Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFM |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 246 |
| Programming | 100 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Wed, 24 Nov 2010
git-reset
The Git subcommand git-reset is very frequently used, and is one of very few
commonly-used Git commands that can permanently destroy real work.
Once work is in the repository, it is almost completely safe from any
catastrophe. But git-reset also affects the working tree, and it is quite
possible to utterly destroy a day's work by doing git-reset --hard at the wrong
time. Unfortunately, the manual is unusually bad, with a huge pile of
this stuff:
working index HEAD target working index HEAD
----------------------------------------------------
A B C D --soft A B D
--mixed A D D
--hard D D D
--merge (disallowed)
working index HEAD target working index HEAD
----------------------------------------------------
A B C C --soft A B C
--mixed A C C
--hard C C C
--merge (disallowed)
Six more of these tables follow, giving the impression that git-reset is quite complicated. Sure, I'm gonna memorize 256 table entries. Or look up the results on the table before every git-reset. Not.
The thing to notice about the two tables I quoted above is that they are redundant, because the second one is simply a special case of the first, with D replaced by C. So if you were really in love with the tables, you might abbreviate the 64 table entries to 28:
working index target working index HEAD
----------------------------------------------------
A B C --soft A B C
--mixed A C C
--hard C C C
--merge (disallowed)
But even this is much more complicated than it should be. git-reset does up
to three things:
- It points the HEAD ref at a new 'target' commit, if you specified one.
- Then it copies the tree of the HEAD commit to the index, unless you said --soft.
- Finally, it copies the contents of the index to the working tree, if you said --hard.
Tables are good for computers to understand, because they have a uniform format and computers are unfazed by giant masses of redundant data. The computer will not understand the data regardless of how well-structured they are, so there is no reason to adopt a representation that showcases the structure.
For humans, however, tables are most useful when there is no deeper understanding of the structure to be had, because the structure tends to get lost in the profusion of data, as it did here.
[ Thanks to Aristotle Pagaltzis for pointing out that git checkout can also destroy the working tree, and for other corrections. ]
[Other articles in category /prog] permanent link
Mon, 15 Nov 2010
A draft of a short introduction to topology
One of my ongoing projects is to figure out how to explain topology
briefly. For example, What is
Topology?, putatively part 1 of a three-part series that I have
not yet written parts 2 or 3 of yet.
CS grad students often have to take classes in category theory. These classes always want to use groups and topological spaces as examples, and my experience is that at this point many of the students shift uncomfortably in their seats since they have not had undergraduate classes in group theory, topology, analysis, or anything else relevant. But you do not have to know much topology to be able to appreciate the example, so I tried to write up the minimal amount necessary. Similarly, if you already understand intuitionistic logic, you do not need to know much topology to understand the way in which topological spaces are natural models for intuitionistic logic—but you do need to know more than zero.
So a couple of years ago I wrote up a short introduction to topology for first-year computer science grad students and other people who similarly might like to know the absolute minimum, and only the absolute minimum, about topology. It came out somewhat longer than I expected, 11 pages, of which 6 are the introduction, and 5 are about typical applications to computer science. But it is a very light, fluffy 11 pages, and I am generally happy with it.
I started writing this shortly after my second daughter was born, and I have not yet had a chance to finish it. It contains many errors. Many, many errors. For example, there is a section at the end about the compactness principle, which can only be taken as a sort of pseudomathematical lorem ipsum. This really is a draft; it is only three-quarters finished.
But I do think it will serve a useful function once it is finished, and that finishing it will not take too long. If you have any interest in this project, I invite you to help.
The current draft is version 0.6 of 2010-11-14. I do not want old erroneous versions wandering around confusing people in my name, so please do not distribute this draft after 2010-12-15. I hope to have an improved draft available here before that.
Please do send me corrections, suggestions, questions, advice, patches, pull requests, or anything else.
- PDF
- LaTeX source
- Github git repository (git://github.com/mjdominus/topology-doc.git)
[Other articles in category /math] permanent link
Wed, 10 Nov 2010
Revert-all-buffers
This is another article about a trivial tool that is worth more to me
than it cost to make. It's my new revert-all-buffers
function for Emacs.
