Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2026: | JFMAMJ |
| 2025: | JFMAMJ |
| JASOND | |
| 2024: | JFMAMJ |
| JASOND | |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
Subtopics:
| Mathematics | 250 |
| Programming | 102 |
| Language | 97 |
| Miscellaneous | 75 |
| Book | 50 |
| Tech | 49 |
| Etymology | 36 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 25 |
| Law | 23 |
| Physics | 21 |
| Perl | 17 |
| Biology | 16 |
| Brain | 15 |
| Calendar | 15 |
| Food | 15 |



Comments disabled
Sun, 26 Aug 2012
Rewriting published history in Git
My earlier article about my
habits using Git attracted some comment, most of which was
favorable. But one recurring comment was puzzlement about my seeming
willingness to rewrite published history. In practice, this was not
at all a problem, I think for three reasons:
- Rewriting published history is not nearly as confusing as people seem to think it will be.
- I worked in a very small shop with very talented developers, so the necessary communication was easy.
- Our repository setup and workflow were very well-designed and unusually effective, and made a lot of things easier, including this one.
If there are N developers, there are N+1 repositories.
There is a master repository to which only a few very responsible persons can push. It is understood that history in this repository should almost never be rewritten, only in the most exceptional circumstances. We usually call this master repository gitbox. It has only a couple of branches, typically master and deployed. You had better not push incomplete work to master, because if you do someone is likely to deploy it. When you deploy a new version from master, you advance deployed up to master to match.
In addition, each developer has their own semi-public repository, named after them, which everyone can read, but which nobody but them can write. Mine is mjd, and that's what we call it when discussing it, but my personal git configuration calls it origin. When I git push origin master I am pushing to this semi-public repo.
It is understood that this semi-public repository is my sandbox and I am free to rewrite whatever history I want in it. People building atop my branches in this repo, therefore, know that they should be prepared for me to rewrite the history they see there, or to contact me if they want me to desist for some reason.
When I get the changes in my own semi-public repository the way I want them, then I push the changes up to gitbox. Nothing is considered truly "published" until it is on the master repo.
When a junior programmer is ready to deploy to the master repository, they can't do it themselves, because they only have read access on the master. Instead, they publish to their own semi-private repository, and then notify a senior programmer to review the changes. The senior programmer will then push those changes to the master repository and deploy them.
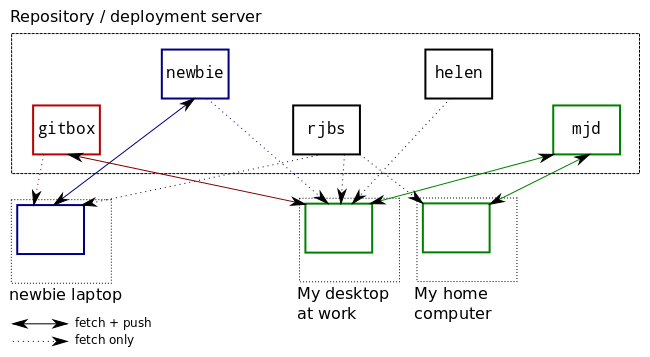
If I do work from three or four different machines, I can use the mjd repo to exchange commits between them. At the end of the day I will push my work-in-progress up to the mjd repo, and then if I want to look at it later that evening, I can fetch the work-in-progress to my laptop or another home computer.
I can create and abandon many topic branches without cluttering up the master repository's history. If I want to send a change or a new test file to a co-worker, I can push it to mjd and then point them at the branch there.
A related note: There is a lot of FUD around the rewriting of published history. For example, the "gitinfo" robot on the #git IRC channel has a canned message:
Rewriting public history is a very bad idea. Anyone else who may have pulled the old history will have to git pull --rebase and even worse things if they have tagged or branched, so you must publish your humiliation so they know what to do. You will need to git push -f to force the push. The server may not allow this. See receive.denyNonFastForwards (git-config)I think this grossly exaggerates the problems. Very bad! Humiliation! The server may deny you! But dealing with a rebased upstream branch is not very hard. It is at worst annoying: you have to rebase your subsequent work onto the rewritten branch and move any refs that pointed to that branch. If you don't have any subsequent work, you might still have to move refs, if you have any that point to it, but you might not have any.
[ Thanks to Rik Signes for helping me put this together. ]
[Other articles in category /prog] permanent link