Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFM |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 246 |
| Programming | 100 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Fri, 28 Mar 2008
Suffering from "make install"
I am writing application X, which uses the nonstandard perl
modules DBI, DBD::SQLite, and Template.
These might not be available on the target system, so I got the idea
to include them in the distribution for X and have the build
process for X build and install the modules. X
already carries its own custom Perl modules in X/lib anyway,
so I can just install DBI and the others into X/lib
and everything will Just Work. Or so I thought.
After building DBI, for example, how do you get it to install itself into X/lib instead of the default system-wide location, which only the super-user has permission to modify?
There are at least five solutions to this common problem.
Uh-oh. If solution #1 had worked, people would not have needed to invent solution #2. If solution #2 had worked, people would not have needed to invent solution #3. Since there are five solutions, there is a good chance that none of them work.
You can, I am informed:
- Set PREFIX=X when building the Makefile
- Set INSTALLDIRS=vendor and VENDORPREFIX=X when
building the Makefile
- Or maybe instead of VENDORPREFIX you need to set INSTALLVENDORLIB or something
- Or maybe instead of setting them while building the Makefile you need to set them while running the make install target
- Set LIB=X/lib when building the Makefile
- Use PAR
- Use local::lib
Some of these items fail because they just plain fail. For example, the first thing everyone says is that you can just set PREFIX to X. No, because then the module Foo does not go into X/lib/Foo.pm. It goes into X/Foo/lib/perl5/site_perl/5.12.23/Foo.pm. Which means that if X does use lib 'X/lib'; it will not be able to find Foo.
 The manual (which goes by the marvelously
obvious and easily-typed name of ExtUtils::MakeMaker, by the
way) is of limited help. It recommends solving the problem by
travelling to Paterson, NJ, gouging your eyes out with your mom's
jewelry, and then driving over the Passaic River falls. Ha ha, just
kidding. That would be a big improvement on what it actually
suggests, for three reasons. First, it is clear and straightforward.
Second, it would feel better than the stuff it does suggest. And
third, it would actually solve your problem, although obliquely.
The manual (which goes by the marvelously
obvious and easily-typed name of ExtUtils::MakeMaker, by the
way) is of limited help. It recommends solving the problem by
travelling to Paterson, NJ, gouging your eyes out with your mom's
jewelry, and then driving over the Passaic River falls. Ha ha, just
kidding. That would be a big improvement on what it actually
suggests, for three reasons. First, it is clear and straightforward.
Second, it would feel better than the stuff it does suggest. And
third, it would actually solve your problem, although obliquely.
It turns out there is a simple solution that doesn't involve travelling to New Jersey. The first thing you have to do is give up entirely on trying to use make install to install the modules. It is completely broken for this application, because even if the destination could somehow be forced to be what you wanted—and, after all, why would you expect that make install would let you configure the destination directory in a simple fashion?—it would still install not only the contents of MODULE/lib, but also the contents of MODULE/bin, MODULE/man, MODULE/share, MODULE/pus, MODULE/dork, MODULE/felch, and MODULE/scrotum, some of which you probably didn't want.
So no. But the solution is actually simple. The normal module build process (as distinct from the install process) puts all this crap under MODULE/blib. The test suite is run against the blib installation. So the test programs have the same problem that X has. If they can find the stuff under blib, so can X, by replicating the layout under blib and then doing what the test suite does.
In fact, the modules are installed into the proper subdirectories of MODULE/blib/lib. So the simple solution is just to build the module and then, instead of trying to get the installer to put the right stuff in the right place, use cp -pr MODULE/blib/lib/* X/lib. Problem solved.
For modules with a shared library, you need to copy MODULE/blib/arch/auto/* into X/lib/auto also.
I remember suffering over this at least ten years ago, when a student in a class I was teaching asked me how to do it and I let ExtUtils::MakeMaker make a monkey of me. I was amazed to find myself suffering over it once again. I am relieved to have found the right answer.
This is one of those days when I am not happy with software. It sometimes surprises me how many of those days involve make.
Dennis Ritchie once said that "make is like Pascal. Everybody likes it, so they go in and change it." I never really thought about this before, but it now occurs to me that probably Ritchie meant that they like make in about the same way that they like bladder stones. Because Dennis Ritchie probably does not like Pascal, and actually nobody else likes Pascal either. They may say they do, and they may even think they do, but if you look a little closer it always turns out that the thing they like is not actually Pascal, but some language that more or less resembles Pascal. Unfortunately, the changes people make to make tend to make it bigger and wartier, and this improves make about as much as it would improve a bladder stone.
I would like to end this article on a positive note. If you haven't already, please read Recursive make Considered Harmful and be prepared to be blinded by the Glorious Truth therein.
[Other articles in category /prog] permanent link
Tue, 25 Mar 2008
The "z" command: output filtering
My last few articles
([1]
[2]
[p]
[p-2]) have been about
this z program. The first part of
this article is a summary of that discussion, which you can
skip if you remember it.
The idea of z is that you can do:
z grep pattern files...
and it does approximately the same as:
zgrep pattern files...
or you could do:
z sed script files...
and it would do the same as:
zsed script files...
if there were a zsed command, although there isn't.Much of the discussion has concerned a problem with the implementation, which is that the names of the original compressed files are not available to the command, due to the legerdemain z must perform in order to make the uncompressed data available to the command. The problem is especially apparent with wc:
% z wc *
411 2611 16988 ctime.blog
71 358 2351 /proc/self/fd/3
121 725 5053 /proc/self/fd/4
51 380 2381 files-talk.blog
48 145 885 find-uniq.pl
288 2159 12829 /proc/self/fd/5
95 665 4337 ssh-agent-revisted.blog
221 941 6733 struct-inode.blog
106 555 3976 sync-2.blog
115 793 4904 sync.blog
124 624 4208 /proc/self/fd/6
1651 9956 64645 total
Here /proc/self/fd/3 and the rest should have been names ending in .gz, such as env-2.blog.gz.
Another possible solution
At the time I wrote the first article, it occurred to me briefly that it would be possible to have z capture the output of the command and attempt to translate /proc/self/fd/3 back to env-2.blog.gz or whatever is appropriate, because although the subcommand does not know the original filenames, z itself does. The code would look something like this. Instead of ending by execing the command, as the original version of z did:exec $command, @ARGV; die "Couldn't run '$command': $!.\n";this revised version of z, which we might call zz, would end with the code to translate back to the original filenames:
open my($out), "-|", $command, @ARGV
or die "Couldn't run '$command': $!.\n";
while (<$out>) {
s{/proc/self/fd/(\d+)}{$old[$1]}g;
print;
}
Here @old is an array that translates from file descriptors
back to the original filename.At the time, I thought of doing this, and my immediate thought was "well, that is so obviously a terrible idea that it is not worth even mentioning", so I left it out. But since then at least five people have written to me to suggest it, so it appears that it is not obviously a terrible idea. I had to think a little deeper about why I thought it was a terrible idea.
