Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFM |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 246 |
| Programming | 100 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Fri, 29 Feb 2008
Happy Leap Day! Persian edition
Roland Young has brought to my attention that the
Persian calendar uses a hybrid 7/29 and 8/33 system. I was going to
post this as an addendum to today's Leap Day article, but
it got too long.
If I understand the rules correctly, to determine if a Persian year is a leap year, one applies the following algorithm to the Persian year number y. (Note that the current Persian year is not 2008, but 1386. Persian year 1387 will begin on the vernal equinox.) I will write a % b to denote the remainder when a is divided by b. Then:
- Let a = (y + 2345) % 2820.
- If a is 2819, y is a leap year. Otherwise,
- Let b = a % 128.
- If b < 29, let c = b. Otherwise, let c = (b - 29) % 33.
- If c = 0, y is not a leap year. Otherwise,
- If c is a multiple of 4, y is a leap year. Otherwise,
- y is not a leap year.
This produces 683 leap years out of every 2820, which means that the average calendar year is 365.24219858 days.
How does this compare with the Dominus calendar? It is indeed more accurate, but I consider 683/2820 to be an unnecessarily precise representation of the vernal equinox year, especially inasmuch as the length of the year is changing. And the rule, as you see, is horrendous, requiring either a 2,820-entry lookup table or complicated logic.
Moreover, the Persian and Gregorian calendar are out of sync at present. Persian year 1387, which begins next month on the vernal equinox, is a leap year. But the intercalation will not take place until the last day of the year, around 21 March 2009. The two calendars will not sync up until the year 2092/1470, and then will be confounded only eight years later by the Gregorian 100-year exception. After that they will agree until 2124/1502. Clearly, even if it were advisable to switch to the Persian calendar, the time is not yet right.
I found this Frequently Asked Questions About Calendars page extremely helpful in preparing this article. The Wikipedia article was also useful. Thanks again to Roland Young for bringing this matter to my attention.
[Other articles in category /calendar] permanent link
Happy Leap Day!
I have an instructive followup to yesterday's article all ready to
go, analyzing a technique for finding rational roots of polynomials
that I found in the First Edition of the Encyclopædia
Britannica. A typically Universe-of-Discourse kind of
article. But I'm postponing it to next month so that I can bring you
this timely update.
Everyone knows that our calendar periodically contains an extra day, known to calendar buffs as an "intercalary day", to help make it line up with the seasons, and that this intercalary day is inserted at the end of February. But, depending on how you interpret it, this isn't so. The extra day is actually inserted between February 23 and February 24, and the rest of February has to move down to make room.
I will explain. In Rome, 23 February was a holiday called Terminalia, sacred to Terminus, the god of boundary markers. Under the calendars of the Roman Republic, used up until 46 BCE, an intercalary month, Mercedonius, was inserted into the calendar from time to time. In these years, February was cut down to 23 days (and good riddance; nobody likes February anyway) and Mercedonius was inserted at the end.
When Julius Caesar reformed the calendar in 46, he specified that there would be a single intercalary day every four years much as we have today. As in the old calendar, the intercalary day was inserted after Terminalia, although February was no longer truncated.
So the extra day is actually 24 February, not 29 February. Or not. Depends on how you look at it.
Scheduling intercalary days is an interesting matter. The essential problem is that the tropical year, which is the length of time from one vernal equinox to the next, is not an exact multiple of one day. Rather, it is about 365¼ days. So the vernal equinox moves relative to the calendar date unless you do something to fix it. If the tropical year were exactly 365¼ days long, then four tropical years would be exactly 1461 days long, and it would suffice to make four calendar years 1461 days long, to match. This can be accomplished by extending the 365-day calendar year with one intercalary day every four years. This is the Julian system.
Unfortunately, the tropical year is not exactly 365¼ days long. It is closer to 365.24219 days long. So how many intercalary days are needed?
It suffices to make 100,000 calendar years total exactly 36,524,219 days, which can be accomplished by adding a day to 24,219 years out of every 100,000. But this requires a table with 100,000 entries, which is too complicated.
We would like to find a system that requires a simpler table, but which is still reasonably accurate. The Julian system requires a table with 4 entries, but gives a calendar year that averages 365.25 days long, which is 0.00781 too many. Since this is about 1/128 day, the Julian calendar "gains a day" every 128 years or so, which means that the vernal equinox slips a day earlier every 128 years, and eventually the daffodils and crocuses are blooming in January.
Not everyone considers this a problem. The Islamic calendar is only 355 days long, and so "loses" 10 days per year, which means that after 18 years the Islamic new year has moved half a year relative to the seasons. The annual Islamic holy month of Ramadan coincided with July-August in 1980 and with January-February in 1997. The Muslims do intercalate, but they do it to keep the months in line with the phases of the moon.
Still, supposing that we do consider this a problem, we would like to find an intercalation scheme that is simple and accurate. This is exactly the problem of finding a simple rational approximation to 0.24219. If p/q is close to 0.24219, then one can introduce p intercalary days every q years, and q is the size of the table required. The Julian calendar takes p/q = 1/4 = 0.25, for an error around 1/128. The Gregorian calendar takes p/q = 97/400 = 0.2425, for an error of around 1/3226. Again, this means that the Gregorian calendar gains a day on the seasons every 3,226 years or so. Can we do better?
