Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2024: | JFMA |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 238 |
| Programming | 99 |
| Language | 92 |
| Miscellaneous | 67 |
| Book | 49 |
| Tech | 48 |
| Etymology | 34 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 23 |
| Physics | 21 |
| Law | 21 |
| Perl | 17 |
| Biology | 15 |



Comments disabled
Wed, 21 Feb 2007
A bug in HTML generation
A few days ago I hacked on the TeX plugin I wrote for Blosxom so that
it would put the TeX source code into the ALT attributes of the image
elements it generated.
But then I started to see requests in the HTTP error log for URLs like this:
/pictures/blog/tex/total-die-rolls.gif$${6/choose%20k}k!{N!/over%20/prod%20{i!}^{n_i}{n_i}!}/qquad%20/hbox{/rm%20where%20$k%20=%20/sum%20n_i$}$$.gif
Someone must be referring people to these incorrect URLs, and it is
presumably me. The HTML version of the blog looked okay, so I checked
the RSS and Atom files, and found that, indeed, they were malformed.
Instead of <img src="foo.gif" alt="$TeX$">, they
contained codes for <img src="foo.gif$TeX$">.I tracked down and fixed the problem. Usually when I get a bug like this, I ask myself what I could learn from it. This one is unusual. I can't think of much. Here's the bug.
The <img> element is generated by a function called imglink. The arguments to imglink are the filename that contains the image (for use in the SRC attribute) and the text for the ALT attribute. The ALT text is optional. If it is omitted, the function tries to locate the TeX source code and fetch it. If this attempt fails, it continues anyway, and omits the ALT attribute. Then it generates and returns the HTML:
sub imglink {
my $file = shift;
...
my $alt = shift || fetch_tex($file);
...
$alt = qq{alt="$alt"} if $alt;
qq{<img $alt border=0 src="$url">};
}
This function is called from several places in the plugin. Sometimes
the TeX source code is available at the place from which the call
comes, and the code has return imglink($file, $tex);
sometimes it isn't and the code has
return imglink($file) and hopes that the imglink
function can retrieve the TeX.One such place is the branch that handles generation of tags for every type of output except HTML. When generating the HTML output, the plugin actually tries to run TeX and generate the resulting image file. For other types of output, it assumes that the image file is already prepared, and just calls imglink to refer to an image that it presumes already exists:
return imglink($file, $tex) unless $blosxom::flavour eq "html";The bug was that I had written this instead:
return imglink($file. $tex) unless $blosxom::flavour eq "html";The . here is a string concatenation operator.
It's a bit surprising that I don't make more errors like this than I do. I am a very inaccurate typist.
Stronger type checking would not have saved me here. Both arguments are strings, concatenation of strings is perfectly well-defined, and the imglink function was designed and implemented to accept either one or two arguments.
The function did note the omission of the $tex argument, attempted to locate the TeX source code for the bizarrely-named file, and failed, but I had opted to have it recover and continue silently. I still think that was the right design. But I need to think about that some more.
The only lesson I have been able to extract from this so far is that I need a way of previewing the RSS and Atom outputs before publishing them. I do preview the HTML output, but in this case it was perfectly correct.
[Other articles in category /prog/bug] permanent link
Tue, 20 Feb 2007
Addenda to Apostol's proof that sqrt(2) is irrational
Yesterday I posted Tom
Apostol's wonderful proof that √2 is irrational. Here are some
additional notes about it.
- Gareth McCaughan observed that:
It's equivalent to the following simple algebraic proof: if a/b is the "simplest" integer ratio equal to √2 then consider (2b-a)/(a-b), which a little manipulation shows is also equal to √2 but has smaller numerator and denominator, contradiction.
- According to Cut-the-knot, the proof was anticipated in 1892 by A. P. Kiselev and appeared on page 121 of his book Geometry.
[Other articles in category /math] permanent link
A polynomial trivium
A couple of months ago I calculated the following polynomial—I
forget why—and wrote
it on my whiteboard. I want to erase the whiteboard, so I'm recording
the polynomial here instead.
$${9\over 8}x^4 - {45\over 4}x^3 + 39{3\over8}x^2 - 54{1\over4}x + 27$$
The property this polynomial was designed to have is this: at x = 1, 2, 3, 4, it takes the values 2, 4, 6, 8. But at x=5 it gives not 10 but 37.
