Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2025: | JFMAM |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 245 |
| Programming | 99 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 35 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 22 |
| Physics | 21 |
| Perl | 17 |
| Biology | 15 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Mon, 30 Apr 2007
Woodrow Wilson on bloggers
Last weekend my family and I drove up to New York. On the way we
stopped in the Woodrow Wilson Service Area on the New Jersey
Turnpike, which has a little plaque on the wall
commemorating Woodrow Wilson and providing some quotations, such as:
Uncompromising thought is the luxury of the closeted recluse.
(Part of a speech at the University of Tennessee in 17 June, 1890).
Bloggers beware; Woodrow Wilson has your number.
[Other articles in category /meta] permanent link
Sun, 29 Apr 2007
Your age as a fraction, again
In a recent article, I
discussed methods for calculating your age as a fractional year, in
the style of (a sophisticated) three-and-a-half-year-old. For
example, as of today, Richard M. Stallman is (a sophisticated)
54-and-four-thirty-thirds-year-old; tomorrow he'll be a
54-and-one-eighth-year-old.
I discussed several methods of finding the answer, including a clever but difficult method that involved fiddling with continued fractions, and some dead-simple brute force methods that take nominally longer but are much easier to do.
But a few days ago on IRC, a gentleman named Mauro Persano said he thought I could use the Stern-Brocot tree to solve the problem, and he was absolutely right. Application of a bit of clever theory sweeps away all the difficulties of the continued-fraction approach, leaving behind a solution that is clever and simple and fast.
Here's the essence of it: We consider a list of intervals that covers all the positive rational numbers; initially, the list contains only the interval (0/1, 1/0). At each stage we divide each interval in the list in two, by chopping it at the simplest fraction it contains.
To chop the interval (a/b, c/d), we split it into the two intervals (a/b, (a+c)/(b+d)), ((a+c)/(b+d)), c/d). The fraction (a+c)/(b+d) is called the mediant of a/b and c/d. It's not obvious that the mediant is always the simplest possible fraction in the interval, but it is true.
So we start with the interval (0/1, 1/0), and in the first step we split it at (0+1)/(1+0) = 1/1. It is now two intervals, (0/1, 1/1) and (1/1, 1/0). At the next step, we split these two intervals at 1/2 and 2/1, respectively; the resulting four intervals are (0/1, 1/2), (1/2, 1/1), (1/1, 2/1), and (2/1, 1/0). We split these at 1/3, 2/3, 3/2, and 3/1. The process goes on from there:
| 0/1 | 1/0 | ||||||||||||||||||||||||||||||
| 0/1 | 1/1 | 1/0 | |||||||||||||||||||||||||||||
| 0/1 | 1/2 | 1/1 | 2/1 | 1/0 | |||||||||||||||||||||||||||
| 0/1 | 1/3 | 1/2 | 2/3 | 1/1 | 3/2 | 2/1 | 3/1 | 1/0 | |||||||||||||||||||||||
| 0/1 | 1/4 | 1/3 | 2/5 | 1/2 | 3/5 | 2/3 | 3/4 | 1/1 | 4/3 | 3/2 | 5/3 | 2/1 | 5/2 | 3/1 | 4/1 | 1/0 |
Or, omitting the repeated items at each step:
| 0/1 | 1/0 | ||||||||||||||||||||||||||||||
| 1/1 | |||||||||||||||||||||||||||||||
| 1/2 | 2/1 | ||||||||||||||||||||||||||||||
| 1/3 | 2/3 | 3/2 | 3/1 | ||||||||||||||||||||||||||||
| 1/4 | 2/5 | 3/5 | 3/4 | 4/3 | 5/3 | 5/2 | 4/1 |
If we disregard the two corners, 0/1 and 1/0, we can see from this diagram that the fractions naturally organize themselves into a tree. If a fraction is introduced at step N, then the interval it splits has exactly one endpoint that was introduced at step N-1, and this is its parent in the tree; conversely, a fraction introduced at step N is the parent of the two step-N+1 fractions that are introduced to split the two intervals of which it is an endpoint.
This process has many important and interesting properties. The splitting process eventually lists every positive rational number exactly once, as a fraction in lowest terms. Every fraction is simpler than all of its descendants in the tree. And, perhaps most important, each time an interval is split, it is divided at the simplest fraction that the interval contains. ("Simplest" just means "has the smallest denominator".)
This means that we can find the simplest fraction in some interval simply by doing binary tree search until we find a fraction in that interval.
For example, Placido Polanco had a .368 batting average last season. What is the smallest number of at-bats he could have had? We are asking here for the denominator of the simplest fraction that lies in the interval [.3675, .3685).
- We start at the root, which is 1/1. 1 is too big, to we move left down the tree to 1/2.
- 1/2 = .5000 and is also too big, so we move left down the tree to 1/3.
- 1/3 = .3333 and is too small, so we move right down the tree to 2/5.
- 2/5 = .4000 and is too big, so go left to 3/8, which is the mediant of 1/3 and 2/5.
- 3/8 = .3750, so go left to 4/11, the mediant of 1/3 and 3/8.
- 4/11 = .3636, so go right to 7/19, the mediant of 3/8 and 4/11.
