enough times, and they are not very
large. I don't know why I never noticed it on my own. But I might
also have had the idea of spying on the network traffic through the
D-Bus socket, which is under /tmp somewhere.
I was also starting to tinker with dbus-send, which is like qdbus
but more powerful, and can post signals, which I think qdbus can't
do, and with gdbus, another D-Bus introspector. I would have kept
getting more familiar with these tools and this would have led
somewhere useful.
Or had I taken just a little longer to solve this, I would have
followed up on Sumana Harihareswara’s suggestion to look at
Bustle, which is
a utility that logs and traces D-Bus requests. It would certainly
have solved my problem, because it makes perfectly clear that clicking
that apply button invoked the configure method:

I still wish I knew why strace hadn't been able to print out those
strings through.
[Other articles in category /Unix] permanent link
Wed, 27 Jul 2016
Controlling KDE screen locking from a shell script
Lately I've started watching stuff on Netflix. Every time I do this, the screen locker kicks in sixty seconds in, and I have to unlock it, pause the video, and adjust the system settings to turn off the automatic screen locker. I can live with this.
But when the show is over, I often forget to re-enable the automatic screen locker, and that I can't live with. So I wanted to write a shell script:
#!/bin/sh
auto-screen-locker disable
sleep 3600
auto-screen-locker enable
Then I'll run the script in the background before I start watching, or at least after the first time I unlock the screen, and if I forget to re-enable the automatic locker, the script will do it for me.
The question is: how to write auto-screen-locker?
strace
My first idea was: maybe there is actually an auto-screen-locker
command, or a system-settings command, or something like that, which
was being run by the System Settings app when I adjusted the screen
locker from System Settings, and all I needed to do was to find out
what that command was and to run it myself.
So I tried running System Settings under strace -f and then looking
at the trace to see if it was execing anything suggestive.
It wasn't, and the trace was 93,000 lines long and frighting. Halfway
through, it stopped recording filenames and started recording their
string addresses instead, which meant I could see a lot of calls to
execve but not what was being execed. I got sidetracked trying to
understand why this had happened, and I never did figure it
out—something to do with a call to clone, which is like fork, but
different in a way I might understand once I read the man page.
The first thing the cloned process did was to call set_robust_list,
which I had never heard of, and when I looked for its man page I found
to my surprise that there was one. It begins:
NAME
get_robust_list, set_robust_list - get/set list of robust futexes
And then I felt like an ass because, of course, everyone knows all about the robust futex list, duh, how silly of me to have forgotten ha ha just kidding WTF is a futex? Are the robust kind better than regular wimpy futexes?
It turns out that Ingo Molnár wrote a lovely explanation of robust futexes which are actually very interesting. In all seriousness, do check it out.
I seem to have digressed. This whole section can be summarized in one sentence:
stracewas no help and took me a long way down a wacky rabbit hole.
Sorry, Julia!
Stack Exchange
The next thing I tried was Google search for kde screen locker. The
second or third link I followed was to this StackExchange question,
“What is the screen locking mechanism under
KDE?
It wasn't exactly what I was looking for but it was suggestive and
pointed me in the right direction. The crucial point in the answer
was a mention of
qdbus org.freedesktop.ScreenSaver /ScreenSaver Lock
When I saw this, it was like a new section of my brain coming on line. So many things that had been obscure suddenly became clear. Things I had wondered for years. Things like “What are these horrible
Object::connect: No such signal org::freedesktop::UPower::DeviceAdded(QDBusObjectPath)
messages that KDE apps are always spewing into my terminal?” But now the light was on.
KDE is built atop a toolkit called Qt, and Qt provides an interprocess
communication mechanism called “D-Bus”. The qdbus command, which I
had not seen before, is apparently for sending queries and commands on
the D-Bus. The arguments identify the recipient and the message you
are sending. If you know the secret name of the correct demon, and
you send it the correct secret command, it will do your bidding. (
The mystery message above probably has something to do with the app
using an invalid secret name as a D-Bus address.)
Often these sorts of address hierarchies work well in theory and then
fail utterly because there is no way to learn the secret names. The X
Window System has always had a feature called “resources” by which
almost every aspect of every application can be individually
customized. If you are running xweasel and want just the frame of
just the error panel of just the output window to be teal blue, you
can do that… if you can find out the secret names of the xweasel
program, its output window, its error panel, and its frame. Then you
combine these into a secret X resource name, incant a certain command
to load the new resource setting into the X server, and the next time
you run xweasel the one frame, and only the one frame, will be blue.
In theory these secret names are documented somewhere, maybe. In
practice, they are not documented anywhere. you can only extract them
from the source, and not only from the source of xweasel itself but
from the source of the entire widget toolkit that xweasel is linked
with. Good luck, sucker.
D-Bus has a directory
However! The authors of Qt did not forget to include a directory mechanism in D-Bus. If you run
qdbus
you get a list of all the addressable services, which you can grep for
suggestive items, including org.freedesktop.ScreenSaver. Then if
you run
qdbus org.freedesktop.ScreenSaver
you get a list of all the objects provided by the
org.freedesktop.ScreenSaver service; there are only seven. So you
pick a likely-seeming one, say /ScreenSaver, and run
qdbus org.freedesktop.ScreenSaver /ScreenSaver
and get a list of all the methods that can be called on this object, and their argument types and return value types. And you see for example
method void org.freedesktop.ScreenSaver.Lock()
and say “I wonder if that will lock the screen when I invoke it?” And then you try it:
qdbus org.freedesktop.ScreenSaver /ScreenSaver Lock
and it does.
That was the most important thing I learned today, that I can go
wandering around in the qdbus hierarchy looking for treasure. I
don't yet know exactly what I'll find, but I bet there's a lot of good stuff.
When I was first learning Unix I used to wander around in the filesystem looking at all the files, and I learned a lot that way also.
“Hey, look at all the stuff in
/etc! Huh, I wonder what's in/etc/passwd?”“Hey,
/etc/protocolshas a catalog of protocol numbers. I wonder what that's for?”“Hey, there are a bunch of files in
/usr/spool/mailnamed after users and the one with my name has my mail in it!”“Hey, the manuals are all under
/usr/man. I could grep them!”
Later I learned (by browsing in /usr/man/man7) that there was a
hier(7) man page that listed points of interest, including some I
had overlooked.
The right secret names
Everything after this point was pure fun of the “what happens if I
turn this knob” variety. I tinkered around with the /ScreenSaver
methods a bit (there are twenty) but none of them seemed to be quite
what I wanted. There is a
method uint Inhibit(QString application_name, QString reason_for_inhibit)
method which someone should be calling, because that's evidently what you call if you are a program playing a video and you want to inhibit the screen locker. But the unknown someone was delinquent and it wasn't what I needed for this problem.
Then I moved on to the /MainApplication object and found
method void org.kde.KApplication.reparseConfiguration()
which wasn't quite what I was looking for either, but it might do: I
could perhaps modify the configuration and then invoke this method. I
dimly remembered that KDE keeps configuration files under
$HOME/.kde, so I ls -la-ed that and quickly found
share/config/kscreensaverrc, which looked plausible from the
outside, and more plausible when I saw what was in it:
Enabled=True
Timeout=60
among other things. I hand-edited the file to change the 60 to
243, ran
qdbus org.freedesktop.ScreenSaver /MainApplication reparseConfiguration
and then opened up the System Settings app. Sure enough, the System
Settings app now reported that the lock timeout setting was “4
minutes”. And changing Enabled=True to Enabled=False and back
made the System Settings app report that the locker was enabled or
disabled.
The answer
So the script I wanted turned out to be:
timeout=${1:-3600}
perl -i -lpe 's/^Enabled=.*/Enabled=False/' $HOME/.kde/share/config/kscreensaverrc
qdbus org.freedesktop.ScreenSaver /MainApplication reparseConfiguration
sleep $timeout
perl -i -lpe 's/^Enabled=.*/Enabled=True/' $HOME/.kde/share/config/kscreensaverrc
qdbus org.freedesktop.ScreenSaver /MainApplication reparseConfiguration
Problem solved, but as so often happens, the journey was more important than the destination.
I am greatly looking forward to exploring the D-Bus hierarchy and sending all sorts of inappropriate messages to the wrong objects.
Just before he gets his ass kicked by Saruman, that insufferable know-it-all Gandalf says “He who breaks a thing to find out what it is has left the path of wisdom.” If I had been Saruman, I would have kicked his ass at that point too.
Addendum
Right after I posted this, I started watching Netflix. The screen locker cut in after sixty seconds. “Aha!” I said. “I'll run my new script!”
I did, and went back to watching. Sixty seconds later, the screen
locker cut in again. My script doesn't work! The System Settings app
says the locker has been disabled, but it's mistaken. Probably it's only
reporting the contents of the configuration file that I edited, and
the secret sauce is still missing. The System Settings app does
something to update the state of the locker when I click that “Apply”
button, and I thought that my qdbus command was doing the same
thing, but it seems that it isn't.
I'll figure this out, but maybe not today. Good night all!
[ Addendum 20160728: I figured it out the next day ]
[ Addendum 20160729: It has come to my attention that there is
actually a program called xweasel. ]
[Other articles in category /Unix] permanent link
Thu, 21 Jul 2016
A hack for getting the email address Git will use for a commit
Today I invented a pretty good hack.
Suppose I have branch topic checked out. It often happens that I want to
git push origin topic:mjd/topic
which pushes the topic branch to the origin repository, but on
origin it is named mjd/topic instead of topic. This is a good
practice when many people share the same repository. I wanted to write
a program that would do this automatically.
So the question arose, how should the program figure out the mjd
part? Almost any answer would be good here: use some selection of
environment variables, the current username, a hard-wired default, and
the local part of Git's user.email configuration setting, in some
order. Getting user.email is easy (git config get user.email) but
it might not be set and then you get nothing. If you make a commit
but have no user.email, Git doesn't mind. It invents an address
somehow. I decided that I would like my program to to do exactly what
Git does when it makes a commit.
But what does Git use for the committer's email address if there is
no user.email set? This turns out to be complicated. It consults
several environment variables in some order, as I suggested before.
(It is documented in
git-commit-tree if you
are interested.) I did not want to duplicate Git's complicated
procedure, because it might change, and because duplicating code is a
sin. But there seemed to be no way to get Git to disgorge this value,
short of actually making a commit and examining it.
So I wrote this command, which makes a commit and examines it:
git log -1 --format=%ce $(git-commit-tree HEAD^{tree} < /dev/null)
This is extremely weird, but aside from that it seems to have no concrete drawbacks. It is pure hack, but it is a hack that works flawlessly.
What is going on here? First, the $(…) part:
git-commit-tree HEAD^{tree} < /dev/null
The git-commit-tree command is what git-commit uses to actually
create a commit. It takes a tree object, reads a commit message from
standard input, writes a new commit object, and prints its SHA1 hash
on standard output. Unlike git-commit, it doesn't modify the index
(git-commit would use git-write-tree to turn the index into a tree
object) and it doesn't change any of the refs (git-commit would
update the HEAD ref to point to the new commit.) It just creates
the commit.
Here we could use any tree, but the tree of the HEAD commit is
convenient, and HEAD^{tree} is its name. We supply an empty commit
message from /dev/null.
Then the outer command runs:
git log -1 --format=%ce $(…)
The $(…) part is replaced by the SHA1 hash of the commit we just
created with git-commit-tree. The -1 flag to git-log gets the
log information for just this one commit, and the --format=%ce tells
git-log to print out just the committer's email address, whatever it
