Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFM |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 246 |
| Programming | 100 |
| Language | 95 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Thu, 19 Oct 2006
Boring answers to Powell's questions
A while back I answered some questions for Powell's City of Books web site. I
didn't know they had posted the answers until it was brought to my
attention by John Gabriele. Thank you, John.
They sent fifteen questions and asked me to pick at least five. I had a lot of trouble finding five of their questions that I wanted to answer. Most of the questions were not productive of interesting answers; I had to work hard to keep my answers from being super-dull.
The non-super-dull answers are on Powell's site. Here are the questions I didn't answer, with their super-dull answers:
- Have you ever taken the Geek Test? How did you rate?
Hardly anyone seems to answer this question, and really, who cares? Except that Sir Roger Penrose said something like "There's a Geek Test?".
I did take it once, but I forget how I scored. But if you read this blog, you can probably extrapolate: high on math, science, and programming. But really, who cares? Telling someone else about your geek test score is even more boring than telling them about your dreams.
- What do you do for relaxation?
I didn't answer this one because my answer seemed so uninteresting. I program. I read a lot; unlike most people who read a lot, I read a lot of different things. Sometimes I watch TV. I go for walks and drive the car.
One thing I used to do when I was younger was the "coffee trick". I'd go to an all-night diner with pens and a pad of paper and sit there drinking coffee all night and writing down whatever came out of my caffeine-addled brain. I'm too old for that now; it would make me sick.
- What's your favorite blog right now?
I answered this one for Powell's, and cited my own blog and Maciej Ceglowski's. But if I were answering the question today I would probably mention What Jeff Killed. Whenever a new What Jeff Killed post shows up in the aggregator, I get really excited. "Oh, boy!" I say. "I can't wait to see What Jeff Killed today!".
It occurs to me that just that one paragraph could probably give plenty of people a very clear idea of what I'm like, at least to the point that they would be able to decide they didn't want to know me.
- Douglas Adams or Scott Adams?
I think they're both boring. But I wasn't going to say so in my Powell's interview.
- What was your favorite book as a kid?
This should have been easy to answer, but none of the books I thought of seemed particularly revealing. When I was in sixth grade my favorite book was "The Hero from Otherwhere," by Jay Williams. (He also wrote the Danny Dunn books.) A few years back Andrew Plotkin posted on rec.arts.sf.written that he had recently read this, and that it occurred to him that it might have been his favorite book, had he read it in sixth grade, and had anyone had that experience. I wasn't the only one who had.
I reread it a few years ago and it wasn't that good anymore.
Robertson Davies writes about the awful juvenile-fiction magazines that he loved when he was a juvenile. Yes, they were terrible, but they fed something in him that needed to be fed. I think a lot of the books we love as children are like that.
- What new technology do you think may actually have the potential
for making people's lives better?
I couldn't think of any way to answer this question that wouldn't be really boring. That probably says a lot more about me than about the question. I thought about gene therapy, land mine detection, water purification. But I don't personally have anything to do with those things, so it would just be a rehash of what I read in some magazine. And what's the point of reading an interview with an author who says, "Well, I read in Newsweek..."?
- If you could be reincarnated for one day to live the life of any
scientist or writer, who would you choose and why?
This seems like it could have been interesting, but I couldn't figure out what to do with it. I might like to be Galileo, or to know what it's like to be Einstein, but that's not what the question says; it says that I'm me, living the life of Galileo or Einstein. But why would I want to do that? If I'm living the life of Einstein, that means I get to get up in the morning, go to an office in Zurich or Princeton, and sit behind a desk for eight hours, wishing I was smart enough to do Einstein's job.
Some writers and scientists had exciting lives. I could be reincarnated as Evariste Galois, who was shot to death in a duel. That's not my idea of a good time.
I once knew a guy who said he'd like to be David Lee Roth for one day, so that he could have sex with a groupie. Even if I wanted to have sex with a groupie, the question ("scientist or writer") pretty much rules out that form of entertainment. I suppose there's someone in the world who would want to be Pierre Curie, so that he know what it was like to fuck Marie Curie. That person isn't me.
- What are some of the things you'd like your computer to do that it
cannot now do?
I came really close to answering this question. I had an answer all written. I wrote that I wanted the computer to be able to manufacture pornography on demand to the user's specification: if they asked for a kneecap fetish movie featuring Celine Dion and an overalls-wearing midget, it should be able to do that.
Then I came to my senses and I realized I didn't want that answer to appear on my interview on the Powell's web site.
But it'll happen, you wait and see.
I also said I'd settle for having the computer discard spam messages before I saw them. I think the porn thing is a lot more likely.
- By the end of your life, where do you think humankind will be in
terms of new science and technological advancement?
First I was stumped on this one because I don't know when the end of my life will be. I could be crushed in a revolving door next week, right?
And assuming that I'll live another thirty years seems risky too. I'm hoping for a medical breakthrough that will prolong my life indefinitely. I expect it'll be along sooner or later. So my goal is to stay alive and healthy long enough to be able to take advantage of it when it arrives.