Really the question is why I think this is a more terrible idea than the original z program was in the first place. Because one could say that z is garbling the output of its command, and the filtering code in zz is only un-garbling it. But I think this isn't the right way to look at it.
The output of the command has a certain format, a certain structure. We don't know ahead of time what that structure is, but it can be described for any particular command. For instance, the output of wc is always a sequence of lines where each line has four whitespace-separated fields, of which the first three are numerals and the last is a filename, and then a final total line at the end.
Similarly, the output of tar is a file in a complicated binary format, one which is documented somewhere and which is intelligible to other instances of the tar command that are trying to decode it.
The original behavior of z may alter the content of the command output to some extent, replacing some filenames with others. But it cannot disrupt the structure or the format of the file, ever. This is because the output of z tar is the output of tar, unmodified. The z program tampers with the arguments it gives to tar, but having done that it runs tar and lets tar do what it wants, and tar then must produce a tar-format output, possibly not the one it would have normally produced—the content might be a little different—but a properly-formatted one for sure. In particular, any program written to deal properly with the output of tar will still work with the output of z tar. The output might not have the same meaning, but we can say very particularly what the extent of the differences might be: if the output mentions filenames, then some of these might have changed from the true filenames to filenames of the form /proc/self/fd/37.
With zz, we cannot make any such guarantee. The output of zz tar zc foo.gz, for example, might be in proper .tar.gz format. But suppose the output of tar zc foo.gz creates compressed binary output that just happens to contain the byte sequence 2f70 726f 632f 7365 6c66 2f66 642f 33? (That is, "/proc/self/fd/3".) Then zz will silently replace these 15 bytes with the six bytes 666f 6f2e 677a.
What if the original sequence was understood as part of a sequence of 2-byte integers? The result is not even properly aligned. What if that initial 2f was a count? The resulting count (66) is much too long. The result would be utterly garbled and unintelligible to tar zx. What the tar command will do with a garbled input is not well-defined: it might dump core, or it might write out random garbage data, or overwrite essential files in the filesystem. We are into nasal demon territory. With the original z, we never get anywhere near the nasal demons.
I suppose the short summary here is that z treats its command as a black box, while zz pretends to understand what comes out of it. But zz's understanding is a false pretense. My experience says that programs should not screw around with things they don't understand, and this is why I instantly rejected the idea when I thought of it before.
One correspondent argued that the garbling is very unlikely, and proposed various techniques to make it even less likely, mostly by rewriting the input filenames to various long random strings. But I felt then that this was missing the point, and I still do. He says it is unlikely, but he doesn't know that it is unlikely, and indeed the unlikeliness depends on the format of the output of the command, which is precisely the unknown here. In my view, the difference between z and zz is that the changes that z makes are bounded, because you can describe them briefly, as I did above, and the changes that zz makes are unbounded, because there is no limit to what could happen as a result.
On the other hand, this correspondent made a good point that if the output of zz is not consumed by anything other than human eyeballs, there may be no real problem. And for some particular commands, such as wc, there is never any problem at all. So perhaps it's a good idea to add a command-line option to z to enable the zz behavior. I did this in my version, and I'm going to try it out and see how it goes.
Complete modified source code is available. (Diffs from previous version.)
[Other articles in category /Unix] permanent link
Sat, 22 Mar 2008
The "z" command: alternative implementations
In yesterday's article I discussed a
possibly-useful utility program named z, which has a flaw.
To jog your memory, here is a demonstration:
% z grep immediately *
ctime.blog:we want to update. It is immediately copied into a register, and
/proc/self/fd/3:All five people who wrote to me about this immediately said "oh, yes,
/proc/self/fd/5:program continues immediately, possibly posting its message. (It
struct-inode.blog:is a symbolic link, its inode is returned immediately; iname() would
sync.blog:and reports success back to the process immediately, even though the
For a detailed discussion, see the
previous article.Fixing this flaw seems difficult-to-impossible. As I said earlier, the trick is to fool the command into reading from a pipe when it thinks it is opening a file, and this is precisely what /proc/self/fd is for. But there is an older, even more widely-implemented Unix feature that does the same thing, namely the FIFO. So an alternative implementation creates one FIFO for each compressed file, with a gzip process writing to the FIFO, and tells the command to read from the FIFO. Since we have some limited control over the name of the FIFO, we can ameliorate the missing-filename problem to some extent. Say, for example, we create the FIFOs in /tmp/PID. Then the broken zgrep example above might look like this instead:
% z grep immediately *
ctime.blog:we want to update. It is immediately copied into a register, and
/tmp/7516/env-2.blog.gz:All five people who wrote to me about this immediately said "oh, yes,
/tmp/7516/qmail-throttle.blog.gz:program continues immediately, possibly posting its message. (It
struct-inode.blog:is a symbolic link, its inode is returned immediately; iname() would
sync.blog:and reports success back to the process immediately, even though the
The output is an improvement, but it is not completely solved, and the
cost is that the process and file management are much more
complicated. In fact, the cost is so high that you have to wonder if
it might not be simpler to replace z with a shell script that
copies the data to a temporary directory, uncompresses the files, and
runs the command on the uncompressed files, perhaps something along
these lines:
#!/bin/sh
DIR=/tmp/$$
mkdir $DIR
COMMAND=$1
shift
cp -p "$@" $DIR
cd $DIR
gzip -d *
$COMMAND *
This has problems too, but my point is that if you are willing to
accept a crappy, semi-working solution along the lines of the FIFO
one, simpler ones are at hand. You can compare the FIFO version
directly with the shell script, and I think the FIFO version loses.
The z implementation I have is a
solution in a different direction, and different tradeoffs, and so
might be preferable to it in a number of ways. But as I said, I don't know yet.
[ Addendum 20080325: Several people suggested a fix that I had considered so unwise that I didn't even mention it. But after receiving the suggestion repeatedly, I wrote an article about it. ]
[Other articles in category /Unix] permanent link
Fri, 21 Mar 2008
z-commands
The gzip distribution includes a command called zcat. Its
command-line arguments can include any number of filenames, compressed
or not, and it prints out the contents, uncompressing them on the fly
if necessary. Sometime later a zgrep command appeared, which
was similar but which also performed a grep search.
But for anything else, you either need to uncompress the files, or build a special tool. I have a utility that scans the web logs of blog.plover.com, and extracts a report about new referrers. The historical web logs are normally kept compressed, so I recently built in support for decompression. This is quite easy in Perl. Normally one scans a sequence of input files something like this:
while (<>) {
... do something with $_ ...