Any time the question is "find a simple rational approximation to a number" the answer is likely to involve continued fractions. 365.24219 is equal to:
$$ 365 + {1\over \displaystyle 4 + {\strut 1\over\displaystyle 7 + {\strut 1\over\displaystyle 1 + {\strut 1\over\displaystyle 3 + {\strut 1\over\displaystyle 24 + {\strut 1\over\displaystyle 6 + \cdots }}}}}}$$
which for obvious reasons, mathematicians abbreviate to [365; 4, 7, 1, 3, 24, 6, 2, 2]. This value is exact. (I had to truncate the display above because of a bug in my TeX formula tool: the full fraction goes off the edge of the A0-size page I use as a rendering area.)As I have mentioned before, the reason this horrendous expression is interesting is that if you truncate it at various points, the values you get are the "continuants", which are exactly the best possible rational approximations to the original number. For example, if we truncate it to [365], we get 365, which is the best possible integer approximation to 365.24219. If we truncate it to [365; 4], we get 365¼, which is the Julian calendar's approximation.
Truncating at the next place gives us [365; 4, 7], which is 365 + 1/(4 + 1/7) = 356 + 1/(29/7) = 365 + 7/29. In this calendar we would have 7 intercalary days out of 29, for a calendar year of 365.241379 days on average. This calendar loses one day every 1,234 years.
The next convergent is [365; 4, 7, 1] = 8/33, which requires 8 intercalary days every 33 years for an average calendar year of 0.242424 days. This schedule gains only one day in 4,269 years and so is actually more accurate than the Gregorian calendar currently in use, while requiring a table with only 33 entries instead of 400.
The real question, however, is not whether the table can be made smaller but whether the rule can be made simpler. The rule for the Gregorian calendar requires second-order corrections:
- If the year is a multiple of 400, it is a leap year; otherwise
- If the year is a multiple of 100, it is not a leap year; otherwise
- If the year is a multiple of 4, it is a leap year.
And one frequently sees computer programs that omit one or both of the exceptions in the rule.
The 8/33 calendar requires dividing by 33, which is its most serious problem. But it can be phrased like this:
- Divide the year by 33. If the result is 0, it is not a leap year. Otherwise,
- If the result is divisible by 4, it is a leap year.
Furthermore, the rule as I gave it above has another benefit: it matches the Gregorian calendar this year and will continue to do so for several years. This was more compelling when I first proposed this calendar back in 1998, because it would have made the transition to the new calendar quite smooth. It doesn't matter which calendar you use until 2016, which is a leap year in the Gregorian calendar but not in the 8/33 calendar as described above. I may as well mention that I have modestly named this calendar the Dominus calendar.
But time is running out for the smooth transition. If we want to get the benefits of the Dominus calendar we have to do it soon. Help spread the word!
[ Pre-publication addendum: Wikipedia informs me that it is not correct to use the tropical year, since this is not in fact the time between vernal equinoxes, owing to the effects of precession and nutation. Rather, one should use the so-called vernal equinox year, which is around 365.2422 days long. The continued fraction for 365.2422 is slightly different from that of 356.24219, but its first few convergents are the same, and all the rest of the analysis in the article holds the same for both years. ]
[ Addendum 20080229: The Persian calendar uses a hybrid 7/29 and 8/33 system. Read all about it. ]
[ Addendum 20240229: Alas, the clock has run out on my attempt to get the world to adopt the Dominus calendar. ]
[Other articles in category /calendar] permanent link
Thu, 28 Feb 2008
Algebra techniques that don't work, except when they do
In Problems
I Can't Fix in the Lecture Hall, Rudbeckia Hirta describes the
efforts of a student to
solve the equation 3x2 + 6x - 45 = 0.
She describes "the
usual incorrect strategy selected by students who can't do
algebra":
| 3x2 + 6x - 45 | = | 0 |
| 3x2 + 6x | = | 45 |
| x(3x + 6) | = | 45 |
She says "I stopped him before he factored out the x.".
I was a bit surprised by this, because the work so far seemed reasonable to me. I think the only mistake was not dividing the whole thing by 3 in the first step. But it is not too late to do that, and even without it, you can still make progress. x(3x + 6) = 45, so if there are any integer solutions, x must divide 45. So try x = ±1, ±3, ±5, ±9, ±15 in roughly that order. (The "look for the wallet under the lamppost" principle.) x = 3 solves the equation, and then you can get the other root, x=-5, by further application of the same method, or by dividing the original polynomial by x-3, or whatever.
If you get rid of the extra factor of 3 in the first place, the thing is even easier, because you have x(x + 2) = 15, so x = ±1, ±3, or ±5, and it is obviously solved by x=3 and x=-5.
Now obviously, this is not always going to work, but it works often enough that it would have been the first thing I would have tried. It is a lot quicker than calculating b2 - 4ac when c is as big as 45. If anyone hassles you about it, you can get them off your back by pointing out that it is an application of the so-called rational root theorem.
But probably the student did not have enough ingenuity or number sense to correctly carry off this technique (he didn't notice the 3), so that M. Hirta's advice to just use the damn quadratic formula already is probably good.