Some people tell me they don't want to be immortal, that they think they would get bored. I believe them. People are bored because they're boring. Let them die; I won't miss them. I know exactly what I would do with immortality: I would read every book in the library.
A few months ago I was visiting my mother, and she said that as a child I had always wanted to learn everything, and that it took me a long time to realize that you couldn't learn everything.
I got really angry, and I shouted "I'm not done yet!"
Well, even assuming that I live another thirty years, I don't think I can answer the question. When I was a kid my parents would go to the bank to cash a check. We got seven channels on the TV, and that was more than anyone else; we lived in New York. Nobody owned a computer; few people even owned typewriters. Big companies stored records on microfiche. The only way to find out what the law was was to go to the library and pore over some giant dusty book for hours until you found what you wanted.
And sixty years ago presidential campains weren't yet advertising on television. Harry Truman campaigned by going from town to town on the back of a train (a train!) making speeches and shaking hands with people.
Thirty years from now the world will be at least that different from the way things are now. How could I know what it'll be like?
- Which country do you believe currently leads the world in science
and technology? In ten years?
In case you hadn't noticed, I hate trying to predict the future; I don't think I'm good at it and I don't think anyone else is. Most people who try don't seem to revisit their old predictions to see if they were correct, or to learn from their past errors, and the people who listen to them never do this.
Technology prognosticators remind me of the psychics in the National Enquirer who make a hundred predictions for 2007: Jennifer Aniston will get pregnant with twins; space aliens will visit George Bush in the White House. Everyone can flap their mouth about what will happen next year, but it's not clear that anyone has any useful source of information about it, or is any better than anyone else at predicting.
I read a book a few years back called The Year 2000: A Framework for Speculation on the Next Thirty Years, by Kahn and Weiner. It has a bunch of very carefully-done predictions about the year 2000, and was written in 1967. The predictions about computers are surprisingly accurate, if you ignore the fact that they completely failed to predict the PC. The geopolitical predictions are also surprisingly accurate, if you ignore the fact that they completely failed to predict the fall of the Soviet Union.
But hardly anyone predicted the PC or the fall of the Soviet Union. And even now it's not clear whether the people who did predict those things did so because they were good at predicting or if it was just lucky guesses, like a stopped clock getting the time right twice a day.
Sometimes I have to have dinner with predictors. It never goes well. Two years ago at OSCON I was invited to dinner with Google. I ended up sitting at a whole table of those people. Last year I was invited again. I said no thanks.
[ Addendum 20180423: Andrew Plotkin's rec.arts.sf.written post. ]
[Other articles in category /book] permanent link
Wed, 18 Oct 2006
A statistical puzzle
I heard a nice story a few years back. I don't know if it's true, but
it's fun anyway. The story was that the University of North Carolina
surveyed their graduates, asking them how much money they made, and
calculated the average salary for each major. Can you guess which
major had the highest average salary?
Answer:
| Geography |
Can you explain this?
Explanation:
| Michael Jordan majored in Geography. |
[Other articles in category /math] permanent link
Tue, 17 Oct 2006
It's not pi
In August I was in Portland for OSCON. One afternoon I went out to
Washington Park to visit the museums there. The light rail station is
underground, inside a hill, and the walls are decorated with all sorts
of interesting things. For example, there's an illuminated panel with
pictures of a sea urchin, a cactus, and a guy with a mohawk; another
one compares an arm bone and a trombone. They bored a long lava core
out of the hill, and display the lava core on the wall:

The inbound platform walls have a bunch of mathematics displays, including a display of Pascal's triangle. Here's a picture of one of them that I found extremely puzzling:

So what's the deal? Did they just screw up? Did they think nobody would notice? Is it a coded message? Or is there something else going on that I didn't get?
[ Addendum 20061017: The answer! ]
[Other articles in category /math] permanent link
Why it was the wrong pi
It my last article, I
pointed out that the value of π carved into the wall of the
Washington Park Portland MAX station is wrong:

3.1415926535 8979323846 2643383279 5028841971 6939937510 5820974944 5923078164 0628620899 8628034825 3421170679
8214808651 3282306647 0938446095 5058223172 5359408128 4811174502 8410270193 8521105559 6446229489 5493038196
4428810975 6659334461 2847564823 3786783165 2712019091 4564856692 3460348610 4543266482 1339360726 0249141273
7245870066 0631558817 4881520920 9628292540 9171536436 7892590360 0113305305 4882046652 1384146951 9415116094
3305727036 5759591953 0921861173 8193261179 3105118548 0744623799 6274956735 1885752724 8912279381 8301194912
9833673362 4406566430 8602139494 6395224737 1907021798 6094370277 0539217176 2931767523 8467481846 7669405132
0005681271 4526356082 7785771342 7577896091 7363717872 1468440901 2249534301 4654958537 1050792279 6892589235
4201995611 2129021960 8640344181 5981362977 4771309960 5187072113 4999999837 2978049951 0597317328 1609631859
5024459455 3469083026 4252230825 3344685035 2619311881 7101000313 7838752886 5875332083 8142061717 7669147303
5982534904 2875546873 1159562863 8823537875 9375195778 1857780532 1712268066 1300192787 6611195909 2164201989
897932
The digits are meant to be read across, so that after the "535" in the
first group, the next digits are "8979..." on the same line. But
instead, the artist has skipped down to the first group in the second
line, "8214...". Whoops.This explanation was apparently discovered by Oregonians for Rationality. I found it by doing Google search for "portland 'washington park' max station pi wrong value". Thank you, Google.