}
The <> operator implicitly scans all the lines in all the
files named in the command-line arguments, opening a new file each
time the previous one is exhausted. To decompress the files on the fly, one can preprocess the command-line arguments:
for (@ARGV) {
if (/\.gz$/) {
$_ = "gzip -dc $_ |";
}
}
while (<>) {
... do something with $_ ...
}
The for loop scans the command-line arguments, replacing each
one that has the form foo.gz with gzip -dc foo.gz |.
Perl's magic open semantics treat filenames specially if they end with
a pipe symbol: a pipe to a command is opened instead. Of course, anyone can
think of half a dozen ways in which this can go wrong. But Larry
Wall's skill in making such tradeoffs has been a large factor in Perl's
success. But it bothered me to have to make this kind of change in every program that wanted to handle compressed files. We have zcat and zgrep; where are zcut, zpr, zrev, zwc, zcol, zbc, zsed, zawk, and so on? Echh.
But after I got to thinking about it, I decided that I could write a single z utility that would do a lot of the same things. Instead of this:
zsed -e 's/:.*//' * | ...
where the * matches some files that have .gz
suffixes and some that haven't, one would write:
z sed -e 's/:.*//' * | ...
and it would Just Work. That's the idea, anyway.If sed were written in Perl, z would have an easy job. It could rely on Perl's magic open, and simply preprocess the arguments before running sed:
# hypothetical implementation of z
#
my $command = shift;
for (@ARGV) {
if (/\.gz$/) {
$_ = "gzip -dc $_ |";
}
}
exec $command, @ARGV;
die "Couldn't run command '$command': $!\n";
But sed is not written in Perl, and has no magic open. So I
have to play a trickier trick:
for my $file (@ARGV) {
if ($file =~ /\.gz$/) {
unless (open($fhs[@fhs], "-|", "gzip", "-cd", $file)) {
warn "Couldn't open file '$file': $!; skipping\n";
next;
}
my $fd = fileno $fhs[-1];
$_ = "/proc/self/fd/$fd";
}
}
# warn "running $command @ARGV\n";
exec $command, @ARGV;
die "Couldn't run command '$command': $!\n";
This is a stripped-down version to illustrate the idea. For various
reasons that I explained
yesterday, it does not actually work.
The
complete, working source code is here.The idea, as before, is that the program preprocesses the command-line arguments. But instead of replacing the arguments with pipe commands, which are not supported by open(2), the program sets up the pipes itself, and then directs the command to take its input from the pipes by specifying the appropriate items from /proc/self/fd.
The trick depends crucially on having /proc/self/fd, or /dev/fd, or something of the sort, because otherwise there's no way to trick the command into reading from a pipe when it thinks it is opening a file. (Actually there is at least one other way, involving FIFOs, which I plan to discuss tomorrow.) Most modern systems do have /proc/self/fd. That feature postdates my earliest involvement with Unix, so it isn't a ready part of my mental apparatus as perhaps it ought to be. But this utility seems to me like a sort of canonical application of /proc/self/fd, in the sense that, if you couldn't think what /proc/self/fd might be good for, then you could read this example and afterwards have a pretty clear idea.
The z utility has a number of flaws. Principally, the original filenames are gone. Here's a typical run with regular zgrep:
% zgrep immediately *
ctime.blog:we want to update. It is immediately copied into a register, and
env-2.blog.gz:All five people who wrote to me about this immediately said "oh, yes,
qmail-throttle.blog.gz:program continues immediately, possibly posting its message. (It
struct-inode.blog:is a symbolic link, its inode is returned immediately; iname() would
sync.blog:and reports success back to the process immediately, even though the
But here's the same thing with z:
% z grep immediately *
ctime.blog:we want to update. It is immediately copied into a register, and
/proc/self/fd/3:All five people who wrote to me about this immediately said "oh, yes,
/proc/self/fd/5:program continues immediately, possibly posting its message. (It
struct-inode.blog:is a symbolic link, its inode is returned immediately; iname() would
sync.blog:and reports success back to the process immediately, even though the
The problem is even more glaring in the case of commands like
wc:
% z wc *
411 2611 16988 ctime.blog
71 358 2351 /proc/self/fd/3
121 725 5053 /proc/self/fd/4
51 380 2381 files-talk.blog
48 145 885 find-uniq.pl
288 2159 12829 /proc/self/fd/5
95 665 4337 ssh-agent-revisted.blog
221 941 6733 struct-inode.blog
106 555 3976 sync-2.blog
115 793 4904 sync.blog
124 624 4208 /proc/self/fd/6
1651 9956 64645 total
So perhaps z will not turn out to be useful enough to be more than a curiosity. But I'm not sure yet.
This is article #300 on my blog. Thanks for reading.
[ Addendum 20080322: There is a followup to this article. ]
[ Addendum 20080325: Another followup. ]
[Other articles in category /Unix] permanent link
Closed file descriptors: the answer
This is the answer to yesterday's article about a
small program that had a mysterious error.
my $command = shift;
for my $file (@ARGV) {
if ($file =~ /\.gz$/) {
my $fh;
unless (open $fh, "<", $file) {
warn "Couldn't open $file: $!; skipping\n";
next;
}
my $fd = fileno $fh;
$file = "/proc/self/fd/$fd";
}
}
exec $command, @ARGV;
die "Couldn't run command '$command': $!\n";
When the loop exits, $fh is out of scope, and the
filehandle it contains is garbage-collected, closing the file."Duh."
Several people suggested that it was because open files are not preserved across an exec, or because the meaning of /proc/self would change after an exec, perhaps because the command was being run in a separate process; this is mistaken. There is only one process here. The exec call does not create a new process; it reuses the same one, and it does not affect open files, unless they have been flagged with FD_CLOEXEC.
Abhijit Menon-Sen ran a slightly different test than I did:
% z cat foo.gz bar.gz
cat: /proc/self/fd/3: No such file or directory
cat: /proc/self/fd/3: No such file or directory
As he said, this makes it completely obvious what is wrong, since
the two files are both represented by the same file descriptor.
[Other articles in category /prog/perl] permanent link
Thu, 20 Mar 2008
Closed file descriptors
I wasn't sure whether to file this on the /oops
section. It is a mistake, and I spent a lot longer chasing the bug
than I should have, because it's actually a simple bug. But it isn't
a really big conceptual screwup of the type I like to feature in the
/oops section.