[Other articles in category /math] permanent link
Mon, 19 Feb 2007
A new proof that the square root of 2 is irrational
Last week I ran into this totally brilliant proof that √2 is
irrational. The proof was discovered by Tom M. Apostol, and was
published as
"Irrationality of the Square Root of Two - A Geometric Proof"
in the American Mathematical Monthly, November
2000, pp. 841–842.
In short, if √2 were rational, we could construct an isosceles right triangle with integer sides. Given one such triangle, it is possible to construct another that is smaller. Repeating the construction, we could construct arbitrarily small integer triangles. But this is impossible since there is a lower limit on how small a triangle can be and still have integer sides. Therefore no such triangle could exist in the first place, and √2 is irrational.
In hideous detail: Suppose that √2 is rational. Then by scaling up the isosceles right triangle with sides 1, 1, and √2 appropriately, we obtain the smallest possible isosceles right triangle whose sides are all integers. (If √2 = a/b, where a/b is in lowest terms, then the desired triangle has legs with length b and hypotenuse a.) This is ΔOAB in the diagram below:
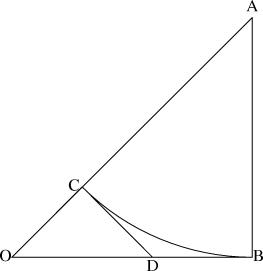
Now construct arc BC, whose center is at A. AC and AB are radii of the same circle, so AC = AB, and thus AC is an integer. Since OC = OA - CA, OC is also an integer.
Let CD be the perpendicular to OA at point C. Then ΔOCD is also an isosceles right triangle, so OC = CD, and CD is an integer. CD and BD are tangents to the same arc from the same point D, so CD = BD, and BD is an integer. Since OB and BD are both integers, so is OD.
Since OC, CD, and OD are all integers, ΔOCD is another isosceles right triangle with integer sides, which contradicts the assumption that OAB was the smallest such.
The thing I find amazing about this proof is not just how simple it is, but how strongly geometric. The Greeks proved that √2 was irrational a long time ago, with an argument that was essentially arithmetical. The Greeks being who they were, their essentially arithmetical argument was phrased in terms of geometry, with all the numbers and arithmetic represented by operations on line segments. The Tom Apostol proof is much more in the style of the Greeks than is the one that the Greeks actually found!
[ 20070220: There is a short followup to this article. ]
[Other articles in category /math] permanent link
Sun, 18 Feb 2007
ALT attributes in formula image elements
I have a Blosxom plugin that recognizes
<formula>...</formula> elements in my blog article files,
interprets the contents as TeX, converts the results to a gif file,
and then replaces the whole thing with an inline image tag to inline
the gif file.
Today I fixed the plugin to leave the original TeX source code in the ALT attribute of the IMG tag. I should have done this in the first place.
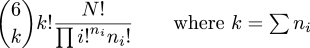
[Other articles in category /meta] permanent link
Fri, 16 Feb 2007
Yahtzee probability
In the game of Yahtzee, the players roll five dice and try to generate
various combinations, such as five of a kind, or full house (a
simultaneous pair and a three of a kind.) A fun problem is to
calculate the probabilities of getting these patterns. In Yahtzee,
players get to re-roll any or all of the dice, twice, so the probabilities
depend in part on the re-rolling strategy you choose. But the first
step in computing the probabilities is to calculate the chance of
getting each pattern in a single roll of all five dice.
A related problem is to calculate the probability of certain poker hands. Early in the history of poker, rules varied about whether a straight beat a flush; players weren't sure which was more common. Eventually it was established that straights were more common than flushes. This problem is complicated by the fact that the deck contains a finite number of each card. With cards, drawing a 6 reduces the likelihood of drawing another 6; this is not true when you roll a 6 at dice.
With three dice, it's quite easy to calculate the likelihood of rolling various patterns:
| Pattern | Probability | |
| A A A | 6 | / 216 |
| A A B | 90 | / 216 |
| A B C | 120 | / 216 |
A high school student would have no trouble with this. For pattern AAA, there are clearly only six possibilities. For pattern AAB, there are 6 choices for what A represents, times 5 choices for what B represents, times 3 choices for which die is B; this makes 90. For pattern ABC, there are 6 choices for what A represents times 5 choices for what B represents times 4 choices for what C represents; this makes 120. Then you check by adding up 6+90+120 to make sure you get 63 = 216.
