Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFM |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
| A programmer had a problem... |
| Contravariant types |
| Flipping coins |
| Flipping coins, corrected |
| On design |
| Oyster jokes |
| Phrasal verbs |
| Someone else's mistake |
Subtopics:
| Mathematics | 246 |
| Programming | 100 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Fri, 21 Jul 2006
Oyster jokes
Last week I heard a pathetically bad joke about oysters. Here it
is:
What did the girl oyster say to the boy oyster?Well, the world is full of dumb jokes, so why am I wasting your time with this one? Because I think it should be possible, perhaps even easy, to do much better. Sex jokes, even old, tired sex jokes, are a lot funnier than relationship jokes, particularly relationship jokes as old and as tired as this one. The implied sexism only makes it that much more tiresome. And really, whatever humor there is is barely more than a pun."You never open up to me."
But it seems to me that there is a lot of unexploited material to be gotten from oysters.
For example, oysters, considered as food, are famous for their aphrodisiac properties. It ought to be possible to do something with that. What do the boy and the girl oyster use as aphrodisiacs? Does it involve oyster cannibalism? So much the better. Can the aphrodisiac cannibalism be tied to oral sex somehow? Better still. How could a joke about oyster cunnilingus fail to be hilarious?
Moreover, oysters are hermaphrodites. Surely there is some farcical oyster humor available from the fact that the boy and the girl oysters might in fact be the same individual. Now we have oyster autofellatial autocannibalism. It's both dirty and disgusting!
I was not able to come up with any oyster jokes, however, and a quick web search turned up nothing of value. Really nothing. Don't waste your time. I found one joke that was introduced with "Jennifer sent in this great oyster joke..." and then the joke wasn't even about oysters; it was about the ingestion of testicles. And I had heard it before.
I think there's a small gap in the world just the size and shape of a good oyster-themed joke. Don't you? Here is your big chance to make up a joke that nobody has ever heard before. Please send me your oyster jokes.
[Other articles in category /humor] permanent link
Thu, 20 Jul 2006
Flipping coins, corrected
In a recent article about coin
flipping, I said:
After a million tosses of a fair coin, you can expect that the numbers of heads and tails will differ by about 1,000.In fact, the expected difference is actually !!\sqrt{2n/\pi}!!. For n=1,000,000, this gives an expected difference of about 798, not 1,000 as I said....
In general, if you flip the coin n times, the expected difference between the numbers of heads and tails will be about √n.
I correctly remembered that the expected difference is on the order of √n, but forgot that the proportionality constant was not 1.
The main point of my article, however, is still correct. I said that the following assertion is not quite right (although not quite wrong either):
Over a million tosses you'll have almost the same amount of heads as tails
I pointed out that although the relative difference tends to get small, the absolute difference tends to infinity. This is still true.
Thanks to James Wetterau for pointing out my error.
[Other articles in category /math] permanent link
Wed, 19 Jul 2006
Flipping coins
A gentleman on IRC recently said:
Over a million tosses you'll have almost the same amount of heads as tails
Well, yes, and no. It depends on how you look at it.
After a million tosses of a fair coin, you can expect that the numbers of heads and tails will differ by about 1,000. This is a pretty big number.
On the other hand, after a million tosses of a fair coin, you can expect that the numbers of heads and tails will differ by about 0.1%. This is a pretty small number.
In general, if you flip the coin n times, the expected difference between the numbers of heads and tails will be about √n. As n gets larger, so does √n. So the more times you flip the coin, the larger the expected difference in the two totals.
But the relative difference is the quotient of the difference and the total number of flips; that is, √n/n = 1/√n. As n gets larger, 1/√n goes to zero. So the more times you flip the coin, the smaller the expected difference in the two totals.
It's not quite right to say that you will have "almost the same amount of heads as tails". But it's not quite wrong either. As you flip the coin more and more, you can expect the totals to get farther and farther apart—but the difference between them will be less and less significant, compared with the totals themselves.
[ Addendum 20060720: Although the main point of this article is correct, I made some specific technical errors. A correction is available. ]
[Other articles in category /math] permanent link
Thu, 13 Jul 2006
Someone else's mistake
I don't always screw up, and here's a story about mistake I
could have made, but didn't.
Long ago, I was fresh out of college, looking for work. I got a lead on what sounded like a really excellent programming job, working for a team at University of Maryland that was preparing a scientific experiment that would be sent up into space in the Space Shuttle. That's the kind of work you dream about at twenty-one.