It concerns a
program that I'll discuss in detail tomorrow. In the meantime, here's
a stripped-down summary, and a stripped-down version of the code:
my $command = shift;
for my $file (@ARGV) {
if ($file =~ /\.gz$/) {
my $fh;
unless (open $fh, "<", $file) {
warn "Couldn't open $file: $!; skipping\n";
next;
}
my $fd = fileno $fh;
$file = "/proc/self/fd/$fd";
}
}
exec $command, @ARGV;
die "Couldn't run command '$command': $!\n";
The idea here is that this program, called z, will preprocess
the arguments of some command, and then run the command
with the modified arguments. For some of the command-line arguments,
here the ones named *.gz, the original file will be replaced
by the output of some file descriptor. In the example above, the
descriptor is attached to the original file, which is pointless. But
once this part of the program was working, I planned to change the code
so that the descriptor would be
attached to a pipe instead.Having written something like this, I then ran a test, which failed:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directory"Aha," I said instantly. "I know what is wrong. Perl set the close-on-exec flag on file descriptor 3."
You see, after a successful exec, the kernel will automatically close all file descriptors that have the close-on-exec flag set, before the exec'ed image starts running. Perl normally sets the close-on-exec flag on all open files except for standard input, standard output, and standard error. Actually it sets it on all open files whose file descriptor is greater than the value of $^F, but $^F defaults to 2.
So there is an easy fix for the problem: I just set $^F = 100000 at the top of the program. That is not the best solution, but it can be replaced with a better one once the program is working properly. Which I expected it would be:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directoryHuh, something is still wrong.
Maybe I misspelled /proc/self/fd? No, it is there, and contains the special files that I expected to find.
Maybe $^F did not work the way I thought it did? I checked the manual, but it looked okay.
Nevertheless I put in use Fcntl and used the fcntl function to remove the close-on-exec flags explicitly. The code to do that looks something like this:
use Fcntl;
....
my $flags = fcntl($fh, F_GETFD, 0);
fcntl($fh, F_SETFD, $flags & ~FD_CLOEXEC);
And try it again:
% z cat foo.gz cat: /proc/self/fd/3: No such file or directoryHuh.
I then wasted a lot of time trying to figure out an easy way to tell if the file descriptor was actually open after the exec call. (The answer turns out to be something like this: perl -MPOSIX=fstat -le 'print "file descriptor 3 is ", fstat(3) ? "open" : "closed"'.) This told me whether the error from cat meant what I thought it meant. It did: descriptor 3 was indeed closed after the exec.
Now your job is to figure out what is wrong. It took me a shockingly long time. No need to email me about it; I have it working now. I expect that you will figure it out faster than I did, but I will also post the answer on the blog tomorrow. Sometime on Friday, 21 March 2008, this link will start working and will point to the answer.
[ Addendum 20080321: I posted the answer. ]
[Other articles in category /prog/perl] permanent link
Fri, 14 Mar 2008
Drawing lines
As part of this thing I sometimes do when I'm not writing in my
blog—what is it called?—oh, now I remember.
As part of my job I had to produce the following display:
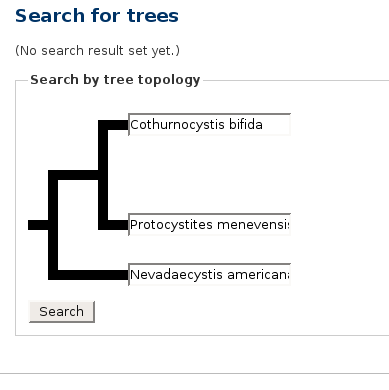
If you wanted to hear more about phylogeny, Java programming, or tree algorithms, you are about to be disappointed. The subject of my article today is those fat black lines.
The first draft of the page did not have the fat black lines. It had some incredibly awful ASCII-art that was not even properly aligned. Really it was terrible; it would have been better to have left it out completely. I will not make you look at it.
I needed the lines, so I popped down the "graphics" menu on my computer and looked for something suitable. I tried the Gimp first. It seems that the Gimp has no tool for drawing straight lines. If someone wants to claim that it does, I will not dispute the claim. The Gimp has a huge and complex control panel covered with all sorts of gizmos, and maybe one of those gizmos draws a straight line. I did not find one. I gave up after a few minutes.
Next I tried Dia. It kept selecting the "move the line around on the page" tool when I thought I had selected the "draw another line" tool. The lines were not constrained to a grid by default, and there was no obvious way to tell it that I wanted to draw a diagram smaller than a whole page. I would have had to turn the thing into a bitmap and then crop the bitmap. "By Zeus's Beard," I cried, "does this have to be so difficult?" Except that the oath I actually uttered was somewhat coarser and less erudite than I have indicated. I won't repeat it, but it started with "fuck" and ended with "this".
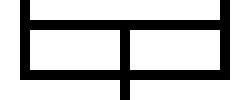
Here's what I did instead. I wrote a program that would read an input like this:
>-v-<
'-+-`
and produce a jpeg file that looks like this:
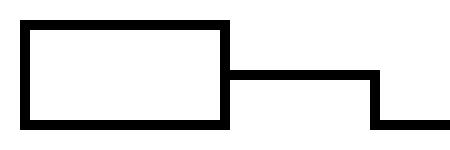
.---,
| >--,
'---` '-
Becomes this:
Now I know some of you are just itching to write to me and ask "why didn't you just use...?", so before you do that, let me remind you of two things. First, I had already wasted ten or fifteen minutes on "just use..." that didn't work. And second, this program only took twenty minutes to write.
The program depends on one key insight, which is that it is very, very easy to write a Perl program that generates a graphic output in "PBM" ("portable bitmap") format. Here is a typical PBM file:
P1
10 10
1111111111
1000000001
1000000001
1001111001
1001111001
1001111001
1001111001
1000000001
1000000001
1111111111
The P1 is a magic number that identifies the file format; it
is always the same. The 10 10 warns the processor that the
upcoming bitmap is 10 pixels wide and 10 pixels high. The following
characters are the bitmap data.
I'm not going to insult you by showing the 10×10 bitmap image
that this represents.PBM was invented about twenty years ago by Jef Poskanzer. It was intended to be an interchange format: say you want to convert images from format X to format Y, but you don't have a converter. You might, however, have a converter that turns X into PBM and then one that turns PBM into Y. Or if not, it might not be too hard to produce such converters. It is, in the words of the Extreme Programming guys, the Simplest Thing that Could Possibly Work.
There are also PGM (portable graymap) and PPM (portable pixmap) formats for grayscale and 24-bit color images as well. They are only fractionally more complicated.
Because these formats are so very, very simple, they have been widely adopted. For example, the JPEG reference implementation includes a sample cjpeg program, for converting an input to a JPEG file. The input it expects is a PGM or PPM file.
Writing a Perl program to generate a P?M file, and then feeding the output to pbmtoxbm or ppmtogif or cjpeg is a good trick, and I have used it many times. For example, I used this technique to generate a zillion little colored squares in this article about the Pólya-Burnside counting lemma. Sure, I could have drawn them one at a time by hand, and probably gone insane and run amuck with an axe immediately after, but the PPM technique was certainly much easier. It always wins big, and this time was no exception.