It is perhaps a bit surprising that the majority of rolls of three dice have all three dice different. Then again, maybe not. In elementary school I was able to amaze some of my classmates by demonstrating that I could flip three coins and get a two-and-one pattern most of the time. Anyway, it should be clear that as the number of dice increases, the chance of them all showing all different numbers decreases, until it hits 0 for more than 6 dice.
The three-die case is unusually simple. Let's try four dice:
| Pattern | Probability | |
| A A A A | 6 | / 1296 |
| A A A B | 120 | / 1296 |
| A A B B | 90 | / 1296 |
| A A B C | 720 | / 1296 |
| A B C D | 360 | / 1296 |
There are obviously 6 ways to throw the pattern AAAA. For pattern AAAB there are 6 choices for A × 5 choices for B × 4 choices for which die is the B = 120. So far this is no different from the three-die case. But AABB has an added complication, so let's analyze AAAA and AAAB a little more carefully.
First, we count the number of ways of assigning numbers of pips on the dice to symbols A, B, and so on. Then we count the number of ways of assigning the symbols to actual dice. The total is the product of these. For AAAA there are 6 ways of assigning some number of pips to A, and then one way of assigning A's to all four dice. For AAAB there are 6×5 ways of assigning pips to symbols A and B, and then four ways of assigning A's and B's to the dice, namely AAAB, AABA, ABAA, and BAAA. With that in mind, let's look at AABB and AABC.
For AABB, There are 6 choices for A and 5 for B, as before. And there are !!4\choose2!! = 6 choices for which dice are A and which are B. This would give 6·5·6 = 180 total. But of the 6 assignments of A's and B's to the dice, half are redundant. Assignments AABB and BBAA, for example, are completely equivalent. Taking A=2 B=4 with pattern AABB yields the same die roll as A=4 B=2 with pattern BBAA. So we have double-counted everything, and the actual total is only 90, not 180.
Similarly, for AABC, we get 6 choices for A × 5 choices for B × 4 choices for C = 120. And then there seem to be 12 ways of assigning dice to symbols:
| AABC | AACB |
| ABAC | ACAB |
| ABCA | ACBA |
| BAAC | CAAB |
| BACA | CABA |
| BCAA | CBAA |
But no, actually there are only 6, because B and C are entirely equivalent, and so the patterns in the left column cover all the situations covered by the ones in the right column. The total is not 120×12 but only 120×6 = 720.
Then similarly for ABCD we have 6×5×4×3 = 360 ways of assigning pips to the symbols, and 24 ways of assigning the symbols to the dice, but all 24 ways are equivalent, so it's really only 1 way of assigning the symbols to the dice, and the total is 360.
The check step asks if 6 + 120 + 90 + 720 + 360 = 64 = 1296, which it does, so that is all right.
Before tackling five dice, let's try to generalize. Suppose the we have N dice and the pattern has k ≤ N distinct symbols which occur (respectively) p1, p2, ... pk times each.
There are !!{6\choose k}k!!! ways to assign the pips to the symbols. (Note for non-mathematicians: when k > 6, !!{6\choose k}!! is zero.)
Then there are !!N\choose p_1 p_2
\ldots p_k!! ways to assign the symbols to the dice, where
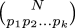 denotes the so-called multinomial
coefficient, equal to !!{N!\over
p_1!p_2!\ldots p_k!}!!.
denotes the so-called multinomial
coefficient, equal to !!{N!\over
p_1!p_2!\ldots p_k!}!!.
But some of those pi might be equal, as with
AABB, where p1 =
p2 = 2, or with AABC, where
p2 =
p3 = 1. In such cases
case some of the
assignments are redundant.
So rather than dealing with the pi directly, it's convenient to aggregate them into groups of equal numbers. Let's say that ni counts the number of p's that are equal to i. Then instead of having pi = (3, 1, 1, 1, 1) for AAABCDE, we have ni = (4, 0, 1) because there are 4 symbols that appear once, none that appear twice, and one ("A") that appears three times.