One thing that struck me about the digits as written is that there seemed to be too many repeats; this is what made me wonder if the digits were invented by the artist out of laziness or an attempt to communicate a secret message. We now know that they weren't. But I wondered if my sense that there were an unusually large number of duplicates was accurate, so I counted. If the digits are normal, we would expect exactly 1/10 of the digits to be the same as the previous digit.
In fact, of 97 digit pairs, 14 are repeats; we would expect 9.7. So this does seem to be on the high side. Calculating the likelihood of 14 repeats appearing entirely by chance seems like a tedious chore, without using somewhat clever methods. I'm in the middle of reading some books by Feller and Gnedenko about probability theory, and they do explain the clever methods, but they're at home now, so perhaps I'll post about this further tomorrow.
[Other articles in category /math] permanent link
Mon, 16 Oct 2006
Why two ears?
Aaron Swartz, remembering my earlier article about
interesting science questions, sent me a reference to
an
interesting article about odd questions asked of students
applying for admission to Cambridge and Oxford universities.
The example given in the article that I found most interesting was "Why don't we just have one ear in the middle of our face?". As I said earlier, I think the mark of a good question is that it's quick to ask and long to answer. I've been thinking about this one for several days now, and seems pretty long to answer.
Any reasonable answer to this question is going to be based on evolutionary and adaptive considerations, I think. When you answer from evolutionary considerations, there are only a few kinds of answers you can give:
- It's that way because it confers a survival or reproductive advantage.
- It's that way because that's the only way it can be made to work.
- It's that way because it doesn't really matter, and that's just the way it happened to come out.
(Why only one heart? There's no benefit to having two; if you lose 50% of your cardiac capacity, you'll die anyway. Why one mouth? It needs to be big enough to eat with, and anyway, you can't lose it. Why one liver? No reason; that's just the way it's made; two livers would work just as well as one. Why two lungs? I'm not sure; I suppose it's a combination between "no reason, that's the way it's made" (#3 above) and "because that way you can still breathe even if one lung gets clogged up" (#1).)
The positioning of your ears is important. Having two ears far apart on the sides of your head allows you to locate sounds by triangulation. Triangulation requires at least two ears, and requires that they be as far apart as possible. This also explains why the ears are on the sides rather than the front.
Consider what would go wrong if the positions of the eyes and ears were switched. The ears would be pointed in the same direction, which would impede the triangulation-by-sound process. The eyes would be pointed in opposite directions, which would completely ruin the triangulation-by-sight process; you would completely lose your depth perception. So the differing position of the eyes and ears can be seen a response to the differing physical properties of light and sound: light travels in straight lines; sound does not.
The countervailing benefit to losing your depth perception would be that you would be able to see almost 180 degrees around you. Many animals do have their eyes on the side of their heads: antelopes, rabbits, and so forth. Prey, in other words. Predators have eyes on the fronts of their heads so that they can see the prey they are sneaking up on. Prey have eyes on the sides of their heads so that predators can't sneak up on their flanks. Congratulations: you're predator, not prey.
Animals do have exactly one nose in the middle of their face. Why not two? Here, triangulation is not an issue at all. Having one nose on each side of your head would not help you at all to locate the source of an odor. So the nose is stuck in the middle of the head, I suppose for mostly mechanical reasons: animals with noses evolved from animals with a long breathing tube down the middle of their bodies. The nose arises as sensors stuck in the end of the tube. This is another explanation for the one mouth.
Another consideration is symmetry. The body is symmetric, so if you want two ears, you have to put one on each side. Why is this? I used to argue that it was to save information space in the genome: there is only so much room in your chromosomes for instructions about how to build your body, so the information must be compressed. One excellent way to compress it is to make some parts like other parts and then express the differences as diffs. This, I used to say, is why the body is symmetric, why your feet look like your hands, and why men's and women's bodies are approximately the same.
I now think this is wrong. Well, wrong and right, essentially right, but mostly wrong. The fact is, there is plenty of space in the chromosomes for instructions about all sorts of stuff. Chromosomes are really big, and full of redundancy and junk. And if it's so important to save space in the chromosome, why is the inside of your body so very asymmetric?
