Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2024: | JFMA |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
| Another Git catastrophe cleaned up |
| Let's decipher a thousand-year-old magic square |
| Ysolo has been canceled |
Subtopics:
| Mathematics | 238 |
| Programming | 99 |
| Language | 92 |
| Miscellaneous | 67 |
| Book | 49 |
| Tech | 48 |
| Etymology | 34 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 23 |
| Physics | 21 |
| Law | 21 |
| Perl | 17 |
| Biology | 15 |



Comments disabled
Thu, 15 Dec 2016
Let's decipher a thousand-year-old magic square
The Parshvanatha temple in Madhya Pradesh, India was built around 1,050 years ago. Carved at its entrance is this magic square:

The digit signs have changed in the past thousand years, but it's a quick and fun puzzle to figure out what they mean using only the information that this is, in fact, a magic square.
A solution follows. No peeking until you've tried it yourself!
There are 9 one-digit entries




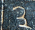
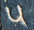
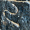

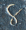
and 7 two-digit entries
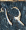

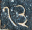
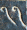


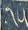
so we can guess
that the entries are the numbers 1 through 16, as is usual, and the
magic sum is 34. The appears in the
same position in all the two-digit numbers, so it's the digit 1. The
other digit of the numeral is  , and this must be zero. If it were
otherwise, it would appear on its own, as does for example the
from or the
from .
, and this must be zero. If it were
otherwise, it would appear on its own, as does for example the
from or the
from .
It is tempting to imagine that is 4.
But we can see it's not so. Adding up the rightmost column, we get
+ + + =
+ 11 + + =
(10 + ) + 11 + +
= 34,
so that must be an odd number. We
know it isn't 1 (because is 1), and it
can't be 7 or 9 because appears in the
bottom row and there is no 17 or 19. So
must be 3 or 5.
Now if were 3, then would be 13, and the third column would be
+ + + =
1 + + 10 + 13 = 34,
and then would be 10, which is too big. So must be 5, and this means that is 4 and is 8.
( appears only a as a single-digit
numeral, which is consistent with it being 8.)
The top row has
+ + + =
+ + 1 + 14 =
+ (10 + ) + 1 + 14 = 34
so that +
= 9. only appears as a single digit and
we already used 8 so must be 7 or 9.
But 9 is too big, so it must be 7, and then is 2.
is the only remaining unknown single-digit
numeral, and we already know 7 and 8, so
is 9. The leftmost column tells us
that is 16, and the last two entries,
and are
easily discovered to be 13 and 3. The decoded square is:
|
|
I like that people look at the right-hand column and immediately see 18 + 11 + 4 + 8 but it's actually 14 + 11 + 5 + 4.
This is an extra-special magic square: not only do the ten rows, columns, and diagonals all add up to 34, so do all the four-cell subsquares, so do any four squares arranged symmetrically about the center, and so do all the broken diagonals that you get by wrapping around at the edges.
[ Addendum: It has come to my attention that the digit symbols in the magic square are not too different from the current forms of the digit symbols in the Gujarati script. ]
[ Addendum 20161217: The temple is not very close to Gujarat or to the area in which Gujarati is common, so I guess that the digit symbols in Indian languages have evolved in the past thousand years, with the Gujarati versions remaining closest to the ancient forms, or else perhaps Gujarati was spoken more widely a thousand years ago. I would be interested to hear about this from someone who knows. ]
[ Addendum 20170130: Shreevatsa R. has contributed a detailed discussion of the history of the digit symbols. ]
[Other articles in category /math] permanent link
Mon, 12 Dec 2016
Another Git catastrophe cleaned up
My co-worker X had been collaborating with a front-end designer on a very large change, consisting of about 406 commits in total. The sum of the changes was to add 18 new files of code to implement the back end of the new system, and also to implement the front end, a multitude of additions to both new and already-existing files. Some of the 406 commits modified just the 18 back-end files, some modified just the front-end files, and many modified both.
X decided to merge and deploy just the back-end changes, and then, once that was done and appeared successful, to merge the remaining front-end changes.
His path to merging the back-end changes was unorthodox: he checked
out the current master, and then, knowing that the back-end changes
were isolated in 18 entirely new files, did
git checkout topic-branch -- new-file-1 new-file-2 … new-file-18
He then added the 18 files to the repo, committed them, and published
the resulting commit on master. In due course this was deployed to
production without incident.
The next day he wanted to go ahead and merge the front-end changes,
but he found himself in “a bit of a pickle”. The merge didn't go
forward cleanly, perhaps because of other changes that had been made
to master in the meantime. And trying to rebase the branch onto the
new master was a complete failure. Many of those 406 commits included
various edits to the 18 back-end files that no longer made sense now
that the finished versions of those files were in the master branch
he was trying to rebase onto.
So the problem is: how to land the rest of the changes in those 406 commits, preferably without losing the commit history and messages.
The easiest strategy in a case like this is usually to back in time:
If the problem was caused by the unorthodox checkout-add-commit, then
reset master to the point before that happened and try doing it a
different way. That strategy wasn't available because X had already
published the master with his back-end files, and a hundred other
programmers had copies of them.