I went down for an interview, and met the folks working on the project. All except for the principal investigator, who was out of town.
The folks there were very friendly and helpful, and answered all my questions, except for two. I asked each person I met what the experiment was about, and what my programs would need to do. And none of them could tell me. They kept saying what a shame it was that the principal investigator was out of town, since he would have been able to explain it all to my satisfaction. After I got that answer a few times, I started to get nervous.
I'm sure it wasn't quite that simple at the time. I imagine, for example, that there was someone there who didn't really understand what was going on, but was willing to explain it to me anyway. I think they probably showed me some other stuff they were working on, impressed me with a tour of the lab, and so on. But at the end of the day, I knew that I still didn't know what they were doing or what they wanted me to do for them.
If that happened to me today, I would probably just say to them at 5PM that their project was doomed and that I wouldn't touch it with a ten-foot pole. At the time, I didn't have enough experience to be sure. Maybe what they were saying was true, maybe it really wasn't a problem that nobody seemed to have a clue as to what was going on? Maybe it was just me that was clueless? I had never seen anything like the situation there, and I wasn't sure what to think.
I didn't have the nerve to turn the job down. At twenty-one, just having gotten out of school, with no other prospects at the time, I didn't have enough confidence to be quite sure to throw away this opportunity. But I felt in my guts that something was wrong, and I never got back to them about the job.
A few years afterward I ran into one of those guys again, and asked him what had become of the project. And sure enough, it had been a failure. They had missed the deadline for the shuttle launch, and the shuttle had gone up with a box of lead in it where their experiment was supposed to have been.
Looking back on it with a lot more experience, I know that my instincts were right on, even though I wasn't sure at the time. Even at twenty-one, I could recognize the smell of disaster.
[Other articles in category /oops] permanent link
Sun, 09 Jul 2006
Phrasal verbs
My mom teaches English to visiting foreign students, and last time I
met her she was talling me about phrasal verbs. A phrasal verb is a
verb that incorporates a preposition. Examples include "speed up",
"try out", "come across", "go off", "turn down". The prepositional
part is uninflected, so "turns down", "turned down", "turning down",
not *"turn downs", *"turn downed", *"turn downing". My mom says she
uses a book that has a list of all of them; there are several hundred.
She was complaining specifically about "go off", which has an
unusually peculiar meaning: when the alarm clock goes off in the
morning, it actually goes on.
This reminded me that "slow up" and "slow down" are synonymous. And there is "speed up", but no "speed down". And you cannot understand "stand down" by analogy with "stand up", "sit up", and "sit down". And you also cannot understand "nose job" by analogy with "hand job". But I digress.
One of the things about the phrasal verbs that gives the foreign students so much trouble is that the verbs don't all obey the same rules. For example, some are separable and some not. Consider "turned down". I can turn down the thermostat, but I can also turn the thermostat down. And I can try out my new game, and I can also try my new game out. And I can stand up my blind date, and I can stand my blind date up. But while I can come across a fountain in the park, I can't *come a fountain across in the park. And while I can go off to Chicago, I can't *go to Chicago off. There's no way to know which of these work and which not, except just by memorizing which are allowed and which not.
And sometimes the separable ones can't be unseparated. I can give back the map, and I can give the map back, and I can give it back, but I can't *give back it. I can hold up the line, and I can hold the line up, and I can hold us up, but I can't *hold up us. I don't know what the rule is exactly, and I don't want to go to the library again to get the Cambridge Grammar, because last time I did that I dropped it on my toe.
I hadn't realized any of this until I read this article about them, but when I did, I had a sudden flash of insight. I had not realized before what was going on when someone set up us the bomb. "Set up" is separable: I can set up the bomb, or set the bomb up, or someone can set us up. But "us", as noted above, is not deseperable, so you cannot have *set up us. But I think I understand the mistake better now than I did before; it seems less like a complete freak and more like a member of a common type of error.
[Other articles in category /lang] permanent link
Sat, 08 Jul 2006
A programmer had a problem...
A while back, I wrote an
article in which I mentioned a programmer who had a problem, tried
to solve it with weak references, and, as a result, had two problems.
I said that weak references work unusually well in that little
formula.
Yesterday I was about to make the same mistake. I had a problem, and weak references seemed like the solution. Fortunately, it was time to go home, which is a two-mile walk. Taking a two-mile walk is a great way to fix mistakes, especially the ones you haven't made yet. On this particular walk, I came to my senses and avoided the weak references.
