Mark Dominus (陶敏修)
mjd@pobox.com

Archive:
| 2024: | JFMA |
| 2023: | JFMAMJ |
| JASOND | |
| 2022: | JFMAMJ |
| JASOND | |
| 2021: | JFMAMJ |
| JASOND | |
| 2020: | JFMAMJ |
| JASOND | |
| 2019: | JFMAMJ |
| JASOND | |
| 2018: | JFMAMJ |
| JASOND | |
| 2017: | JFMAMJ |
| JASOND | |
| 2016: | JFMAMJ |
| JASOND | |
| 2015: | JFMAMJ |
| JASOND | |
| 2014: | JFMAMJ |
| JASOND | |
| 2013: | JFMAMJ |
| JASOND | |
| 2012: | JFMAMJ |
| JASOND | |
| 2011: | JFMAMJ |
| JASOND | |
| 2010: | JFMAMJ |
| JASOND | |
| 2009: | JFMAMJ |
| JASOND | |
| 2008: | JFMAMJ |
| JASOND | |
| 2007: | JFMAMJ |
| JASOND | |
| 2006: | JFMAMJ |
| JASOND | |
| 2005: | OND |
In this section:
Subtopics:
| Mathematics | 238 |
| Programming | 99 |
| Language | 92 |
| Miscellaneous | 67 |
| Book | 49 |
| Tech | 48 |
| Etymology | 34 |
| Haskell | 33 |
| Oops | 30 |
| Unix | 27 |
| Cosmic Call | 25 |
| Math SE | 23 |
| Physics | 21 |
| Law | 21 |
| Perl | 17 |
| Biology | 15 |



Comments disabled
Sat, 23 Apr 2016
Steph Curry: fluke or breakthrough?
[ Disclaimer: I know very little about basketball. I think there's a good chance this article contains at least one basketball-related howler, but I'm too ignorant to know where it is. ]
Randy Olson recently tweeted a link to a New York Times article about Steph Curry's new 3-point record. Here is Olson’s snapshot of a portion of the Times’ clever and attractive interactive chart:

(Skip this paragraph if you know anything about basketball. The object of the sport is to throw a ball through a “basket” suspended ten feet (3 meters) above the court. Normally a player's team is awarded two points for doing this. But if the player is sufficiently far from the basket—the distance varies but is around 23 feet (7 meters)—three points are awarded instead. Carry on!)

Stephen Curry
The chart demonstrates that Curry this year has shattered the single-season record for three-point field goals. The previous record, set last year, is 286, also by Curry; the new record is 406. A comment by the authors of the chart says
The record is an outlier that defies most comparisons, but here is one: It is the equivalent of hitting 103 home runs in a Major League Baseball season.
(The current single-season home run record is 73, and !!\frac{406}{286}·73 \approx 103!!.)
I found this remark striking, because I don't think the record is an outlier that defies most comparisons. In fact, it doesn't even defy the comparison they make, to the baseball single-season home run record.

Babe Ruth
In 1919, the record for home runs in a single season was 29, hit by Babe Ruth. The 1920 record, also by Ruth, was 54. To make the same comparison as the authors of the Times article, that is the equivalent of hitting !!\frac{54}{29}·73 \approx 136!! home runs in a Major League Baseball season.
No, far from being an outlier that defies most comparisons, I think what we're seeing here is something that has happened over and over in sport, a fundamental shift in the way the game is played; in short, a breakthrough. In baseball, Ruth's 1920 season was the end of what is now known as the dead-ball era. The end of the dead-ball era was the caused by the confluence of several trends (shrinking ballparks), rule changes (the spitball), and one-off events (Ray Chapman, the Black Sox). But an important cause was simply that Ruth realized that he could play the game in a better way by hitting a crapload of home runs.
The new record was the end of a sudden and sharp upward trend. Prior to Ruth's 29 home runs in 1919, the record had been 27, a weird fluke set way back in 1887 when the rules were drastically different. Typical single-season home run records in the intervening years were in the 11 to 16 range; the record exceeded 20 in only four of the intervening 25 years.
Ruth's innovation was promptly imitated. In 1920, the #2 hitter hit 19 home runs and the #10 hitter hit 11, typical numbers for the nineteen-teens. By 1929, the #10 hitter hit 31 home runs, which would have been record-setting in 1919. It was a different game.