Here's the use case: I'm editing 17 files, and I've saved a bunch of changes to them. Then I commit the changes with git, and then I change the working copy of the files out from under Emacs by doing some other git operation—I merge in another branch, or do a rebase, or something like that.
Now when I go back to edit the files, the Emacs buffers are out of date. Emacs notices that, and for each file, it will at some point ask me "Contents of ... have changed on disk; do you really want to edit the buffer?", interrupting my train of thought. I can answer the question by typing r, which will refresh the buffer from the disk version, but having to do that for every buffer is a pain, because I know all those files have changed, and I don't want to be asked each time.
Here's the solution:
(defun revert-all-buffers ()
"Refreshes all open buffers from their respective files"
(interactive)
(let* ((list (buffer-list))
(buffer (car list)))
(while buffer
(when (and (buffer-file-name buffer)
(not (buffer-modified-p buffer)))
(set-buffer buffer)
(revert-buffer t t t))
(setq list (cdr list))
(setq buffer (car list))))
(message "Refreshed open files"))
I have this function bound to some otherwise useless key: it runs
through all the buffers, and for each one that has an associated file,
and has no unsaved changes, it reverts the contents from the
version on the disk.This occasionally fails, most often because I have removed or renamed a file from the disk that I still have open in Emacs. Usually the response is to close the buffer, or reopen it from the new name. I could probably handle that properly in 99% of cases just by having Emacs close the buffer, but the other cases could be catastrophic, so I'm leaving it the way it is for a while.
I swiped the code, with small changes, from EmacsWiki.
[Other articles in category /prog] permanent link
Mon, 08 Nov 2010
Semi-boneless ham
The Math Project on Wikipedia is having a discussion about whether or
not to have an article about the jargon term "semi-infinite", which I
have long considered one of my favorite jargon terms, because it
sounds so strange, but makes so much sense. A structure is
semi-infinite when it is infinite in one direction but not in the
other. For example, the set of positive integers is semi-infinite,
since it possesses a least element (1) but no greatest element.
Similarly rays in geometry are semi-infinite.
The term is informal, however, and it's not clear just what it should mean in all cases. For example, consider the set S of 1/n for every positive integer n. Is this set semi-infinite? It is bounded in both directions, since it is contained in [0, 1]. But as you move left through the set, you ancounter an infinite number of elements, so it ought to be semi-infinite in the same sense that S ∪ { 1-x : x ∈ S } is fully-infinite. Whatever sense that is.
Informal and ill-defined it may be, but the term is widely used; one can easily find mentions in the literature of semi-infinite paths, semi-infinite strips, semi-infinite intervals, semi-infinite cylinders, and even semi-infinite reservoirs and conductors.
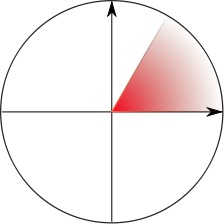
 The term has spawned an
offshoot, the even stranger-sounding "quarter-infinite". This seems
to refer to a geometric object that is unbounded in the same way that
a quarter-plane is unbounded, where "in the same way" is left rather
vague. Consider the set (depicted at left) of all points of the plane
for which 0 ≤ |y/x| ≤ √3, for example; is
this set quarter-infinite, or only 1/6-infinite? Is the set of points
(depicted at right) with xy > 1 and x, y >
0 quarter-infinite? I wouldn't want to say. But the canonical
example is simple: the product of two semi-infinite intervals is a
quarter-infinite set.
The term has spawned an
offshoot, the even stranger-sounding "quarter-infinite". This seems
to refer to a geometric object that is unbounded in the same way that
a quarter-plane is unbounded, where "in the same way" is left rather
vague. Consider the set (depicted at left) of all points of the plane
for which 0 ≤ |y/x| ≤ √3, for example; is
this set quarter-infinite, or only 1/6-infinite? Is the set of points
(depicted at right) with xy > 1 and x, y >
0 quarter-infinite? I wouldn't want to say. But the canonical
example is simple: the product of two semi-infinite intervals is a
quarter-infinite set.