- 7/19 = .3684, which is in the interval, so we are done.
Calculation of mediants is incredibly simple, even easier than adding fractions. Tree search is simple, just compare and then go left or right. Calculating whether a fraction is in an interval is simple too. Everything is simple simple simple.
Our program wants to find the simplest fraction in some interval, say (L, R). To do this, it keeps track of l and r, initially 0/1 and 1/0, and repeatedly calculates the mediant m of l and r. If the mediant is in the target interval, the function is done. If the mediant is too small, set l = m and continue; if it is too large set r = m and continue:
# Find and return numerator and denominator of simplest fraction
# in the range [$Ln/$Ld, $Rn/$Rd)
#
sub find_simplest_in {
my ($Ln, $Ld, $Rn, $Rd) = @_;
my ($ln, $ld) = (0, 1);
my ($rn, $rd) = (1, 0);
while (1) {
my ($mn, $md) = ($ln + $rn, $ld + $rd);
# print " $ln/$ld $mn/$md $rn/$rd\n";
if (isin($Ln, $Ld, $mn, $md, $Rn, $Rd)) {
return ($mn, $md);
} elsif (isless($mn, $md, $Ln, $Ld)) {
($ln, $ld) = ($mn, $md);
} elsif (islessequal($Rn, $Rd, $mn, $md)) {
($rn, $rd) = ($mn, $md);
} else {
die;
}
}
}
(In this program, rn and rd are the numerator and
the denominator of r.)The isin, isless, and islessequal functions are simple utilities for comparing fractions.
# Return true iff $an/$ad < $bn/$bd
sub isless {
my ($an, $ad, $bn, $bd) = @_;
$an * $bd < $bn * $ad;
}
# Return true iff $an/$ad <= $bn/$bd
sub islessequal {
my ($an, $ad, $bn, $bd) = @_;
$an * $bd <= $bn * $ad;
}
# Return true iff $bn/$bd is in [$an/$ad, $cn/$cd).
sub isin {
my ($an, $ad, $bn, $bd, $cn, $cd) = @_;
islessequal($an, $ad, $bn, $bd) and isless($bn, $bd, $cn, $cd);
}
The asymmetry between
isless and islessequal is because I want to deal with
half-open intervals.Just add a trivial scaffold to run the main function and we are done:
#!/usr/bin/perl
my $D = shift || 10;
for my $N (0 .. $D-1) {
my $Np1 = $N+1;
my ($mn, $md) = find_simplest_in($N, $D, $Np1, $D);
print "$N/$D - $Np1/$D : $mn/$md\n";
}
Given the argument 10, the program produces this output:
0/10 - 1/10 : 1/11
1/10 - 2/10 : 1/6
2/10 - 3/10 : 1/4
3/10 - 4/10 : 1/3
4/10 - 5/10 : 2/5
5/10 - 6/10 : 1/2
6/10 - 7/10 : 2/3
7/10 - 8/10 : 3/4
8/10 - 9/10 : 4/5
9/10 - 10/10 : 9/10
This says that the simplest fraction in the range [0/10, 1/10) is
1/11; the simplest fraction in the range [3/10, 4/10) is 1/3, and so
forth. The simplest fractions that do not appear are 1/5, which is
beaten out by the simpler 1/4 in the [2/10, 3/10) range, and 3/5,
which is beaten out by 2/3 in the [6/10, 7/10) range.Unlike the programs from the previous article, this program is really fast, even in principle, even for very large arguments. The code is brief and simple. But we had to deploy some rather sophisticated number theory to get it. It's a nice reminder that the sawed-off shotgun doesn't always win.
This is article #200 on my blog. Thanks for reading.
[Other articles in category /math] permanent link
Sat, 28 Apr 2007
1219.2 feet
In Thursday's article, I
quoted an article about tsunamis that asserted that:
In the Pacific Ocean, a tsunami moves 60.96 feet a second, passing through water that is around 1219.2 feet deep."60.96 feet a second" is an inept conversion of 100 km/h to imperial units, but I wasn't able to similarly identify 1219.2 feet.
Scott Turner has solved the puzzle. 1219.2 feet is an inept conversion of 4000 meters to imperial units, obtained by multiplying 4000 by 0.3048, because there are 0.3048 meters in a foot.
Thank you, M. Turner.
[ Addendum 20070430: 60.96 feet per second is nothing like 100 km/hr, and I have no idea why I said it was. The 60.96 feet per second is a backwards conversion of 200 m/s. ]
[Other articles in category /physics] permanent link
Thu, 26 Apr 2007
Excessive precision
You sometimes read news articles that say that some object is 98.42
feet tall, and it is clear what happened was that the object was
originally reported to be 30 meters tall, and some knucklehead
translated 30 meters to 98.42 feet, instead of to 100 feet as they
should have.
Finding a real example for you was easy: I just did Google search for "62.14 miles", and got this little jewel:
Tsunami waves can be up to 62.14 miles long! They can also be about three feet high in the middle of the ocean. Because of its strong underwater energetic force, the tsunami can rise up to 90 feet, in extreme cases, when they hit the shore! Tsunami waves act like shallow water waves because they are so long. Because it is so long, it can last an hour. In the Pacific Ocean, a tsunami moves 60.96 feet a second, passing through water that is around 1219.2 feet deep.The 60.96 feet per second is actually 100 km/hr, but I'm not sure what's going on with the 1219.2 feet deep. Is it 1/5 nautical mile? But that would be strange. [ Addendum 20070428: the explanation.](.)