The problem concerns the following classes and methods. You have a database object $db. You can call @rec = $db->lookup, which may return some record objects that represent records. You then call methods on the records, say $rec[3]->get_color, to extract data from them, or $rec[3]->set_color("purple"), to modify the data in the records. The updating is done in-memory only, and a later call to $db->flush writes all the updates back to the database.
The database object needs to store the changes that have been made but not yet written out. The easy way to do this is to have it store a change log of the modified record objects. So set_color first makes its change to the target record object, and then calls an internal _update method on the original database object to attach the record to the change log. Later on, flush will process this array, writing out the indicated changes.
In order for set_color to know which database to direct the _update call to, each record object must have a pointer back to the database that created it. This is convenient for other purposes too. Fine. But then if the record object is stored in the change log inside the database object, we now have a reference loop: the database contains a change log with a pointer to the record, which contains a pointer back to the database itself. This means that neither the database nor the record will ever be garbage collected. (This problem is common in complex Perl programs, and would simply vanish if Perl had even a slightly less awful garbage collector. Improvement is unlikely to occur before the release of Perl 6, now scheduled for October 28, 2073.)
My first reaction when faced with a problem like this one is to gurgle contentedly in my sleep, turn over, and pull the blankets over my head. This strategy is the primary contributor to my success as a programmer; it is somewhat superior to the typical programmer's response, which is to swing into action, overthink the problem, and come up with an elaborate solution. Aron Nimzovitch once said that the problem chess novices have is the irrepressible urge to always be doing something. Programmers are similar. They are all very bright people, very good at solving problems, and they solve problems all the time, even the ones that don't need to be solved.
I seem to be digressing. How unusual. In any case, this problem really did have to be solved. One wants the database object to flush out its pending changes at the time it becomes inacessible. If the object is never garbage collected, then the programmer must always remember to flush out the changes manually. Miss one call to flush, and your updates are lost. This is unacceptable. The primary purpose of a database is to record the updates. So I had to take my head out from under the covers, like it or not.
I thought about several solutions, and even tried one out, but it was too complicated and got me into a horrible tar pit, so I threw it away and started over. (That is another superior strategy that programmers don't exercise as often as they should. As Erik Naggum says, they will drive a hundred miles through a forest, stopping every five feet to cut down another tree, instead of pausing to wonder if maybe they shouldn't have driven off the road in the first place.)
Then I got the bright idea to use weak references, which seemed like just the thing. That's what weak references are for: breaking dependency loops so that things that need to be garbage collected can be. Fortunately, it was time to go, so I walked home instead of diving into the chyme-filled swimming pool of weak references.
With the weak references, you need to decide which reference to weaken. There is a reference to the record object, in the change log inside the database object. And there is a reference to the database object, in the record object. Which do you weaken?
If you weaken the reference to the record, you get a disaster:
{
my ($rec) = $db->lookup(...);
$rec->set_color("purple");
}
$db->flush;
When the block is exited, the last strong reference to the record goes
away, and the modified record evaporates, leaving nothing inside the
database object. The flush method can see by the lingering
ghost that there was something there it was supposed to deal with, but
it no longer knows what. So that choice is doomed.What if you weaken the reference inside the record, the one that points back to the database? That is hardly any better:
my $rec;
{
my $db = FlatFile->new(...);
($rec) = $db->lookup(...);
}
$rec->set_color("purple");
We would like the database object to hang around as long as there are
still some extant records from it. But because we weakened the
references from the records to the database, it doesn't; it evaporates
at the end of the block, leaving the record orphaned. The
set_color method then fails, because the database to which it
is supposed to write changes has evaporated.Conclusion: I've heard it before, and it wasn't funny the first time.
On the walk home, I realized something else: actually storing the database data inside the record objects is a bad move. The general advice under which this is a bad move is something like Don't store the same data in two places. The specific problems in this instance are exemplified by this:
my ($a) = $db->lookup(unique_id => "142857");
my ($b) = $db->lookup(unique_id => "142857");
$a->set_color("red");
$b->set_color("purple");
$a->color eq "purple"; # True or false?
Since $a and $b represent the same record, the
answer should be true. But in the implementation I had (and still
have, actually; I haven't fixed this yet) it is false. The
set_color method on $b updates the data that is
cached in object $b, but has no idea that it should also
update the data cached in $a.To work properly, $a and $b should be identical objects. One way to do this is to store an object in memory for every record in the database, and hand out these preconstructed objects as needed; then both calls to lookup return the same object. This is time- and memory-intensive. Another way to do this is to cache the record objects as they are constructed, and arrange for lookup to return the cached objects when appropriate. This is more complicated.