I now think the reason for symmetries and homologies between body parts is less to do with data compression and storage space in the chromosome, and more to do with the shortness of the distance between points in information space. Suppose you are an animal with two limbs, each of which has a hand on the end. Then a freak mutation occurs so that your descendants now have four limbs. The four limbs will all have similar hands, because mutation cannot invent an entirely new kind of hand out of thin air. Your genome contains only one set of instructions for appendages that go on the ends of limbs, so these are the instructions that are available to your descendants. These instructions can be duplicated and modified, but again, there is no natural process by which a new set of instructions for a new kind of appendage can be invented from whole cloth. So your descendants' hands will look something like their feet for quite a long time.
Similarly, there is a certain probability, say p, of an earless species evolving something that functions as an ear. The number p is small, and ears arise only because of natural selection in favor of having ears. The chance that the species will simultaneously and independently evolve two completely different kinds of ear structures is no more than p2, which is vanishingly small. And once the species has something earlike, the selection pressure in favor of the second sort of ear is absent. So a species gets one kind of ear. If having two ears is beneficial, it is extremely unlikely to arise through independent evolution, and much more likely to arise through a much smaller mutation that directs the same structure, the one for which complete instructions already exist in the genome, to appear on each side of the head.
So this is the reason for bodily symmetry. Think of (A) an earless organism, (B) an organism with two completely different ears, and (C) an organism with two identical ears. Think of these as three points in the space of all possible organisms. The path from point A to C is both much shorter than the path from A to B, and also much more likely to be supported by selection processes.
Now, why is the outside of the body symmetric while the inside is not? I haven't finished thinking this through yet. But I think it's because the outside interacts with the gross physical world to a much greater extent than the inside, and symmetry confers an advantage in large-scale physical interactions. Consider your legs, for example. They are approximately the same length. This is important for walking. If you had a choice between having both legs shortened six inches each, and having one leg shortened by six inches, you would certainly choose the former. (Unless you were a sidehill winder.) Similarly, having two different ears would mess up your hearing, particularly your ability to locate sounds. On the other hand, suppose one of your kidneys were much larger than the other. Big deal. Or suppose you had one giant liver on your right side and none on the left. So what? As long as your body is generally balanced, it is not going to matter, because the liver's interactions with the world are mostly on a chemical level.
So I think that's why you have an ear on each side, instead of one ear in the middle of your head: first, it wouldn't work as well to have one. Second, symmetry is favored by natural selection for information-conserving reasons.
[Other articles in category /bio] permanent link
Sat, 07 Oct 2006
Bone names
Names of bones are usually Latin. They come in two types. One type is
descriptive. The auditory ossicles (that's Latin for "little
bones for hearing") are named in English the hammer, anvil, and
stirrup, and their formal, Latin names are the malleus
("hammer"), incus ("anvil"), and stapes ("stirrup")


 The
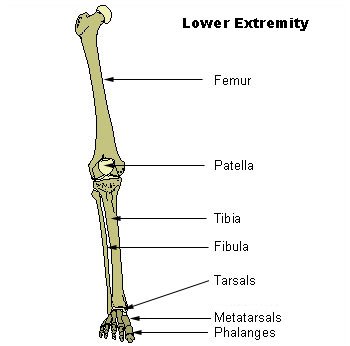
fibula is the small bone in the lower leg; it's named for the Latin
fibula, which is a kind of Roman safety pin. The other leg
bone, the tibia, is much bigger; that's the frame of the pin, and the
fibula makes the thin sharp part.
The
fibula is the small bone in the lower leg; it's named for the Latin
fibula, which is a kind of Roman safety pin. The other leg
bone, the tibia, is much bigger; that's the frame of the pin, and the
fibula makes the thin sharp part.
The kneecap is the patella, which is a "little pan". The big,
flat parietal bone in the skull is from paries, which is a wall
or partition. The clavicle, or collarbone, is a little key.
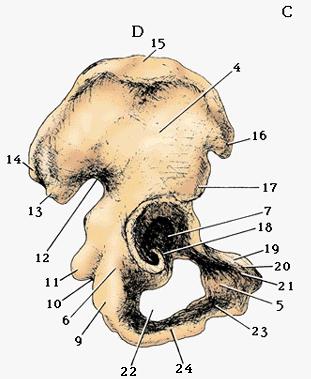 "Pelvis" is Latin for "basin". The pelvis is made of four bones: the
sacrum, the coccyx, and the left and right os innominata. Sacrum is
short for os sacrum, "the sacred bone", but I don't know why it
was called that. Coccyx is a cuckoo bird, because it looks like a
cuckoo's beak. Os innominatum means "nameless bone": they gave
up on the name because it doesn't look like anything. (See
illustration to right.)
"Pelvis" is Latin for "basin". The pelvis is made of four bones: the
sacrum, the coccyx, and the left and right os innominata. Sacrum is
short for os sacrum, "the sacred bone", but I don't know why it
was called that. Coccyx is a cuckoo bird, because it looks like a
cuckoo's beak. Os innominatum means "nameless bone": they gave
up on the name because it doesn't look like anything. (See
illustration to right.)
