Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
Subtopics:
| Mathematics | 250 |
| Programming | 102 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Sun, 01 Jun 2008
Addenda to recent articles 200805
- Regarding the bicameral mind
theory put forth in Julian Jaynes' book The Origin of
Consciousness in the breakdown of the Bicameral Mind, Carl
Witty informs me that the story "Sour Note on Palayata", by James
Schmitz, features a race of bicameral aliens whose mentality is
astonishingly similar to the bicameral mentality postulated by Julian
Jaynes. M. Witty describes it as follows:
The story features a race of humanoid aliens with a "public" and a "private" mind. The "public" mind is fairly stupid, and handles all interactions with the real world; and the "private" mind is intelligent and psychic. The private mind communicates psychically with the private minds of other members of the race, but has only limited influence over the public mind; this influence manifests as visions and messages from God.
This would not be so remarkable, since Jaynes' theories have been widely taken up by some science fiction authors. For example, they appear in Neal Stephenson's novel Snow Crash, and even more prominently in his earlier novel The Big U, so much so that I wondered when reading it how anyone could understand it without having read Jaynes first. But Schmitz's story was published in 1956, twenty years before the publication of The Origin of Consciousness. - Also in connection with Jaynes: I characterized his theory as
"either a work of profound genius, or of profound crackpottery". I
should have mentioned that this
characterization was not lost on Jaynes himself. In his book, he
referred to his own theory as "preposterous".
- Many people wrote in with more commentary about my articles on
artificial Finnish
[1]
[2]:
- I had said that "[The one-letter word 'i'] appears in my sample
in connection with Sukselaisen
I hallitus, whatever that is". Several people
explained that this "I" is actually a Roman numeral 1, denoting the ordinal number
"first", and that Sukselaisen
I hallitus is the first government headed by V. J. Sukselaisen.
I had almost guessed this—I saw "Sukselaisen I" in the source material and guessed that the "I" was an ordinal, and supposed that "Sukselaisen I" was analogous to "Henry VIII" in English. But when my attempts to look up the putative King Sukselaisen I met with failure, and I discovered that "Sukselaisen I" never appeared without the trailing "hallitus", I decided that there must be more going on than I had supposed, as indeed there was. Thanks to everyone who explained this.
- Marko Heiskanen says that the (fictitious) word
yhdysvalmistämistammonit is "almost correct", at least up to the
nonsensical plural component "tammonit". The vowel harmony failure
can be explained away because compound words in Finnish do not respect the
vowel harmony rules anyway.
- Several people objected to my program's generation of the word
"klee": Jussi Heinonen said "Finnish has quite few words that begin with
two consonants", and Jarkko Hietaniemi said "No word-initial "kl":s
possible in native Finnish words". I checked, and my sample Finnish
input contains "klassisesta", which Jarkko explained was a loanword,
I suppose from Russian.
Had I used a larger input sample, oddities like "klassisesta" would have had less influence on the output.
- I acquired my input sample by selecting random articles from
Finnish Wikipedia, but my random sampling was rather unlucky, since it
included articles about Mikhail Baryshnikov (not Finnish), Dmitry Medvevev
(not Finnish), and Los Angeles (also not Finnish). As a result, the
input contained too many strange un-Finnish letters, like B, D, š, and
G, and so therefore did the output. I could have been more careful in
selecting the input data, but I didn't want to take the time.
Medvedev was also the cause of that contentious "klassisesta", since, according to Wikipedia, "Medvedev pitää klassisesta rock-musiikista". The Medvedev presidency is not even a month old and already he has this international incident to answer for. What catastrophes could be in the future?