A simpler solution is not to store the data in memory at all. Record objects are always created as needed, but contain nothing but a database handle and some sort of locator information that says how to get the record data, should it be asked for. ("Any problem can be solved by another layer of indirection," they say, although it's not really true. Still, there are several classes of problems that can be solved by adding another layer of indirection, and this particular object identity problem could serve well as an exemplar of one of those classes.) Then modifications don't go into the record objects themselves. Instead, they go into the database object as an instruction to modify a certain record in a certain way.
This solution, however, presupposes that there is a good way to build locator information for a flat file and update it as needed. Fortunately, there is. I did a really good job of solving this problem a few years ago when I wrote the Tie::File module. It represents a text file as a Perl array, so a record locator can simply be an index into the array, and a record object then becomes something like:
{
db => $db,
recno => 37,
}
The change log inside the database object looks something like:
{ 0 => no change,
1 => no change,
2 => "color" field was set to "purple",
3 => no change,
4 => "size" field was set to "unusually large",
...
}
This happily gets rid of the garbage collection problem I had been
trying to solve in the first place.Using Tie::File also eliminates a lot of I/O issues that I had solved before, and gets all the I/O code out of the database module. I had already been thinking about getting rid of the explicit I/O and having the database module depend on Tie::File, and when I recognized the lurking record object identity problem, I was convinced that it had to happen sooner rather than later. Having done it, I'm really pleased with the outcome.
[Other articles in category /prog] permanent link
Fri, 07 Jul 2006
On design
I'm writing this Perl module called FlatFile, which is
supposed to provide lightweight simple access to flat-file databases,
such as the Unix password file. An interesting design issue came up,
and since I think that understanding is usually best served by
minuscule examination
of specific examples, that's what I'm going to do.
The basic usage of the module is as follows: You create a database object that represents the entire database:
my $db = FlatFile->new(FILE => "/etc/passwd",
FIELDS => ['username', 'password', 'uid', 'gid',
'gecos', 'homedir', 'shell'],
FIELDSEP => ':',
) or die ...;
Then you can do queries on the database:
my @roots = $db->lookup(uid => 0);
This returns a list of Record objects. (Actually it returns
a list of FlatFile::Record::A objects, where
FlatFile::Record::A is a dynamically-generated class that was
manufactured at the time you did the new call, and which
inherits from FlatFile::Record, but we can ignore that here.)
Once we have the Record objects, we can query them or modify
them:
for my $root (@roots) {
if ($root->username eq 'root') {
$root->set_shell('/bin/false');
} else {
$root->delete;
}
}
This loops over the records that were selected in the earlier call and
examines the username field in each one. if the username is
root, the program sets the shell in the record to
/bin/false; otherwise it deletes the record entirely.Since lookup returns all the matching records, there is the question of what this should do:
my $root = $db->lookup(uid => 0);
Here we have provided enough room for at most one root user. What if
there is more than one?Every Perl function needs to make a decision about this issue. The function could be called in list context or in scalar context, and you need to choose the two behaviors sensibly. Here are some possibilities for what lookup might do if called in scalar context:
- die unconditionally
- return the number of matching records, analogous to the builtin
grep function or the @array syntax
- return the single matching record, if there is only one, and die
if there is more than one.
- return the first matching record, and discard the others
- return a reference to an array of all matching records
- return an iterator object which can be used to access all the
matching records
How to decide on the best behavior? This is the kind of problem that I really enjoy. What will people expect? What will they want? What do they need?
Two important criteria are:
- Difficulty: Whatever I provide should be something that's not easy to get any
other way.
- Usefulness: Whatever I provide should be something that people will use a lot.
my $ref = [ $db->lookup(...) ];
Or they can subclass the Record module and add a new one-line
method that does the same:
sub lookup_ref {
my $self = shift;
[ $self->lookup(@_) ];
}
Similarly, behavior #2 (return a count) is so easy to get that
supporting it directly would probably not be a good use of my code or
my precious interface space:
my $N_recs = () = $db->lookup(...);
I had originally planned to do #3 (require that the query produce a
single record, on pain of death), and here's why: in my first forays
into programming with this module, I frequently found myself writing
things like my $rec = $db->lookup(...) without meaning to,
and in spite of the fact that I had documented the behavior in scalar
context as being undefined. I kept doing it unintentionally in cases
where I expected only one record to be returned. So each time I wrote
this code, I was putting in an implicit assumption that there would be
only one match. I would have been quite surprised in each case if
there had actually been multiple matches. That's the sort of
assumption that you might like to have automatically checked.I ran the question by the folks on IRC, and reaction against this design was generally negative. Folks said that it's not the module's job to try to discern the programmer's intention and enforce this inference by committing suicide.