On the other hand, some names are not descriptive: they're just the
Latin words for the part of the body that they are. For example, the
thighbone is called the femur, which is Latin for "thigh". The
big lower arm bone is the ulna, Latin for "elbow". The upper
arm bone is the humerus, which is Latin for "shoulder".
(Actually, Latin is umerus, but classical words beginning in
"u" often acquire an initial "h" when they come into English.) The
leg bone corresponding to the ulna is the tibia, which is Latin
for "tibia". It also means "flute", but I think the flute meaning is
secondary—they made flutes out of hollowed-out tibias.
Some of the nondescriptive names are descriptive in Latin, but not in English. The vertebra in English are so called after Latin vertebra, which means the vertebra. But the Latin word is ultimately from the verb vertere, which means to turn. (Like in "avert" ("turn away") and "revert" ("turn back").) The jawbone, or "mandible", is so-called after mandibula, which means "mandible". But the Latin word is ultimately from mandere, which means to chew.
The cranium is Greek, not Latin; kranion (or κρανιον, I suppose) is Greek for "skull". Sternum, the breastbone, is Greek for "chest"; carpus, the wrist, is Greek for "wrist"; tarsus, the ankle, is Greek for "instep". The zygomatic bone of the face is yoke-shaped; ζυγος ("zugos") is Greek for "yoke".
The hyoid bone is the only bone that is not attached to any other bone. (It's located in the throat, and supports the base of the tongue.) It's called the "hyoid" bone because it's shaped like the letter "U". This used to puzzle me, but the way to understand this is to think of it as the "U-oid" bone, which makes sense, and then to remember two things. First, that classical words beginning in "u" often acquire an initial "h" when they come into English, as "humerus". And second, classical Greek "u" always turns into "y" in Latin. You can see this if you look at the shape of the Greek letter capital upsilon, which looks like this: Υ. Greek αβυσσος ("abussos" = "without a bottom") becomes English "abyss"; Greek ανωνυμος ("anonumos") becomes English "anonymous"; Greek υπος ("hupos"; there's supposed to be a diacritical mark on the υ indicating the "h-" sound, but I don't know how to type it) becomes "hypo-" in words like "hypothermia" and "hypodermic". So "U-oid" becomes "hy-oid".
(Other parts of the body named for letters of the alphabet are the sigmoid ("S-shaped") flexure of the colon and the deltoid ("Δ-shaped") muscle in the arm. The optic chiasm is the place in the head where the optic nerves cross; "chiasm" is Greek for a crossing-place, and is so-called after the Greek letter Χ.)
The German word for "auditory ossicles" is Gehörknöchelchen. Gehör is "for hearing". Knöchen is "bones"; Knöchelchen is "little bones". So the German word, like the Latin phrase "auditory ossicles", means "little bones for hearing".
[Other articles in category /lang/etym] permanent link
Fri, 06 Oct 2006
[Other articles in category /anniversary] permanent link
Tue, 03 Oct 2006
Really real examples of HOP techniques in action
I recently stopped working for the University of Pennsylvannia's
Informations Systems and Computing group, which is the organization
that provides computer services to everyone on campus that doesn't
provide it for themselves.
I used HOP stuff less than I might have if I hadn't written the HOP book myself. There's always a tradeoff with the use of any advanced techniques: it might provide some technical benefit, like making the source code smaller, but the drawback is that the other people you work with might not be able to maintain it. Since I'm the author of the book, I can be expected to be biased in favor of the techniques. So I tried to compensate the other way, and to use them only when I was absolutely sure it was the best thing to do.
There were two interesting uses of HOP techniques. One was in the username generator for new accounts. The other was in a generic server module I wrote.
Name generation
The name generator is used to offer account names to incoming students and faculty. It is given the user's full name, and optionally some additional information of the same sort. It then generates a bunch of usernames to offer the user. For example, if the user's name is "George Franklin Bauer, Jr.", it might generate usernames like:
george bauer georgef fgeorge fbauer bauerf
gf georgeb fg fb bauerg bf
georgefb georgebf fgeorgeb fbauerg bauergf bauerfg
ge ba gef gbauer fge fba
bgeorge baf gfbauer gbauerf fgbauer fbgeorge
bgeorgef bfgeorge geo bau geof georgeba
fgeo fbau bauerge bauf fbauerge bauergef
bauerfge geor baue georf gb fgeor
fbaue bg bauef gfb gbf fgb
fbg bgf bfg georg georgf gebauer
fgeorg bageorge gefbauer gebauerf fgebauer
The code that did this, before I got to it, was extremely long and
convoluted. It was also extremely slow. It would generate a zillion
names (slowly) and then truncate the list to the required length.It was convoluted because people kept asking that the generation algorithm be tweaked in various ways. Each tweak was accompanied by someone hacking on the code to get it to do things a little differently.