The program may be interesting as an example of this technique, and possibly also as a reminder of something else. The Perl community luminaries invest a lot of effort in demonstrating that not every Perl program looks like a garbage heap, that Perl can be as bland and aseptic as Java, that Perl is not necessarily the language that most closely resembles quick-drying shit in a tube, from which you can squirt out the contents into any shape you want and get your complete, finished artifact in only twenty minutes and only slightly smelly.
No, sorry, folks. Not everything we do is a brilliant, diamond-like jewel, polished to a luminous gloss with pages torn from one of Donald Knuth's books. This line-drawing program was squirted out of a tube, and a fine brown piece of engineering it is.
#!/usr/bin/perl
my ($S) = shift || 50;
$S here is "size". The default is to turn every character in
the input into a 50×50 pixel tile. Here's the previous example
with $S=10: 
my ($h, $w);
my $output = [];
while (<>) {
chomp;
$w ||= length();
$h++;
push @$output, convert($_);
}
The biggest defect in the program is right here: it assumes that each
line will have the same width $w. Lines all must be
space-padded to the same width. Fixing this is left as an easy
exercise, but it wasn't as easy as padding the inputs, so I didn't do it.The magic happens here:
open STDOUT, "| pnmscale 1 | cjpeg" or die $!;
print "P1\n", $w * $S, " ", $h * $S, "\n";
print $_, "\n" for @$output;
exit;
The output is run through cjpeg to convert the PBM data to
JPEG. For some reason cjpeg doesn't accept PBM data, only
PGM or PPM, however, so the output first goes through
pnmscale, which resizes a P?M input. Here the scale factor
is 1, which is a no-op, except that pnmscale happens to turn
a PBM input into a PGM output. This is what is known in the business
as a "trick". (There is a pbmtopgm program, but it does
something different.)If we wanted gif output, we could have used "| ppmtogif" instead. If we wanted output in Symbolics Lisp Machine format, we could have used "| pgmtolispm" instead. Ah, the glories of interchange formats.
I'm going to omit the details of convert, which just breaks each line into characters, calls convert_ch on each character, and assembles the results. (The complete source code is here if you want to see it anyway.) The business end of the program is convert_ch:
#
sub convert_ch {
my @rows;
my $ch = shift;
my $up = $ch =~ /[<|>^'`+]/i;
my $dn = $ch =~ /[<|>V.,+]/i;
my $lt = $ch =~ /[-<V^,`+]/i;
my $rt = $ch =~ /[->V^.'+]/i;
These last four variables record whether the tile has a line from its
center going up, down, left, or right respectively. For example,
"|" produces a tile with lines coming up and down from the
center, but not left or right. The /i in the regexes is
because I kept writing v instead of V in the
inputs.
my $top = int($S * 0.4);
my $mid = int($S * 0.2);
my $bot = int($S * 0.4);
The tile is divided into three bands, of the indicated widths. This
probably looks bad, or fails utterly, unless $S is a multiple
of 5. I haven't tried it. Do you think I care? Hint: I haven't tried
it.
my $v0 = "0" x $S;
my $v1 = "0" x $top . "1" x $mid . "0" x $bot;
push @rows, ($up ? $v1 : $v0) x $top;
This assembles the top portion of the tile, including the "up" line,
if there is one. Note that despite their names, $top also
determines the width of the left portion of the tile, and
$bot determines the width of the right portion. The letter
"v" here is for "vertical".Perhaps I should explain for the benefit of the readers of Planet Haskell (if any of them have read this far and not yet fainted with disgust) that "$a x $b" in Perl is like concat (replicate b a) in the better sorts of languages.
my $ls = $lt ? "1" : "0";
my $ms = ($lt || $rt || $up || $dn) ? "1" : "0";
my $rs = $rt ? "1" : "0";
push @rows, ($ls x $top . $ms x $mid . $rs x $bot) x $mid;
This assembles the middle section, including the "left" and "right"
lines.
push @rows, ($dn ? $v1 : $v0) x $bot;
This does the bottom section.
return @rows;
}
And we are done.
Nothing to it. Adding diagonal lines would be a fairly simple matter.Download the complete source code if you haven't seen enough yet.
There is no part of this program of which I am proud. Rather, I am proud of the thing as a whole. It did the job I needed, and it did it by 5 PM. Larry Wall once said that "a Perl script is correct if it's halfway readable and gets the job done before your boss fires you." Thank you, Larry.
No, that is not quite true. There is one line in this program that I'm proud of. I noticed after I finished that there is exactly one comment in this program, and it is blank. I don't know how that got in there, but I decided to leave it in. Who says program code can't be funny?
[Other articles in category /prog/perl] permanent link
Thu, 06 Mar 2008
Throttling qmail
This may well turn out to be another oops. Sometimes when I screw
around with the mail system, it's a big win, and sometimes it's a big
lose. I don't know yet how this will turn out.
Since I moved house, I have all sorts of internet-related problems that I didn't have before. I used to do business with a small ISP, and I ran my own web server, my own mail service, and so on. When something was wrong, or I needed them to do something, I called or emailed and they did it. Everything was fine.
Since moving, my ISP is Verizon. I have great respect for Verizon as a provider of telephone services. They have been doing it for over a hundred years, and they are good at it. Maybe in a hundred years they will be good at providing computer network services too. Maybe it will take less than a hundred years. But I'm not as young as I once was, and whenever that glorious day comes, I don't suppose I'll be around to see it.
One of the unexpected problems that arose when I switched ISPs was that Verizon helpfully blocks incoming access to port 80. I had moved my blog to outside hosting anyway, because the blog was consuming too much bandwidth, so I moved the other plover.com web services to the same place. There are still some things that don't work, but I'm dealing with them as I have time.
Another problem was that a lot of sites now rejected my SMTP connections. My address was in a different netblock. A Verizon DSL netblock. Remote SMTP servers assume that anybody who is dumb enough to sign up with Verizon is also too dumb to run their own MTA. So any mail coming from a DSL connection in Verizonland must be spam, probably generated by some Trojan software on some infected Windows box.
The solution here (short of getting rid of Verizon) is to relay the mail through Verizon's SMTP relay service. mail.plover.com sends to outgoing.verizon.net, and lets outgoing.verizon.net forward the mail to its final destination. Fine.
But but but.
If my machine sends more than X messages per Y time, outgoing.verizon.net will assume that mail.plover.com has been taken over by a Trojan spam generator, and cut off access. All outgoing mail will be rejected with a permanent failure.
