Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
Subtopics:
| Mathematics | 249 |
| Programming | 100 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Thu, 11 May 2017
I'm almost done with anagrams. For now, anyway. I think. This article is to mop up the last few leftover anagram-related matters so that I can put the subject to rest.
(Earlier articles: [1] [2] [3] [•] )
Code is available
Almost all the code I wrote for this project is available on Github.
The documentation is not too terrible, I think.
Anagram lists are available
I have also placed my scored anagram lists on my web site. Currently available are:
Original file from the 1990s. This contains 23,521 anagram pairs, the results of my original scoring algorithm on a hand-built dictionary that includes the Unix spellcheck dictionary (
/usr/dict/words), the Webster's Second International Dictionary word list, and some lexicons copied from a contemporaneous release of WordNet. This file has been in the same place on my web site since 1997 and is certainly older than that.New file from February. Unfortunately I forget what went into this file. Certainly everything in the previous file, and whatever else I had lying around, probably including the Moby Word Lists. It contains 38,333 anagram pairs.
Very big listing of Wikipedia article titles. (11 MB compressed) I acquired the current list of article titles from the English Wikipedia; there are around 13,000,000 of these. I scored these along with the other lexicons I had on hand. The results include 1,657,150 anagram pairs. See below for more discussion of this.
!!Con talk
On Saturday I gave a talk about the anagram-scoring work at !!Con in New York. The talk was not my best work, since I really needed 15 minutes to do a good job and I was unwilling to cut it short enough. (I did go overtime, which I deeply regret.) At least nobody came up to me afterward and complained.
Talk materials are on my web site and I will link other talk-related stuff from there when it becomes available. The video will be available around the end of May, and the text transcript probably before that.
[ Addendum 20170518: The video is available thanks to Confreaks. ]
Both algorithms are exponential
The day after the talk an attendee asked me a very good question: why did I say that one algorithm for scoring algorithms was better than the other, when they are both exponential? (Sorry, I don't remember who you were—if you would like credit please drop me a note.)
The two algorithms are:
A brute-force search to construct all possible mappings from word A to word B, and then calculate the minimum score over all mappings (more details)
The two words are converted into a graph; we find the maximum independent set in the graph, and the size of the MIS gives the score (more details)
The answer to this excellent question begins with: just because two problems are both hard doesn't mean they are equally hard. In this case, the MIS algorithm is better for several reasons:
The number of possible mappings from A to B depends on the number of repeated letters in each word. For words of length n, in the worst case this is something like !! n! !!. This quantity is superexponential; it eventually exceeds !! c^n !! for all constants !!c!!. The naïve algorithm for MIS is only exponential, having !!c=2!!.
The problem size for the mapping algorithm depends on the number of repeated letters in the words. The problem size for the MIS algorithm depends on the number of shared adjacent letter pairs in the two words. This is almost always much smaller.
There appears to be no way to score all the mappings without constructing the mappings and scoring them. In contrast, MIS is well-studied and if you don't like the obvious !!2^n!! algorithm you can do something cleverer that takes only !!1.22^n!!.
Branch-and-bound techniques are much more effective for the MIS problem, and in this particular case we know something about the graph structure, which can be exploited to make them even more effective. For example, when calculating the score for
chromophotolithograph photochromolithographmy MIS implementation notices the matching trailing
olithographparts right away, and can then prune out any part of the MIS search that cannot produce a mapping with fewer than 11 chunks. Doing this in the mapping-generating algorithm is much more troublesome.
Stuff that didn't go into the talk
On Wednesday I tried out the talk on Katara and learned that it was around 75% too long. I had violated my own #1 content rule: “Do not begin with a long introduction”. My draft talk started with a tour of all my favorite anagrams, with illustrations. Included were:
“Please”
 and “asleep” and “elapse”.
and “asleep” and “elapse”.“Spectrum”
 and “crumpets”
and “crumpets”
 ; my wife noticed this while
we were at a figure-skating event at the Philadelphia
Spectrum, depicted
above.