- Another serious problem with my artificial Finnish is that the
words were too long; several people complained about this, and the
graph below shows the problem fairly clearly:
The x-axis is word length, and the y-axis is frequency, on a logarithmic scale, so that if 1/100 of the words have 17 letters, the graph will include the point (17, -2). The red line, "in.dat", traces the frequencies for my 6 kilobyte input sample, and the blue line, "pseudo.dat", the data for the 1000-character sample I published in the article. ("Ävivät mena osakeyhti...") The green line, "out.dat", is a similar trace for a 6 kb N=3 text I generated later. The long right tail is clearly visible. My sincere apologies to color-blind (and blind) readers.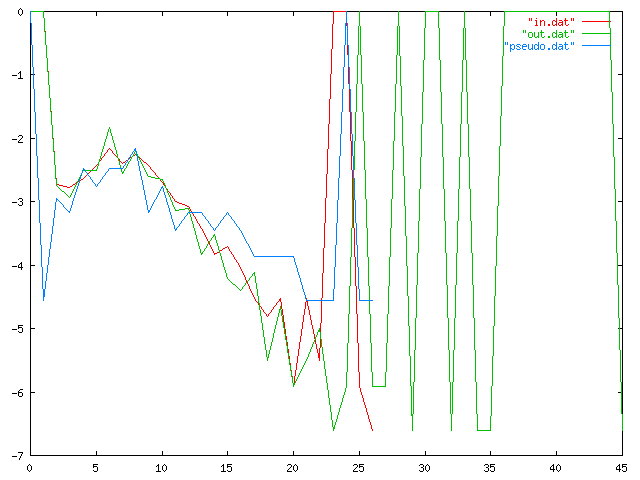
I am not sure exactly what happened here, but I can guess. The Markov process has a limited memory, 3 characters in this case, so in particular is has essentially no idea how long the words are that it is generating. This means that the word lengths that it generates should appear in roughly an exponential distribution, with the probability of a word of length N approximately equal to !!\lambda e^{-\lambda N} !!, where 1/λ is the mean word length.
But there is no particular reason why word lengths in Finnish (or any other language) should be exponentially distributed. Indeed, one would expect that the actual distribution would differ from exponential in several ways. For example, extremely short words are relatively uncommon compared with what the exponential distribution predicts. (In the King James Bible, the most common word length is 3, then 4, with 1 and 8 tied for a distant seventh place.) This will tend to push the mean rightwards, and so it will skew the Markov process' exponential distribution rightwards as well.
I can investigate the degree to which both real text and Markov process output approximate a theoretical exponential distribution, but not today. Perhaps later this month.
My thanks again to the many helpful Finnish speakers who wrote in on these and other matters, including Marko Heiskanen, Shae Erisson, Antti-Juhani Kaijanaho, Ari Loytynoja, Ilmari Vacklin, Jarkko Hietaniemi, Jussi Heinonen, Nuutti-Iivari Meriläinen, and any others I forgot to mention.
- I had said that "[The one-letter word 'i'] appears in my sample
in connection with Sukselaisen
I hallitus, whatever that is". Several people
explained that this "I" is actually a Roman numeral 1, denoting the ordinal number
"first", and that Sukselaisen
I hallitus is the first government headed by V. J. Sukselaisen.
- My explanation of Korean
vowel harmony rules in that article is substantively correct, but
my description of the three vowel groups was badly wrong. I have
apparently forgotten most of the tiny bit I once knew about Middle
Korean. For a correct description, see
the Wikipedia article
or
this
blog post. My thanks to the anonymous author of the blog post for
his correction.
- Regarding the
transitivity of related-by-blood-ness, Toth András told me about a
(true!) story from the life of Hungarian writer Karinthy
Frigyes:
Karinthy Frigyes got married two times, the Spanish flu epidemic took his first wife away. A son of his was born from his first marriage, then his second wife brought a boy from his previous husband, and a common child was born to them. The memory of this the reputed remark: "Aranka, your child and my child beats our child."
(The original Hungarian appears on this page, and the surprisingly intelligible translation was provided by M. Toth and the online translation service at webforditas.hu. Thank you, M. Toth.
- Chung-chieh Shan tells me that the missing
document-viewer feature that I described is available in recent
versions of xdvi. Tanaeem M. Moosa says
that it is also available in Adobe Reader
8.1.2.
[Other articles in category /addenda] permanent link