Here's another delightful example:
The MiniC.A.T. is very cost-efficient to operate. According to MDI, it costs less than one dollar per 62.14 miles... Given the absence of combustion and the fact that the MiniC.A.T. runs on vegetable oil, oil changes are only necessary every 31,068 miles.(I should add that many of the hits for "62.14 miles" were perfectly legitimate. Many concerned 100-km bicycle races, or the conditions for winning the X-prize. In both cases the distance is in fact 62.14 miles, not 62.13 or 62.15, and the precision is warranted. But I digress.)(eesi.org.)
(Long ago there was a parody of the New York Times which included a parody sports section that announced "FOOTBALL TO GO METRIC". The article revealed that after the change, the end zones would be placed 91.44 meters apart...)
Anyway, similar knuckleheadedness occurs in the well-known value of 98.6 degrees Fahrenheit for normal human body temperature. Human body temperature varies from individual to individual, and by a couple of degrees over the course of the day, so citing the "normal" temperature to a tenth of a degree is ridiculous. The same thing happened here as with the 62.14-mile tsunami. Normal human body temperature was determined to be around 37 degrees Celsius, and then some knucklehead translated 37°C to 98.6°F instead of to 98°F.
When our daughter Katara was on the way, Lorrie and I took a bunch of classes on baby care. Several of these emphasized that the maximum safe spacing for the bars of a crib, rails of a banister, etc., was two and three-eighths inches. I was skeptical, and at one of these classes I was foolish enough to ask if that precision were really required: was two and one-half inches significantly less safe? How about two and seven-sixteenths inches? The answer was immediate and unequivocal: two and one-half inches was too far apart for safety; two and three-eighths inches is the maximum safe distance.
All the baby care books say the same thing. (For example...)
But two and three-eighths inches is 6.0325 cm, so draw your own conclusion about what happened here.
[ Addendum 20070430: 60.96 feet per second is nothing like 100 km/hr, and I have no idea why I said it was. The 60.96 feet per second appears to be a backwards conversion of 200 m/s to ft/s, multiplying by 3.048 instead of dividing. As Scott turner noted a few days ago, a similar error occurs in the conversion of meters to feet in the "1219.2 feet deep" clause. ]
[ Addendum 20220124: the proper spacing of crib slats ]
[Other articles in category /physics] permanent link
Sat, 21 Apr 2007
Degrees of algebraic numbers
An algebraic number x is said to have degree n if it is
the zero of some irreducible nth-degree polynomial P with
integer coefficients.
For example, all rational numbers have degree 1, since the rational number a/b is a zero of the first-degree polynomial bx - a. √2 has degree 2, since it is a zero of x2 - 2, but (as the Greeks showed) not of any first-degree polynomial.
It's often pretty easy to guess what degree some number has, just by looking at it. For example, the nth root of a prime number p has degree n. !!\sqrt{1 + \sqrt 2}!! has a square root of a square root, so it's fourth-degree number. If you write !!x = \sqrt{1 + \sqrt 2}!! then eliminate the square roots, you get x4 - 2x2 - 1, which is the 4th-degree polynomial satisfied by this 4th-degree number.
But it's not always quite so simple. One day when I was in high
school, I bumped into the fact that !!\sqrt{7 + 4 \sqrt 3}!!, which looks
just like a 4th-degree number, is actually a 2nd-degree number.
It's numerically equal to !!2 + \sqrt 3!!. At the time,
I was totally boggled. I couldn't believe it at first, and I had to
get out my calculator and calculate both values numerically to be sure
I wasn't hallucinating. I was so sure that the nested square
roots in 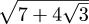 would force it to be
4th-degree.
would force it to be
4th-degree.
If you eliminate the square roots, as in the other example, you get
the 4th-degree polynomial
x4 - 14x2 + 1, which is satisfied
by . But unlike the previous
4th-degree polynomial, this one is reducible. It factors into
(x2 + 4x + 1)(x2 - 4x + 1). Since
is a zero of the polynomial, it
must be a zero of one of the two factors, and so it is
second-degree. (It is a zero of the second factor.)
I don't know exactly why I was so stunned to discover this. Clearly, the square of any number of the form a + b√c is another number of the same form (namely (a2 + b2c) + 2ab√c), so it must be the case that lots of a + b√c numbers must be squares of other such, and so that lots of !!\sqrt{a + b \sqrt c}!! numbers must be second-degree. I must have known this, or at least been capable of knowing it. Socrates says that the truth is within us, and we just don't know it yet; in this case that was certainly true. I think I was so attached to the idea that the nested square roots signified fourth-degreeness that I couldn't stop to realize that they don't always.