; my wife noticed this while
we were at a figure-skating event at the Philadelphia
Spectrum, depicted
above.“English”
 and “shingle”
and “shingle”  ; I came up with this looking at a
teabag while at breakfast with my wife's parents. This prompted my
mother-in-law to remark that it must be hard to always be thinking
about such things—but then she admitted that when she sees long
numerals she always checks them for divisibility by 9.
; I came up with this looking at a
teabag while at breakfast with my wife's parents. This prompted my
mother-in-law to remark that it must be hard to always be thinking
about such things—but then she admitted that when she sees long
numerals she always checks them for divisibility by 9.“Soupmaster”
 and
and
 “mousetraps”. The
picture here is not perfect. I wanted a picture of the Soupmaster
restaurant that was at the Liberty Place food court in Philadelphia,
but I couldn't find one.
“mousetraps”. The
picture here is not perfect. I wanted a picture of the Soupmaster
restaurant that was at the Liberty Place food court in Philadelphia,
but I couldn't find one.I also wanted to show the back end of a Honda Integra and a picture of granite, but I couldn't find a good picture of either one before I deleted them from the talk. (My wife also gets credit for noticing this one.) [ Addendum 20170515: On the road yesterday I was reminded of another one my wife noticed: “Pontiac” / “caption”. ]
Slide #1 defines what anagrams actually are, with an example of “soapstone” / “teaspoons”. I had originally thought I might pander to the left-wing sensibilities of the !!Con crowd by using the example “Donald Trump” / “Lord Dampnut” and even made the illustration. I eventually rejected this for a couple of reasons. First, it was misleading because I only intended to discuss single-word anagrams. Second, !!Con is supposed to be fun and who wants to hear about Donald Trump?
But the illustration might be useful for someone else, so here it is. Share and enjoy.

After I rejected this I spent some time putting together an alternative, depicting “I am Lord Voldemort” / “Tom Marvolo Riddle”. I am glad I went with the soapstone teaspoons instead.
People Magazine
Clearly one important ingredient in finding good anagrams is that they should have good semantics. I did not make much of an effort in this direction. But it did occur to me that if I found a list of names of well-known people I might get something amusing out of it. For example, it is well known that “Britney Spears” is an anagram of “Presbyterians” which may not be meaningful but at least provides something to mull over.
I had some trouble finding a list of names of well-known people, probably because I do not know where to look, but I did eventually find a list of a few hundred on the People Magazine web site so I threw it into the mix and was amply rewarded:
| Cheryl Burke | Huckleberry |

| 
|
I thought Cheryl Burke was sufficiently famous, sufficiently recently, that most people might have heard of her. (Even I know who she is!) But I gave a version of the !!Con talk to the Philadelphia Perl Mongers the following Monday and I was the only one in the room who knew. (That version of the talk took around 75 minutes, but we took a lot of time to stroll around and look at the scenery, much of which is in this article.)
I had a struggle finding the right Cheryl Burke picture for the !!Con talk. The usual image searches turned up lots of glamour and fashion pictures and swimsuit pictures. I wanted a picture of her actually dancing and for some reason this was not easy to find. The few I found showed her from the back, or were motion blurred. I was glad when I found the one above.
Wikipedia
A few days before the !!Con talk my original anagram-scoring article hit #1 on Hacker News. Hacker News user Pxtl suggested using the Wikipedia article title list as an input lexicon. The article title list is available for download from the Wikimedia Foundation so you don't have to scrape the pages as Pxtl suggested. There are around 13 million titles and I found all the anagrams and scored them; this took around 25 minutes with my current code.
The results were not exactly disappointing, but neither did they deliver anything as awesomely successful as “cinematographer” / “megachiropteran”. The top scorer by far was “ACEEEFFGHHIILLMMNNOORRSSSTUV”, which is the pseudonym of 17th-century German writer Hans Jakob Christoffel von Grimmelshausen. Obviously, Grimmelshausen constructed his pseudonym by sorting the letters of his name into alphabetical order.