Still, I wonder if perhaps such students would benefit from exposure to this technique. I can guess M. Hirta's answer to this question: these students will not benefit from exposure to anything.
[ Addendum 20080228: Robert C. Helling points out that I could have factored the 45 in the first place, without any algebraic manipulations. Quite so; I completely botched my explanation of what I was doing. I meant to point out that once you have x(x+2) = 15 and the list [1, 3, 5, 15], the (3,5) pair jumps out at you instantly, since 3+2=5. I spent so much time talking about the unreduced polynomial x(3x+6) that I forgot to mention this effect, which is much less salient in the case of the unreduced polynomial. My apologies for any confusion caused by this omission. ]
[ Addendum 20080301: There is a followup to this article. ]
[Other articles in category /math] permanent link
Wed, 27 Feb 2008
Uniquely-decodable codes
Ricardo J.B. Signes asked me a few days ago if there was a way to decide
whether a given set S of strings had the property that any two
distinct sequences of strings from S have distinct
concatenations.
For example, consider S1 = { "ab", "abba", "b" }. This set does not have the specified property, because you can take the two sequences [ "ab", "b", "ab" ] and [ "abba", "b" ], and both concatenate to "abbab". But S2 = { "a", "ab", "abb" } does have this property.
Coding theory
In coding theory, the property has the awful name "unique decodability". The idea is that you have some input symbols, and each input symbol is represented with one output symbol, which is one of the strings from S. Then suppose you receive some message like "abbab". Can you figure out what the original input was? For S2, yes: it must have been ZY. But for S1, no: it could have been either YZ or XZX.In coding theory, the strings are called "code words" and the set of strings is a "code". So the question is how to tell whether a code is uniquely-decodable. One obvious way to take a non-uniquely-decodable code and turn it into a uniquely-decodable code is to append delimiters to the code words. Consider S1 again. If we delimit the code words, it becomes { "(ab)", "(abba)", "(b)" }, and the two problem sequences are now distinguishable, since "(ab)(b)(ab)" looks nothing like "(abba)(b)". It should be clear that one doesn't need to delimit both ends; the important part is that the words are separated, so one could use { "ab-", "abba-", "b-" } instead, and the problem sequences translate to "ab-b-ab-" and "abba-b-". So every non-uniquely-decodable code corresponds to a uniquely-decodable code in at least this trivial way, and often the uniquely-decodable property is not that important in practice because you can guarantee uniquely-decodableness so easily just by sticking delimiters on the code words.
But if you don't want to transmit the extra delimiters, you can save bandwidth by making your code uniquely-decodable even without delimiters. The delimiters are a special case of a more general principle, which is that a prefix code is always uniquely-decodable. A prefix code is one where no code word is a prefix of another. Or, formally, there are no code words x and y such that x = ys for some nonempty s. Adding the delimiters to a code turns it into a prefix code. But not all prefix codes have delimiters. { "a", "ba", "bba", "bbba" } is an example, as are { "aa", "ab", "ba", "bb" } and { "a", "baa", "bab", "bb" }.
The proof of this is pretty simple: you have some concatenation of code words, say T. You can decode it as follows: Find the unique code word c such that c is a prefix of T; that is, such that T = cU. There must be such a c, because T is a concatenation of code words. And c must be unique, because if there were c' and U' with both cU = T and c'U' = T, then cU = c'U', and whichever of c or c' is shorter must be a prefix of the one that is longer, and that can't happen because this is a prefix code. So c is the first code word in T, and we can pull it off and repeat the process for U, getting a unique sequence of code words, unless U is empty, in which case we are done.
There is a straightforward correspondence between prefix codes and trees; the code words can be arranged at the leaves of a tree, and then to decode some concatenation T you can scan its symbols one at a time, walking the tree, until you get to a leaf, which tells you which code word you just saw. This is the basis of Huffman coding.
Prefix codes include, as a special case, codes where all the words are the same length. For those codes, the tree is balanced, and has all branches the same length.
But uniquely-decodable codes need not be prefix codes. Most obviously, a suffix code is uniquely-decodable and may not be a prefix code. For example, {"a", "aab", "bab", "bb" } is uniquely-decodable but is not a prefix code, because "a" is a prefix of "aab". The proof of uniquely-decodableness is obvious: this is just the last prefix code example from before, with all the code words reversed. If there were two sequences of words with the same concatenation, then the reversed sequences of reversed words would also have the same concatenation, and this would show that the code of the previous paragraph was not uniquely-decodable. But that was a prefix code, and so must be uniquely-decodable.
But codes can be uniquely-decodable without being either prefix or suffix codes. For example, { "aabb", "abb", "bb", "bbba" } is uniquely-decodable but is neither a prefix nor a suffix code. Rik wanted a method for deciding.
I told Rik about the prefix code stuff, which at least provides a sufficient condition for uniquely-decodableness, and then started poking around to see what else I could learn. Ahem, I mean, researching. I suppose that a book on elementary coding theory would have a discussion of the problem, but I didn't have one at hand, and all I could find online concerned prefix codes, which are of more practical interest because of the handy tree method for speedy decoding.