I threw it all away and replaced it with a lazy generator based on the lazy stream stuff of Chapter 6. The underlying stream library was basically the same as the one in Chapter 6. Atop this, I built some functions that generated streams of names. For example, one requirement was that if the name generator ran out of names like the examples above, it should proceed by generating names that ended with digits. So:
sub suffix {
my ($s, $suffix) = @_;
smap { "$_$suffix" } $s;
}
# Given (a, b, c), produce a1, b1, c1, a2, b2, c2, a3...
sub enumerate {
my $s = shift;
lazyappend(smap { suffix($s, $_) } iota());
}
# Given (a, b, c), produce a, b, c, a1, b1, c1, a2, b2, c2, a3...
sub and_enumerate {
my $s = shift;
append($s, enumerate($s));
}
# Throw away names that are already used
sub available_filter {
my ($s, $pn) = @_;
$pn ||= PennNames::Generate::InUse->new;
sgrep { $pn->available($_) } $s;
}
The use of the stream approach was strongly indicated here for two
reasons. First, the number of names to generate wasn't known in
advance. It was convenient for the generation module to pass back a
data structure that encapsulated an unlimited number of names, and let
the caller mine it for as many names as were necessary. Second, the frequent changes and tinkerings to the name generation algorithm in the past suggested that an extremely modular approach would be a benefit. In fact, the requirements for the generation algorithm chanced several times as I was writing the code, and the stream approach made it really easy to tinker with the order in which names were generated, by plugging together the prefabricated stream modules.
Generic server
For a different project, I wrote a generic forking server module. The module would manage a listening socket. When a new connection was made to the socket, the module would fork. The parent would go back to listening; the child would execute a callback function, and exit when the callback returned.The callback was responsible for communicating with the client. It was passed the client socket:
sub child_callback {
my $socket = shift;
# ... read and write the socket ...
return; # child process exits
}
But typically, you don't want to have to manage the socket manually.
For example, the protocol might be conversational: read a request
from the client, reply to it, and so forth:
# typical client callback:
sub child_callback {
my $socket = shift;
while (my $request = <$socket>) {
# generate response to request
print $socket $response;
}
}
The code to handle the loop and the reading and writing was
nontrivial, but was going to be the same for most client functions.
So I provided a callback generator. The input to the callback
generator is a function that takes requests and returns appropriate
responses:
sub child_behavior {
my $request = shift;
if ($request =~ /^LOOKUP (\w+)/) {
my $input = $1;
if (my $result = lookup($input)) {
return "OK $input $result";
} else {
return "NOK $input";
}
} elsif ($request =~ /^QUIT/) {
return;
} elsif ($request =~ /^LIST/) {
my $N = my @N = all_names();
return join "\n", "OK $N", @N, ".";
} else {
return "HUH?";
}
}
This child_behavior function is not suitable as a callback,
because the argument to the callback is the socket handle. But the
child_behavior function can be turned into a callback:
$server->run(CALLBACK => make_callback(\&child_behavior));
make_callback() takes a function like
child_behavior() and wraps it up in an I/O loop to turn it
into a callback function. make_callback() looks something
like this:
sub make_callback {
my $behavior = shift;
return sub {
my $socket = shift;
while (my $request = <$socket>) {
chomp $request;
my $response = $behavior->($request);
return unless defined $response;
print $socket $response;
}
};
}
I think this was the right design; it kept the design modular and
flexible, but also simple.
[Other articles in category /prog] permanent link
Ralph Johnson on design patterns
Last month I wrote an
article about design patterns which attracted a lot of favorable
attention in blog world. I started by paraphrasing Peter
Norvig's observation that:
"Patterns" that are used recurringly in one language may be invisible or trivial in a different language.
and ended by concluding:
Patterns are signs of weakness in programming languages.Ralph Johnson, one of the four authors of the famous book Design Patterns, took note of my article and responded. I found Johnson's response really interesting, and curious in a number of ways. I think everyone who was interested in my article should read his too. [ Addendum 20070127: The link above to Ralph Johnson's response is correct, but your client will be rejected if you are referred from here. To see his blog page, visit the page without clicking on the link. ]When we identify and document one, that should not be the end of the story. Rather, we should have the long-term goal of trying to understand how to improve the language so that the pattern becomes invisible or unnecessary.
Johnson raises several points. First there is a meta-issue to deal with. Johnson says:
He clearly thinks that what he says is surprising. And other people think it is surprising, too. That is surprising to me.I did think that what I had to say was interesting and worth saying, of course, or I would not have said it. And I was not surprised to find that other people agreed with me.
One thing that I did find surprising is the uniformity of other people's surprise and interest. There were dozens of blog posts and comments in the following two weeks, all pretty much saying what a great article I had written and how right I was. I tracked the responses as carefully as I could, and I did not see any articles that called me a dumbass; I did not see any except for Johnson's that suggested that what I was saying was unsurprising.
We can't conclude from this that I am right, of course; people agree with all sorts of stupid crap. But we can conclude that that what I said was surprising and interesting, since people were surprised and interested by it, even people who already have some knowledge of this topic. Johnson is right to be surprised by this, because he thought this was obvious and well-known, and that it was clearly laid out in his book, and he was mistaken. Many or most of the readers of his book have completely missed this point. I didn't miss it, but I didn't get it from the book, either.