I can certainly get behind that point of view. I once wrote an article complaining bitterly about modules that call die. I said it was like when you're having tea and crumpets on your 112-piece Spode china set, and you accidentally chip the teacup, and the butler comes running in, crying "Don't worry, Master! I'll take care of that for you!" and then he whips out a hammer and smashes all 112 pieces of china to tiny bits.
I don't think the point applies here, though. I had mentioned it in connection with the Text::ParseWords module, which would throw an exception if the input string was unparseable, hardly an uncommon occurrence, and one that was entirely unavoidable: if I knew that the string would be unparseable, I wouldn't be calling Text::ParseWords to parse it.
Folks on IRC said that when the method might call die, you have to wrap every call to it in an exception handler, which I certainly agree is a pain in the ass. But in this example, you do not have to do that. Here, to prevent the function from dying is very easy: just call it in list context; then it will never die. If what you want is behavior #4, to have it discard all the records but the first one, that is easy to get, regardless of the design I adopt for scalar context behavior:
my ($rec) = $db->lookup(...);
This argues against #4 (return the first matching record) in the same
way that we argued against #2 and #5 already: it's so very easy to do
already, maybe we don't need an even easier way to do it. But if so,
couldn't the programmer just:
sub lookup_first {
my $self = shift;
my ($rec) = $self->lookup(@_);
return $rec;
}
A counterargument in favor of #4 might be based on the usefulness
criterion: perhaps this behavior is so commonly wanted that we
really do need an even easier way to do it.I was almost persuaded by the strong opinion in favor of #4, but then Roderick Schertler spoke up in favor of #3, for basically the reasons I set forth. I consider M. Schertler to have higher-than-normal reliability on matters of this type, so his opinion counterbalances several of the counteropinions on the other side. #3 is not too difficult to get, but still scores higher than most of the others on the difficulty scale. There doesn't seem to be a trivial inline expression of it, as there was with #2, #4, and #5. You would have to actually write a method, or else do something nasty like:
(my ($rec) = $db->lookup(...)) < 2 or die ...;
What about the other proposed behaviors? #1 (unconditional fatality)
is simple, but both criteria seem to argue against it. It does,
however, have the benefit of being a good temporary solution since it
is easy to change without breaking backward compatibility. Were I to
adopt it, it would be very unlikely (although not impossible) that
anyone would write a program that would depend on that behavior; I
would then be able to change it later on. #6 (return an iterator object) is very tempting, because it is the only one that scores high on the difficulty criterion scale: it is difficult or impossible to do this any other way, so by providing it, I am providing a real service to users of the module, rather than yet another way to do the same thing. The module's user cannot implement a good iterator interface as a wrapper around lookup, because lookup always searches the entire database before it returns, and allocates enough memory to store every returned record, whereas a good iterator interface will search only as far as is necessary to find the next matching record, and will store only one record at a time.
This performance argument would be more important if we expected the databases to be very large. But since this is a module for manipulating plain text files, we can expect that they will not be too big, and perhaps the time and memory costs of searching them will be relatively small, so perhaps this design will score fairly low on the usefulness scale.
I still haven't made up my mind, although writing this article has pushed me strongly toward #6. I would be glad to receive email on the matter.
[Other articles in category /prog] permanent link
Thu, 06 Jul 2006
Contravariant types
I just had a slightly frustrating discussion with some colleagues,
involving a small matter of object-oriented design. I don't want to
get into the details of the problem here, except to say that it
involved a class A and its derived class B; I was
asking for advice about the design of a "demote" method that would
take a B object and turn it into an A object.
The frustrating part was that about half of the people in the conversation were confused by my use of the word "demotion" and about whether A was inheriting from B or vice versa. I had intended for B to inherit from A. The demotion, as I said, takes a B object and gives you back an equivalent but stripped-down A object.
To me, this makes perfect sense, logically and terminologically. Demotion implies movement downward. Downward is toward the base class; that's why it's the "base" class. A is the base class here, so the demotion operation takes a B and gives you back an A.