In the years since, I came to realize that recognizing the degree of an algebraic number could be quite difficult. One method, of course, is the one I used above: eliminate the radical signs, and you have a polynomial; then factor the polynomial and find the irreducible factor of which the original number is a root. But in practice this can be very tricky, even before you get to the "factor the polynomial" stage. For example, let x = 21/2 + 21/3. Now let's try to eliminate the radicals.
Proceeding as before, we do x - 21/3 = 21/2 and then square both sides, getting x2 - 2·21/3x + 22/3 = 2, and then it's not clear what to do next.
So we try the other way, starting with x - 21/2 = 21/3 and then cube both sides, getting x3 - 3·21/2x2 + 6x - 2·21/2 = 2. Then we move all the 21/2 terms to the other side: x3 + 6x - 2 = (3x2 + 2)·21/2. Now squaring both sides eliminates the last radical, giving us x6 + 12x4 - 4x3 + 36x2 - 24x + 4 = 18x4 + 12x2 + 8. Collecting the terms, we see that 21/2 + 21/3 is a root of x6 - 6x4 - 4x3 + 12x2 - 24x - 4. Now we need to make sure that this polynomial is irreducible. Ouch.
In the course of writing this article, though, I found a much better method. I'll work a simpler example first, √2 + √3. The radical-eliminating method would have us put x - √2 = √3, then x2 - 2√2x + 2 = 3, then x2 - 1 = 2√2x, then x4 - 2x2 + 1 = 8x2, so √2 + √3 is a root of x4 - 10x2 + 1.
The new improved method goes like this. Let x = √2 + √3. Now calculate powers of x:
| x0 = | 1 | |||
| x1 = | √2 + | √3 | ||
| x2 = | 2√6 + | 5 | ||
| x3 = | 11√2 + | 9√3 | ||
| x4 = | 20√6 + | 49 |
That's a lot of calculating, but it's totally mechanical.
All of the powers of x have the form a6√6 + a2√2 + a3√3 + a1. This is easy to see if you write p for √2 and q for √3. Then x = p + q and powers of x are polynomials in p and q. But any time you have p2 you replace it with 2, and any time you have q2 you replace it with 3, so your polynomials never have any terms in them other than 1, p, q, and pq.
This means that you can think of the powers of x as being vectors in a 4-dimensional vector space whose canonical basis is {1, √2, √3, √6}. Any four vectors in this space, such as {1, x, x2, x3}, are either linearly independent, and so can be combined to total up to any other vector, such as x4, or else they are linearly dependent and three of them can be combined to make the fourth. In the former case, we have found a fourth-degree polynomial of which x is a root, and proved that there is no simpler such polynomial; in the latter case, we've found a simpler polynomial of which x is a root.
To complete the example above, it is evident that {1, x, x2, x3} are linearly independent, but if you don't believe it you can use any of the usual mechanical tests. This proves that √2 + √3 has degree 4, and not less. Because if √2 + √3 were of degree 2 (say) then we would be able to find a, b, c such that ax2 + bx + c = 0, and then the x2, x1, and x0 vectors would be dependent. But they aren't, so we can't, so it isn't.
Instead, there must be a, b, c, and d such that x4 = ax3 + bx2 + cx + d. To find these we need merely solve a system of four simultaneous equations, one for each column in the table:
| 2 b | = | 20 |
| 11 a + c | = | 0 |
| 9 a + c | = | 0 |
| 5 b + d | = | 49 |
And we immediately get a=0, b=10, c=0, d=-1, so x4 = 10x2 - 1, and our polynomial is x4 - 10x2 + 1, as before.
Yesterday's draft of this article said:
I think [21/2 + 21/3] turns out to be degree 6, but if you try to work it out in the straightforward way, by equating it to x and then trying to get rid of the roots, you get a big mess. I think it turns out that if two numbers have degrees a and b, then their sum has degree at most ab, but I wouldn't even want to swear to that without thinking it over real carefully.Happily, I'm now sure about all of this. I can work through the mechanical method on it. Putting x = 21/2 + 21/3, we get:
| x0 = | [0 | 0 | 0 | 0 | 0 | 1] |
| x1 = | [0 | 0 | 0 | 1 | 1 | 0] |
| x2 = | [0 | 1 | 2 | 0 | 0 | 2] |
| x3 = | [3 | 0 | 0 | 6 | 2 | 2] |
| x4 = | [0 | 12 | 8 | 2 | 8 | 4] |
| x5 = | [20 | 2 | 10 | 20 | 4 | 40] |
| x6 = | [12 | 60 | 24 | 60 | 80 | 12] |
Where the vector [a, b, c, d, e, f] is really shorthand for a21/2·22/3 + b22/3 + c21/2·21/3 + d21/3 + e21/2 + f.
x0...x5 turn out to be linearly independent, almost by inspection, so 21/2 + 21/3 has degree 6. To express x6 as a linear combination of x0...x5, we set up the following equations:
| 20a | + 3c | = 12 | ||||
| 2a | + 12b | + d | = 60 | |||
| 10a | + 8b | + 2d | = 24 | |||
| 20a | + 2b | + 6c | + e | = 60 | ||
| 4a | + 8b | + 2c | + e | = 80 | ||
| 40a | + 4b | + 2c | + 2d | + f | = 12 |
Solving these gives [a, b, c, d, e, f]= [0, 6, 4, -12, 24, 4], so x6 = 6x4 + 4x3 - 12x2 + 24x + 4, and 21/2 + 21/3 is a root of x6 - 6x4 - 4x3 + 12x2 - 24x - 4, which is irreducible.