We can re-express
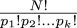 in terms of the ni:
in terms of the ni:
$$N!\over {1!}^{n_1}{2!}^{n_2}\ldots{k}!^{n_k}$$
And the reduced contribution from equivalent patterns is easy to express too; we need to divide by !!\prod {n_i}!!!. So we can write the total as:
$$ {6\choose k}k! {N!\over \prod {i!}^{n_i}{n_i}!} \qquad \text{where $k = \sum n_i$} $$
Note that k, the number of distinct symbols, is merely the sum of the ni.To get the probability, we just divide by 6N. Let's see how that pans out for the Yahtzee example, which is the N=5 case:
| Pattern | ni | Probability | |||||
| 1 | 2 | 3 | 4 | 5 | |||
| A A A A A | 1 | 6 | / 7776 | ||||
| A A A A B | 1 | 1 | 150 | / 7776 | |||
| A A A B B | 1 | 1 | 300 | / 7776 | |||
| A A A B C | 2 | 1 | 1200 | / 7776 | |||
| A A B B C | 1 | 2 | 1800 | / 7776 | |||
| A A B C D | 3 | 1 | 3600 | / 7776 | |||
| A B C D E | 5 | 720 | / 7776 | ||||
6 + 150 + 300 + 1,200 + 1,800 + 3,600 + 720 = 7,776, so this checks out. The table is actually not quite right for Yahtzee, which also recognizes "large straight" (12345 or 23456) and "small straight" (1234X, 2345X, or 3456X.) I will continue to disregard this.
The most common Yahtzee throw is one pair, by a large margin. (Any Yahtzee player could have told you that.) And here's a curiosity: a full house (AAABB), which scores 25 points, occurs twice as often as four of a kind (AAAAB), which scores at most 29 points and usually less.
The key item in the formula is the factor of !!{N!\over \prod {i!}^{n_i}{n_i}!}!! on the right. This was on my mind because of the article I wrote a couple of days ago about counting permutations by cycle class. The key formula in that article was:
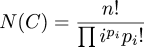
Anyway, I digress. We can generalize the formula above to work for S-sided dice;
this is a simple matter of replacing the 6 with an S. We
don't even need to recalculate the ni.
And since the key factor of 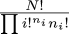 does not involve S, we can easily
precalculate it for some pattern and then plug it into the rest of the
formula to get the likelihood of rolling that pattern with different
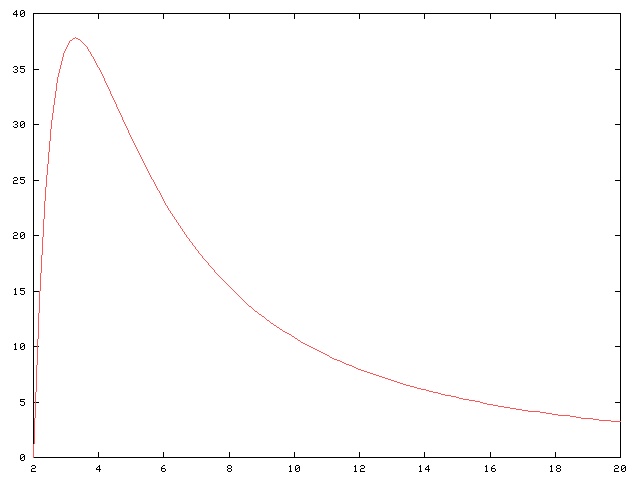
kinds of dice. For example, consider the two-pairs pattern AABBC.
This pattern has n1 = 1,
n2 = 2, so the key factor comes out to be 15.
Plugging this into the rest of the formula, we see that the probability of
rolling AABBC with five S-sided dice is
!!90 {S \choose 3} S^{-5}!!.
Here is a tabulation:
does not involve S, we can easily
precalculate it for some pattern and then plug it into the rest of the
formula to get the likelihood of rolling that pattern with different
kinds of dice. For example, consider the two-pairs pattern AABBC.
This pattern has n1 = 1,
n2 = 2, so the key factor comes out to be 15.
Plugging this into the rest of the formula, we see that the probability of
rolling AABBC with five S-sided dice is
!!90 {S \choose 3} S^{-5}!!.