is.
This is fast—nearly instantaneous—and cheap. It doesn't change the state of the repository, except to write a new object, which typically takes up 125 bytes. The new commit object is not attached to any refs and so will be garbage collected in due course. You can do it in the middle of a rebase. You can do it in the middle of a merge. You can do it with a dirty index or a dirty working tree. It always works.
(Well, not quite. It will fail if run in an empty repository, because
there is no HEAD^{tree} yet. Probably there are some other
similarly obscure failure modes.)
I called the shortcut git-push program
git-pusho
but I dropped the email-address-finder into
git-get,
which is my storehouse of weird “How do I find out X” tricks.
I wish my best work of the day had been a little bit more significant, but I'll take what I can get.
[ Addendum: Twitter user @shachaf has reminded me that the right way to do this is
git var GIT_COMMITTER_IDENT
which prints out something like
Mark Jason Dominus (陶敏修) <mjd@plover.com> 1469102546 -0400
which you can then parse. @shachaf also points out that a Stack Overflow discussion of this very question contains a comment suggesting the same weird hack! ]
[Other articles in category /prog] permanent link
Thu, 14 Jul 2016
Surprising reasons to use a syntax-coloring editor
[ Danielle Sucher reminded me of this article I wrote in 1998, before I had a blog, and I thought I'd repatriate it here. It should be interesting as a historical artifact, if nothing else. Thanks Danielle! ]
I avoided syntax coloring for years, because it seemed like a pretty stupid idea, and when I tried it, I didn't see any benefit. But recently I gave it another try, with Ilya Zakharevich's `cperl-mode' for Emacs. I discovered that I liked it a lot, but for surprising reasons that I wasn't expecting.
I'm not trying to start an argument about whether syntax coloring is good or bad. I've heard those arguments already and they bore me to death. Also, I agree with most of the arguments about why syntax coloring is a bad idea. So I'm not trying to argue one way or the other; I'm just relating my experiences with syntax coloring. I used to be someone who didn't like it, but I changed my mind.
When people argue about whether syntax coloring is a good idea or not, they tend to pull out the same old arguments and dust them off. The reasons I found for using syntax coloring were new to me; I'd never seen anyone mention them before. So I thought maybe I'd post them here.
Syntax coloring is when the editor understands something about the
syntax of your program and displays different language constructs in
different fonts. For example, cperl-mode displays strings in
reddish brown, comments in a sort of brick color, declared variables
(in my) in gold, builtin function names (defined) in green,
subroutine names in blue, labels in teal, and keywords (like my and
foreach) in purple.
The first thing that I noticed about this was that it was easier to recognize what part of my program I was looking at, because each screenful of the program had its own color signature. I found that I was having an easier time remembering where I was or finding that parts I was looking for when I scrolled around in the file. I wasn't doing this consciously; I couldn't describe the color scheme any particular part of the program was, but having red, gold, and purple blotches all over made it easier to tell parts of the program apart.
The other surprise I got was that I was having more fun programming. I felt better about my programs, and at the end of the day, I felt better about the work I had done, just because I'd spent the day looking at a scoop of rainbow sherbet instead of black and white. It was just more cheerful to work with varicolored text than monochrome text. The reason I had never noticed this before was that the other coloring editors I used had ugly, drab color schemes. Ilya's scheme won here by using many different hues.
I haven't found many of the other benefits that people say they get from syntax coloring. For example, I can tell at a glance whether or not I failed to close a string properly—unless the editor has screwed up the syntax coloring, which it does often enough to ruin the benefit for me. And the coloring also slows down the editor. But the two benefits I've described more than outweigh the drawbacks for me. Syntax coloring isn't a huge win, but it's definitely a win.
If there's a lesson to learn from this, I guess it's that it can be valuable to revisit tools that you rejected, to see if you've changed your mind. Nothing anyone said about it was persuasive to me, but when I tried it I found that there were reasons to do it that nobody had mentioned. Of course, these reasons might not be compelling for anyone else.
Addenda 2016
Looking back on this from a distance of 18 years, I am struck by the following thoughts:
Syntax highlighting used to make the editor really slow. You had to make a real commitment to using it or not. I had forgotten about that. Another victory for Moore’s law!
Programmers used to argue about it. Apparently programmers will argue about anything, no matter how ridiculous. Well okay, this is not a new observation. Anyway, this argument is now finished. Whether people use it or not, they no longer find the need to argue about it. This is a nice example that sometimes these ridiculous arguments eventually go away.
I don't remember why I said that syntax highlighting “seemed like a pretty stupid idea”, but I suspect that I was thinking that the wrong things get highlighted. Highlighters usually highlight the language keywords, because they're easy to recognize. But this is like highlighting all the generic filler words in a natural language text. The words you want to see are exactly the opposite of what is typically highlighted.
Syntax highlighters should be highlighting the semantic content like expression boundaries, implied parentheses, boolean subexpressions, interpolated variables and other non-apparent semantic features. I think there is probably a lot of interesting work to be done here. Often you hear programmers say things like “Oh, I didn't see the that the trailing comma was actually a period.” That, in my opinion, is the kind of thing the syntax highlighter should call out. How often have you heard someone say “Oh, I didn't see that
whilethere”?I have been misspelling “arguments” as “argmuents” for at least 18 years.
[Other articles in category /prog] permanent link
Tue, 12 Jul 2016
A simple but difficult arithmetic puzzle
Lately my kids have been interested in puzzles of this type: You are given a sequence of four digits, say 1,2,3,4, and your job is to combine them with ordinary arithmetic operations (+, -, ×, and ÷) in any order to make a target number, typically 24. For example, with 1,2,3,4, you can go with $$((1+2)+3)×4 = 24$$ or with $$4×((2×3)×1) = 24.$$
We were stumped trying to make 6,6,5,2 total 24, so I hacked up a solver; then we felt a little foolish when we saw the solutions, because it is not that hard. But in the course of testing the solver, I found the most challenging puzzle of this type that I've ever seen. It is:
Given 6,6,5,2, make 17.
There are no underhanded tricks. For example, you may not concatenate 2 and 5 to make 25; you may not say !!6÷6=1!! and !!5+2=7!! and concatenate 1 and 7 to make !!17!!; you may not interpret the 17 as a base 12 numeral, etc.
I hope to write a longer article about solvers in the next week or so.
[ Addendum 20170305: The next week or so, ha ha. Anyway, here it is. ]
[Other articles in category /math] permanent link
Mon, 11 Jul 2016
Addenda to recent articles 201607
Here are some notes on posts from the last couple of months that I couldn't find better places for.
I wrote a long article about tracking down a system bug. At some point I determined that the problem was related to Perl, and asked Frew Schmidt for advice. He wrote up the details of his own investigation, which pick up where mine ended. Check it out. I 100% endorse his lament about
ltrace.There was a Hacker News discussion about that article. One participant asked a very pertinent question:
I read this, but seemed to skip over the part where he explains why this changed suddenly, when the behavior was documented?
What changed to make the perl become capable whereas previously it lacked the low port capability?
So far, we don't know! Frew told me recently that he thinks the
TMPDIR-losing has been going on for months and that whatever precipitated my problem is something else.In my article on the Greek clock, I guessed a method for calculating the (approximate) maximum length of the day from the latitude: $$ A = 360 \text{ min}\cdot(1-\cos L).$$
Sean Santos of UCAR points out that this is inaccurate close to the poles. For places like Philadelphia (40° latitude) it is pretty close, but it fails completely for locations north of the Arctic Circle. M. Santos advises instead:
$$ A = 360 \text{ min}\cdot \frac{2}{\pi}\cdot \sin^{-1}(\tan L\cdot \tan\epsilon)$$
where ε is the axial tilt of the Earth, approximately 23.4°. Observe that when !!L!! is above the Arctic Circle (or below the Antarctic) we have !!\tan L \cdot \tan \epsilon > 1!! (because !!\frac1{\tan x} = \tan(90^\circ - x)!!) so the arcsine is undefined, and we get no answer.
[Other articles in category /addenda] permanent link
Fri, 01 Jul 2016
Don't tug on that, you never know what it might be attached to
This is a story about a very interesting bug that I tracked down yesterday. It was causing a bad effect very far from where the bug actually was.
emacsclient
The emacs text editor comes with a separate utility, called
emacsclient, which can communicate with the main editor process and
tell it to open files for editing. You have your main emacs
running. Then somewhere else you run the command
emacsclient some-files...
and it sends the main emacs a message that you want to edit
some-files. Emacs gets the message and pops up new windows for editing
those files. When you're done editing some-files you tell Emacs, by
typing C-# or something, it
it communicates back to emacsclient that the editing is done, and
emacsclient exits.
This was more important in the olden days when Emacs was big and bloated and took a long time to start up. (They used to joke that “Emacs” was an abbreviation for “Eight Megs And Constantly Swapping”. Eight megs!) But even today it's still useful, say from shell scripts that need to run an editor.
Here's the reason I was running it. I have a very nice shell script,
called also, that does something like this:
- Interpret command-line arguments as patterns
- Find files matching those patterns
- Present a menu of the files
- Wait for me to select files of interest
- Run
emacsclienton the selected files
It is essentially a wrapper around
menupick,
a menu-picking utility I wrote which has seen use as a component of
several other tools.
I can type
also Wizard
in the shell and get a menu of the files related to the wizard, select the ones I actually want to edit, and they show up in Emacs. This is more convenient than using Emacs itself to find and open them. I use it many times a day.
Or rather, I did until this week, when it suddenly stopped working.
Everything ran fine until the execution of emacsclient, which would
fail, saying:
emacsclient: can't find socket; have you started the server?
(A socket is a facility that enables interprocess communication, in
this case between emacs and emacsclient.)
This message is familiar. It usually means that I have forgotten to
tell Emacs to start listening for emacsclient, by running M-x
server-start. (I should have Emacs do this when it starts up, but I
don't. Why not? I'm not sure.) So the first time it happened I went
to Emacs and ran M-x server-start. Emacs announced that it had
started the server, so I reran also. And the same thing happened.
emacsclient: can't find socket; have you started the server?
Finding the socket
So the first question is: why can't emacsclient find the socket?
And this resolves naturally into two subquestions: where is the
socket, and where is emacsclient looking?
The second one is easily answered; I ran strace emacsclient (hi
Julia!) and saw that the last interesting thing emacsclient did
before emitting the error message was
stat("/mnt/tmp/emacs2017/server", 0x7ffd90ec4d40) = -1 ENOENT (No such file or directory)
which means it's looking for the socket at /mnt/tmp/emacs2017/server
but didn't find it there.
The question of where Emacs actually put the socket file was a little
trickier. I did not run Emacs under strace because I felt sure that
the output would be voluminous and it would be tedious to grovel over
it.
I don't exactly remember now how I figured this out, but I think now
that I probably made an educated guess, something like: emacsclient
is looking in /mnt/tmp; this seems unusual. I would expect the
socket to be under /tmp. Maybe it is under /tmp? So I looked
under /tmp and there it was, in /tmp/emacs2017/server:
srwx------ 1 mjd mjd 0 Jun 27 11:43 /tmp/emacs2017/server
(The s at the beginning there means that the file is a “Unix-domain
socket”. A socket is an endpoint for interprocess communication. The
most familiar sort is a TCP socket, which has a TCP address, and which
enables communication over the internet. But since ancient times Unix
has also supported Unix-domain sockets, which enable communication
between two processes on the same machine. Instead of TCP addresses,
such sockets are addressed using paths in the filesystem, in this case