(Robert Hooke famously used the same scheme to claim priority for discovery of his spring law without actually revealing it. He published the statement as “ceiiinosssttuv” and then was able to claim, two years later, that this was an anagram of the actual law, which was “ut tensio, sic vis”. (“As the extension, so the force.”) An attendee of my Monday talk wondered if there is some other Latin phrase that Hooke could have claimed to have intended. Perhaps someone else can take the baton from me on this project.)
Anyway, the next few top scorers demonstrate several different problems:
21 Abcdefghijklmnopqrstuvwxyz / Qwertyuiopasdfghjklzxcvbnm
21 Abcdefghijklmnopqrstuvwxyz / Qwertzuiopasdfghjklyxcvbnm
21 Ashland County Courthouse / Odontorhynchus aculeatus
21 Daniel Francois Malherbe / Mindenhall Air Force Base
20 Christine Amongin Aporu / Ethnic groups in Romania
20 Message force multiplier / Petroleum fiscal regimes
19 Cholesterol lowering agent / North West Regional College
19 Louise de Maisonblanche / Schoenobius damienella
19 Scorpaenodes littoralis / Steroidal spirolactones
The “Qwerty” ones are intrinsically uninteresting and anyway we could have predicted ahead of time that they would be there. And the others are just sort of flat. “Odontorhynchus aculeatus” has the usual problems. One can imagine that there could be some delicious irony in “Daniel Francois Malherbe” / “Mindenhall Air Force Base” but as far as I can tell there isn't any and neither was Louise de Maisonblanche killed by an S. damienella. (It's a moth. Mme de Maisonblanche was actually killed by Variola which is not an anagram of anything interesting.)
Wikipedia article titles include many trivial variations. For example, many people will misspell “Winona Ryder” as “Wynona Rider”, so Wikipedia has pages for both, with the real article at the correct spelling and the incorrect one redirecting to it. The anagram detector cheerfully picks these up although they do not get high scores. Similarly:
- there are a lot of articles about weasels that have alternate titles about “weasles”
- there are a lot of articles about the United States or the United Kingdom that have alternate titles about the “Untied States” or the “Untied Kingdom”
- Articles about the “Center for” something or other with redirects to (or from) the “Centre for” the same thing.
- There is an article about “Major professional sports leagues in Canada and the United States” with a redirect from “Major professional sports leagues in the United States and Canada”.
- You get the idea.
The anagram scorer often had quite a bit of trouble with items like these because they are long and full of repeated letter pairs. The older algorithm would have done even worse. If you're still wondering about the difference between two exponential algorithms, some of these would make good example cases to consider.
As I mentioned above you can download the Wikipedia anagrams from my web site and check for yourself. My favorite item so far is:
18 Atlantis Casino Resort Spa / Carter assassination plot
Romania
Some words appear with surprising frequency and I don't know why. As I mentioned above one of the top scorers was “Ethnic groups in Romania” and for some reason Romania appears in the anagram list over and over again:
20 Christine Amongin Aporu / Ethnic groups in Romania
17 List of Romanian actors / Social transformation
15 Imperial Coronation / Romanian riot police
14 Rakhine Mountains / Romanians in the UK
14 Mindanao rasbora / Romanians abroad
13 Romanian poets / ramosopinnate
13 Aleuron carinatum / Aromanian culture
11 Resita Montana / Romanian state
11 Monte Schiara / The Romaniacs
11 Monetarianism / Romanian Times
11 Marion Barnes / Romanian Serb
11 Maarsen railway station / Romanian State Railways
11 Eilema androconia / Nicolae de Romania
11 Ana Maria Norbis / Arabs in Romania
( 170 more )
Also I had never thought of this before, but Romania appears in this unexpected context:
09 Alicia Morton / Clitoromania
09 Carinito Malo / Clitoromania
(Alicia Morton played Annie in the 1999 film. Carinito Malo is actually Cariñito Malo. I've already discussed the nonequivalence of “n” and “ñ” so I won't beat that horse again.)