Here is a tabulation:
| 
| |||||||||||||||||||||||||||||||||||||
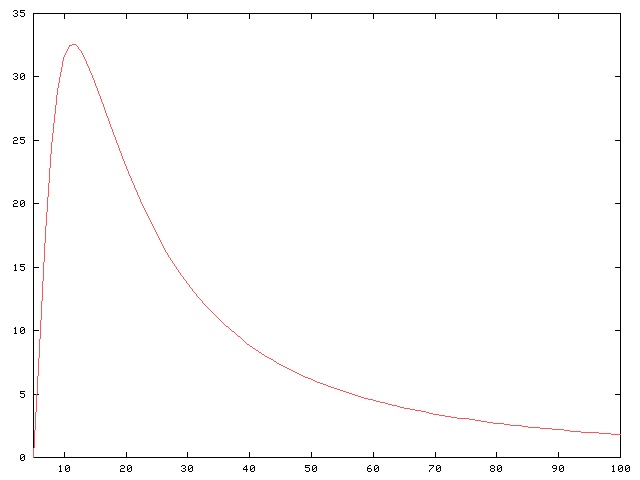
The graph is quite typical, and each pattern has its own favorite kind of dice. Here's the corresponding graph and table for rolling the AABBCDEF pattern on eight dice:
| 
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Returning to the discussion of poker hands, we might ask what the ranking of poker hands whould be, on the planet where a poker hand contains six cards instead of five. Does four of a kind beat three pair? Using the methods in this article, we can get a quick approximation. It will be something like this:
- Two trips (AAABBB)
- Overfull house (AAAABB)
- Three pair
- Four of a kind
- Full house (AAABBC)
- Three of a kind
- Two pair
- One pair
- No pair
I was going to end the article with tabulations of the number of different ways to roll each possible pattern, and the probabilities of getting them, but then I came to my senses. Instead of my running the program and pasting in the voluminous output, why not just let you run the program yourself, if you care to see the answers?
[Other articles in category /math] permanent link
Wed, 14 Feb 2007
Subtlety or sawed-off shotgun?
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
There's a line in one of William Gibson's short stories about how some situations call for a subtle and high-tech approach, and others call for a sawed-off shotgun. I think my success as a programmer, insofar as I have any, comes from knowing when to deploy each kind of approach.
In a recent article I needed to produce the table that appears at left.This was generated by a small computer program. I learned a long time ago that although it it tempting to hack up something like this by hand, you should usually write a computer program to do it instead. It takes a little extra time up front, and that time is almost always amply paid back when you inevitably decide that that table should have three columns instead of two, or the lines should alternate light and dark gray, or that you forgot to align the right-hand column on the decimal points, or whatever, and then all you have to do is change two lines of code and rerun the program, instead of hand-editing all 34 lines of the output and screwing up two of them and hand-editing them again. And again. And again.
When I was making up the seating chart for my wedding, I used this approach. I wrote a raw data file, and then a Perl program to read the data file and generate LaTeX output. The whole thing was driven by make. I felt like a bit of an ass as I wrote the program, wondering if I wasn't indulging in an excessive use of technology, and whether I was really going to run the program more than once or twice. How often does the seating chart need to change, anyway?
Gentle readers, that seating chart changed approximately one million and six times.
The Nth main division of the table at left contains one line for every partition of the integer N. The right-hand entry in each line (say 144) is calculated by a function permcount, which takes the left-hand entry (say [5, 1]) as input. The permcount function in turn calls upon fact to calculate factorials and choose to calculate binomial coefficients.

But how is the left-hand column generated? In my book, I spent quite a lot of time discussing generation of partitions of an integer, as an example of iterator techniques. Some of these techniques are very clever and highly scalable. Which of these clever partition-generating techniques did I use to generate the left-hand column of the table?
Why, none of them, of course! The left-hand column is hard-wired into
the program:
while (<DATA>) {
chomp;
my @p = split //;
...
}
...
__DATA__
1
11
2
111
12
3
...
51
6
I guessed that it would take a lot longer to write code to generate
partitions, or even to find it already written and use it, than it
would just to generate the partitions out of my head and type them in.
This guess was correct.
The only thing wrong with my approach is that it doesn't scale. But
it doesn't need to scale.
The sawed-off shotgun wins!
[ Addendum 20190920: The Gibson story is Johnny Mnemonic, which begins:
I put the shotgun in an Adidas bag and padded it out with four pairs of tennis socks, not my style at all, but that was what I was aiming for: If they think you're crude, go technical; if they think you're technical, go crude. I'm a very technical boy. So I decided to get as crude as possible.The rest of the paragraph somewhat undercuts my point: Shotguns were so long obsolete that Johnny had to manufacture the cartridges himself. ]
[Other articles in category /prog] permanent link
Tue, 13 Feb 2007
Cycle classes of permutations
I've always had trouble sleeping. In high school I would pass the
time at night by doing math. Math is a good activity for insomniacs:
It's quiet and doesn't require special equipment.