And similarly, using this method, one can calculate in a few minutes that 21/2 + 21/4 has degree 4 and is a root of x4 - 4x2 - 8x + 2.
I wish I had figured this out in high school; it would have delighted me.
[Other articles in category /math] permanent link
Sun, 15 Apr 2007
Happy birthday Leonhard Euler
Leonhard Euler, one of the greatest and most prolific mathematicians
ever to walk the earth, was born 300 years ago today in Basel,
Switzerland.
Euler named the constant e (not for himself; he used vowels for constants and had already used a for something else), and discovered the astonishing formula !!e^{ix} = \cos x + i \sin x!!, which is known as Euler's formula. A special case of this formula is the Euler identity: !!e^{i\pi} + 1 = 0!!.
I never really understood what was going on there until last year, when I read the utterly brilliant book Visual Complex Analysis, by Tristan Needham. This was certainly the best math book I read in all of 2006, and probably the best one I've read in the past five years. (Many thanks to Dan Schmidt for rcommending it.)
The brief explanantion is something like this: the exponential function ect is exactly the function that satisfies the differential equation df/dt = cf(t). That is, it is the function that describes the motion of a particle whose velocity is proportional to its position at all times.
Imagine a particle moving on the real line. If its velocity is proportional to its position, it will speed away from the origin at an exponentially increasing rate. Or, if the proportionality constant is negative, it will rapidly approach the origin, getting closer (but never quite reaching it) at an exponentially increasing rate.
Now, suppose we consider a particle moving on the complex plane instead of on the real line, again with velocity proportional to position. If the proportionality constant is real, the particle will speed away from the origin (or towards it, if the constant is negative), as before. But what if the proportionality constant is imaginary?
A proportionality constant of i means that the velocity of the particle is at right angles to the position, because multiplication by i in the complex plane corresponds to a counterclockwise rotation by 90°, as always. In this case, the path of the particle is a circle, and so its position as a function of t is described by something like cos t + i sin t. But this function must satisfy the differential equation also, with c = i, and we have Euler's formula.
Another famous and important formula named after Euler is also called Euler's formula, and states that for any simply-connected polyhedron with F faces, E edges, and V vertices, F - E + V = 2. For example, the cube has 6 faces, 12 edges, and 8 vertices, and indeed 6 - 12 + 8 = 2. The formula also holds for all planar graphs and is the fundamental result of planar graph theory.
Spheres in this case behave like planes, and graphs that cover spheres also satisfy F - E + V = 2. One then wonders whether the theorem holds for more complex surfaces, such as tori; this is equivalent to asking about polyhedra that have a single hole. In this case, the theorem is a little different, and the identity becomes F - E + V = 0.
It turns out that every surface S has a value χ(S), called the Euler characteristic, such that graphs on the surface all satisfy F - E + V = χ(S).
Euler also discovered that the sum of the first n terms of the harmonic series, 1 + 1/2 + 1/3 + ... + 1/n, is approximately log n. We might like to say that it becomes arbitrarily close to log n, as so many things do, but it does not. It is always a bit larger than log n, and you cannot make it as close as you want. The more terms you take, the closer the sum gets to log n + γ, where γ is approximately 0.577216. This γ is Euler's constant:
$$\gamma = \lim_{n\rightarrow\infty}\left({\sum_{i=1}^n {1\over i} - \ln n}\right)$$
This is one of those numbers that shows up all over the place, and is easy to calculate, but is a big fat mystery. Is it rational? Everyone would be shocked if it were, but nobody knows for sure.The Euler totient function φ(x) counts the number of integers less than x that have no divisors in common with x. It is of tremendous importance in combinmatorics and number theory. One of the most fundamental and astonishing facts about the totient function is Euler's theorem: aφ(n) - 1 is a multiple of n whenever a and n have no divisors in common. For example, since &phi(9) = 6, a6 - 1 is a multiple of 9, except when a is divisible by 3:
| 16 - 1 | = | 0· | 9. |
| 26 - 1 | = | 7· | 9. |
| 46 - 1 | = | 455· | 9. |
| 56 - 1 | = | 1736· | 9. |
| 76 - 1 | = | 13072· | 9. |
Euler's solution in 1736 of the "bridges of Königsberg" problem is often said to have begun the study of topology. It is also the source of the term "Eulerian path".
Wikipedia lists forty more items that are merely named for Euler. The list of topics that he discovered, invented, or contributed to would be far too large to actually construct.
Happy birthday, Leonhard Euler.