/tmp/emacs2017/server. When the server creates such a socket, it
appears in the filesystem as a special type of file, as here.)
I confirmed that this was the correct file by typing M-x
server-force-delete in Emacs; this immediately caused
/tmp/emacs2017/server to disappear. Similarly M-x server-start
made it reappear.
Why the disagreement?
Now the question is: Why is emacsclient looking for the socket under
/mnt/tmp when Emacs is putting it in /tmp? They used to
rendezvous properly; what has gone wrong? I recalled that there was
some environment variable for controlling where temporary files are
put, so I did
env | grep mnt
to see if anything relevant turned up. And sure enough there was:
TMPDIR=/mnt/tmp
When programs want to create tmporary files and directories, they normally do it in /tmp. But
if there is a TMPDIR setting, they use that directory instead. This
explained why emacsclient was looking for
/mnt/tmp/emacs2017/socket. And the explanation for why Emacs itself
was creating the socket in /tmp seemed clear: Emacs was failing to
honor the TMPDIR setting.
With this clear explanation in hand, I began to report the bug in
Emacs, using M-x report-emacs-bug. (The folks in the #emacs IRC
channel on Freenode suggested this. I had a bad
experience last time I tried
#emacs, and then people mocked me for even trying to get useful
information out of IRC. But this time it went pretty well.)
Emacs popped up a buffer with full version information and invited me to write down the steps to reproduce the problem. So I wrote down
% export TMPDIR=/mnt/tmp
% emacs
and as I did that I ran those commands in the shell.
Then I wrote
In Emacs:
M-x getenv TMPDIR
(emacs claims there is no such variable)
and I did that in Emacs also. But instead of claiming there was no
such variable, Emacs cheerfully informed me that the value of TMPDIR
was /mnt/tmp.
(There is an important lesson here! To submit a bug report, you find a minimal demonstration. But then you also try the minimal demonstration exactly as you reported it. Because of what just happened! Had I sent off that bug report, I would have wasted everyone else's time, and even worse, I would have looked like a fool.)
My minimal demonstration did not demonstrate. Something else was going on.
Why no TMPDIR?
This was a head-scratcher. All I could think of was that
emacsclient and Emacs were somehow getting different environments,
one with the TMPDIR setting and one without. Maybe I had run them
from different shells, and only one of the shells had the setting?
I got on a sidetrack at this point to find out why TMPDIR was set in
the first place; I didn't think I had set it. I looked for it in
/etc/profile, which is the default Bash startup instructions, but it
wasn't there. But I also noticed an /etc/profile.d which seemed
relevant. (I saw later that the /etc/profile contained instructions
to load everything under /etc/profile.d.) And when I grepped for
TMPDIR in the profile.d files, I found that it was being set by
/etc/profile.d/ziprecruiter_environment.sh, which the sysadmins had
installed. So that mystery at least was cleared up.
That got me on a second sidetrack, looking through our Git history for
recent changes involving TMPDIR. There weren't any, so that was a
dead end.
I was still puzzled about why Emacs sometimes got the TMPDIR setting
and sometimes not. That's when I realized that my original Emacs
process, the one that had failed to rendezvous with emacsclient,
had not been started in the usual way. Instead of simply running
emacs, I had run
git re-edit
which invokes Git, which then runs
/home/mjd/bin/git-re-edit
which is a Perl program I wrote that does a bunch of stuff to figure
out which files I was editing recently and then execs emacs to edit
them some more. So there are several programs here that could be
tampering with the environment and removing the TMPDIR setting.
To more accurately point the finger of blame, I put some diagnostics
into the git-re-edit program to have it print out the value of
TMPDIR. Indeed, git-re-edit reported that TMPDIR was unset.
Clearly, the culprit was Git, which must have been removing TMPDIR
from the environment before invoking my Perl program.
Who is stripping the environment?
To confirm this conclusion, I created a tiny shell script,
/home/mjd/bin/git-env, which simply printed out the environment, and
then I ran git env, which tells Git to find git-env and run it.
If the environment it printed were to omit TMPDIR, I would know Git
was the culprit. But TMPDIR was in the output.
So I created a Perl version of git-env, called git-perlenv, which
did the same thing, and I ran it via git perlenv. And this time
TMPDIR was not in the output. I ran diff on the outputs of git
env and git perlenv and they were identical—except that git
perlenv was missing TMPDIR.
So it was Perl's fault! And I verified this by running perl
/home/mjd/bin/git-re-edit directly, without involving Git at all.
The diagnostics I had put in reported that TMPDIR was unset.
WTF Perl?
At this point I tried getting rid of get-re-edit itself, and ran the
one-line program
perl -le 'print $ENV{TMPDIR}'
which simply runs Perl and tells it to print out the value of the
TMPDIR environment variable. It should print /mnt/tmp, but instead
it printed the empty string. This is a smoking gun, and Perl no
longer has anywhere to hide.
The mystery is not cleared up, however. Why was Perl doing this?
Surely not a bug; someone else would have noticed such an obvious bug
sometime in the past 25 years. And it only failed for TMPDIR, not
for other variables. For example
FOO=bar perl -le 'print $ENV{FOO}'
printed out bar as one would expect. This was weird: how could
Perl's environment handling be broken for just the TMPDIR variable?
At this point I got Rik Signes and Frew Schmidt to look at it with me. They confirmed that the problem was not in Perl generally, but just in this Perl. Perl on other systems did not display this behavior.
I looked in the output of perl -V, which says what version of Perl
you are using and which patches have been applied, and wasted a lot of
time looking into
CVE-2016-2381,
which seemed relevant. But it turned out to be a red herring.
Working around the problem, 1.
While all this was going on I was looking for a workaround. Finding
one is at least as important as actually tracking down the problem
because ultimately I am paid to do something other than figure out why
Perl is losing TMPDIR. Having a workaround in hand means that when
I get sick and tired of looking into the underlying problem I can
abandon it instantly instead of having to push onward.
The first workaround I found was to not use the Unix-domain socket. Emacs has an option to use a TCP socket instead, which is useful on systems that do not support Unix-domain sockets, such as non-Unix systems. (I am told that some do still exist.)
You set the server-use-tcp variable to a true value, and when you
start the server, Emacs creates a TCP socket and writes a description
of it into a “server file”, usually ~/.emacs.d/server/server. Then
when you run emacsclient you tell it to connect to the socket that
is described in the file, with
emacsclient --server-file=~/.emacs.d/server/server
or by setting the EMACS_SERVER_FILE environment variable. I tried
this, and it worked, once I figured out the thing about
server-use-tcp and what a “server file” was. (I had misunderstood
at first, and thought that “server file” meant the Unix-domain socket
itself, and I tried to get emacsclient to use the right one by
setting EMACS_SERVER_FILE, which didn't work at all. The resulting
error message was obscure enough to lead me to IRC to ask about it.)
Working around the problem, 2.
I spent quite a while looking for an environment variable analogous to
EMACS_SERVER_FILE to tell emacsclient where the Unix-domain socket
was. But while there is a --socket-name command-line argument to
control this, there is inexplicably no environment variable. I hacked
my also command (responsible for running emacsclient) to look for
an environment variable named EMACS_SERVER_SOCKET, and to pass its
value to emacsclient --socket-name if there was one. (It probably
would have been better to write a wrapper for emacsclient, but I
didn't.) Then I put
EMACS_SERVER_SOCKET=$TMPDIR/emacs$(id -u)/server
in my Bash profile, which effectively solved the problem. This set
EMACS_SERVER_SOCKET to /mnt/tmp/emacs2017/server whenever I
started a new shell. When I ran also it would notice the setting
and pass it along to emacsclient with --socket-name, to tell
emacsclient to look in the right place. Having set this up I could
forget all about the original problem if I wanted to.
But but but WHY?
But why was Perl removing TMPDIR from the environment? I didn't
figure out the answer to this; Frew took it to the #p5p IRC channel
on perl.org, where the answer was eventually tracked down by Matthew
Horsfall and Zefrem.
The answer turned out to be quite subtle. One of the classic attacks
that can be mounted against a process with elevated privileges is as
follows. Suppose you know that the program is going to write to a
temporary file. So you set TMPDIR beforehand and trick it into
writing in the wrong place, possibly overwriting or destroying
something important.
When a program is loaded into a process, the dynamic loader does the
loading. To protect against this attack, the loader checks to see if
the program it is going to run has elevated privileges, say because it
is setuid, and if so it sanitizes the process’ environment to prevent
the attack. Among other things, it removes TMPDIR from the
environment.
I hadn't thought of exactly this, but I had thought of something like
it: If Perl detects that it is running setuid, it enables
a secure mode which, among other things, sanitizes the environment.
For example, it ignores the PERL5LIB environment variable that
normally tells it where to look for loadable modules, and instead
loads modules only from a few compiled-in trustworthy directories. I
had checked early on to see if this was causing the TMPDIR problem,
but the perl executable was not setuid and Perl was not running in
secure mode.
But Linux supports a feature called “capabilities”, which is a sort of
partial superuser privilege. You can give a program some of the
superuser's capabilities without giving away the keys to the whole
kingdom. Our systems were configured to give perl one extra
capability, of binding to low-numbered TCP ports, which is normally
permitted only to the superuser. And when the dynamic loader ran
perl, it saw this additional capability and removed TMPDIR from
the environment for safety.
This is why Emacs had the
TMPDIRsetting when run from the command line, but not when run viagit-re-edit.
Until this came up, I had not even been aware that the “capabilities” feature existed.
A red herring
There was one more delightful confusion on the way to this happy ending. When Frew found out that it was just the Perl on my development machine that was misbehaving, he tried logging into his own, nearly identical development machine to see if it misbehaved in the same way. It did, but when he ran a system update to update Perl, the problem went away. He told me this would fix the problem on my machine. But I reported that I had updated my system a few hours before, so there was nothing to update!
The elevated capabilities theory explained this also. When Frew
updated his system, the new Perl was installed without the elevated
capability feature, so the dynamic loader did not remove TMPDIR from
the environment.
When I had updated my system earlier, the same thing happened. But as soon as the update was complete, I reloaded my system configuration, which reinstated the capability setting. Frew hadn't done this.
Summary
- The system configuration gave
perla special capability - so the dynamic loader sanitized its environment
- so that when
perlranemacs, - the Emacs process didn't have the
TMPDIRenvironment setting - which caused Emacs to create its listening socket in the usual place
- but because
emacsclientdid get the setting, it looked in the wrong place
Conclusion
This computer stuff is amazingly complicated. I don't know how anyone gets anything done.
[ Addendum 20160709: Frew Schmidt has written up the same incident, but covers different ground than I do. ]
[ Addendum 20160709: A Hacker News comment asks what changed to cause
the problem? Why was Perl losing TMPDIR this week but not the week
before? Frew and I don't know! ]
[Other articles in category /tech] permanent link
Tue, 21 Jun 2016
The Greek clock
In former times, the day was divided into twenty-four hours, but they
were not of equal length. During the day, an hour was one-twelfth of
the time from sunrise to sunset; during the night, it was one-twelfth
of the time from sunset to sunrise. So the daytime hours were all
equal, and the nighttime hours were all equal, but the daytime hours
were not equal to the nighttime hours, except on the equinoxes, or at
the equator. In the summer, the day hours were longer and the night
hours shorter, and in the winter, vice versa.
Some years ago I suggested, as part of the Perl Quiz of the Week, that people write a greektime program that printed out the time according to a clock that divided the hours in this way. You can, of course, spend a lot of time and effort downloading and installing CPAN astronomical modules to calculate the time of sunrise and sunset, and reading manuals and doing a whole lot of stuff. But if you are content with approximate times, you can use some delightful shortcuts.