The way I eventually proceeded was to rebase the 406-commit work
branch onto the current master, but to tell Git meantime that
conflicts in the 18 back-end files should be ignored, because the
version of those files on the master branch was already perfect.
Merge drivers
There's no direct way to tell Git to ignore merge conflicts in exactly
18 files, but there is a hack you can use to get the same effect.
The repo can contain a .gitattributes file that lets you specify
certain per-file options. For example, you can use .gitattributes
to say that the files in a certain directory are text, that when they
are checked out the line terminators should be converted to whatever
the local machine's line terminator convention is, and they should be
converted back to NLs when changes are committed.
Some of the per-file attributes control how merge conflicts are resolved. We were already using this feature for a certain frequently-edited file that was a list of processes to be performed in a certain order:
do A
then do B
Often different people would simultaneously add different lines to the end of this file:
# Person X's change:
do A
then do B
then do X
# Person Y's change:
do A
then do B
then do Y
X would land their version on master and later there would be a
conflict when Y tried to land their own version:
do A
then do B
<<<<<<<<
then do X
--------
then do Y
>>>>>>>>
Git was confused: did you want new line X or new line Y at the end of the file, or both, and if both then in what order? But the answer was always the same: we wanted both, X and then Y, in that order:
do A
then do B
then do X
then do Y
With the merge attribute set to union for this file, Git
automatically chooses the correct resolution.
So, returning to our pickle, I wanted to set the merge attribute for
the 18 back-end files to tell Git to always choose the version already
in master, and always ignore the changes from the branch I was
merging.
There is not exactly a way to do this, but the mechanism that is provided is extremely general, and it is not hard to get it to do what we want in this case.
The merge attribute in .gitattributes specifies the name of a
“driver” that resolves merge conflicts. The driver can be one of a
few built-in drivers, such as the union driver I just described, or
it can be the name of a user-supplied driver, configured in
.gitconfig. The first step is to use .gitattributes to tell Git
to use our private, special-purpose driver for the 18 back-end files:
new-file-1 merge=ours
new-file-2 merge=ours
…
new-file-18 merge=ours
(The name ours here is completely arbitrary. I chose it because its
function was analogous to the -s ours and -X ours options of
git-merge.)
Then we add a section to .gitconfig to say what the
ours driver should do:
[merge "ours"]
name = always prefer our version to the one being merged
driver = true
The name is just a human-readable description and is ignored by Git.
The important part is the deceptively simple-appearing driver = true
line. The driver is actually a command that is run when there is
a merge conflict. The command is run with the names of three files
containing different versions of the target file: the main file
being merged into, and temporary files containing the version with the
conflicting changes and the common ancestor of the first two files. It is
the job of the driver command to examine the three files, figure out how to
resolve the conflict, and modify the main file appropriately.
In this case merging the two or three versions of the file is very
simple. The main version is the one on the master branch, already
perfect. The proposed changes are superfluous, and we want to ignore
them. To modify the main file appropriately, our merge driver command
needs to do exactly nothing. Unix helpfully provides a command that
does exactly nothing, called true, so that's what we tell Git to use
to resolve merge conflicts.
With this configured, and the changes to .gitattributes checked in,
I was able to rebase the 406-commit topic branch onto the current
master. There were some minor issues to work around, so it was not
quite routine, but the problem was basically solved and it wasn't a
giant pain.
I didn't actually use git-rebase
I should confess that I didn't actually use git-rebase at this
point; I did it semi-manually, by generating a list of commit IDs and
then running a loop that cherry-picked them one at a time:
tac /tmp/commit-ids |
while read commit; do
git cherry-pick $commit || break
done
I don't remember why I thought this would be a better idea than just
using git-rebase, which is basically the same thing. (Superstitious anxiety,
perhaps.) But I think the process and the result were pretty much the
same. The main drawback of my approach is that if one of the
cherry-picks fails, and the loop exits prematurely, you have to
hand-edit the commit-ids file before you restart the loop, to remove the commits that were
successfully picked.
Also, it didn't work on the first try
My first try at the rebase didn't quite work. The merge driver was
working fine, but some commits that it wanted to merge modified only
the 18 back-end files and nothing else. Then there were merge
conflicts, which the merge driver said to ignore, so that the net
effect of the merged commit was to do nothing. But git-rebase
considers that an error, says something like
The previous cherry-pick is now empty, possibly due to conflict resolution.
If you wish to commit it anyway, use:
git commit --allow-empty
and stops and waits for manual confirmation. Since 140 of the 406 commits modified only the 18 perfect files I was going to have to intervene manually 140 times.
I wanted an option that told git-cherry-pick that empty commits were
okay and just to ignore them entirely, but that option isn't in
there. There is something almost as good though; you can supply
--keep-redundant-commits and instead of failing it will go ahead and create commits
that make no changes. So I ended up with a branch with 406 commits of
which 140 were empty. Then a second git-rebase eliminated them,