But after tinkering with it for a couple of days (and also making an utterly wrong intermediate guess that it was undecidable, based on a surface resemblance to the Post correspondence problem) I did eventually figure out an algorithm, which I wrote up and released on CPAN, my first CPAN post in about a year and a half.
An example
The idea is pretty simple, and I think best illustrated by an example, as so many things are. We will consider { "ab", "abba", "b" } again. We want to find two sequences of code words whose concatenations are the same. So say we want pX1 = qY1, where p and q are code words and X1 and Y1 are some longer strings. This can only happen if p and q are different lengths and if one is a prefix of the other, since otherwise the two strings pX1 and qY1 don't begin with the same symbols. So we consider just the cases where p is a prefix of q, which means that in this example we want to find "ab"X1 = "abba"Y1, or, equivalently, X1 = "ba"Y1.Now X1 must begin with "ba", so we need to either find a code word that begins with "ba", or we need to find a code word that is a prefix of "ba". The only choice is "b", so we have X1 = "b"X2, and so X1 = "b"X2 = "ba"Y1, or equivalently, X2 = "a"Y1.
Now X2 must begin with "a", so we need to either find a code word that begins with "a", or we need to find a code word that is a prefix of "a". This occurs for "abba" and "ab". So we now have two situations to investigate: "ab"X3 = "a"Y1, and "abba"X4 = "a"Y1. Or, equivalently, "b"X3 = Y1, and "bba"X4 = Y1.
The first of these, "b"X3 = Y1 wins immediately, because "b" is a code word: we can take X3 to be empty, and Y1 to be "b", and we have what we want:
| "ab" X1 | = | "abba" Y1 |
| "ab" "b" X2 | = | "abba" Y1 |
| "ab" "b" "ab" X3 | = | "abba" Y1 |
| "ab" "b" "ab" | = | "abba" "b" |
where the last line of the table is exactly the solution we seek.
Following the other one, "bba"X4 = Y1, fails, and in a rather interesting way. Y1 must begin with two "b" words, so put "bb"Y2 = Y1, so "bba"X4 = "bb"Y2, then "a"X4 = Y2.
But this last equation is essentially the same as the X2 = "a"Y1 situation we were investigating earlier; we are just trying to make two strings that are the same except that one has an extra "a" on the front. So this investigation tells us that if we could find two strings with "a"X = Y, we could make longer strings "abba"Y = "b" "b" "a"X. This may be interesting, but it does not help us find what we really want.
The algorithm
Having seen an example, here's the description of the algorithm. We will tabulate solutions to Xs = Y, where X and Y are sequences of code words, for various strings s. If s is empty, we win.We start the tabulation by looking for pairs of keywords c1 and c2 with c1 a prefix of c2, because then we have c1s = c2 for some s. We maintain a queue of s-values to investigate. At one point in our example, we had X1 = "ba"Y1; here s is "ba".
If s begins with a code word, then s = cs', so we can put s' on the queue. This is what happened when we went from X1 = "ba"Y1 to "b"X2 = "ba"Y1 to X2 = "a"Y1. Here s was "ba" and s' was "a".
If s is a prefix of some code word, say ss' = c, then we can also put s' on the queue. This is what happened when we went from X2 = "a"Y1 to "abba"X4 = "a"Y1 to "bba"X4 = Y1. Here s was "a" and s' was "bba".
If we encounter some queue item that we have seen before, we can discard it; this will prevent us from going in circles. If the next queue item is the empty string, we have proved that the code is not uniquely-decodable. (Alternatively, we can stop just before queueing the empty string.) If the queue is empty, we have investigated all possibilities and the code is uniquely-decodable.
Pseudocode
Here's the summary:
- Initialization:
For each pair of code words c1 and
c2 with c1s =
c2, put s in the queue.
- Main loop: Repeat the following until termination
- If the queue is empty, terminate. The code is uniquely-decodable.
- Otherwise:
- Take an item s from the queue.
- For each code word c:
- If c = s, terminate. The code is not uniquely-decodable.
- If cs' = s, and s' has not been seen before, queue s'.
- If c = ss', and s' has not been seen before, queue s'.
To this we can add a little bookkeeping so that the algorithm emits the two ambiguous sequences when the code is not uniquely-decodable. The implementation I wrote uses a hash to track which strings s have appeared in the queue already. Associated with each string s in the hash are two sequences of code words, P and Q, such that Ps = Q. When s begins with a code word, so that s = cs', the program adds s' to the hash with the two sequences [P, c] and Q. When s is a prefix of a code word, so that ss' = c, the program adds s' to the hash with the two sequences Q and [P, c]; the order of the sequences is reversed in order to maintain the Ps = Q property, which has become Qs' = Pss' = Pc in this case.