[Other articles in category /anniversary] permanent link
Thu, 12 Apr 2007
A security problem in a CGI program: addenda
Shell-less piping in Perl
In my previous article, I said:
Unfortunately, there is no easy way to avoid the shell when running a command that is attached to the parent process via a pipe. Perl provides open "| command arg arg arg...", which is what I used, and which is analogous to [system STRING], involving the shell. But it provides nothing analogous to [system ARGLIST], which avoids the shell. If it did, then I probably would have used it, writing something like this:Several people wrote to point out that, as of Perl 5.8.0, Perl does provide this, with a syntax almost identical to what I proposed:
open M, "|", $MAILER, "-fnobody\@plover.com", $addre;and the whole problem would have been avoided.
open M, "|-", $MAILER, "-fnobody\@plover.com", $addre;
Why didn't I use this? The program was written in late 2002, and Perl
5.8.0 was released in July 2002, so I expect it's just that I wasn't
familiar with the new feature yet. Why didn't I mention it in the
original article? As I said, I just got back from Asia, and I am
still terribly jetlagged.(Jet lag when travelling with a toddler is worse than normal jet lag, because nobody else can get over the jet lag until the toddler does.)
Jeff Weisberg also pointed out that even prior to 5.8.0, you can write:
open(F, "|-") || exec("program", "arg", "arg", "arg");
Why didn't I use this construction? I have run out of excuses.
Perhaps I was jetlagged in 2002 also.
RFC 822
John Berthels wrote to point out that my proposed fix, which rejects all inputs containing spaces, also rejects some RFC822-valid addresses. Someone whose address was actually something like "Mark Dominus"@example.com would be unable to use the web form to subscribe to the mailing list.Quite so. Such addresses are extremely rare, and people who use them are expected to figure out how to subscribe by email, rather than using the web form.
qmail
Nobody has expressed confusion on this point, but I want to expliticly state that, in my opinion, the security problem I described was entirely my fault, and was not due to any deficiency in the qmail mail system, or in its qmail-inject or qmail-queue components.Moreover, since I have previously been paid to give classes at large conferences on how to avoid exactly this sort of problem, I deserve whatever scorn and ridicule comes my way because of this.
Thanks to everyone who wrote in.
[Other articles in category /oops] permanent link
Wed, 11 Apr 2007
A security problem in a CGI program
<sarcasm>No! Who could possibly have predicted such a
thing?</sarcasm>
I was away in Asia, and when I got back I noticed some oddities in my mail logs. Specifically, Yahoo! was rejecting mail.plover.com's outgoing email. In the course of investigating the mail logs, I discovered the reason why: mail.plover.com had been relaying a ton of outgoing spam.
It took me a little while to track down the problem. It was a mailing list subscription form on perl.plover.com:
The form took the input email address and used it to manufacture an email message, requesting that that address be subscribed to the indicated lists:
my $MAILER = '/var/qmail/bin/qmail-inject';
...
for (@lists) {
next unless m|^perl-qotw[\-a-z]*|;
open M, "|$MAILER" or next;
print M "From: nobody\@plover.com\n";
print M "To: $_-subscribe-$addre\@plover.com\n";
print M "\nRequested by $ENV{REMOTE_ADDR} at ", scalar(localtime), "\n";
close M or next;
push @DONE, $_;
}
The message was delivered to the list management software, which
interpreted it as a request to subscribe, and generated an appropriate
confirmation reply. In theory, this doesn't open any new security
holes, because a malicious remote user could also forge an identical
message to the list management software without using the form.The problem is the interpolated $addre variable. The value of this variable is essentially the address from the form. Interpolating user input into a string like this is always fraught with peril. Daniel J. Bernstein has one of the most succinct explanantions of this that I have ever seen:
The essence of user interfaces is parsing: converting an unstructured sequence of commands, in a format usually determined more by psychology than by solid engineering, into structured data.In this case, I interpolated user data without quoting, and suffered the consequences.When another programmer wants to talk to a user interface, he has to quote: convert his structured data into an unstructured sequence of commands that the parser will, he hopes, convert back into the original structured data.
This situation is a recipe for disaster. The parser often has bugs: it fails to handle some inputs according to the documented interface. The quoter often has bugs: it produces outputs that do not have the right meaning. Only on rare joyous occasions does it happen that the parser and the quoter both misinterpret the interface in the same way.
When the original data is controlled by a malicious user, many of these bugs translate into security holes.
The malicious remote user supplied an address of the following form:
into9507@plover.com
Content-Transfer-Encoding: quoted-printable
Content-Type: text/plain
From: Alwin Bestor <Morgan@plover.com>
Subject: Enhance your love life with this medical marvel
bcc: hapless@example.com,recipients@example.com,of@example.net,
spam@example.com,...
Attention fellow males..
If you'd like to have stronger, harder and larger erections,
more power and intense orgasms, increased stamina and
ejaculatory control, and MUCH more,...
.
(Yes, my system was used to send out penis enlargement spam. Oh, the
embarrassment.) The address contained many lines of data, separated by CRNL, and a complete message header. Interpolated into the subscription message, the bcc: line caused the qmail-inject user ineterface program to add all the "bcc" addresses to the outbound recipient list.
Several thoughts occur to me about this.
User interfaces and programmatic interfaces
The problem would probably not have occurred had I used the qmail-queue progam, which provides a programmatic interface, rather than qmail-inject, which provides a user interface. I originally selected qmail-inject for convenience: it automatically generates Date and Message-ID fields, for example. The qmail-queue program does not try to parse the recipient information from the message header; it takes recipient information in an out-of-band channel.