This also makes it a good way to pass the time on trains and in boring meetings. I've written before about the time-consuming math problems I use to pass time on trains.
Today's article is about another entertainment I've been using lately in meetings: count the number of permutations in each cycle class.In case you have forgotten, here is a brief summary: a permutation is a mapping from a set to itself. A cycle of a permutation is a subset of the set for which the elements fall into a single orbit. For example, the permutation:
$$ \pmatrix{1&2&3&4&5&6&7&8\cr 1&4&2&8&5&7&6&3\cr}$$
can be represented by the following diagram:
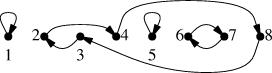
We can sort the permutations into cycle classes by saying that two permutations are in the same cycle class if the lengths of the cycles are all the same. This effectively files the numeric labels off the points in the diagrams. So, for example, the permutations of {1,2,3} fall into the three following cycle classes:
| Cycle lengths | Permutations | How many? | |
 | 1 1 1 | () | 1 |
 | 2 1 | (1 2) (1 3) (2 3) | 3 |
 | 3 | (1 2 3) (1 3 2) | 2 |
| Cycle lengths | Permutations | How many? | |
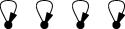 | 1 1 1 1 | () | 1 |
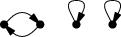 | 2 1 1 | (1 2) (1 3) (1 4) (2 3) (2 4) (1 4) | 6 |
 | 2 2 | (1 2)(3 4) (1 3)(2 4) (1 4)(2 3) | 3 |
 | 3 1 | (1 2 3) (1 2 4) (1 3 2) (1 3 4) (1 4 2) (1 4 3) (2 3 4) (2 4 3) | 8 |
 | 4 | (1 2 3 4) (1 2 4 3) (1 3 2 4) (1 3 4 2) (1 4 2 3) (1 4 3 2) | 6 |
It is not too hard a problem, and would probably only take fifteen or twenty minutes outside of a meeting, but this is exactly what makes it a good problem for meetings, where you can give the problem only partial and intermittent attention. Now that I have a simple formula, the enumeration of cycle classes loses all its entertainment value. That's the way the cookie crumbles.
Here's the formula. Suppose we want to know how many permutations of {1,...,n} are in the cycle class C. C is a partition of the number n, which is to say it's a multiset of positive integers whose sum is n. If C contains p1 1's, p2 2's, and so forth, then the number of permutations in cycle class C is:
$$ N(C) = {n! \over {\prod i^{p_i}{p_i}!}} $$
This can be proved by a fairly simple counting argument, plus a bit of algebraic tinkering. Note that if any of the pi is 0, we can disregard it, since it will contribute a factor of i0·0! = 1 in the denominator.For example, how many permutations of {1,2,3,4,5} have one 3-cycle and one 2-cycle? The cycle class is therefore {3,2}, and all the pi are 0 except for p2 = p3 = 1. The formula then gives 5! in the numerator and factors 2 and 3 in the denominator, for a total of 120/6 = 20. And in fact this is right. (It's equal to !!2{5\choose3}!!: choose three of the five elements to form the 3-cycle, and then the other two go into the 2-cycle. Then there are two possible orders for the elements of the 3-cycle.)
How many permutations of {1,2,3,4,5} have one 2-cycle and three 1-cycles? Here we have p1 = 3, p2 = 1, and the other pi are 0. Then the formula gives 120 in the numerator and factors of 6 and 2 in the denominator, for a total of 10.