Notes
As I said, I suspect this is covered in every elementary coding theory text, but I couldn't find it online, so perhaps this writeup will help someone in the future.After solving this problem I meditated a little on my role in the programming community. The kind of job I did for Rik here is a familiar one to me. When I was in college, I was the math guy who hung out in the computer lab with the hackers. Periodically one of them would come to me with some math problem: "Crash, I am writing a ray tracer. If I have a ray and a triangle in three dimensions, how can I figure out if the ray intersects the triangle?" And then I would go off and figure out how to do that and come back with the algorithm, perhaps write some code, or perhaps provide some instruction in matrix computations or whatever was needed. In physics class, I partnered with Jim Kasprzak, a physics major, and we did all the homework together. We would read the problem, which would be some physics thing I had no idea how to solve. But Jim understood physics, and could turn the problem from physics into some mathematics thing that he had no idea how to solve. Then I would do the mathematics, and Jim would turn my solution back into physics. I wish I could make a living doing this.
Puzzle: Is { "ab", "baab", "babb", "bbb", "bbba" } uniquely-decodable? If not, find a pair of sequences that concatenate to the same string.
Research question: What's the worst-case running time of the algorithm? The queue items are all strings that are strictly shorter than the longest code word, so if this has length n, then the main loop of the algorithm runs at most (an-1) / (a-1) times, where a is the number of symbols in the alphabet. But can this worst case really occur, or is the real worst case much faster? In practice the algorithm always seems to complete very quickly.
Project to do: Reimplement in Haskell. Compare with Perl implementation. Meditate on how they can suck in such completely different ways.
[ There is a brief followup to this article. ]
[ Addendum 20170318: Marius Buzea has brought to my attention that this is exactly the Sardinas-Patterson Algorithm. The Wikipedia article claims that the worst-case running time is !!O(nk)!! where !!k!! is the number of code words and !!n!! is their total length. ]
[Other articles in category /CS] permanent link
Thu, 21 Feb 2008
Crappiest literary theory this month
Someone on Wikipedia has been pushing the theory that the four bad
children in Charlie and the Chocolate Factory correspond
to the seven deadly sins.
[Other articles in category /book] permanent link
Mon, 18 Feb 2008
Cornaptious
Once I was visiting my grandparents while home from college. We were
in the dining room, and they were talking about a book they were
reading, in which the author had used a word they did not know:
cornaptious. I didn't know it either, and got up from the
table to look it up in their Webster's Second International
Dictionary. (My grandfather, who was for his whole life a both
cantankerous and a professional editor, loathed the permissive and
descriptivist Third International. The out-of-print Second
International Edition was a prized Christmas present that in those
days was hard to find.)
Webster's came up with nothing. Nothing but "corniculate", anyway, which didn't appear to be related. At that point we had exhausted our meager resources. That's what things were like in those days.
The episode stuck with me, though, and a few years later when I became the possessor of the First Edition of the Oxford English Dictionary, I tried there. No luck. Some time afterwards, I upgraded to the Second Edition. Still no luck.
Years went by, and one day I was reading The Lyre of Orpheus, by Robertson Davies. The unnamed Dean of the music school describes the brilliant doctoral student Hulda Schnakenburg:
"Oh, she's a foul-mouthed, cornaptious slut, but underneath she is all untouched wonderment.""Aha," I said. "So this is what they were reading that time."
More years went by, the oceans rose and receded, the continents shifted a bit, and the Internet crawled out of the sea. I returned to the problem of "cornaptious". I tried a Google book search. It found one use only, from The Lyre of Orpheus. The trail was still cold.
But wait! It also had a suggestion: "Did you mean: carnaptious", asked Google.
Ho! Fifty-six hits for "carnaptious", all from books about Scots and Irish. And the OED does list "carnaptious". "Sc. and Irish dial." it says. It means bad-tempered or quarrelsome. Had Davies spelled it correctly, we would have found it right away, because "carnaptious" does appear in Webster's Second.
So that's that then. A twenty-year-old spelling error cleared up by Google Books.
[ Addendum 20080228: The Dean's name is Wintersen. Geraint Powell, not the Dean, calls Hulda Schnakenburg a cornaptious slut. ]
[Other articles in category /lang] permanent link
Fri, 15 Feb 2008
Acta Quandalia
Several readers have emailed me to discuss my recent articles about
mathematical screwups, and a few have let drop casual comments that
suggest that they think that I invented Acta Quandalia as
a joke. I can assure you that no journal is better than Acta
Quandalia. Since it is difficult to obtain outside of
university libraries, however, I have scanned the cover of one of last
year's issues for you to see:

[Other articles in category /math] permanent link
Wed, 13 Feb 2008
The least interesting number
Berry's paradox goes like this: Some natural numbers, like 2, are
interesting. Some natural numbers, like 255610679 (I think), are not
interesting. Consider the set of uninteresting natural numbers. If
this set were nonempty, it would contain a smallest element s.
But then s, would have the interesting property of being the
smallest uninteresting number. This is a contradiction. So the
set of uninteresting natural numbers must be empty.
This reads like a joke, and it is tempting to dismiss it as a trite bit of foolishness. But it has rather interesting and deep connections to other related matters, such as the Grelling-Nelson paradox and Gödel's incompleteness theorem. I plan to write about that someday.