Takeru Kobayashi
For another example of a breakthrough, let's consider competitive hot dog eating. Between 1980 and 1990, champion hot-dog eaters consumed between 9 and 16 hot dogs in 10 minutes. In 1991 the time was extended to 12 minutes and Frank Dellarosa set a new record, 21½ hot dogs, which was not too far out of line with previous records, and which was repeatedly approached in the following decade: through 1999 five different champions ate between 19 and 24½ hot dogs in 12 minutes, in every year except 1993.
But in 2000 Takeru Kobayashi (小林 尊) changed the sport forever, eating an unbelievably disgusting 50 hot dogs in 12 minutes. (50. Not a misprint. Fifty. Roman numeral Ⅼ.) To make the Times’ comparison again, that is the equivalent of hitting !!\frac{50}{24\frac12}·73 \approx 149!! home runs in a Major League Baseball season.
At that point it was a different game. Did the record represent a fundamental shift in hot dog gobbling technique? Yes. Kobayashi won all of the next five contests, eating between 44½ and 53¾ each time. By 2005 the second- and third-place finishers were eating 35 or more hot dogs each; had they done this in 1995 they would have demolished the old records. A new generation of champions emerged, following Kobayashi's lead. The current record is 69 hot dogs in 10 minutes. The record-setters of the 1990s would not even be in contention in a modern hot dog eating contest.

Bob Beamon
It is instructive to compare these breakthroughs with a different sort of astonishing sports record, the bizarre fluke. In 1967, the world record distance for the long jump was 8.35 meters. In 1968, Bob Beamon shattered this record, jumping 8.90 meters. To put this in perspective, consider that in one jump, Beamon advanced the record by 55 cm, the same amount that it had advanced (in 13 stages) between 1925 and 1967.
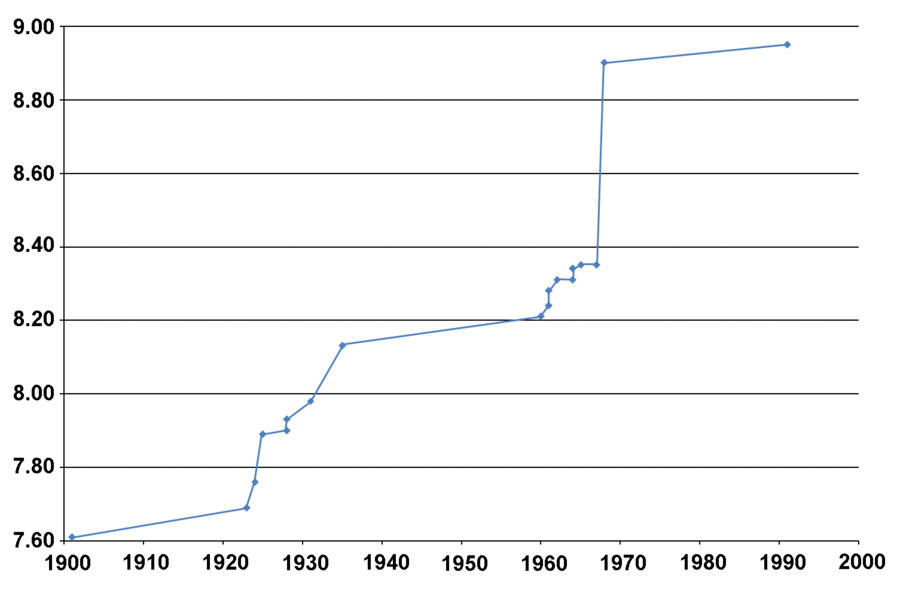
Progression of the world long jump record
The cliff at 1968 is Bob Beamon
Did Beamon's new record represent a fundamental shift in long jump technique? No: Beamon never again jumped more than 8.22m. Did other jumpers promptly imitate it? No, Beamon's record was approached only a few times in the following quarter-century, and surpassed only once. Beamon had the benefit of high altitude, a tail wind, and fabulous luck.