Or, to make the issue clearer with an example, suppose that the two classes are Soldier and General. Which inherits from the other? Obviously, General inherits from Soldier, and not vice-versa. Soldiers support methods for marching, sleeping, and eating. Generals inherit all these methods, and support additional methods for ordering attacks and for convening courts martial. What does a demotion method do? It turns a General into a Soldier. It turns an object of the derived class into an object of the base class.
So how could people get this mixed up? I'm not sure, but I think one possibility is that they were thinking of subclasses and superclasses. The demotion method takes an object in the subclass and returns an object in the superclass. The terminology here is backwards. There are lots and lots of people, me included, who never use the terms "subclass" and "superclass", for precisely this reason. Even if my colleagues weren't thinking of these terms, they were probably thinking of the conventional class inheritance diagram, in which the base class, contrary to its name, is at the top of the diagram, with the derived classes hanging under it. The demotion operation, in this picture, pushes an object upwards, toward the base class.
The problem with "subclass" and "superclass" runs deeper. Mathematical terminology for sets is well-established and intuitive: A is a "subset" of B if set A is entirely contained in set B, if every element of A is an element of B. For example, the set of generals is a subset of the set of soldiers. The converse relation is that B is a superset of A: the set of soldiers is a superset of the set of generals. We expect from the names that a subset will be a smaller set than its superset, and so it is. There are fewer generals than soldiers.
Now let's consider programming language types. A type can be considered to be just a set of values. For example, the int type is the set of all integer values. The real type is the set of all real number values. Since every integer is also a real number, we might say that the int type is a subset of the real type. In fact, the word we usually use is that int is a subtype of real. But "subtype" means no more and no less than "subset".
Now let's consider the types General and Soldier of all objects of classes General and Soldier respectively. Clearly, General is a subtype of Soldier, since every General is a Soldier. This matches the OOP terminology also: General is a subclass of Soldier.
The confusing thing for data types, I think, is that there are two ways in which a type can be a "subtype" of another. A could be a smaller set than B, in which case we use the words "subtype" and "subclass", in accordance with mathematical convention. But A could also support a smaller set of operations than B; in OOP-world we would say that A is a base class and B a derived class. But then B is a subclass of A, which runs counter to the terminological implication that A is at the "base".
(It's tempting to add a long digression here about how computer scientists always draw their trees with the root at the top and the leaves at the bottom, and then talk about how many nodes are under the root of the tree. I will try to restrain myself.)
Anyway, this contravariance is what I really wanted to get at. If we adopt the rule of thumb that most values support few operations, and a few values support some additional operations, then the containment relation for functionality is contravariant to the containment relation for sets. Large sets, like Soldier, support few operations, such as eat and march; smaller sets support more operations, such as convene_court_martial.
The thing that struck me about this is that functions themselves are contravariant. Suppose A and B are types. Now consider the type A×B of pairs of values where the first component is an A and the second is a B. This pairing operation is covariant in A and B. By this I mean that if A' is a subtype of A, then A'×B is a subtype of A×B. Similarly, if B' is a subtype of B, then A×B' is a subtype of A×B.
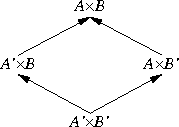
| 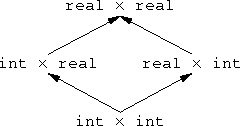 |
Similarly, +, the type sum operation, is also covariant in both of its arguments.
But function types are different. Suppose A → B is the type of functions whose arguments have type A and whose return values are type B. Then A → B' is a subtype of A → B. Here's a simple example: Let A and B be real, and let A' and B' be int. Then every int → int—that is, every function from integers to integers—is also an example of a int → real; it can be considered as a function that takes an int and returns a real. That's because it is actually returning an int, and an int is a kind of real.
But A' → B is not a subtype of A → B. Just the opposite: A → B is a subtype of A' → B.
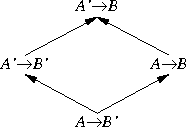
| 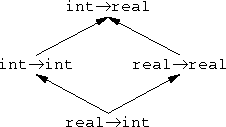 |
I remember standing on a train platform around 1992 and realizing this for the first time, that containment of function types was covariant in the second component but contravariant in the first component. I was quite surprised.
I suspect that the use of "covariant" and "contravariant" here suggests some connection with category theory, and with the notions of covariant and contravariant functors, but I don't know what the connection is.
[Other articles in category /CS] permanent link