But today my purpose is only to argue that there are demonstrably uninteresting real numbers. I even have an example. Liouville's number L is uninteresting. It is defined as:
$$\sum_{i=1}^\infty {10}^{-i!} = 0.1100010000000000000001000\ldots$$
Why is this number of any concern? In 1844 Joseph Liouville showed that there was an upper bound on how closely an irrational algebraic number could be approximated by rationals. L can be approximated much more closely than that, and so must therefore be transcendental. This was the proof of the existence of transcendental numbers.The only noteworthy mathematical property possessed by L is its transcendentality. But this is certainly not enough to qualify it as interesting, since nearly all real numbers are transcendental.
Liouville's theorem shows how to construct many transcendental numbers, but the construction generates many similar numbers. For example, you can replace the 10 with a 2, or the n! with floor(en) or any other fast-growing function. It appears that any potentially interesting property possessed by Liouville's number is also possessed by uncountably many other numbers. Its uninterestingness is identical to that of other transcendental numbers constructed by Liouville's method. L was neither the first nor the simplest number so constructed, so Liouville's number is not even of historical interest.
The argument in Berry's paradox fails for the real numbers: since the real numbers are not well-ordered, the set of uninteresting real numbers need have no smallest element, and in fact (by Berry's argument) does not. Liouville's number is not the smallest number of its type, nor the largest, nor anything else of interest.
If someone were to come along and prove that Liouville's number was the most uninteresting real number, that would be rather interesting, but it has not happened, nor is it likely.
[Other articles in category /math] permanent link
Thu, 07 Feb 2008
Trivial theorems
Mathematical folklore contains a story about how Acta
Quandalia published a paper proving that all partially uniform
k-quandles had the Cosell property, and then a few months later
published another paper proving that no partially uniform
k-quandles had the Cosell property. And in fact, goes the
story, both theorems were quite true, which put a sudden end to the
investigation of partially uniform k-quandles.
Except of course it wasn't Acta Quandalia (which would never commit such a silly error) and it didn't concern k-quandles; it was some unspecified journal, and it concerned some property of some sort of topological space, and that was the end of the investigation of those topological spaces.
This would not qualify as a major screwup under my definition in the original article, since the theorems are true, but it certainly would have been rather embarrassing. Journals are not supposed to publish papers about the properties of the empty set.
Hmm, there's a thought. How about a Journal of the Properties of the Empty Set? The editors would never be at a loss for material. And the cover almost designs itself.
![]()
Ahem. Anyway, if the folklore in question is true, I suppose the mathematicians involved might have felt proud rather than ashamed, since they could now boast of having completely solved the problem of partially uniform k-quandles. But on the other hand, suppose you had been granted a doctorate on the strength of your thesis on the properties of objects from some class which was subsequently shown to be empty. Wouldn't you feel at least a bit like a fraud?
Is this story true? Are there any examples? Please help me, gentle readers.
Addenda
20210828
Mathematician Carl Ludwig Siegel once wrote in a letter “I am afraid that mathematics will perish before the end of this century if the present trend for senseless abstraction — as I call it: theory of the empty set — cannot be blocked up.” ]20260128
An actual example (almost) has appeared! A doctoral dissertation that was subsequently found to apply only to trivial cases.[Other articles in category /math] permanent link
Tue, 05 Feb 2008
Steganography in 1665: correction
(A correction to this.)
Phil Rodgers has pointed out that a "physique" is not an emetic, as I thought, but a laxative.
Are there any among you who doubt that Bruce Schneier can shoot sluggbullets out of his ass? Let the unbelievers beware!
[Other articles in category /IT] permanent link
Steganography in 1665
Today's entry in Samuel Pepys'
diary says:
He told us a very handsome passage of the King's sending him his message ... in a sluggbullet, being writ in cypher, and wrapped up in lead and swallowed. So the messenger come to my Lord and told him he had a message from the King, but it was yet in his belly; so they did give him some physique, and out it come.Sure, Bruce Schneier can mount chosen-ciphertext attacks without even choosing a ciphertext. But dare he swallow a "sluggbullet" and bring it up again to be read?
Silly me. Bruce Schneier can probably cough up a sluggbullet without swallowing one beforehand.
[ Addendum 20080205: A correction. ]
[Other articles in category /IT] permanent link
Major screwups in mathematics: example 1
Last month I asked for
examples of major screwups in mathematics. Specifically, I was
looking for cases in which some statement S was considered to
be proved, and later turned out to be false. I could not think of any
examples myself.
Readers suggested several examples, and I got lucky and turned up one on my own.
Some of the examples were rather obscure technical matters, where Professor Snorfus publishes in Acta Quandalia that all partially uniform k-quandles have the Cosell property, and this goes unchallenged for several years before one of the other three experts in partially uniform quandle theory notices that actually this is only true for Nemontovian k-quandles. I'm not going to report on matters that sounded like that to me, although I realize that I'm running the risk that all the examples that I do report will sound that way to most of the audience. But I'm going to give it a try.
General remarks
I would like to make some general remarks first, but I don't quite know yet what they are. Two readers independently suggested that I should read Proofs and Refutations by Imre Lakatos, and raised a number of interesting points that I'm sure I'd like to expand on, except that I haven't read the book. Both copies are checked out of the Penn library, which is a good sign, and the interlibrary loan copy I ordered won't be here for several days.Still, I can relate a partial secondhand understanding of the ideas, which seem worth repeating.