First, let's establish what the problem is. We're going to take the conventional time labels ("12:35" and so forth) and adjust them so that half of them take up the time from sunrise to sunset and the other half go from sunset to sunrise. Some will be stretched, and some squeezed. 01:00 in this new system will no longer mean "3600 seconds after midnight", but rather "exactly 7/12 of the way between sunset and sunrise".
To do this, we'll introduce a new daily calendar with the following labels:
| Midnight | Sunrise | Noon | Sunset | Midnight |
| 00:00 | 06:00 | 12:00 | 18:00 | 24:00 |
We'll assume that noon (when the sun is directly overhead) occurs at 12:00 and that midnight occurs at 00:00. (Or 24:00, which is the same thing.) This is pretty close to the truth anyway, although it is screwed up by such oddities as time zones and the like.
On the equinoxes, the sun rises around 06:00 and sets around 18:00, again ignoring time zones and the like. (If you live at the edge of a time zone, especially a large one like U.S. Central Time, local civil noon does not occur at solar noon, so these calculations require adjustments.) On the equinoxes the normal calendar corresponds to the Greek one, because the day and the night are each exactly twelve standard hours long. (The day from 06:00 to 18:00, and the night from 18:00 to 06:00 the following day.) In the winter, the sun rises later and sets earlier; in the summer it rises earlier and sets later. So let's take 06:00 to be the label for the time of sunrise in the Greek clock all year round; 18:00 is similarly the time of sunset in the Greek clock all year round.
With these conventions, it turns out that it's rather easy to calculate the approximate time of sunrise for any day of the year. You need two magic numbers, A and d. The number d is the number of days that have elapsed since the vernal equinox, which is around 19 March (or 19 September, if you live in the southern hemisphere.) The number A is a bit trickier, and I will return to it shortly.
Once you have the two numbers, you just plug into the formula:
$$\text{Sunrise} = \text{06:00} - A \sin {2\pi d\over 365.2422}$$
The tricky part is the magic number A; it depends on your latitude. At the equator, it is 0. And you can probably calculate it directly from the latitude, if you happen to know your latitude. I do know my latitude (Philadelphia is conveniently located at almost exactly 40° N) but I failed observational astronomy classes twice, so I don't know how to do the necessary calculation.(Actually it occurs to me now that !!A = 360 \text{ min}\times (1-\cos L)!!, should work, where L is the absolute latitude. For the equator (!!L = 90^\circ!!), this gives 0, as it should, and for Philadelphia it gives !!360\text{ min}\cdot (1- \cos 40^\circ) \approx 84.22\text{ min}!!, which is just about right.)
However, there's another trick you can use even if you don't know your latitude. If you know the time of sunset on the summer solstice, you can calculate A quite easily:
$$A = {\text{ Sunset on summer solstice}} - \text{18:00}$$
Does that really help? If it were October, it might not. But the summer solstice is today. So all you have to do is to look out the window in the evening and notice when the sun seems to be going down. Then plug the time into the formula. (Or you can remember what happened yesterday, or wait until tomorrow; the time of sunset hardly changes at all this time of year, by only a few seconds per day. Or you could look at the front page of a daily newspaper, which will also tell you the time of sunset.)
The sun went down here around 20:30 today, but that is really 19:30
because of
 daylight
saving time, so we get A = 19:30 -
18:00 = 90 minutes, which happily agrees with the 84.22 we got earlier by a
different method. Then the time of sunrise in Philadelphia d
days after the vernal equinox is
$$\text{Sunrise} =
\text{06:00} - 90\text{ min}\cdot \sin {2\pi d\over 365.2422}$$
Today is June 21, which is (counts on fingers) about 31+30+31 = 92
days after the vernal equinox which was around March 21. So notice
that the formula above involves !!\sin{2\pi\cdot 92\over 365.2422}
\approx \sin{\frac\pi 2} = 1!! because 92 is just about one-fourth of
365.2422—that is, today is just about a quarter of a year after the
vernal equinox. So the formula says that sunrise ought to be about
04:30, or, because of
daylight saving time, that's 05:30 local civil time. This time of
year the night is only 9 standard hours long, so the Greek nighttime
hour is !!\frac9{12}!! standard hours long, or 45 minutes. Right now
it's 22:43 daylight time, which is 133 standard minutes past sundown,
or just about 3 Greek nighttime hours. So the Greek time is close to
9 PM. In another 2:15 standard hours another 3 Greek hours will have
elapsed and it will be Greek midnight; this coincides with standard
midnight, which is 01:00 local civil time because of daylight saving.
daylight
saving time, so we get A = 19:30 -
18:00 = 90 minutes, which happily agrees with the 84.22 we got earlier by a
different method. Then the time of sunrise in Philadelphia d
days after the vernal equinox is
$$\text{Sunrise} =
\text{06:00} - 90\text{ min}\cdot \sin {2\pi d\over 365.2422}$$
Today is June 21, which is (counts on fingers) about 31+30+31 = 92
days after the vernal equinox which was around March 21. So notice
that the formula above involves !!\sin{2\pi\cdot 92\over 365.2422}
\approx \sin{\frac\pi 2} = 1!! because 92 is just about one-fourth of
365.2422—that is, today is just about a quarter of a year after the
vernal equinox. So the formula says that sunrise ought to be about
04:30, or, because of
daylight saving time, that's 05:30 local civil time. This time of
year the night is only 9 standard hours long, so the Greek nighttime
hour is !!\frac9{12}!! standard hours long, or 45 minutes. Right now
it's 22:43 daylight time, which is 133 standard minutes past sundown,
or just about 3 Greek nighttime hours. So the Greek time is close to
9 PM. In another 2:15 standard hours another 3 Greek hours will have
elapsed and it will be Greek midnight; this coincides with standard
midnight, which is 01:00 local civil time because of daylight saving.
Here's code for greektime that you can run where you to find out the current Greek time. I hereby place this program in the public domain.
#!/usr/bin/perl
#
# Calculate local time in fictitious Greek clock
# http://blog.plover.com/calendar/Greek-clock.html
# Author: Mark Jason Dominus (mjd@plover.com)
# This program is in the public domain.
#
my $PI = atan2(0, -1);
use Getopt::Std;
my %opt;
getopts('l:s:', \%opt) or usage();
my $A;
if ($opt{l} =~ /\d/) {
$A = 360 * 60 * (1-cos(radians($opt{l})));
} elsif ($opt{s} =~ /:/) {
my ($hr, $mn) = split /:/, $opt{s};
$A = (($hr - 18) * 60 + $mn) * 60;
} else {
usage();
}
my $time = time;
my $days_since_equinox = ($time - 1047950185)/86400;
my $days_per_year = 365.2422;
my $sunrise_adj = $A * sin($days_since_equinox / $days_per_year
* 2 * $PI );
my $length_of_daytime = 12 * 3600 + 2 * $sunrise_adj;
my $length_of_nighttime = 12 * 3600 - 2 * $sunrise_adj;
my $time_of_sunrise = 6 * 3600 - $sunrise_adj;
my $time_of_sunset = 18 * 3600 + $sunrise_adj;
my ($gh, $gm) = time_to_greek($time);
my ($h, $m) = (localtime($time))[2,1];
printf "Standard: %2d:%02d\n", $h, $m;
printf " Greek: %2d:%02d\n", $gh, $gm;
sub time_to_greek {
my ($epoch_time) = shift;
my $time_of_day;
{ my ($h, $m, $s, $dst) = (localtime($epoch_time))[2,1,0,8];
$time_of_day = ($h-$dst) * 3600 + $m * 60 + $s;
}
my ($greek, $hour, $min);
if ($time_of_day < $time_of_sunrise) {
# change early morning into night
$time_of_day += 24 * 3600;
}
if ($time_of_day < $time_of_sunset) {
# day
my $diff = $time_of_day - $time_of_sunrise;
$greek = 6 + ($diff / $length_of_daytime) * 12;
} else {
# night
my $diff = $time_of_day - $time_of_sunset;
$greek = 18 + ($diff / $length_of_nighttime) * 12;
}
$hour = int($greek);
$min = int(60 * ($greek - $hour));
($hour, $min);
}
sub radians {
my ($deg) = @_;
return $deg * 2 * $PI / 360;
}
sub usage {
print STDERR "Usage: greektime [ -l latitude ] [ -s summer_solstice_sunset ]
One of latitude or sunset time must be given.
Latitude should be in degrees north of the equator.
(Negative for southern hemisphere)
Sunset time should be given in the form '19:37' in local STANDARD time.
(Southern hemisphere should use the WINTER solstice.)
";
exit 2;
}
This article has been in the works since January of 2007, but I missed
the deadline on 18 consecutive solstices. The 19th time is the
charm![ Addendum 20160711: Sean Santos has some corrections to my formula for A. ]
[Other articles in category /calendar] permanent link
Sun, 15 May 2016
My Favorite NP-Complete Problem at !!Con 2016
Back in 2006 when this blog was new I observed that the problem of planning Elmo’s World video releases was NP-complete.
This spring I turned the post into a talk, which I gave at !!Con 2016 last week.
[Other articles in category /talk] permanent link
Sun, 01 May 2016It will suprise nobody to learn that when I was a child, computers were almost unknown, but it may be more surprising that typewriters were unusual.
Probably the first typewriter I was familiar with was my grandmother’s IBM “Executive” model C. At first I was not allowed to touch this fascinating device, because it was very fancy and expensive and my grandmother used it for her work as an editor of medical journals.
The “Executive” was very advanced: it had proportional spacing. It had two space bars, for different widths of spaces. Characters varied between two and five ticks wide, and my grandmother had typed up a little chart giving the width of each character in ticks, which she pasted to the top panel of the typewriter. The font was sans-serif, and I remember being a little puzzled when I first noticed that the lowercase j had no hook: it looked just like the lowercase i, except longer.
The little chart was important, I later learned, when I became old enough to use the typewriter and was taught its mysteries. Press only one key at a time, or the type bars will collide. Don't use the (extremely satisfying) auto-repeat feature on the hyphen or underscore, or the platen might be damaged. Don't touch any of the special controls; Grandma has them adjusted the way she wants. (As a concession, I was allowed to use the “expand” switch, which could be easily switched off again.)
The little chart was part of the procedure for correcting errors. You would backspace over the character you wanted to erase—each press of the backspace key would move the carriage back by one tick, and the chart told you how many times to press—and then place a slip of correction paper between the ribbon and the paper, and retype the character you wanted to erase. The dark ribbon impression would go onto the front of the correction slip, which was always covered with a pleasing jumble of random letters, and the correction slip impression, in white, would exactly overprint the letter you wanted to erase. Except sometimes it didn't quite: the ribbon ink would have spread a bit, and the corrected version would be a ghostly white letter with a hair-thin black outline. Or if you were a small child, as I was, you would sometimes put the correction slip in backwards, and the white ink would be transferred uselessly to the back of the ribbon instead of to the paper. Or you would select a partly-used portion of the slip and the missing bit of white ink would leave a fragment of the corrected letter on the page, like the broken-off leg of a dead bug.
Later I was introduced to the use of Liquid Paper (don't brush on a big glob, dot it on a bit at a time with the tip of the brush) and carbon paper, another thing you had to be careful not to put in backward, although if you did you got a wonderful result: the typewriter printed mirror images.
From typing alphabets, random letters, my name, and of course qwertyuiops I soon moved on to little poems, stories, and other miscellanea, and when my family saw that I was using the typewriter for writing, they presented me with one of my own, a Royal manual (model HHE maybe?) with a two-color ribbon, and I was at last free to explore the mysteries of the TAB SET and TAB CLEAR buttons. The front panel had a control for a three-color ribbon, which forever remained an unattainable mystery. Later I graduated to a Smith-Corona electric, on which I wrote my high school term papers. The personal computer arrived while I was in high school, but available printers were either expensive or looked like crap.
When I was in first grade our classroom had acquired a cheap manual typewriter, which as I have said, was an unusual novelty, and I used it whenever I could. I remember my teacher, Ms. Juanita Adams, complaining that I spent too much time on the typewriter. “You should work more on your handwriting, Jason. You might need to write something while you’re out on the street, and you won't just be able to pull a typewriter out of your pocket.”
She was wrong.
[Other articles in category /tech] permanent link
Sat, 23 Apr 2016
Steph Curry: fluke or breakthrough?
[ Disclaimer: I know very little about basketball. I think there's a good chance this article contains at least one basketball-related howler, but I'm too ignorant to know where it is. ]
Randy Olson recently tweeted a link to a New York Times article about Steph Curry's new 3-point record. Here is Olson’s snapshot of a portion of the Times’ clever and attractive interactive chart:

(Skip this paragraph if you know anything about basketball. The object of the sport is to throw a ball through a “basket” suspended ten feet (3 meters) above the court. Normally a player's team is awarded two points for doing this. But if the player is sufficiently far from the basket—the distance varies but is around 23 feet (7 meters)—three points are awarded instead. Carry on!)

Stephen Curry
The chart demonstrates that Curry this year has shattered the single-season record for three-point field goals. The previous record, set last year, is 286, also by Curry; the new record is 406. A comment by the authors of the chart says
The record is an outlier that defies most comparisons, but here is one: It is the equivalent of hitting 103 home runs in a Major League Baseball season.
(The current single-season home run record is 73, and !!\frac{406}{286}·73 \approx 103!!.)
I found this remark striking, because I don't think the record is an outlier that defies most comparisons. In fact, it doesn't even defy the comparison they make, to the baseball single-season home run record.

Babe Ruth
In 1919, the record for home runs in a single season was 29, hit by Babe Ruth. The 1920 record, also by Ruth, was 54. To make the same comparison as the authors of the Times article, that is the equivalent of hitting !!\frac{54}{29}·73 \approx 136!! home runs in a Major League Baseball season.
No, far from being an outlier that defies most comparisons, I think what we're seeing here is something that has happened over and over in sport, a fundamental shift in the way the game is played; in short, a breakthrough. In baseball, Ruth's 1920 season was the end of what is now known as the dead-ball era. The end of the dead-ball era was the caused by the confluence of several trends (shrinking ballparks), rule changes (the spitball), and one-off events (Ray Chapman, the Black Sox). But an important cause was simply that Ruth realized that he could play the game in a better way by hitting a crapload of home runs.
The new record was the end of a sudden and sharp upward trend. Prior to Ruth's 29 home runs in 1919, the record had been 27, a weird fluke set way back in 1887 when the rules were drastically different. Typical single-season home run records in the intervening years were in the 11 to 16 range; the record exceeded 20 in only four of the intervening 25 years.
Ruth's innovation was promptly imitated. In 1920, the #2 hitter hit 19 home runs and the #10 hitter hit 11, typical numbers for the nineteen-teens. By 1929, the #10 hitter hit 31 home runs, which would have been record-setting in 1919. It was a different game.

Takeru Kobayashi
For another example of a breakthrough, let's consider competitive hot dog eating. Between 1980 and 1990, champion hot-dog eaters consumed between 9 and 16 hot dogs in 10 minutes. In 1991 the time was extended to 12 minutes and Frank Dellarosa set a new record, 21½ hot dogs, which was not too far out of line with previous records, and which was repeatedly approached in the following decade: through 1999 five different champions ate between 19 and 24½ hot dogs in 12 minutes, in every year except 1993.
But in 2000 Takeru Kobayashi (小林 尊) changed the sport forever, eating an unbelievably disgusting 50 hot dogs in 12 minutes. (50. Not a misprint. Fifty. Roman numeral Ⅼ.) To make the Times’ comparison again, that is the equivalent of hitting !!\frac{50}{24\frac12}·73 \approx 149!! home runs in a Major League Baseball season.
At that point it was a different game. Did the record represent a fundamental shift in hot dog gobbling technique? Yes. Kobayashi won all of the next five contests, eating between 44½ and 53¾ each time. By 2005 the second- and third-place finishers were eating 35 or more hot dogs each; had they done this in 1995 they would have demolished the old records. A new generation of champions emerged, following Kobayashi's lead. The current record is 69 hot dogs in 10 minutes. The record-setters of the 1990s would not even be in contention in a modern hot dog eating contest.

Bob Beamon
It is instructive to compare these breakthroughs with a different sort of astonishing sports record, the bizarre fluke. In 1967, the world record distance for the long jump was 8.35 meters. In 1968, Bob Beamon shattered this record, jumping 8.90 meters. To put this in perspective, consider that in one jump, Beamon advanced the record by 55 cm, the same amount that it had advanced (in 13 stages) between 1925 and 1967.
Progression of the world long jump record
The cliff at 1968 is Bob Beamon
Did Beamon's new record represent a fundamental shift in long jump technique? No: Beamon never again jumped more than 8.22m. Did other jumpers promptly imitate it? No, Beamon's record was approached only a few times in the following quarter-century, and surpassed only once. Beamon had the benefit of high altitude, a tail wind, and fabulous luck.

Joe DiMaggio
Another bizarre fluke is Joe DiMaggio's hitting streak: in the 1941 baseball season, DiMaggio achieved hits in 56 consecutive games. For extensive discussion of just how bizarre this is, see The Streak of Streaks by Stephen J. Gould. (“DiMaggio’s streak is the most extraordinary thing that ever happened in American sports.”) Did DiMaggio’s hitting streak represent a fundamental shift in the way the game of baseball was played, toward high-average hitting? Did other players promptly imitate it? No. DiMaggio's streak has never been seriously challenged, and has been approached only a few times. (The modern runner-up is Pete Rose, who hit in 44 consecutive games in 1978.) DiMaggio also had the benefit of fabulous luck.
Is Curry’s new record a fluke or a breakthrough?
I think what we're seeing in basketball is a breakthrough, a shift in the way the game is played analogous to the arrival of baseball’s home run era in the 1920s. Unless the league tinkers with the rules to prevent it, we might expect the next generation of players to regularly lead the league with 300 or 400 three-point shots in a season. Here's why I think so.
Curry's record wasn't unprecedented. He's been setting three-point records for years. (Compare Ruth’s 1920 home run record, foreshadowed in 1919.) He's continuing a trend that he began years ago.
Curry’s record, unlike DiMaggio’s streak, does not appear to depend on fabulous luck. His 402 field goals this year are on 886 attempts, a 45.4% success rate. This is in line with his success rate every year since 2009; last year he had a 44.3% success rate. Curry didn't get lucky this year; he had 40% more field goals because he made almost 40% more attempts. There seems to be no reason to think he couldn't make the same number of attempts next year with equal success, if he wants to.
Does he want to? Probably. Curry’s new three-point strategy seems to be extremely effective. In his previous three seasons he scored 1786, 1873, and 1900 points; this season, he scored 2375, an increase of 475, three-quarters of which is due to his three-point field goals. So we can suppose that he will continue to attempt a large number of three-point shots.
Is this something unique to Curry or is it something that other players might learn to emulate? Curry’s three-point field goal rate is high, but not exceptionally so. He's not the most accurate of all three-point shooters; he holds the 62nd–64th-highest season percentages for three-point success rate. There are at least a few other players in the league who must have seen what Curry did and thought “I could do that”. (Kyle Korver maybe? I'm on very shaky ground; I don't even know how old he is.) Some of those players are going to give it a try, as are some we haven’t seen yet, and there seems to be no reason why some shouldn't succeed.
A number of things could sabotage this analysis. For example, the league might take steps to reduce the number of three-point field goals, specifically in response to Curry’s new record, say by moving the three-point line farther from the basket. But if nothing like that happens, I think it's likely that we'll see basketball enter a new era of higher offense with more three-point shots, and that future sport historians will look back on this season as a watershed.
[ Addendum 20160425: As I feared, my Korver suggestion was ridiculous. Thanks to the folks who explained why. Reason #1: He is 35 years old. ]
[ Addendum 20210627: Blog article about the slowness with which the league adapted to the three-point rule. ]
[Other articles in category /games] permanent link
Tue, 19 Apr 2016A classic puzzle of mathematics goes like this:
A father dies and his will states that his elder daughter should receive half his horses, the son should receive one-quarter of the horses, and the younger daughter should receive one-eighth of the horses. Unfortunately, there are seven horses. The siblings are arguing about how to divide the seven horses when a passing sage hears them. The siblings beg the sage for help. The sage donates his own horse to the estate, which now has eight. It is now easy to portion out the half, quarter, and eighth shares, and having done so, the sage's horse is unaccounted for. The three heirs return the surplus horse to the sage, who rides off, leaving the matter settled fairly.
(The puzzle is, what just happened?)
It's not hard to come up with variations on this. For example, picking three fractions at random, suppose the will says that the eldest child receives half the horses, the middle child receives one-fifth, and the youngest receives one-seventh. But the estate has only 59 horses and an argument ensues. All that is required for the sage to solve the problem is to lend the estate eleven horses. There are now 70, and after taking out the three bequests, !!70 - 35 - 14 - 10 = 11!! horses remain and the estate settles its debt to the sage.
But here's a variation I've never seen before. This time there are 13 horses and the will says that the three children should receive shares of !!\frac12, \frac13,!! and !!\frac14!!. respectively. Now the problem seems impossible, because !!\frac12 + \frac13 + \frac14 \gt 1!!. But the sage is equal to the challenge! She leaps into the saddle of one of the horses and rides out of sight before the astonished heirs can react. After a day of searching the heirs write off the lost horse and proceed with executing the will. There are now only 12 horses, and the eldest takes half, or six, while the middle sibling takes one-third, or 4. The youngest heir should get three, but only two remain. She has just opened her mouth to complain at her unfair treatment when the sage rides up from nowhere and hands her the reins to her last horse.
[Other articles in category /math] permanent link
Thackeray's illustrations for Vanity Fair
Last month I finished reading Thackeray’s novel Vanity Fair. (Related blog post.) Thackeray originally did illustrations for the novel, but my edition did not have them. When I went to find them online, I was disappointed: they were hard to find and the few I did find were poor quality and low resolution.
Before
| After
(click to enlarge) |
The illustrations are narratively important. Jos Osborne dies suspiciously; the text implies that Becky has something to do with it. Thackeray's caption for the accompanying illustration is “Becky’s Second Appearance in the Character of Clytemnestra”. Thackeray’s depiction of Miss Swartz, who is mixed-race, may be of interest to scholars.
I bought a worn-out copy of Vanity Fair that did have the illustrations and scanned them. These illustrations, originally made around 1848 by William Makepeace Thackeray, are in the public domain. In the printing I have (George Routeledge and Sons, New York, 1886) the illustrations were 9½cm × 12½ cm. I have scanned them at 600 dpi.
Unfortunately, I was only able to find Thackeray’s full-page illustrations. He also did some spot illustrations, chapter capitals, and so forth, which I have not been able to locate.
Share and enjoy.






