Johnson and his three co-authors wrote this book, Design Patterns, which has had a huge influence on the way that programming is practiced. I think a lot of that influence has been malign. Any practice can be corrupted, of course, by being reduced to its formal aspects and applied in a rote fashion. (There's a really superb discussion of this in A. Ya. Khinchin's essay On the Teaching of Mathematics, and a shorter discussion in Polya's How to Solve It, in the section on "Pedantry and Mastery".) That will happen to any successful movement, and the Gang of Four can't take all the blame for that.
But if they really intended that everyone should understand that each design pattern is a demonstration of a weakness in its target language, then they blew it, because it appears that hardly anyone understood that.
Let's pause for a moment to imagine an alternate universe in which the subtitle of the Design Patterns book was not "Elements of Reusable Object-Oriented Software" but "Solutions for Recurring Problems in Object-Oriented Languages". And let's imagine that in each section, after "Pattern name", "Intent", "Motivation", "Applicability", and so forth, there was another subsection titled "Prophylaxis" that went something like this: "The need for the Iterator pattern in C++ appears to be due partly to its inflexible type system and partly to its lack of abstract iteration structures. The iterator pattern is unnecessary in the Python language, which avoids these defects as follows: ... at the expense of ... . In Common Lisp, on the other hand, ... (etc.)".
I would have liked to have seen that universe, but I suppose it's too late now. Oh well.
Anyway, moving on from meta-issues to the issues themselves, Johnson continues:
At the very end, he says that patterns are signs of weakness in programming languages. This is wrong.This is interesting, and I was going to address it later, but I now think that it's the first evidence of a conceptual mistake that Johnson has made that underlies his entire response to my article, so I'll take it up now.
At the very end of his response, Johnson says:
No matter how complicated your language will be, there will always be things that are not in the language. These things will have to be patterns. So, we can eliminate one set of patterns by moving them into the language, but then we'll just have to focus on other patterns. We don't know what patterns will be important 50 years from now, but it is a safe bet that programmers will still be using patterns of some sort.Here we are in complete agreement. So, to echo Johnson, I was surprised that he would think this was surprising. But how can we be in complete agrement if what I said was "wrong"? There must be a misunderstanding somewhere.
I think I know where it is. When I said "[Design] Patterns are signs of weakness in programming languages," what I meant was something like "Each design pattern is a sign of a weakness in the programming language to which it applies." But it seems that Johnson thinks that I meant that the very existence of design patterns, at all, is a sign of weakness in all programming languages everywhere.
If I thought that the existence of design patterns, at all, was a sign that current programming languages are defective, as a group, I would see an endpoint to programming language development: someday, we would have a perfect überlanguage in which it would be unnecessary to use patterns because all possible patterns would have been built in already.
I think Johnson thinks this was my point. In the passage quoted above, I think he is addressing the idea of the überlanguage that incorporates all patterns everywhere at all levels of abstraction. And similarly:
Some people like languages with a lot of features. . . . I prefer simple languages.And again:
No matter how complicated your language will be, there will always be things that are not in the language.But no, I don't imagine that someday we will have the ultimate language, into which every conceivable pattern has been absorbed. So a lot of what Johnson has to say is only knocking down a straw man.
What I imagine is that when pattern P applies to language L, then, to the extent that some programmer on some project finds themselves needing to use P in their project, the use of P indicates a deficiency in language L for that project.
The absence of a convenient and simple way to do P in language L is not always a problem. You might do a project in language L that does not require the use of pattern P. Then the problem does not manifest, and, whatever L's deficiencies might be for other projects, it is not deficient in that way for your project.
This should not be difficult for anyone to understand. Perl might be a very nice language for writing a program to compile a bioinformatic data file into a more reasonable form; it might be a terrible language for writing a real-time missile guidance system. Its deficiencies operate in the missile guidance project in a way that they may not in the data munging project.
But to the extent that some deficiency does come up in your project, it is a problem, because you are implementing the same design over and over, the same arrangement of objects and classes, to accomplish the same purpose. If the language provided more support for solving this recurring design problem, you wouldn't need to use a "pattern". Consider again the example of the "subroutine" pattern in assembly language: don't you have anything better to do than redesign and re-implement the process of saving the register values in a stack frame, over and over? Well, yes, you do. And that is why you use a language that has that built in. Consider again the example of the "object-oriented class" pattern in C: don't you have anything better to do than redesign and re-implement object-oriented method dispatch with inheritance, over and over? Yes, you do. And that is why you use a language that has that built in, if that is what you need.
By Gamma, Helm, Johnson, and Vlissides' own definition, the problems solved by patterns are recurring problems, and programmers must address them recurringly.