I was going to say that I had never seen an instance of the obvious next step, the eighth-infinite solid, but in researching this article I did run into a few. I can't say it trips off the tongue, however. And if we admit that a half of a quarter-infinite plane segment is also eighth-infinite, we could be getting ourselves into trouble.
(This all reminds me of the complaint of J.H. Conway of the increasing use of the term "biunique". Conway sarcastically asked if he should expect to see "triunique" and soforth, culminating in the idiotic "polyunique".)
Sometimes "semi" really does mean exactly one-half, as in "semimajor axis" (the longest segment from the center of an ellipse to its boundary), "semicubic parabola" (determined by an equation with a term kx3/2), or "semiperimeter" (half the perimeter of a triangle). But just as often, "semi" is one of the dazzling supply of mathematical pejoratives. ("Abnormal, irregular, improper, degenerate, inadmissible, and otherwise undesirable", says Kelley's General Topology.) A semigroup, for example, is not half of a group, but rather an algebraic structure that possesses less structure than a group. Similarly, one has semiregular polyhedra and semidirect products.
I was planning to end with a note that mathematics has so far avoided the "demisemi-" prefix. But alas! Google found this 1971 paper on Demi-semi-primal algebras and Mal'cev-type conditions.
[Other articles in category /math] permanent link
Fri, 05 Nov 2010
Linus Torvalds' Greatest Invention
Happy Guy Fawkes' Day!
On Wednesday night I gave a talk for the Philadelphia Linux Users' Group on "Linus Torvalds' Greatest Invention". I was hoping that some people would show up expecting it to be Linux, but someone spilled the beans ahead of time and everyone knew it was going to be about Git. But maybe that wasn't so bad because a bunch of people showed up to hear about Git.
But then they were probably disappointed because I didn't talk at all about how to use Git. I talked a little about what it would do, and some about implementation. I used to give a lot of talks of the type "a bunch of interesting crap I threw together about X", but in recent years I've felt that a talk needs to have a theme. So for quite a while I knew I wanted to talk about Git internals, but I didn't know what the theme was.
Then I realized that the theme could be that Git proves that Linus was really clever. With Linux, the OS was already designed for him, and he didn't have to make a lot of the important decisions, like what it means to be a file. But Git is full of really clever ideas that other people might not have thought of.
Anyway, the slides are online if you are interested in looking.
[Other articles in category /misc] permanent link
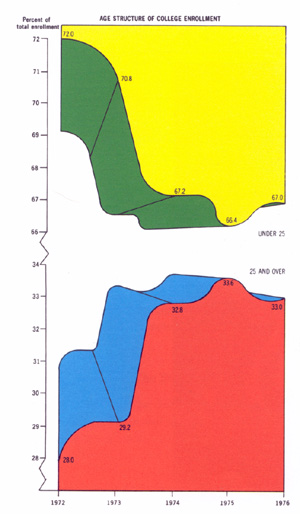
Tue, 05 Oct 2010 In his awesome classic The Visual Display of Quantitative Information, Edward Tufte presents this infographic:
Unfortunately the standards of the Internet can be even lower than those of print, as exhibited by this infographic, produced by Pingdom:
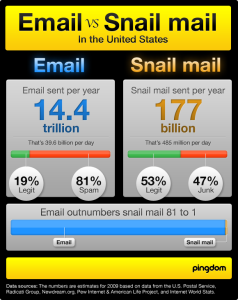
Chapter 6 of Tufte's book, "Data-Ink Maximization and Graphical Design", explores the exercise of erasing all the ink from an infographic that does not perform the function of communicating data. If we were to take this a little farther, and replace the original 80,265-byte graphic file with the 32 bytes of numeric data that it was designed to communicate, we might conclude that the image contained an astounding 99.96% chartjunk.
[Other articles in category /IT] permanent link
Sat, 18 Sep 2010
The coming singularity
A Wikipedia user asked on the Wikipedia reference desk page:
You know the idea that eventually we'll be able to download our brains/personalities to computer, to achieve physical immortality?There is a big trouble with this version of the immortality thing that people rarely mention. You go to the scanning and uploading center one day and write them a check. They scan and upload your brain, and say "All done, time to go home!"