Joe DiMaggio
Another bizarre fluke is Joe DiMaggio's hitting streak: in the 1941 baseball season, DiMaggio achieved hits in 56 consecutive games. For extensive discussion of just how bizarre this is, see The Streak of Streaks by Stephen J. Gould. (“DiMaggio’s streak is the most extraordinary thing that ever happened in American sports.”) Did DiMaggio’s hitting streak represent a fundamental shift in the way the game of baseball was played, toward high-average hitting? Did other players promptly imitate it? No. DiMaggio's streak has never been seriously challenged, and has been approached only a few times. (The modern runner-up is Pete Rose, who hit in 44 consecutive games in 1978.) DiMaggio also had the benefit of fabulous luck.
Is Curry’s new record a fluke or a breakthrough?
I think what we're seeing in basketball is a breakthrough, a shift in the way the game is played analogous to the arrival of baseball’s home run era in the 1920s. Unless the league tinkers with the rules to prevent it, we might expect the next generation of players to regularly lead the league with 300 or 400 three-point shots in a season. Here's why I think so.
Curry's record wasn't unprecedented. He's been setting three-point records for years. (Compare Ruth’s 1920 home run record, foreshadowed in 1919.) He's continuing a trend that he began years ago.
Curry’s record, unlike DiMaggio’s streak, does not appear to depend on fabulous luck. His 402 field goals this year are on 886 attempts, a 45.4% success rate. This is in line with his success rate every year since 2009; last year he had a 44.3% success rate. Curry didn't get lucky this year; he had 40% more field goals because he made almost 40% more attempts. There seems to be no reason to think he couldn't make the same number of attempts next year with equal success, if he wants to.
Does he want to? Probably. Curry’s new three-point strategy seems to be extremely effective. In his previous three seasons he scored 1786, 1873, and 1900 points; this season, he scored 2375, an increase of 475, three-quarters of which is due to his three-point field goals. So we can suppose that he will continue to attempt a large number of three-point shots.
Is this something unique to Curry or is it something that other players might learn to emulate? Curry’s three-point field goal rate is high, but not exceptionally so. He's not the most accurate of all three-point shooters; he holds the 62nd–64th-highest season percentages for three-point success rate. There are at least a few other players in the league who must have seen what Curry did and thought “I could do that”. (Kyle Korver maybe? I'm on very shaky ground; I don't even know how old he is.) Some of those players are going to give it a try, as are some we haven’t seen yet, and there seems to be no reason why some shouldn't succeed.
A number of things could sabotage this analysis. For example, the league might take steps to reduce the number of three-point field goals, specifically in response to Curry’s new record, say by moving the three-point line farther from the basket. But if nothing like that happens, I think it's likely that we'll see basketball enter a new era of higher offense with more three-point shots, and that future sport historians will look back on this season as a watershed.
[ Addendum 20160425: As I feared, my Korver suggestion was ridiculous. Thanks to the folks who explained why. Reason #1: He is 35 years old. ]
[ Addendum 20210627: Blog article about the slowness with which the league adapted to the three-point rule. ]
[Other articles in category /games] permanent link
Tue, 19 Apr 2016A classic puzzle of mathematics goes like this:
A father dies and his will states that his elder daughter should receive half his horses, the son should receive one-quarter of the horses, and the younger daughter should receive one-eighth of the horses. Unfortunately, there are seven horses. The siblings are arguing about how to divide the seven horses when a passing sage hears them. The siblings beg the sage for help. The sage donates his own horse to the estate, which now has eight. It is now easy to portion out the half, quarter, and eighth shares, and having done so, the sage's horse is unaccounted for. The three heirs return the surplus horse to the sage, who rides off, leaving the matter settled fairly.
(The puzzle is, what just happened?)
It's not hard to come up with variations on this. For example, picking three fractions at random, suppose the will says that the eldest child receives half the horses, the middle child receives one-fifth, and the youngest receives one-seventh. But the estate has only 59 horses and an argument ensues. All that is required for the sage to solve the problem is to lend the estate eleven horses. There are now 70, and after taking out the three bequests, !!70 - 35 - 14 - 10 = 11!! horses remain and the estate settles its debt to the sage.
But here's a variation I've never seen before. This time there are 13 horses and the will says that the three children should receive shares of !!\frac12, \frac13,!! and !!\frac14!!. respectively. Now the problem seems impossible, because !!\frac12 + \frac13 + \frac14 \gt 1!!. But the sage is equal to the challenge! She leaps into the saddle of one of the horses and rides out of sight before the astonished heirs can react. After a day of searching the heirs write off the lost horse and proceed with executing the will. There are now only 12 horses, and the eldest takes half, or six, while the middle sibling takes one-third, or 4. The youngest heir should get three, but only two remain. She has just opened her mouth to complain at her unfair treatment when the sage rides up from nowhere and hands her the reins to her last horse.
[Other articles in category /math] permanent link
Thackeray's illustrations for Vanity Fair
Last month I finished reading Thackeray’s novel Vanity Fair. (Related blog post.) Thackeray originally did illustrations for the novel, but my edition did not have them. When I went to find them online, I was disappointed: they were hard to find and the few I did find were poor quality and low resolution.
Before
| After
(click to enlarge) |
The illustrations are narratively important. Jos Osborne dies suspiciously; the text implies that Becky has something to do with it. Thackeray's caption for the accompanying illustration is “Becky’s Second Appearance in the Character of Clytemnestra”. Thackeray’s depiction of Miss Swartz, who is mixed-race, may be of interest to scholars.
I bought a worn-out copy of Vanity Fair that did have the illustrations and scanned them. These illustrations, originally made around 1848 by William Makepeace Thackeray, are in the public domain. In the printing I have (George Routeledge and Sons, New York, 1886) the illustrations were 9½cm × 12½ cm. I have scanned them at 600 dpi.
Unfortunately, I was only able to find Thackeray’s full-page illustrations. He also did some spot illustrations, chapter capitals, and so forth, which I have not been able to locate.
Share and enjoy.






