So what happens if someone sends a message to one of the 500-subscriber email lists that I host here? mail.plover.com generates 500 outgoing messages, sends the first hundred or so through Verizon. Then Verizon cuts off my mail service. The mailing list detects 400 bounce messages, and unsubscribes 400 subscribers. If any mail comes in for another mailing list before Verizon lifts my ban, every outgoing message will bounce and every subscriber will be unsubscribed.
One solution is to get a better mail provider. Lorrie has an Earthlink account that comes with outbound mail relay service. But they do the same thing for the same reason. My Dreamhost subscription comes with an outbound mail relay service. But they do the same thing for the same reason. My Pobox.com account comes with an unlimited outbound mail relay service. But they require SASL authentication. If there's a SASL patch for qmail, I haven't been able to find it. I could implement it myself, I suppose, but I don't wanna.
So far there are at least five solutions that are on the "eh, maybe, if I have to" list:
- Get a non-suck ISP
- Find a better mail relay service
- Hack SASL into qmail and send mail through Pobox.com
- Do some skanky thing with serialmail
- Get rid of qmail in favor of postfix, which presumably supports SASL
It also occurred to me in the shower this morning that the old ISP might be willing to sell me mail relaying and nothing else, for a small fee. That might be worth pursuing. It's gotta be easier than turning qmail-remote into a SASL mail client.
The serialmail thing is worth a couple of sentences, because there's an autoresponder on the qmail-users mailing-list that replies with "Use serialmail. This is discussed in the archives." whenever someone says the word "throttle". The serialmail suite, also written by Daniel J. Bernstein, takes a maildir-format directory and posts every message in it to some remote server, one message at a time. Say you want to run qmail on your laptop. Then you arrange to have qmail deliver all its mail into a maildir, and then when your laptop is connected to the network, you run serialmail, and it delivers the mail from the maildir to your mail relay host. serialmail is good for some throttling problems. You can run serialmail under control of a daemon that will cut off its network connection after it has written a certain amount of data, for example. But there seems to be no easy way to do what I want with serialmail, because it always wants to deliver all the messages from the maildir, and I want it to deliver one message.
There have been some people on the qmail-users mailing-list asking for something close to what I want, and sometimes the answer was "qmail was designed to deliver mail as quickly and efficiently as possible, so it won't do what you want." This is a variation of "Our software doesn't do what you want, so I'll tell you that you shouldn't want to do it." That's another rant for another day. Anyway, I shouldn't badmouth qmail-users mailing-list, because the archives did get me what I wanted. It's only a stopgap solution, and it might turn out to be a big mistake, but so far it seems okay, and so at last I am coming to the point of this article.
I hacked qmail to support outbound message rate throttling. Following a suggestion of Richard Lyons from the qmail-users mailing-list, it was much easier to do than I had initially thought.
Here's how it works. Whenever qmail wants to try to deliver a message to a remote address, it runs a program called qmail-remote. qmail-remote is responsible for looking up the MX records for the host, contacting the right server, conducting the SMTP conversation, and returning a status code back to the main component. Rather than hacking directly on qmail-remote, I've replaced it with a wrapper. The real qmail-remote is now in qmail-remote-real. The qmail-remote program is now written in Perl. It maintains a log file recording the times at which the last few messages were sent. When it runs, it reads the log file, and a policy file that says how quickly it is allowed to send messages. If it is okay to send another message, the Perl program appends the current time to the log file and invokes the real qmail-remote. Otherwise, it sleeps for a while and checks again.
The program is not strictly correct. It has some race conditions. Suppose the policy limits qmail to sending 8 messages per minute. Suppose 7 messages have been sent in the last minute. Then six instances of qmail-remote might all run at once, decide that it is OK to send a message, and send one. Then 13 messages have been sent in the last minute, which exceeds the policy limit. So far this has not been much of a problem. It's happened twice in the last few hours that the system sent 9 messages in a minute instead of 8. If it worries me too much, I can tell qmail to run only one qmail-remote at a time, instead of 10. On a normal qmail system, qmail speeds up outbound delivery by running multiple qmail-remote processes concurrently. On my crippled system, speeding up outbound delivery is just what I'm trying to avoid. Running at most one qmail-remote at a time will cure all race conditions. If I were doing the project over, I think I'd take out all the file locking and such, and just run one qmail-remote. But I didn't think of it in time, and for now I think I'll live with the race conditions and see what happens.
So let's see? What else is interesting about this program? I made at least one error, and almost made at least one more.
The almost-error was this: The original design for the program was something like:
- do
- lock the history file, read it, and unlock it
- lock the history file, update it, and unlock it
- send the message
One way to fix this is to have the processes append to the history file, but never remove anything from it. That is clearly not a sustainable strategy. Someone must remove expired entries from the history file.
Another fix is to have the read and the update in the same critical section:
- lock the history file
- do
- read the history file
- update the history file and unlock it
- send the message
Cleaning the history file could be done by a separate process that periodically locks the file and rewrites it. But instead, I have the qmail-remote processes to it on the fly:
- do
- lock the history file, read it, and unlock it
- lock the history file, read it, update it, and unlock it
- send the message
Here's a mistake that I did make. This is the block of code that sleeps until it's time to send the message:
while (@last >= $msgs) {
my $oldest = $last[0];
my $age = time() - $oldest;
my $zzz = $time - $age + int(rand(3));
$zzz = 1 if $zzz < 1;
# Log("Sleeping for $zzz secs");
sleep $zzz;
shift @last while $last[0] < time() - $time;
load_policy();
}
The throttling
policy is expressed by two numbers, $msgs and $time,
and the program tries to send no more than $msgs messages per
$time seconds. The @last array contains a list of
Unix epoch timestamps of the times at which the messages of the last
$time seconds were sent.
So the loop condition checks to see if fewer than $msgs
messages were sent in the last $time seconds. If not, the
program continues immediately, possibly posting its message. (It
rereads the history file first, in case some other messages have been
posted while it was asleep.)
Otherwise the program will sleep for a while. The first three lines in the loop calculate how long to sleep for. It sleeps until the time the oldest message in the history will fall off the queue, possibly plus a second or two. Then the crucial line:
shift @last while $last[0] < time() - $time;
which discards the expired items from the history. Finally, the call
to load_policy() checks to see if the policy has changed, and
the loop repeats if necessary.The bug is in this crucial line. if @last becomes empty, this line turns into an infinite busy-loop. It should have been:
shift @last while @last && $last[0] < time() - $time;
Whoops. I noticed this this morning when my system's load was around
12, and eight or nine qmail-remote processes were collectively eating 100% of
the CPU. I would have noticed sooner, but outbound deliveries hadn't
come to a complete halt yet.Incidentally, there's another potential problem here arising from the concurrency. A process will complete the sleep loop in at most $time+3 seconds. But then it will go back and reread the history file, and it may have to repeat the loop. This could go on indefinitely if the system is busy. I can't think of a good way to fix this without getting rid of the concurrent qmail-remote processes.