[ Addendum 20180116: Evgen Stepanovych Stasiuk has brought to my attention that this set is incomplete; the original edition of Vanity Fair had 38 full-page plates. I don't know whether these were missing from the copy I scanned, or whether I just missed them, but in any case I regret the omission. The Internet Archive has a scan of the original 1848 edition, complete with all 38 plates and the interior illustrations also. ]
[Other articles in category /book] permanent link
Fri, 15 Apr 2016
How to recover lost files added to Git but not committed
If you lose something [in Git], don't panic. There's a good chance that you can find someone who will be able to hunt it down again.
I was not expecting to have a demonstration ready so soon. But today
I finished working on a project, I had all the files staged in the
index but not committed, and for some reason I no longer remember I
chose that moment to do git reset --hard, which throws away the
working tree and the staged files. I may have thought I had
committed the changes. I hadn't.
If the files had only been in the working tree, there would have been nothing to do but to start over. Git does not track the working tree. But I had added the files to the index. When a file is added to the Git index, Git stores it in the repository. Later on, when the index is committed, Git creates a commit that refers to the files already stored. If you know how to look, you can find the stored files even before they are part of a commit.
(If they are part of a commit, the problem is much easier.
Typically the answer is simply “use git-reflog to find the commit
again and check it out”. The git-reflog command is probably the
first thing anyone should learn on the path from being a Git beginner
to becoming an intermediate Git user.)
Each file added to the Git index is stored as a “blob object”. Git
stores objects in two ways. When it's fetching a lot of objects from
a remote repository, it gets a big zip file with an attached table of
contents; this is called a pack. Getting objects from a pack can be
a pain. Fortunately, not all objects are in packs. When when you just
use git-add to add a file to the index, git makes a single object,
called a “loose” object. The loose object is basically the file
contents, gzipped, with a header attached. At some point Git will
decide there are too many loose objects and assemble them into a pack.
To make a loose object from a file, the contents of the file are checksummed, and the checksum is used as the name of the object file in the repository and as an identifier for the object, exactly the same as the way git uses the checksum of a commit as the commit's identifier. If the checksum is 0123456789abcdef0123456789abcdef01234567, the object is stored in
.git/objects/01/23456789abcdef0123456789abcdef01234567
The pack files are elsewhere, in .git/objects/pack.
So the first thing I did was to get a list of the loose objects in the repository:
cd .git/objects
find ?? -type f | perl -lpe 's#/##' > /tmp/OBJ
This produces a list of the object IDs of all the loose objects in the repository:
00f1b6cc1dfc1c8872b6d7cd999820d1e922df4a
0093a412d3fe23dd9acb9320156f20195040a063
01f3a6946197d93f8edba2c49d1bb6fc291797b0
…
ffd505d2da2e4aac813122d8e469312fd03a3669
fff732422ed8d82ceff4f406cdc2b12b09d81c2e
There were 500 loose objects in my repository. The goal was to find the eight I wanted.
There are several kinds of objects in a Git repository. In addition
to blobs, which represent file contents, there are commit objects,
which represent commits, and tree objects, which represent
directories. These are usually constructed at the time the commit is
done. Since my files hadn't been committed, I knew I wasn't
interested in these types of objects. The command git cat-file -t
will tell you what type an object is. I made a file that related each
object to its type:
for i in $(cat /tmp/OBJ); do
echo -n "$i ";
git type $i;
done > /tmp/OBJTYPE
The git type command is just an alias for git cat-file -t. (Funny
thing about that: I created that alias years ago when I first started
using Git, thinking it would be useful, but I never used it, and just
last week I was wondering why I still bothered to have it around.) The
OBJTYPE file output by this loop looks like this:
00f1b6cc1dfc1c8872b6d7cd999820d1e922df4a blob
0093a412d3fe23dd9acb9320156f20195040a063 tree
01f3a6946197d93f8edba2c49d1bb6fc291797b0 commit
…
fed6767ff7fa921601299d9a28545aa69364f87b tree
ffd505d2da2e4aac813122d8e469312fd03a3669 tree
fff732422ed8d82ceff4f406cdc2b12b09d81c2e blob
Then I just grepped out the blob objects:
grep blob /tmp/OBJTYPE | f 1 > /tmp/OBJBLOB
The f 1 command throws away the types and
keeps the object IDs. At this point I had filtered the original 500
objects down to just 108 blobs.
Now it was time to grep through the blobs to find the ones I was
looking for. Fortunately, I knew that each of my lost files would
contain the string org-service-currency, which was my name for the
project I was working on. I couldn't grep the object files directly,
because they're gzipped, but the command git cat-file disgorges
the contents of an object:
for i in $(cat /tmp/OBJBLOB ) ; do
git cat-file blob $i |
grep -q org-service-curr
&& echo $i;
done > /tmp/MATCHES
The git cat-file blob $i produces the contents of the blob whose ID
is in $i. The grep searches the contents for the magic string.
Normally grep would print the matching lines, but this behavior is
disabled by the -q flag—the q is for “quiet”—and tells grep
instead that it is being used only as part of a test: it yields true
if it finds the magic string, and false if not. The && is the test;
it runs echo $i to print out the object ID $i only if the grep
yields true because its input contained the magic string.
So this loop fills the file MATCHES with the list of IDs of the
blobs that contain the magic string. This worked, and I found that
there were only 18 matching blobs, so I wrote a very similar loop to
extract their contents from the repository and save them in a
directory:
for i in $(cat /tmp/OBJBLOB ) ; do
git cat-file blob $i |
grep -q org-service-curr
&& git cat-file blob $i > /tmp/rescue/$i;
done
Instead of printing out the matching blob ID number, this loop passes
it to git cat-file again to extract the contents into a file in
/tmp/rescue.
The rest was simple. I made 8 subdirectories under /tmp/rescue
representing the 8 different files I was expecting to find. I
eyeballed each of the 18 blobs, decided what each one was, and sorted
them into the 8 subdirectories. Some of the subdirectories had only 1
blob, some had up to 5. I looked at the blobs in each subdirectory to
decide in each case which one I wanted to keep, using diff when it
wasn't obvious what the differences were between two versions of the
same file. When I found one I liked, I copied it back to its correct
place in the working tree.
Finally, I went back to the working tree and added and committed the rescued files.
It seemed longer, but it only took about twenty minutes. To recreate the eight files from scratch might have taken about the same amount of time, or maybe longer (although it never takes as long as I think it will), and would have been tedious.
But let's suppose that it had taken much longer, say forty minutes instead of twenty, to rescue the lost blobs from the repository. Would that extra twenty minutes have been time wasted? No! The twenty minutes spent to recreate the files from scratch is a dead loss. But the forty minutes to rescue the blobs is time spent learning something that might be useful in the future. The Git rescue might have cost twenty extra minutes, but if so it was paid back with forty minutes of additional Git expertise, and time spent to gain expertise is well spent! Spending time to gain expertise is how you become an expert!
Git is a core tool, something I use every day. For a long time I have been prepared for the day when I would try to rescue someone's lost blobs, but until now I had never done it. Now, if that day comes, I will be able to say “Oh, it's no problem, I have done this before!”
So if you lose something in Git, don't panic. There's a good chance that you can find someone who will be able to hunt it down again.
[Other articles in category /prog] permanent link
Tue, 12 Apr 2016
Neckbeards and other notes on “The Magnificent Ambersons”
Last week I read Booth Tarkington’s novel The Magnificent Ambersons, which won the 1919 Pulitzer Prize but today is chiefly remembered for Orson Welles’ 1942 film adaptation.
(It was sitting on the giveaway shelf in the coffee shop, so I grabbed it. It is a 1925 printing, discarded from the Bess Tilson Sprinkle library in Weaverville, North Carolina. The last due date stamped in the back is May 12, 1957.)
The Ambersons are the richest and most important family in an unnamed Midwestern town in 1880. The only grandchild, George, is completely spoiled and grows up to ruin the lives of everyone connected with him with his monstrous selfishness. Meanwhile, as the automobile is invented and the town evolves into a city the Amberson fortune is lost and the family dispersed and forgotten. George is destroyed so thoroughly that I could not even take any pleasure in it.
I made a few marginal notes as I read.
Neckbeards
It was a hairier day than this. Beards were to the wearer’s fancy … and it was possible for a Senator of the United States to wear a mist of white whisker upon his throat only, not a newspaper in the land finding the ornament distinguished enough to warrant a lampoon.
I wondered who Tarkington had in mind. My first thought was Horace Greeley:


His neckbeard fits the description, but, although he served as an unelected congressman and ran unsuccessfully for President, he was never a Senator.
Then I thought of Hannibal Hamlin, who was a Senator:

But his neckbeard, although horrifying, doesn't match the description.
Gentle Readers, can you help me? Who did Tarkington have in mind? Or, if we can't figure that out, perhaps we could assemble a list of the Ten Worst Neckbeards of 19th Century Politics.
Other notes
I was startled on Page 288 by a mention of “purple haze”, but a Google Books search reveals that the phrase is not that uncommon. Jimi Hendrix owns it now, but in 1919 it was just purple haze.
George’s Aunt Fanny writes him a letter about his girlfriend Lucy:
Mr. Morgan took your mother and me to see Modjeska in “Twelfth Night” yesterday evening, and Lucy said she thought the Duke looked rather like you, only much more democratic in his manner.
Lucy, as you see, is not entirely sure that she likes George. George, who is not very intelligent, is not aware that Lucy is poking fun at him.
A little later we see George’s letter to Lucy. Here is an excerpt I found striking:
[Yours] is the only girl’s photograph I ever took the trouble to have framed, though as I told you frankly, I have had any number of other girls’ photographs, yet all were passing fancies, and oftentimes I have questioned in years past if I was capable of much friendship toward the feminine sex, which I usually found shallow until our own friendship began. When I look at your photograph, I say to myself “At last, at last here is one that will not prove shallow.”
The arrogance, the rambling, the indecisiveness of tone, and the vacillation reminded me of the speeches of Donald Trump, whom George resembles in several ways. George has an excuse not available to Trump; he is only twenty.
Addendum 20160413: John C. Calhoun seems like a strong possibility:

Addendum 20210206: Neckbeard Society is a blog that features notable neckbeards, many more horrifying than anything you could imagine.
[Other articles in category /book] permanent link
Mon, 11 Apr 2016Recently the following amusing item was going around on Twitter:

I have some bad news and some good news. First the good news: there is an Edith-Anne. Her name is actually Patty Polk, and she lived in Maryland around 1800.
Now the bad news: the image above is almost certainly fake. It may be a purely digital fabrication (from whole cloth, ha ha), or more likely, I think, it is a real physical object, but of recent manufacture.
I wouldn't waste blog space just to crap on this harmless bit of fake history. I want to give credit where it is due, to Patty Polk who really did do this, probably with much greater proficiency.
Why I think it's fake
I have not looked into this closely, because I don't think the question merits a lot of effort. But I have two reasons for thinking so.
The main one is that the complaint “Edith-Anne … hated every Stitch” would have taken at least as much time and effort as the rest of the sampler, probably more. I find it unlikely that Edith-Anne would have put so much work—so many more hated stitches—into her rejection.
Also, the work is implausibly poor. These samplers were stitched by girls typically between the ages of 7 and 14, and their artisanship was much, much better than either section of this example. Here is a sampler made by Lydia Stocker in 1798 at the age of 12:

Here's one by Louisa Gauffreau, age 8:

 Compare these
with Edith-Anne's purported cross-stitching. One tries to imagine how
old she is, but there seems to be no good answer. The crooked
stitching is the work of a very young girl, perhaps five or six. But
the determination behind the sentiment, and the perseverance that
would have been needed to see it through, belong to a much older girl.
Compare these
with Edith-Anne's purported cross-stitching. One tries to imagine how
old she is, but there seems to be no good answer. The crooked
stitching is the work of a very young girl, perhaps five or six. But
the determination behind the sentiment, and the perseverance that
would have been needed to see it through, belong to a much older girl.
Of course one wouldn't expect Edith-Anne to do good work on her hated sampler. But look at the sampler at right, wrought by a young Emily Dickinson, who is believed to have disliked the work and to have intentionally done it poorly. Even compared with this, Edith-Anne's claimed sampler doesn't look like a real sampler.
Patty Polk
Web search for “hated every stitch” turns up several other versions of Edith-Anne, often named Polly Cook1 or Mary Pitt2 (“This was done by Mary Pitt / Who hated every stitch of it”) but without any reliable source.
However, Patty Polk is reliably sourced. Bolton and Coe's American Samplers3 describes Miss Polk's sampler:
POLK, PATTY. [Cir. 1800. Kent County, Md.] 10 yrs. 16"×16". Stem-stitch. Large garland of pinks, roses, passion flowers, nasturtiums, and green leaves; in center, a white tomb with “G W” on it, surrounded by forget-me-nots. “Patty Polk did this and she hated every stitch she did in it. She loves to read much more.”
The description was provided by Mrs. Frederic Tyson, who presumably owned or had at least seen the sampler. Unfortunately, there is no picture. The “G W” is believed to refer to George Washington, who died in 1799.
There is a lively market in designs for pseudo-vintage samplers that you can embroider yourself and “age”. One that features Patty Polk was produced by Falling Star Primitives:

Thanks to Lee Morrison of Falling Star Primitives for permission to use her “Patty Polk” design.
References
1. Parker, Rozsika. The Subversive Stitch: Embroidery and the Making of the Feminine. Routledge, 1989. p. 132.
2. Wilson, Erica. Needleplay. Scribner, 1975. p. 67.
3. Bolton, Ethel Stanwood and Eva Johnston Coe. American Samplers. Massachusetts Society of the Colonial Dames of America, 1921. p. 210.
[ Thanks to several Twitter users for suggesting gender-neutral vocabulary. ]
[ Addendum: Twitter user Kathryn Allen observes that Edith-Anne hated cross-stitch so much that she made another sampler to sell on eBay. Case closed. ]
[ Addendum: Ms. Allen further points out that the report by Mrs. Tyson in American Samplers may not be reliable, and directs me to the discussion by J.L. Bell, Clues to a Lost Sampler. ]
[ Addendum 20160619: Edith-Anne strikes again!. For someone who hated sewing, she sure did make a lot of these things. ]
[ Addendum 20200801: More about this by Emily Wells, who cites an earlier Twitter thread by fashion historian Hilary Davidson that makes the same points I did: “no matter how terribly you sewed in 1877, it would have been impossible to sew badly like this for a middle-class sampler”. ]
[ Addendum 20211011: Ms. Wells’ article also explains the connection between Patty Polk and Mrs. Tyson, who I said “presumably owned or had at least seen the sampler.”:
Patty Polk was Martha E. Polk, the daughter of Joseph Polk and Margaret Durborough. Born on March 2, 1817, Polk likely completed her needlework picture at some point in the 1830s. In 1921, Polk’s daughter, Florence McIntyre Tyson, submitted her mother’s sampler for inclusion in Bolton and Coe’s American Samplers.
]
[Other articles in category /misc] permanent link
Fri, 08 Apr 2016I'm becoming one of the people at my company that people come to when they want help with git, so I've been thinking a lot about what to tell people about it. It's always tempting to dive into the technical details, but I think the first and most important things to explain about it are:
Git has a very simple and powerful underlying model. Atop this model is piled an immense trashheap of confusing, overlapping, inconsistent commands. If you try to just learn what commands to run in what order, your life will be miserable, because none of the commands make sense. Learning the underlying model has a much better payoff because it is much easier to understand what is really going on underneath than to try to infer it, Sherlock-Holmes style, from the top.
One of Git's principal design criteria is that it should be very difficult to lose work. Everything is kept, even if it can sometimes be hard to find. If you lose something, don't panic. There's a good chance that you can find someone who will be able to hunt it down again. And if you make a mistake, it is almost always possible to put things back exactly the way they were, and you can find someone who can show you how to do it.
One exception is changes that haven't been committed. These are not yet under Git's control, so it can't help you with them. Commit early and often.
[ Addendum 20160415: I wrote a detailed account of a time I recovered lost files. ]
[ Addendum 20160505: I don't know why I didn't mention it before, but if you want to learn Git's underlying model, you should read Git from the Bottom Up (which is what worked for me) or Git from the Inside Out which is better illustrated. ]
[Other articles in category /prog] permanent link
Sun, 20 Mar 2016
Technical jargon failure modes
Technical jargon is its own thing, intended for easy communication between trained practitioners of some art, but not necessarily between anyone else.
Jargon can be somewhat transparent, like the chemical jargon term “alcohol”. “Alcohol” refers to a large class of related chemical compounds, of which the simplest examples are methyl alcohol (traditionally called “wood alcohol”) and ethyl alcohol (the kind that you get in your martini). The extension of “alcohol” to the larger class is suggestive and helpful. Someone who doesn't understand the chemical jargon usage of “alcohol” can pick it up by analogy, and even if they don't they will probably have something like the right idea. A similar example is “aldehyde”. An outsider who hears this for the first time might reasonably ask “does that have something to do with formaldehyde?” and the reasonable answer is “yes indeed, formaldehyde is the simplest example of an aldehyde compound.” Again the common term is adapted to refer to the members of a larger but related class.
An opposite sort of adaptation is found in the term “bug”. The common term is extremely broad, encompassing all sorts of terrestrial arthropods, including mosquitoes, ladybugs, flies, dragonflies, spiders, and even isopods (“pillbugs”) and centipedes and so forth. It should be clear that this category is too large and heterogeneous to be scientifically useful, and the technical use of “bug” is much more restricted. But it does include many creatures commonly referred to as bugs, such as bed bugs, waterbugs, various plant bugs, and many other flat-bodied crawling insects.
Mathematics jargon often wanders in different directions. Some mathematical terms are completely opaque. Nobody hearing the term “cobordism” or “simplicial complex” or “locally compact manifold” for the first time will think for an instant that they have any idea what it means, and this is perfect, because they will be perfectly correct. Other mathematical terms are paradoxically so transparent seeming that they reveal their opacity by being obviously too good to be true. If you hear a mathematician mention a “field” it will take no more than a moment to realize that it can have nothing to do with fields of grain or track-and-field sports. (A field is a collection of things that are number-like, in the sense of having addition, subtraction, multiplication, and division that behave pretty much the way one would expect those operations to behave.) And some mathematical jargon is fairly transparent. The non-mathematician's idea of “line”, “ball”, and “cube” is not in any way inconsistent with what the mathematician has in mind, although the full technical meaning of those terms is pregnant with ramifications and connotations that are invisible to non-mathematicians.
But mathematical jargon sometimes goes to some bad places. The term “group” is so generic that it could mean anything, and outsiders often imagine that it means something like what mathematicians call a “set”. (It actually means a family of objects that behave like the family of symmetries of some other object.)
This last is not too terrible, as jargon failures go. There is a worse kind of jargon failure I would like to contrast with “bug”. There the problem, if there is a problem, is that entomologists use the common term “bug” much more restrictively than one expects. An entomologist will well-actually you to explain that a millipede is not actually a bug, but we are used to technicians using technical terms in more restrictive ways than we expect. At least you can feel fairly confident that if you ask for examples of bugs (“true bugs”, in the jargon) that they will all be what you will consider bugs, and the entomologist will not proceed to rattle off a list that includes bats, lobsters, potatoes, or the Trans-Siberian Railroad. This is an acceptable state of affairs.
Unacceptable, however, is the botanical use of the term “berry”:
It is one thing to adopt a jargon term that is completely orthogonal to common usage, as with “fruit”, where the technical term simply has no relation at all to the common meaning. That is bad enough. But to adopt the term “berry” for a class of fruits that excludes nearly everything that is commonly called a ”berry” is an offense against common sense.
This has been on my mind a long time, but I am writing about it now because I think I have found, at last, an even more offensive example.

Stonehenge is so-called because it is a place of hanging stones: “henge” is cognate with “hang”.
In 1932 archaeologists adapted the name “Stonehenge” to create the word “henge” as a generic term for a family of ancient monuments that are similar to Stonehenge.
Therefore, if there were only one thing in the whole world that ought to be an example of a henge, it should be Stonehenge.
However, Stonehenge is not, itself, a henge.
Stonehenge is not a henge.
STONEHENGE IS NOT A HENGE.
{kind=link}
Stonehenge is not a henge. … Technically, [henges] are earthwork enclosures in which a ditch was dug to make a bank, which was thrown up on the outside edge of the ditch.
— Michael Pitts, Hengeworld, pp. 26–28.
“Henge” may just be the most ineptly coined item of technical jargon in history.
[ Addendum 20161103: Zimbabwe's Great Dyke is not actually a dyke. ]
[ Addendum 20190502: I found a mathematical example that is approximately as bad as the worst examples on this page. ]
[Other articles in category /lang] permanent link
Sat, 19 Mar 2016
Sympathetic magic for four-year-olds
When Katara was about four, she was very distressed by the idea that green bugs were going to invade our house, I think though the mail slot in the front door. The obvious thing to do here was to tell her that there are no green bugs coming through the mail slot and she should shut up and go to sleep, but it seems clear to me that this was never going to work.
(It surprises me how few adults understand that this won't work. When Marcie admits at a cocktail party that she is afraid that people are staring at her in disgust, wondering why her pores are so big, many adults—but by no means all—know that it will not help her to reply “nobody is looking at your pores, you lunatic,” however true that may be. But even most of these enlightened adults will not hesitate to say the equivalent thing to a four-year-old afraid of mysterious green bugs. Adults and children are not so different in their irrational fears; they are just afraid of different kinds of monsters.)
Anyway, I tried to think what to say instead, and I had a happy idea. I told Katara that we would cast a magic spell to keep out the bugs. Red, I observed, was the opposite of green, and the green bugs would be powerfully repelled if we placed a bright red object just inside the front door where they would be sure to see it. Unwilling to pass the red object, they would turn back and leave us alone. Katara found this theory convincing, and so we laid sheets of red construction paper in the entryway under the mail slot.
Every night before bed for several weeks we laid out the red paper, and took it up again in the morning. This was not very troublesome, and certainly it less troublesome than arguing about green bugs every night with a tired four-year-old. For the first few nights, she was still a little worried about the bugs, but I confidently reminded her that the red paper would prevent them from coming in, and she was satisfied. The first few nights we may also have put red paper inside the door of her bedroom, just to be sure. Some nights she would forget and I would remind her that we had to put out the red paper before bedtime; then she would know that I took the threat seriously. Other nights I would forget and I would thank her for reminding me. After a few months of this we both started to forget, and the phase passed. I suppose the green bugs gave up eventually and moved on to a less well-defended house.
Several years later, Katara's younger sister Toph had a similar concern: she was afraid the house would be attacked by zombies. This time I already knew what to do. We discussed zombies, and how zombies are created by voodoo magic; therefore they are susceptible to voodoo, and I told Toph we would use voodoo to repel the zombies. I had her draw a picture of the zombies attacking the house, as detailed and elaborate as possible. Then we took black paper and cut it into black bars, and pasted the bars over Toph's drawing, so that the zombies were in a cage. The cage on the picture would immobilize the real zombies, I explained, just as one can stick pins into a voodoo doll of one's enemy to harm the real enemy. We hung the picture in the entryway, and Toph proudly remarked on how we had stopped the zombies whenever we went in or out.
Rationality has its limits. It avails nothing against green bugs or murderous zombies. Magical enemies must be fought with magic.
[Other articles in category /kids] permanent link
Sun, 07 Feb 2016I've read a bunch of 19-century English novels lately. I'm not exactly sure why; it just sort of happened. But it's been a lot of fun. When I was small, my mother told me more than once that people often dislike these books because they are made to read them too young; the books were written for adult readers and don't make sense to children. I deliberately waited to read most of these, and I am very pleased now to find that now that I am approaching middle age I enjoy books that were written for people approaching middle age.
Spoilers abound.
Jane Eyre
This is one of my wife's favorite books, or perhaps her very favorite, but I had not read it before. Wow, it's great! Jane is as fully three-dimensional as anyone in fiction.
I had read The Eyre Affair, which unfortunately spoiled a lot of the plot for me, including the Big Shocker; I kept wondering how I would feel if I didn't know what was coming next. Fortunately I didn't remember all the details.
From her name, I had expected Blanche Ingram to be pale and limp; I was not expecting a dark, disdainful beauty.
When Jane tells Rochester she must leave, he promises to find her another position, and the one he claims to have found is hilariously unattractive: she will be the governess to the five daughters of Mrs. Dionysus O'Gall of Bitternutt Lodge, somewhere in the ass-end of Ireland.
What a thrill when Jane proclaims “I am an independent woman now”! But she has achieved this by luck; she inherited a fortune from her long-lost uncle. That was pretty much the only possible path, and it makes an interesting counterpoint to Vanity Fair, which treats some of the same concerns.
The thought of dutifully fulfilling the duty of a dutiful married person by having dutiful sex with the dutiful Mr. Rivers makes my skin crawl. I imagine that Jane felt the same way.
Mr. Brocklehurst does not get one-tenth of what he deserves.
Jane Eyre set me off on a Victorian novel kick. The preface of Jane Eyre praises William Thackeray and Vanity Fair in particular. So I thought I'd read some Thackeray and see how I liked that. Then for some reason I read Silas Marner instead of Vanity Fair. I'm not sure how that happened.
Silas Marner
Silas Marner was the big surprise of this batch of books. I don't know why I had always imagined Silas Marner would be the very dreariest and most tedious of all Victorian novels. But Silas Marner is quite short, and I found it very sweet and charming.
I do not suppose my Gentle Readers are as likely to be familiar with Silas Marner as with Jane Eyre. As a young man, Silas is a member of a rigid, inward-looking religious sect. His best friend frames him for a crime, and he is cast out. Feeling abandoned by society and by God, he settles in Raveloe and becomes a miser, almost a hermit. Many years pass, and his hoarded gold is stolen, leaving him bereft. But one snowy evening a two-year-old girl stumbles into his house and brings new purpose to his life. I have omitted the subplot here, but it's a good subplot.
One of the scenes I particularly enjoyed concerns Silas’ first (and apparently only) attempt to discipline his adopted two-year-old daughter Eppie, with whom he is utterly besotted. Silas knows that sooner or later he will have to, but he doesn't know how—striking her seems unthinkable—and consults his neighbors. One suggests that he shut her in the dark, dirty coal-hole by the fireplace. When Eppie wanders away one day, Silas tries to be stern.
“Eppie must go into the coal hole for being naughty. Daddy must put her in the coal hole.”
He half expected that this would be shock enough and that Eppie would begin to cry. But instead of that she began to shake herself on his knee as if the proposition opened a pleasing novelty.
As they say, no plan survives contact with the enemy.
Seeing that he must proceed to extremities, he put her into the coal hole, and held the door closed, with a trembling sense that he was using a strong measure. For a moment there was silence but then came a little cry “Opy, opy!” and Silas let her out again…
Silas gets her cleaned up and changes her clothes, and is about to settle back to his work
when she peeped out at him with black face and hands again and said “Eppie in de toal hole!”
Two-year-olds are like that: you would probably strangle them, if they weren't so hilariously cute.
Everyone in this book gets what they deserve, except the hapless Nancy Lammeter, who gets a raw deal. But it's a deal partly of her own making. As Thackeray says of Lady Crawley, in a somewhat similar circumstance, “a title and a coach and four are toys more precious than happiness in Vanity Fair”.
There is a chapter about a local rustics at the pub which may remind you that human intercourse could be plenty tiresome even before the invention of social media. The one guy who makes everything into an argument will be quite familiar to my Gentle Readers.
I have added Silas Marner to the long list of books that I am glad I was not forced to read when I was younger.
The Old Curiosity Shop