Well, this is something I can investigate. For each string of letters, we have here the number of Wikipedia article titles in which the string appears (middle column), the number of anagram pairs in which the string appears (left column; anagrams with score less than 6 are not counted) and the quotient of the two (right column).
romania 110 4106 2.7%
serbia 109 4400 2.5%
croatia 68 3882 1.8%
belarus 24 1810 1.3%
ireland 140 11426 1.2%
andorra 7 607 1.2%
austria 60 5427 1.1%
russia 137 15944 0.9%
macedonia 28 3167 0.9%
france 111 14785 0.8%
spain 64 8880 0.7%
slovenia 18 2833 0.6%
wales 47 9438 0.5%
portugal 17 3737 0.5%
italy 21 4353 0.5%
denmark 19 3698 0.5%
ukraine 12 2793 0.4%
england 37 8719 0.4%
sweden 11 4233 0.3%
scotland 16 4945 0.3%
poland 22 6400 0.3%
montenegro 4 1446 0.3%
germany 16 5733 0.3%
finland 6 2234 0.3%
albania 10 3268 0.3%
slovakia 3 1549 0.2%
norway 9 3619 0.2%
greece 10 8307 0.1%
belgium 3 2414 0.1%
switzerland 0 5439 0.0%
netherlands 1 3522 0.0%
czechia 0 75 0.0%
As we see, Romania and Serbia are substantially ahead of the others.
I suspect that it is a combination of some lexical property (the
interesting part) and the relatively low coverage of those countries
in English Wikipedia. That is, I think if we were to identify the
lexical component, we might well find that russia has more of it,
but scores lower than romania because Russia is much more important.
My apologies if I
accidentally omitted your favorite European country.
[ Oh, crap, I just realized I left out Bosnia. ]
Lesbians
Another one of the better high scorers turns out to be the delightful:
16 Lesbian intercourse / Sunrise Celebration
“Lesbian”, like “Romania”, seems to turn up over and over; the next few are:
11 Lesbian erotica / Oreste Bilancia
11 Pitane albicollis / Political lesbian
12 Balearic islands / Radical lesbians
12 Blaise reaction / Lesbian erotica
(43 more)
Wikipedia says:
The Blaise reaction is an organic reaction that forms a β-ketoester from the reaction of zinc metal with a α-bromoester and a nitrile.
A hundred points to anyone who can make a genuinely funny joke out of this.
Oreste Bilancia is an Italian silent-film star, and Pitane albicollis is another moth. I did not know there were so many anagrammatic moths. Christian Bale is an anagram of Birthana cleis, yet another moth.
[ Addendum 20220227: Sean Carney has applied my method to the headwords from Urban Dictionary and says “even though it doesn’t score quite as well, in my mind, the clear winner is genitals be achin / cheating lesbian”. ]
I ran the same sort of analysis on lesbian as on romania, except
that since it wasn't clear what to compare it to, I picked a bunch of
random words.