Perl piped open is deficient
Perl's system and exec functions have two modes. One mode looks like this:
system "command arg arg arg...";
If the argument string contains shell metacharacters or certain other
constructions, Perl uses the shell to execute the command; otherwise
it forks and execs the command directly. The shell is the cause of
all sorts of parsing-quoting problems, and is best avoided in programs
like this one. But Perl provides an alternative:
system "command", "arg", "arg", "arg"...;
Here Perl never uses the shell; it always forks and execs the command
directly. Thus, system "cat *" prints the contents of all
the files in the current working directory, but system "cat",
"*" prints only the contents of the file named "*", if
there is one.qmail-inject has an option to take the envelope information from an out-of-band channel: you can supply it in the command-line arguments. I did not use this option in the original program, because I did not want to pass the user input through the Unix shell, which is what Perl's open FH, "| command args..." construction would have required.
Unfortunately, there is no easy way to avoid the shell when running a command that is attached to the parent process via a pipe. Perl provides open "| command arg arg arg...", which is what I used, and which is analogous to the first construction, involving the shell. But it provides nothing analogous to the second construction, which avoids the shell. If it did, then I probably would have used it, writing something like this:
open M, "|", $MAILER, "-fnobody\@plover.com", $addre;
and the whole problem would have been avoided.A better choice would have been to set up the pipe myself and use Perl's exec function to execute qmail-inject, which bypasses the shell. The qmail-inject program would always have received exactly one receipient address argument. In the event of an attack like the one above, it would have tried to send mail to into9507@plover.com^M^JContent-Transfer-Encoding:..., which would simply have bounced.
Why didn't I do this? Pure laziness.
qmail-queue more vulnerable than qmail-inject in this instance
Rather strangely, an partial attack is feasible with qmail-queue, even though it provides a (mostly) non-parsing interface. The addresses to qmail-queue are supplied to it on file descriptor 1 in the form:
Taddress1@example.com^@Taddress2@example.com^@Taddress3@example.com^@...^@
If my program were to talk to qmail-queue instead of to qmail-inject, the program would have
contained code that looked like this:
print QMAIL_QUEUE_ENVELOPE "T$addre\0";
qmail-queue parses only to the extent of dividing up its input at the ^@
characters. But even this little bit of parsing is a problem.
By supplying an appropriately-formed address string, a malicious user
could still have forced my program to send mail to many addresses. But still the recipient addresses would have been out of the content of the message. If the malicious user is unable to affect the content of the message body, the program is not useful for spamming.
But using qmail-queue, my program would have had to generate the To field itself, and so it would have had to insert the user-supplied address into the content of the message. This would have opened the whole can of worms again.
My program attacked specifically
I think some human put real time into attacking this particular program. There are bots that scour the web for email submission forms, and then try to send spam through them. Those bots don't successfully attack this program, because the recipient address is hard-wired. Also, the program refuses to send email unless at least one of the checkboxes is checked, and form-spam bots don't typically check boxes. Someone had to try some experiments to get the input format just so. I have logs of the experiments.A couple of days after the exploit was discovered, a botnet started using it to send spam; 42 different IP addresses sent requests. I fixed the problem last night around 22:30; there were about 320 more requests, and by 09:00 this morning the attempts to send spam stopped.
Perl's "taint" feature would not have prevented this
Perl offers a feature that is designed specifically for detecting and preventing exactly this sort of problem. It tracks which data are possibly under control of a malicious user, and whether they are used in unsafe operations. Unsafe operations include most file and process operations.One of my first thoughts was that I should have enabled the tainting feature to begin with. However, it would not have helped in this case. Although the user-supplied address would have been flagged as "tainted" and so untrustworthy; by extension, the email message string into which it was interpolated would have been tainted. But Perl does not consider writing a tainted string to a pipe to be an "unsafe" operation and so would not have signalled a failure.
The fix
The short-range fix to the problem was simple:
my $addr = param('addr');
$addr =~ s/^\s+//;
$addr =~ s/\s+$//;
...
if ($addr =~ /\s/) {
sleep 45 + rand(45);
print p("Sorry, addresses are not allowed to contain spaces");
fin();
}
Addresses are not allowed to contain whitespace, except leading or
trailing whitespace, which is ignored. Since whitespace inside an
address is unlikely to be an innocent mistake, the program waits
before responding, to slow down the attacker.
Summary
Dammit.[ Addendum 20070412: There is a followup article to this one. ]
[Other articles in category /oops] permanent link
Thu, 05 Apr 2007[ Note: because this article is in the oops section of my blog, I intend that you understand it as a description of a mistake that I have made. ]
Abhijit Menon-Sen wrote to me to ask for advice in finding the smallest triangular number that has at least 500 divisors. (That is, he wants the smallest n such that both n = (k2 + k)/2 for some integer k and also ν(n) ≥ 500, where ν(n) is the number of integers that divide n.) He said in his note that he believed that brute-force search would take too long, and asked how I might trim down the search.
The first thing that occurred to me was that ν is a multiplicative function, which means that ν(ab) = ν(a)ν(b) whenever a and b are relatively prime. Since n and n-1 are relatively prime, we have that ν(n(n-1)) = ν(n)·ν(n-1), and so if T is triangular, it should be easy to calculate ν(T). In particular, either n is even, and ν(T) = ν(n/2)·ν(n-1), or n is odd, and ν(T) = ν(n)·ν((n-1)/2).