"That's it?" you say. "I don't feel any different."
"Well, of course not. You're no different. But the uploaded version is immortal."
Then you go home and grow old, and every once in a while you get an email:
From: Mark Dominus (Immortal version) <mjd@forever.org> Subject: Wish you were here Having a great time here in paradise! Haven't aged a day. Thanks!Or maybe one like this:
From: Mark Dominus (Immortal version) <mjd@forever.org> Subject: Guess what I just did? Today I had sex with Arthur C. Clarke while swimming in a giant hot-fudge sundae. It was totally awesome! Too bad you couldn't be here. I know exactly how much you would have enjoyed it. Sorry to hear you're sick. Hope the chemo works out.Then you die, and some computer program somewhere simulates the immortal version of you having a little ritual observance to mark your passing.
Sometimes the proponents of this scheme try to conceal this enormous drawback by suggesting that they obliterate the original version of you immediately after the upload. Consider carefully whether you believe this will improve the outcome.
[Other articles in category /brain] permanent link
Fri, 27 Aug 2010
A dummy generator for mock objects
I am not sure how useful this actually is, but I after having used it
once it was not yet obvious that it was a bad idea, so I am writing it
up here.
Suppose you are debugging some method, say someMethod, which accepts as one of its arguments complicated, annoying objects $annoying that you either can't or don't want to instantiate. This might be because $annoying is very complicated, with many sub-objects to set up, or perhaps you simply don't know how to build $annoying and don't care to find out.
That is okay, because you can get someMethod to run without the full behavior of $annoying. Say for example someMethod calls $annoying->foo_manager->get_foo(...)->get_user_id. You don't understand or care about the details because for debugging someMethod it is enough to suppose that the end result is the user ID 3. You could supply a mock object, or several, that implement the various methods, but that requires some work up front.
Instead, use this canned Dummy class. Instead of instantiating a real $annoying (which is difficult) or using a bespoke mock object, use Dummy->new("annoying"):
package Dummy;
use Data::Dumper;
$Data::Dumper::Terse = 1;
our $METHOD;
my @names = qw(bottle corncob euphonium octopus potato slide);
my $NAME = "aaa";
sub new {
my ($class, $name) = @_;
$name ||= $METHOD || shift(@names) || $NAME++;
bless { N => $name } => $class;
}
The call Dummy->new("annoying") will generate an ad-hoc mock
object; whenever any method is called on this dummy object, the call
will be caught by an AUTOLOAD that will prompt you for the
return value you want it to produce:
sub AUTOLOAD {
my ($self, @args) = @_;
my ($p, $m) = $AUTOLOAD =~ /(.*)::(.*)/;
local $METHOD = $m;
print STDERR "<< $_[0]{N}\->$m >>\n";
print STDERR "Arguments: " . Dumper(\@args) . "\n";
my $v;
do {
print STDERR "Value? ";
chomp($v = <STDIN>);
} until eval "$v; 1";
return(eval $v);
}
sub DESTROY { }
1;
The prompt looks like this:
<< annoying->foo_manager >> Arguments: [] Value?If the returned value should be a sub-object, no problem: just put in new Dummy and it will make a new Dummy object named foo_manager, and the next prompt will be:
<< foo_manager->get_foo >> Arguments: ... ... Value?Now you can put in new Dummy "(Fred's foo)" or whatever. Eventually it will ask you for a value for (Fred's foo)->id and you can have it return 4.
It's tempting to add caching, so that it won't ask you twice for the results of the same method call. But that would foreclose the option to have the call return different results twice. Better, I think, is for the user to cache the results themselves if they plan to use them again; there is nothing stopping the user from entering a value expression like $::val = ....
This may turn out to be one of those things that is mildly useful, but not useful enough to actually use; we'll see.
[Other articles in category /prog/perl] permanent link
Thu, 26 Aug 2010
Monad terminology problem
I think one problem (of many) that beginners might have with Haskell
monads is the confusing terminology. The word "monad" can refer to
four related but different things:
- The Monad typeclass itself.
- When a type constructor T of kind ∗ → ∗ is an
instance of Monad we say that T "is a monad".