because the default behavior of git-rebase is to discard empty
commits. I would have needed that final rebase anyway, because I had
to throw away the extra commit I added at the beginning to check in
the changes to the .gitattributes file.
A few conflicts remained
There were three or four remaining conflicts during the giant rebase, all resulting from the following situation: Some of the back-end files were created under different names, edited, and later moved into their final positions. The commits that renamed them had unresolvable conflicts: the commit said to rename A to B, but to Git's surprise B already existed with different contents. Git quite properly refused to resolve these itself. I handled each of these cases manually by deleting A.
I made this up as I went along
I don't want anyone to think that I already had all this stuff up my sleeve, so I should probably mention that there was quite a bit of this I didn't know beforehand. The merge driver stuff was all new to me, and I had to work around the empty-commit issue on the fly.
Also, I didn't find a working solution on the first try; this was my second idea. My notes say that I thought my first idea would probably work but that it would have required more effort than what I described above, so I put it aside planning to take it up again if the merge driver approach didn't work. I forget what the first idea was, unfortunately.
Named commits
This is a minor, peripheral technique which I think is important for everyone to know, because it pays off far out of proportion to how easy it is to learn.
There were several commits of interest that I referred to repeatedly while investigating and fixing the pickle. In particular:
- The last commit on the topic branch
- The first commit on the topic branch that wasn't on
master - The commit on
masterfrom which the topic branch diverged
Instead of trying to remember the commit IDs for these I just gave
them mnemonic names with git-branch: last, first, and base,
respectively. That enabled commands like git log base..last … which
would otherwise have been troublesome to construct. Civilization
advances by extending the number of important operations which we can
perform without thinking of them. When you're thinking "okay, now I
need to rebase this branch" you don't want to derail the train of
thought to remember where the bottom of the branch is every time.
Being able to refer to it as first is a big help.
Other approaches
After it was all over I tried to answer the question “What should X
have done in the first place to avoid the pickle?” But I couldn't
think of anything, so I asked Rik Signes. Rik immediately said that
X should have used git-filter-branch to separate the 406 commits
into two branches, branch A with just the changes to the 18 back-end
files and branch B with just the changes to the other files. (The
two branches together would have had more than 406 commits, since a
commit that changed both back-end and front-end files would be
represented in both branches.) Then he would have had no trouble
landing branch A on master and, after it was deployed, landing
branch B.
At that point I realized that git-filter-branch also provided a less
peculiar way out of the pickle once we were in: Instead of using my
merge driver approach, I could have filtered the original topic branch
to produce just branch B, which would have rebased onto master
just fine.
I was aware that git-filter-branch was not part of my personal
toolkit, but I was unaware of the extent of my unawareness. I would
have hoped that even if I hadn't known exactly how to use it, I would
at least have been able to think of using it. I plan to
set aside an hour or two soon to do nothing but mess around with
git-filter-branch so that next time something like this happens I
can at least consider using it.
It occurred to me while I was writing this that it would probably have
worked to make one commit on master to remove the back-end files
again, and then rebase the entire topic branch onto that commit. But
I didn't think of it at the time. And it's not as good as what I did
do, which left the history as clean as was possible at that point.
I think I've written before that this profusion of solutions is the sign of a well-designed system. The tools and concepts are powerful, and can be combined in many ways to solve many problems that the designers didn't foresee.
[Other articles in category /prog] permanent link
Thu, 08 Dec 2016An earlier article discussed how I discovered that a hoax item in a Wikipedia list had become the official name of a mountain, Ysolo Mons, on the planet Ceres.
I contacted the United States Geological Survey to point out the hoax, and on Wednesday I got the following news from their representative:
Thank you for your email alerting us to the possibility that the name Ysolo, as a festival name, may be fictitious.
After some research, we agreed with your assessment. The IAU and the Dawn Team discussed the matter and decided that the best solution was to replace the name Ysolo Mons with Yamor Mons, named for the corn/maize festival in Ecuador. The WGPSN voted to approve the change.
Thank you for bringing the matter to our attention.
(“WGPSN” is the IAU's Working Group for Planetary System Nomenclature. Here's their official announcement of the change, the USGS record of the old name and the USGS record of the new name.)
This week we cleaned up a few relevant Wikipedia articles, including one on Italian Wikipedia, and Ysolo has been put to rest.
I am a little bit sad to see it go. It was fun while it lasted. But I am really pleased about the outcome. Noticing the hoax, following it up, and correcting the name of this mountain is not a large or an important thing, but it's a thing that very few people could have done at all, one that required my particular combination of unusual talents. Those opportunities are seldom.
[ Note: The USGS rep wishes me to mention that the email I quoted above is not an official IAU communication. ]
[Other articles in category /wikipedia] permanent link