Here are the breakdowns of the number of partitions in each cycle class for various n:
1
| | 1 | 1
| 2
| | 1 1 | 1
| | 2 | 1
| 3
| | 1 1 1 | 1
| | 1 2 | 3
| | 3 | 2
| 4
| | 1 1 1 1 | 1
| | 1 1 2 | 6
| | 2 2 | 3
| | 3 1 | 8
| | 4 | 6
| 5
| | 1 1 1 1 1 | 1
| | 2 1 1 1 | 10
| | 2 2 1 | 15
| | 3 1 1 | 20
| | 3 2 | 20
| | 4 1 | 30
| | 5 | 24
| 6
| | 1 1 1 1 1 1 | 1
| | 2 1 1 1 1 | 15
| | 2 2 1 1 | 45
| | 2 2 2 | 15
| | 3 1 1 1 | 40
| | 3 2 1 | 120
| | 3 3 | 40
| | 4 1 1 | 90
| | 4 2 | 90
| | 5 1 | 144
| | 6 | 120
| | ||||||||||||
Incidentally, the thing about the average permutation having exactly one fixed point is quite easy to prove. Consider a permutation of N things. Each of the N things is left fixed by exactly (N-1)! of the permutations. So the total number of fixed points in all the permutations is N!, and we are done.
A similar but slightly more contorted analysis reveals that the average number of 2-cycles per permutation is 1/2, the average number of 3-cycles is 1/3, and so forth. Thus the average number of total cycles per permutation is !!\sum_{i=1}^n{1\over i} = H_n!!. For example, for n=4, examination of the table above shows that there is 1 permutation with 4 independent cycles (the identity permutation), 6 with 3 cycles, 11 with 2 cycles, and 6 with 1 cycle, for an average of (4+18+22+6)/24 = 50/24 = 1 + 1/2 + 1/3 + 1/4.
The 1, 6, 11, 6 are of course the Stirling numbers of the first kind; the identity !!\sum{n\brack i}i = n!H_n!! is presumably well-known.
[Other articles in category /math] permanent link
Fri, 09 Feb 2007What to make of this?
- Sentence 2 is false.
- Sentence 1 is true.
Many answers are possible. The point of this note is to refute one particular common answer, which is that the whole thing is just meaningless.
This view is espoused by many people who, it seems, ought to know better. There are two problems with this view.
The first problem is that it involves a theory of meaning that appears to have nothing whatsoever to do with pragmatics. You can certainly say that something is meaningless, but that doesn't make it so. I can claim all I want to that "jqgc ihzu kenwgeihjmbyfvnlufoxvjc sndaye" is a meaningful utterance, but that does not avail me much, since nobody can understand it. And conversely, I can say as loudly and as often as I want to that the utterance "Snow is white" is meaningless, but that doesn't make it so; the utterance still means that snow is white, at least to some people in some contexts.
Similarly, asserting that the sentences are meaningless is all very well, but the evidence is against this assertion. The meaning of the utterance "sentence 2 is false" seems quite plain, and so does the meaning of the utterance "sentence 1 is true". A theory of meaning in which these simple and plain-seeming sentences are actually meaningless would seem to be at odds with the evidence: People do believe they understand them, do ascribe meaning to them, and, for the most part, agree on what the meaning is. Saying that "snow is white" is meaningless, contrary to the fact that many people agree that it means that snow is white, is foolish; saying that the example sentences above are meaningless is similarly foolish.
I have heard people argue that although the sentences are individually meaningful, they are meaningless in conjunction. This position is even more problematic. Let us refer to a person who holds this position as P. Suppose sentence 1 is presented to you in isolation. You think you understand its meaning, and since P agrees that it is meaningful, he presumably would agree that you do. But then, a week later, someone presents you with sentence 2; according to P's theory, sentence 1 now becomes meaningless. It was meaningful on February 1, but not on February 8, even though the speaker and the listener both think it is meaningful and both have the same idea of what it means. But according to P, as midnight of February 8, they are suddenly mistaken.
The second problem with the notion that the sentences are meaningless comes when you ask what makes them meaningless, and how one can distinguish meaningful sentences from sentences like these that are apparently meaningful but (according to the theory) actually meaningless.
The answer is usually something along the lines that sentences that
contain self-reference are meaningless. This answer is totally
inadequate, as has been demonstrated many times by many people,
notably W.V.O. Quine. In the example above, the self-reference
objection is refuted simply by observing that neither sentence is
self-referent. One might try to construct an argument about
reference loops, or something of the sort, but none of this will
avail, because of Quine's example:
But all of this is peripheral to the main problem with the argument
that sentences that contain self-reference are meaningless. The main
problem with this argument is that it cannot be true. The
sentence "sentences that contain self-reference are meaningless" is
itself a sentence, and therefore refers to itself, and is therefore
meaningless under its own theory. If the assertion is true, then the
sentence asserting it is meaningless under the assertion itself; the
theory deconstructs itself. So anyone espousing this theory has
clearly not thought through the consequences. (Graham Priest says that
people advancing this theory are subject to a devastating ad
hominem attack. He doesn't give it specifically, but many such
come to mind.)