So I wrote a program to run through all possible values of n, calculating a table of ν(n), and then the corresponding ν(n(n-1)/2), and then stopping when it found one with sufficiently large ν.
my $N = 1;
my $max = 0;
while (1) {
my $n = $N % 2 ? divisors($N) : divisors($N/2);
my $np1 = $N % 2 ? divisors(($N+1)/2) : divisors($N+1);
if ($n * $np1 > $max) {
$max = $n * $np1;
print "N=$N; T=", $N*($N+1)/2, "; nd()=$max\n";
}
last if $max >= 500;
$N++;
}
There may be some clever way to quickly calculate ν(n) in
general, but I don't know it. But if you have the prime factorization
of n, it's easy: if n =
p1a1p2a2...
then ν(n) = (a1 + 1)(a2
+ 1)... . This is a consequence of the multiplicativity of ν and
the fact that ν(pn) is clearly
n+1. Since I expected that n wouldn't get too big, I
opted to factor n and to calculate ν from the prime
factorization:
my @nd;
sub divisors {
my $n = shift;
return $nd[$n] if $nd[$n];
my @f = factor($n);
my $ND = 1;
my $cur = 0;
my $curct = 0;
while (@f) {
my $next = shift @f;
if ($next != $cur) {
$cur = $next;
$ND *= $curct+1;
$curct = 1;
} else {
$curct++;
}
}
$ND *= $curct+1;
return $ND;
}
Unix comes with a factor program that factors numbers pretty
quickly, so I used that:
sub factor {
my $r = qx{factor $_[0]};
my @f = split /\s+/, $r;
shift @f;
return @f;
}
This found the answer, 76,576,500, in about a minute and a half.
(76,576,500 = 1 + 2 + ... + 12,375, and has 576 factors.) I sent this
off to Abhijit.I was rather pleased with myself, so I went onto IRC to boast about my cleverness. I posed the problem, and rather than torment everyone there with a detailed description of the mathematics, I just said that I had come up with some advice about how to approach the problem that turned out to be good advice.
A few minutes later one of the gentlemen on IRC, who goes by "jeek", (real name T.J. Eckman) asked me if 76,576,500 was the right answer. I said that I thought it was and asked how he'd found it. I was really interested, because I was sure that jeek had no idea that ν was multiplicative or any of that other stuff. Indeed, his answer was that he used the simplest possible brute force search. Here's jeek's program:
$x=1; $y=0;
while(1) {
$y += $x++; $r=0;
for ($z=1; $z<=($y ** .5); $z++) {
if (($y/$z) == int($y/$z)) {
$r++;
if (($y/$z) != ($z)) { $r++; }
}
}
if ($r>499) {print "$y\n";die}
}
(I added whitespace, but changed nothing else.)In this program, the variable $y holds the current triangular number. To calculate ν(y), this program just counts $z from 1 up to √y, incrementing a counter every time it discovers that z is a divisor of y. If the counter exceeds 499, the program prints y and stops. This takes about four and a half minutes.
It takes three times as long, but uses only one-third the code. Beginners may not see this as a win, but it is a huge win. It is a lot easier to reduce run time than it is to reduce code size. A program one-third the size of another is almost always better—a lot better.
In this case, we can trim up some obvious inefficiencies and make the program even smaller. For example, the tests here can be omitted:
if (($y/$z) != ($z)) { $r++; }
It can yield false only if
y is the square of z. But y is triangular, and
triangular numbers are never square. And we can optimize away the
repeated square root in the loop test, and use a cheaper and simpler
$y % $z == 0 divisibility test in place of the complicated one.
while(1) {
$y += $x++; $r=0;
for $z (1 .. sqrt($y)) {
$y % $z == 0 and $r+=2;
}
if ($r>499) {print "$x $y\n";die}
}
The program is now one-fifth the size of mine and runs in 75
seconds. That is, it is now smaller and faster than mine.This shows that jeek's approach was the right one and mine was wrong, wrong, wrong. Simple programs are a lot easier to speed up than complicated ones. And I haven't even consider the cost of the time I wasted writing my complicated program when I could have written Jeek's six-liner that does the same thing.
So! I had to write back to my friend to tell him that my good advice was actually bad advice.
The sawed-off shotgun wins again!
[ Addendum 20070405: Robert Munro pointed out an error in the final version of the program, which I have since corrected. ]
[ Addendum 20070405: I said that triangular numbers are never square, which is manifestly false, since 1 is both, as is 36. I should have remembered this, since some time in the past three years I investigated this exact question and found the answer. But it hardly affects the program. The only way it could cause a failure is if there were a perfect square triangular number with exactly 499 factors; such a number would be erroneously reported as having 500 factors instead. But the program reports a number with 576 factors instead. Conceivably this could actually be a misreported perfect square with only 575 factors, but regardless, the reported number is correct. ]
[ Addendum 20060617: I have written an article about triangular numbers that are also square. ]
[Other articles in category /oops] permanent link