Here's the code. I hereby place it in the public domain. It was written between 1 AM and 3 AM last night, so don't expect too much.
[Other articles in category /Unix] permanent link
Tue, 04 Mar 2008
"Boolean" or "boolean"?
In a recent article I wrote:
... a logical negation function ... takes a boolean argument and returns a boolean result.I worried for some time about whether to capitalize "boolean" here. But writing "Boolean" felt strange enough that I didn't actually try it to see how it looked on the page.
I looked at the the Big Dictionary, and all the citations were capitalized. But the most recent one was from 1964, so that was not much help.
Then I tried Google search for "boolean capitalized". The first hit was a helpful article by Eric Lippert. M. Lippert starts by pointing out that "Boolean" means "pertaining to George Boole", and so should be capitalized. That much I knew already.
But then he pointed out a countervailing consideration:
English writers do not usually capitalize the eponyms "shrapnel" (Henry Shrapnel, 1761-1842), "diesel" (Rudolf Diesel, 1858-1913), "saxophone" (Adolphe Sax, 1814-1894), "baud" (Emile Baudot, 1845-1903), "ampere" (Andre Ampere, 1775-1836), "chauvinist" (Nicolas Chauvin, 1790-?), "nicotine" (Jean Nicot, 1530-1600) or "teddy bear" (Theodore Roosevelt, 1858-1916).Isn't that a great paragraph? I just had to quote the whole thing.
Lippert concluded that the tendency is to capitalize an eponym when it is an adjective, but not when it is a noun. (Except when it isn't that way; consider "diesel engine". English is what it is.)
I went back to my example to see if that was why I resisted capitalizing "Boolean":
... takes a boolean argument and returns a boolean result.Hmm, no, that wasn't it. I was using "boolean" as an adjective in both places. Wasn't I?
Something seemed wrong. I tried changing the example:
... takes an integer argument and returns an integer result.Aha! Notice "integer", not "integral". "Integral" would have been acceptable also, but that isn't analogous to the expression I intended. I wasn't using "boolean" as an adjective to modify "argument" and "result". I was using it as a noun to denote a certain kind of data, as part of a noun phrase. So it is a noun, and that's why I didn't want to capitalize it.
I would have been happy to have written "takes a boolean and returns a boolean", and I think that's the controlling criterion.
Sorry, George.
[Other articles in category /lang] permanent link
Mon, 03 Mar 2008
Uniquely-decodable codes revisited
[ This is a followup to an earlier article. ]
Alan Morgan wrote to ask if there was a difference between uniquely-decodable (UD) codes for strings and for streams. That is, is there a code for which every finite string is UD, but for which some infinite sequence of symbols has multiple decodings.
I pondered this a bit, and after a little guessing came up with an example: { "a", "ab", "bb" } is UD, because it is a suffix code. But the stream "abbbbbbbbbb..." can be decoded in two ways.
After I found the example, I realized that I shouldn't have needed to guess, because I already knew that you sometimes have to see the last symbol of a string before you can know how to decode it, and in such a code, if there is no such symbol, the decoding must be ambiguous. The code above is UD, but to decode "abbbbbbbbbbbbbbb" you have to count the "b"s to figure out whether the first code word is "a" or "ab".
Let's say that a code is UD+ if it has the property that no two infinite sequences of code words have the same concatenation. Can we characterize the UD+ codes? Clearly, UD+ implies UD, and the example above shows that the converse is not true. A simple argument shows that all prefix codes are UD+. So the question now is, are there UD+ codes that are not prefix codes? I don't know.
[ Addendum 20080303: Gareth McCaughan points out that { "a", "ab" } is UD+ but not prefix. ]
[Other articles in category /CS] permanent link
Sun, 02 Mar 2008[ Note: You are cautioned that this article is in the oops section of my blog, and so you should understand it as a description of a mistake that I have made. ]
For more than a year now my day job has involved work on a large project written entirely in Java. I warned my employers that I didn't have any professional experience in Java, but they hired me anyway. So I had to learn Java. Really learn it, I mean. I hadn't looked at it closely since version 1.2 or so.
Java 1.5 has parametrized types, which they call "generics". These looked pretty good to me at first, and a big improvement on the cruddy 1975-style type system Java had had before. But then I made a shocking discovery: If General is a subtype of Soldier, then List<General> is not a subtype of List<Soldier>.
In particular, you cannot:
List<General> listOfGenerals = ...
List<Soldier> listOfSoldiers = listOfGenerals;
For a couple of weeks I went around muttering to myself about what
idiots the Java people must be. "Geez fuckin' Louise," I said. "The
Hindley-Milner languages have had this right for twenty years. How
hard would it have been for those Java idiots to pick up a damn book
or something?" I was, of course, completely wrong in all respects. The assignment above leads to problems that are obvious if you think about it a bit, and that should have been obvious to me, and would have been, except that I was so busy exulting in my superiority to the entire Java community that I didn't bother to think about it a bit.
You would like to be able to do this:
Soldier someSoldier = ...;
listOfSoldiers.add(someSoldier);
But if you do, you are setting up a type failure:
General someGeneral = listOfGenerals.getLast();
someGeneral.orderAttack(...);
Here listOfSoldiers and listOfGenerals refer to the
same underlying object, so we put a common soldier into that object
back on line 4, and then took it out again on line 5. But line 5 is
expecting it to be a General, and it is not. So we either have a type
failure right there, or else we have a General variable that holds a
a Soldier
object, and then on line 6 a mere private is
allowed to order an attack, causing a run-time type failure. If we're
lucky.The language designers must forbid one of these operations, and the best choice appears to be to forbid the assignment of the List<General> object to the List<Soldier> variable on line 2. The other choices seem clearly much worse.
The canonical Java generics tutorial has an example just like this one, to explain precisely this feature of Java generics. I would have known this, and I would have saved myself two weeks of grumbling, if I had picked up a damn book or something.
Furthermore, my premise was flawed. The H-M languages (SML, Haskell, Miranda, etc.) have not had this right for twenty years. It is easy to get right in the absence of references. But once you add references the problem becomes notoriously difficult, and SML, for example, has gone through several different strategies for dealing with it, as the years passed and more was gradually learned about the problem.