If these problems recurred in every language, we might conclude that they were endemic to programming itself. We might not, but it's hard to say, since if there are any such problems, they have not yet been brought to my attention. Every pattern discovered so far seems to be specific to only a small subset of the world's languages.
So it seems a small step to conclude that these recurring, language-specific problems are actually problems with the languages themselves. No problem is a problem in every language, but rather each problem is a red arrow, pointing at a design flaw in the language in which it appears.
Johnson continues:
Patterns might be a sign of weakness, but they might be a sign of simplicity. . . .I think this argument fails, in light of the examples I brought up in my original article. The argument is loaded by the use of the word "simplicity". As Einstein said, things should be as simple as possible, but no simpler. In assembly language, "subroutine call" is a pattern. Does Johnson or anyone seriously think that C++ or Smalltalk or Common Lisp or Java would be improved by having the "subroutine call" pattern omitted? The languages might be "simpler", but would they be better?
The alternative, remember, is to require the programmer to use a "pattern": to make them consult a manual of "patterns" to implement a "general arrangement of objects and classes" to solve the subroutine-call problem every time it comes up.
I guess you could interpret that as a sign of "simplicity", but it's the wrong kind of simplicity. Language designers have a hard problem to solve. If they don't put enough stuff into the language, it'll be too hard to use. But if they put in too much stuff, it'll be confusing and hard to program, like C++. One reason it's hard to be a language designer is that it's hard to know what to put in and what to leave out. There is an extremely complex tradeoff between simplicity and functionality.
But in the case of "patterns", it's much easier to understand the tradeoff. A pattern, remember, is a general method for solving "a recurring design problem". Patterns might be a sign of "simplicity", but if so, they are a sign of simplicity in the wrong place, a place where the language needs to be less simple and more featureful. Because patterns are solutions to recurring design problems.
If you're a language designer, and a "pattern" comes to your attention, then you have a great opportunity. The programmers using your language have a recurring problem. They have to implement the same solution to it, over and over. Clearly, this is a good place to try to expend some design effort; perhaps you can trade off a little simplicity for some functionality and fix the language so that the problem is a problem no longer.
Getting rid of one recurring design problem might create new ones. But if the new problems are operating at a higher level of abstraction, you may have a win. Getting rid of the need for the "subroutine call" pattern in assembly language opened up all sorts of new problems: when and how do I do recursion? When and how do I do coroutines?
Getting rid of the "object-oriented class" pattern in C created a need for higher-level patterns, including the ones described in the Design Patterns book. When people didn't have to worry about implementing inheritance themselves, a lot of their attention was freed up, and they could notice patterns like Façade.
As Alfred North Whitehead says, civilization advances by extending the number of important operations which we can perform without thinking about them. The Design Patterns approach seems to be to identify the important operations and then to think about them over and over and over and over and over.
Or so it seems to me. Johnson's next paragraph makes me wonder if I've completely missed his point, because it seems completely senseless to me:
There is a trade-off between putting something in your programming language and making it be a convention, or perhaps putting it in the library. Smalltalk makes "constructor" be a convention. Arithmetic is in the library, not in the language. Control structures and exception handling are from the library, not in the language.Huh? Why does "library" matter? Unless I have missed something essential, whether something is in the "language" or the "library" is entirely an implementation matter, to be left to the discretion of the compiler writer. Is printf part of the C language, or its library? The library, everyone knows that. Oh, well, except that its behavior is completely standardized by the language standard, and it is completely permissible for the compiler writer to implement printf by putting a special case into the compiler that is enabled when the compiler happens to see the directive #include <stdio.h>. There is absolutely no requirement that printf be loaded from a separate file or anything like that.
Or consider Perl's dbmopen function. Prior to version 5.000, it was part of the "language", in some sense; in 5.000 and later, it became part of the "library". But what's the difference, really? I can't find any.
Is Johnson talking about some syntactic or semantic difference here? Maybe if I knew more about Smalltalk, I would understand his point. As it is, it seems completely daft, which I interpret to mean that there's something that went completely over my head.
Well, the whole article leaves me wondering if maybe I missed his point, because Johnson is presumably a smart guy, but his argument about the built-in features vs. libraries makes no sense to me, his argument about simplicity seems so clearly and obviously dismantled by his own definition of patterns, and his apparent attack on a straw man seems so obviously erroneous.
But I can take some consolation in the thought that if I did miss his point, I'm not the only one, because the one thing I can be sure of in all of this is that a lot of other people have been missing his point for years.
Johnson says at the beginning that he "wasn't sure whether to be happy or unhappy". If I had written a book as successful and widely read as Design Patterns and then I found out that everyone had completely misunderstood it, I think I would be unhappy. But perhaps that's just my own grumpy personality.
[ Addendum 20080303: Miles Gould wrote a pleasant and insightful article on Johnson's point about libraries vs. language features. As I surmised, there was indeed a valuable point that went over my head. I said I couldn't find any difference between "language" and "library", but, as M. Gould explains, there is an important difference that I did not appreciate in this context. ]
[Other articles in category /prog] permanent link