[ Addendum 20180116: Evgen Stepanovych Stasiuk has brought to my attention that this set is incomplete; the original edition of Vanity Fair had 38 full-page plates. I don't know whether these were missing from the copy I scanned, or whether I just missed them, but in any case I regret the omission. The Internet Archive has a scan of the original 1848 edition, complete with all 38 plates and the interior illustrations also. ]
[Other articles in category /book] permanent link
Fri, 15 Apr 2016
How to recover lost files added to Git but not committed
If you lose something [in Git], don't panic. There's a good chance that you can find someone who will be able to hunt it down again.
I was not expecting to have a demonstration ready so soon. But today
I finished working on a project, I had all the files staged in the
index but not committed, and for some reason I no longer remember I
chose that moment to do git reset --hard, which throws away the
working tree and the staged files. I may have thought I had
committed the changes. I hadn't.
If the files had only been in the working tree, there would have been nothing to do but to start over. Git does not track the working tree. But I had added the files to the index. When a file is added to the Git index, Git stores it in the repository. Later on, when the index is committed, Git creates a commit that refers to the files already stored. If you know how to look, you can find the stored files even before they are part of a commit.
(If they are part of a commit, the problem is much easier.
Typically the answer is simply “use git-reflog to find the commit
again and check it out”. The git-reflog command is probably the
first thing anyone should learn on the path from being a Git beginner
to becoming an intermediate Git user.)
Each file added to the Git index is stored as a “blob object”. Git
stores objects in two ways. When it's fetching a lot of objects from
a remote repository, it gets a big zip file with an attached table of
contents; this is called a pack. Getting objects from a pack can be
a pain. Fortunately, not all objects are in packs. When when you just
use git-add to add a file to the index, git makes a single object,
called a “loose” object. The loose object is basically the file
contents, gzipped, with a header attached. At some point Git will
decide there are too many loose objects and assemble them into a pack.
To make a loose object from a file, the contents of the file are checksummed, and the checksum is used as the name of the object file in the repository and as an identifier for the object, exactly the same as the way git uses the checksum of a commit as the commit's identifier. If the checksum is 0123456789abcdef0123456789abcdef01234567, the object is stored in
.git/objects/01/23456789abcdef0123456789abcdef01234567
The pack files are elsewhere, in .git/objects/pack.
So the first thing I did was to get a list of the loose objects in the repository:
cd .git/objects
find ?? -type f | perl -lpe 's#/##' > /tmp/OBJ
This produces a list of the object IDs of all the loose objects in the repository:
00f1b6cc1dfc1c8872b6d7cd999820d1e922df4a
0093a412d3fe23dd9acb9320156f20195040a063
01f3a6946197d93f8edba2c49d1bb6fc291797b0
…
ffd505d2da2e4aac813122d8e469312fd03a3669
fff732422ed8d82ceff4f406cdc2b12b09d81c2e
There were 500 loose objects in my repository. The goal was to find the eight I wanted.
There are several kinds of objects in a Git repository. In addition
to blobs, which represent file contents, there are commit objects,
which represent commits, and tree objects, which represent
directories. These are usually constructed at the time the commit is
done. Since my files hadn't been committed, I knew I wasn't
interested in these types of objects. The command git cat-file -t
will tell you what type an object is. I made a file that related each
object to its type:
for i in $(cat /tmp/OBJ); do
echo -n "$i ";
git type $i;
done > /tmp/OBJTYPE
The git type command is just an alias for git cat-file -t. (Funny
thing about that: I created that alias years ago when I first started
using Git, thinking it would be useful, but I never used it, and just
last week I was wondering why I still bothered to have it around.) The
OBJTYPE file output by this loop looks like this:
00f1b6cc1dfc1c8872b6d7cd999820d1e922df4a blob
0093a412d3fe23dd9acb9320156f20195040a063 tree
01f3a6946197d93f8edba2c49d1bb6fc291797b0 commit
…
fed6767ff7fa921601299d9a28545aa69364f87b tree
ffd505d2da2e4aac813122d8e469312fd03a3669 tree
fff732422ed8d82ceff4f406cdc2b12b09d81c2e blob
Then I just grepped out the blob objects:
grep blob /tmp/OBJTYPE | f 1 > /tmp/OBJBLOB
The f 1 command throws away the types and
keeps the object IDs. At this point I had filtered the original 500
objects down to just 108 blobs.