The naive approach for SML is simple. It says that if α is any type, then there is a type ref α, which is the type of a reference that refers to a storage cell that contains a value of type α. So for example ref int is the type of a reference to an int value. There are three functions for manipulating reference types:
ref : α → ref α
! : ref α → α
:= : (ref α * α) → unit
The ref function takes a value and produces a reference to
it, like & in C; if the original value had type α then
the result has type ref α. The ! function takes a reference
of type ref α and dereferences it, returning the value of type α that
it refers to, like * in C. And the := function,
usually written infix, takes a reference and a value, stores the value
into the place that the reference points to, replacing what was there
before, and returns nothing. So for example:
val a = "Kitty cat"; (* a : string *)
val r = ref a; (* r : ref string *)
r := "Puppy dog";
print !r;
This prints Puppy dog. But this next example fails, as you
would hope and expect:
val a = "Kitty cat";
val r = ref a;
r := 37; (* fails *)
because r has type ref string, but 37
has type int, and := requires that the type of
the value on the right match the type referred to by the reference on
the left. That is the obvious, naive approach. What goes wrong, though? The canonical example is:
fun id x = x (* id : α → α *)
val a = ref id; (* a : ref (α → α) *)
fun not true = false
| not false = true ; (* not: bool → bool *)
a := not;
(!a) 13
The key here is that a is a variable of type ref (α → α), that is,
a reference to a cell that can hold a function whose argument is any
type α and whose return value is the same type. Here it holds a
reference to id, which is the identity function.Then we define a logical negation function, not, which has type bool → bool, that is, it takes a boolean argument and returns a boolean result. Since this is a subtype of α → α, we can store this function in the cell referenced by a.
Then we dereference a, recovering the value it points to, which, since the assignment, is the not function. But since a has type ref (α → α), !a has type α → α, and so should be applicable to any value. So the application of !a to the int value 13 passes the type checker, and SML blithely applies the not function to 13.
I've already talked about SML way longer than I planned to, and I won't belabor you further with explanations of the various schemes that were hatched over the years to try to sort this out. Suffice it to say that the problem is still an open research area.
Java, of course, is all references from top to bottom, so this issue obtrudes. The Java people do not know the answer either.
The big error that I made here was to jump to the conclusion that the Java world must be populated with idiots who know nothing about type theory or Haskell or anything else that would have tipped them off to the error I thought they had committed. Probably most of them know nothing about that stuff, but there are a lot of them, and presumably some of them have a clue, and perhaps some of them even know a thing or two that I don't. I said a while back that people who want to become smarter should get in the habit of assuming that everything is more complex than they imagine. Here I assumed the opposite.
As P.J. Plauger once said in a similar circumstance, there is a name for people who are so stupid that they think everyone else is stupid instead.
Maybe I won't be that person next time.
[ Addendum 20201021: [Here's the original post by Plauger](https://groups.google.com/g/comp.std.c/c/aPENvL9wZFw/m/II24s61rOcoJ), in case I want to find it again, or someone else is interested. ]
[Other articles in category /oops] permanent link
Sat, 01 Mar 2008
More rational roots of polynomials
I have a big file of ideas for blog articles, and when I feel like
writing but I can't think of a topic, I look over the file. An item
from last April was relevant to yesterday's article about finding
rational roots of polynomials. It's a trick I saw in the first
edition (1768!) of the Encyclopædia Britannica.
Suppose you have a polynomial P(x) = xn + ...+ p = 0. If it has a rational root r, this must be an integer that divides p = P(0). So far so good.
But consider P(x-1). This is a different polynomial, and if r is a root of P(x), then r+1 is a root of P(x-1). So, just as r must divide P(0), r+1 must divide P(-1). And similarly, r-1 must divide P+1.
So we have an extension of the rational root theorem: instead of guessing that some factor r of P(0) is a root, and checking it to see, we first check to see if r+1 is a factor of P(-1), and if r-1 is a factor of P(1), and proceed with the full check only if these two auxiliary tests pass.
My notes conclude with:
Is this really less work than just trying all the divisors of P(0) directly?Let's find out.
As in the previous article, say P(x) = 3x2 + 6x - 45. The method only works for monic polynomials, so divide everything by 3. (It can be extended to work for non-monic polynomials, but the result is just that you have to divide everything by 3, so it comes to the same thing.) So we consider x2 + 2x - 15 instead. Say r is a rational root of P(x). Then:
| r-1 | divides | P(1) | = -12 |
| r | divides | P(0) | = -15 |
| r+1 | divides | P(-1) | = -16 |
So we need to find three consecutive integers that respectively divide 12, 15, and 16. The Britannica has no specific technique for this; it suggests doing it by eyeball. In this case, 2–3–4 jumps out pretty quickly, giving the root 3, and so does 6–5–4, which is the root -5. But the method also yields a false root: 4–3–2 suggests that -3 might be a root, and it is not.
Let's see how this goes for a harder example. I wrote a little Haskell program that generated the random polynomial x4 - 26x3 + 240 x2 - 918x + 1215.
| r-1 | divides | P(1) | = 512 | = 29 |
| r | divides | P(0) | = 1215 | = 35·5 |
| r+1 | divides | P(-1) | = 2400 | = 25·3·52 |
That required a fair amount of mental arithmetic, and I screwed up and got 502 instead of 512, which I only noticed because 502 is not composite enough; but had I been doing a non-contrived example, I would not have noticed the error. (Then again, I would have done the addition on paper instead of in my head.) Clearly this example was not hard enough because 2–3–4 and 4–5–6 are obviously solutions, and it will not always be this easy. I increased the range on my random number generator and tried again.
The next time, it came up with the very delightful polynomial x4 - 2735x3 + 2712101 x2 - 1144435245x + 170960860950, and I decided not going to go any farther with it. The table values are easy to calculate, but they will be on the order of 170960860950, and I did not really care to try to factor that.
I decided to try one more example, of intermediate difficulty. The program first gave me x4 - 25x3 + 107 x2 - 143x + 60, which is a lucky fluke, since it has a root at 1. The next example it produced had a root at 3. At that point I changed the program to generate polynomials that had integer roots between 10 and 20, and got x4 - 61x3 + 1364 x2 - 13220x + 46800.
| r-1 | divides | P(1) | = 34864 | = 22·33·17·19 |
| r | divides | P(0) | = 46800 | = 24·32·52·13 |
| r+1 | divides | P(-1) | = 61446 | = 2·3·72·11·19 |
This is just past my mental arithmetic ability; I got 34884 instead of 34864 in the first row, and balked at factoring 61446 in my head. But going ahead (having used the computer to finish the arithmetic), the 17 and 19 in the first and last rows are suggestive, and there is indeed a 17–18–19 to be found. Following up on the 19 in the first row suggests that we look for 19–20–21, which there is, and following up on the 11 in the last row, hoping for a 9–10–11, finds one of those too. All of these are roots, and I do have to admit that I don't know any better way of discovering that. So perhaps the method does have some value in some cases. But I had to work hard to find examples for which it made sense. I think it may be more reasonable with 18th-century technology than it is with 21st-century technology.
[Other articles in category /math] permanent link