Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFM |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
Subtopics:
| Mathematics | 246 |
| Programming | 100 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Tue, 21 Feb 2017
Moore's law beats a better algorithm
Yesterday I wrote about the project I did in the early 1990s to find the best anagrams. The idea is to give pair of anagram words a score, which is the number of chunks into which you have to divide one word in order to rearrange the chunks to form the other word. This was motivated by the observation that while “cholecysto-duodeno-stomy” and “duodeno-cholecysto-stomy” are very long words that are anagrams of one another, they are not interesting because they require so few chunks that the anagram is obvious. A shorter but much more interesting example is “aspired / diapers”, where the letters get all mixed up.
I wrote:
One could do this with a clever algorithm, if one were available. There is a clever algorithm, based on finding maximum independent sets in a certain graph. I did not find this algorithm at the time; nor did I try. Instead, I used a brute-force search.
I wrote about the brute-force search yesterday. Today I am going to discuss the clever algorithm. (The paper is Avraham Goldstein, Petr Kolman, Jie Zheng “Minimum Common String Partition Problem: Hardness and Approximations”, The Electronic Journal of Combinatorics, 12 (2005).)
The plan is to convert a pair of anagrams into a graph that expresses
the constraints on how the letters can move around when one turns into
the other. Shown below is the graph for comparing
acrididae (grasshoppers)
with cidaridae (sea
urchins):
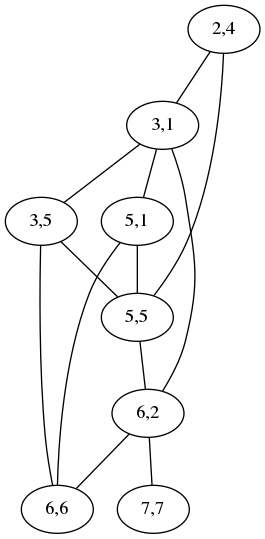
The “2,4” node at the top means that the letters ri at position
2 in acrididae match the letters ri at position 4 in cidaridae;
the “3,1” node is for the match between the first id and the first
id. The two nodes are connected by an edge to show that the two
matchings are incompatible: if you map the ri to the ri, you
cannot also map the first id to the first id; instead you have to
map the first id to the second one, represented by the node “3,5”,
which is not connected to “2,4”. A maximum independent set in this
graph is a maximum selection of compatible matchings in the words,
which corresponds to a division into the minimum number of chunks.
Usually the graph is much less complicated than this. For simple cases it is empty and the maximum independent set is trivial. This one has two maximum independent sets, one (3,1; 5,5; 6,6; 7,7) corresponding to the obvious minimum splitting:

and the other (2,4; 3,5; 5,1; 6,2) to this other equally-good splitting:
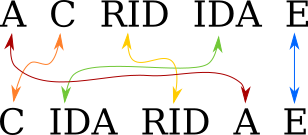
[ Addendum 20170511: It actually has three maximum independent sets. ]
In an earlier draft of yesterday's post, I wrote:
I should probably do this over again, because my listing seems to be incomplete. For example, it omits “spectrum / crumpets” which would have scored 5, because the Webster's Second list contains crumpet but not crumpets.
I was going to leave it at that, but then I did do it over again, and this time around I implemented the “good” algorithm. It was not that hard. The code is on GitHub if you would like to see it.
To solve the maximum independent set instances, I used a guided brute-force search. Maximum independent set is NP-complete, and so the best known algorithm for it runs in exponential time. But the instances in which we are interested here are small enough that this doesn't matter. The example graph above has 8 nodes, so one needs to check at most 256 possible sets to see which is the maximum independent set.
I collated together all the dictionaries I had handy. (I didn't know yet about SCOWL.) These totaled 275,954 words, which is somewhat more than Webster's Second by itself. One of the new dictionaries did contain crumpets so the result does include “spectrum / crumpets”.
The old scored anagram list that I made in the 1990s contained 23,521 pairs. The new one contains 38,333. Unfortunately most of the new stuff is of poor quality, as one would expect. Most of the new words that were missing from my dictionary the first time around are obscure. Perhaps some people would enjoy discovering that that “basiparachromatin” and “Marsipobranchiata” are anagrams, but I find it of very limited appeal.
But the new stuff is not all junk. It includes:
10 antiparticles paternalistic
10 nectarines transience
10 obscurantist subtractions11 colonialists oscillations
11 derailments streamlined
which I think are pretty good.
I wasn't sure how long the old program had taken to run back in the early nineties, but I was sure it had been at least a couple of hours. The new program processes the 275,954 inputs in about 3.5 seconds. I wished I knew how much of this was due to Moore's law and how much to the improved algorithm, but as I said, the old code was long lost.
But then just as I was finishing up the article, I found the old brute-force code that I thought I had lost! I ran it on the same input, and instead of 3.5 seconds it took just over 4 seconds. So almost all of the gain since the 1990s was from Moore's law, and hardly any was from the “improved” algorithm.
I had written in the earlier article:
In 2016 [ the brute force algorithm ] would probably still [ run ] quicker than implementing the maximum independent set algorithm.
which turned out to be completely true, since implementing the maximum independent set algorithm took me a couple of hours. (Although most of that was building out a graph library because I didn't want to look for one on CPAN.)
But hey, at least the new program is only twice as much code!
[ Addendum: The program had a minor bug: it would disregard
capitalization when deciding if two words were anagrams, but then
compute the scores with capitals and lowercase letters distinct. So
for example Chaenolobus was considered an anagram of unchoosable,
but then the Ch in Chaenolobus would not be matched to the ch in
unchoosable, resulting in a score of 11 instead of 10. I have
corrected the program and the output. Thanks to Philip Cohen for
pointing this out. ]
[ Addendum 20170223: More about this ]
[ Addendum 20170507: Slides from my !!Con 2017 talk are now available. ]
[ Addendum 20170511: A large amount of miscellaneous related material ]
[Other articles in category /lang] permanent link