Now it was time to grep through the blobs to find the ones I was
looking for. Fortunately, I knew that each of my lost files would
contain the string org-service-currency, which was my name for the
project I was working on. I couldn't grep the object files directly,
because they're gzipped, but the command git cat-file disgorges
the contents of an object:
for i in $(cat /tmp/OBJBLOB ) ; do
git cat-file blob $i |
grep -q org-service-curr
&& echo $i;
done > /tmp/MATCHES
The git cat-file blob $i produces the contents of the blob whose ID
is in $i. The grep searches the contents for the magic string.
Normally grep would print the matching lines, but this behavior is
disabled by the -q flag—the q is for “quiet”—and tells grep
instead that it is being used only as part of a test: it yields true
if it finds the magic string, and false if not. The && is the test;
it runs echo $i to print out the object ID $i only if the grep
yields true because its input contained the magic string.
So this loop fills the file MATCHES with the list of IDs of the
blobs that contain the magic string. This worked, and I found that
there were only 18 matching blobs, so I wrote a very similar loop to
extract their contents from the repository and save them in a
directory:
for i in $(cat /tmp/OBJBLOB ) ; do
git cat-file blob $i |
grep -q org-service-curr
&& git cat-file blob $i > /tmp/rescue/$i;
done
Instead of printing out the matching blob ID number, this loop passes
it to git cat-file again to extract the contents into a file in
/tmp/rescue.
The rest was simple. I made 8 subdirectories under /tmp/rescue
representing the 8 different files I was expecting to find. I
eyeballed each of the 18 blobs, decided what each one was, and sorted
them into the 8 subdirectories. Some of the subdirectories had only 1
blob, some had up to 5. I looked at the blobs in each subdirectory to
decide in each case which one I wanted to keep, using diff when it
wasn't obvious what the differences were between two versions of the
same file. When I found one I liked, I copied it back to its correct
place in the working tree.
Finally, I went back to the working tree and added and committed the rescued files.
It seemed longer, but it only took about twenty minutes. To recreate the eight files from scratch might have taken about the same amount of time, or maybe longer (although it never takes as long as I think it will), and would have been tedious.
But let's suppose that it had taken much longer, say forty minutes instead of twenty, to rescue the lost blobs from the repository. Would that extra twenty minutes have been time wasted? No! The twenty minutes spent to recreate the files from scratch is a dead loss. But the forty minutes to rescue the blobs is time spent learning something that might be useful in the future. The Git rescue might have cost twenty extra minutes, but if so it was paid back with forty minutes of additional Git expertise, and time spent to gain expertise is well spent! Spending time to gain expertise is how you become an expert!
Git is a core tool, something I use every day. For a long time I have been prepared for the day when I would try to rescue someone's lost blobs, but until now I had never done it. Now, if that day comes, I will be able to say “Oh, it's no problem, I have done this before!”
So if you lose something in Git, don't panic. There's a good chance that you can find someone who will be able to hunt it down again.
[Other articles in category /prog] permanent link
Tue, 12 Apr 2016
Neckbeards and other notes on “The Magnificent Ambersons”
Last week I read Booth Tarkington’s novel The Magnificent Ambersons, which won the 1919 Pulitzer Prize but today is chiefly remembered for Orson Welles’ 1942 film adaptation.
(It was sitting on the giveaway shelf in the coffee shop, so I grabbed it. It is a 1925 printing, discarded from the Bess Tilson Sprinkle library in Weaverville, North Carolina. The last due date stamped in the back is May 12, 1957.)
The Ambersons are the richest and most important family in an unnamed Midwestern town in 1880. The only grandchild, George, is completely spoiled and grows up to ruin the lives of everyone connected with him with his monstrous selfishness. Meanwhile, as the automobile is invented and the town evolves into a city the Amberson fortune is lost and the family dispersed and forgotten. George is destroyed so thoroughly that I could not even take any pleasure in it.
I made a few marginal notes as I read.
Neckbeards
It was a hairier day than this. Beards were to the wearer’s fancy … and it was possible for a Senator of the United States to wear a mist of white whisker upon his throat only, not a newspaper in the land finding the ornament distinguished enough to warrant a lampoon.
I wondered who Tarkington had in mind. My first thought was Horace Greeley:


His neckbeard fits the description, but, although he served as an unelected congressman and ran unsuccessfully for President, he was never a Senator.
Then I thought of Hannibal Hamlin, who was a Senator:

But his neckbeard, although horrifying, doesn't match the description.
Gentle Readers, can you help me? Who did Tarkington have in mind? Or, if we can't figure that out, perhaps we could assemble a list of the Ten Worst Neckbeards of 19th Century Politics.
Other notes
I was startled on Page 288 by a mention of “purple haze”, but a Google Books search reveals that the phrase is not that uncommon. Jimi Hendrix owns it now, but in 1919 it was just purple haze.
George’s Aunt Fanny writes him a letter about his girlfriend Lucy:
Mr. Morgan took your mother and me to see Modjeska in “Twelfth Night” yesterday evening, and Lucy said she thought the Duke looked rather like you, only much more democratic in his manner.
Lucy, as you see, is not entirely sure that she likes George. George, who is not very intelligent, is not aware that Lucy is poking fun at him.
A little later we see George’s letter to Lucy. Here is an excerpt I found striking:
[Yours] is the only girl’s photograph I ever took the trouble to have framed, though as I told you frankly, I have had any number of other girls’ photographs, yet all were passing fancies, and oftentimes I have questioned in years past if I was capable of much friendship toward the feminine sex, which I usually found shallow until our own friendship began. When I look at your photograph, I say to myself “At last, at last here is one that will not prove shallow.”
The arrogance, the rambling, the indecisiveness of tone, and the vacillation reminded me of the speeches of Donald Trump, whom George resembles in several ways. George has an excuse not available to Trump; he is only twenty.
Addendum 20160413: John C. Calhoun seems like a strong possibility:

Addendum 20210206: Neckbeard Society is a blog that features notable neckbeards, many more horrifying than anything you could imagine.
[Other articles in category /book] permanent link
Mon, 11 Apr 2016Recently the following amusing item was going around on Twitter:

I have some bad news and some good news. First the good news: there is an Edith-Anne. Her name is actually Patty Polk, and she lived in Maryland around 1800.
Now the bad news: the image above is almost certainly fake. It may be a purely digital fabrication (from whole cloth, ha ha), or more likely, I think, it is a real physical object, but of recent manufacture.
I wouldn't waste blog space just to crap on this harmless bit of fake history. I want to give credit where it is due, to Patty Polk who really did do this, probably with much greater proficiency.
Why I think it's fake
I have not looked into this closely, because I don't think the question merits a lot of effort. But I have two reasons for thinking so.
The main one is that the complaint “Edith-Anne … hated every Stitch” would have taken at least as much time and effort as the rest of the sampler, probably more. I find it unlikely that Edith-Anne would have put so much work—so many more hated stitches—into her rejection.
Also, the work is implausibly poor. These samplers were stitched by girls typically between the ages of 7 and 14, and their artisanship was much, much better than either section of this example. Here is a sampler made by Lydia Stocker in 1798 at the age of 12:

Here's one by Louisa Gauffreau, age 8:

 Compare these
with Edith-Anne's purported cross-stitching. One tries to imagine how
old she is, but there seems to be no good answer. The crooked
stitching is the work of a very young girl, perhaps five or six. But
the determination behind the sentiment, and the perseverance that
would have been needed to see it through, belong to a much older girl.
Compare these
with Edith-Anne's purported cross-stitching. One tries to imagine how
old she is, but there seems to be no good answer. The crooked
stitching is the work of a very young girl, perhaps five or six. But
the determination behind the sentiment, and the perseverance that
would have been needed to see it through, belong to a much older girl.
Of course one wouldn't expect Edith-Anne to do good work on her hated sampler. But look at the sampler at right, wrought by a young Emily Dickinson, who is believed to have disliked the work and to have intentionally done it poorly. Even compared with this, Edith-Anne's claimed sampler doesn't look like a real sampler.
Patty Polk
Web search for “hated every stitch” turns up several other versions of Edith-Anne, often named Polly Cook1 or Mary Pitt2 (“This was done by Mary Pitt / Who hated every stitch of it”) but without any reliable source.
However, Patty Polk is reliably sourced. Bolton and Coe's American Samplers3 describes Miss Polk's sampler:
POLK, PATTY. [Cir. 1800. Kent County, Md.] 10 yrs. 16"×16". Stem-stitch. Large garland of pinks, roses, passion flowers, nasturtiums, and green leaves; in center, a white tomb with “G W” on it, surrounded by forget-me-nots. “Patty Polk did this and she hated every stitch she did in it. She loves to read much more.”
The description was provided by Mrs. Frederic Tyson, who presumably owned or had at least seen the sampler. Unfortunately, there is no picture. The “G W” is believed to refer to George Washington, who died in 1799.
There is a lively market in designs for pseudo-vintage samplers that you can embroider yourself and “age”. One that features Patty Polk was produced by Falling Star Primitives:

Thanks to Lee Morrison of Falling Star Primitives for permission to use her “Patty Polk” design.
References
1. Parker, Rozsika. The Subversive Stitch: Embroidery and the Making of the Feminine. Routledge, 1989. p. 132.
2. Wilson, Erica. Needleplay. Scribner, 1975. p. 67.
3. Bolton, Ethel Stanwood and Eva Johnston Coe. American Samplers. Massachusetts Society of the Colonial Dames of America, 1921. p. 210.
[ Thanks to several Twitter users for suggesting gender-neutral vocabulary. ]
[ Addendum: Twitter user Kathryn Allen observes that Edith-Anne hated cross-stitch so much that she made another sampler to sell on eBay. Case closed. ]
[ Addendum: Ms. Allen further points out that the report by Mrs. Tyson in American Samplers may not be reliable, and directs me to the discussion by J.L. Bell, Clues to a Lost Sampler. ]
[ Addendum 20160619: Edith-Anne strikes again!. For someone who hated sewing, she sure did make a lot of these things. ]
[ Addendum 20200801: More about this by Emily Wells, who cites an earlier Twitter thread by fashion historian Hilary Davidson that makes the same points I did: “no matter how terribly you sewed in 1877, it would have been impossible to sew badly like this for a middle-class sampler”. ]
[ Addendum 20211011: Ms. Wells’ article also explains the connection between Patty Polk and Mrs. Tyson, who I said “presumably owned or had at least seen the sampler.”:
Patty Polk was Martha E. Polk, the daughter of Joseph Polk and Margaret Durborough. Born on March 2, 1817, Polk likely completed her needlework picture at some point in the 1830s. In 1921, Polk’s daughter, Florence McIntyre Tyson, submitted her mother’s sampler for inclusion in Bolton and Coe’s American Samplers.
]
[Other articles in category /misc] permanent link
Fri, 08 Apr 2016I'm becoming one of the people at my company that people come to when they want help with git, so I've been thinking a lot about what to tell people about it. It's always tempting to dive into the technical details, but I think the first and most important things to explain about it are:
Git has a very simple and powerful underlying model. Atop this model is piled an immense trashheap of confusing, overlapping, inconsistent commands. If you try to just learn what commands to run in what order, your life will be miserable, because none of the commands make sense. Learning the underlying model has a much better payoff because it is much easier to understand what is really going on underneath than to try to infer it, Sherlock-Holmes style, from the top.
One of Git's principal design criteria is that it should be very difficult to lose work. Everything is kept, even if it can sometimes be hard to find. If you lose something, don't panic. There's a good chance that you can find someone who will be able to hunt it down again. And if you make a mistake, it is almost always possible to put things back exactly the way they were, and you can find someone who can show you how to do it.
One exception is changes that haven't been committed. These are not yet under Git's control, so it can't help you with them. Commit early and often.
[ Addendum 20160415: I wrote a detailed account of a time I recovered lost files. ]
[ Addendum 20160505: I don't know why I didn't mention it before, but if you want to learn Git's underlying model, you should read Git from the Bottom Up (which is what worked for me) or Git from the Inside Out which is better illustrated. ]
[Other articles in category /prog] permanent link