nosehair 3 3 100.0%
margarine 4 16 25.0%
penis 95 573 16.6%
weasel 11 271 4.1%
phallus 5 128 3.9%
lesbian 26 863 3.0%
center 340 23969 1.4%
flowers 14 1038 1.3%
trumpet 6 487 1.2%
potato 10 941 1.1%
octopus 4 445 0.9%
coffee 12 1531 0.8%
It seems that lesbian appears with unusually high but not remarkably
high frequency. The unusual part is its participation in so many
anagrams with very high scores. The outstanding item here is
penis. (The top two being rare outliers.) But penis still wins
even if I throw away anagrams with scores less than 10 (instead of
less than 6):
margarine 1 16 6.2%
penis 13 573 2.3%
lesbian 8 863 0.9%
trumpet 2 487 0.4%
flowers 4 1038 0.4%
center 69 23969 0.3%
potato 2 941 0.2%
octopus 1 445 0.2%
coffee 1 1531 0.1%
weasel 0 271 0.0%
phallus 0 128 0.0%
nosehair 0 3 0.0%
Since I'm sure you are wondering, here are the anagrams of margarine
and nosehair:
07 Nosehair / Rehsonia
08 Aso Shrine / Nosehairs
09 Nosehairs / hoariness
04 Margaret Hines / The Margarines
07 Magerrain / margarine
07 Ramiengar / margarine
08 Rae Ingram / margarine
11 Erika Armstrong / Stork margarine
I think “Margaret Hines” / “The Margarines” should score more than 4, and that this exposes a defect in my method.
Acrididae graphs
Here is the graph constructed by the MIS algorithm for the pair “acrididae” / “cidaridae”, which I discussed in an earlier article and also mentioned in my talk.
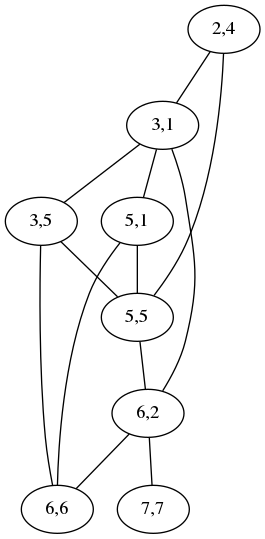
Each maximum independent set in this graph corresponds to a minimum-chunk mapping between “acrididae” and “cidaridae”. In the earlier article, I claimed:
This one has two maximum independent sets
which is wrong; it has three, yielding three different mappings with five chunks:

| 
| 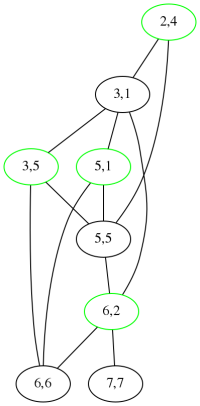
|

| 
| 
|
My daughter Katara points out that the graphs above resemble grasshoppers. My Gentle Readers will no doubt recall that acrididae is the family of grasshoppers, comprising around 10,000 species. I wanted to find an anagram “grasshopper” / “?????? graph”. There are many anagrams of “eoprs” and “eoprss” but I was not able to find anything good. The best I could do was “spore graphs”.
Thank you, Gentle Readers, for taking this journey with me. I hope nobody walks up to me in the next year to complain that my blog does not feature enough anagram-related material.
[ Addendum 20230423: A discussion on LanguageHat of the original article includes the interesting Russian pair австралопитек / ватерполистка. австралопитек is an Australopithecus. ватерполистка is a female water polo player. ]
[Other articles in category /lang] permanent link
Mon, 08 May 2017
An anagrammatic cautionary tale

I previously claimed that “cinematographer” / “megachiropteran” was the best anagram in English. Scoring all the anagrams in the list of 13 million Wikipedia article titles did not refute this, but it did reveal that “cinematographer” is also an anagram of “Taichang Emperor”.
The Taichang Emperor (泰昌) lived from 1582 to 1620 and was the 14th emperor of the Ming Dynasty. His reign as emperor lasted only 29 days, after which he died of severe diarrhea. Wikipedia says:
According to non-official primary sources, the Taichang Emperor's illness was brought about by excessive sexual indulgence after he was presented with eight maidens by Lady Zheng.
To counteract the diarrhea, the emperor took a “red pill” offered to him by a court official:
It was recorded in official Ming histories that the Taichang Emperor felt much better after taking the red pill, regained his appetite and repeatedly praised Li Kezhuo as a "loyal subject". That same afternoon, the emperor took a second pill and was found dead the next morning.
Surely this tale of Ming China has something to teach us even today.
[Other articles in category /misc] permanent link