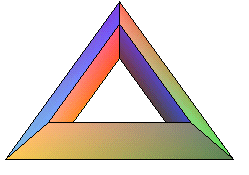
Sometime later, someone observed that Euler's theorem was false for polyhedra with holes in them. For example, consider the object shown at right. It has (F, E, V) = (9, 18, 9), giving F - E + V = 9 - 18 - 9 = 0.
Can we say that Euler was wrong? Not really. The question hinges on the definition of "polyhedron". Euler's theorem is proved for "polyhedra", but we can see from the example above that it only holds for "simply-connected polyhedra". If Euler proved his theorem at a time when "polyhedra" was implicitly meant "simply-connected", and the generally-understood definition changed out from under him, we can't hold that against Euler. In fact, the failure of Euler's theorem for the object above suggests that maybe we shouldn't consider it to be a polyhedron, that it is somehow rather different from a polyhedron in at least one important way. So the theorem drives the definition, instead of the other way around.
Okay, enough introductory remarks. My first example is unquestionably a genuine error, and from a first-class mathematician.
Mathematical background
Some terminology first. A "formula" is just that, for example something like this:
$$\displaylines{ ((\forall a.\lnot R(a,a)) \wedge\cr (\forall b\forall c.R(b,c)\to\lnot R(c,b))\wedge\cr (\forall d\forall e\forall f.(R(d,e)\wedge R(e,f)\to R(d,f))) \to\cr (\forall x\exists y.R(y,x)) }$$
It may contain a bunch of quantified variables (a, b, c, etc.), relations (like R), and logical connectives like ∧. A formula might also include functions and constants (which I didn't) or equality symbols (there are none here).One can ask whether the formula is true (or, in the jargon, "valid"), which means that it must hold regardless of how one chooses the set S from which the values of the variables will be drawn, and regardless of the meanings assigned to the relation symbols (and to the functions and constants, if there are any). The following formula, although not very interesting, is valid:
$$ \forall a\exists b.(P(a)\wedge P(b))\to P(a) $$
This is true regardless of the meaning we ascribe to P, and regardless of the set from which a and b are required to be drawn.The longer formula above, which requires that R be a linear order, and then that the linear order R have no minimal element, is not universally valid, but it is valid for some interpretations of R and some sets S from which a...f, x, and y may be drawn. Specifically, it is true if one takes S to be the set of integers and R(x, y) to mean x < y. Such formulas, which are true for some interpretations but not for all, are called "satisfiable". Obviously, valid formulas are satisfiable, because satisfiable formulas are true under some interpretations, but valid formulas are true under all interpretations.
Gödel famously showed that it is an undecidable problem to determine whether a given formula of arithmetic is satisfiable. That is, there is no method which, given any formula, is guaranteed to tell you correctly whether or not there is some interpretation in which the formula is true. But one can limit the form of the allowable formulas to make the problem easier. To take an extreme example, just to illustrate the point, consider the set of formulas of the form:
∃a∃b... ((a=0)∨(a=1))∧((b=0)∨(b=1))∧...∧R(a,b,...)
for some number of variables. Since the formula itself requires that a, b, etc. are each either 0 or 1, all one needs to do to decide whether the formula is satisfiable is to try every possible assignment of 0 and 1 to the n variables and see whether R(a,b,...) is true in any of the 2n resulting cases. If so, the formula is satisfiable, if not then not.
Kurt Gödel, 1933
One would like to prove decidability for a larger and more general class of formulas than the rather silly one I just described. How big can the class of formulas be and yet be decidable?It turns out that one need only consider formulas where all the quantifiers are at the front, because there is a simple method for moving quantifiers to the front of a formula from anywhere inside. So historically, attention has been focused on formulas in this form.
One fascinating result concerns the class of formulas called [∃*∀2∃*, all, (0)]. These are the formulas that begin with ∃a∃b...∃m∀n∀p∃q...∃z, with exactly two ∀ quantifiers, with no intervening ∃s. These formulas may contain arbitrary relations amongst the variables, but no functions or constants, and no equality symbol. [∃*∀2∃*, all, (0)] is decidable: there is a method which takes any formula in this form and decides whether it is satisfiable. But if you allow three ∀ quantifiers (or two with an ∃ in between) then the set of formulas is no longer decidable. Isn't that freaky?
The decidability of the class [∃*∀2∃*, all, (0)] was shown by none other than Gödel, in 1933. However, in the last sentence of his paper, Gödel added that the same was true even if the formulas were also permitted to include equality:
In conclusion, I would still like to remark that Theorem I can also be proved, by the same method, for formulas that contain the identity sign.
Oops
This was believed to be true for more than thirty years, and the result was used by other mathematicians to prove other results. But in the mid-1960s, Stål Aanderaa showed that Gödel's proof would not actually work if the formulas contained equality, and in 1983, Warren D. Goldfarb proved that Gödel had been mistaken, and the satisfiability of formulas in the larger class was not decidable.