For example, "Tree is a monad"; "((→) a) is
a monad". This is the only usage that is strictly corrrect.
- Types resulting from the application of monadic type constructors
(#2) are sometimes referred to as monads. For example, "[Integer]
is a monad".
- Individual values of monadic types (#3) are often referred to as
monads. For example, the "All
About Monads" tutorial says "A
list is also a monad".
The most serious problem here is #4, that people refer to individual values of monadic types as "monads". Even when they don't do this, they are hampered by the lack of a good term for it. As I know no good alternative has been proposed. People often say "monadic value" (I think), which is accurate, but something of a mouthful.
One thing I have discovered in my writing life is that the clarity of a confusing document can sometimes be improved merely by replacing a polysyllabic noun phrase with a monosyllable. For example, chapter 3 of Higher-Order Perl discussed the technique of memoizing a function by generating an anonymous replacement for it that maintains a cache and calls the real function on a cache miss. Early drafts were hard to understand, and improved greatly when I replaced the phrase "anonymous replacement function" with "stub". The Perl documentation was significantly improved merely by replacing "associative array" everywhere with "hash" and "funny punctuation character" with "sigil".
I think a monosyllabic replacement for "monadic value" would be a similar boon to discussion of monads, not just for beginners but for everyone else too. The drawback, of introducing yet another jargon term, would in this case be outweighed by the benefits. Jargon can obscure, but sometimes it can clarify.
The replacement word should be euphonious, clear but not overly specific, and not easily confused with similar jargon words. It would probably be good for it to begin with the letter "m". I suggest:
So return takes a value and returns a mote. The >>= function similarly lifts a function on pure values to a function on motes; when the mote is a container one may think of >>= as applying the function to the values in the container. [] is a monad, so lists are motes. The expression on the right-hand side of a var ← expr in a do-block must have mote type; it binds the mote on the right to the name on the left, using the >>= operator.
I have been using this term privately for several months, and it has been a small but noticeable success. Writing and debugging monadic programs is easier because I have a simple name for the motes that the program manipulates, which I can use when I mumble to myself: "What is the type error here? Oh, commit should be returning a mote." And then I insert return in the right place.
I'm don't want to oversell the importance of this invention. But there is clearly a gap in the current terminology, and I think it is well-filled by "mote".
(While this article was in progress I discovered that What a Monad is not uses the nonceword "mobit". I still prefer "mote".)
[Other articles in category /prog/haskell] permanent link
Sun, 03 Jan 2010
A short bibliography of probability monads
Several people helpfully wrote to me to provide references to earlier
work on probability
distribution monads. Here is a summary:
- Material related to Martin Erwig and Steve Kollmansberger's
probability library:
- Probabilistic Functional Programming in Haskell, their 2006 paper
- the package, described in the paper, and specifically its probability distribution monad
- Some
commentary on this library, by someone who doesn't put their name
on their blog.
- Some stuff from Dan Piponi's blog:
- Eric Kidd's blog: "What would a programming language look like if Bayes’ rule were as simple as an if statement?"
I did not imagine that my idea was a new one. I arrived at it by thinking about List as a representation of non-deterministic computation. But if you think of it that way, the natural interpretation is that every list element represents an equally likely outcome, and so annotating the list elements with probabilities is the obvious next step. So the existence of the Erwig library was not a big surprise.
A little more surprising though, were the references in the Erwig paper. Specifically, the idea dates back to at least 1981; Erwig cites a paper that describes the probability monad in a pure-mathematics context.
Nobody responded to my taunting complaint about Haskell's failure to provide support a good monad of sets. It may be that this is because they all agree with me. (For example, the documentation of the Erwig package says "Unfortunately we cannot use a more efficient data structure because the key type must be of class Ord, but the Monad class does not allow constraints for result types.") But a number of years ago I said that the C++ macro processor blows goat dick. I would not have put it so strongly had I not naïvely believed that this was a universally-held opinion. But no, plenty of hapless C++ programmers wrote me indignant messages defending their macro system. So my being right is no guarantee that language partisans will not dispute with me, and the Haskell community's failure to do so in this case reflects well on them, I think.
[Other articles in category /prog/haskell] permanent link