In fact, the self-reference-implies-meaninglessness theory obliterates
not only itself, but almost all useful statements of logic. Consider
for example "The negation of a true sentence is false and the negation
of a false sentence is true." This sentence, or a variation of it, is
probably found in every logic textbook ever written. Such a sentence
refers to itself, and so, in the
self-reference-implies-meaninglessness theory, is meaningless. So too
with most of the other substantive assertions of our logic textbooks,
which are principally composed of such self-referent sentences about
properties of sentences; so much for logic.
The problems with ascribing meaninglessness to self-referent sentences
run deeper still. If a sentence is meaningless, it cannot be
self-referent, because, being meaningless, it cannot refer to anything
at all. Is "jqgc ihzu kenwgeihjmbyfvnlufoxvjc sndaye" self-referent?
No, because it is meaningless. In order to conclude that it was
self-referent, we would have to understand it well enough to ascribe a
meaning to it, and this would prove that it was meaningful.
So the position that the example sentences 1 and 2 are "meaningless"
has no logical or pragmatic validity at all; it is totally
indefensible. It is the philosophical equivalent of putting one's
fingers in one's ears and shouting "LA LA LA I CAN'T HEAR YOU!"
[Other articles in category /math/logic]
permanent link
Fondue
Lorrie was in charge of buying the ingredients. I did not read the
label on the wine before I opened and tasted it, and so was startled
to discover that it was a Riesling, which is very much not a dry wine,
as is traditional. Riesling is is a very sweet and fruity wine.
I asked Lorrie how she chose the wine, and she said she had gotten
Riesling because she prefers sweet wines. I remarked that dry wines
are traditional for fondue. But it was what we had, and I made the
fondue with it. Anyway, as Lorrie pointed out, fondue is often
flavored with a dash of kirsch, which is a cherry liqueur, and not at
all dry. I never have kirsch in the house, and usually use port or
sherry instead. Since we were using Riesling, I left that stuff
out.
The fondue was really outstanding, easily the most delicious fondue
I've ever made. Using Riesling totally changed the character of the
dish. The Riesling gave it a very rich and complex flavor. I'm going
to use Riesling in the future too. Give it a try.
Transfer to a caquelon (fondue pot) and serve with chunks of crusty
French bread and crisp apples.
[Other articles in category /food]
permanent link
Mnemonics
The
Wikipedia article about the number e mentions a very silly
mnemonic for remembing the digits of e: "2.7-Andrew
Jackson-Andrew Jackson-Isosceles Right Triangle". Apparently, Andrew
Jackson was elected President in 1828. When I saw this, my immediate
thought was "that's great; from now on I'll always remember when
Andrew Jackson was elected President."
In high school, I had a math teacher who pointed out that a mnemonic
for the numerical value of √3 was to recall that George
Washington was born in the year 1732. And indeed, since that day I
have never forgotten that Washington was born in 1732.
[Other articles in category /math]
permanent link
"snow is white" is false when you change "is" to "is not".
Or similarly:
If a sentence is false, then its negation is true.
Nevertheless, Quine's sentence is an antinomy of the same sort as the
example sentences at the top of the article.
Lorrie and I had fondue for dinner two nights ago. To make cheese
fondue, you melt a lot of Swiss cheese into a cup of dry white wine,
then serve hot and dunk chunks of bread into the melted cheese with
long forks. Recipe
Rub the inside of a heavy saucepan with a cut garlic clove. Heat 1
cup Riesling over medium heat in the saucepan. When the surface of
the wine is covered with fine bubbles, add 1 tablespoon corn starch
and stir until dissolved. Reduce heat and slowly add 3/4 lb grated
emmenthaler and 3/4 lb grated gruyere cheeses, stirring constantly
until completely melted.
A while back I recounted the joke about the plover's egg: A teenage
girl, upon hearing that the human testicle is the size of a plover's
egg, remarks "Oh, so that's how big a plover's egg is." I believe this
was considered risqué in 1974, when it was current. But today
I was reminded of it in a rather different context.