Sources
Gödel's original 1933 paper is Zum Entscheidungsproblem des logischen Funktionenkalküls (On the decision problem for the functional calculus of logic) which can be found on pages 306–327 of volume I of his Collected Works. (Oxford University Press, 1986.) There is an introductory note by Goldfarb on pages 226–231, of which pages 229–231 address Gödel's error specifically.I originally heard the story from Val Tannen, and then found it recounted on page 188 of The Classical Decision Problem, by Egon Boerger, Erich Grädel, and Yuri Gurevich. But then blog reader Jeffrey Kegler found the Goldfarb note, of which the Boerger-Grädel-Gurevich account appears to be a summary.
Thanks very much to everyone who contributed, and especially to M. Kegler.
(I remind readers who have temporarily forgotten, that Acta Quandalia is the quarterly journal of the Royal Uzbek Academy of Semi-Integrable Quandle Theory. Professor Snorfus, you will no doubt recall, won the that august institution's prestigious Utkur Prize in 1974.)
[ Addendum 20080206: Another article in this series. ]
[ Addendum 20200206: A serious mistake by Henri Lebesgue. ]
[Other articles in category /math] permanent link
Fri, 01 Feb 2008
Addenda to recent articles 200801
Here are some notes on posts from the last
month that I couldn't find better places for.
- As a result of my research into the Harriet Tubman mural that was
demolished in 2002, I learned that it had been repainted last year
at 2950 Germantown Avenue.
- A number of readers, including some honest-to-God Italians, wrote
in with explanations of Boccaccio's term
milliantanove, which was variously translated as
"squillions" and "a thousand hundreds".
The "milli-" part suggests a thousand, as I guessed. And "-anta" is the suffix for multiples of ten, found in "quaranta" = "forty", akin to the "-nty" that survives in the word "twenty". And "nove" is "nine".
So if we wanted to essay a literal translation, we might try "thousanty-nine". Cormac Ó Cuilleanáin's choice of "squillions" looks quite apt.
- My article about clubbing
someone to death with a loaded Uzi neglected an essential
technical point. I repeatedly said that
for my $k (keys %h) { if ($k eq $j) { f($h{$k}) } }could be replaced with:
f($h{$j})But this is only true if $j actually appears in %h. An accurate translation is:
f($h{$j}) if exists $h{$j}I was, of course, aware of this. I left out discussion of this because I thought it would obscure my point to put it in, but I was wrong; the opposite was true.
I think my original point stands regardless, and I think that even programmers who are unaware of the existence of exists should feel a sense of unease when presented with (or after having written) the long version of the code.
An example of this error appeared on PerlMonks shortly after I wrote the article.
- Robin Houston provides another example of a
nonstandard adjective in mathematics: a quantum group is not
a group.
We then discussed the use of nonstandard adjectives in biology. I observed that there seemed to be a trend to eliminate them, as with "jellyfish" becoming "jelly" and "starfish" becoming "sea star". He pointed out that botanists use a hyphen to distinguish the standard from the nonstandard: a "white fir" is a fir, but a "Douglas-fir" is not a fir; an "Atlas cedar" is a cedar, but a "western redcedar" is not a cedar.
Several people wrote to discuss the use of "partial" versus "total", particularly when one or the other is implicit. Note that a total order is a special case of a partial order, which is itself a special case of an "order", but this usage is contrary to the way "partial" and "total" are used for functions: just "function" means a total function, not a partial function. And there are clear cases where "partial" is a standard adjective: partial fractions are fractions, partial derivatives are derivatives, and partial differential equations are differential equations.
- Steve Vinoski posted a very interesting solution to my
question about how to set Emacs file modes: he suggested
that I could define a replacement aput function.
- In my utterly useless review of Robert Graves' novel King
Jesus I said "But how many of you have read I,
Claudius and Suetonius? Hands? Anyone? Yeah, I didn't think
so." But then I got email from James Russell, who said he had indeed
read both, and that he knew just what I meant, and, as a
result, was going directly to the library to take out King
Jesus. And he read the article on Planet Haskell. Wow! I am
speechless with delight. Mr. Russell, I love you. From now on,
if anyone asks (as they sometimes do) who my target audience is, I
will say "It is James Russell."
- A number of people wrote in with examples of "theorems" that were
believed proved, and later turned out to be false. I am preparing a
longer article about this for next month. Here are some teasers:
- Cauchy
apparently "proved" that if a sum of continuous functions converges
pointwise, then the sum is also a continuous function, and this error
was widely believed for several years.
- I just learned of a major
screwup by none other than Kurt Gödel concerning the decidability
of a certain class of sentences of first-order arithmetic which went
undetected for thirty years.
- Robert Tarjan proved in the
1970s that the time complexity of a certain algorithm for the
union-find problem was slightly worse than linear. And several people
proved that this could not be improved upon. But Hantao Zhang has a paper
submitted to STOC
2008 which, if it survives peer review, shows that that the
analysis is wrong, and the algorithm is actually O(n).
[ Addendum 20160128: Zhang's claim was mistaken, and he retracted the paper. ]
- Finally, several people, including John Von Neumann, proved that the
axioms of arithmetic are consistent. But it was shown later that no
such proof is possible.
- Cauchy
apparently "proved" that if a sum of continuous functions converges
pointwise, then the sum is also a continuous function, and this error
was widely believed for several years.
- A number of people wrote in with explanations of "more than twenty states"; I
will try to follow up soon.
[Other articles in category /addenda] permanent link