Unlike Silas Marner, I know why I read this one. In the park near my house is a statue of Charles Dickens and Little Nell, on which my daughter Toph is accustomed to climb. As she inevitably asked me who it was a statue of, I explained that Dickens was a famous writer, and Nell is a character in a book by Dickens. She then asked me what the book was about, and who Nell was, and I did not know. I said I would read the book and find out, so here we are.
My experience with Dickens is very mixed. Dickens was always my mother's number one example of a writer that people were forced to read when too young. My grandfather had read me A Christmas Carol when I was young, and I think I liked it, but probably a lot of it went over my head. When I was about twenty-two I decided to write a parody of it, which meant I had to read it first, but I found it much better than I expected, and too good to be worth parodying. I have reread it a couple of times since. it is very much worth going back to, and is much better than its many imitators.
I had been required to read Great Expectations in high school, had not cared for it, and had stopped after four or five chapters. But as an adult I kept a copy in my house for many years, waiting for the day when I might try again, and when I was thirty-five I did try again, and I loved it.
Everyone agrees that Great Expectations is one of Dickens’ best, and so it is not too surprising that I was much less impressed with Martin Chuzzlewit when I tried that a couple of years later. I remember liking Mark Tapley, but I fell off the bus shortly after Martin came to America, and I did not get back on.

A few years ago I tried reading The Pickwick Papers, which my mother said should only be read by middle-aged people, and I have not yet finished it. It is supposed to be funny, and I almost never find funny books funny, except when they are read aloud. (When I tell people this, they inevitably name their favorite funny books: “Oh, but you thought The Hitchhiker’s Guide to the Galaxy was funny, didn't you?” or whatever. Sorry, I did not. There are a few exceptions; the only one that comes to mind is Stanisław Lem's The Cyberiad, which splits my sides every time. SEVEN!
Anyway, I digress. The Old Curiosity Shop was extremely popular when it was new. You always hear the same two stories about it: that crowds assembled at the wharves in New York to get spoilers from the seamen who might have read the new installments already, and that Oscar Wilde once said “one must have a heart of stone to read the death of Little Nell without laughing.” So I was not expecting too much, and indeed The Old Curiosity Shop is a book with serious problems.
Chief among them: it was published in installments, and about a third of the way through writing it Dickens seems to have changed his mind about how he wanted it to go, but by then it was too late to go back and change it. There is Nell and her grandfather on the one hand, the protagonists, and the villain is the terrifying Daniel Quilp. It seems at first that Nell's brother Fred is going to be important, but he disappears and does not come back until the last page when we find out he has been dead for some time. It seems that Quilp's relations with his tyrannized wife are going to be important, but Quilp soon moves out of his house and leaves Mrs. Quilp more or less alone. It seems that Quilp is going to pursue the thirteen-year-old Nell sexually, but Nell and Grandpa flee in the night and Quilp never meets them again. They spend the rest of the book traveling from place to place not doing much, while Quilp plots against Nell's friend Kit Nubbles.
Dickens doesn't even bother to invent names for many of the characters. There is Nell’s unnamed grandfather; the old bachelor; the kind schoolmaster; the young student; the guy who talks to the fire in the factory in Birmingham; and the old single gentleman.
The high point of the book for me was the development of Dick Swiveller. When I first met Dick I judged him to be completely worthless; we later learn that Dick keeps a memorandum book with a list of streets he must not go into, lest he bump into one of his legion of creditors. But Dick turns out to have some surprises in him. Quilp's lawyer Sampson Brass is forced to take on Swiveller as a clerk, in furtherment of Quilp's scheme to get Swiveller married to Nell, another subplot that comes to nothing. While there, Swiveller, with nothing to amuse himself, teaches the Brasses’ tiny servant, a slave so starved and downtrodden that she has never been given a name, to play cribbage. She later runs away from the Brasses, and Dick names her Sophronia Sphynx, which he feels is “euphonious and genteel, and furthermore indicative of mystery.” He eventually marries her, “and they played many hundred thousand games of cribbage together.”
I'm not alone in finding Dick and Sophronia to be the most interesting part of The Old Curiosity Shop. The anonymous author of the excellent blog A Reasonable Quantity of Butter agrees with me, and so does G.K. Chesterton:
The real hero and heroine of The Old Curiosity Shop are of course Dick Swiveller and [Sophronia]. It is significant in a sense that these two sane, strong, living, and lovable human beings are the only two, or almost the only two, people in the story who do not run after Little Nell. They have something better to do than to go on that shadowy chase after that cheerless phantom.
Today is Dickens’ 204th birthday. Happy birthday, Charles!
Vanity Fair
I finally did get to Vanity Fair, which I am only a quarter of the way through. It seems that Vanity Fair is going to live or die on the strength of its protagonist Becky Sharp.
When I first met Ms. Sharp, I thought I would love her. She is independent, clever, and sharp-tongued. But she quickly turned out to be scheming, manipulative, and mercenary. She might be hateful if the people she was manipulating were not quite such a flock of nincompoops and poltroons. I do not love her, but I love watching her, and I partly hope that her schemes succeed, although I rather suspect that she will sabotage herself and undo all her own best plans.
Becky, like Jane Eyre, is a penniless orphan. She wants money, and in Victorian England there are only two ways for her to get it: She can marry it or inherit it. Unlike Jane, she does not have a long-lost wealthy uncle (at least, not so far) so she schemes to get it by marriage. It's not very creditable, but one can't feel too righteous about it; she is in the crappy situation of being a woman in Victorian England, and she is working hard to make the best of it. She is extremely cynical, but the disagreeable thing about a cynic is that they refuse to pretend that things are better than they are. I don't think she has done anything actually wrong, and so far her main path to success has been to act so helpful and agreeable that everyone loves her, so I worry that I may come out of this feeling that Thackeray does not give her a fair shake.
In the part of the book I am reading, she has just married the exceptionally stupid Rawdon Crawley. I chuckle to I think of the flattering lies she must tell him when they are in the sack. She has married him because he is the favorite relative of his rich but infirm aunt. I wonder at this, because the plan does not seem up to Becky’s standards: what if the old lady hangs on for another ten years? But perhaps she has a plan B that hasn't yet been explained.

Thackeray says that Becky is very good-looking, but in his illustrations she has a beaky nose and an unpleasant, predatory grin. In a recent film version she was played by Reese Witherspoon, which does not seem to me like a good fit. Although Becky is blonde, I keep picturing Aubrey Plaza, who always seems to me to be saying something intended to distract you from what she is really thinking.
I don't know yet if I will finish Vanity Fair—I never know if I will finish a book until I finish it, and I have at times said “fuck this” and put down a book that I was ninety-five percent of the way through—but right now I am eager to find out what happens next.
Blah blah blah
This post observes the tenth anniversary of this blog, which I started in January 2006, directly inspired by Steve Yegge’s rant on why You Should Write Blogs, which I found extremely persuasive. (Articles that appear to have been posted before that were backdated, for some reason that I no longer remember but would probably find embarrassing.) I hope my Gentle Readers will excuse a bit of navel-gazing and self-congratulation.
When I started the blog I never imagined that I would continue as long as I have. I tend to get tired of projects after about four years and I was not at all sure the blog would last even that long. But to my great surprise it is one of the biggest projects I have ever done. I count 484 published articles totalling about 450,000 words. (Also 203 unpublished articles in every possible state of incompletion.) I drew, found, stole, or otherwise obtained something like 1,045 diagrams and illustrations. There were some long stoppages between articles, but I always came back to it. And I never wrote out of obligation or to meet a deadline, but always because the spirit moved me to write.
Looking back on the old articles, I am quite pleased with the blog and with myself. I find it entertaining and instructive. I like the person who wrote it. When I'm reading articles written by other people it sometimes happens that I smile ruefully and wish that I had been clever enough to write that myself; sometimes that happens to me when I reread my own old blog articles, and then my smile isn't rueful.
The blog paints a good picture, I think, of my personality, and of the kinds of things that make me unusual. I realized long long ago that I was a lot less smart than many people. But the way in which I was smart was very different from the way most smart people are smart. Most of the smart people I meet are specialists, even ultra-specialists. I am someone who is interested in a great many things and who strives for breadth of knowledge rather than depth. I want to be the person who makes connections that the specialists are too nearsighted to see. That is the thing I like most about myself, and that comes through clearly in the blog. I know that if my twenty-five-year-old self were to read it, he would be delighted to discover that he would grow up to be the kind of person that he wanted to be, that he did not let the world squash his individual spark. I have changed, but mostly for the better. I am a much less horrible person than I was then: the good parts of the twenty-five-year-old’s personality have developed, and the bad ones have shrunk a bit. I let my innate sense of fairness and justice overcome my innate indifference to other people’s feelings, and I now treat people less callously than before. I am still very self-absorbed and self-satisfied, still delighted above all by my own mind, but I think I do a better job now of sharing my delight with other people without making them feel less.
My grandparents had Eliot and Thackeray on the shelf, and I was always intrigued by them. I was just a little thing when I learned that George Eliot was a woman. When I asked about these books, my grandparents told me that they were grown-up books and I wouldn't like them until I was older—the implication being that I would like them when I was older. I was never sure that I would actually read them when I was older. Well, now I'm older and hey, look at that: I grew up to be someone who reads Eliot and Thackeray, not out of obligation or to meet a deadline, but because the spirit moves me to read.
Thank you Grandma Libby and Grandpa Dick, for everything. Thank you, Gentle Readers, for your kind attention and your many letters through the years.
[Other articles in category /book] permanent link